

前言
本系列的第一部分介绍了Semmle QL,以及Microsoft安全响应中心(MSRC)如何使用它来审核向我们报告的漏洞。这篇文章讨论了一个我们如何主动使用它的例子,包括Azure固件组件的安全审计。
这是Azure服务深度安全审查的更广泛防御的一部分,从假设对手的角度探索攻击向量,该对手已经渗透了至少一个安全边界,现在位于服务后端的操作环境中(在下图中用*标记)。

本次审查的目标之一是基于Linux的嵌入式设备,它与服务后端和管理后端相连接,在两者之间传递操作数据。该设备的主要攻击面是两个接口上使用的管理协议。
对其固件的初步手动审查表明,该管理协议是基于消息的,有400多种不同的消息类型,每种类型都有自己的处理程序功能。手动审计每一个函数都是乏味且容易出错的,所以使用Semmle来扩展我们的代码审查能力是一个简单的选择。我们使用本文中讨论的静态分析技术,总共发现了33个易受攻击的消息处理函数。
定义攻击面
我们的第一步是编写一些QL来模拟来自攻击者的数据。管理协议以请求-响应为基础工作,其中每个消息请求类型都用类别号和命令号来标识。这是在源代码中使用如下结构数组定义的,例如:
MessageCategoryTable g_MessageCategoryTable[] =
{
{ CMD_CATEGORY_BASE, g_CommandHandlers_Base },
{ CMD_CATEGORY_APP0, g_CommandHandlers_App0 },
…
{ NULL, NULL }
};
CommandHandlerTable g_CommandHandlers_Base [] =
{
{ CMD_GET_COMPONENT_VER, sizeof(ComponentVerReq), GetComponentVer, … },
{ CMD_GET_GLOBAL_CONFIG, -1, GetGlobalConfig, … },
…
{ NULL, NULL, NULL, … }
};
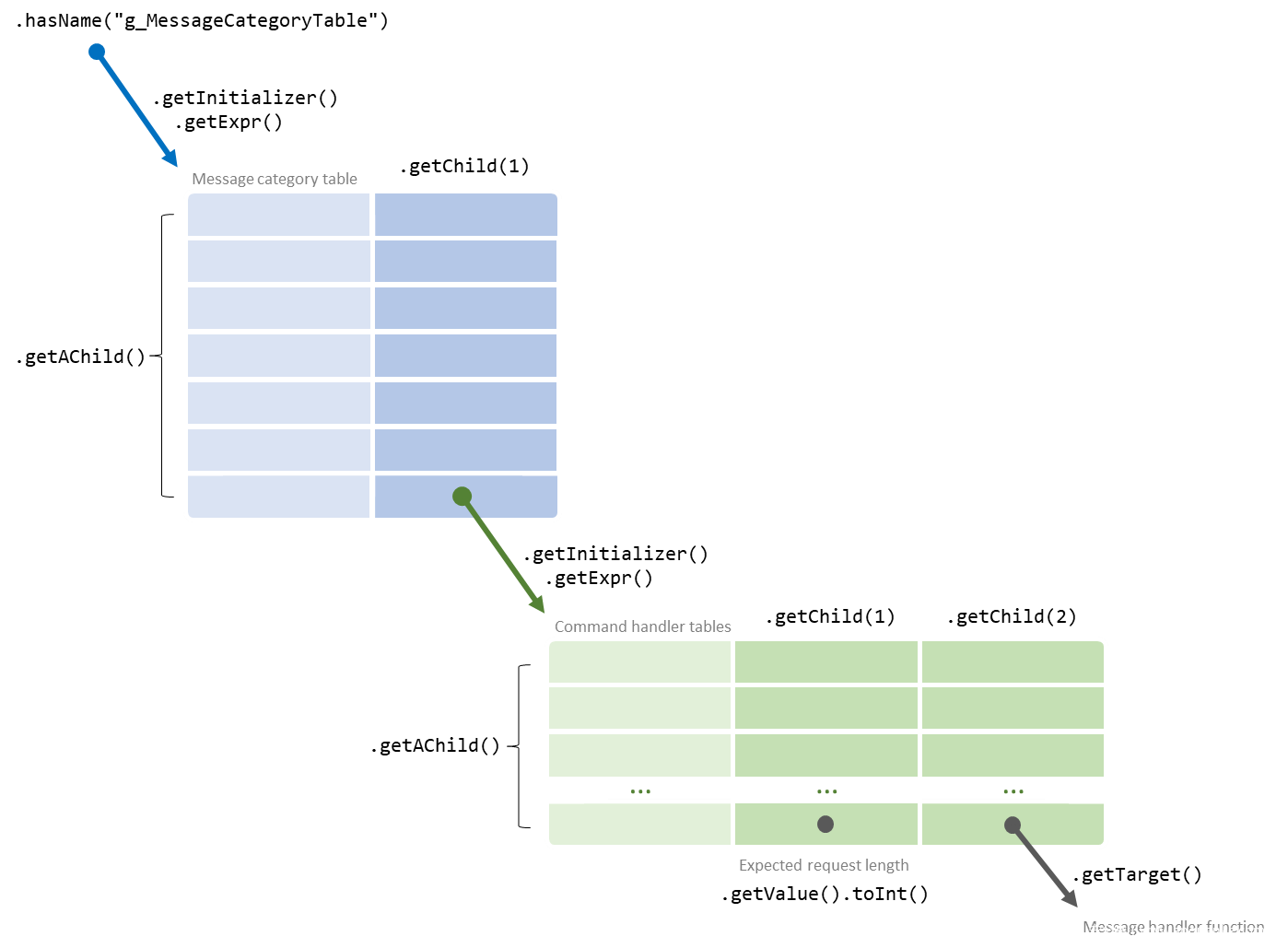
在上面的示例中,类别类型为CMD_CATEGORY_BASE、命令类型为CMD_GET_COMPONENT_VER的消息将被路由到GetComponentVer函数。命令处理程序表具有关于请求消息的预期大小的信息,该信息在调用处理函数之前在消息调度例程中得到验证。
我们使用以下QL定义了消息处理程序表:
class CommandHandlerTable extends Variable {
CommandHandlerTable() {
exists(Variable v | v.hasName("g_MessageCategoryTable")
and this.getAnAccess() = v.getInitializer().getExpr().getAChild().getChild(1)
)
}
}
这需要一个名为g_MessageCategoryTable的变量,找到它的初始化表达式,并匹配该表达式的所有子表达式——每个子表达式对应于消息类别表的一行。对于每一行,它采用第二列(这是getChild(1),因为getChild的参数是零索引的),每一列都是对命令处理程序表的引用,并匹配引用的变量。在上面的例子中,它们是g_CommandHandlers_Base和g_CommandHandlers_App0。
我们使用类似的方法定义了消息处理函数集:
class MessageHandlerFunction extends Function {
Expr tableEntry;
MessageHandlerFunction() {
exists(CommandHandlerTable table |
tableEntry = table.getInitializer().getExpr().getAChild()
)
and this = tableEntry.getChild(2).(FunctionAccess).getTarget()
}
int getExpectedRequestLength() {
result = tableEntry.getChild(1).getValue().toInt()
}
…
}
这个QL类使用成员变量tableEntry来保存所有命令处理程序表中所有行的集合。这就是为什么它可以在(messageHandlerffunction ( ) {…} )和getExpectedRequestLength ( )中引用,而无需重复定义。
所有这些都映射到上面的代码结构,如下所示:
每个消息处理函数都有相同的签名:
typedef unsigned char UINT8;
int ExampleMessageHandler(UINT8 *pRequest, int RequestLength, UINT8 *pResponse);
并遵循一种通用模式,其中请求数据被转换为表示消息布局的结构类型,并通过其字段进行访问:
int ExampleMessageHandler(UINT8 *pRequest, int RequestLength, UINT8 *pResponse)
{
ExampleMessageRequest* pMsgReq = (ExampleMessageRequest *)pRequest;
…
someFunction(pMsgReq->aaa.bbb)
…
}
在这个分析中,我们只对请求数据感兴趣。我们在MessageHandlerFunction QL类中定义了两个额外的谓词来对请求数据及其长度进行建模:
class MessageHandlerFunction extends Function {
Expr tableEntry;
…
Parameter getRequestDataPointer() {
result = this.getParameter(0)
}
Parameter getRequestLength() {
result = this.getParameter(1)
}
}
抽象出消息处理函数的定义,它可以像任何其他QL类一样使用。例如,该查询按照循环复杂性的降序列出了所有消息处理程序函数:
from MessageHandlerFunction mhf
select
mhf,
mhf.getADeclarationEntry().getCyclomaticComplexity() as cc
order by cc desc
分析数据流
既然我们已经为不可信数据定义了一组入口点,下一步就是找到它可能以不安全的方式被使用的地方。为此,我们需要通过代码库跟踪这些数据流。QL提供了一个强大的全局数据流库,它抽象出了大部分复杂的语言细节。
DataFlow 库通过以下方式被纳入查询范围:
import semmle.code.cpp.dataflow.DataFlow
它通过子类化 DataFlow::Configuration 和覆盖谓词来定义数据流,就像它应用于 DataFlow::Node一样,这是一个QL类,表示数据可以流过的任何程序假象:
| 配置谓词 | 描述 |
|---|---|
isSource(source) |
数据必须来自 source |
isSink(sink) |
数据必须流入 sink |
isAdditionalFlowStep(node1, node2) |
数据也可以在node1和node2之间流动 |
isBarrier(node) |
数据无法通过 node流动 |
大多数数据流查询将如下所示:
class RequestDataFlowConfiguration extends DataFlow::Configuration {
RequestDataFlowConfiguration() { this = "RequestDataFlowConfiguration" }
override predicate isSource(DataFlow::Node source) {
…
}
override predicate isSink(DataFlow::Node sink) {
…
}
override predicate isAdditionalFlowStep(DataFlow::Node node1, DataFlow::Node node2) {
…
}
override predicate isBarrier(DataFlow::Node node) {
…
}
}
from DataFlow::Node source, DataFlow::Node sink
where any(RequestDataFlowConfiguration c).hasFlow(source, sink)
select
"Data flow from $@ to $@",
source, sink
请注意,QL数据流库执行过程间分析——除了检查函数本地的数据流,它还将包括通过函数调用参数的数据。这是我们安全审查的一个基本特性,因为尽管下面讨论的易受攻击的代码模式在简单的示例函数中显示以便于演示,但是在我们目标的实际源代码中,大多数结果都有跨越多个复杂函数的数据流。
发现内存安全漏洞
由于这个固件组件是纯C代码库,我们首先决定搜索与内存安全相关的代码模式。
这种错误的一个常见来源是不执行边界检查的数组索引。单独搜索这种模式将提供很大一部分结果,这些结果很可能不是安全漏洞,因为我们真正感兴趣的是攻击者对索引值的控制。因此,在这种情况下,我们在寻找数据流,其中接收器是数组索引表达式,源是消息处理函数的请求数据,并且任何数据流节点都有一个由相关边界检查保护的屏障。
例如,我们想要找到匹配代码的数据流,如下所示:
int ExampleMessageHandler(UINT8 *pRequest(1:source), int RequestLength, UINT8 *pResponse)
{
ExampleMessageRequest* pMsgReq(3) = (ExampleMessageRequest *) pRequest(2);
int index1(6) = pMsgReq(4)->index1(5);
pTable1[index1(7:sink)].field1 = pMsgReq->value1;
}
但我们也希望排除代码的数据流,如下所示:
int ExampleMessageHandler(UINT8 *pRequest(1:source), int RequestLength, UINT8 *pResponse)
{
ExampleMessageRequest* pMsgReq(3) = (ExampleMessageRequest *) pRequest(2);
int index2(6) = pMsgReq(4)->index2(5);
if (index2 >= 0 && index2 < PTABLE_SIZE)
{
pTable2[index2].field1 = pMsgReq->value2;
}
}
源是使用前面讨论的MessageHandlerFunction类定义的,我们可以使用ArrayExpr的getArrayOffset谓词来定义合适的接收器:
override predicate isSource(DataFlow::Node source) {
any(MessageHandlerFunction mhf).getRequestDataPointer() = source.asParameter()
}
override predicate isSink(DataFlow::Node sink) {
exists(ArrayExpr ae | ae.getArrayOffset() = sink.asExpr())
}
默认情况下,数据流库只包括在每个节点保留值的流,如函数调用参数、赋值表达式等。但是我们也需要数据从请求数据指针流向它被转换到的结构的字段。我们将这样做:
override predicate isAdditionalFlowStep(DataFlow::Node node1, DataFlow::Node node2)
{
// any terminal field access on request packet
// e.g. in expression a->b.c the data flows from a to c
exists(Expr e, FieldAccess fa |
node1.asExpr() = e and node2.asExpr() = fa |
fa.getQualifier*() = e and not (fa.getParent() instanceof FieldAccess)
)
}
要使用边界检查排除流,我们在控制流图中较早的某些条件语句中使用变量或字段的任何节点上放置一个屏障(目前,我们假设任何这样的边界检查都是正确完成的):
override predicate isBarrier(DataFlow::Node node) {
exists(ConditionalStmt condstmt |
// dataflow node variable is used in expression of conditional statement
// this includes fields (because FieldAccess extends VariableAccess)
node.asExpr().(VariableAccess).getTarget().getAnAccess()
= condstmt.getControllingExpr().getAChild*()
// and that statement precedes the dataflow node in the control flow graph
and condstmt.getASuccessor+() = node.asExpr()
// and the dataflow node itself not part of the conditional statement expression
and not (node.asExpr() = cs.getControllingExpr().getAChild*())
)
}
将此应用于以上两个示例,通过每个节点的数据流将是:
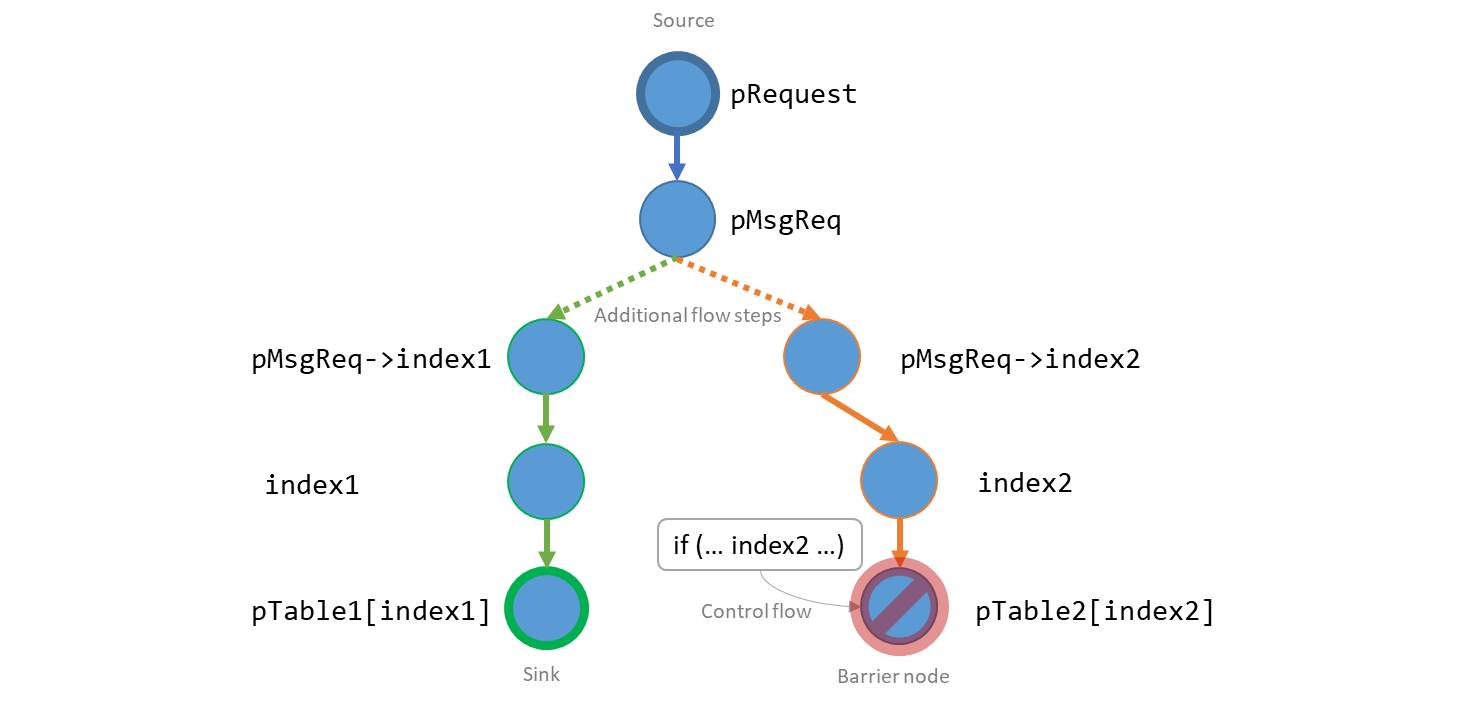
在我们的固件代码库中,此查询在15个消息处理程序函数中共定位了18个漏洞,这是攻击者控制的越界读写的混合。
我们应用了类似的分析来查找函数调用的参数,而不首先验证消息请求数据。首先,我们定义了一个QL类来定义感兴趣的函数调用和参数,包括调用memcpy的大小参数和类似的函数_fmemcpy,以及CalculateChecksum的长度参数。alculateChecksum是一个特定于此代码库的函数,它将返回缓冲区的CRC32,并且可能被用作信息公开原语,消息处理函数将这个值复制到它的响应缓冲区中。
class ArgumentMustBeCheckedFunctionCall extends FunctionCall {
int argToCheck;
ArgumentMustBeCheckedFunctionCall() {
( this.getTarget().hasName("memcpy") and argToCheck = 2 ) or
( this.getTarget().hasName("_fmemcpy") and argToCheck = 2 ) or
( this.getTarget().hasName("CalculateChecksum") and argToCheck = 1 )
}
Expr getArgumentToCheck() { result = this.getArgument(argToCheck) }
}
接下来,我们修改了上一个查询的接收器,以匹配argumentMustBecheckedFunctioncall而不是数组索引:
override predicate isSink(DataFlow::Node sink) {
// sink node is an argument to a function call that must be checked first
exists (ArgumentMustBeCheckedFunctionCall fc |
fc.getArgumentToCheck() = sink.asExpr())
}
该查询揭示了13个消息处理程序中的另外17个漏洞,大部分是攻击者控制的越界读取(我们后来确认在响应消息中披露了这一点),其中一个是越界写入。
污点跟踪
在上面的查询中,我们重写了DataFlow库的isAdditionalFlowStep谓词,以确保当数据流向一个结构指针时,该结构的字段将作为节点添加到数据流图中。我们这样做是因为默认情况下,数据流分析仅包括数据值未经修改的路径,但我们希望跟踪它可能也受影响的特定表达式集。也就是说,我们定义了一组被不受信任的数据污染的特定表达式。
QL包含一个内置库,可以应用更通用的方法来进行污点跟踪。它在DataFlow库之上开发,会覆盖isAdditionalFlowStep,并为值修改表达式提供更丰富的规则集。这是TaintTracking库,它以类似于DataFlow的方式导入:
import semmle.code.cpp.dataflow.TaintTracking
它的使用方式与数据流库几乎相同,只是要扩展的QL类是TaintTracking :: Configuration,配置谓词如下:
| 配置谓词 | 描述 |
|---|---|
isSource(source) |
数据必须来自source |
isSink(sink) |
数据必须流入sink |
isAdditionalTaintStep(node1, node2) |
node1上的数据也会污染node2 |
isSanitizer(node) |
数据无法通过node流动 |
我们重新运行了先前的查询,删除了isAdditionalFlowStep(因为我们不再需要定义它)并且将isBarrier重命名为isSanitizer。正如预期的那样,它返回了上面提到的所有结果,但也在数组索引中发现了一些额外的整数下溢缺陷。例如:
int ExampleMessageHandler(UINT8 * pRequest (1:source), int RequestLength,UINT8 * pResponse)
{
ExampleMessageRequest * pMsgReq (3) =(ExampleMessageRequest *)pRequest (2) ;
int index1 (6) = pMsgReq (4) - > index1 (5) ;
pTable1 [ ( index1 (7) - 2 )(8:sink) ]。field1 = pMsgReq-> value1;
}
对于每种漏洞类型的内部报告,我们希望将它们与之前的查询结果分开进行分类。这包括使用SubExpr QL类对接收器进行简单修改:
override predicate isSink(DataFlow::Node sink) {
// this sink is the left operand of a subtraction expression,
// 是数组偏移表达式的一部分,例如[x - 1]中的x
exists(ArrayExpr ae, SubExpr s | sink.asExpr() instanceof FieldAccess
and ae.getArrayOffset().getAChild*() = s
and s.getLeftOperand().getAChild*() = sink.asExpr())
}
使我们在2个消息处理函数中增加了3个漏洞。
查找路径遍历漏洞
为了找到潜在的路径遍历漏洞,我们使用QL来尝试识别在文件打开函数中使用攻击者控制的文件名的消息处理函数。
这次,我们使用了一种稍微不同的方法来跟踪污点,定义了一些额外的污点步骤,这些步骤将流经各种字符串处理的C库函数:
predicate isTaintedString(Expr expSrc, Expr expDest) {
exists(FunctionCall fc, Function f |
expSrc = fc.getArgument(1) and
expDest = fc.getArgument(0) and
f = fc.getTarget() and (
f.hasName("memcpy") or
f.hasName("_fmemcpy") or
f.hasName("memmove") or
f.hasName("strcpy") or
f.hasName("strncpy") or
f.hasName("strcat") or
f.hasName("strncat")
)
)
or exists(FunctionCall fc, Function f, int n |
expSrc = fc.getArgument(n) and
expDest = fc.getArgument(0) and
f = fc.getTarget() and (
(f.hasName("sprintf") and n >= 1) or
(f.hasName("snprintf") and n >= 2)
)
)
}
…
override predicate isAdditionalTaintStep(DataFlow::Node node1, DataFlow::Node node2) {
isTaintedString(node1.asExpr(), node2.asExpr())
}
并将接收器定义为文件打开函数的路径参数:
class FileOpenFunction extends Function {
FileOpenFunction() {
this.hasName("fopen") or this.hasName("open")
}
int getPathParameter() { result = 0 } // filename parameter index
}
…
override predicate isSink(DataFlow::Node sink) {
exists(FunctionCall fc, FileOpenFunction fof |
fc.getTarget() = fof and fc.getArgument(fof.getPathParameter()) = sink.asExpr())
}
通过对我们的目标设备如何工作的一些预先了解,从最初的回顾中观察到,在我们解决下一个排除数据验证流程的问题之前,我们预计至少会有一些结果,就像之前的查询一样。但是,查询根本没有返回任何内容。
由于没有要检查的数据流路径,我们回过头来查询函数调用图,以搜索消息处理函数和调用文件打开函数之间的任何路径,不包括path参数为常量的调用:
// this recursive predicate defines a function call graph
predicate mayCallFunction(Function caller, FunctionCall fc) {
fc.getEnclosingFunction() = caller or mayCallFunction(fc.getTarget(), fc)
}
from MessageHandlerFunction mhf, FunctionCall fc, FileOpenFunction fof
where mayCallFunction(mhf, fc)
and fc.getTarget() = fof
and not fc.getArgument(fof.getPathParameter()).isConstant()
select
mhf, "$@ may have a path to $@",
mhf, mhf.toString(),
fc, fc.toString()
该查询提供了5个结果——足够少,可以手动检查——由此我们发现了2个路径遍历漏洞,一个写入文件,另一个读取文件,这两个漏洞都是攻击者提供的路径。事实证明,污点跟踪没有标记这些,因为它需要发送两种不同的消息类型:第一种是设置文件名,第二个读取或写入具有该名称的文件的数据。幸运的是,QL足够灵活,可以提供另一种探索途径。
结论
在微软,我们采取深度防御的方法来保护云和客户数据的安全。其中一个重要部分是对Azure内部攻击面进行全面的安全审查。在这个嵌入式设备的源代码回顾中,我们应用了Semmle QL的高级静态分析技术来发现基于消息的管理协议中的漏洞。这在各种bug类中发现了总共33个易受攻击的消息处理程序。使用QL使我们能够自动执行完全手动代码审查的重复部分,同时仍然应用探索性方法。
附:Part1在去年发布的,已经有过他人翻译:
使用Semmle QL进行漏洞探索 Part1: https://xz.aliyun.com/t/2641 (翻译:@Stefano )







发表评论
您还未登录,请先登录。
登录