

0x00 前言
学习pwn绕不开Linux的堆,找到了有人翻译的shellphish团队在Github上开源的堆漏洞教程。
里面有github地址以及《Glibc内存管理-Ptmalloc2源码分析》的地址,我就不贴了,另外安利一本《程序员的自我修养》
本文是我在学习how2heap遇到的一些坑,做了一些整理,最主要的是因为glibc-2.26之后引入了tcache机制,导致刚开始学习时,发现运行结果和说好的不一样,N脸懵逼。
0x01 准备工作
how2heap的代码要使用不同的版本glibc进行实验,因此提供了glibc_run.sh,使用方法
glibc_run.sh <version> <code>
栗子:
glibc_run.sh 2.25 ./glibc_2.25/unsafe_unlink
不过由于还要使用gdb调试,就不能依赖glibc_run.sh脚本了,看下脚本执行的内容,栗子执行的命令就是LD_PRELOAD="./glibc_versions/libc-2.25.so" ./glibc_versions/ld-2.25.so ./glibc_2.25/unsafe_unlink
使用不同的libc可以通过环境变量LD_PRELOAD解决,在gdb中可以通过命令set exec-wrapper env "LD_PRELOAD=./libc-2.25.so"解决,现在就剩下链接器了,在看雪上看到有人分享了Python脚本修改程序使用的ld
0x02 tcache
这里只是初步展示下tcache,一个长度为64的链表数组,每个链表的长度最大是7,链表类似于fastbin,通过fd连起来,不过fastbin中fd指针是指向下一个chunk的首地址,而tcache是指向下一个chunk的fd的地址。
这里以64位为例,tcache是个结构体,里面有count数组和指针数组,长度都是64,根据下标一一对应,结构体的声明是参考的:https://www.anquanke.com/post/id/104760
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
static __thread tcache_perthread_struct *tcache = NULL;
数组长度是64,存储的chunk大小是从32~1040字节,递增16字节,所以是数组下标从0开始,那么对应chunk大小就是(下标+2)*16
这个缓存链表类似于fastbin,每组链表节点长度为7,对应chunk释放后加入链表时,对应的in_use状态不变(状态位在内存相邻的下一个chunksizi字段上),因此内存地址上连续的两个chunk都释放了,也是不会合并的。
链表是通过fd指针相连的,fd也是指向另一个chunk的fd指针的地址,顺序是先进后出。
进行两个实验,实验一是为了证明数组大小,对应的chunk范围以及chunk是先进后出,实验二是为了证明链表长度最大是7。
实验一:
chunk大小范围是32-1040
因此申请的最小chunk设为16,最大chunk设为1024
a[0]=malloc(16)
a[1]=malloc(16)
a[2]=malloc(1024)
再按顺序释放a[0]、a[2]、a[1],然后再申请一次a[3]=malloc(16)
申请过3个内存之后的heap
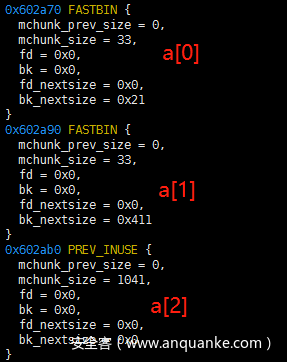
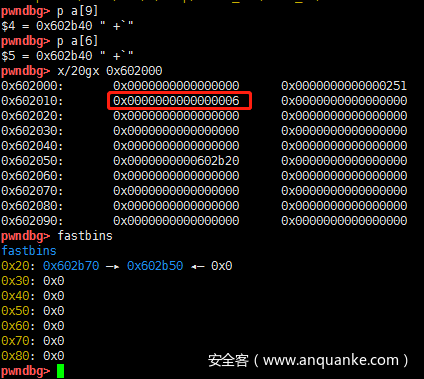
现在释放a[0]和a[2],tcache也是申请的一块堆内存上存放的,因此查看申请的第一块内存的数据,tcache的chunk是从0x602000开始的,前16字节是chunk头,之后的64字节是count数组,用来记录对应下标链表的个数,之后的每8个字节是一个链表,总体是链表数组,长度是64。count数组的最低位和最高位分别记数了1,链表里存放的是a[0]和a[2]的fd指针的地址。
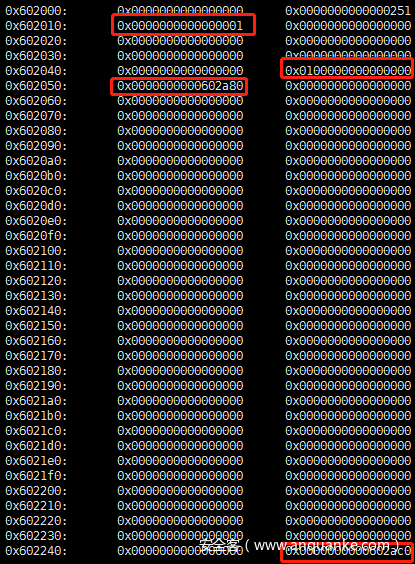
现在再释放a[1],tcache链表数组的第一个链表会指向a[1]的fd指针,也就是0x6020a0,而a[1]的fd存储的是a[0]的fd地址,并且count数组对应的值会变为2(对应count数组中的下标为0)
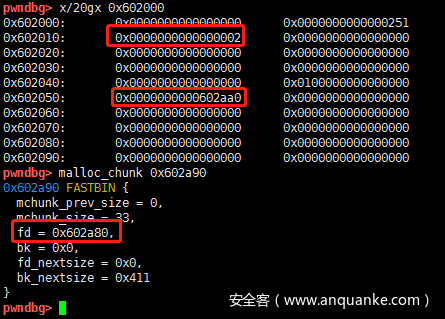
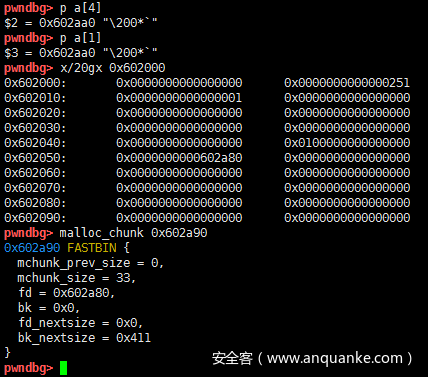
之后再去申请16字节的内存,那么会从tcahce中获取,按照FILO的原则,a[1]对应的chunk会先被选中,因此a[4]与a[1]的值是一样的
实验二:
申请a[0]~a[8]一共9个chunk,依次释放,会发现前7个在tcache中,后两个会在fastbin上。
先释放a[0]~a[6]
查看tcache,现在链表长度是7,fastbins中没有chunk
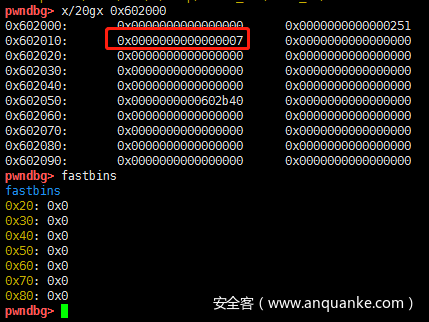
现在继续释放a[7],tcache是没有变化的,a[7]进入fastbins
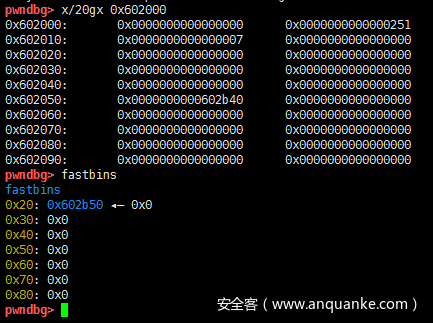
继续释放a[8],a[8]也加入了fastbins中
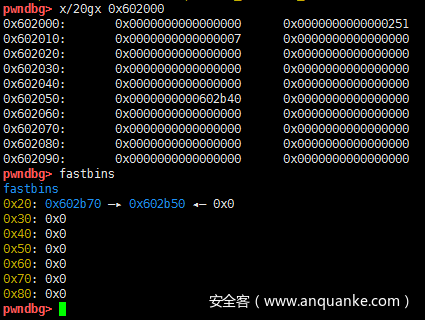
接着看下a[7],a[8]的fd是指向的chunk头还是fd
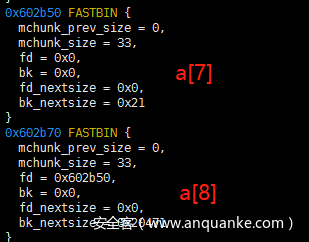
fastbins中的单链表还是指向的chunk头地址。
最后再申请一个16字节内存,应该是从tcahce中获取
0x03 first_fit
由于how2heap的源代码内还有说明,为了调试看的简单点,做了一些删减
/*first_fit.c*/
#include<stdlib.h>
#include<string.h>
int main()
{
char *a = malloc(512);
char *b = malloc(256);
char *c;
printf("1st malloc(512) %pn",a);
printf("2nd malloc(256) %pn",b);
strcpy(a,"this is A!");
free(a);
printf("free an");
c = malloc(500);
printf("3rd malloc(500) %pn",c);
strcpy(c,"this is C!");
printf("copy string 'this is c' to cn");
printf("c(%p):%sn",c,c);
printf("a(%p):%sn",a,a);
return 0;
}
编译:gcc -g -no-pie -o first_fit first_fit.c,加入源码信息,关闭PIE。
使用不同版本glibc,通过chaneld脚本修改程序使用的ld,这些是实验前的准备工作,之后不提了。
first_fit是先申请了a,b两块内存,b是为了防止a释放后被top chunk合并,释放了a之后,再去申请c,c的大小小于a,那么c对应内存的首地址与a的一致,如果a存在UAF漏洞,就可以做一些事了(我不知道是什么事),在glibc-2.26之前,a的大小已经是大于fastbin了,所以释放后是进入unsorted bin,那么在申请c的时候,会将a的chunk做切割,然后分配给c,因此c与a的首地址相同,而在glibc-2.26的版本中,a是进入了tcache,只有chunk大小完全匹配,才会将a分配给c。
0x04 fastbin_dup
删减过的代码
#include <stdio.h>
#include <stdlib.h>
int main()
{
int *a = malloc(0x20);
int *b = malloc(0x20);
int *c = malloc(0x20);
fprintf(stderr, "1st malloc(8): %pn", a);
fprintf(stderr, "2nd malloc(8): %pn", b);
fprintf(stderr, "3rd malloc(8): %pn", c);
free(a);
free(b);
free(a);
fprintf(stderr, "1st malloc(0x20): %pn", malloc(0x20));
fprintf(stderr, "2nd malloc(0x20): %pn", malloc(0x20));
fprintf(stderr, "3rd malloc(0x20): %pn", malloc(0x20));
}
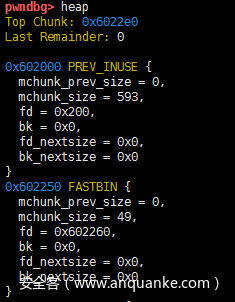
实验是将同一个chunk释放两次,对于fastbin不能连续调用两次free(a),因为会检测当前链表头部的chunk与释放的chunk是否为同一个,而在glibc-2.26版本中,只是进入了tcache中,没有多大区别。
但是现在可以把free(b)这一句删除,在glibc-2.26之前的版本,会触发检测到double free的错误

在tcache中则没有检测了,可以将同一块内存同时释放两次。
代码执行效果
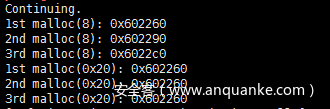
a对应chunk(0x602250)中fd指针是指向自己的地址的
0x05 fastbin_dup_into_stack
修改过的源码
#include <stdio.h>
#include <stdlib.h>
int main()
{
unsigned long long stack_var;
fprintf(stderr, "The address we want malloc() to return is %p.n", 8+(char *)&stack_var);
int *a = malloc(8);
int *b = malloc(8);
int *c = malloc(8);
free(a);
// free(b);//glibc-2.26版本不需要在free(b)了
free(a);
unsigned long long *d = malloc(8);
fprintf(stderr, "1st malloc(8): %pn", d);
fprintf(stderr, "2nd malloc(8): %pn", malloc(8));//这一句glibc-2.26中也可以删除的,不删除也无所谓,不修改fd指针之前,是循环返回a的地址。
// stack_var = 0x20; //glibc-2.26版本不需要满足size字段在对应范围内
*d = (unsigned long long) (((char*)&stack_var) + sizeof(d)); //2.26版本之后这里是+,2.25版本是-,因为stack_var变量是伪造chunk的size字段,2.26中fd指向的是另一个chunk的fd,所以是size字段+8,而2.25是指向chunk头,所以是size字段-8
fprintf(stderr, "3rd malloc(8): %p, putting the stack address on the free listn", malloc(8));
fprintf(stderr, "4th malloc(8): %pn", malloc(8));
}
这个算是上一个的延续,通过将一个内存块释放两次,那么申请一个出来,就可以修改其fd指针了,控制之后申请返回的地址为任意地址,fastbin的话还需要满足地址+8(也就是size字段)处的值是在对应fastbin范围内,比如栗子中fastbin的大小是0x20,那么指定的其他地址处,size字段值应该是0x20~0x2f。但是对于tcache来说就简单多了,没有double free检测,没有size字段的检测。
gdb调试
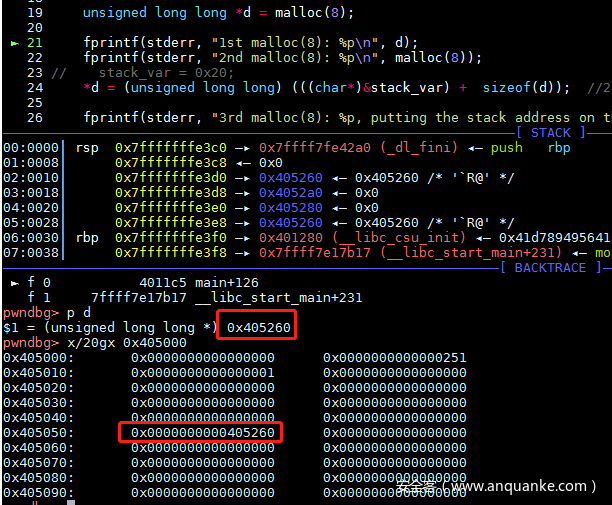
申请过d之后,0x405260还在tcache中,用户使用内存就是chunk的从fd开始的,因此直接修改*d的值即可
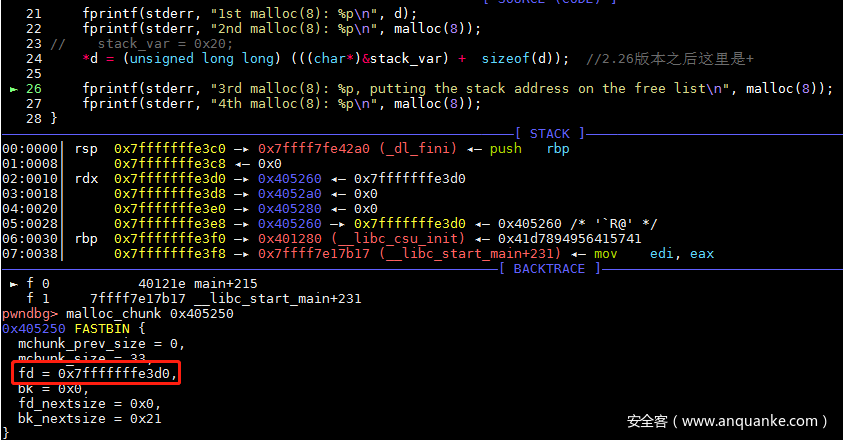
fd已经指向了我们希望返回的地址了,先申请一个chunk将d对应的chunk卸下,查看tcache
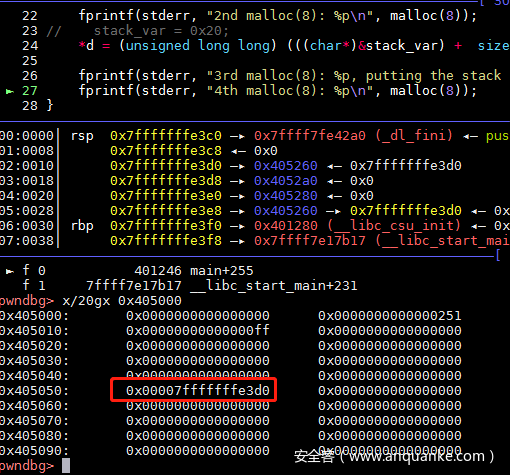
最后成功返回指定的地址
PS:house_of_lore对于glibc-2.26版本来说没什么区别,因为代码一个是利用fastbin,一个是利用small bin,但是tcache范围较大,就都在tcache内了。
0x06 unsorted bin attack(glibc-2.25)
unsorted bin attack其实就是泄露unsorted bin 的地址,根据unsorted bin的地址计算出malloc_area的地址(main_area=unsorted bin – 0x58),从而推算出libc_base的加载地址,那么就能去获取one_gadget的实际地址,或者是知道system函数地址之类的。因为针对unsorted bin,所以和tcache无关,因此这部分内容其实和标题也无关,算个彩蛋?
这里整理了三个方法,其实就是三种读取到unsorted bin地址的方法。
方法一
how2heap的代码给了一个思路是,将内存释放进入unsorted bin之后,假设这个chunk为p,修改p的bk地址为一个可获取内容的变量地址-2size_t(代码中是一个栈变量),那么再申请一个chunk p大小所对应的的内存,会将p从链表中取出,此时
p->fd = unsorted bin 头部 = FD
p->bk = 栈变量-2size_t = BK
卸下链表的操作就是
FD->bk = BK (这个是导致unsorted bin之后申请的内存为栈地址)
BK->fd = FD(此时BK->fd 就是BK的地址加上2*size_t,所以就是栈变量地址,那么就是获取了unsorted bin 的地址)
方法二
UAF的方法,当chunk进入unsorted bin,直接输出fd或者bk的值(之前如果是空的话),如果之前unsortedbin有值,那么最好还是输出bk的值保险(合并的情况排除 )
方法三
有两个连续的chunk p和q,其中p的大小是大于fastbin的,那么free之后是会进入unsorted bin的,然后修改p的大小(通过溢出漏洞,如果没有这个方法就没办法用了)为p+q的大小(即理解为p和q是合并为一个chunk了),那么再去申请一个chunk p对应大小的内存,会将假装合并的p+q的chunk分隔出来,将p分配出去,从而修改了chunk q的fd和bk,会指向unsorted bin,那么去读取chunk q的fd或者bk即可。
方法一示例
方法一就是how2heap内的源码,未做修改,直接看下过程。
先申请一个chunk p,再申请个malloc(500)是为了防止free(p)时,p被top chunk合并。
free(p)之后,chunk 进入unsorted bin

然后修改p的bk指针为栈变量地址-2site_t(也可以修改p的fd指针为栈变量地址-3size_t)
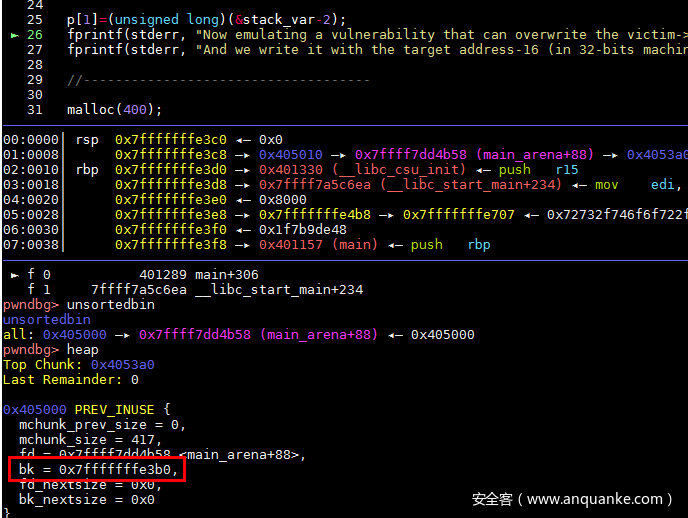
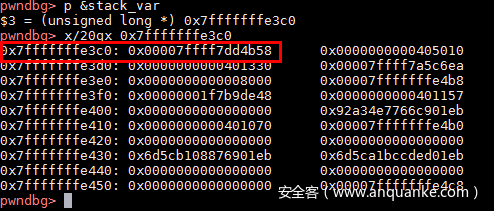
然后申请一个chunk p 对应的大小,会将p从链表中卸下,此时栈变量存储的就是unsorted bin的地址了。
方法二示例
UAF,演示代码
#include <stdio.h>
#include <stdlib.h>
int main(){
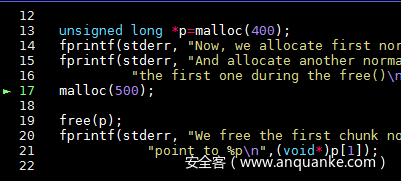
unsigned long *p=malloc(400);
malloc(500);
free(p);
printf("p[1] is at %p:%pn",p,(void*)p[1]);
}
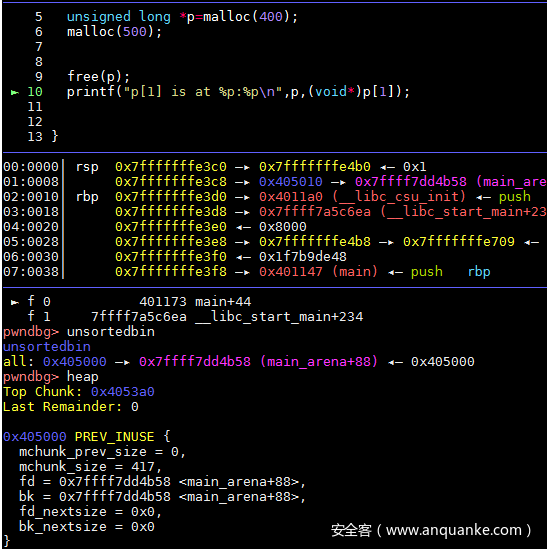
emmm,没什么说明的了。
方法三示例
通过修改unsortedbin中chunk的size,达到分割chunk来获取unsorted bin的地址
源码
#include <stdio.h>
#include <stdlib.h>
int main(){
unsigned long *p=malloc(0x100);
unsigned long *q=malloc(0x40);
free(p);
*(p-1) = 0x161;
printf("free(p) and p's value is %pn",(void *)p[0]);
unsigned long *t = malloc(0x100);
printf("t is at %pn",t);
printf("p is at %pn",p);
printf("q's value is %pn",(void *)q[0]);
}
申请两个内存,p和q,对应chunk大小分别是0x110和0x50
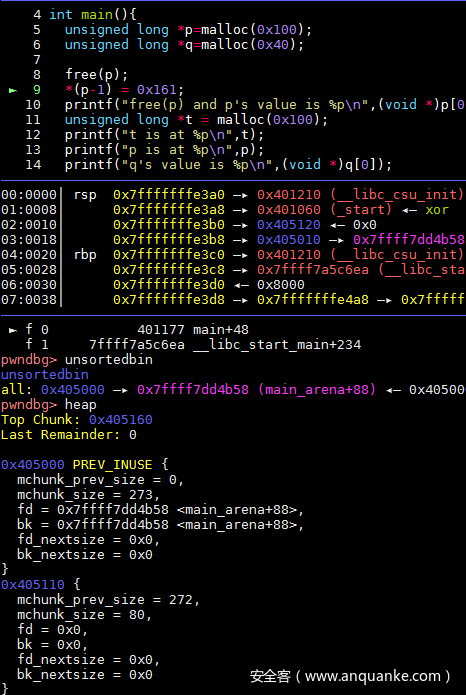
此时修改p的size大小(其实只要p的大小+4*size_t就可以了,但是不想分割q了)为p+q的大小和,所以是0x160,再加上最低位表示前一个chunk在使用,所以修改值为0x161,此时查看heap可以看到q好像被合并了
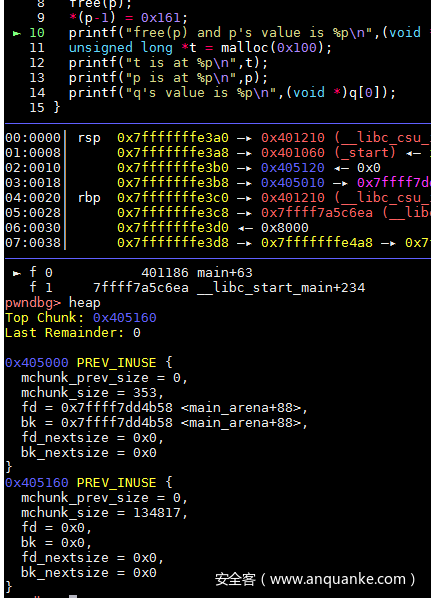
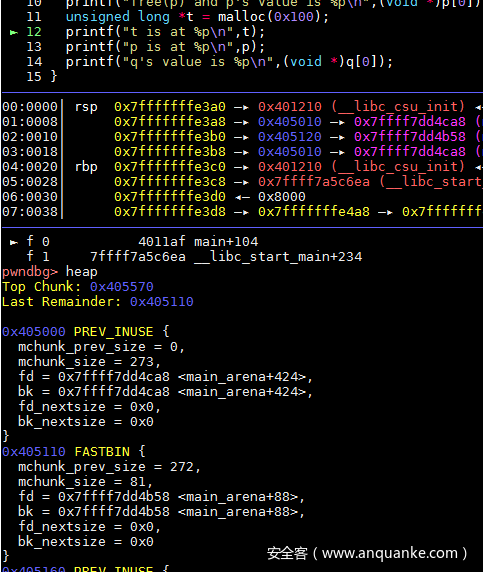
再申请一个0x100的内存,就是再将p分割出来,此时q的fd和bk就是指向unsortedbin了,而此时q是从未释放过的,所以读取q的值算正常操作,因此能获取到unsorted bin的地址。







发表评论
您还未登录,请先登录。
登录