
第三届DDCTF高校闯关赛鸣锣开战,DDCTF是滴滴针对国内高校学生举办的网络安全技术竞技赛,由滴滴出行安全产品与技术部顶级安全专家出题,已成功举办两届。在过去两年,共有一万余名高校同学参加了挑战,其中部分优胜选手选择加入滴滴,参与到了解决出行领域安全问题的挑战中。通过这样的比赛,我们希望挖掘并培养更多的国际化创新型网络安全人才,共同守护亿万用户的出行安全。
Windows Reverse1
通过段名发现是UPX壳,upx -d脱壳后进行分析 核心函数只是通过data数组做一个转置,反求index即可 值得一说的是data的地址与实际数组有一些偏移 由于输入的可见字符最小下标就是空格的0x20,因此data这个地址实际上也是真正的表地址(0xb03018)-0x20=0xb02ff8,在实际反查的时候需要稍作处理

from ida_bytes import get_bytes
data = get_bytes(0xb03018,0xb03078-0xb03018)
r = "DDCTF{reverseME}"
s = ""
for i in range(len(r)):
s += chr(data.index(r[i])+0xb03018-0xb02ff8)
print(s)
Windows Reverse 2
用PEID查壳发现是aspack壳,直接运行程序,然后用调试器附加上去 通过调用堆栈来追溯到输入函数 具体方法为: 当程序运行到等待输入时,在调试器中按下暂停,然后选择主线程,观察调用堆栈(Stack Trace / Call Stack)窗口
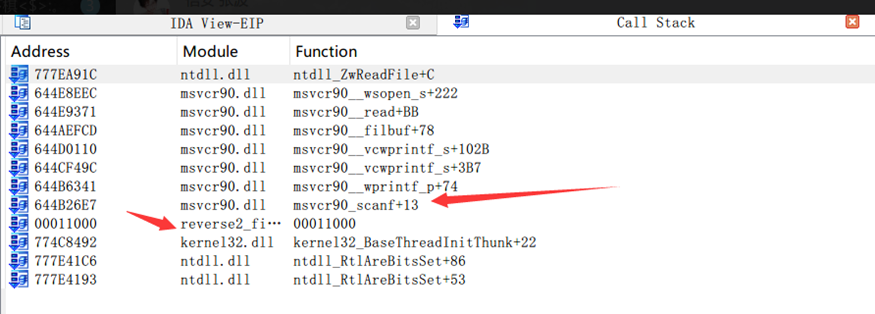
可以看出调用堆栈中存在scanf函数,这是因为接收输入时程序阻塞,必然是在程序调用接收输入的函数过程中阻塞的。而根据栈帧的机制,函数返回值会被存放在各个栈帧中,所以scanf的上一个函数就是用户模块了。 双击即可跟进去,此时看到的是一片数据
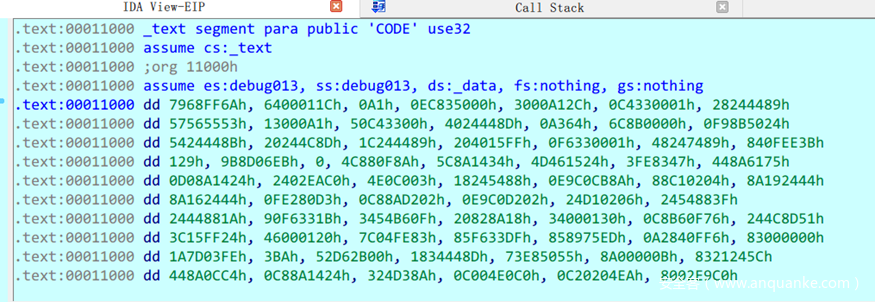
这是因为代码由动态解密得到,IDA还没有对他们进行分析。 对着它们按C,即可将其作为Code识别,进行分析了 然后重新看调用堆栈窗口的具体地址即可找到目标 也可以直接在Options-general窗口中找到Reanalyse program按钮进行重新分析
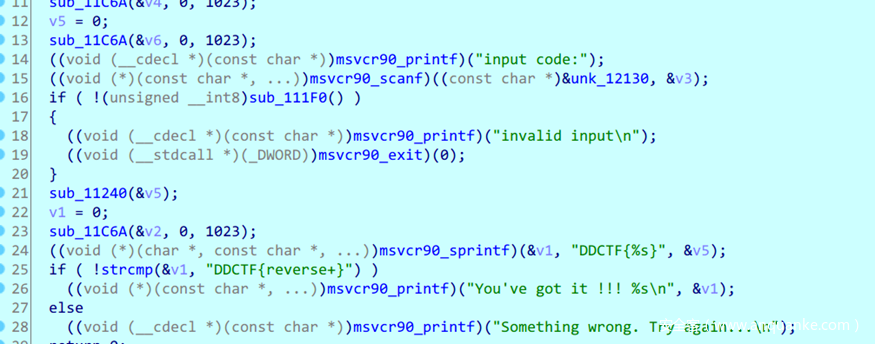
关键函数是sub111f0和sub11240 跟踪数据变化可以直接看出两个函数分别是hexdecode和base64encode 反向计算得到flag
from base64 import b64decode
print(b64decode(b"reverse+").hex().upper())
Confused
ios程序 Main函数中没有逻辑,所以通过字符串查找”DDCTF”取两次交叉引用,找到ViewController checkCode:函数 前段主要是校验开头结尾的”DDCTF{}”标志,API的各种命名都很清晰,无需多言。关键部分在msgSend“onSuccess”前的最后一个判断函数sub_1000011d0中
第一个调用sub100001f60可以看出来是构造函数,将对象的各个成员进行初始化,并把输入即a2的18个字节拷贝到全局变量中 第二个调用sub100001f00则开始虚拟机的执行循环,初始化IP寄存器后即不断向后执行,直到碰到结尾字节0xf3为止 loop函数内部很清晰,遍历对象的所有opcode与当前IP所指的值相比较,相等时即执行对应函数,函数内部负责后移IP,使VM执行下一条指令
平常做VM可以直接上angr、pintools或者记录运行log来方便地处理,但是本题是mac平台,由于钱包原因就只能乖乖静态逆了 首先整理字节码,位于0x100001984的地方 提出部分以作示例
0xf0, 0x10, 0x66, 0x0, 0x0, 0x0,
0xf8,
0xf2, 0x30,
0xf6, 0xc1,
0xf0, 0x10, 0x63, 0x0, 0x0, 0x0,
0xf8,
0xf2, 0x31,
0xf6, 0xb6,第一个code是0xf0,对应的handler为sub_100001d70
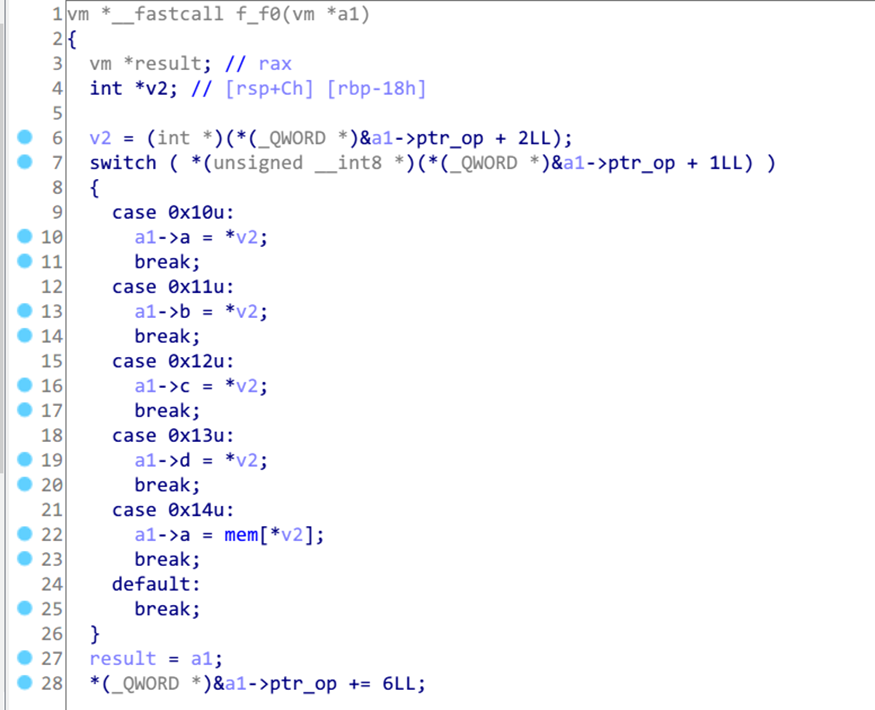
通过structures结构体功能可以将对象的成员重命名、整理结构成比较易读的形式 具体方法为在Structures窗口中按Insert创建结构体,按D创建成员

最后将a1的类型按y重定义成结构体指针vm*即可
可以看出来f0根据第二个字节来决定将后4个字节的Int存入某个寄存器中,例如0x10表示a 然后是0xf8,对应的handler为sub_100001C60
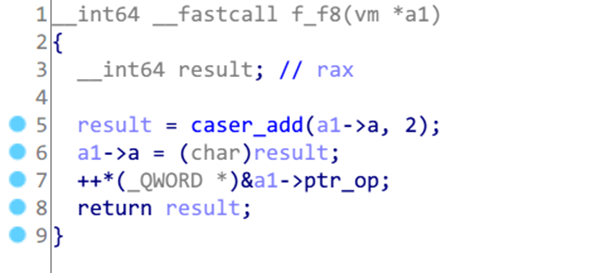
即对a寄存器的值在字母域内加2,相当于ROT2吧
以此类推,0xf2是判断a寄存器内的值是否和全局变量中以后一个字节为偏移的值相等,实际上也就是刚才memcpy进来的input 0xf6则是根据0xf2判断的结果来决定是否跳转,下同循环 因此整个算法实际上就是逐字符判断定值+2是否与输入相等,只需要将code_array中的定值取出即可 例如一个正则表达式
code="""0xf0, 0x10, ... 略"""
import re
data = re.findall(r"\n?0xf0, \n?0x10, \n?0x(..)", code)
print(data)
for i in data:
v = int(i,16)+2
print(chr(v-26 if (v>ord('Z') and v<ord('a')) or v>ord('z') else v),end='')
obfuscating macros
本题是一个经过OLLVM混淆的较简单算法的程序
基础分析
主函数中通过cin接受输入,传入两个函数中处理后要求皆返回True 两个函数都被OLLVM了 第一个函数通过黑盒可以知道是HexDecode,输出仍保存在原来的位置里,若输入超出数字和大写ABCDEF则Decode失败返回False 第二个函数则是对输入进行了一些比较,输出比较的结果
可供尝试有下列几种方法:
- 动态调试
- 符号执行
- 单字节穷举
动态调试
对于被控制流平坦化处理过的程序,执行流完全打散,所以很难知道各个代码块之间的关系,再加上虚假执行流会污染代码块,使得同一个真实块出现多次,难以分辨真实代码 因此在不deflat的情况下最好的办法就是单步执行慢慢跟,等到执行真实代码,尤其是一些运算的时候稍作注意 本题中通过这样的办法发现了这样一处代码
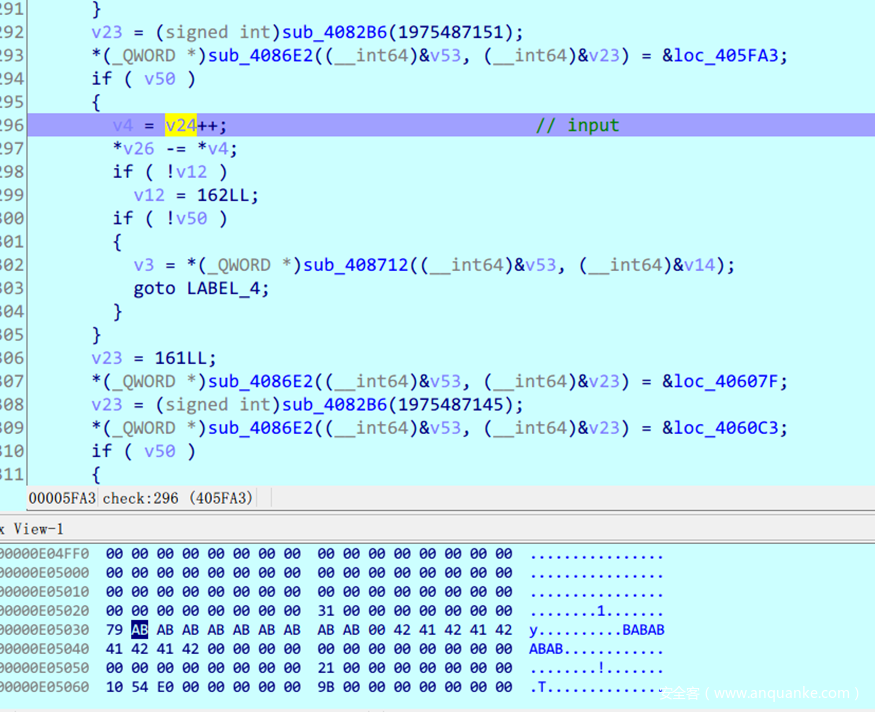
指针++后取值,很符合字符串的逐字符处理逻辑 点进去看一下可以发现正是hexdecode过后的输入,而v26与输入产生了联系,所以我们下一步要跟着v26的数据走

这里判断的v26的值是否为0,等价于cmp data,input; jz xxx; 因此可以知道要求第一个值为79,同理继续往下跟即可获得所有flag 另外快速一点的方法是使用断点脚本,在0x405fc6处下断并设置下述脚本,则会在output窗口打印出所需值
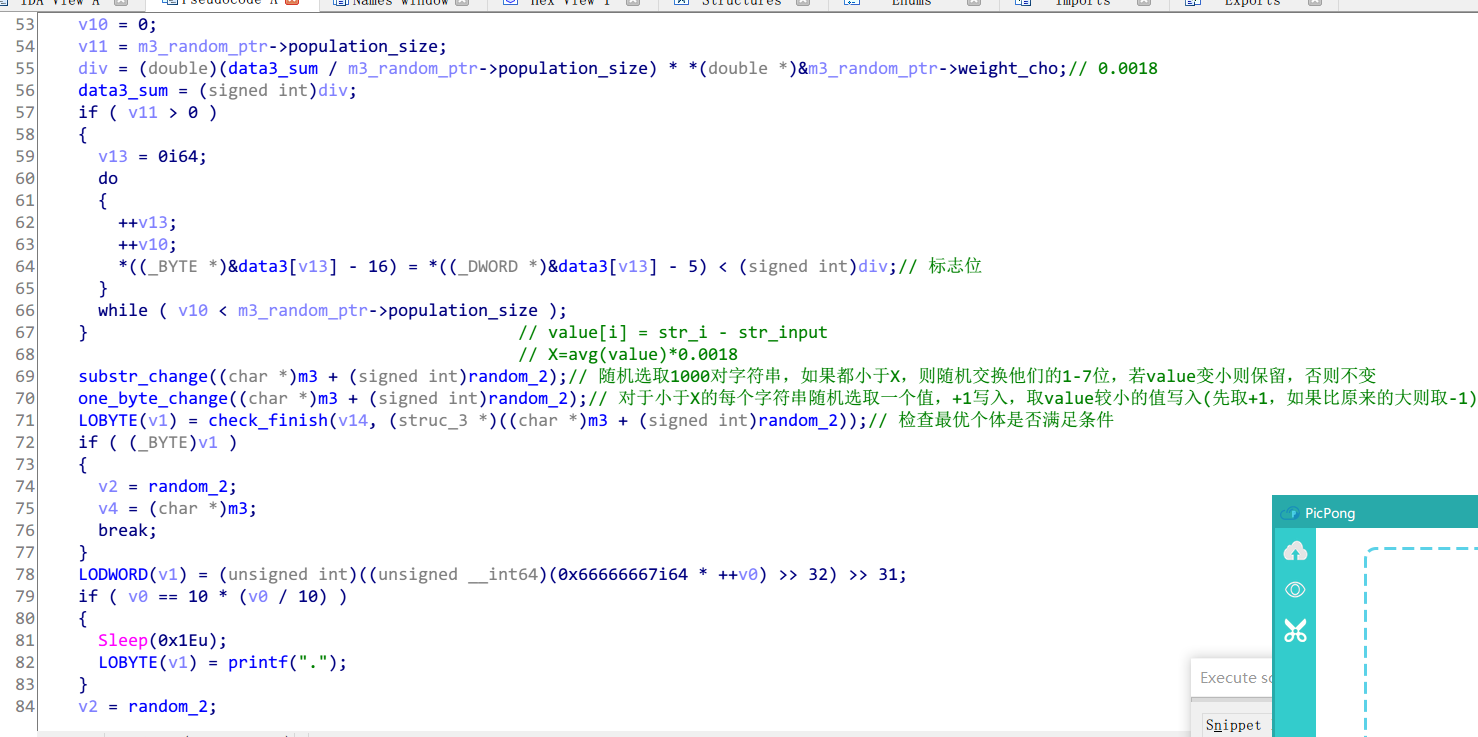
v = GetRegValue("ecx")
SetRegValue(v,"eax")
print("%X"%v)另外算法实际上也并不复杂,简单来说是通过一个data数组和另一个数组异或产生的数据,前一个数组是逐个赋值的,所以并不好找出顺序来静态解出flag
单字节穷举
由于该程序的算法是逐字节校验,并且当某一个值错误时就会退出,因此可以应用pintools类的侧信道攻击 但并不能直接上轮子,因为在check的前面还有一个hexdecode,使得输入必须两个一组,并且由于数字和字母处理逻辑不同所以也会产生执行次数的跃变,要做特殊修正 首先字典调整成[“%02x”%i for i in range(1,0×100] 然后要判断key中存在的字母个数,经测试发现每个字母大概会使运行次数增加1681-1683次,将误差消除后比较即可
大概在一小时左右可以得到flag,效率虽然比较感人,但优势在于期间不用关注该题,只等躺着拿flag就行了233
在之前的轮子上做了微调的脚本如下
#-*- coding:utf-8 -*-
import popen2,string
INFILE = "test"
CMD = "/root/pin/pin -t /root/pin/source/tools/ManualExamples/obj-intel64/inscount1.so -- /root/Project/obfuscating_macros.out <" + INFILE
#choices = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!#$%&'()*+,-./:;<=>?@[\]^_`{|}~"#自定义爆破字典顺序,将数字和小写字母提前可以使得速度快一些~
choices = ["%02X"%i for i in range(1,0x100)]
def execlCommand(command):
global f
fin,fout = popen2.popen2(command)
result1 = fin.readline()#获取程序自带打印信息,wrong或者correct
print result1
if(result1 != 'wrong answer\n'):#输出Correct时终止循环
f = 0
result2 = fin.readline()#等待子进程结束,结果输出完成
fin.close()
def writefile(data):
fi = open(INFILE,'w')
fi.write(data)
fi.close()
def pad(data, n, padding):
return data + padding * (n - len(data))
flag = ''
f = 1
while(f):
dic = {}
l = 0#初始化计数器
for i in choices:
key = flag + i#测试字符串
print ">",key
writefile(pad(key, 8, '0'))
execlCommand(CMD)
fi = open('./inscount.out', 'r')
# 管道写入较慢,读不到内容时继续尝试读
while(1):
try:
n = int(fi.read().split(' ')[1], 10)
break
except IndexError:
continue
fi.close()
c = 0
for ch in key:
if(ch in string.ascii_uppercase):
c += 1682
print n-c
if(n-c-l>50 and l ):
flag += i
break
else:
l = n-c
print flag毫无疑问的是对于被OLLVM混淆过的程序,纯静态分析难度较大 而本题的混淆方案经过处理,网上现成的轮子只有TSRC于17年发布的文章,但由于块的分布不同所以还需要调整,由于我并不熟悉angr就不班门弄斧了,等一个师傅指教 所以所谓的静态分析其实还是要在动态的基础之上进行一定操作的。
黑盒破解2-时间谜题
本题目继承去年的黑盒破解,有大量的冗余无关代码,因此逆起来比较吃力,需要耐心和经常整理思路
整体而言题目很新颖,但难度有些高,需要做题人完全理解遗传算法,大胆、跳出常规思路去解题
个人认为题目的难点主要是正常做题是倒着来,即思考如何能达到目标–使correct标志位为1,进而追溯哪些数据和条件影响该标志位,然后逆向相关的函数并寻找它们和输入的关系,从而反推出输入。
而本题要求首先逆清整个程序的逻辑和几乎所有功能,然后再思考哪些逻辑不合常理,或者说应该被修改,这是一个很反常的思路。
换言之,这是不同于以往找出正确输入的CrackMe,而是一个修复类型的题目
main中主要有两个函数比较重要,分别是负责初始化的init和负责调用VM的check

init里无需多言,主要是各种各样的初始化,里面还有一些混淆,例如随机数、内存交换解密等等,但不受输入影响所以不用关心
check里跟去年一样的方式比对code,然后调用对应的函数
去年的目标是在表中构造出Binggo!\0的字符串,然后调用输出函数print出来,最后hash校验成功使得flag出现
而今年这个结构仍然保留了,所以构造Binggo!\0的字符串还是能输出Congratulations!,而题目里却没有说明这个字符串,对做题人来说题目里出现了如果构造一个输出满足hash则能给出正确反馈的状况,所以这是一个很大的坑…
还好我翻出了去年的题目一看hash完全一样,打扰了 乖乖看后面那个函数吧

是否输出Congratulations的校验标志有两处交叉引用,一处在VM的handler中,另一处则在这个final进去以后的某部分中
事实上这里才是今年题目的开始
关于VM相关的内容可以参考去年的WP中re2黑盒破解的部分,不过去年的时候还不怎么会用结构体功能来恢复对象2333
另外handler有一些升级,需要注意到,主要在于当下标寄存器大于char_table的范围即256时,去年是直接return,防止越界读写
而今年刻意地提供了这个功能
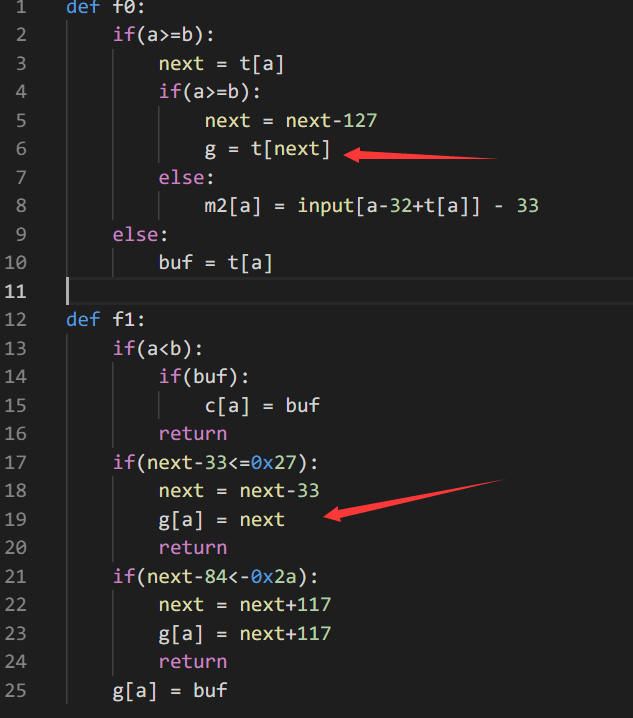
随便逆了两个func发现这个VM具备任意写的能力,那么这样可操作的范围就大了,甚至大到让人无所适从的地步
毕竟理论上来说任意写甚至可以直接按照pwn的思路来get shell
找了一圈leak,发现堆地址在init函数中提供了

继续往下看,在final()函数中做了很多事情
首先是随机生成1000个字符串,每个字符串15字节,构成一个对象数组,字符串的字符种类有3种,分别是大写字母、小写字母和数字

然后循环100次

- 计算每个字符串和标准字符串的相似度,具体计算方法为逐字符做差取绝对值累加,将相似度保存在对象中,然后对整个数组按照相似度排序
- 求出相似度的平均值,乘以一个比例0.0018(double类型,根据IEEE标准解析),得到值X
- 遍历所有字符串,相似度小于X的打上标记
- 随机选取1000对字符串,如果都具备标记则随机交换后半部分,交换完后计算相似度,如果降低则保留,否则还原
- 遍历带有标记的字符串,随机选取一个值做+1/-1浮动,选择相似度较小的保留
- 判断相似度最小的字符串的相似度是否小于某个值0x147,若小于则取相似度排名200-300的带有标记的字符串进行两两异或,从尾部开始逐字符计算,若相等则中断并判断下标是否小于某个值Len=0x4E57795F,若小于则判断Len+4是否大于等于30,是则退出,否则从Len开始重复该串的0-Len位,并在最后附加fill_value=”5mE9″。这一段逻辑比较绕,建议自己调试两遍看看memmove的作用
![screenShot.png]()

根据逻辑想到遗传算法
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容

上述所有参数都是对象的成员
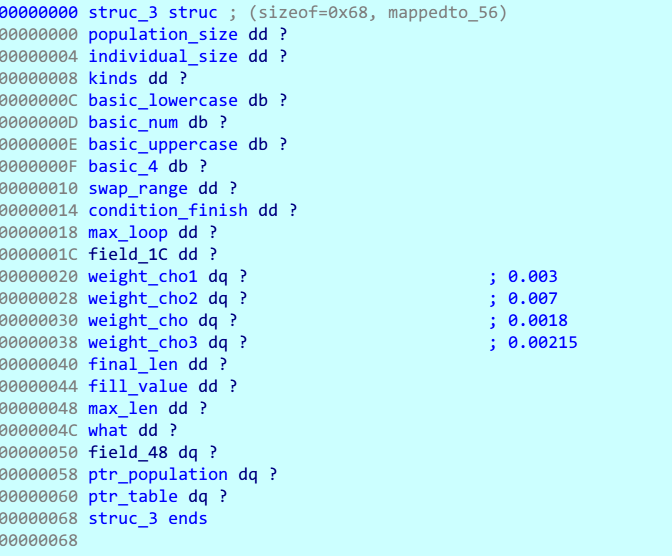
由于我们之前对虚拟机的逆向已经知道有任意写的能力,于是这里的所有参数我们都是可以修改的
那么问题就在于修改哪些了
默认情况下怎么跑都会由于X=平均值*选优比例0.0018=0而没有字符串被标记,于是后面几个函数就都没有用了
所以首先要修改的就是比例0.0018,虽然对象中有几个备选比例成员,测试发现都还是不行,于是大胆给他上了200(……
这个200也是需要用double类型存储的,用matlab转换
octave:3> num2hex(200)
ans = 4069000000000000
发现经过100轮遗传以后产生了很多字符串,但相似度仍然很低,于是再把max_loop遗传代数调大到1000,发现出现了很多跟标准字符串相似的串

注意特征是不同的字符全部位于尾端,猜测是因为交换的算法是两串交换尾端部分
再观察排名200-300的串
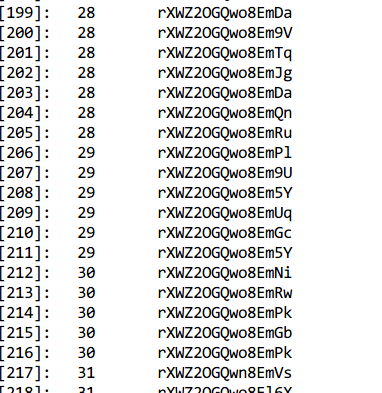
确认猜想,就是尾部若干字符不同
那么flag为啥还没出现呢?
因为数据成员中还有一个Len,默认值高达0x4E57795F,会导致任何串都无法进入
而怎么调整也并没有任何线索,它从0-23全部可取,每一个值都会导致解锁密钥不同,且进入解密时会破坏原密文
暴力试了所有值都无果,最终想到了对标准串暴力枚举所有Len和相同的值下标
结果正确的标准是对数据RC4解密后hash的值为36468080
class RC4:
def __init__(self, public_key=None):
if not public_key:
public_key = 'none_public_key'
self.public_key = public_key
self.index_i = 0;
self.index_j = 0;
self._init_box()
def _init_box(self):
"""
初始化 置换盒
"""
self.Box = [i for i in range(256)]
key_length = len(self.public_key)
j = 0
for i in range(256):
index = ord(self.public_key[(i % key_length)])
j = (j + self.Box[i] + index) % 256
self.Box[i], self.Box[j] = self.Box[j], self.Box[i]
def do_crypt(self, string):
"""
加密/解密
string : 待加/解密的字符串
"""
out = []
for s in string:
self.index_i = (self.index_i + 1) % 256
self.index_j = (self.index_j + self.Box[self.index_i]) % 256
self.Box[self.index_i], self.Box[self.index_j] = self.Box[self.index_j], self.Box[self.index_i]
r = (self.Box[self.index_i] + self.Box[self.index_j]*2 + self.index_i + self.index_j) % 256
# r = (self.Box[self.index_i] + self.Box[self.index_j]) % 256
R = self.Box[r] # 生成伪随机数
out.append(((s) ^ R))
return (out)
# c = [0x7f, 0x2e, 0x79, 0x56, 0x6, 0xc2, 0xb8, 0x47, 0x52, 0xe1, 0xb9, 0x7f, 0x38, 0x1b, 0xa, 0xcc, 0x18, 0x7a, 0xec, 0xf8, 0xa2, 0x89, 0x91, 0x78, 0xa6, 0x4b, 0x1b, 0x85, 0x93, 0x9a, 0x4c, 0x59, 0x6e, 0xf5, 0xf4, 0x7c, 0xd2, 0xf4, 0x2, 0x6, 0xe4, 0xfb, 0xcb, 0xd7, 0x7c, 0xa9, 0x85, 0xe5, 0x0, 0x15, 0x90, 0x6, 0x4f, 0x1f, 0x52, 0x54, 0xf, 0x5a, 0x3d, 0x87, 0x32, 0x5b, 0xd6, 0xb2]
c = [0xbe, 0x70, 0x48, 0xc6, 0xa1, 0x60, 0x68, 0xcf, 0xd2, 0x6e, 0x9e, 0x60, 0x81, 0x1a, 0x5d, 0x4a, 0x71, 0x9b, 0xea, 0x51, 0x2c, 0xb7, 0x46, 0xa1, 0x15, 0xb9, 0xee, 0xc6, 0xc8, 0x0, 0x8f, 0x10, 0xd, 0xc0, 0xe2, 0x79, 0xa5, 0x88, 0xcc, 0x6f, 0xc2, 0x1d, 0xd7, 0x8e, 0x2, 0xf6, 0x1b, 0x7a, 0x5f, 0x5b, 0x6f, 0xe3, 0x59, 0xe, 0x3f, 0x91, 0x16, 0x3c, 0x32, 0x95, 0x29, 0xec, 0xcb, 0xec]
def hash1(x):
r = 0
for i in x:
if(i>0x7f):
i = i+0xffffff00
r = r*16 + i
v46 = r&0xf0000000
if(v46!=0):
r = r^(v46>>24)
r = (~v46) & r & 0xffffffff
return r
true_h1 = 36468080
ori = "rXWZ2OGQwo8Em9y"
for final_len in range(24):
for i in range(len(ori)):
if(i>final_len):
continue
ss = ["" for k in range(48)]
tmp = ["" for k in range(24)]
s = ""
for k in range(len(ori)):
ss[k] = ori[k]
ss[i]=""
for k in range(final_len):
tmp[k] = ss[k]
for k in range(final_len):
ss[final_len+k-1] = tmp[k]
for k in range(len(ss)):
if(ss[k]==""):
ss[k] = "8"
ss[k+1] = "E"
ss[k+2] = "m"
ss[k+3] = "9"
break
print(ss)
for k in ss:
if(k==""):
break
s += k
print(final_len, i, s)
rc4 = RC4(s)
p = rc4.do_crypt(c)
print("".join(map(chr,p)))
h1 = hash1(p)
print((i,s,h1))
if(h1==36468080):
print("!"*150)打印出的值检索”!!!”可以发现flag

事后跟出题老师交流了一下发现问题出在min_value上,期望解法应该是将其改为1,这样当最优解即跟标准串完全一致的串出现时,排名200-300的串才具备N个字符不同的特征
默认的0x147出现时,排名200-300的串可能有N+1,N+2个字符不同,而RC4解密是一次性的,如果第一个进行解密的串不符标准就会破坏密文导致后续正确key即使出现也无法解密出flag
赛时写了一个方便Patch的IDA脚本,在generation之前执行即可Patch各个参数
from ida_bytes import patch_bytes
import struct
base = idaapi.get_imagebase()
GA = Qword(base+0x286a8)+Qword(base+0x286b0)
print(hex(GA))
min_value = GA+0x14
loop_size = GA+0x18
weight = GA+0x30
ptr_str = GA+0x60
final_len = GA+0x40
w = "3ff0000000000000"
#w = "3FF007D4E4D205F3"
w = w.decode("hex")[::-1]
patch_bytes(weight, w)
patch_bytes(final_len, struct.pack("<L",0xd))
patch_bytes(loop_size,struct.pack("<L",20000))
patch_bytes(min_value,struct.pack("<L",1))
#patch_bytes(ptr_str,struct.pack("<Q",guess_str))
print("Patch finished")查看当前种群
base = idaapi.get_imagebase()
data3 = Qword(base+0x29d90)
GA = Qword(base+0x286a8)+Qword(base+0x286b0)
#min_value = Dword(GA+0x14)
min_value = Dword(base+0x29d80)
for i in range(1000):
v = Dword(data3+4+24*i)
if(v>=min_value):
break
if(i<300):
s = ""
ptr_s = Qword((data3+16+24*i))
for j in range(16):
s += chr(Byte(ptr_s+j))
print("[%d]:\t%d\t%s"%(i+1,v,s))
print("alive:%d, v=%d"%(i+1,v))
想了解更多 题目出题人视角解析,请关注:滴滴安全应急响应中心(DSRC)公众号查看:








发表评论
您还未登录,请先登录。
登录