

议题概要
dlmalloc和jemalloc是Android用户空间使用的两个内存管理器,议题详细分析了两种malloc的实现,深入分配和释放的算法,数据结构的相关细节,讲解中还附带提供了几个堆内存可视化的调试器插件。最后会介绍如何利用堆分配器控制内存布局,并以堆缓冲区溢出为例讲解具体应用。
作者介绍
三叉戟(Pegasus)让以色列的NSO Group一战成名,Shmarya Rubenstein正是该组织成员之一。他研究的领域上至应用软件和固件的代码,下至芯片、PCB级别的硬件实现,精熟于嵌入式设备的安全分析。具有十二年专业领域的逆向分析经验。
议题解析
dlmalloc
经历了数十年的迭代更新,目前仍然广泛活跃在历史舞台的漏洞几乎都是堆内存中出现的漏洞(OOB,UAF)。想要在目标进程中利用这些漏洞时,不免都要和内存分配器打交道。
Android对libc的实现里(bionic)一开始采用了dlmalloc(诞生于1987,于2012停止更新),是一套非常成熟的解决方案。
dlmalloc通过segment和chunk管理内存,一块segment当中包含若干块chunk,当有比如malloc(0x300)的内存申请时,top chunk会划分出一块新内存:
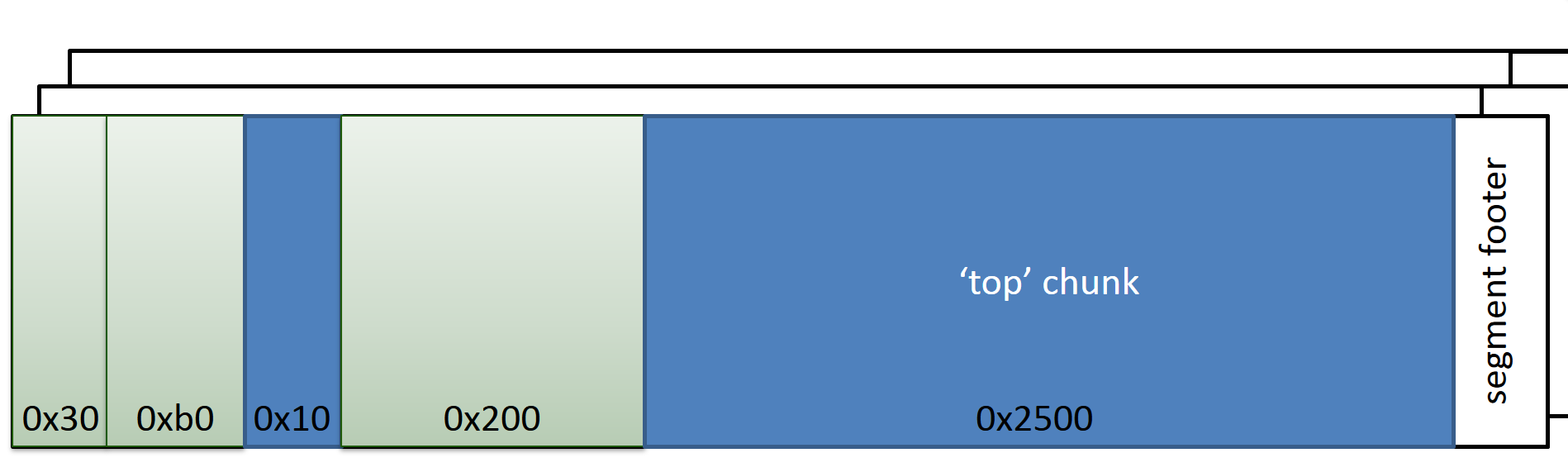
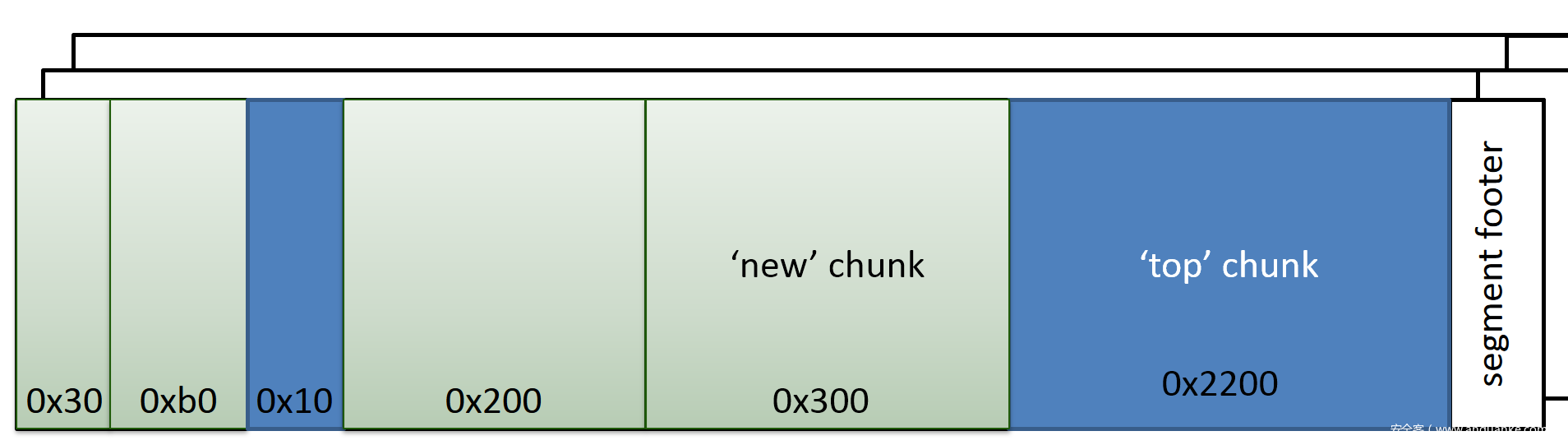
不同大小的chunk可以连续排布,chunk中要包含metadata用于说明该chunk以及上一个chunk的大小,还有这两个chunk是否被使用:

当被free的chunk临近有已经被free的chunk时,两个chunk会合并。除了这些基本的管理方式,dlmalloc还使用bin来管理内存。相同大小且被free的chunk会以双链表形式存放在bin当中。bin中的内存遵循FIFO原则,下一次malloc时会优先从bin中取内存,选择大小不小于申请内存的一块返回。一共有32个small bins和32个tree bins,tree bins用于管理大内存,采用bitwise digital tree结构存储。dlmalloc的小内存分配原则总结如下:
- 计算对象大小
- 从small bin中找大小和目标相同的chunk返回
- 最近一次被释放的内存块是否合适
- 从small bin中找不小于目标的chunk返回
- 从tree bin中找大小不小于目标的chunk返回
- 如果仍然没有才从top chunk中划分新内存,或者创建新的segment
dlmalloc分配大内存时和上述流程相似,但要简单一些,直接从tree bin开始往下执行。当请求分配的内存大于64k时,malloc会调用mmap分配内存。
为了适应多线程,dlmalloc只是简单地在malloc开始和结束的位置加了一个lock,对多线程的应用性能影响还是比较大的。
jemalloc
Android目前已经开始转为使用jemalloc管理内存,相比dlmalloc,它的设计更利于多线程的运行环境。jemalloc在2014年五月,也就是Android 5.0开始引入,随后被设置为默认的分配选项。不过时至今日,Android 5和6的设备中仍能同时看到dlmalloc和jemalloc两者并存。
jemalloc管理内存时要复杂一些,最大的管理单元是arena,一共有两个,分别带有一个lock。不同线程尝试分配内存时,会平均分配至两个arena,只有在相同的arena中分配内存时才需要获取lock。arena中实际管理内存的是chunk和region,Android 7之前chunk为256k,之后32位系统改为512k,64位系统改为2MB。
每个chunk中会包含若干个run,run里面的region大小完全相同,而run的metadata会存放在chunk的header当中,这样region里只存放数据本身,不再有内存属性说明,malloc实际返回的是region的地址:
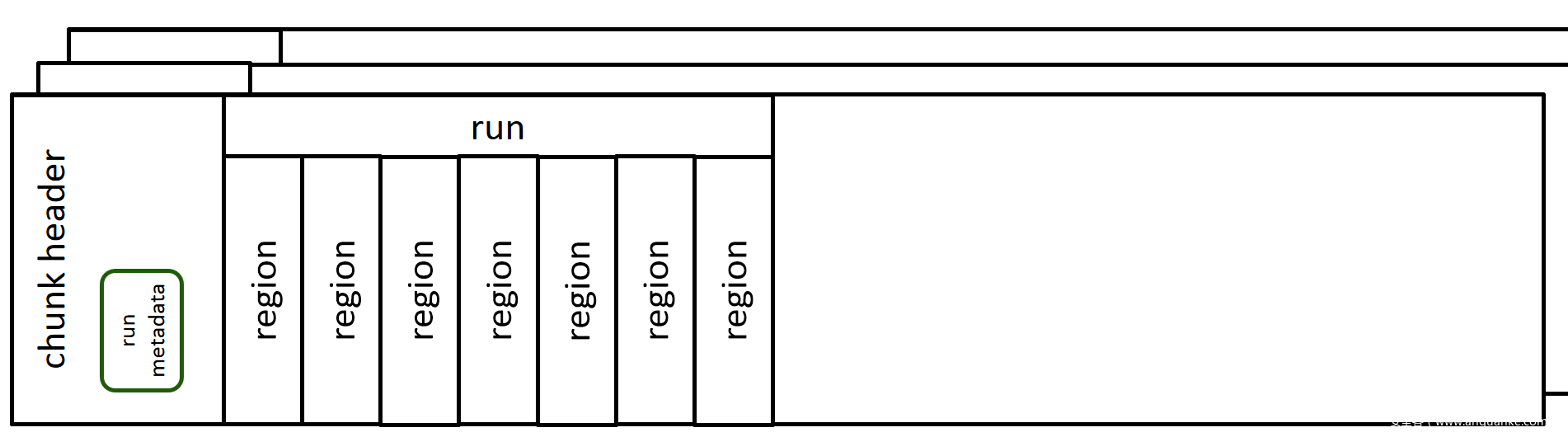
jemalloc也用bin来管理内存,共有39个bins。不同于dlmalloc的分配方法,jemalloc分配的内存完全来取自于bin。bin的metadata存放于arena的header中,39个bin还会存放当前正在使用的run。所有带有空闲region的run和闲置的chunk信息会被放置在红黑树结构当中,这样寻找空闲内存的复杂度可以控制在o(log(n)):
除此之外,为了优化多线程性能,jemalloc还采用了LIFO结构的tcache,存放近期被释放的region,每个线程的每个bin都对应一个tcache。存放在tcache中的内存并不会设置free标记位,并且由于tache附着于线程本身,使得大部分情况下从tcache分配内存时完全无需lock。
当tcache中存放的内存块用尽时会触发prefill,此时jemalloc会lock当前arena,并从当前run中取出一定数量的region存入tcache,使得它总有存量。
当tcache存满时(small bin是8,larger bin是20)会触发flush,tcache中存放的region才会被真正标记为释放。被释放的region才能被其他线程再次申请。
另外jemalloc本身也有GC,即有一个全局的计数器记录申请和释放,达到阈(读yu,四声)值时会触发一次特殊的释放,目标bin里tcaches中四分之三的region会被释放。下次GC时会轮到下一个bin。这是另一种真正释放region的方法。总结一下jemalloc的分配原则:
- 计算申请内存大小
- 从当前线程的tcache中找到合适的bin
- 如果tcache为空,就从当前的run中prefill一些region进来
- 如果当前run耗尽,就从低地址开始找到第一个非空run
- 如果现有run里没有足够的内存就分配一个新run
- 如果chunk里没有空间了就分配一个新chunk,同时分配新run并prefill一些region到tcache
对比两种内存管理方式如下: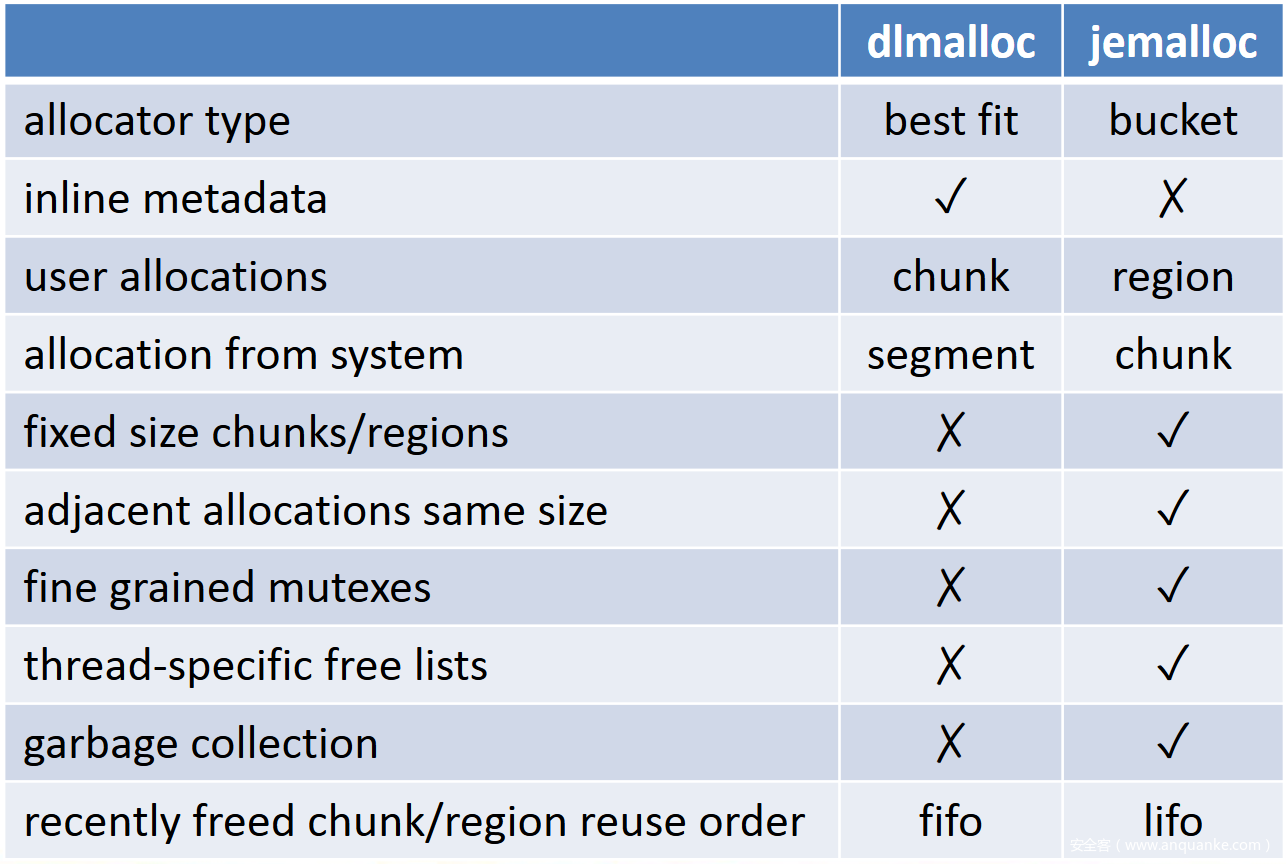 目前系统中大概30%使用dlmalloc,70%是jemalloc。
目前系统中大概30%使用dlmalloc,70%是jemalloc。
Exploitation
在一个漏洞利用的过程中,通常会基于这些前置的基础知识操纵堆内存。使得其按照我们预定的方式排布,如让特定的两个对象相邻,或者让一个对象重用另一个被释放的对象的内存,这些技巧统称为堆风水。
为了更好控制堆的状态,能够随时查看内存的分布情况是很有帮助的。下面三个工具非常好用,一个是去年INFILTRATE大会上Cencus的pyrsistence,另外一个是作者自己写的shade,最后就是NCC Group发布的libdlmalloc。以作者自己的工具为例,基于GDB的插件可以实时显示目标内存附近的区块状态。
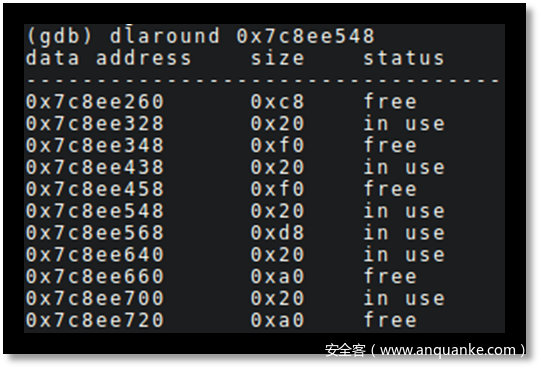
不知道是不是开源的情况下反而更没有人去研究原理和可视化工具,Windows上反而很多年前就已经有各种堆内存可视化脚本了,几乎是每个调试器的标配功能。
Android可以说是目前主流系统中附加各类缓解措施最多的系统了,地址随机化,SELinux,进程沙盒等都让漏洞利用过程无比痛苦。下面以溢出为例,看看上述关于堆分配的知识能推导出哪些实际使用技巧。
堆溢出
在一个漏洞利用过程中,一般先要获取一些gadget,然后利用这些gadget扩大战果。gadget包括相对地址读/写、任意地址读/写,任意执行等。比如一个常见构造gadget的方法,让越界写的对象和一个带有数据指针+长度的对象相邻:
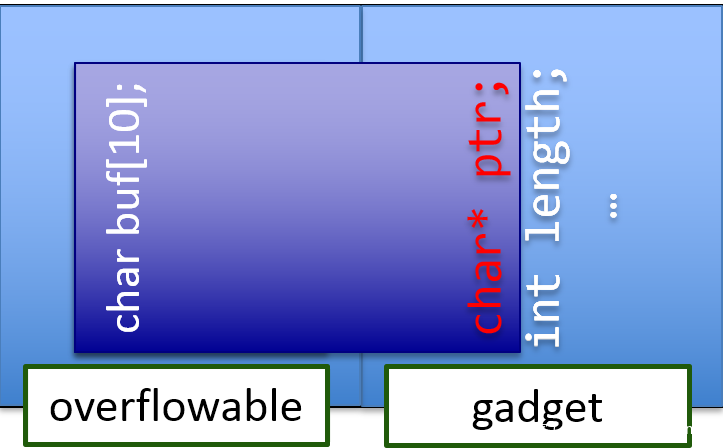
这样越界写后,临接对象就会成为一个读或写的gadget,这取决于临接对象能够提供哪些操作让我们使用。这一手应该早已经是脚本环境中漏洞利用的家常便饭了。实际在找这类gadget时可以直接在代码中找含有malloc,new,reallocs,std::vector,std::string的对象。如果能够访问到他们的方法,就可能是一个潜在的gadget。
jemalloc分配内存的情况下,临接对象的选择条件更为苛刻,必须和溢出的对象大小对齐后相同,这样才有可能位于同一个run当中。
另外一个技巧是placeholder,即提前分配大量和目标对象大小相同的占位对象,然后释放他们勇于填充漏洞对象和gadget,这样很大几率会出现临接的情况,确保溢出行为有效:
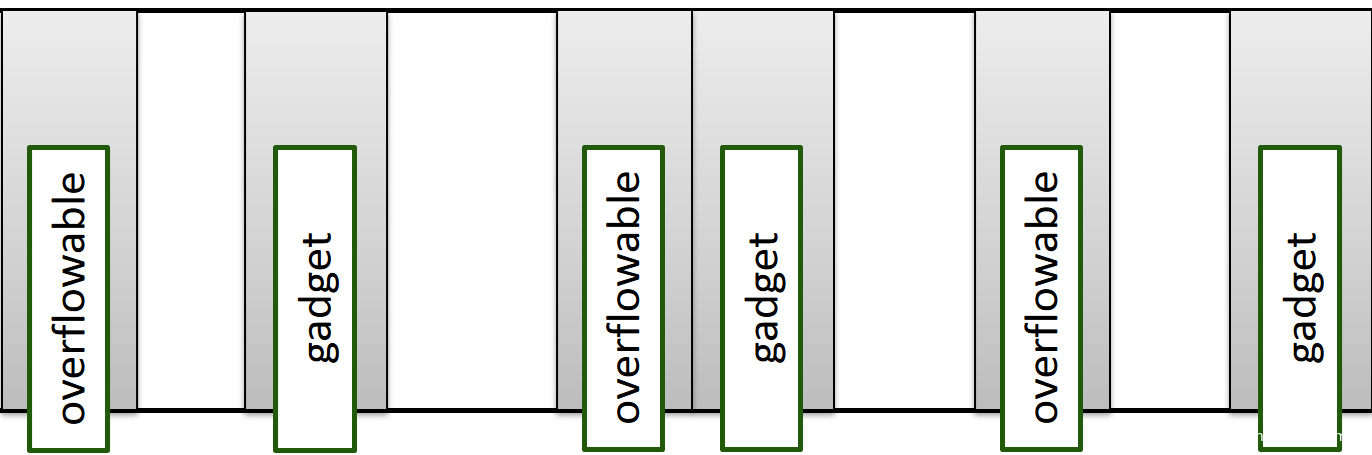
如果能提前分配足够多的对象将已有内存占满,后面placeholder将有更大几率分配在临接连续的内存当中。
在分配目标内存和gadget等过程中,很有可能引入噪音,即未预期的对象也因此分配并占了一精心排布的内存。对于这些噪音,一个很好的去除方法是预先分配足够的小内存块。每次引入噪音前先释放一些小内存块,确保噪音被这些内存块收纳。
由于dlmalloc内存chunk中有metadata,溢出时应该把这些字段的大小也纳入考虑范围,而jemalloc的metadata存放在region之外所以不用考虑。
另外,有可能本来用于临接的对象和溢出对象由不同的thread创建,对于dlmalloc来说这没有什么影响,但jemalloc就比较棘手,不同的tcache很难保证二者临接。遇到这种情况最好的办法是触发flush或者GC,让目标区块转移到同一个线程当中。
还有一个问题是padding,jemalloc分配的对象由于region大小固定,region很可能比对象实际要大,这样溢出时就要考虑把中间没有用到的内存也覆盖掉。
最后的一个可能导致问题的是两个对象所属arena不同,不过这个问题很好解决,可以先创建比如30个线程,相邻的线程应该位于刚好不同的arena当中。然后每隔一个线程释放掉自身。由于平衡的诉求,接下来创建的15个线程都会位于相同的arena当中。
总结
在漏洞利用的学习过程中,可能一个漏洞案例只能学到一手技巧,即便看了很多例子,方法却大同小异。Shmarya Rubenstein把这些技巧集中展现,虽然有些抽象,但抽出来的才最像。Android堆分配原理弄清楚了,无论以后遇到什么利用场景都能自行找到解决方法,而不是广撒网似的找其他利用案例去揣度。
这些内存分配方面的技巧相当可贵,近来越来越多人分享时只提及讲案例本身,而且专挑奇案特例,且关键步骤一笔带过,留给听众的最多只是特例的解决方法,回过神发现自己遇到的问题与此稍有不同就无从下手。与之相比,Shmarya Rubenstein的分享应该回让想要深耕漏洞利用的研究人员大呼过瘾。
温馨提示:安全客近期会陆续发布更多MOSEC干货议题解读,敬请关注~







发表评论
您还未登录,请先登录。
登录