

前言
Defcon ctf 2019中大部分时间都在和队友一起看hotel_california这道题,看到最后也只是知道应该利用TSX,想办法让程序能进入到预先加载的指令——也就是我们写入的shellcode,从而实现执行shellcode获得shell的目的,但是一直到最后也没有运行shellcode成功,直到看了Github上x64x6a给出的exp,才豁然开朗。
hotel_california题目分析
首先,要讲清楚这道题本身的函数执行流程,通过IDA逆向分析后主要函数如下:

函数主要是在每一次循环中,读取最多1024个字节,然后通过/dev/urandom生成两个随机数并读取,之后就是使用allocate函数,申请一个可读可写可执行的堆块,申请长度为length(shellcode长度)+65+4,并且先存储4个字节的随机数和65个字节硬编码在程序中的数据(经分析这是一段汇编代码),实际大小为0x450.
然后当shellcode长度不为0时,使用cpy函数从栈中获取发送的shellcode复制到堆块中来。
最后执行堆块中的汇编代码,这一段代码dump出来后如下:
0: 48 8d 3d f9 ff ff ff lea rdi,[rip+0xfffffffffffffff9] # 0x0
7: 48 83 ef 14 sub rdi,0x14
b: 8b 07 mov eax,DWORD PTR [rdi]
d: 89 07 mov DWORD PTR [rdi],eax
f: 48 31 c0 xor rax,rax
12: 48 31 c9 xor rcx,rcx
15: 48 31 d2 xor rdx,rdx
18: 48 31 f6 xor rsi,rsi
1b: f2 f0 31 1f xacquire lock xor DWORD PTR [rdi],ebx
1f: 0f 01 d6 xtest
22: 75 01 jne 0x25
24: c3 ret
25: 48 31 ed xor rbp,rbp
28: 48 31 e4 xor rsp,rsp
2b: 48 31 ff xor rdi,rdi
2e: 48 31 db xor rbx,rbx
这段代码重点就在于三行代码:
1b: f2 f0 31 1f xacquire lock xor DWORD PTR [rdi],ebx
1f: 0f 01 d6 xtest
22: 75 01 jne 0x25
当跳转成功时,就会进入到我们发送的shellcode中,这样就可以很快getshell了,但是问题在于xacquire指令前缀,这个指令前缀属于硬件锁省略(HLE,Hardware Lock Elision),当出现这个前缀时,就表示对后面的指令所操作的内存开始锁省略。
这样一来,就到了xtest指令的判断了,对于xtest指令,intel官方描述如下:
Intel® TSX also provides an XTEST instruction, allowing software to query whether the logical processor is transactionally executing in a transactional region identified by either Hardware Lock Elision (HLE) or Restricted Transactional Memory (RTM).
大概意思就是intel提供了一条指令xtest,用来让软件查询逻辑进程是否在一个事务性区域进行一个事务性地执行,判断方式就是查看是否有HLE或者RTM(Restricted Transactional Memory,限制事务内存)。
那么此处明显有一个硬件锁省略,所以xtest指令运行后,跳转将不会执行,函数返回,无法执行我们构造的shellcode。
那么怎么解决这个硬件锁省略的问题呢?
这里就要说到现代CPU的一个特点,为了提升工作效率,CPU会以推测的方式预先加载一部分指令,从而充分利用处理器的性能,减少等待时间,而这一特性是存在缺陷的,这一缺陷也作为Meltdown漏洞与Spectre。不过这道题很巧妙的是,判断分支是否进入的指令其结果是可以在预加载中改变的,那就是xacquire指令对应的另一条指令xrelease——当出现这个前缀时,就表示对后面的指令所操作的内存结束锁省略,所以只要在后面要执行的shellcode中调用xrelease指令,将xacquire指令锁住的内存解锁,那么xtest判断后,跳转就将会执行,进入到我们构造好的shellcode中。
exp之python脚本分析
x64x6a给出的python脚本十分清晰明了,给服务器总共发送了两次数据。第一次发送1024个字节,第二次通过pwntools库的shutdown函数发送一个EOF.
第一次发送,将构造好的shellcode填充到1024字节,注意此处必须要保证最后的申请空间大于0x400,否则在后面第二次申请堆块时将不会从这次free掉的大堆块中分割空间,因为小于等于0x400字节,这样的堆块free掉之后将会进入tcache bin中,第二次必须申请相同size的chunk才能申请到这一块空间,而第二次由于发送了EOF,只申请了0x50大小的空间,所以要想申请到同一个堆块,就必须让第一次被free掉的堆块落入到unsorted bin中。
第二次发送,通过pwntools中的shutdown()函数,发送EOF信息,然后循环中将会则此申请一个65+4大小的堆(实际为0x50),这个堆将会直接从unsorted bin中分配,也就是第一次存储了shellcode信息的那个堆,而此时shellcode相对应的偏移没有变化,这样当跳转实现成功,将会正确执行shellcode。注意,第二次只能发送EOF,原因在于程序读取输入的shellcode时,如果不足1024字节,必须要在最后一个字节为x00时才会停止读取,而这样就会出现前一次写入的shellcode被x00截断的情况,无法执行。
到了这里,仍然有一个问题——为什么要发送两次?
这个问题就必须要考虑到xrelease的解锁操作了,从上面的分析可以知道,xacquire将存储第一个随机数处的内存锁上,使用xrelease解锁时,需要将原始随机数的值赋给相应内存将随机数还原,才能解锁,而原始的随机数的值存在于栈上,第一次发送时没有办法寻找到栈的地址,所以发送两次是为了实现一个uaf,想办法泄露libc的地址,再通过libc泄露出栈地址,从而完成解锁操作,顺利执行shellcode。
exp之shellcode汇编代码分析
x64x6a编写了一份汇编代码,用于生成shellcode,其中先通过uaf泄露libc地址和栈地址最终实现解锁的过程,后面的代码先后调用了syscall_open,syscall_read,syscall_write,从而获取flag并回显。
下面仅分析解锁过程,代码如下:
section .text
_start:
jmp escape
db 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA'
escape:
; get libc address from heap offset, it's in main arena
mov rbx,[rel $ -0x18]
; calculate environ stack pointer from libc
sub rbx,-0x23f8
mov rdx, [rbx]
; get first random number from the stack
mov edx, [rdx-0x584]
; load original [rdi] address
lea rdi, [rel $ -0x87]
; end lock elision on [rdi] by storing the original random value
xrelease mov [rdi], edx
; fix up the stack
mov rsp,[rbx]
add rsp, -0x18888
这里需要说明两次调用时堆的内容。第一次调用时,分配了一个0x450的堆块,如下所示:
chunk +--------> +-------------+-------------+
| | |
+---------------------------+
| | |
+---------------------------+
| | |
+---------------------------+
| | |
+-------------+-------------+
| |jmp AAAA.. |
+---------------------------+
|AAAA... |
+---------------------------+
|AAAAAA... |
escape: +--------> +---------------------------+
| |
| |
| |
+---------------------------+
首先前4个字节为复制过来的随机数,后面的解锁过程就是要使这个数复原,然后是65个字节硬编码在elf文件中的内容,随后就是我们发送的shellcode。
第二次调用函数时,实际上只申请了0x45个字节,但是会从之前0x450的大堆块中分配内存,此时内存中的内容如下:
chunk +--------> +-------------+-------------+
| | |
+---------------------------+
| | |
+---------------------------+
| | |
+---------------------------+
| | |
+-------------+-------------+
| |jmp size |
+-------------+-------------+
| fd | bk |
+-------------+-------------+
|fd_nextsize |bk_nextsize |
escape: +--------> +---------------------------+
| |
| |
| |
+---------------------------+
在第二次申请时,由于对齐的原因,实际上申请了0x50大小的堆块,此时后面的内存还剩0x400,并且成为一个新的bin,但是这个新的bin大小应该为0x410,将会被分到large bin,原因是这个bin的pre size正被现在使用的堆块复用,之前填充的41个“A”字符有40个被替换掉,分别为size,fd,bk,fd_nextsize,bk_nextsize,这就是shellcode中填充41个“A”字符的原因。
从上一段可以知道,第二次调用函数时,未被分配的内存中出现了bk指针,此时的bk将会指向main_arena,libc的基址也就可以通过bk指针泄露出来,相关代码为:
; get libc address from heap offset, it's in main arena
mov rbx,[rel $ -0x18]
然后通过libc中的environ变量泄露栈的地址,可以通过以下指令在gdb调试中获取对应的environ变量偏移:
shell nm -D /lib/x86_64-linux-gnu/libc-2.27.so |grep environ
然后根据vmmap获取libc的基址,从而计算出通过bk指针泄露的libc地址到environ变量的偏移,获取栈地址,相关代码如下:
; calculate environ stack pointer from libc
sub rbx,-0x23f8
mov rdx, [rbx]
下一步就是根据此时的栈地址,找到存储的随机数,观察程序执行过程中的allocate函数:
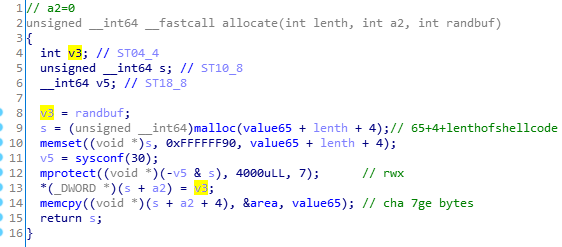
发现了v3这一位于栈上的变量,在gdb调试中,其在泄露栈地址时仍存储着随机数的值,并且偏移固定为0x584,由此获得了随机数,然后通过获取堆地址得到堆中存储随机数的地址,最后实现代码即:
; get first random number from the stack
mov edx, [rdx-0x584]
; load original [rdi] address
lea rdi, [rel $ -0x87]
; end lock elision on [rdi] by storing the original random value
xrelease mov [rdi], edx
而后面对栈进行修复,是因为此时rsp为0,需要将其修复到栈上,否则将会引发系统错误,至于减去0x18888,则是开辟了一个很大的栈而已,这个值也可以设的小一点。
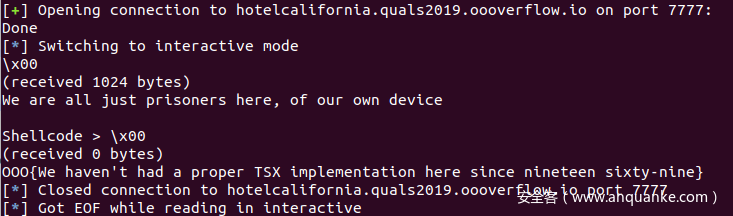
最后执行shellcode,拿到flag:
总结
总的来说,这道题解决方法就是通过对堆的unsorted bin进行攻击,利用UAF获取bk指针泄露出libc的地址,然后查找environ变量泄露出栈地址,最后查找到随机数相对泄露栈地址的偏移,获取随机数的值,利用CPU预加载指令的特性解锁HLE,最终执行shellcode获取flag。
针对这道题,个人感觉题目出的还是挺有趣的,然而让人感觉不太美妙的就是,即使拿着exp我也没能在本地执行shellcode成功,这道题涉及CPU的预加载机制,利用条件并不是很好,所以说出题人这道题出得有点坑,截至目前官方并没有放出这道题的writeup,不过从这道题里面,我还是学到了挺多知识点,对于我这个菜鸟来说,还是挺有意义的,做ctf不一定非要拿到多少分,最重要的还是能够帮助自己找到知识的不足,学习的方向,以及技能的训练,我想这才是最重要的部分。







发表评论
您还未登录,请先登录。
登录