
作者:@v1ll4n(安全研发工程师,现就职于长亭科技,喜欢喵喵 )
在上一篇文章中,我们在 checkWaf() 中戛然而止于 page ratio 这一个概念;但是在本文,笔者会详细介绍 page ratio 对于 sqlmap 整个系统的重要意义和用法,除此之外还会指出一些 sqlmap 的核心逻辑和一些拓展性的功能。包含:
identityWaf
nullConnection (checkNullConnection)
0x00 PageRatio 是什么?
要说 PageRatio 是什么,我们可能需要先介绍另一个模块 difflib。这个模块是在 sqlmap 中用来计算页面的相似度的基础模块,实际处理的时候,sqlmap 并不仅仅是直接计算页面的相似度,而是通过首先对页面进行一些预处理,预处理之后,根据预设的阈值来计算请求页面和模版页面的相似度。
对于 difflib 模块其实本身并没有什么非常特殊的,详细参见官方手册,实际在使用的过程中,sqlmap 主要使用其 SequenceMatcher 这个类。以下是关于这个类的简单介绍:
This is a flexible class for comparing pairs of sequences of any type, so long as the sequence elements are hashable. The basic algorithm predates, and is a little fancier than, an algorithm published in the late 1980’s by Ratcliff and Obershelp under the hyperbolic name “gestalt pattern matching.” The idea is to find the longest contiguous matching subsequence that contains no “junk” elements (the Ratcliff and Obershelp algorithm doesn’t address junk). The same idea is then applied recursively to the pieces of the sequences to the left and to the right of the matching subsequence. This does not yield minimal edit sequences, but does tend to yield matches that “look right” to people.
简单来说这个类使用了 Ratcliff 和 Obershelp 提供的算法,匹配最长相同的字符串,设定无关字符(junk)。在实际使用中,他们应用最多的方法应该就是 ratio()。

根据文档中的描述,这个方法返回两段文本的相似度,相似度的算法如下:我们假设两段文本分别为 text1 与 text2,他们相同的部分长度总共为 M,这两段文本长度之和为 T,那么这两段文本的相似度定义为 2.0 * M / T,这个相似度的值在 0 到 1.0 之间。
PageRatio 的小例子
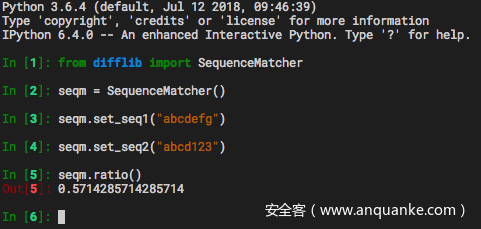
我们通过上面的介绍,知道了对于 abcdefg 和 abce123 我们计算的结果应该是 2.0 * 4 / 14所以计算结果应该是:

到现在我们理解了 PageRatio 是什么样的一种算法,我们就可以开始观察 sqlmap 是如何使用这一个值的了~
0x01 RATIO in checkWaf
在上节的内容中,我们对于 sqlmap 的源码了解到 checkWaf 的部分,结合刚才讲的 PageRatio 的例子,我们直接可以看懂这部分代码:

现在设定 IDS_WAF_CHECK_RATIO = 0.5 表明,只要打了检测 IDS/WAF 的 Payload 的页面结果与模版页面结果文本页面经过一定处理,最后比较出相似度相差 0.5 就可以认为触发了 IDS/WAF。
与 checkWaf 相关的其实还有 identityWaf, 但是这个方法太简单了我们并不想仔细分析,有兴趣的读者可以自行了解一下,本文选择直接跳过这一个步骤。
0x02 checkStability
这个函数其实是在检查原始页面是存在动态内容,并做一些处理。何为动态内容?在 sqlmap 中表示以同样的方式访问量次同一个页面,访问前后页面内容并不是完全相同,他们相差的内容属于动态内容。当然,sqlmap 的处理方式也并不是随意的比较两个页面就没有然后了,在比较完之后,如果存在动态页面,还会做一部分的处理,或者提出扩展设置(--string/--regex),以方便后续使用。
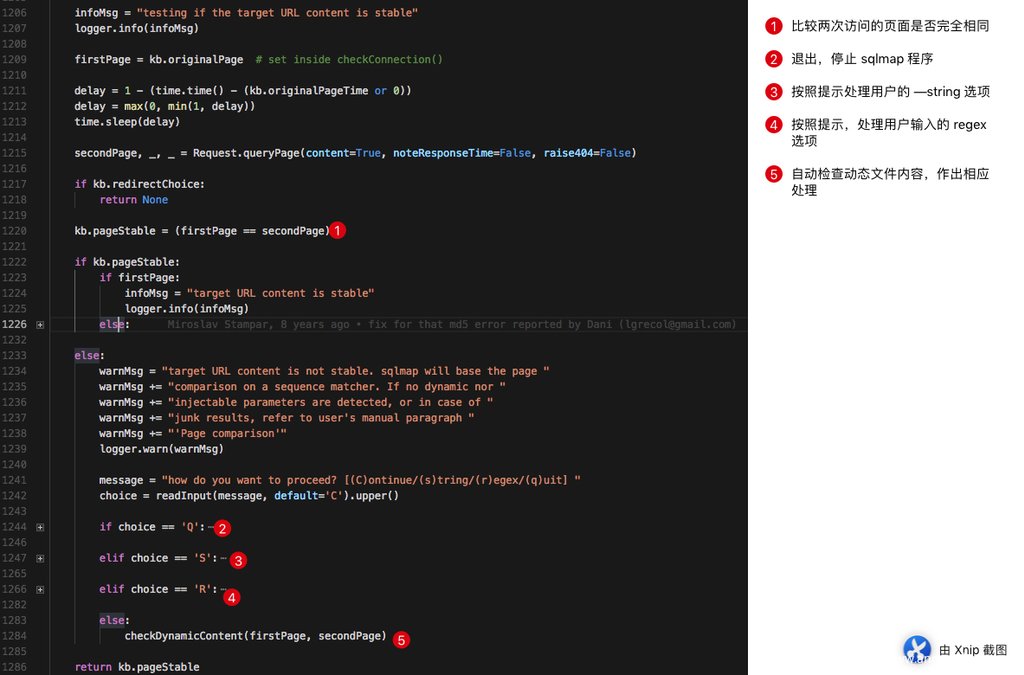
我们发现,实际的 sqlmap 源码确实是按照我们介绍的内容处理的,如果页面内容是动态的话,则会提示用户处理字符串或者增加正则表达式来验证页面。
默认情况下sqlmap通过判断返回页面的不同来判断真假,但有时候这会产生误差,因为有的页面在每次刷新的时候都会返回不同的代码,比如页面当中包含一个动态的广告或者其他内容,这会导致sqlmap的误判。此时用户可以提供一个字符串或者一段正则匹配,在原始页面与真条件下的页面都存在的字符串,而错误页面中不存在(使用–string参数添加字符串,–regexp添加正则),同时用户可以提供一段字符串在原始页面与真条件下的页面都不存在的字符串,而错误页面中存在的字符串(–not-string添加)。用户也可以提供真与假条件返回的HTTP状态码不一样来注入,例如,响应200的时候为真,响应401的时候为假,可以添加参数–code=200。
checkDynamicContent(firstPage, secondPage)
我们发现,如果说我们并没指定 string / regex 那么很多情况,我们仍然也可以正确得出结果;根据 sqlmap 源码,它实际上背后还是有一些处理方法的,而这些方法就在 checkDynamicContent(firstPage, secondPage) 中:

我们在这个函数中发现如果 firstPage 和 secondPage 的相似度小于 0.98 (这个相似度的概念就是前一节介绍的 PageRatio 的概念),则会重试,并且尝试 findDynamicContent(firstPage, secondPage) 然后细化页面究竟是 too dynamic 还是 heavily dynamic。
如果页面是 too dynamic 则提示启用 --text-only 选项:
有些时候用户知道真条件下的返回页面与假条件下返回页面是不同位置在哪里可以使用–text-only(HTTP响应体中不同)–titles(HTML的title标签中不同)。
如果页面仅仅是显示 heavy dynamic 的话,sqlmap 会不断重试直到区分出到底是 too dynamic还是普通的可以接受的动态页面(相似度大于 0.98)。
对于 too dynamic 与可以接受的动态页面(相似度高于 0.98),其实最根本的区别就是在于 PageRatio, 如果多次尝试(超过 conf.retries) 设置的尝试次数,仍然出现了相似度低于 0.98 则会认为这个页面 too dynamic。
findDynamicContent(firstPage, secondPage)
这个函数位于 common.py 中,这个函数作为通用函数,我们并不需要非常严格的去审他的源码,为了节省大家的时候,笔者在这里可以描述这个函数做了一件什么样的事情,并举例说明。
这个函数按函数名来解释其实是,寻找动态的页面内容。
实际在工作中,如果寻找到动态内容,则会将动态内容的前后内容(前:prefix,后:suffix,长度均在 DYNAMICITY_BOUNDARY_LENGTH 中设定,默认为 20)作为一个 tuple,存入 kb.dynamicMarkings,在每一次页面比较之前,会默认移除这些动态内容。
kb.dynamicMarkings.append((prefix if prefix else None, suffix if suffix else None))
例如,在实际使用中,我们按照官方给定的一个例子:
"""
This function checks if the provided pages have dynamic content. If they
are dynamic, proper markings will be made
>>> findDynamicContent("Lorem ipsum dolor sit amet, congue tation referrentur ei sed. Ne nec legimus habemus recusabo, natum reque et per. Facer tritani reprehendunt eos id, modus constituam est te. Usu sumo indoctum ad, pri paulo molestiae complectitur no.",
"Lorem ipsum dolor sit amet, congue tation referrentur ei sed. Ne nec legimus habemus recusabo, natum reque et per. <script src='ads.js'></script>Facer tritani reprehendunt eos id, modus constituam est te. Usu sumo indoctum ad, pri paulo molestiae complectitur no.")
>>> kb.dynamicMarkings
[('natum reque et per. ', 'Facer tritani repreh')]
"""
根据观察,两段文本差别在 script 标签,标记的动态内容应该是 script 标签,所以动态内容的前 20 字节的文本座位 prefix 后 20 字节的文本作为 suffix,分别为:
- prefix:
'natum reque et per. ' - suffix:
'Facer tritani repreh'
0x03 中场休息与阶段性总结
我们虽然之分析了两个大函数,但是整个判断页面相应内容的核心原理应该是已经非常清晰了;可能有些读者反馈我们的进度略慢,但是其实这好比一个打基础的过程,我们基础越扎实对 sqlmap 越熟悉,分析后面的部分就越快。
为了更好的继续,我们需要回顾一下之前的流程图
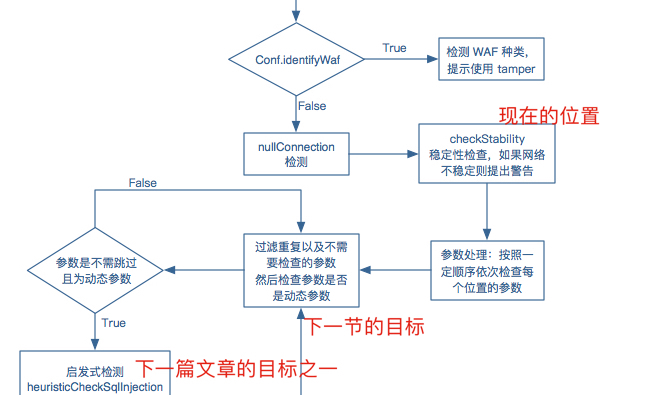
好的,接下来我们的目标就是图中描述的部分“过滤重复以及不需要检查的参数,然后检查参数是为动态参数”,在下一篇文章中,我们将会详细介绍 sqlmap 其他的核心函数,诸如启发式检测,和 sql 注入检测核心函数。
0x04 参数预处理以及动态参数检查
参数预处理
参数预处理包含如下步骤:
参数排序
# Order of testing list (first to last)
orderList = (PLACE.CUSTOM_POST, PLACE.CUSTOM_HEADER, PLACE.URI, PLACE.POST, PLACE.GET)
for place in orderList[::-1]:
if place in parameters:
parameters.remove(place)
parameters.insert(0, place)
参数分级检查for place in parameters:
# Test User-Agent and Referer headers only if
# --level >= 3
skip = (place == PLACE.USER_AGENT and conf.level < 3)
skip |= (place == PLACE.REFERER and conf.level < 3)
# Test Host header only if
# --level >= 5
skip |= (place == PLACE.HOST and conf.level < 5)
# Test Cookie header only if --level >= 2
skip |= (place == PLACE.COOKIE and conf.level < 2)
skip |= (place == PLACE.USER_AGENT and intersect(USER_AGENT_ALIASES, conf.skip, True) not in ([], None))
skip |= (place == PLACE.REFERER and intersect(REFERER_ALIASES, conf.skip, True) not in ([], None))
skip |= (place == PLACE.COOKIE and intersect(PLACE.COOKIE, conf.skip, True) not in ([], None))
skip |= (place == PLACE.HOST and intersect(PLACE.HOST, conf.skip, True) not in ([], None))
skip &= not (place == PLACE.USER_AGENT and intersect(USER_AGENT_ALIASES, conf.testParameter, True))
skip &= not (place == PLACE.REFERER and intersect(REFERER_ALIASES, conf.testParameter, True))
skip &= not (place == PLACE.HOST and intersect(HOST_ALIASES, conf.testParameter, True))
skip &= not (place == PLACE.COOKIE and intersect((PLACE.COOKIE,), conf.testParameter, True))
if skip:
continue
if kb.testOnlyCustom and place not in (PLACE.URI, PLACE.CUSTOM_POST, PLACE.CUSTOM_HEADER):
continue
if place not in conf.paramDict:
continue
paramDict = conf.paramDict[place]
paramType = conf.method if conf.method not in (None, HTTPMETHOD.GET, HTTPMETHOD.POST) else place
参数过滤
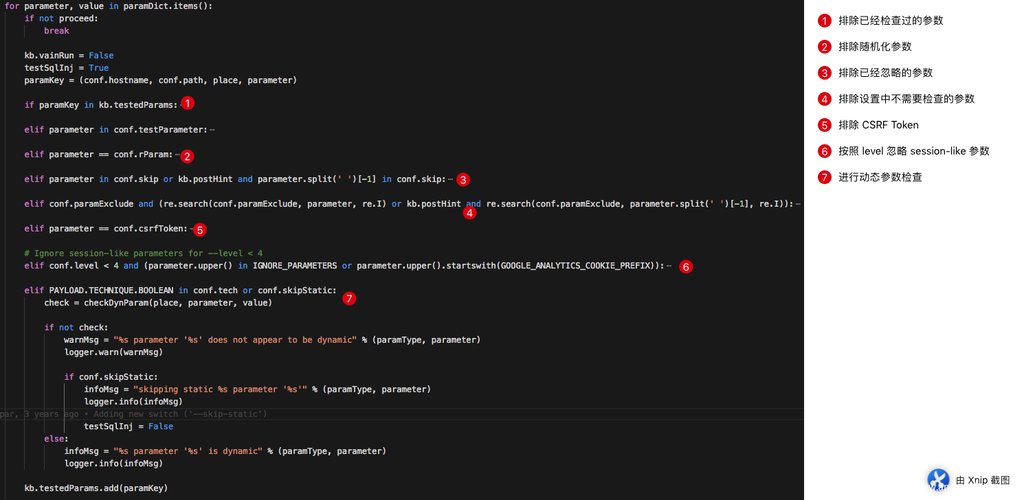
checkDynParam(place, parameter, value)
我们进入 checkDynParam 函数发现,整个函数其实看起来非常简单,但是实际上我们发现 agent.queryPage 这个函数现在又返回了一个好像是 Bool 值的返回值作为 dynResult 这令我们非常困惑,我们上一次见这个函数返回的是 (page, headers, code) 。
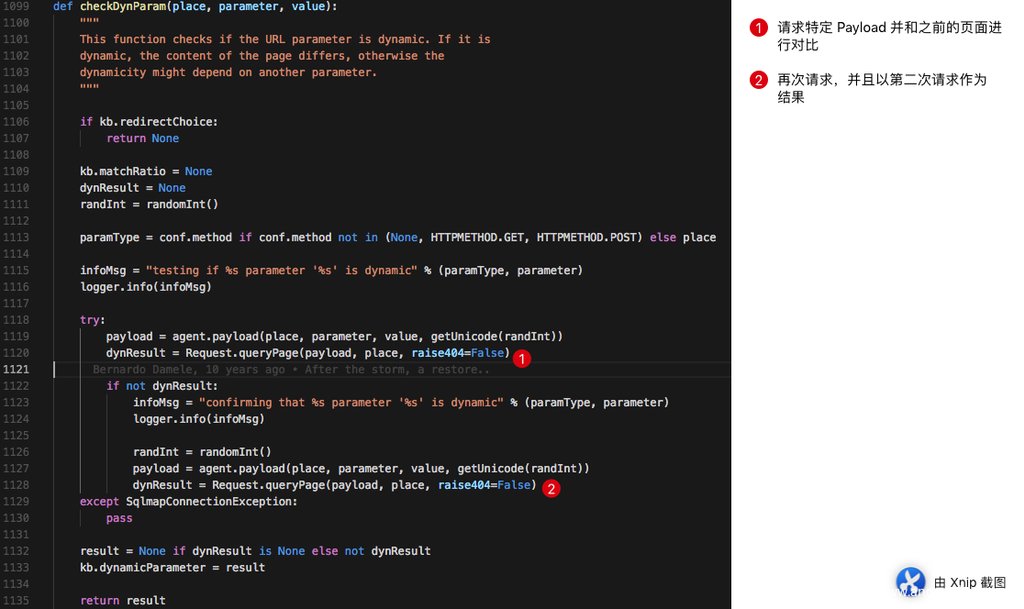
我们发现实际上的页面比较逻辑也并不是在 checkDynParam ,所以表面上,我们这一节的内容是在 checkDynParam 这个函数,但是实际上我们仍然需要跟进到 agent.queryPage。
那么,等什么呢?继续吧!
agent.queryPage 与 comparison
跟进 agent.queryPage 我相信一定是痛苦的,这其实算是 sqlmap 的核心基础函数之一,里面包含了接近三四百行的请求前预处理,包含 tamper 的处理逻辑以及随机化参数和 CSRF 参数的处理检测逻辑。同时如果涉及到了 timeBasedCompare 还包含着时间盲注的处理逻辑;除此之外,一般情况下 agent.queryPage 中还存在着针对页面比较的核心调用,页面对比对应函数为 comparison。为了简化大家的负担,笔者只截取最后返回值的部分 agent.queryPage 。
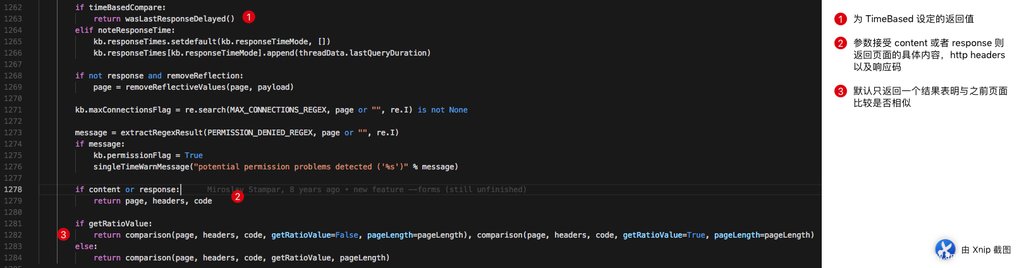
在标注中,我们发现了我们之前的疑问,为什么 agent.queryPage 时而返回页面内容,时而返回页面与模版页面的比较结果。其实在于如果 content/response 被设置为 True 的时候,则会返回页面具体内容,headers,以及响应码;如果 timeBasedCompare 被设定的时候,返回是否发生了延迟;默认情况返回与模版页面的比较结果。
我们发现这一个 comparison 函数很奇怪,他没有输入两个页面的内容,而是仅仅输入当前页面的相关信息,但是为什么笔者要明确说是与“模版页面”的比较结果呢?我们马上就跟入 comparison 一探究竟。
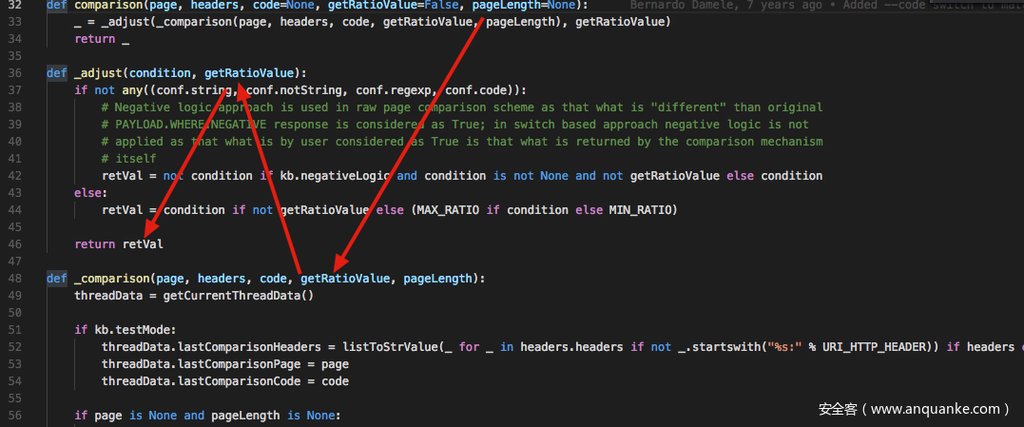
进去之后根据图中的调用关系,我们主要需要观察一下 _comparison 这个函数的行为。当打开这个函数的时候,我们发现也是一段接近一百行的函数,仍然是一个需要硬着头皮看下去的一段代码。
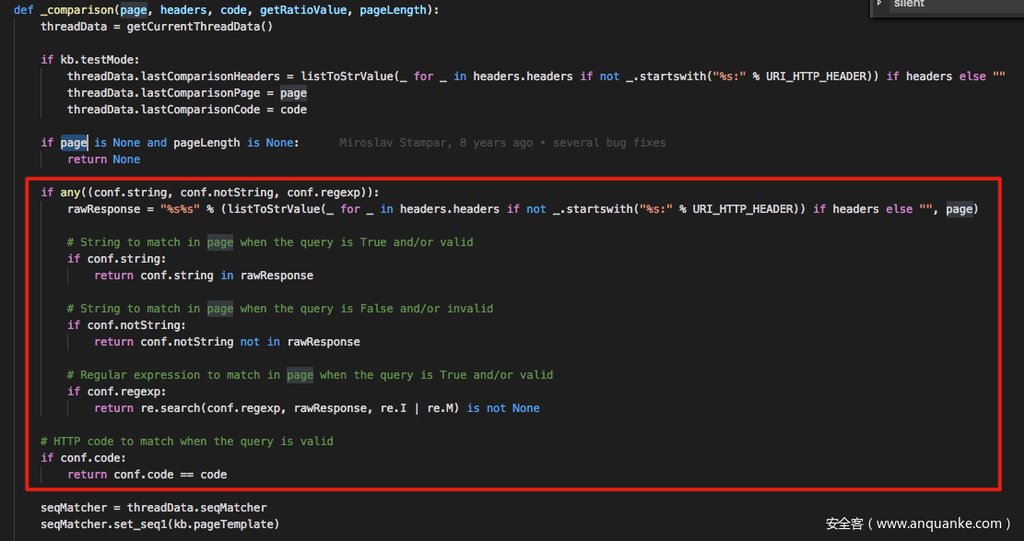
根据图中的使用红色方框框住的代码,我们很容易就能发现,这其实是在禁用 PageRatio 的页面相似度算法,而是因为用户设定了 --string/--not-string/--regex/--code 从而可以明确从其他方面区分出页面为什么不同。当然,我们的重点并不是他,而是计算 ratio 并且使用 ratio得出页面相似的具体逻辑。
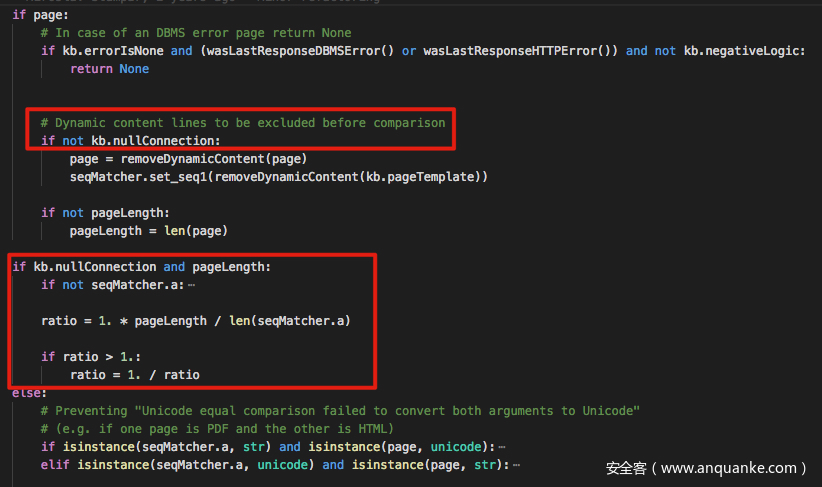
我相信令大家困惑的可能是这两段关于 nullConnection 的代码,在前面的部分中,我们没有详细说明 nullConnection 究竟意味着什么:
Optimization:
These options can be used to optimize the performance of sqlmap
-o Turn on all optimization switches
--predict-output Predict common queries output
--keep-alive Use persistent HTTP(s) connections
--null-connection Retrieve page length without actual HTTP response body
--threads=THREADS Max number of concurrent HTTP(s) requests (default 1)
根据官方手册的描述,nullConnection 是一种不用获取页面内容就可以知道页面大小的方法,这种方法在布尔盲注中有非常好的效果,可以很好的节省带宽。具体的原理详见这一片古老的文章。
明白这一点,上面的代码就变得异常好懂了,如果没有启用 --null-connection 优化,两次比较的页面分别为 page 与 kb.pageTemplate。其实 kb.pageTemplate 也并不陌生,其实就是第一次正式访问页面的时候,存下的那个页面的内容。
conf.originalPage = kb.pageTemplate = page
如果启用 --null-connection,计算 ratio 就只是很简单的通过页面的长度来计算,计算公式为
ratio = 1. * pageLength / len(kv.pageTemplate)
if ratio > 1.:
ratio = 1. / ratio
接下来我们再顺着他的逻辑往下走:
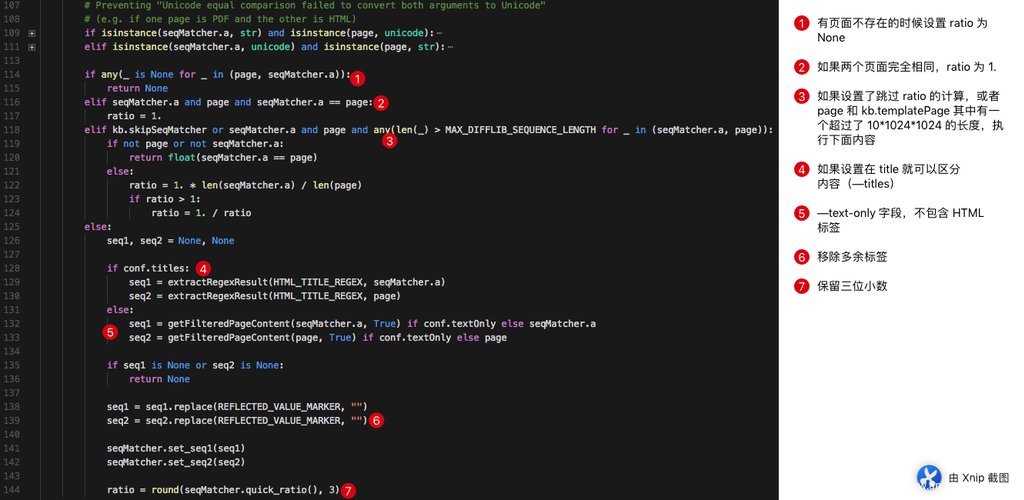
根据上面对源码的标注,我们很容易理解这个 ratio 是怎么算出来的,同样我们也很清楚,其实并不只是简单无脑的使用 ratio 就可以起到很好的效果,配合各种各样的选项或者预处理:比如移除页面的动态内容,只比较 title,只比较文本,不比较 html 标签。
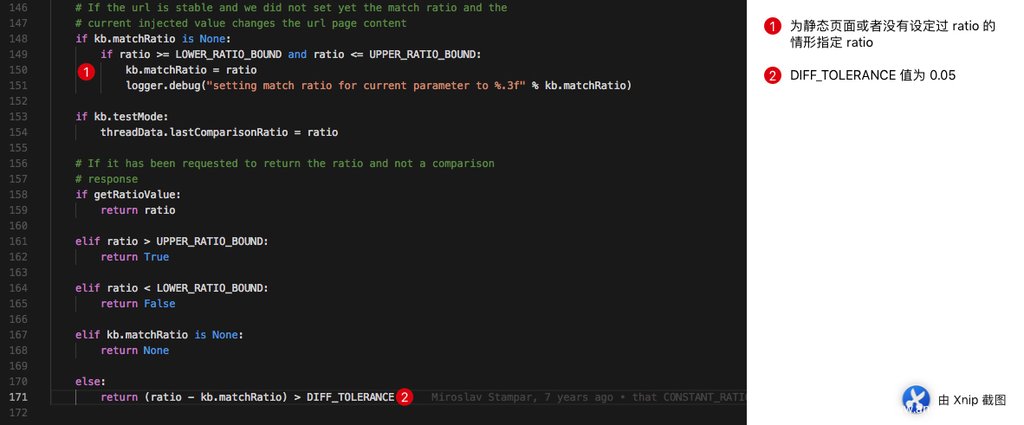
上面源码为最终使用 ratio 对页面的相似度作出判断的逻辑,其中
UPPER_RATIO_BOUND = 0.98
LOWER_RATIO_BOUND = 0.02
DIFF_TOLERANCE = 0.05
0x05 结束语
阅读完本文,我相信读者对 sqlmap 中处理各种问题的细节都会有自己的理解,当然这是最好的。
在下一篇文章,笔者将会带大家进入更深层的 sqlmap 的逻辑,敬请期待。







发表评论
您还未登录,请先登录。
登录