
该课题由独角兽安全夏令营第二届学员黄瑞同学完成
独角兽暑期训练营
360无线电安全研究院每年暑假都会面向在校学生举办一次暑期训练营,申请者投递简历并提交自己想做的课题介绍后,若入选,会在360技术专家的指导下完成课题。
本系列文章会发布今年5位学员在训练营中的成果。文章相关代码后续会在训练营github代码仓库发布 。
引言
从骨干路由器、交通信号灯到家用调制解调器和智能冰箱,嵌入式设备在现代生活中的应用越来越多。嵌入式设备固件的数量也增长到难以计量。安全人员曾经在这类设备上发现很多高危安全漏洞。相比挖掘新漏洞,在这些固件中扫描出已经在其他设备上发现或者是开源代码中发现过的漏洞,也非常重要。
因此,我们需要一种有效的解决方案来搜索固件中的漏洞。 由于各种设备供应商使用了各种不同的处理器架构和独特的工具链,以及固件的高度定制特性,在固件搜索漏洞代码片段极具挑战性。
我们尝试解决的问题是:检测采用不同指令集的二进制固件中,是否使用过包含有特定漏洞的代码片段。我们阅读了一些二进制搜索的学术论文,并实现了验证平台,针对这个目标做了一些改进,识别准确性取得了提高。
主要工作
本文总结了在阅读分析两篇静态二进制代码搜索的文章后,对文章中的思路和算法进行复现并评估效果,在效果并不理想的情况下进行了一点改进并再次评估的过程。
文章分别是:
- Yaniv David, Nimrod Partush, and Eran Yahav. 2018. FirmUp: Precise Static Detection of Common Vulnerabilities in Firmware. (ASPLOS ’18). ACM, New York, NY, USA, 392-404.
- Yaniv David, Nimrod Partush, and Eran Yahav. 2017. Similarity of binaries through re-optimization. SIGPLAN Not. 52, 6 (June 2017), 79-94.
问题定义
给定程序集F={T1, T2, …, Tn} 和一个查询程序Q, Q中包含一个(有漏洞的)函数q,我们的目标是判断 Ti (∈ F) 是否包含一个与q相似的函数。
首先是我们想要解决的问题,比较严谨的问题定义如上,给定T1,T2,T3还有查询程序Q,这些都是二进制程序,其中Q中包含了一个函数q,我们的目标就是搜索这些T中是否有函数与q是相似或者相同的。直观来讲就是在F里面搜索q这个函数。
应用场景
下面来是解决如上所述问题的意义、解决后可以应用在哪些场景:
跨平台、跨工具链、跨优化等级程序中的代码搜索:最广泛的应用场景是目前IOT的设备越来越多,但是设备的固件都是经过编译、去掉符号表、打包好的,相同功能设备上面的程序可能是跨平台、跨工具链、跨优化等级的,这个时候我们只能从二进制层面去尝试大规模的自动化分析。
闭源软件分析:因为windows上的大多数软件都是闭源的,也只能从二进制层面进行分析搜索。
两种解决思路
在阅读了一些文章后总结解决上述问题大致有两种思路:
利用图论:

CFG(control-flow-graph)本质是图,节点是代码片段,边是跳转关系。利用图算法,通过寻找两个CFG间的同构或子图同构来进行相似度匹配
生成特征:

利用一个函数的某些或所有的basic-block的内容以及CFG的结构,执行相应的算法生成属于这个函数的特征,随后通过比较两个代码片段的特征来判断二者的相似度。
Firmup
Firmup是作者这一系列论文中最新的一篇里的解决方案,也是准确率最高的。Firmup方案中使用的是上面的第二种思路,也就是分别生成属于两段代码的特征,然后对比两个特征得出相似度。下面介绍Firmup方案里的特征提取算法以及特征匹配算法。
特征提取算法
第一步:生成CFG

CFG控制流图中每个节点代表一个基本块(basic-block),跳跃目标以一个块开始,和以一个块结束。生成CFG有很多成熟工具可以完成,同时也允许编程,比如IDApython,和angr 二进制分析框架。
第二步:统一为Vex-IR
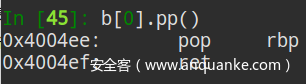
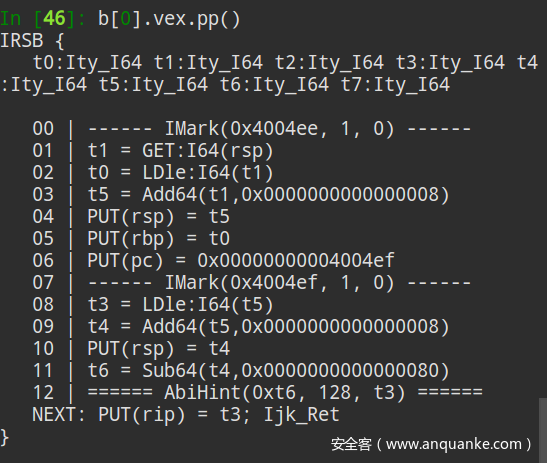
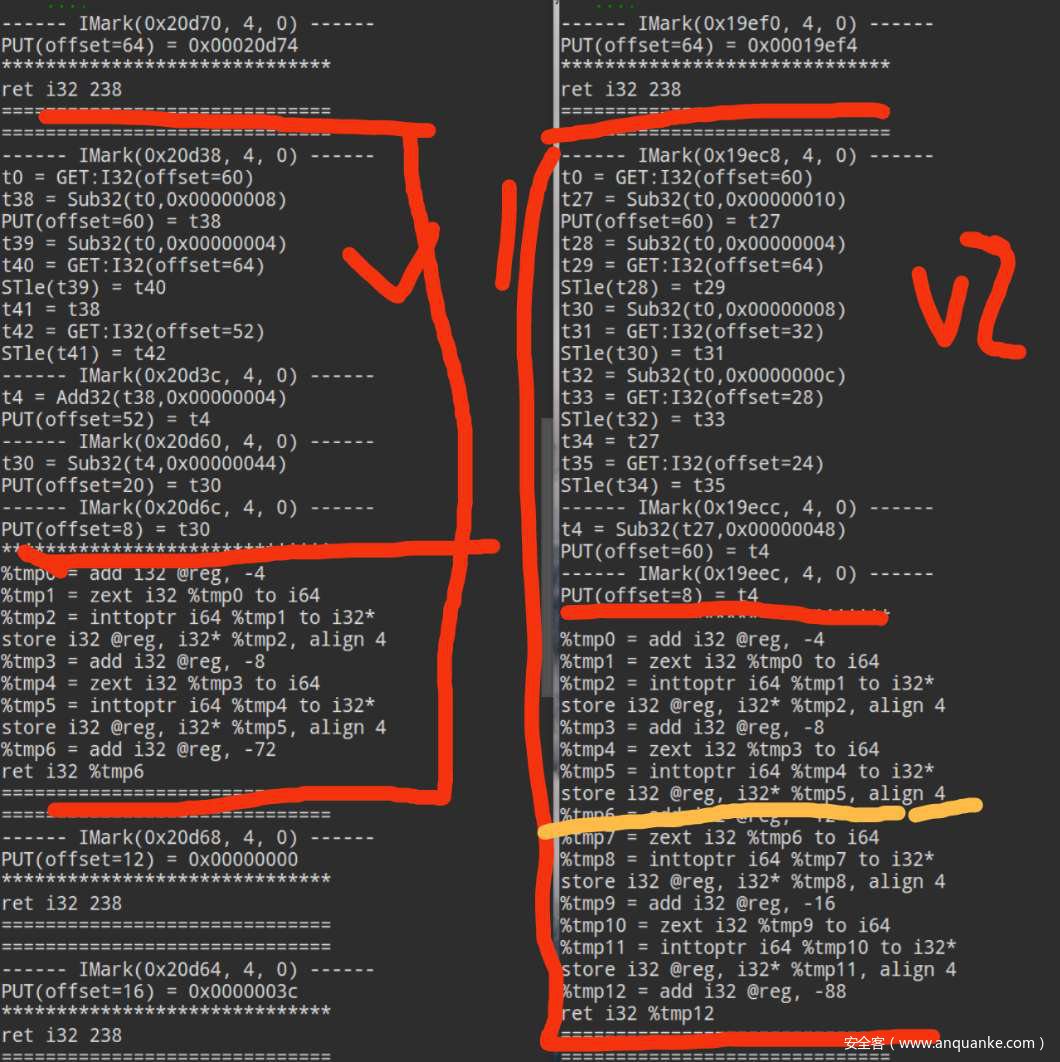
VEX-IR是为了方便二进制自动化分析而创造的跨平台间差异的中间表达式。第二步是將CFG的每个节点也就是basicblock的内容以Vex-IR的形式来储存,IR是一种语言的中间形式,类似于clang编译器前端將c语言翻译为IR,编译器后端再將IR编译成具体平台的代码。但是Vex-IR比较特殊,是由二进制代码提升为IR,是反向的,专门用于跨平台二进制分析,能把不同平台的指令统一为同一种形式。比如上图第一张是两条汇编指令,第二张是翻译成的Vex-IR,以IMark指令为分割,將每条汇编指令都翻译成了多条Vex-IR,比如0x404ee这条pop指令翻译之后,包括了读取rsp当前指向内容、缩小栈再到赋值给rbp、为pc赋值將指令指针指向下一条,可以看出Vex-IR是將一条汇编指令的所有功能翻译为多条简单指令(load以及put)来实现跨平台统一的。这是Firmup的思路中起到跨平台的主要工具。
第三步:数据流分片

这一步运用数据流分片,將Basic-Block分为更细的粒度:strand,strand是一个BB中的一个Use-Define链,每个strand只包含用来计算同一输出的多条指令。具体分片操作是由下向上的,比如先使用第5条指令cmp,在里面使用了寄存器r13,接着上找到第四条sub修改了r13的值,同时又读取了r15,再向上找第2条指令为r15赋值,同时也读取了rax,至此上面也没有指令为rax赋值,一个strand就分割完成了。再经过类似的过程,可以將一块BB分割为多个strand,每一个strand都是一个完整的“赋值-使用”的链条。
第四步:Vex-IR to LLVM-IR

进行到这一步之前,每一个basic-block都已经分割为了strand(由Vex-IR表示)。现在将一个Vex-IR块翻译为LLVM-IR的一个函数。这么做的目的在第五步中会详细说明。这一步转换的过程在Firmup的文章中一句带过,但是实际上是技术实现起来最复杂的部分,具体实现在后面在实现部分会有详细介绍。
第五步:优化LLVM-IR

第五步是对刚刚第四步翻译出来的strand(LLVM-IR形式)进行语义上的优化,之所以费了很大力气把Vex-IR转化成LLVM-IR,是想利用llvm 非常成熟的优化工具opt,这样一来不同优化等级、不同工具链编译的代码,能够在opt的分析下统一优化为最高优化等级的代码,这是Firmup论文的思路中起到跨优化等级跨工具链的主要工具。
第六步:统一化
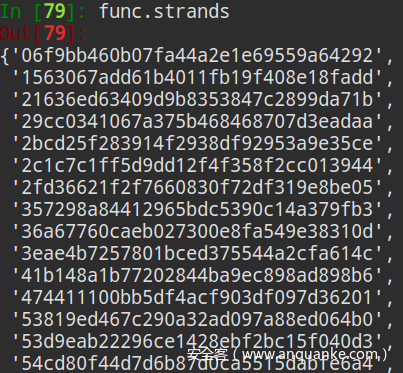
最后会对优化之后的llvm-IR进行命名统一化,包括寄存器名和变量名,统一以其出现的次序重新命名,这也是屏蔽平台间差异的一项措施,最后提取出的一个函数的特征就是他的所有的strand的集合,每个strand都是一段LLVM-IR,也是一串字符,最后我们计算每个strand的md5方便比较、存储。
总结

至此特征提取的六个步骤就介绍完了,总结起来如图:一个可执行程序包含多个函数,每个函数经过CFG得到多块block,每块block都能经过数据流分片分割为多个strand,所以我们提取出的每个function的特征,便是由他下面所有的strand组成的集合,function也是我们用来匹配的单位。
特征匹配算法
两个函数相似度指标:拥有的相同strand的数量(交集大小)
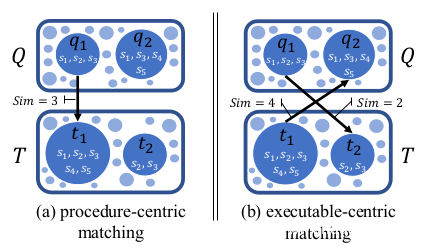
现在我们得到了每个函数的特征,下面介绍文章中的特征匹配算法。按照刚刚的思路,每个函数的特征都是一个strand集合,我们可以简单的比较和哪个函数的strand交集最多就认为那个函数是最佳的匹配。
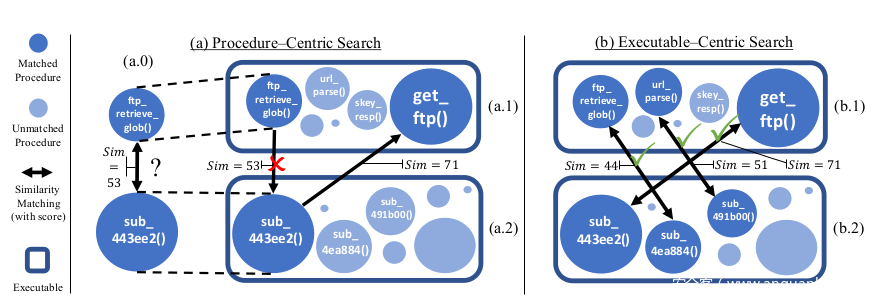
但是此时会遇到一个问题,如上图,上侧的ftp retrieve glob与sub443ee2是strand交集是最多的,但实际上443ee2的最佳匹配是getftp,这是函数不同的大小规模造成的,ftpretrieve比sub443ee2小了一些,正确的匹配应该是像上图右半侧里的对应关系。

下面介绍论文中在一定程度上解决这个问题从而提高准确率的匹配算法,如上图:横纵坐标分别是编译在arm和mips平台上的curl里面的函数,2和3代表编译优化level,函数名后面的括号是他包含的strand数,a1、a2、a3是他们的简称。
我们拿a1作为查询函数,首先看b1、b2、b3哪个函数与a1的strand交集数量最多,是b2,直观上可以看到是不对的。算法继续,计算b2的最佳匹配是a2函数,a2和a1是不同的函数,也就表明a1的最佳匹配应该不是b2。这时候我们把b2也放入tomatch栈,先寻找b2的匹配对象,b2的最佳匹配是a2,a2的最佳匹配也是b2,这时候我们认为a2、b2才是正确的匹配,加入到match列表。 最后这时候tomatch里又只有a1,继续计算最佳匹配,现在应该是b1,因为b2已经找到了最佳的匹配对象,继续再看b1的最佳匹配也是a1,匹配成功。至此匹配完成,可以看出在没有在3×3匹配都计算的情况下得到了正确的匹配。最后更加详细的匹配算法伪代码在论文的Algorithm2,感兴趣的同学可以自行仔细阅读,在此不再贴出来赘述。
假设与限制
最后是论文算法所作出的假设以及限制:
粒度过大
匹配算法做了一个很强的假设,就是假设Q T两个程序有相似的函数,或者说从同一套源码编译的,这也就限制了应用的场景在同源程序间的匹配,没有办法只单单搜索函数或片段。
IR的表达能力有限


第二是Vex-IR没有能够完全屏蔽平台间的差异,比如对flag寄存器的操作,平台特有的指令arm里的clz。
复现及评估
软件架构
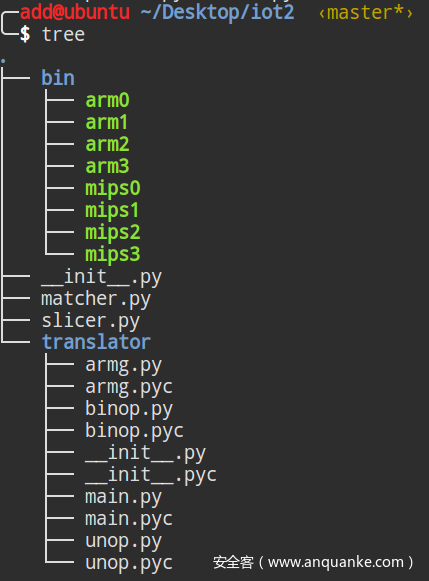
实现软件的架构主要分三个角色,matcher、slicer、translator:
matcher里实现了前面提到的匹配相关的所有算法
slicer里面主要是將block分割为strand的函数
translator是主要的部分,能够將vexIR翻译为LLVMIR
translator实现

因为translator在论文里基本是一句带过,但实际上是技术上实现难度最大的,他的输入是一块vexIR,输出是一个LLVM IR的函数,VexIR里面未读先写的寄存器作为全局变量传入函数,最后一个计算的变量作为函数的返回值,右侧的函数体内是左侧的每条指令逐条翻译过去的,最后用llvm opt优化翻译出的函数,最后根据变量出现的位置进行统一重命名。
效果评估
评估的方法是:分别编译两个curl,不去除符号表,对作为查询者的curl里面的每个函数都进行一次匹配,由于没有去除符号表,因此我们可以明确确定匹配是成功还是失败,最后计算匹配成功的概率。
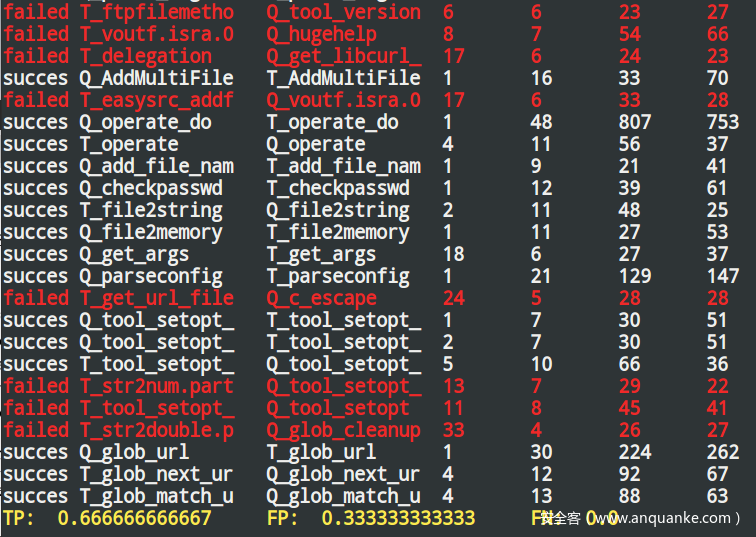
如上图,红色是匹配失败项,TP指正确匹配,FP指程序声称匹配到了结果,但结果是错误的。FN指程序认为被搜索的程序中没有匹配到对应函数,但是我们知道这个函数是存在的。
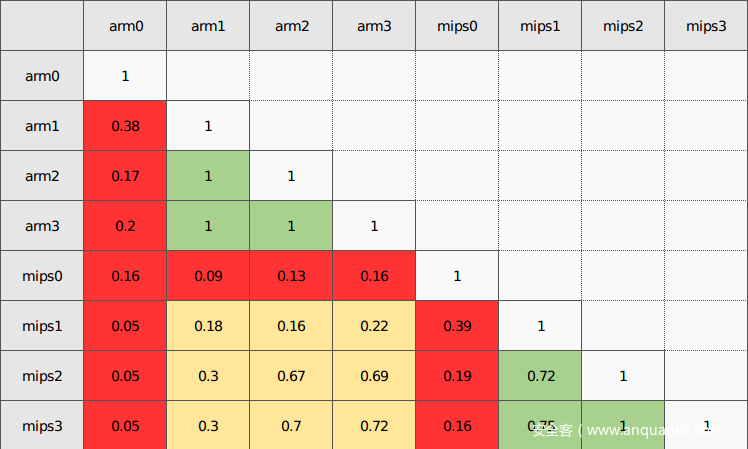
上面是一个比较全面的测试结果,arm0代表在arm架构上优化等级为0。可以看出红色区域是匹配双方包含编译优化等级为0的程序的情况,效率都很不理想,绿色是匹配双方同平台优化等级相似的情况,这时候准确率高一些。黄色区域是跨平台但都经过优化的情况。可以看到总体来看效果不是太理想。
改进
刚刚的效果很不理想,后面在寻找原因时,我发现了一个比较典型的现象,下图中左右两侧分别是两个curl同一个函数的第一块block,红色区域上半部分是Vex-IR,下半部分是翻译后的LLVM-IR,可以看出Vex-IR部分是明显不一致的,但是LLVM-IR部分右侧的黄线以上的部分是与左侧完全相同的。这个现象说明,当前strand的粒度可能还是太大了,前面的复现里的strand的组成是一条一条的汇编指令,我决定将其粒度改为Vex-IR中的一条条statement指令,也就是细化strand的粒度。
改进后效果评估
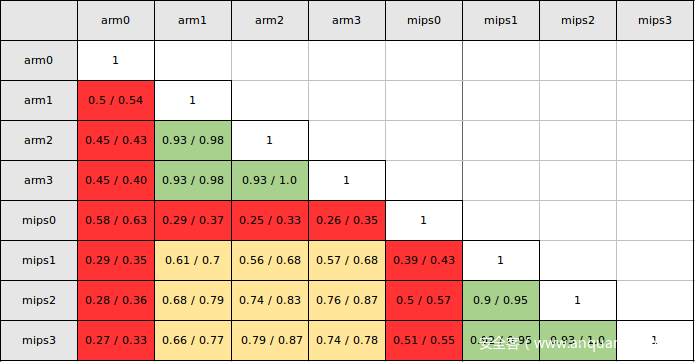
上图更改之后的效果,相同的测试场景,可以看到准确率有了明显的提升。
每个单元格的第一个数字代表只保留strand数大于5的函数的准确率,第二个数字代表只保留strand数大于15的函数的准确率,因此可以看出Firmup匹配算法更适合规模较大的函数。







发表评论
您还未登录,请先登录。
登录