

0x00 前言
一次使用sqlmap过程中,它无法检测出一个很明显的布尔型回显注入,很好奇sqlmap如何检测不出。再加上有写检测注入工具的想法,看看sqlmap究竟是如何自动判断boolean型注入。
0x01 无法检测boolean注入
这里是存在boolean型注入,sqlmap检测不出来了。
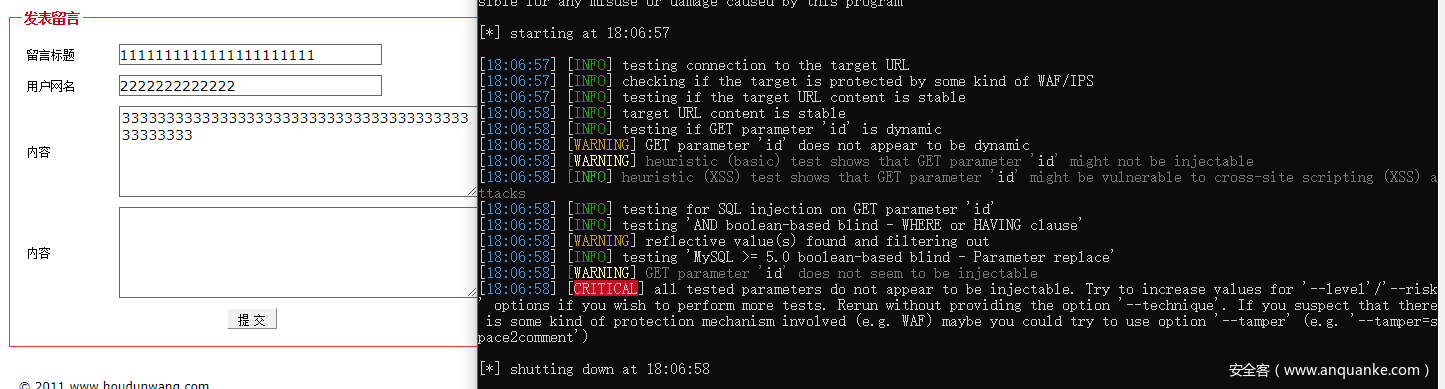
但是当把”33333333”增长一点,sqlmap是提取到”33333333…”作为了关键词来判断哪个页面正确哪个页面错误。
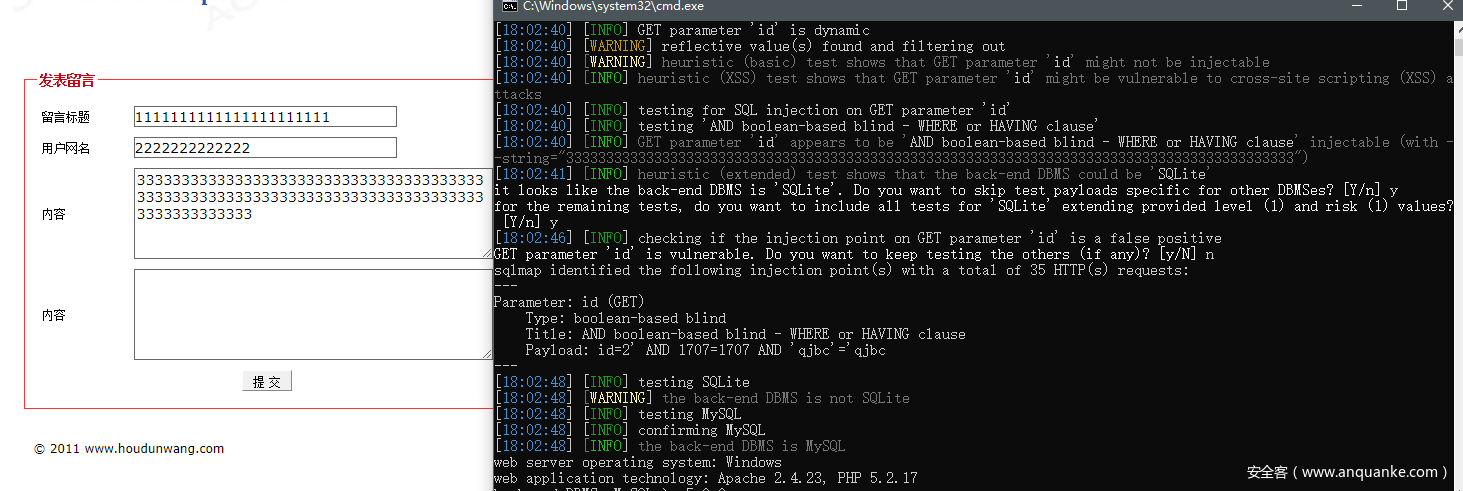
那sqlmap是如何提取的呢?
0x02 分析
sqlmap之所以能成为神器,因为它考虑了很多,代码也就很多,但是我对其他的技术细comparison节不太感兴趣,所以只针对如何检测boolean进行详细追溯。开始分析的时候,看代码的时候是根据关键词往上溯,这里是从上往下看。
通过上图,通过sqlmap显示的info,找到关键词with --string=,来到sqlmap-masterlibcontrollerchecks.py,再寻找if、while之类的看下代码的流程,来到478行
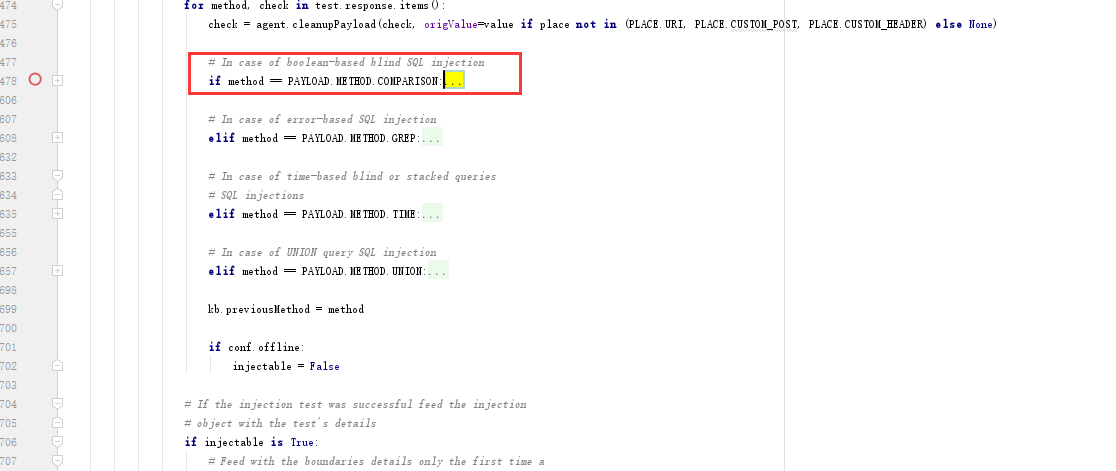
从注释可以看到,这里是boolean型检测开始,下面还有其他的error-based、time-based、UNION query。明白自己所在的位置,大概分析的范围。
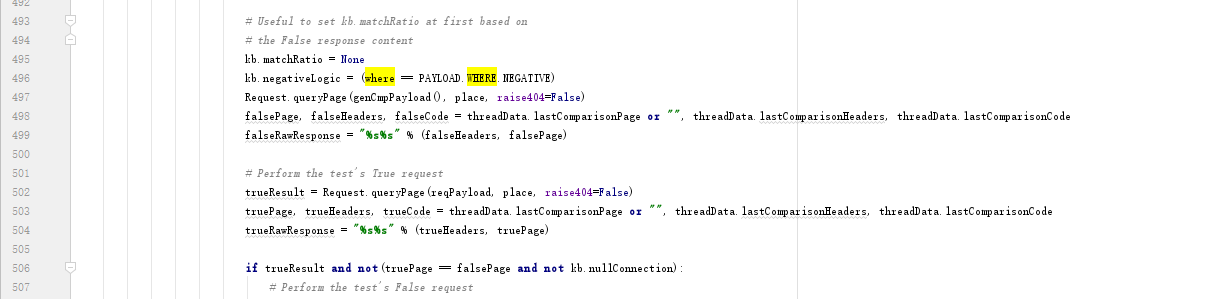
genCmpPayload这个函数用于生成boolean类型payload,
kb.matchRatio是原始页面和id=原始值+"),'.)(((,报错页面的相似度。
kb.negativeLogic是负逻辑,用一个负的随机数然后添加or的payload,where其他值可以在sqlmap-masterxmlpayloadsboolean_blind.xml看到具体含义。

接下来是queryPage函数,这个函数比较重要,它有一个修饰器,在sqlmap-masterlibcoredecorators.py中,threadData比较重要,它存储着上次请求的请求的各种数据,用来进行对比数据。在这个修饰的作用是为了当函数调用失败的时候,如果函数增加了往threadData.valueStack增加了数据,可以进行删除,从而恢复原来未调用函数之前的状态。下面是threadData存储的内容。

queryPage还会根据参数值,返回不同的结果,比较关键的是getRatioValue参数,因为这个参数的bool值影响里面最为关键函数comparison返回值。
comparison函数,也是根据getRatioValue参数,返回不同的结果,当getRatioValue为True的时候,返回与原始页面的相似度。
为False的时候,返回Bool值:
ratio > UPPER_RATIO_BOUND(0.98),返回True。
ratio < LOWER_RATIO_BOUND(0.02)为False。
(ratio - kb.matchRatio) > DIFF_TOLERANCE(0.05),允许%0.05的误差。
很多情况下payload会回显在页面上,sqlmap这里是把payload替换成REFLECTED_VALUE,然后对比的时候再把这些干扰因素去掉。
再通过threadData给falsePage, truePage返回包的各种参数(用于后面提取特征)。并通过queryPage获取相似度。进入到下一步判断。
这里有一个kb.nullConnection,通过checkNullConnection函数进行检测,
1、HEAD方法请求,判断返回包里面是否有Content-Length。(近iis6支持)
2、增加Header头Range: bytes=-1,通过len判断返回报body的长度是不是等于1。(这个测试了apache、nginx、Apache-Coyote/1.1都无效)
3、直接通过判断返回报文里面是否有Content-Length,如果有则说明支持skip-read。(仅仅读取Content-Length的长度,来作为判断注入的依据)
当取Content-Length作为判断的时候的相似度计算公式,这里注意一点,这里有一个取倒数
ratio = 1. * len(seqMatcher.a) / len(page)
if ratio > 1:
ratio = 1. / ratio
因为多字节的问题,”路飞”,len(“路飞”)为2,而Content-Length为4。这样会导致ratio大于1。
再看下下面的判断

前面是发送正确的payload返回true,现在拿false的payload发送,测试是否返回false。如果错误页面的相似度也高于0.98则进入提取特征的环节,并不会判定为为注入。如果错误页面低于0.98虽然也会进入获取页面特征环节,但是此时已经被标注成了注入了。
在标记注入前,如果kb.heavilyDynamic(太多的变量了),还会进行一次使用ture payload判断是否如何规则。然后才把injectable置为true。
函数getFilteredPageContent通过正则<script.+?</script>|<!--.+?-->|<style.+?</style>|<[^>]+>|t|n|r去掉所有的标签和script和css样式代码,通过对比正确的页面和错误页面收集的关键词,减去差集获取特征候选者。
获取到特征候选者还会继续判断是不是仅仅由字符,逗号,句号,感叹,空格构成,里面是否又感叹号,是长度大于10,这样才之后才能成为特征值。

这里主要是用于在判断了可能存在注入,提取一些特征,比如返回状态码、返回字符串。函数extractTextTagContent通过正则<(abbr|acronym|b|blockquote|br|center|cite|code|dt|em|font|h\d|i|li|p|pre|q|strong|sub|sup|td|th|title|tt|u)(?!\w).*?>([^<]+)提取特定标签的text,然后获取正确页面text-错误页面text集合-错误页面的text,得到特征字符串。

提取不返回的字符串,如果没有字符串和状态码这样明显特征,在判定可能存在注入的情况下,就只能靠相似度来识别。

后面判定存在了,做了一些赋值,为后面的注入数据做准备工作。下面还有两个检测过滤工作。
checkSuhosinPatch(injection),检查了Suhosin path,因为Suhosin Get类型的,只获取value值前512字节,所以发送超过512字节的payload,看是否还存在注入,如果存在,就没有Suhosin path,
payload为:
id=1' and 9703= (512空格) 9703 AND 'DyXn'='DyXn
checkFilteredChars(injection),检测大于号和圆括号是否过滤,如果利用下面payload请求返回包的相似度判断是否被过滤。
AND 2210>2209 AND 'mTvV'='mTvV
AND (2209)=2209 AND 'ZWWn'='ZWWn
总结
首先会收集原始页面body内容,用于相似度的比较,然后通过相似度初步判断是不是注入,如果判定为注入还会进行提取特征去作为特征值,如果没有只能使用相似度作为判断。
if re.match(r"A[w.,! ]+Z", candidate) and ' ' in candidate and candidate.strip() and len(candidate) > CANDIDATE_SENTENCE_MIN_LENGTH:
conf.string = candidate
injectable = True
最开始说的那个注入之所以没有检测出,就是因为错误页面的相似度高于0.98,虽然提取出特征出来,但是后面判断特征不符合,放弃了该特征,导致判定没有注入。
而这个判断是不太符合国情的,因为我们语言中使用空格的频率并不高,而英语是一个单词一个空格。







发表评论
您还未登录,请先登录。
登录