

前言
- 轮子的核心是使用Frida来实现的。
- 菜鸡的心得,大神骂的时候温柔点,谢谢^_^
由于本人没有做过漏洞挖掘(目前苦逼码农),也没有研究过漏洞原理,就只是听说过大概有两种内存漏洞,一种栈的,一种堆的。这整个文章都是基于我自己的理解,所以很有可能想法理论都是错的,希望大家能指正。
UAF(Use After Free)字面意思就是释放内存后再使用这块释放的内存。
根据自己的理解,写了一个demo如下:
#include <iostream>
#include <unistd.h>
void uaf_printf() {
char *buff = (char *)malloc(1024);
free(buff);
strcpy(buff, "use printf after free memoryn");
printf("%sn", buff);
}
int main(int argc, char *argv[]) {
uaf_printf();
return 0;
}
由于自己也不确定这到底是不是UAF漏洞,然后经过一些复杂的途径,询问大佬,得知这就是一个UAF(暗暗自喜,随手一写就是一个漏洞)。
分析
从上面的demo可以看出来,UAF这个漏洞实际上就是释放内存之后再重新使用这块内存。所以我的大致思路就是记录下所有malloc分配的内存的地址,然后记录free的时候传递的地址是多少,然后标记内存的分配释放情况,如果某块内存分配了,直到结束都没有被释放,那么就可能导致内存泄漏;如果某块内存分配了然后释放了,这个时候这个分配的内存再被使用就存在UAF了。
开始造轮子
开始我以为我是第一个想出这种方法的,本来想着自己留着说不定能挖到一个CVE。后面才听大佬说,有很多成熟的堆漏洞检测工具。而我这个轮子不仅效率低,准确率还不如别人的。所以说这是一次失败的造轮子的经历。
既然有了上一步分析的结果,那我们就根据这个结果来造轮子,我们需要实现以下功能:
- 记录malloc分配的内存的位置,分配内存的大小以及当时堆栈情况
- 记录free传入的地址,当时的堆栈情况
- 记录一些常见可以读写内存的函数使用情况(下面代码只实现了
strcpy和printf)
程序大致流程为,js脚本执行hook操作,然后把信息传递给python脚本,python把接受的数据存到内存中,有malloc分配内存的时候,就记录分配内存的地址;有free释放内存的时候,就遍历之前存放的malloc分配的内存,将其标记为释放;有使用printf和strcpy这一类函数读写内存的时候,就去看那块内存是否被标记为已经释放,已经释放了的时候使用就是UAF。但是需要注意一些坑:
- 一块内存
malloc分配了之后使用free释放,下一次使用malloc分配内存的时候还是分配到这个地址,所以一个地址可能分配不止一次。我们可以记录分配的次数和释放的次数。如果释放的次数减去分配的次数等于零,那么就是已经释放了,如果大于零,那么就是一块内存被释放了多次,如果小于零,那么就是没有被释放。 -
printf函数内部有使用malloc分配内存,但是在改函数里面free的时候传递的值是0,所以脚本会误报很多使用printf的地方分配内存未释放。
具体怎么做的就看代码了,下面贴出专研好几个小时的代码:
js脚本
var malloc = Module.findExportByName(null, "malloc");
var calloc = Module.findExportByName(null, "calloc");
var free = Module.findExportByName(null, "free");
var strcpy = Module.findExportByName(null, "strcpy");
var memcpy = Module.findExportByName(null, "memcpy");
var read = Module.findExportByName(null, "read");
var strncpy = Module.findExportByName(null, "strncpy");
var sprintf = Module.findExportByName(null, "sprintf");
var snprintf = Module.findExportByName(null, "snprintf");
var printf = Module.findExportByName(null, "printf");
var _strlen = Module.findExportByName(null, "strlen");
var strlen = new NativeFunction(_strlen, 'ulong', ['pointer']);
var module_count = 0;
var start_trace = false;
const EXEC_NAME = "EXEC_NAME";
function init() {
Process.enumerateModules({
onMatch: function (module) {
var data = {}
data.type = "module";
data.name = module.name;
data.base = module.base;
data.path = module.path;
data.size = module.size;
send(JSON.stringify(data))
},
onComplete: function () {
}
});
}
function onStart() {
start_trace = true;
}
function onEnd() {
start_trace = false;
var enddata = {};
enddata.type = "end";
send(JSON.stringify(enddata));
}
function addressExists(addr) {
for(var item in result) {
if(result[item][ADDRESS] == addr) {
return true;
}
}
return false;
}
function __trace_memory_use() {
if(malloc != undefined) {
Interceptor.attach(malloc, {
onEnter: function (args) {
if(start_trace) {
size = "0x" + args[0].toString(16);
stack = Thread.backtrace(this.context, Backtracer.ACCURATE);
}
},
onLeave: function (retval) {
if(start_trace) {
ret = "" + retval;
var data = {};
data.type = "alloc";
data.method = "malloc";
data.address = ret;
data.size = size;
data.stack = stack;
send(JSON.stringify(data));
}
}
});
}
if(calloc != undefined) {
}
if(free != undefined) {
Interceptor.attach(free, {
onEnter: function (args) {
if(start_trace) {
var data = {};
data.type = "free";
data.address = "" + args[0];
send(JSON.stringify(data));
}
},
onLeave: function (retval) {
}
});
}
if(strcpy != undefined) {
Interceptor.attach(strcpy, {
onEnter: function (args) {
if(start_trace) {
var data = {};
data.type = "use";
data.address = "" + args[0];
data.method = "strcpy";
data.sourcelen = strlen(args[1]);
data.source = Memory.readUtf8String(args[1]);
data.stack = Thread.backtrace(this.context, Backtracer.ACCURATE);
send(JSON.stringify(data));
}
},
onLeave: function (retval) {
}
});
}
if(printf != undefined) {
Interceptor.attach(printf, {
onEnter: function (args) {
if(start_trace) {
var format = Memory.readUtf8String(args[0]);
var nformat = format.split('%').length - 1;
var data = {};
data.type = "printf";
data.method = "printf";
data.format = format;
data.nformat = nformat;
var forarg = [];
for(var i = 0; i < nformat; i++) {
forarg[i] = args[i + 1];
}
data.forarg = forarg;
data.stack = Thread.backtrace(this.context, Backtracer.ACCURATE);
send(JSON.stringify(data));
}
},
onLeave: function (retval) {
}
});
}
}
function trace() {
var main = Module.findExportByName(EXEC_NAME, "main");
if(main != undefined) {
Interceptor.attach(main, {
onEnter: function (args) {
onStart();
},
onLeave: function (retval) {
onEnd();
}
});
}
}
init();
__trace_memory_use();
trace();
python脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import frida
import json
import os
# 下面这一段是从 https://github.com/TheCjw/Frida-Android-Scripts/blob/master/loader.py#L19 抄的
import colorlog
from colorlog import ColoredFormatter
handler = colorlog.StreamHandler()
formatter = ColoredFormatter(
"%(log_color)s[%(asctime)s] [%(levelname)s]%(reset)s %(message)s",
datefmt="%H:%M:%S",
reset=True,
log_colors={
"DEBUG": "cyan",
"INFO": "green",
"WARNING": "yellow",
"ERROR": "red",
"CRITICAL": "red,bg_white",
}
)
handler.setFormatter(formatter)
logger = colorlog.getLogger("loader")
logger.addHandler(handler)
logger.level = 10 # DEBUG
# 抄完了
class dofrida(object):
def __init__(self, _exepath, _exename, _mode):
self.loads = json.loads
self.log = logger
self.modules = []
self.result = []
self.uafresult = []
self.exepath = _exepath
self.exename = _exename
self.exe = os.path.join(self.exepath, self.exename)
if _mode == "start":
device = frida.get_local_device()
pid = device.spawn([self.exe])
session = frida.attach(pid);
fd = open("./tool.js")
src = fd.read()
fd.close()
src = src.replace('const EXEC_NAME = "EXEC_NAME";', ('const EXEC_NAME = "%s";' %self.exename))
script = session.create_script(src)
if script :
script.on("message", self.on_message)
script.load()
device.resume(pid)
elif _mode == "attach":
device = frida.get_local_device()
pid = -1
for p in device.enumerate_processes():
if p.name == self.exename:
pid = p.pid
if pid != -1 :
session = frida.attach(pid)
fd = open("./tool.js")
src = fd.read()
fd.close()
src = src.replace('const EXEC_NAME = "EXEC_NAME";', ('const EXEC_NAME = "%s";' %self.exename))
src = src.replace('var start_trace = false;', 'var start_trace = true;')
session.on('detached', self.on_end)
script = session.create_script(src)
if script :
script.on("message", self.on_message)
script.load()
import sys
sys.stdin.read()
def on_message(self, message, data):
if message['type'] == 'send':
payload = self.loads(message['payload'])
if payload['type'] == "module" :
self.modules.append(payload)
elif payload['type'] == "alloc" :
address = payload['address']
method = payload['method']
if self.address_exists(address) :
alloc_info = {}
alloc_info['size'] = payload['size']
alloc_info['stack'] = payload['stack']
self.insert_item_into_exist_address(address, alloc_info)
else :
data = {}
data['address'] = address
data['method'] = method
data['alloc_count'] = 1 # 分配内存到这个地址的次数
data['free_count'] = 0 # 这个地址分配的内存被释放的次数
data['alloc'] = []
alloc_info = {}
alloc_info['size'] = payload['size']
alloc_info['stack'] = payload['stack']
data['alloc'].append(alloc_info)
self.result.append(data)
elif payload['type'] == "free":
for i in range(0, len(self.result)) :
if self.result[i]['address'] == payload['address']:
self.result[i]['free_count'] += 1
elif payload['type'] == "use":
for i in range(0, len(self.result)) :
if self.result[i]['address'] == payload['address']:
if self.result[i]['free_count'] - self.result[i]['alloc_count'] >= 0:
self.log.error("Use After Free: address: %s , alloc method: %s, use method: %s, source data: %s, source len %s, stack: %s" %(self.result[i]['address'], self.result[i]['method'], payload['method'], payload['source'], payload['sourcelen'], payload['stack']))
data = {}
data['address'] = payload['address']
data['sourcelen'] = payload['sourcelen']
data['stack'] = payload['stack']
data['source'] = payload['source']
data['method'] = payload['method']
data['count'] = self.result[i]['alloc_count']
self.uafresult.append(data)
elif payload['type'] == "printf":
if payload['nformat'] == 0 :
# 格式化字符串,误报超级高
self.log.error("Format String: format: %s, stack: %s" %(payload['format'], payload['stack']))
for i in range(0, len(self.result)):
for item in payload['forarg']:
if item == self.result[i]['address'] :
if self.result[i]['free_count'] - self.result[i]['alloc_count'] >= 0:
self.log.error("Use After Free(printf): address: %s, alloc method: %s, use method: printf, format: %s, stack: %s" %(self.result[i]['address'], self.result[i]['method'], payload['format'], payload['stack']))
data = {}
data['address'] = self.result[i]['address']
data['sourcelen'] = payload['nformat']
data['stack'] = payload['stack']
data['source'] = payload['format']
data['method'] = payload['method']
data['count'] = self.result[i]['alloc_count']
self.uafresult.append(data)
elif payload['type'] == "end" :
self.on_end()
def on_end(self):
self.log.debug("Trace Method Ended")
self.uaf()
self.doubleFree()
self.unfreed()
# 因为malloc分配的内存在free之后,下一个malloc分配的内存就会是free这个地方,so......
def address_exists(self, address):
for item in self.result:
if address == item['address'] :
return True
return False
def insert_item_into_exist_address(self, address, data):
for i in range(0, len(self.result)) :
if address == self.result[i]['address'] :
self.result[i]['alloc'].append(data)
self.result[i]['alloc_count'] += 1
def uaf(self):
hasval = False
uafre = "| address | alloc method | use method | alloc size | use size | alloc stack | use stack |n"
uafre += "| --- | --- | --- | --- | --- | --- | --- |n"
for item in self.uafresult :
for reitem in self.result:
if item['address'] == reitem['address']:
alloc_stack = ""
use_stack = ""
for st in item['stack']:
modname,modaddr = self.whichModule(st)
if modname != "None":
use_stack += "`%s->0x%x` " %(modname, (int(st, 16) - modaddr))
for st in reitem['alloc'][item['count'] - 1]['stack']:
modname,modaddr = self.whichModule(st)
if modname != "None":
alloc_stack += "`%s->0x%x` " %(modname, (int(st, 16) - modaddr))
uafre += "| %s | %s | %s | %s | %s | %s | %s |n" %(reitem['address'], reitem['method'], item['method'], reitem['alloc'][item['count'] -1]['size'], item['sourcelen'], alloc_stack, use_stack)
hasval = True
if hasval is True:
fp = open("uaf.md", "wb")
fp.write(uafre)
fp.close()
def do_printf(self):
pass
def doubleFree(self):
pass
def unfreed(self):
hasval = False
unf = "| address | method | size | stack |n"
unf += "| --- | --- | --- | --- |n"
for item in self.result:
if item['alloc_count'] - item['free_count'] > 0 :
for alloc in item['alloc'] :
stack = ""
for s in alloc['stack']:
modname,modaddr = self.whichModule(s)
if modname != "None":
stack += "`%s->0x%x` " %(modname, (int(s, 16) - modaddr))
unf += "| %s | %s | %s | %s |n" %(item['address'], item['method'], alloc['size'], stack)
hasval = True
if hasval is True:
fp = open("unfreed.md", "wb")
fp.write(unf)
fp.close()
def whichModule(self, address) :
addr = int(address, 16)
for module in self.modules:
modaddr = int(module['base'], 16)
modsize = module['size']
if (addr >= modaddr) and (addr < modaddr + modsize) :
return module['name'], modaddr
return "None","None"
def main():
_exepath = "../testcase"
_exename = "main.elf"
dofrida(_exepath=_exepath, _exename=_exename, _mode="attach")
if __name__ == '__main__':
main()
脚本使用起来也很简单,修改main函数里面的两个值:_exepath为可执行文件在哪个文件夹(使用start这种模式才有效),_exename为可执行文件的名字。然后修改dofrida创建对象的时候最后一个参数_mode,有两种模式,一种start,一种attach,start是由frida来启动这个程序,attach是附加到已经启动的程序上面(脚本写的很简单)。
使用自己造的轮子实践RHme3 CTF
RHme3 CTF是一UAF的题,下面用我们自己造的轮子来实践一下:
- 修改
main函数里面的_exename为main.elf,然后修改_mode为attach - 启动
main.elf - 运行我们的python脚本
- 在
main.elf里面做这些操作。添加一个player,选择第0个player,添加一个player,删除第0个player,然后显示选择的player,最后退出。 - 使用ida打开
main.elf,然后rebase program..到0x0。
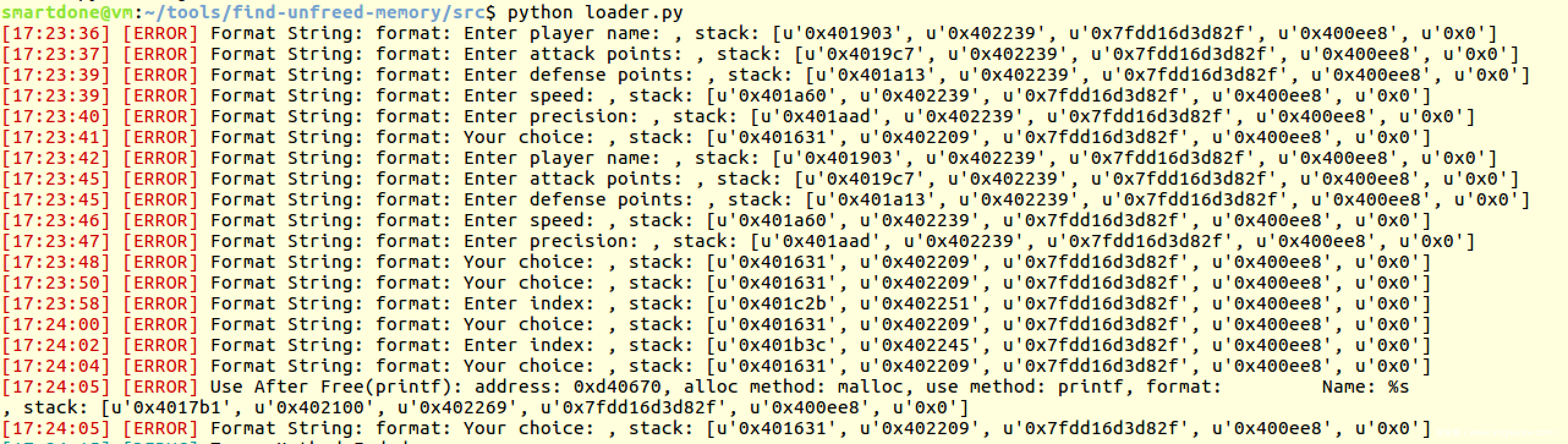
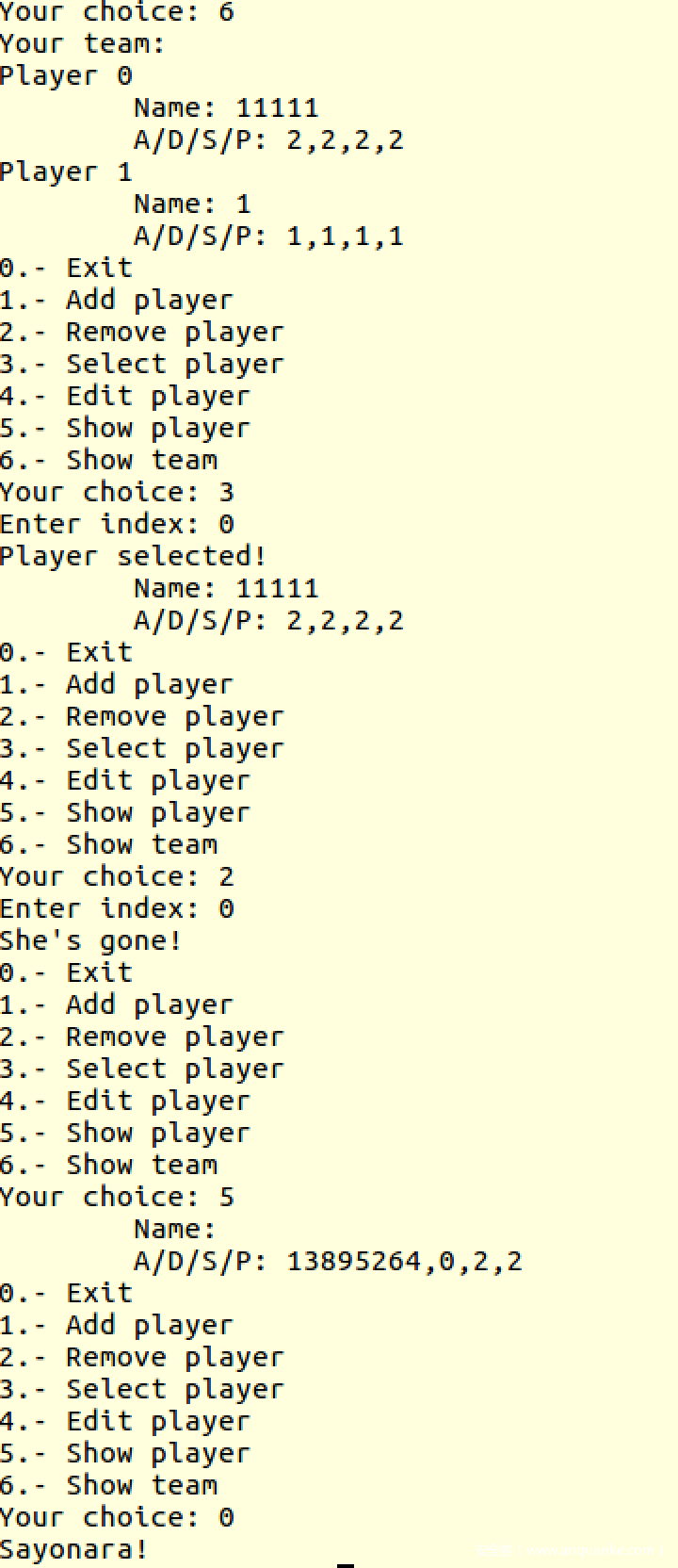
我们在上面步骤中会得到一个uaf.md的文件,其内容如下
| address | alloc method | use method | alloc size | use size | alloc stack | use stack |
|---|---|---|---|---|---|---|
| 0xd40670 | malloc | printf | 0x6 | 1 |
main.elf->0x195a main.elf->0x2239 libc-2.23.so->0x2082f main.elf->0xee8
|
main.elf->0x17b1 main.elf->0x2100 main.elf->0x2269 libc-2.23.so->0x2082f main.elf->0xee8
|
我们需要的关键数据是malloc和printf的时候的堆栈,其中malloc的时候堆栈最上面是0x195a,printf的时候堆栈最上面为0x17b1。
我们用ida按g键跳转到0x195a,这个位置其实是执行完malloc之后跳转的地址,我们可以差不多比较精确的定位到存在UAF漏洞的malloc分配的地方就是下面哪里
.text:00000000000018DB mov rax, [rbp+s]
.text:00000000000018E2 mov edx, 18h ; n
.text:00000000000018E7 mov esi, 0 ; c
.text:00000000000018EC mov rdi, rax ; s
.text:00000000000018EF call _memset
.text:00000000000018F4 mov edi, 4024BBh ; format
.text:00000000000018F9 mov eax, 0
.text:00000000000018FE call _printf
.text:0000000000001903 mov rax, cs:stdout@@GLIBC_2_2_5
.text:000000000000190A mov rdi, rax ; stream
.text:000000000000190D call _fflush
.text:0000000000001912 lea rax, [rbp+src]
.text:0000000000001919 mov edx, 100h ; n
.text:000000000000191E mov esi, 0 ; c
.text:0000000000001923 mov rdi, rax ; s
.text:0000000000001926 call _memset
.text:000000000000192B lea rax, [rbp+src]
.text:0000000000001932 mov esi, 100h
.text:0000000000001937 mov rdi, rax
.text:000000000000193A call readline
.text:000000000000193F lea rax, [rbp+src]
.text:0000000000001946 mov rdi, rax ; s
.text:0000000000001949 call _strlen
.text:000000000000194E add rax, 1
.text:0000000000001952 mov rdi, rax ; size
.text:0000000000001955 call _malloc
.text:000000000000195A mov rdx, rax
.text:000000000000195D mov rax, [rbp+s]
.text:0000000000001964 mov [rax+10h], rdx
然后我们按g跳转到0x17b1,这个地方就是释放后使用的地方了:
.text:000000000000178B show_player_func proc near ; CODE XREF: select_player+BB↓p
.text:000000000000178B ; show_player+48↓p ...
.text:000000000000178B
.text:000000000000178B var_8 = qword ptr -8
.text:000000000000178B
.text:000000000000178B push rbp
.text:000000000000178C mov rbp, rsp
.text:000000000000178F sub rsp, 10h
.text:0000000000001793 mov [rbp+var_8], rdi
.text:0000000000001797 mov rax, [rbp+var_8]
.text:000000000000179B mov rax, [rax+10h]
.text:000000000000179F mov rsi, rax
.text:00000000000017A2 mov edi, 402447h ; format
.text:00000000000017A7 mov eax, 0
.text:00000000000017AC call _printf
.text:00000000000017B1 mov rax, cs:stdout@@GLIBC_2_2_5
.text:00000000000017B8 mov rdi, rax ; stream
.text:00000000000017BB call _fflush
.text:00000000000017C0 mov rax, [rbp+var_8]
.text:00000000000017C4 mov esi, [rax+0Ch]
.text:00000000000017C7 mov rax, [rbp+var_8]
.text:00000000000017CB mov ecx, [rax+8]
.text:00000000000017CE mov rax, [rbp+var_8]
.text:00000000000017D2 mov edx, [rax+4]
.text:00000000000017D5 mov rax, [rbp+var_8]
.text:00000000000017D9 mov eax, [rax]
.text:00000000000017DB mov r8d, esi
.text:00000000000017DE mov esi, eax
.text:00000000000017E0 mov edi, 402452h ; format
.text:00000000000017E5 mov eax, 0
.text:00000000000017EA call _printf
.text:00000000000017EF mov rax, cs:stdout@@GLIBC_2_2_5
.text:00000000000017F6 mov rdi, rax ; stream
.text:00000000000017F9 call _fflush
.text:00000000000017FE nop
.text:00000000000017FF leave
.text:0000000000001800 retn
.text:0000000000001800 show_player_func endp
我们的实践就到此为止了。
轮子存在的缺陷
- 因为
malloc、free、strcpy这些函数调用太频繁了,应用被hook的时候会很卡很卡,甚至崩溃掉。 - 内存读写相关函数太多,要全部实现监控,写代码是个体力活。
- 这个只是针对函数级别的监控,假如是直接对某个地址赋值就监控不到了,比如下面这样:
char *x = (char *)malloc(1024);
char *p = x;
for(int i = 0; i < 10; i++) {
*p = 'x';
p++;
}
致谢
- 感谢TheCjw教我写frida脚本
- 感谢Bean3ai和我讨论堆相关知识
- 感谢堆利用——UAF之殇这篇文章让我找到测试用例
- 感谢linux-x86-UAF.md让我大致了解UAF
菜鸡心声
我也想学挖洞,求大佬带我。我求学道德水准还是可以的,不会因为一些小问题来一直烦你们,一直问。只有遇到无从下手的问题的时候才会提问,而且也不一定需要完整解答,教我思路就行。目前特别需要一个人指点下,我要挖洞的话应该怎么入手,外行完全不知道该从何做起。要是有大佬看中,就请收下我吧。







发表评论
您还未登录,请先登录。
登录