本文篇幅较长、内容干货,建议收藏慢慢看
在2018年5月到12月,伴随着阿里安全主办的软件供应链安全大赛,我们自身在设计、引导比赛的形式规则的同时,也在做着反思和探究,直接研判诸多方面潜在风险,以及透过业界三方的出题和解题案例分享,展示了行业内一线玩家对问题、解决方案实体化的思路
(参见如下历史文章:
2、阿里软件供应链安全大赛到底在比什么?C源代码赛季官方赛题精选出炉!
3、『功守道』软件供应链安全大赛·PE二进制赛季启示录:上篇
4、『功守道』软件供应链安全大赛·PE二进制赛季启示录:下篇
另外,根据近期的一些历史事件,也做了一些深挖和联想,考虑恶意的上游开发者,如何巧妙(或者说,处心积虑)地将问题引入,并在当前的软件供应链生态体系中,造成远比表面上看起来要深远得多的影响(参见:《深挖CVE-2018-10933(libssh服务端校验绕过)兼谈软件供应链真实威胁》)。
以上这些,抛开体系化的设想,只看案例,可能会得到这样的印象:这种威胁,都是由蓄意的上游或第三方参与者造成的;即便在最极端情况下,假使一个大型软件商或开源组织,被发现存在广泛、恶意的上游代码污染,那它顶多也不过相当于“奥创”一样的邪恶寡头,与其划清界限、清除历史包袱即可,虽然可能有阵痛。
可惜,并非如此。
在我们组织比赛的后半程中,对我们面临的这种威胁类型,不断有孤立的事例看似随机地发生,对此我以随笔的方式对它们做了分析和记录,以下与大家分享。
Ⅰ. 从感染到遗传:LibVNC与TightVNC系列漏洞
2018年12月10日晚9:03,OSS漏洞预警平台弹出的一封漏洞披露邮件,引起了我的注意。披露者是卡巴斯基工控系统漏洞研究组的Pavel Cheremushkin。
一些必要背景
VNC是一套屏幕图像分享和远程操作软件,底层通信为RFB协议,由剑桥某实验室开发,后1999年并入AT&T,2002年关停实验室与项目,VNC开源发布。
VNC本被设计用在局域网环境,且诞生背景决定其更倾向研究性质,商用级安全的缺失始终是个问题。后续有若干新的实现软件,如TightVNC、RealVNC,在公众认知中,AT&T版本已死,后起之秀一定程度上修正了问题。
目前各种更优秀的远程控制和分享协议取代了VNC的位置,尽管例如苹果仍然系统內建VNC作为远程方式。但在非桌面领域,VNC还有我们想不到的重要性,比如工控领域需要远程屏幕传输的场景,这也是为什么这系列漏洞作者会关注这一块。
漏洞技术概况
Pavel总结到,在阶段漏洞挖掘中共上报11个漏洞。在披露邮件中描述了其中4个的技术细节,均在协议数据包处理代码中,漏洞类型古典,分别是全局缓冲区溢出、堆溢出和空指针解引用。其中缓冲区溢出类型漏洞可方便构造PoC,实现远程任意代码执行的漏洞利用。
漏洞本身原理简单,也并不是关键。以其中一个为例,Pavel在发现时负责任地向LibVNC作者提交了issue,并跟进漏洞修复过程;在第一次修复之后,复核并指出修复代码无效,给出了有效patch。这个过程是常规操作。
漏洞疑点
有意思的是,在漏洞披露邮件中,Pavel重点谈了自己对这系列漏洞的一些周边发现,也是这里提到的原因。其中,关于存在漏洞的代码,作者表述:
我最初认为,这些问题是libvnc开发者自己代码中的错误,但看起来并非如此。其中有一些(如CoRRE数据处理函数中的堆缓冲区溢出),出现在AT&T实验室1999年的代码中,而后被很多软件开发者原样复制(在Github上搜索一下HandleCoRREBPP函数,你就知道),LibVNC和TightVNC也是如此。
为了证实,翻阅了这部分代码,确实在其中数据处理相关代码文件看到了剑桥和AT&T实验室的文件头GPL声明注释,

这证实这些文件是直接从最初剑桥实验室版本VNC移植过来的,且使用方式是 直接代码包含,而非独立库引用方式。在官方开源发布并停止更新后,LibVNC使用的这部分代码基本没有改动——除了少数变量命名方式的统一,以及本次漏洞修复。通过搜索,我找到了2000年发布的相关代码文件,确认这些文件与LibVNC中引入的原始版本一致。
另外,Pavel同时反馈了TightVNC中相同的问题。TightVNC与LibVNC没有继承和直接引用关系,但上述VNC代码同样被TightVNC使用,问题的模式不约而同。Pavel测试发现在Ubuntu最新版本TightVNC套件(1.3.10版本)中同样存在该问题,上报给当前软件所有者GlavSoft公司,但对方声称目前精力放在不受GPL限制的TightVNC 2.x版本开发中,对开源的1.x版本漏洞代码“可能会进行修复”。看起来,这个问题被踢给了各大Linux发行版社区来焦虑了——如果他们愿意接锅。
问题思考
在披露邮件中,Pavel认为,这些代码bug“如此明显,让人无法相信之前没被人发现过……也许是因为某些特殊理由才始终没得到修复”。
事实上,我们都知道目前存在一些对开源基础软件进行安全扫描的大型项目,例如Google的OSS;同时,仍然存活的开源项目也越来越注重自身代码发布前的安全扫描,Fortify、Coverity的扫描也成为很多项目和平台的标配。在这样一些眼睛注视下,为什么还有这样的问题?我认为就这个具体事例来说,可能有如下两个因素:
- 上游已死。仍然在被维护的代码,存在版本更迭,也存在外界的持续关注、漏洞报告和修复、开发的迭代,对于负责人的开发者,持续跟进、评估、同步代码的改动是可能的。但是一旦一份代码走完了生命周期,就像一段史实一样会很少再被改动。
- 对第三方上游代码的无条件信任。我们很多人都有过基础组件、中间件的开发经历,不乏有人使用Coverity开启全部规则进行代码扫描、严格修复所有提示的问题甚至编程规范warning;报告往往很长,其中也包括有源码形式包含的第三方代码中的问题。但是,我们一方面倾向于认为这些被广泛使用的代码不应存在问题(不然早就被人挖过了),一方面考虑这些引用的代码往往是组件或库的形式被使用,应该有其上下文才能认定是否确实有可被利用的漏洞条件,现在单独扫描这部分代码一般出来的都是误报。所以这些代码的问题都容易被忽视。
但是透过这个具体例子,再延伸思考相关的实践,这里最根本的问题可以总结为一个模式: 复制粘贴风险。复制粘贴并不简单意味着剽窃,实际是当前软件领域、互联网行业发展的基础模式,但其中有一些没人能尝试解决的问题:
- 在传统代码领域,如C代码中,对第三方代码功能的复用依赖,往往通过直接进行库的引入实现,第三方代码独立而完整,也较容易进行整体更新;这是最简单的情况,只需要所有下游使用者保证仅使用官方版本,跟进官方更新即可;但在实践中很难如此贯彻,这是下节讨论的问题。
- 有些第三方发布的代码,模式就是需要被源码形式包含到其他项目中进行统一编译使用(例如腾讯的开源Json解析库RapidJSON,就是纯C++头文件形式)。在开源领域有如GPL等规约对此进行规范,下游开发者遵循协议,引用代码,强制或可选地显式保留其GPL声明,可以进行使用和更改。这样的源码依赖关系,结合规范化的changelog声明代码改动,侧面也是为开发过程中跟进考虑。但是一个成型的产品,比如企业自有的服务端底层产品、中间件,新版本的发版更新是复杂的过程,开发者在旧版本仍然“功能正常”的情况下往往倾向于不跟进新版本;而上游代码如果进行安全漏洞修复,通常也都只在其最新版本代码中改动,安全修复与功能迭代并存,如果没有类似Linux发行版社区的努力,旧版本代码完全没有干净的安全更新patch可用。
- 在特定场景下,有些开发实践可能不严格遵循开源代码协议限定,引入了GPL等协议保护的代码而不做声明(以规避相关责任),丢失了引入和版本的信息跟踪;在另一些场景下,可能存在对开源代码进行大刀阔斧的修改、剪裁、定制,以符合自身业务的极端需求,但是过多的修改、人员的迭代造成与官方代码严重的失同步,丧失可维护性。
- 更一般的情况是,在开发中,开发者个体往往心照不宣的存在对网上代码文件、代码片段的复制-粘贴操作。被参考的代码,可能有上述的开源代码,也可能有各种Github作者练手项目、技术博客分享的代码片段、正式开源项目仅用来说明用法的不完备示例代码。这些代码的引入完全无迹可寻,即便是作者自己也很难解释用了什么。这种情况下,上面两条认定的那些与官方安全更新失同步的问题同样存在,且引入了独特的风险:被借鉴的代码可能只是原作者随手写的、仅仅是功能成立的片段,甚至可能是恶意作者随意散布的有安全问题的代码。由此,问题进入了最大的发散空间。
在Synopsys下BLACKDUCK软件之前发布的《2018 Open Source Security and Risk Analysis Report》中分析,96%的应用中包含有开源组件和代码,开源代码在应用全部代码中的占比约为57%,78%的应用中在引用的三方开源代码中存在历史漏洞。也就是说,现在互联网上所有厂商开发的软件、应用,其开发人员自己写的代码都是一少部分,多数都是借鉴来的。而这还只是可统计、可追溯的;至于上面提到的非规范的代码引用,如果也纳入进来考虑,三方代码占应用中的比例会上升到多少?曾经有分析认为至少占80%,我们只期望不会更高。
Ⅱ. 从碎片到乱刃:OpenSSH在野后门一览
在进行基础软件梳理时,回忆到反病毒安全软件提供商ESET在2018年十月发布的一份白皮书《THE DARK SIDE OF THE FORSSHE: A landscape of OpenSSH backdoors》。其站在一个具有广泛用户基础的软件提供商角度,给出了一份分析报告,数据和结论超出我们对于当前基础软件使用全景的估量。以下以我的角度对其中一方面进行解读。
一些必要背景
SSH的作用和重要性无需赘言;虽然我们站在传统互联网公司角度,可以认为SSH是通往生产服务器的生命通道,但当前多样化的产业环境已经不止于此(如之前libssh事件中,不幸被我言中的,SSH在网络设备、IoT设备上(如f5)的广泛使用)。
OpenSSH是目前绝大多数SSH服务端的基础软件,有完备的开发团队、发布规范、维护机制,本身是靠谱的。如同绝大多数基础软件开源项目的做法,OpenSSH对漏洞有及时的响应,针对最新版本代码发出安全补丁,但是各大Linux发行版使用的有各种版本的OpenSSH,这些社区自行负责将官方开发者的安全补丁移植到自己系统搭载的低版本代码上。
白皮书披露的现状
如果你是一个企业的运维管理人员,需要向企业生产服务器安装OpenSSH或者其它基础软件,最简单的方式当然是使用系统的软件管理安装即可。但是有时候,出于迁移成本考虑,可能企业需要在一个旧版本系统上,使用较新版本的OpenSSL、OpenSSH等基础软件,这些系统不提供,需要自行安装;或者需要一个某有种特殊特性的定制版本。这时,可能会选择从某些rpm包集中站下载某些不具名第三方提供的现成的安装包,或者下载非官方的定制化源码本地编译后安装,总之从这里引入了不确定性。
这种不确定性有多大?我们粗估一下,似乎不应成为问题。但这份白皮书给我们看到了鲜活的数据。
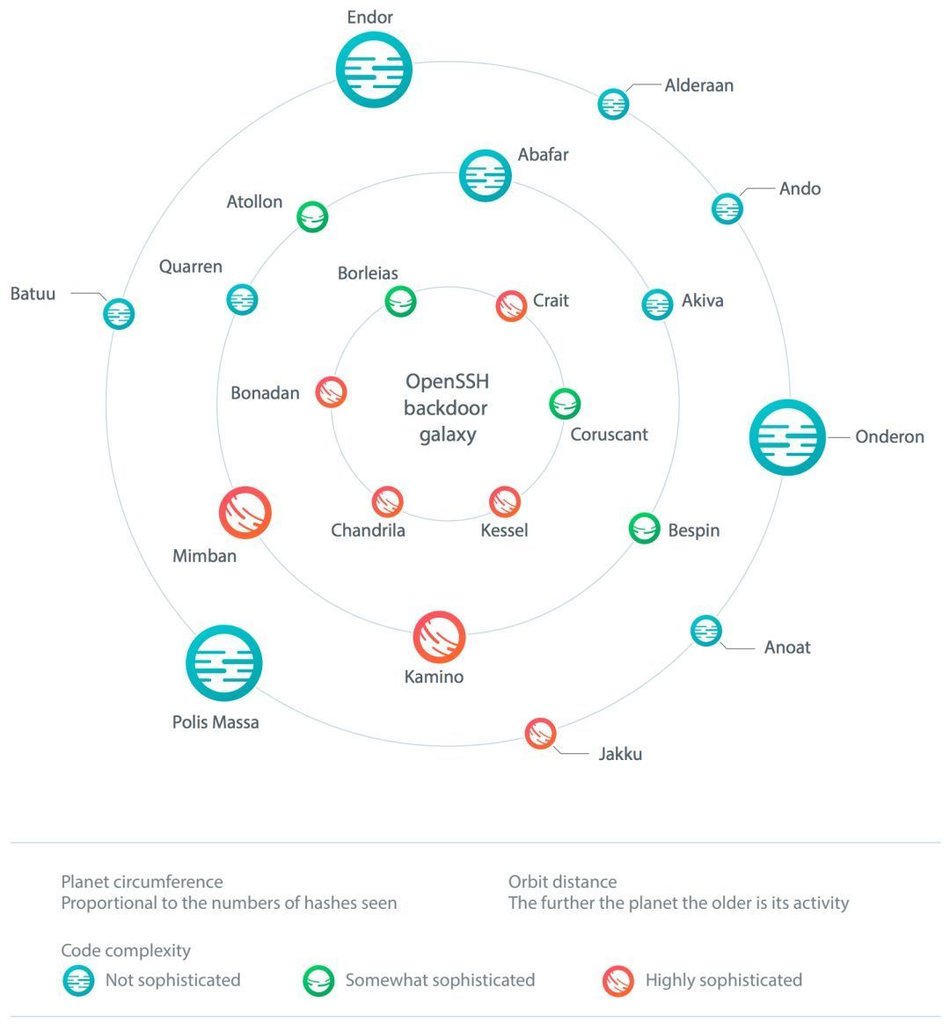
ESET研究人员从OpenSSH的一次历史大规模Linux服务端恶意软件Windigo中获得启示,采用某种巧妙的方式,面向在野的服务器进行数据采集,主要是系统与版本、安装的OpenSSH版本信息以及服务端程序文件的一个特殊签名。整理一个签名白名单,包含有所有能搜索到的官方发布二进制版本、各大Linux发行版本各个版本所带的程序文件版本,将这些标定为正常样本进行去除。最终结论是:
- 共发现了几百个非白名单版本的OpenSSH服务端程序文件ssh和sshd;
- 分析这些样本,将代码部分完全相同,仅仅是数据和配置不同的合并为一类,且分析判定确认有恶意代码的,共归纳为 21个各异的恶意OpenSSH家族;
- 在21个恶意家族中,有12个家族在10月份时完全没有被公开发现分析过;而剩余的有一部分使用了历史上披露的恶意代码样本,甚至有源代码;
- 所有恶意样本的实现,从实现复杂度、代码混淆和自我保护程度到代码特征有很大跨度的不同,但整体看,目的以偷取用户凭证等敏感信息、回连外传到攻击者为主,其中有的攻击者回连地址已经存在并活跃数年之久;
- 这些后门的操控者,既有传统恶意软件黑产人员,也有APT组织;
- 所有恶意软件或多或少都在被害主机上有未抹除的痕迹。ESET研究者尝试使用蜜罐引诱出攻击者,但仍有许多未解之谜。这场对抗,仍未取胜。
白皮书用了大篇幅做技术分析报告,此处供细节分析,不展开分析,以下为根据恶意程序复杂度描绘的21个家族图谱:
问题思考
问题引入的可能渠道,我在开头进行了一点推测,主要是由人的原因切入的,除此以外,最可能的是恶意攻击者在利用各种方法入侵目标主机后,主动替换了目标OpenSSH为恶意版本,从而达成攻击持久化操作。但是这些都是止血的安全运维人员该考虑的事情;关键问题是,透过表象,这显露了什么威胁形式?
这个问题很好回答,之前也曾经反复说过:基础软件碎片化。
如上一章节简单提到,在开发过程中有各种可能的渠道引入开发者不完全了解和信任的代码;在运维过程中也是如此。二者互相作用,造成了软件碎片化的庞杂现状。在企业内部,同一份基础软件库,可能不同的业务线各自定制一份,放到企业私有软件仓库源中,有些会有人持续更新供自己产品使用,有些由系统软件基础设施维护人员单独维护,有些则可能是开发人员临时想起来上传的,他们自己都不记得;后续用到的这个基础软件的开发和团队,在这个源上搜索到已有的库,很大概率会倾向于直接使用,不管来源、是否有质量背书等。长此以往问题会持续发酵。而我们开最坏的脑洞,是否可能有黑产人员入职到内部,提交个恶意基础库之后就走人的可能?现行企业安全开发流程中审核机制的普遍缺失给这留下了空位。
将源码来源碎片化与二进制使用碎片化并起来考虑,我们不难看到一个远远超过OpenSSH事件威胁程度的图景。但这个问题不是仅仅靠开发阶段规约、运维阶段规范、企业内部管控、行业自查、政府监管就可以根除的,最大的问题归根结底两句话: 不可能用一场战役对抗持续威胁;不可能用有限分析对抗无限未知。
Ⅲ. 从自信到自省:RHEL、CentOS backport版本BIND漏洞

2018年12月20日凌晨,在备战冬至的软件供应链安全大赛决赛时,我注意到漏洞预警平台捕获的一封邮件。但这不是一个漏洞初始披露邮件,而是对一个稍早已披露的BIND在RedHat、CentOS发行版上特定版本的1day漏洞CVE-2018-5742,由BIND的官方开发者进行额外信息澄(shuǎi)清(guō)的邮件。
一些必要背景
关于BIND
互联网的一个古老而基础的设施是DNS,这个概念在读者不应陌生。而BIND“是现今互联网上最常使用的DNS软件,使用BIND作为服务器软件的DNS服务器约占所有DNS服务器的九成。BIND现在由互联网系统协会负责开发与维护参考。”所以BIND的基础地位即是如此,因此也一向被大量白帽黑帽反复测试、挖掘漏洞,其开发者大概也一直处在紧绷着应对的处境。
关于ISC和RedHat
说到开发者,上面提到BIND的官方开发者是互联网系统协会(ISC)。ISC是一个老牌非营利组织,目前主要就是BIND和DHCP基础设施的维护者。而BIND本身如同大多数历史悠久的互联网基础开源软件,是4个UCB在校生在DARPA资助下于1984年的实验室产物,直到2012年由ISC接管。
那么RedHat在此中是什么角色呢?这又要提到我之前提到的Linux发行版和自带软件维护策略。Red Hat Enterprise Linux(RHEL)及其社区版CentOS秉持着稳健的软件策略,每个大的发行版本的软件仓库,都只选用最必要且质量久经时间考验的软件版本,哪怕那些版本实在是老掉牙。这不是一种过分的保守,事实证明这种策略往往给RedHat用户在最新漏洞面前提供了保障——代码总是跑得越少,潜在漏洞越多。
但是这有两个关键问题。
一方面,如果开源基础软件被发现一例有历史沿革的代码漏洞,那么官方开发者基本都只为其最新代码负责,在当前代码上推出修复补丁。
另一方面,互联网基础设施虽然不像其上的应用那样爆发性迭代,但依然持续有一些新特性涌现,其中一些是必不可少的,但同样只在最新代码中提供。
两个刚需推动下,各Linux发行版对长期支持版本系统的软件都采用一致的策略,即保持其基础软件在一个固定的版本,但对于这些版本软件的最新漏洞、必要的最新软件特性,由发行版维护者将官方开发者最新代码改动“向后移植”到旧版本代码中,即backport。这就是基础软件的“官宣”碎片化的源头。
讲道理,Linux发行版维护者与社区具有比较靠谱的开发能力和监督机制,backport又基本就是一些复制粘贴工作,应当是很稳当的……但真是如此吗?
CVE-2018-5742漏洞概况
CVE-2018-5742是一个简单的缓冲区溢出类型漏洞,官方评定其漏洞等级moderate,认为危害不大,漏洞修复不积极,披露信息不多,也没有积极给出代码修复patch和新版本rpm包。因为该漏洞仅在设置DEBUG_LEVEL为10以上才会触发,由远程攻击者构造畸形请求造成BIND服务崩溃,在正常的生产环境几乎不可能具有危害,RedHat官方也只是给出了用户自查建议。
这个漏洞只出现在RHEL和CentOS版本7中搭载的BIND 9.9.4-65及之后版本。RedHat同ISC的声明中都证实,这个漏洞的引入原因,是RedHat在尝试将BIND 9.11版本2016年新增的NTA机制向后移植到RedHat 7系中固定搭载的BIND 9.9版本代码时,偶然的代码错误。NTA是DNS安全扩展(DNSSEC)中,用于在特定域关闭DNSSEC校验以避免不必要的校验失败的机制;但这个漏洞不需要对NTA本身有进一步了解。
漏洞具体分析
官方没有给出具体分析,但根据CentOS社区里先前有用户反馈的bug,我得以很容易还原漏洞链路并定位到根本原因。
若干用户共同反馈,其使用的BIND 9.9.4-RedHat-9.9.4-72.el7发生崩溃(coredump),并给出如下的崩溃时调用栈backtrace:

这个调用过程的逻辑为,在#9 dns_message_logfmtpacket函数判断当前软件设置是否DEBUG_LEVEL大于10,若是,对用户请求数据包做日志记录,先后调用#8 dns_message_totext、#7 dns_message_sectiontotext、#6 dns_master_rdatasettotext、#5 rdataset_totext将请求进行按协议分解分段后写出。
由以上关键调用环节,联动RedHat在9.9.4版本BIND源码包中关于引入NTA特性的源码patch,进行代码分析,很快定位到问题产生的位置,在上述backtrace中的#5,masterdump.c文件rdataset_totext函数。漏洞相关代码片段中,RedHat进行backport后,这里引入的代码为:

这里判断对于请求中的注释类型数据,直接通过isc_buffer_putstr宏对缓存进行操作,在BIND工程中自定义维护的缓冲区结构对象target上,附加一字节字符串(一个分号)。而漏洞就是由此产生:isc_buffer_putstr中不做缓冲区边界检查保证,这里在缓冲区已满情况下将造成off-by-one溢出,并触发了缓冲区实现代码中的assertion。
而ISC上游官方版本的代码在这里是怎么写的呢?找到ISC版本BIND 9.11代码,这里是这样的:
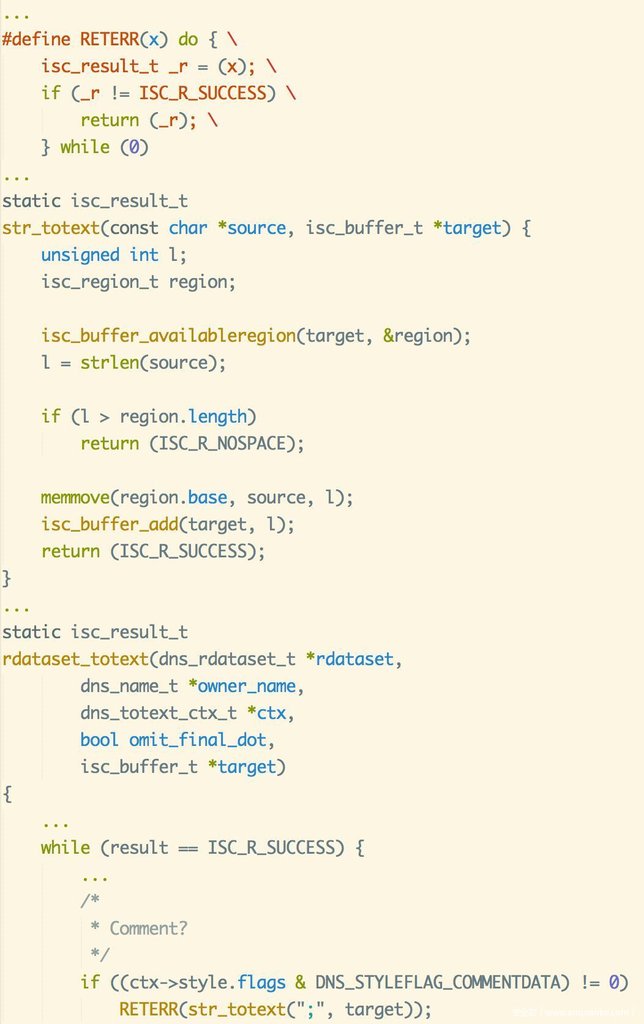
这里可以看到,官方代码在做同样的“附加一个分号”这个操作时,审慎的使用了做缓冲区剩余空间校验的str_totext函数,并额外做返回值成功校验。而上述提到的str_totext函数与RETERR宏,在移植版本的masterdump.c中,RedHat开发者也都做了保留。但是,查看代码上下文发现,在RedHat开发者进行代码移植过程中,对官方代码进行了功能上的若干剪裁,包括一些细分数据类型记录的支持;而这里对缓冲区写入一字节,也许开发者完全没想到溢出的可能,所以自作主张地简化了代码调用过程。
问题思考
这个漏洞本身几乎没什么危害,但是背后足以引起思考。
没有人在“借”别人代码时能不出错
不同于之前章节提到的那种场景——将代码文件或片段复制到自己类似的代码上下文借用——backport作为一种官方且成熟的做法,借用的代码来源、粘贴到的代码上下文,是具有同源属性的,而且开发者一般是追求稳定性优先的社区开发人员,似乎质量应该有足够保障。但是这里的关键问题是:代码总要有一手、充分的语义理解,才能有可信的使用保障;因此,只要是处理他人的代码,因为不够理解而错误使用的风险,只可能减小,没办法消除。
如上分析,本次漏洞的产生看似只是做代码移植的开发者“自作主张”之下“改错了”。但是更广泛且可能的情况是,原始开发者在版本迭代中引入或更新大量基础数据结构、API的定义,并用在新的特性实现代码中;而后向移植开发人员仅需要最小规模的功能代码,所以会对增量代码进行一定规模的修改、剪裁、还原,以此适应旧版本基本代码。这些过程同样伴随着第三方开发人员不可避免的“望文生义”,以及随之而来的风险。后向移植操作也同样助长了软件碎片化过程,其中每一个碎片都存在这样的问题;每一个碎片在自身生命周期也将有持续性影响。
多级复制粘贴无异于雪上加霜
这里简单探讨的是企业通行的系统和基础软件建设实践。一些国内外厂商和社区发布的定制化Linux发行版,本身是有其它发行版,如CentOS特定版本渊源的,在基础软件上即便同其上游发行版最新版本间也存在断层滞后。RedHat相对于基础软件开发者之间已经隔了一层backport,而我们则人为制造了二级风险。
在很多基础而关键的软件上,企业系统基础设施的维护者出于与RedHat类似的初衷,往往会决定自行backport一份拷贝;通过早年心脏滴血事件的洗礼,即暴露出来OpenSSL一个例子。无论是需要RHEL还没来得及移植的新版本功能特性,还是出于对特殊使用上下文场景中更高执行效率的追求,企业都可能自行对RHEL上基础软件源码包进行修改定制重打包。这个过程除了将风险幂次放大外,也进一步加深了代码的不可解释性(包括基础软件开发人员流动性带来的不可解释)。
Ⅳ. 从武功到死穴:从systemd-journald信息泄露一窥API误用
1月10日凌晨两点,漏洞预警平台爬收取一封漏洞披露邮件。披露者是Qualys,那就铁定是重型发布了。最后看披露漏洞的目标,systemd?这就非常有意思了。
一些必要背景
systemd是什么,不好简单回答。Linux上面软件命名,习惯以某软件名后带个‘d’表示后台守护管理程序;所以systemd就可以说是整个系统的看守吧。而即便现在描述了systemd是什么,可能也很快会落伍,因为其初始及核心开发者Lennart Poettering(供职于Red Hat)描述它是“永无开发完结完整、始终跟进技术进展的、统一所有发行版无止境的差异”的一种底层软件。笼统讲有三个作用:中央化系统及设置管理;其它软件开发的基础框架;应用程序和系统内核之间的胶水。如今几乎所有Linux发行版已经默认提供systemd,包括RHEL/CentOS 7及后续版本。总之很基础、很底层、很重要就对了。systemd本体是个主要实现init系统的框架,但还有若干关键组件完成其它工作;这次被爆漏洞的是其journald组件,是负责系统事件日志记录的看守程序。
额外地还想简单提一句Qualys这个公司。该公司创立于1999年,官方介绍为信息安全与云安全解决方案企业,to B的安全业务非常全面,有些也是国内企业很少有布局的方面;例如上面提到的涉及碎片化和代码移植过程的历史漏洞移动,也在其漏洞管理解决方案中有所体现。但是我们对这家公司粗浅的了解来源于其安全研究团队近几年的发声,这两年间发布过的,包括有『stack clash』、『sudo get_tty_name提权』、『OpenSSH信息泄露与堆溢出』、『GHOST:glibc gethostbyname缓冲区溢出』等大新闻(仅截至2017年年中)。从中可见,这个研究团队专门啃硬骨头,而且还总能开拓出来新的啃食方式,往往爆出来一些别人没想到的新漏洞类型。从这个角度,再联想之前刷爆朋友圈的《安全研究者的自我修养》所倡导的“通过看历史漏洞、看别人的最新成果去举一反三”的理念,可见差距。
CVE-2018-16866漏洞详情
这次漏洞披露,打包了三个漏洞:
- 16864和16865是内存破坏类型
- 16866是信息泄露;
- 而16865和16866两个漏洞组和利用可以拿到root shell
漏洞分析已经在披露中写的很详细了,这里不复述;而针对16866的漏洞成因来龙去脉,Qualys跟踪的结果留下了一点想象和反思空间,我们来看一下。
漏洞相关代码片段是这样的(漏洞修复前):

读者可以先肉眼过一遍这段代码有什么问题。实际上我一开始也没看出来,向下读才恍然大悟。
这段代码中,外部信息输入通过*buf传入做记录处理。输入数据一般包含有空白字符间隔,需要分隔开逐个记录,有效的分隔符包括空格、制表符、回车、换行,代码中将其写入常量字符串;在逐字符扫描输入数据字符串时,将当前字符使用strchr在上述间隔符字符串中检索是否匹配,以此判断是否为间隔符;在240行,通过这样的判断,跳过记录单元字符串的头部连续空白字符。 但是问题在于,strchr这个极其基础的字符串处理函数,对于C字符串终止字符’\0’的处理上有个坑:’\0’也被认为是被检索字符串当中的一个有效字符。所以在240行,当当前扫描到的字符为字符串末尾的NULL时,strchr返回的是WHITESPACE常量字符串的终止位置而非NULL,这导致了越界。
看起来,这是一个典型的问题:API误用(API mis-use),只不过这个被误用的库函数有点太基础,让我忍不住想是不是还会有大量的类似漏洞……当然也反思我自己写的代码是不是也有同样情况,然而略一思考就释然了——我那么笨的代码都用for循环加if判断了:)
漏洞引入和消除历史
有意思的是,Qualys研究人员很贴心地替我做了一步漏洞成因溯源,这才是单独提这个漏洞的原因。漏洞的引入是在2015年的一个commit中:

在GitHub中,定位到上述2015年的commit信息,这里commit的备注信息为:
journald: do not strip leading whitespace from messages.
Keep leading whitespace for compatibility with older syslog implementations. Also useful when piping formatted output to the logger command. Keep removing trailing whitespace.
OK,看起来是一个兼容性调整,对记录信息不再跳过开头所有连续空白字符,只不过用strchr的简洁写法比较突出开发者精炼的开发风格(并不),说得过去。
之后在2018年八月的一个当时尚未推正式版的另一次commit中被修复了,先是还原成了ec5ff4那次commit之前的写法,然后改成了加校验的方式:

虽然Qualys研究者认为上述的修改是“无心插柳”的改动,但是在GitHub可以看到,a6aadf这次commit是因为有外部用户反馈了输入数据为单个冒号情况下journald堆溢出崩溃的issue,才由开发者有目的性地修复的;而之后在859510这个commit再次改动回来,理由是待记录的消息都是使用单个空格作为间隔符的,而上一个commit粗暴地去掉了这种协议兼容性特性。
如果没有以上纠结的修改和改回历史,也许我会倾向于怀疑,在最开始漏洞引入的那个commit,既然改动代码没有新增功能特性、没有解决什么问题(毕竟其后三年,这个改动的代码也没有被反映issue),也并非出于代码规范等考虑,那么这么轻描淡写的一次提交,难免有人为蓄意引入漏洞的嫌疑。当然,看到几次修复的原因,这种可能性就不大了,虽然大家仍可以保留意见。但是抛开是否人为这个因素,单纯从代码的漏洞成因看,一个传统但躲不开的问题仍值得探讨:API误用。
API误用:程序员何苦为难程序员
如果之前的章节给读者留下了我反对代码模块化和复用的印象,那么这里需要正名一下,我们认可这是当下开发实践不可避免的趋势,也增进了社会开发速度。而API的设计决定了写代码和用代码的双方“舒适度”的问题,由此而来的API误用问题,也是一直被当做单纯的软件工程课题讨论。在此方面个人并没有什么研究,自然也没办法系统地给出分类和学术方案,只是谈一下自己的经验和想法。
一篇比较新的学术文章总结了API误用的研究,其中一个独立章节专门分析Java密码学组件API误用的实际,当中引述之前论文认为,密码学API是非常容易被误用的,比如对期望输入数据(数据类型,数据来源,编码形式)要求的混淆,API的必需调用次序和依赖缺失(比如缺少或冗余多次调用了初始化函数、主动资源回收函数)等。凑巧在此方面我有一点体会:曾经因为业务方需要,需要使用C++对一个Java的密码基础中间件做移植。Java对密码学组件支持,有原生的JDK模块和权威的BouncyCastle包可用;而C/C++只能使用第三方库,考虑到系统平台最大兼容和最小代码量,使用Linux平台默认自带的OpenSSL的密码套件。但在开发过程中感受到了OpenSSL满满的恶意:其中的API设计不可谓不反人类,很多参数没有明确的说明(比如同样是表示长度的函数参数,可能在不同地方分别以字节/比特/分组数为计数单位);函数的线程安全没有任何解释标注,需要自行试验;不清楚函数执行之后,是其自行做了资源释放还是需要有另外API做gc,不知道资源释放操作时是否规规矩矩地先擦除后释放……此类问题不一而足,导致经过了漫长的测试之后,这份中间件才提供出来供使用。而在业务场景中,还会存在比如其它语言调用的情形,这些又暴露出来OpenSSL API误用的一些完全无从参考的问题。这一切都成为了噩梦;当然这无法为我自己开解是个不称职开发的指责,但仅就OpenSSL而言其API设计之恶劣也是始终被人诟病的问题,也是之后其他替代者宣称改进的地方。
当然,问题是上下游都脱不了干系的。我们自己作为高速迭代中的开发人员,对于二方、三方提供的中间件、API,又有多少人能自信地说自己仔细、认真地阅读过开发指南和API、规范说明呢?做过通用产品技术运营的朋友可能很容易理解,自己产品的直接用户日常抛出不看文档的愚蠢问题带来的困扰。对于密码学套件,这个问题还好办一些,毕竟如果在没有背景知识的情况下对API望文生义地一通调用,绝大多数情况下都会以抛异常形式告终;但还是有很多情况,API误用埋下的是长期隐患。
不是所有API误用情形最终都有机会发展成为可利用的安全漏洞,但作为一个由人的因素引入的风险,这将长期存在并困扰软件供应链(虽然对安全研究者、黑客与白帽子是很欣慰的事情)。可惜,传统的白盒代码扫描能力,基于对代码语义的理解和构建,但是涉及到API则需要预先的抽象,这一点目前似乎仍然是需要人工干预的事情;或者轻量级一点的方案,可以case by case地分析,为所有可能被误用的API建模并单独扫描,这自然也有很强局限性。在一个很底层可信的开发者还对C标准库API存在误用的现实内,我们需要更多的思考才能说接下来的解法。
Ⅴ. 从规则到陷阱:NASA JIRA误配置致信息泄露血案

软件的定义包括了代码组成的程序,以及相关的配置、文档等。当我们说软件的漏洞、风险时,往往只聚焦在其中的代码中;关于软件供应链安全风险,我们的比赛、前面分析的例子也都聚焦在了代码的问题;但是真正的威胁都来源于不可思议之处,那么代码之外有没有可能存在来源于上游的威胁呢?这里就借助实例来探讨一下,在“配置”当中可能栽倒的坑。
引子:发不到500英里以外的邮件?
让我们先从一个轻松愉快的小例子引入。这个例子初见于Linux中国的一篇译文。
简单说,作者描述了这么一个让人啼笑皆非的问题:单位的邮件服务器发送邮件,发送目标距离本地500英里范围之外的一律失败,邮件就像悠悠球一样只能飞出一定距离。这个问题本身让描述者感到尴尬,就像一个技术人员被老板问到“为什么从家里笔记本上Ctrl-C后不能在公司台式机上Ctrl-V”一样。
经过令人窒息的分析操作后,笔者定位到了问题原因:笔者作为负责的系统管理员,把SunOS默认安装的Senmail从老旧的版本5升级到了成熟的版本8,且对应于新版本诸多的新特性进行了对应配置,写入配置文件sendmail.cf;但第三方服务顾问在对单位系统进行打补丁升级维护时,将系统软件“升级”到了系统提供的最新版本,因此将Sendmail实际回退到了版本5,却为了软件行为一致性,原样保留了高版本使用的配置文件。但Sendmail并没有在大版本间保证配置文件兼容性,这导致很多版本5所需的配置项不存在于保留下来的sendmail.cf文件中,程序按默认值0处理;最终引起问题的就是,邮件服务器与接收端通信的超时时间配置项,当取默认配置值0时,邮件服务器在1个单位时间(约3毫秒)内没有收到网络回包即认为超时,而这3毫秒仅够电信号打来回飞出500英里。
这个“故事”可能会给技术人员一点警醒,错误的配置会导致预期之外的软件行为,但是配置如何会引入软件供应链方向的安全风险呢?这就引出了下一个重磅实例。
JIRA配置错误致NASA敏感信息泄露案例
我们都听过一个事情,马云在带队考察美国公司期间问Google CEO Larry Page自视谁为竞争对手,Larry的回答是NASA,因为最优秀的工程师都被NASA的梦想吸引过去了。由此我们显然能窥见NASA的技术水位之高,这样的人才团队大概至少是不会犯什么低级错误的。
但也许需要重新定义“低级错误”……1月11日一篇技术文章披露,NASA某官网部署使用的缺陷跟踪管理系统JIRA存在错误的配置,可分别泄漏内部员工(JIRA系统用户)的全部用户名和邮件地址,以及内部项目和团队名称到公众,如下:

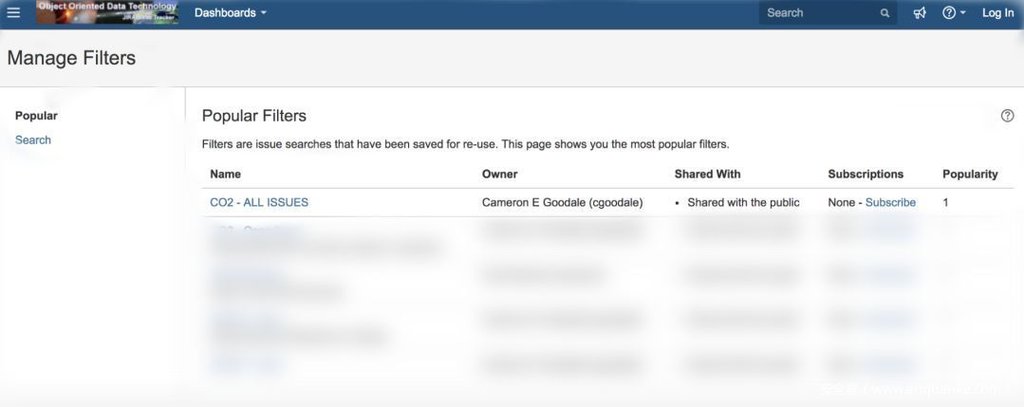
问题的原因解释起来也非常简单:JIRA系统的过滤器和配置面板中,对于数据可见性的配置选项分别选定为All users和Everyone时,系统管理人员想当然地认为这意味着将数据对所有“系统用户”开放查看,但是JIRA的这两个选项的真实效果逆天,是面向“任意人”开放,即不限于系统登录用户,而是任何查看页面的人员。看到这里,我不厚道地笑了……“All users”并不意味着“All ‘users’”,意不意外,惊不惊喜?
但是这种字面上把戏,为什么没有引起NASA工程师的注意呢,难道这样逆天的配置项没有在产品手册文档中加粗标红提示吗?本着为JIRA产品设计找回尊严的态度,我深入挖掘了一下官方说明,果然在Atlassian官方的一份confluence文档(看起来更像是一份增补的FAQ)中找到了相关说明:
所有未登录访客访问时,系统默认认定他们是匿名anonymous用户,所以各种权限配置中的all users或anyone显然应该将匿名用户包括在内。在7.2及之后版本中,则提供了“所有登录用户”的选项。
可以说是非常严谨且贴心了。比较讽刺的是,在我们的软件供应链安全大赛·C源代码赛季期间,我们设计圈定的恶意代码攻击目标还包括JIRA相关的敏感信息的窃取,但是却想不到有这么简单方便的方式,不动一行代码就可以从JIRA中偷走数据。
软件的使用,你“配”吗?
无论是开放的代码还是成型的产品,我们在使用外部软件的时候,都是处于软件供应链下游的消费者角色,为了要充分理解上游开发和产品的真实细节意图,需要我们付出多大的努力才够“资格”?
上一章节我们讨论过源码使用中必要细节信息缺失造成的“API误用”问题,而软件配置上的“误用”问题则复杂多样得多。从可控程度上讨论,至少有这几种因素定义了这个问题:
- 软件用户对必要配置的现有文档缺少了解。这是最简单的场景,但又是完全不可避免的,这一点上我们所有有开发、产品或运营角色经验的应该都曾经体会过向不管不顾用户答疑的痛苦,而所有软件使用者也可以反省一下对所有软件的使用是否都以完整细致的文档阅读作为上手的准备工作,所以不必多说。
- 软件拥有者对配置条目缺少必要明确说明文档。就JIRA的例子而言,将NASA工程师归为上一条错误有些冤枉,而将JIRA归为这条更加合适。在边角但重要问题上的说明通过社区而非官方文档形式发布是一种不负责任的做法,但未引发安全事件的情况下还有多少这样的问题被默默隐藏呢?我们没办法要求在使用软件之前所有用户将软件相关所有文档、社区问答实现全部覆盖。这个问题范围内一个代表性例子是对配置项的默认值以及对应效果的说明缺失。
- 配置文件版本兼容性带来的误配置和安全问题。实际上,上面的SunOS Sendmail案例足以点出这个问题的存在性,但是在真实场景下,很可能不会以这么戏剧性形式出现。在企业的系统运维中,系统的版本迭代常见,但为软件行为一致性,配置的跨版本迁移是不可避免的操作;而且软件的更新迭代也不只会由系统更新推动,还有大量出于业务性能要求而主动进行的定制化升级,对于中小企业基础设施建设似乎是一个没怎么被提及过的问题。
- 配置项组合冲突问题。尽管对于单个配置项可能明确行为与影响,但是特定的配置项搭配可能造成不可预知的效果。这完全有可能是由于开发者与用户在信息不对等的情况下产生:开发者认为用户应该具有必需的背景知识,做了用户应当具备规避配置冲突能力的假设。一个例子是,对称密码算法在使用ECB、CBC分组工作模式时,从密码算法上要求输入数据长度必须是分组大小的整倍数,但如果用户搭配配置了秘钥对数据不做补齐(nopadding),则引入了非确定性行为:如果密码算法库对这种组合配置按某种默认补齐方式操作数据则会引起歧义,但如果在算法库代码层面对这种组合抛出错误则直接影响业务。
- 程序对配置项处理过程的潜在暗箱操作。这区别于简单的未文档化配置项行为,仅特指可能存在的蓄意、恶意行为。从某种意义上,上述“All users”也可以认为是这样的一种陷阱,通过浅层次暗示,引导用户做出错误且可能引起问题的配置。另一种情况是特定配置组合情况下触发恶意代码的行为,这种触发条件将使恶意代码具有规避检测的能力,且在用户基数上具有一定概率的用户命中率。当然这种情况由官方开发者直接引入的可能性很低,但是在众包开发的情况下如果存在,那么扫描方案是很难检测的。
Ⅵ. 从逆流到暗流:恶意代码溯源后的挑战
如果说前面所说的种种威胁都是面向关键目标和核心系统应该思考的问题,那么最后要抛出一个会把所有人拉进赛场的理由。除了前面所有那些在软件供应链下游被动污染受害的情况,还有一种情形:你有迹可循的代码,也许在不经意间会“反哺”到黑色产业链甚至特殊武器中;而现在研究用于对程序进行分析和溯源的技术,则会让你陷入百口莫辩的境地。
案例:黑产代码模块溯源疑云
1月29日,猎豹安全团队发布技术分析通报文章《电信、百度客户端源码疑遭泄漏,驱魔家族窃取隐私再起波澜》,矛头直指黑产上游的恶意信息窃取代码模块,认定其代码与两方产品存在微妙的关联:中国电信旗下“桌面3D动态天气”等多款软件,以及百度旗下“百度杀毒”等软件(已不可访问)。
文章中举证有三个关键点。
首先最直观的,是三者使用了相同的特征字符串、私有文件路径、自定义内部数据字段格式;
其次,在关键代码位置,三者在二进制程序汇编代码层面具有高度相似性;
最终,在一定范围的非通用程序逻辑上,三者在经过反汇编后的代码语义上显示出明显的雷同,并提供了如下两图佐证(图片来源:http://bbs.duba.net/thread-23531362-1-1.html):

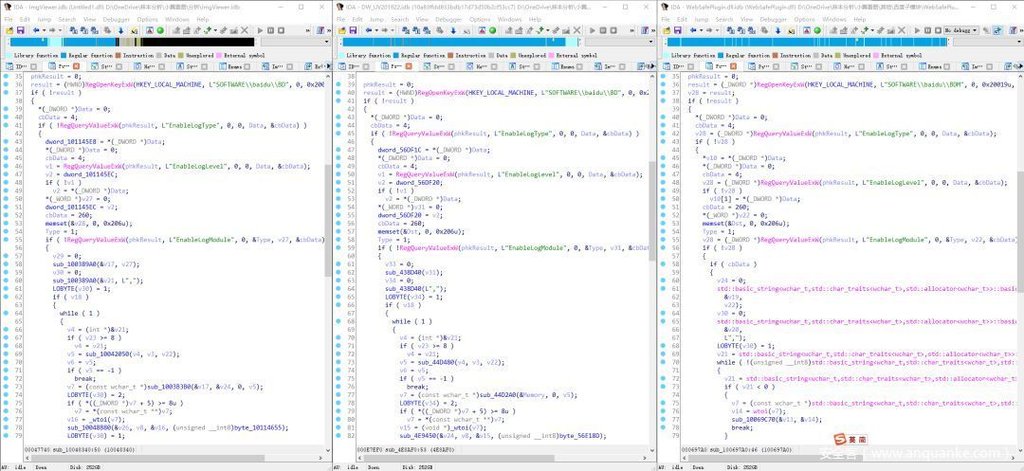
文章指出的涉事相关软件已经下线,对于上述样本文件的相似度试验暂不做复现,且无法求证存在相似、疑似同源的代码在三者中占比数据。对于上述指出的代码雷同现象,猎豹安全团队认为:
我们怀疑该病毒模块的作者通过某种渠道(比如“曾经就职”),掌握有中国电信旗下部分客户端/服务端源码,并加以改造用于制作窃取用户隐私的病毒,另外在该病毒模块的代码中,我们还发现“百度”旗下部分客户端的基础调试日志函数库代码痕迹,整个“驱魔”病毒家族疑点重重,其制作传播背景愈发扑朔迷离。
这样的推断,固然有过于直接的依据(例如三款代码中均使用含有“baidu”字样的特征注册表项);但更进一步地,需要注意到,三个样本在所指出的代码位置,具有直观可见的二进制汇编代码结构的相同,考虑到如果仅仅是恶意代码开发者先逆向另外两份代码后借鉴了代码逻辑,那么在面临反编译、代码上下文适配重构、跨编译器和选项的编译结果差异等诸多不确定环节,仍能保持二进制代码的雷同,似乎确实是只有从根本上的源代码泄漏(抄袭)且保持相同的开发编译环境才能成立。
但是我们却又无法做出更明确的推断。这一方面当然是出于严谨避免过度解读;而从另一方面考虑,黑产代码的一个关键出发点就是“隐藏自己”,而这里居然如此堂而皇之地照搬了代码,不但没有进行任何代码混淆、变形,甚至没有抹除疑似来源的关键字符串,如果将黑产视为智商在线的对手,那这里背后是否有其它考量,就值得琢磨了。
代码的比对、分析、溯源技术水准
上文中的安全团队基于大量样本和粗粒度比对方法,给出了一个初步的判断和疑点。那么是否有可能获得更确凿的分析结果,来证实或证伪同源猜想呢?
无论是源代码还是二进制,代码比对技术作为一种基础手段,在软件供应链安全分析上都注定仍然有效。在我们的软件供应链安全大赛期间,针对PE二进制程序类型的题目,参赛队伍就纷纷采用了相关技术手段用于目标分析,包括:同源性分析,用于判定与目标软件相似度最高的同软件官方版本;细粒度的差异分析,用于尝试在忽略编译差异和特意引入的混淆之外,定位特意引入的恶意代码位置。当然,作为比赛中针对性的应对方案,受目标和环境引导约束,这些方法证明了可行性,却难以保证集成有最新技术方案。那么做一下预言,在不计入情报辅助条件下,下一代的代码比对将能够到达什么水准?
这里结合近一年和今年内,已发表和未发表的学术领域顶级会议的相关文章来简单展望:
- 针对海量甚至全量已知源码,将可以实现准确精细化的“作者归属”判定。在ACM CCS‘18会议上曾发表的一篇文章《Large-Scale and Language-Oblivious Code Authorship Identification》,描述了使用RNN进行大规模代码识别的方案,在圈定目标开发者,并预先提供每个开发者的5-7份已知的代码文件后,该技术方案可以很有效地识别大规模匿名代码仓库中隶属于每个开发者的代码:针对1600个Google Code Jam开发者8年间的所有代码可以实现96%的成功识别率,而针对745个C代码开发者于1987年之后在GitHub上面的全部公开代码仓库,识别率也高达94.38%。这样的结果在当下的场景中,已经足以实现对特定人的代码识别和跟踪(例如,考虑到特定开发人员可能由于编码习惯和规范意识,在时间和项目跨度上犯同样的错误);可以预见,在该技术方向上,完全可以期望摆脱特定已知目标人的现有数据集学习的过程,并实现更细粒度的归属分析,例如代码段、代码行、提交历史。
- 针对二进制代码,更准确、更大规模、更快速的代码主程序分析和同源性匹配。近年来作为一项程序分析基础技术研究,二进制代码相似性分析又重新获得了学术界和工业界的关注。在2018年和2019(已录用)的安全领域四大顶级会议上,每次都会有该方向最新成果的展示,如S&P‘2019上录用的《Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization》,实现无先验知识的条件下的最优汇编代码级别克隆检测,针对漏洞库的漏洞代码检测可实现0误报、100%召回。而2018年北京HITB会议上,Google Project Zero成员、二进制比对工具BinDiff原始作者Thomas Dullien,探讨了他借用改造Google自家SimHash算法思想,用于针对二进制代码控制流图做相似性检测的尝试和阶段结果;这种引入规模数据处理的思路,也可期望能够在目前其他技术方案大多精细化而低效的情况下,为高效、快速、大规模甚至全量代码克隆检测勾出未来方案。
- 代码比对方案对编辑、优化、变形、混淆的对抗。近年所有技术方案都以对代码“变种”的检测有效性作为关键衡量标准,并一定程度上予以保证。上文CCS‘18论文工作,针对典型源代码混淆(如Tigress)处理后的代码,大规模数据集上可有93.42%的准确识别率;S&P‘19论文针对跨编译器和编译选项、业界常用的OLLVM编译时混淆方案进行试验,在全部可用的混淆方案保护之下的代码仍然可以完成81%以上的克隆检测。值得注意的是以上方案都并非针对特定混淆方案单独优化的,方法具有通用价值;而除此以外还有很多针对性的的反混淆研究成果可用;因此,可以认为在采用常规商用代码混淆方案下,即便存在隐藏内部业务逻辑不被逆向的能力,但仍然可以被有效定位代码复用和开发者自然人。
代码溯源技术面前的“挑战”
作为软件供应链安全的独立分析方,健壮的代码比对技术是决定性的基石;而当脑洞大开,考虑到行业的发展,也许以下两种假设的情景,将把每一个“正当”的产品、开发者置于尴尬的境地。
代码仿制
在本章节引述的“驱魔家族”代码疑云案例中,黑产方面通过某种方式获得了正常代码中,功能逻辑可以被自身复用的片段,并以某种方法将其在保持原样的情况下拼接形成了恶意程序。即便在此例中并非如此,但这却暴露了隐忧:将来是不是有这种可能,我的正常代码被泄漏或逆向后出现在恶意软件中,被溯源后扣上黑锅?
这种担忧可能以多种渠道和形式成为现实。
从上游看,内部源码被人为泄漏是最简单的形式(实际上,考虑到代码的完整生命周期似乎并没有作为企业核心数据资产得到保护,目前实质上有没有这样的代码在野泄漏还是个未知数),而通过程序逆向还原代码逻辑也在一定程度上可获取原始代码关键特征。
从下游看,则可能有多种方式将恶意代码伪造得像正常代码并实现“碰瓷”。最简单地,可以大量复用关键代码特征(如字符串,自定义数据结构,关键分支条件,数据记录和交换私有格式等)。考虑到在进行溯源时,分析者实际上不需要100%的匹配度才会怀疑,因此仅仅是仿造原始程序对于第三方公开库代码的特殊定制改动,也足以将公众的疑点转移。而近年来类似自动补丁代码搜索生成的方案也可能被用来在一份最终代码中包含有二方甚至多方原始代码的特征和片段。
基于开发者溯源的定点渗透
既然在未来可能存在准确将代码与自然人对应的技术,那么这种技术也完全可能被黑色产业利用。可能的忧患包括强针对性的社会工程,结合特定开发者历史代码缺陷的漏洞挖掘利用,联动第三方泄漏人员信息的深层渗透,等等。这方面暂不做联想展开。
〇. 没有总结
作为一场旨在定义“软件供应链安全”威胁的宣言,阿里安全“功守道”大赛将在后续给出详细的分解和总结,其意义价值也许会在一段时间之后才能被挖掘。
但是威胁的现状不容乐观,威胁的发展不会静待;这一篇随笔仅仅挑选六个侧面做摘录分析,可即将到来的趋势一定只会进入更加发散的境地,因此这里,没有总结。







发表评论
您还未登录,请先登录。
登录