
去年,写过一篇《漏洞运营规范化》,当时有些朋友问,无论是使用cvss,dread,owasp,或者是现有国内各大src的评级标准,能不能有一套可以减少争议,能够自动化实现的方法呢?
在这一年中,和团队成员不断的探索中,进行了关于漏洞评级的模型选型,标准化,自动化计算,以及根据实际情况的小范围内测和公测,探索了一套基于DREAD模型的漏洞计算模式。
这套模式仍在不断摸索中,欢迎感兴趣的朋友,一起进一步沟通和探讨。
一、选型

如前文所述,已知的漏洞计算模型包括cvss,dread,owasp,还有各大src现在应用的方式,真正准备进行标准化前针对各个模型进行了初步的调研。
调研前首先明确,这套模型需要明确几个概念:
- 目标对象是用在SRC收集漏洞上,而不是单纯的内部扫描器稳定产出的结果,这就意味着收到的漏洞可能场景更复杂,更难以按照类型单一标准化。
- 目标人群外界的白帽子是第一优先用户,内部安全工程师是第二用户,内部的各个业务方包括开发运维测试是第三用户。也就是说,这里面大部分的用户都是非企业安全建设的用户。
- 漏洞等级的定义依据是——“可能带来的影响”。可能带来的影响,既不是指某类漏洞的危害(这里指漏洞的等级不止需要考虑该漏洞本身,同时要考虑这个类型的漏洞实际影响的业务等多个维度),也不是已经带来的影响(已经带来影响的,可能已经是安全事件了)。
- 漏洞类型的范围除了传统的Web安全漏洞,系统网络安全漏洞和移动客户端的安全漏洞,可能还需要包括业务安全、业务逻辑,第三方平台信息泄露等,因为随着安全的发展,出现的各种新型安全问题越来越多,也超出了原本技术漏洞的范畴,是更广义上的漏洞。
几个定义明确了之后,那哪个更适合应用在SRC呢?
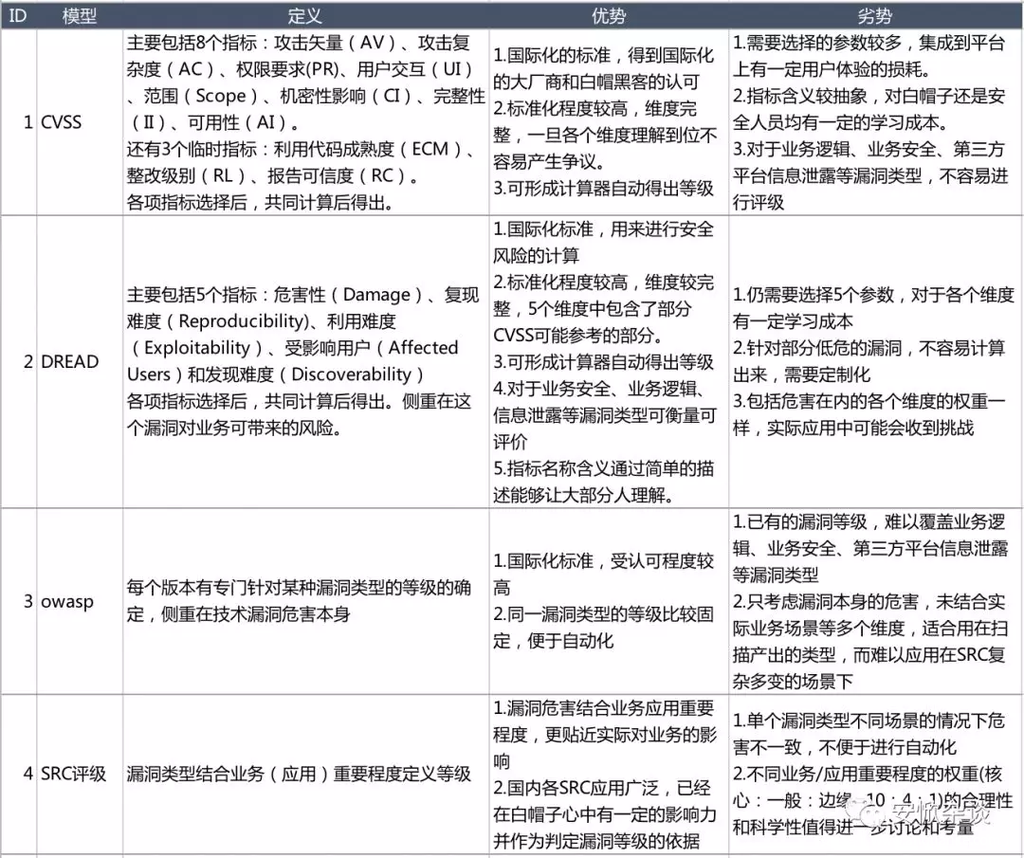
结合以上应用场景,以及各个评分标准下,如果想在SRC进一步进行标准化,那么DREAD成为了优选的对象。
二、等级计算

由于历史原因,SRC的漏洞危害,包括忽略的情况下,一共分为5个大类,11个小类,分别是
| 等级大类 | 等级小类 |
| 严重 | 10 |
| 严重 | 9 |
| 高危 | 8 |
| 高危 | 7 |
| 高危 | 6 |
| 中危 | 5 |
| 中危 | 4 |
| 中危 | 3 |
| 低危 | 2 |
| 低危 | 1 |
| 忽略 | 0 |
由于后续的积分体系,奖励体系都是依照这个等级规则来的,在等级不变的情况下,想与DREAD模型进行匹配,就需要进行一定的适配。
DREAD模型的计算方式:等级=危害性+复现难度+利用难度+受影响用户+发现难度
已有的等级计分分数标准,结合DREAD的等级计算方式,最终适配出来的分数是:
等级[忽略(0),严重(10)]=(危害性[0,4]+复现难度[0,4]+利用难度[0,4]+受影响用户[0,4]+发现难度[0,4])/2
其中,
- 危害性、复现难度、利用难度任意一个值为0,总分即为0;
- 等级为0总分除以2后取整。
三、等级定义
1. 危害性(Damage)
危害性Damage,即how bad would an attackbe?(来源于维基百科,下同)意指:如果被攻击了,会造成怎样的危害?这里根据系统受危害程度,泄露信息的数据敏感性,资损,系统受危害程度等方面来衡量危害。
首先是数据敏感性。各公司一般会数据根据敏感程度分等级,可以是对外公开,内部公开,秘密数据,机密数据等
其次,对于资金的损失,可以按照实际的金额的某些区域进行划分,也可以按照某个比例计算
再次,对于系统的破坏包括但不限于,上面说的数据泄露、资金损失外,能够完全获得权限、执行管理员操作、非法上传更为严重。
由此可参考以下等级划分:
0分:未泄露敏感信息,不涉及资金损失
1分:泄露内部公开的数据,或存在较少资金损失
2分:泄露秘密数据,或存在一定资金损失
3分:泄露机密数据,或资金损失较大
4分:获取完全验证权限,或执行管理员操作,或非法上传文件,或资金存世巨大
2. 复现难度(Reproducibility)
复现难度Reproducibility,即how easy is it to reproduce theattack?意指,复现这个攻击的难易程度是怎样的?重点在于这个漏洞是不是容易复现成功,有难度和概率问题。
(注意,有的地方的翻译是,攻击后恢复运营的简易度,经过几番考察,这里不是恢复运营的简易度,reproduce指的是复现,即把这个漏洞重复演示,而不是恢复运营,国内有的地方按照恢复运营翻译是有问题的)。
0分:非常困难或者不可能复现,即时对于应用管理员
1分:很难复现,复现成功率较低,需要多种因素限制并对技术有较高要求
2分:可以复现,但有时间或其他因素限制
3分:容易复现,需要一步或两步,可能需要变成授权用户
4分:非常容易复现,仅仅一个浏览器和地址栏就ok,不需要身份认证
3. 利用难度(Exploitability)
利用难度Exploitability,即how much work is it to launch theattack?意指,需要什么才能利用这个漏洞?这里特指的是,使用什么才能实现这个攻击,这里关注的重点是具体使用的工具。
0分:漏洞无法利用
1分:利用条件非常苛刻,如未披露的0day
2分:熟练攻击者可攻击,需自定制脚本或高级攻击工具
3分:中级攻击者能攻击,已存在可用工具或可被轻易利用
4分:初学者短期能掌握,仅需Web浏览器即可
4. 受影响用户(Affected Users)
受影响用户Affected Users,即how many people will beimpacted?意指,多少用户会被影响到?实际应用的模型里,添加了业务的重要程度,以及多少算“多”的概念。
业务的等级,同现在大多数公司对于业务的概念,氛围核心、一般和边缘,这个由公司各业务主导业务定级,安全团队进行参考和微调
数量的概念,参考新颁布的网络安全法,如果是敏感数据超过50条即可判刑来看,只要敏感数据超过50条即可认为是大量。
0分:对用户无影响
1分:一般边缘业务的少量用户
2分:一般边缘业务的大量用户或核心业务的少量用户
3分:核心业务的大量用户
4分:所有用户或涉及多个核心业务的大量用户
5. 发现难度(Discoverability)
发现难度Discoverability,即how easy is it to discover thethreat?意指,发现这个威胁的难以程度?实际应用做了一些具体场景化的举例。
当对已有应用进行安全审计时,“可发现性”将依照惯例被设置为4分,也就是默认此风险会被发现。
0分:非常困难,甚至不可能发现;需要源码或者管理员权限
1分:发现漏洞很困难,可以通过猜测或者监测网络活动来发现
2分:在私有区域(如内网),部分非可见(如有权限限制),有时间或其他因素限制,需要深入挖掘的漏洞
3分:容易发现,错误的细节已经在外部公共平台上披露,而且可以用搜索引擎轻易发现,攻击条件较易获得
4分:非常容易发现,信息在web浏览器的地址栏或者表单里可见(通常是外网)
四、问题和校正

在以上等级定义和计算下,经过一段时间的内测和小范围公测,也发现了一些问题。
- 问题:根据DREAD模型计算的5个维度的权重都是1,而通常情况下更多人更看重漏洞危害对等级的影响,或者有的只看重危害和利用难度,或者有的只看重危害+利用难度+影响用户,那么权重是不是需要调整呢,或者删掉一些维度呢?反馈:这个可能需要大量的数据和实践来支撑,目前DREAD模型的标准权重是1,这个是模型的理论基础,后续结合实际情况再看是否和如何调整。
- 问题:大部分时间计算下来的漏洞都是中危以上,基本上很难计算出来低危的漏洞,而实际上确实有低危的情况。
反馈:1)方法一:这就要引入部分漏洞类型,当选择这些类型的时候,会默认给出一些参考值。
2)方法二:调整漏洞等级的大分和小分的值,例如现有低危计算是1~2,可以调整为0.5~3.5都是低危。 - 问题:除了常见的5个维度,有些情况下,如果通盘考虑,除了传统意义上的安全风险,可能还有覆盖不全的?
反馈:1)安全维度本身,有时候需要考虑触发条件等因素,可以酌情进行调整。
2)公关风险和法律风险,可以作为加分项。
参考
- DREAD (risk assessment model)维基百科:https://en.wikipedia.org/wiki/DREAD_(risk_assessment_model)
- Threat Risk Modeling(OWASP翻译4)简书(侵删):https://www.jianshu.com/p/3534c30c0a83
- 6步教你搞定网络威胁建模(侵删)http://www.sohu.com/a/123809332_505884
- DREAD: 安全风险评估模型(侵删):http://www.aiuxian.com/article/p-1962153.html







发表评论
您还未登录,请先登录。
登录