

opcode简介
在学习和分析opcode的过程中,需要参照EVM OPCODEhttps://ethervm.io/#opcodes 。表格已经描述的比较清晰了:第一列是通过0x00~0xFF表示的opcode;第二列是对应的指令;第三列当前指令相关的输入参数(栈中);第四列是执行当前指令的出参(栈中);最后一列是表达式。
opcode分类
在以太坊官方黄皮书中,对OPCODE进行了相应的分类:
0s: Stop and Arithmetic Operations (从0x00-0x0f的指令类型是STOP指令加上算术指令)
10s: Comparison & Bitwise Logic Operations (0x10-0x1f的指令是比较指令和比特位逻辑指令)
20s: SHA3 (目前0x20-0x2f只有一个SHA3指令)
30s: Environmental Information (0x30-0x3f是获取环境信息的指令)*
40s: Block Information (0x40-0x4f是获取区块信息的指令)*
50s: Stack, Memory, Storage and Flow Operations (0x40-0x4f是获取栈、内存、储存信息的指令和流指令(跳转指令))*
60s & 70s: Push Operations (0x60-0x7f是32个PUSH指令,PUSH1-PUSH32)
80s: Duplication Operations (0x80-0x8f属于DUP1-DUP16指令)
90s: Exchange Operations (0x90-0x9f属于SWAP1-SWAP16指令)
a0s: Logging Operations (0xa0-0xa4属于LOG0-LOG4指令)
f0s: System operations (0xf0-0xff属于系统操作指令)
实际上结合参照表格,opcode还是比较容易理解的,就是需要多点时间和耐心去一一分析。这里挑其中几个获取环境信息的指令进行说明:

- CALLVALUE
向栈中压入msg.value,即在调用智能合约的函数时传入的value值; - CALLDATALOAD
读取msg.data值从i开始往后32字节的值,并将该值压入栈中,覆盖i; - CALLDATASIZE
读取msg.data的长度,并压入栈中; - CALLDATACOPY
读取msg中的制定位子的数据存储到相应位子的内存中; - CODESIZE
统计当前合约的代码字节码长度,压入栈中; - CODECOPY
指定当前合约的代码片段存储内容中。
可以通过remix的debug功能验证以上的指令。
在上面我们提到了栈和内存,他们都是存储数据,有什么区别呢?
存储方式
在智能合约中有三种存储方式,分别是stack(栈)、memory(内存)、storage。
stack
在接触EVM的时候,一定看到过介绍说EVM是基于栈的,基于栈的虚拟机数据的存取为先进后出(也即后进先出),在debug的时候跟踪stack的内容就可以看出来。stack可以免费使用,没有 gas 消耗,用来保存函数的局部变量,数量被限制在了 16 个。
用于操作栈的指令有:
- push:用从栈顶弹出一个元素
- popX:把紧跟在后面的 1-32 字节元素推入栈顶,Push 指令一共 32 条,从 Push1)到 Push32,因为栈的一个
字是 256bit,一个字节 8bit,所以 Push 指令最多可以把其后 32 字节的元素放入栈中而不溢出。 - dupX:用来复制从栈顶开始的第 1-16 个元素,复制后把元素在推入栈顶,Dup 指令一共 16 条,从 Dup1到 Dup16。
- swapX:把栈顶元素和从栈顶开始数的第 1-16 个元素进行交换,Swap 指令一共 16 条,从 Swap1一直到 Swap16。
memory
memory 是一个易失性的可以读写修改的空间,主要是在运行期间存储数据,将参数传递给内部函数。内存可以在字节级别寻址,一次可以读取 32 字节。
用于操作 memory 的指令有三个:
- mload 加载一个字从 stack 到内存;
- sstore 存储一个值到指定的内存地址,格式 mstore(p,v),存储 v 到地址 p;
- mstore8 存储一个 byte 到指定地址 ;当我们操作内存的时候,总是需要加载 0x40,因为这个地址保存了空闲内存的指针,避免了覆盖已有的数据。
stroage
Storage 是一个可以读写修改的持久存储的空间,也是每个合约持久化存储数据的地方,存储消耗的gas费用最高。Storage 是一个巨大的 map,一共 2^256 个插槽,一个插糟有 32byte。注意,存储在storage中的值是可以通过外部接口直接读取的:
eth.getStorageAt(合约地址, slot)
# 该函数还有第三个参数,默认为"latest",还可以设置为"earliest"或者"pending",具体作用本文不做分析
EVM 提供的用于操作 storage 的指令有两个:
- sload 用于加载一个字到 stack 中;
- sstore 用于存储一个字到 storage 中;
opcode结构分析
Deconstructing a Solidity Contract —Part I: Introduction – OpenZeppelin blog
Deconstructing a Solidity Contract — Part II: Creation vs. Runtime – OpenZeppelin blog
Deconstructing a Solidity Contract — Part III: The Function Selector – OpenZeppelin blog
Deconstructing a Solidity Contract — Part IV: Function Wrappers – OpenZeppelin blog
Deconstructing a Solidity Contract — Part V: Function Bodies – OpenZeppelin blog
Deconstructing a Solidity Contract — Part VI: The Metadata Hash – OpenZeppelin blog
该部分主要参考以上六篇blog,这六篇文章十分详细有条理的分析了一个合约编译后的opcode的结构,主要思路围绕这幅图:
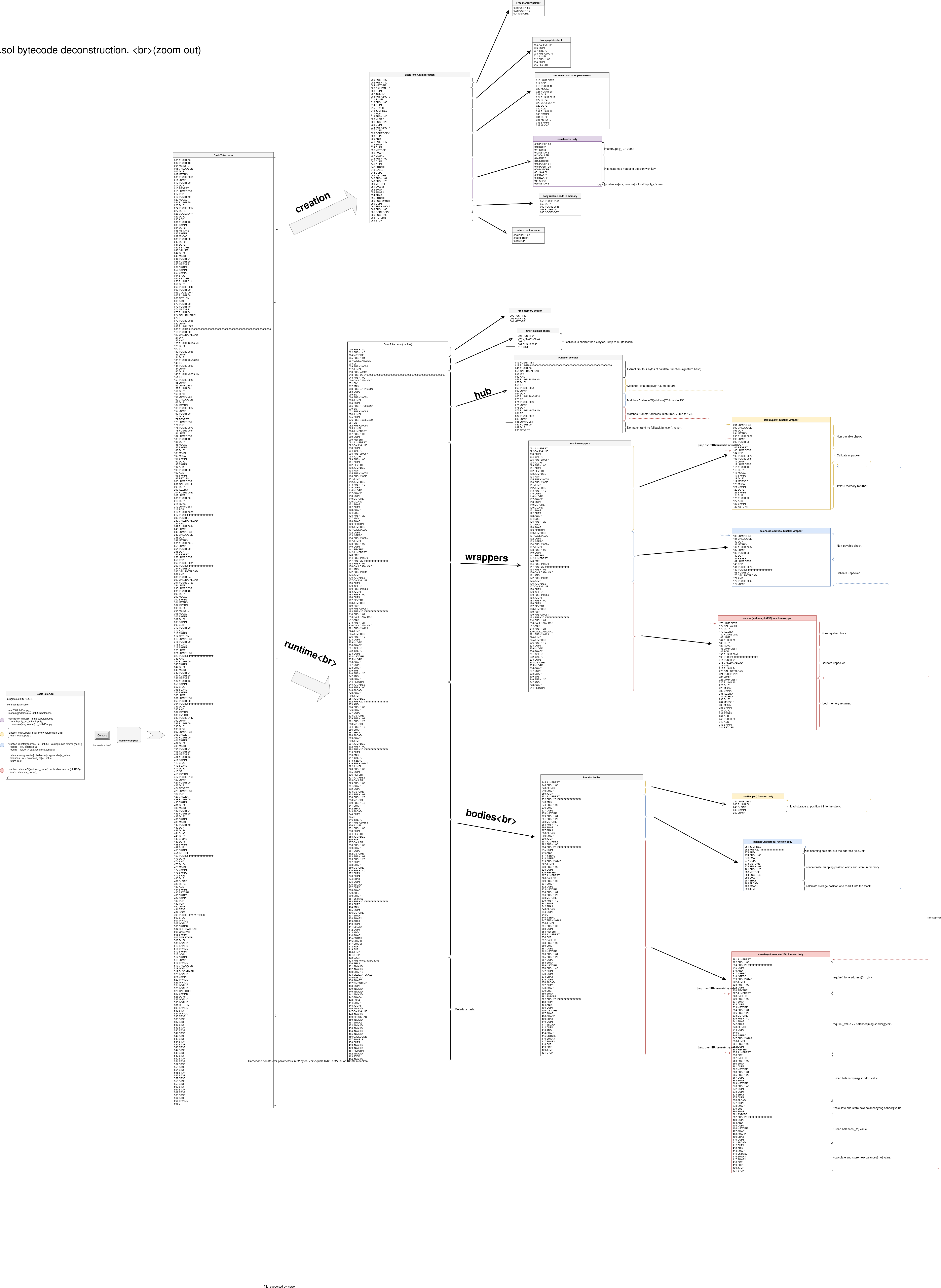
将从一下几个方面对一个合约的opcode结构进行介绍:
总体介绍 —>Creation & Runtime —> 函数selector —> 函数 wrapper —> 函数体分析 —>元数据哈希
Creation & Runtime
- Creation 部分是编译器编译好后的创建合约代码,主要执行了合约的构造函数,并且返回了合约的Runtime代码,以及payable部分的检查。一个智能合约不一样的地方主要是constructor body部分。

- Runtime是真正执行的代码部分,包含了selector、wrapper、function body 和metadata hash 四个部分
函数selector
函数选择器也可以看作是一个路由,内容判断了用户是要调用哪一个函数。
在选择执行函数之前还需要进行内存申请和msg.data的长度检查,是否小于4个字节,若小于,则不继续执行。

而selector中判断路由的部分,关于函数签名:
假设一个函数是a(uint256){},则使用web3.sha3("a(uint256)");计算出a(uint256)的签名,计算结果为
“0xf0fdf83467af68171df09204c0b00056c1e4c80e368b3fff732778b858f7966d”,之后取前四字节”f0fdf834”作为a(uint256)函数的签名。
根据ABI里的标准,假设用户调用balabceOf(address),参数就会规范成0x70a08231000000000000000000000000ca35b7d915458ef540ade6068dfe2f44e8fa733c这样的格式,前四个字节70a08231就使用路由判断。将selecor中的判断转为伪代码:
70a08231 == msg.data[0x00:0x20] / 0x0100000000000000000000000000000000000000000000000000000000 & 0xffffffff;
如果用户调用的函数不存在,若存在 fallback function, 则执行它,否则revert。
函数wrapper
主要是检查payable部分,解析用户的参数,并调转到真正的函数部分以及通过memory返回函数的return。

函数body
这个部分才是合约的核心部分,也是各个合约不一样的地方。
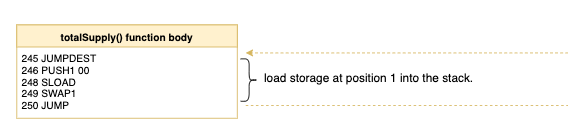
函数体的开头都有JUMPDEST,对应前面wrapper的jump,中间就是函数的具体逻辑。
元数据哈希
这一部分可参见官方文档合约的元数据 — Solidity develop 文档
最后这一段被解析成字节码,但是其中有很多被解析为invalid,实际上这只是一个串0xa1 0x65 'b' 'z' 'z' 'r' '0'开头的hash值。就是一个字符换,所以很多字节码解析不了。

ida静态调试
之前经常使用这个在线的反编译工具,但是后来遇到网页502,突然意识到没有网络的情况下,本地的反编译是必不可少的。这一章节将对使用ida反编译合约进行说明。
示例代码:
pragma solidity ^0.4.18;
contract Debug {
address public owner;
uint public prize;
function setOwner() {
owner = msg.sender;
}
function getOwner() constant public returns (address) {
return owner;
}
function add(uint p) public {
prize += p;
}
}
使用remix进行编译(或者使用solc命令),获得字节码:
0x60806040526004361061006d576000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff1680631003e2d21461007257806340caae061461009f578063893d20e8146100b65780638da5cb5b1461010d578063e3ac5d2614610164575b600080fd5b34801561007e57600080fd5b5061009d6004803603810190808035906020019092919050505061018f565b005b3480156100ab57600080fd5b506100b46101a2565b005b3480156100c257600080fd5b506100cb6101e4565b604051808273ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16815260200191505060405180910390f35b34801561011957600080fd5b5061012261020d565b604051808273ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16815260200191505060405180910390f35b34801561017057600080fd5b50610179610232565b6040518082815260200191505060405180910390f35b8060016000828254019250508190555050565b336000806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff160217905550565b60008060009054906101000a900473ffffffffffffffffffffffffffffffffffffffff16905090565b6000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff1681565b600154815600a165627a7a72305820ffcbeb40a7a1eba0ca0e3fa0595f44425d193e26057cc8a7385148040bf7d7970029
注意,这里取的是runtime部分,同时开头要加上“0x”,否则ida不能正确解析。
ida 反编译插件安装
下载evm插件https://github.com/crytic/ida-evm, 这里注意ida的版本必须是7.0以上。
- 1.复制
evm-loader.py到%IDA%/loaders文件夹下 - 2.复制
evm-cpu.py和known_hashes.py到%IDA%/procs文件夹下 - 3.重启 IDA
- 4.将上面的编译后的字节码复制到文件中,注意,文件名后缀需要是
bytecode,否则ida识别不了 - 5.使用IDA打开字节码文件
ida 反编译
打开后我们可以看到,function name那个窗口显示了反编译出的set,getowner,setowner,add,owner五个函数,因为我们安装的插件中known_hashes.py,实际上是一个”彩虹表”。下图是类似智能合约的数据流图,可以看到这部分展示的是我们上面说的selector部分,判断要调用哪一个函数。
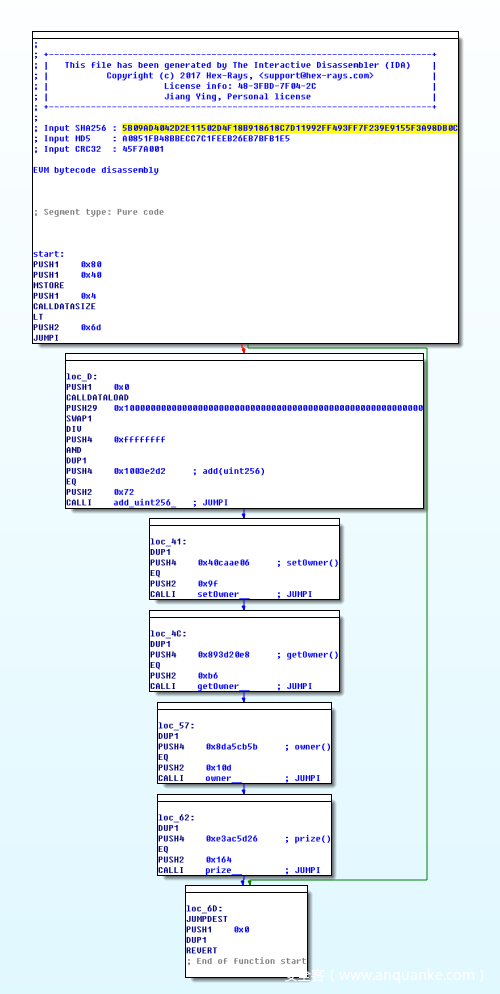
这一段代码几乎所有合约反编译之后都差不多,首先栈压入0x4,然后calldatasize计算msg.data的大小,实际上就是用户所调用的函数(签名),如果这个长度小于4字节,就跳到0x6d,执行revert;否则就跳转到调用的函数,用python简单表示这个过程就是:
def main():
if CALLDATASIZE >= 4:
data = CALLDATA[:4]
if data == 0x1003e2d2:
return add(uint256)
elif data == 0x40caae06:
return setOwner()
elif data == 0x893d20e8:
return getOwner()
elif data == 0x8da5cb5b:
return owner()
elif data == 0xe3ac5d26:
return prize()
else:
pass
else:
revert
跳进具体的函数,查看text view,可以看到每一个函数的内容,我们分别看owner()和getowner(),注释中{}中的内容为栈的内容,左边对应栈顶。
owner():
evm:00000119 loc119: ; CODE XREF: owner_+7↑j
evm:00000119 JUMPDEST
evm:0000011A POP
evm:0000011B PUSH2 0x122
evm:0000011E PUSH2 0x20d //跳转到0x20d
evm:00000121 JUMP
evm:00000122 JUMPDEST
evm:00000123 PUSH1 //0x40,{0x40,storage[0x0]}
evm:00000125 MLOAD //取内存中memory[0x40:0x40+32],{memory[0x40:0x40+32],storage[0x0]}
evm:00000126 DUP1 //memory[0x40:0x40+32],memory[0x40:0x40+32]{memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000127 DUP3 //{storage[0x0],memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000128 PUSH20 0xffffffffffffffffffffffffffffffffffffffff //{0xffffffffffffffffffffffffffffffffffffffff,storage[0x0],memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:0000013D AND //{storage[0x0],memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:0000013E PUSH20 0xffffffffffffffffffffffffffffffffffffffff
evm:00000153 AND //{storage[0x0],memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000154 DUP2 //{memory[0x40:0x40+32],storage[0x0],memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000155 MSTORE //memory[memory[0x40:0x40+32]:memory[0x40:0x40+32]+32]=storage[0x0] //{memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000156 PUSH1 0x20 //{0x20,memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000158 ADD //{0x20+memory[0x40:0x40+32],memory[0x40:0x40+32],storage[0x0]}
evm:00000159 SWAP2 //{storage[0x0],memory[0x40:0x40+32],0x20+memory[0x40:0x40+32]}
evm:0000015A POP //{memory[0x40:0x40+32],0x20+memory[0x40:0x40+32]}
evm:0000015B POP //{0x20+memory[0x40:0x40+32]}
evm:0000015C PUSH1 0x40 { 0x40,0x20+memory[0x40:0x40+32]}
evm:0000015E MLOAD // value = memory[0x40:0x40+32] {memory[0x40:0x40+32],0x20+memory[0x40:0x40+32]}
evm:0000015F DUP1 //{memory[0x40:0x40+32],memory[0x40:0x40+32],0x20+memory[0x40:0x40+32]}
evm:00000160 SWAP2 //{0x20+memory[0x40:0x40+32],memory[0x40:0x40+32],memory[0x40:0x40+32],}
evm:00000161 SUB //{0x20,memory[0x40:0x40+32]}
evm:00000162 SWAP1 //{memory[0x40:0x40+32],0x20}
evm:00000163 RETURN //return memory[memory[0x40:0x40+32]:memory[0x40:0x40+32]+0x20],实际上我们在evm:00000155处注释过这个值就是storage[0x0]},即owner
evm:0000020D loc20D: ; CODE XREF: owner_+14↑j
evm:0000020D JUMPDEST
evm:0000020E PUSH1 0x0 //将0x0压入到栈中
evm:00000210 DUP1 //栈复制0x0
evm:00000211 SWAP1 //交换栈顶两个值
evm:00000212 SLOAD //取出storage[0x0],压入栈顶,覆盖原来栈顶的0x0.
evm:00000213 SWAP1 //{0x0,storage[0x0]}
evm:00000214 PUSH2 0x100 //{0x100,0x0,storage[0x0]}
evm:00000217 EXP //(0x100)^0=1. {0x1,storage[0x0]}
evm:00000218 SWAP1 //{storage[0x0],0x1}
evm:00000219 DIV //storage[0x0]//0x1 {storage[0x0]}
evm:0000021A PUSH20 0xffffffffffffffffffffffffffffffffffffffff //{0xffffffffffffffffffffffffffffffffffffffff,storage[0x0]}
evm:0000022F AND //SLOAD(0) & 0xffffffffffffffffffffffffffffffffffffffff,取了owner的值(address类型)
evm:00000230 DUP2 //{0x122,storage[0x0],0x122},0x122是最开始和0x20d一起压入栈的
evm:00000231 JUMP //跳转到0x122如果有兴趣再看一下getowner()函数,会发现和owner()是一样的。owner是一个全局变量,getowner是获取owner值的公有函数,但是反编译之后的结果是一样的。我们可以推断出
address public a;
等价
function a() public returns (address) {
return a;
}
通过构造不同的测试合约,在使用ida反编译,不清楚的地方可以结合remix的debug进行跟踪,可以加快对OPCODE的逆向速度。
稍微修改上面的代码
pragma solidity ^0.4.18;
contract Debug {
address public owner;
uint public prize;
function setOwner() payable{
owner = msg.sender;
}
function getOwner() constant public returns (address) {
return owner;
}
function add(uint p) public {
prize += p;
}
function (){
prize -= 1;
}
}
在原来的基础上给setOwner()增加了payable,同时增加了一个回退函数,同样进行反编译,我们会发现有payable的函数比没有payable的函数少了一段代码:
evm:000000C3 JUMPDEST
evm:000000C4 CALLVALUE
evm:000000C5 DUP1
evm:000000C6 ISZERO
evm:000000C7 PUSH2 0xcf
evm:000000CA JUMPI
evm:000000CB loc_CB: ; CODE XREF: getOwner__+7↑j
evm:000000CB PUSH1 0x0
evm:000000CD DUP1
evm:000000CE REVERT
很容易理解,CALLVALUE值如果为0,就跳转继续执行,否则revert。
那为什么不是在有payable的函数前增加一段判断,CALLVALUE为0就revert,否则执行?对于一个带有payable的函数,如果用户在调用的时候,没有传入value,是不是也能成功调用呢?
查看owner值:
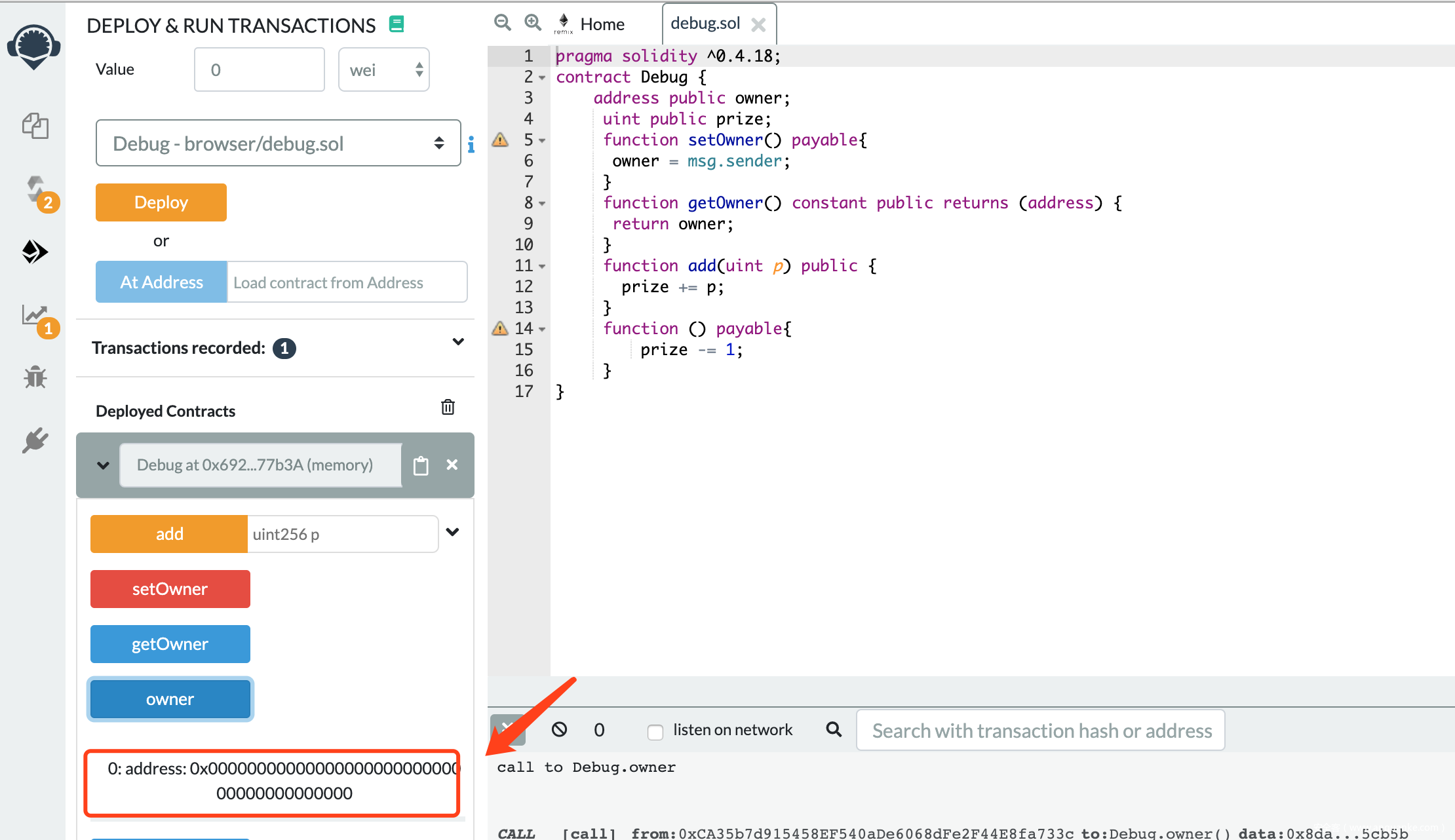
不添加value调用setowner,查看owner值:
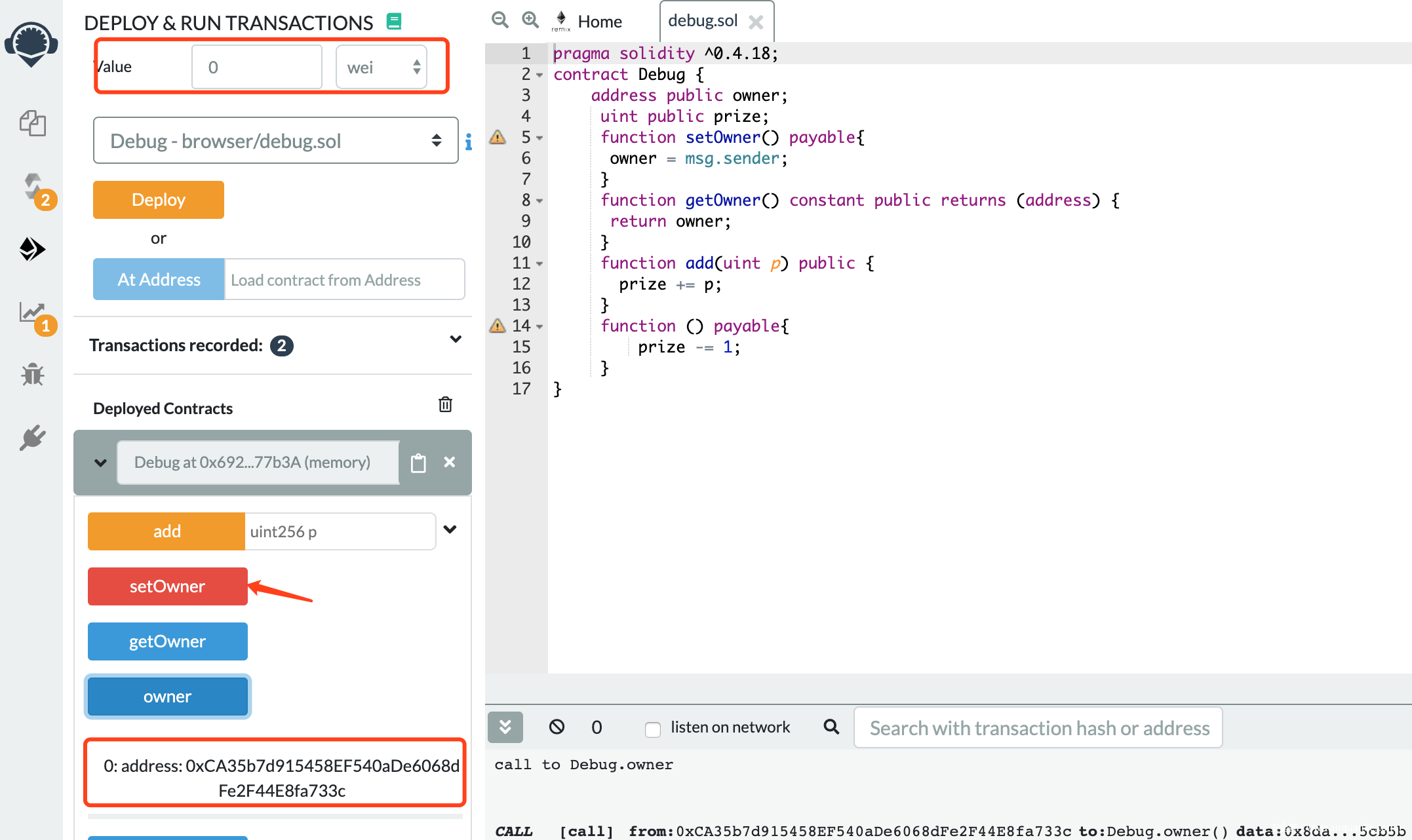
调用成功,因此,对于payable函数,不附加value是可以调用的,除非在函数内部另作判断。
然后我们看回退函数,反编译结果和之前的差别,在start()函数在graph view中,末尾会多出一段:
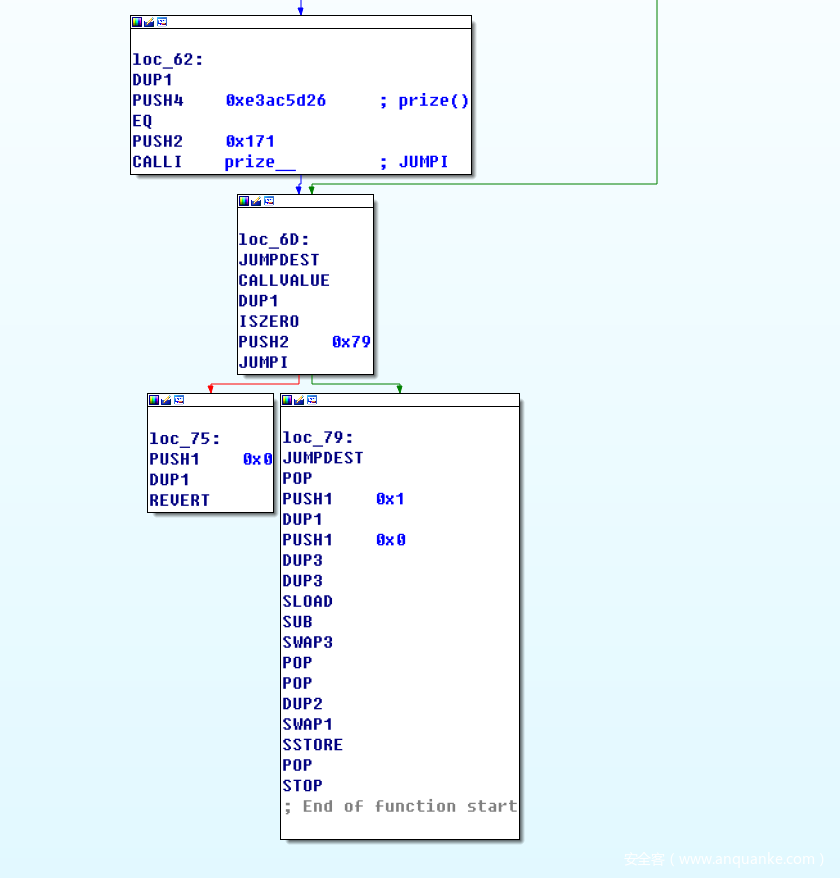
上述过程判断msg.value是否为0,若为0,就执行回退函数中prize-1,否则revert。即当用户调用的函数在selector中一个都没有匹配上的时候,同时msg.value为0,就会执行回退函数。
def main():
if CALLDATASIZE >= 4:
data = CALLDATA[:4]
if data == 0x1003e2d2:
return add(uint256)
elif data == 0x40caae06:
return setOwner()
elif data == 0x893d20e8:
return getOwner()
elif data == 0x8da5cb5b:
return owner()
elif data == 0xe3ac5d26:
return prize()
assert msg.value == 0
prize -= 1
exit()
说到回退函数就想到了重入漏洞,为什么用call.value向合约转账时也可以触发回退函数呢?实际上,为了能够让call.value执行成功,需要一个带有payable的回退函数,因为在所有函数都没有匹配上的时候,如果回退函数没有payable,就还要执行assert msg.value == 0,相反,带上payable的回退函数就能够被执行,同时可以接受转账。
function () payable{
prize -= 1;
}
def main():
if CALLDATASIZE >= 4:
……
elif data == 0xe3ac5d26:
return prize()
//assert msg.value == 0 ,没有了这步,可以转账了,同时也可以直接执行回退函数了
prize -= 1
exit()
然后巧妙的在回退函数里面再次调用call.value,就回再次调用回退,又因为通常判断在上层,因此一直循环转账到把gas消耗光。
小结
以上内容是对之前学习别人分享的智能合约文章的一些总结和思考,其实看了编译后的opcode,我们会发现有很多没有用的指令,比如加了1,又减1等。可以通过上面这种方式比较Enable optimization的编译结果有什么不一样?如何写出节省gas的智能合约?以及不同版本编译器编译结果的差别?下一篇将会继续探索。
参考:
https://paper.seebug.org/640/
https://ethervm.io/
Deconstructing a Solidity Contract —Part I: Introduction – OpenZeppelin blog
Deconstructing a Solidity Contract — Part II: Creation vs. Runtime – OpenZeppelin blog
Deconstructing a Solidity Contract — Part III: The Function Selector – OpenZeppelin blog
Deconstructing a Solidity Contract — Part IV: Function Wrappers – OpenZeppelin blog
Deconstructing a Solidity Contract — Part V: Function Bodies – OpenZeppelin blog
Deconstructing a Solidity Contract — Part VI: The Metadata Hash – OpenZeppelin blog







发表评论
您还未登录,请先登录。
登录