

简介
我们在Check Point Research从事的每个研究项目的目标之一就是对软件的工作方式深入的分析:它们包含哪些组件?它们是否存在漏洞?攻击者如何利用这些漏洞?更重要的是,我们如何防范此类攻击?
在我们的最新研究中,我们提出了一种称为“Safe-Linking”的安全机制,用来保护malloc()的单向链表不被攻击者篡改。我们已经向核心开源代码库的维护者介绍了我们的方法,现在,它已经集成到最常见的标准库中:glibc(Linux)和uClibc-NG(嵌入式系统)。
需要注意的是,Safe-Linking不是万能的,它可以阻止针对现代堆实现的所有利用尝试。但是,这朝着正确方向迈出了一步。根据我们过去的经验,这种特定的缓解措施会阻止我们多年来展示的几个主要漏洞。
背景
在二进制利用的早期,堆内部数据结构就一直是攻击者的主要目标。通过理解堆的malloc()和free()的工作方式,攻击者能够利用堆缓冲区中的早期漏洞,
如线性缓冲区溢出,将其转变为更强的利用原语如任意写(Arbitrary-Write)。
在2001年的Phrack文章中详细介绍了此示例:Vudo Malloc Tricks。本文介绍了多个堆实现的内部原理,并描述了现在的“Unsafe-Unlinking”。修改双向链表的FD和BK指针的攻击可以使用unlink()操作来触发任意写(例如,Small-Bins),从而在目标程序上执行代码。
实际上,2005年的glibc 2.3.6版本对这个的利用进行了修复,称为““Safe-Unlinking”。它在unlink之前先验证了双向链表的完整性,如下图所示:

尽管这一利用在15年前被阻止,但当时没有人提出类似的解决方案来保护单向链表的指针。利用这一点,攻击者将注意力转移到这些未受保护的单向链表上,如Fastbin和TCache。破坏单向链表允许攻击者获得任意Malloc原语,即在任意内存地址中分配一个小的可控地址。
在本文中,我们结合了近20年的安全漏洞,并演示了我们如何创建一种安全机制来保护单向链表。
在深入研究Safe-Unlinking的设计之前,让我们回顾一下针对Fast-Bins的利用。
Fast-Bin 利用案例 – CVE-2020-6007:
在研究智能灯泡的过程中,我们发现了一个基于堆的缓冲区溢出漏洞:CVE-2020-6007。在这个漏洞的利用过程中,我们演示了攻击者如何利用未受保护的Fastbin单链表将堆缓冲区溢出转变为更强大的任意写(Arbitrary-Write)。
在我们的测试案例中,堆是dlmalloc实现的,具体的说是编译为32位版本的uClibc。下图显示了堆实现所使用的数据:

1.当分配和使用缓冲区时,前两个字段存储在用户的数据缓冲区之前。
2.当释放缓冲区并将其置入Fast-Bin中时,也会使用第三个字段,并指向Fast-Bin链表中的下一个节点。此字段位于用户缓冲区的前4个字节处。
3.当缓冲区被释放并且没有存入FastBin中时,第三和第四个字段都被用作双链表的一部分。这些字段位于用户缓冲区的前8个字节处。
Fast-Bins 是一个由各种大小的“Bins”组成的数组,每个都包含一个单链表,最多不超过特定大小。最小的bin大小包含0x10字节的缓冲区,下一个包含0x11到0x18字节的缓冲区,依此类推。
溢出方案
这个漏洞为我们提供了一个基于堆的缓冲区溢出,我们的计划是溢出FastBin中相邻的空闲缓冲区。下图显示了溢出之前的缓冲区状况:

图3:我们可控缓冲区(蓝色)放置在freed的缓冲区(紫色)之前
溢出后的两个缓冲区:

图4:我们的溢出修改了freed缓冲区的size和ptr字段(以红色显示)
我们希望修改的是FastBin的单链表指针。通过将这个指针更改为我们自己的任意地址,我们可以触发堆,使其认为新释放的chunk现在存储在那里。图5显示了Fast-Bin破坏的单链表,在堆中看起来如下:
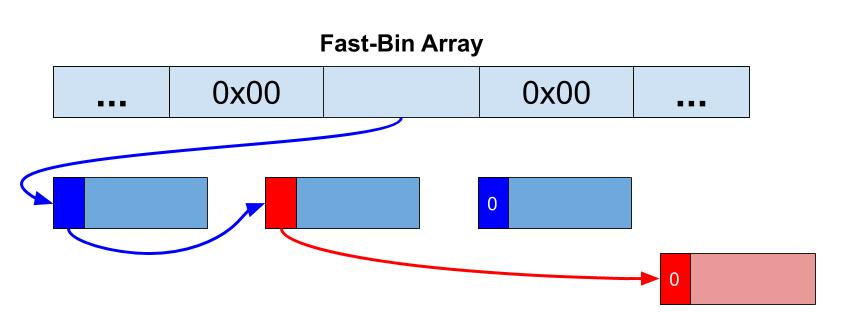
图5:红色标记FastBin破坏的单链表
通过触发与FastBin大小相匹配的分配,我们获得Malloc Where原语。
注意:可能很多人会说,我们获得的Malloc-Where原语受到限制,因为“ Free Chunk”应以与当前Fast-Bin匹配的size字段开头。但是,此附加的检查仅在glibc中实现,而在uClibc-NG中却没有。因此,对于我们的Malloc-Where原语,没有任何限制。
Safe-Linking 介绍
在完成智能灯泡的研究后,在36C3开始之前,我有一些空闲时间,我的计划是解决一些来自最近CTF比赛的pwn挑战。相反,我发现自己在重新思考最近开发的exploit。近十年来,我一直以同样的方式利用基于堆的缓冲区溢出,总是以堆中的单链表为目标。即使在CTF挑战中,我仍然关注TCache易受攻击的单链表。当然,有某种方法可以减轻这种流行的利用原语。
这就是Safe-Linking的出现。Safe-Linking利用了地址随机化(ASLR)中的随机性来“sign”指针,与chunk对齐完整性检查结合使用时,这种新技术可以防止指针被劫持。
我们的解决方案可防止现代漏洞中经常使用的3种常见攻击:
- 1.部分指针覆盖:修改指针的低字节(Little Endian)。
- 2.全指针覆盖:劫持指向任意位置的指针。
- 3.未对齐的chunks:将list指向未对齐的地址。
威胁建模
在我们的威胁模型中,攻击者具有以下功能:
- 1.堆缓冲区上的受控缓冲区上溢/下溢。
- 2.相对任意写堆缓冲区
需要注意的是,我们的攻击者不知道堆位于何处,因为ASLR将堆的基地址与mmap_base一起随机分配。
我们的解决方案提高了门槛并阻止了攻击者基于堆的攻击尝试。一旦部署,攻击者必须以堆泄漏/指针泄漏的形式拥有附加功能。我们保护的一个示例场景是位置相关二进制文件(加载时不带ASLR),它在解析用户输入时有堆溢出。在我们之前的灯泡研究示例中,就是这种情况。
到目前为止,攻击者仅通过依赖二进制文件的固定地址,就能够在不泄漏堆的情况下利用这些目标,并且只对堆的分配进行最小程度的控制。我们可以阻止这种利用尝试,并在将堆分配重定向到目标二进制文件中的固定地址时,利用堆的ASLR获得随机性。
保护
在Linux机器上,堆是通过mmap_base随机分配的,其逻辑如下:
random_base = ((1 << rndbits) - 1) << PAGE_SHIFT)
rndbit 在32位Linux上默认为8,在64位上默认为28。
我们将单链表指针存储为的地址L。现在,我们定义以下计算:
Mask := (L >> PAGE_SHIFT)
根据上面显示的ASLR公式,移位将来自内存地址的第一个随机位定位在掩码的LSBit上。
这就引出了我们的保护方案。我们用P表示单链表指针,方案如下:
- 1.PROTECT(P) := (L >> PAGE_SHIFT) XOR (P)
- 2.*L = PROTECT(P)
代码版本:
#define PROTECT_PTR(pos, ptr, type)
((type)((((size_t)pos) >> PAGE_SHIFT) ^ ((size_t)ptr)))
#define REVEAL_PTR(pos, ptr, type)
PROTECT_PTR(pos, ptr, type)
这样,地址L中的随机位被放置在存储的受保护指针的LSB的顶部,如图6所示:
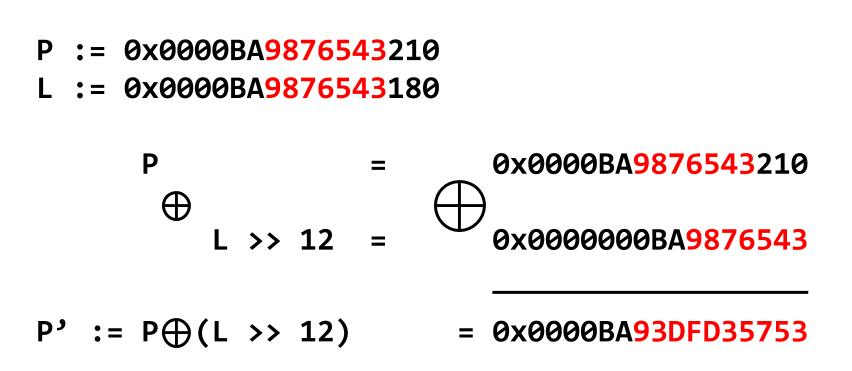
图6:掩码指针P被随机位覆盖,如红色所示
这个保护层防止攻击者在不知道随机的ASLR位(红色显示)的情况下修改指针到受控制的值。
但是,如果您注意一下,就会很容易发现我们在 Safe-Unlinking 机制方面处于劣势。虽然攻击者不能正确地劫持指针,但是我们也受到限制,因为我们不能检查是否发生了指针修改。这是进行额外检查的地方。
堆中所有已分配的chunk均与已知的固定偏移对齐,该偏移通常在32位上为8个字节,在64位上为16个字节。通过检查每个reveal()ed指针是否对齐,我们添加了两个重要的层:
- 攻击者必须正确猜测对齐位。
- 攻击者无法将chunk指向未对齐的内存地址。
在64位机器上,这种保护导致攻击尝试失败16次中的15次。如果我们返回到图6,我们可以看到受保护的指针的值以半字节0x3结尾,否则他将破坏该值并使对齐检查失败。
即使是单独使用,此对齐检查也可以防止已知的利用原语,例如本文中描述的原语,该原语描述了如何将Fast-Bin指向malloc()hook以立即获取代码执行。
注:在intel CPU上,glibc在32位和64位体系结构上仍然使用0x10字节的对齐方式,这与上面刚刚描述的常见情况不同。这意味着对于glibc,我们在32位上提供了增强的保护,并且可以阻止16次攻击尝试中的15次。
示例
下图显示了我们提交给glibc的初始补丁的片段:
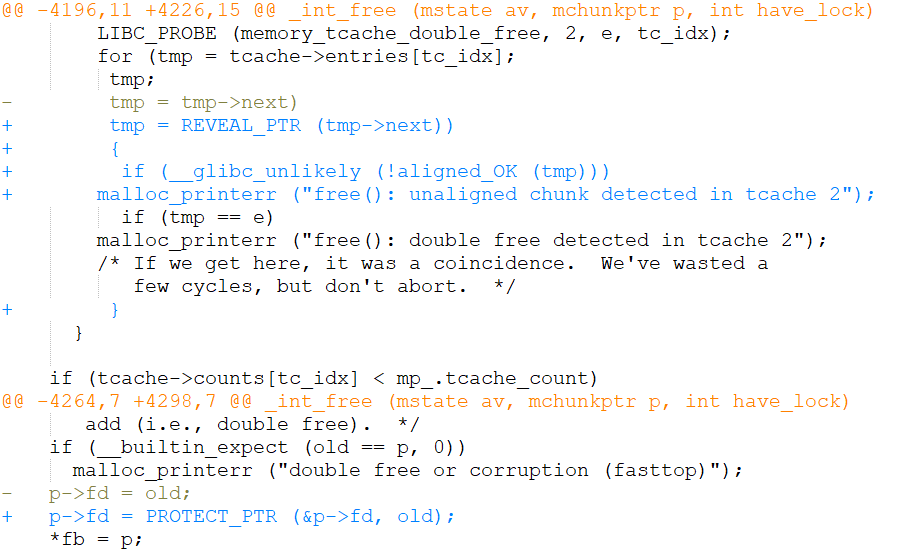
图7:来自补丁程序初始版本的示例代码片段
虽然补丁已经被清除,但是我们仍然可以看到保护glibc的TCache所需的代码修改是非常容易的。这就引出了下一部分基准测试。
基准测试
基准测试表明,添加的代码总计为:对于free()2-3个asm指令和对于malloc()3-4个asm指令。在glibc上,即使在GCP中的单个vCPU上总计10亿次malloc()/ free()操作,这种更改可以忽略不计,测试在64位版本的库上运行。下面是在同一GCP服务器上的大小为128 (0x80)字节的缓冲区上运行glibc的基准测试malloco-simple后的结果:
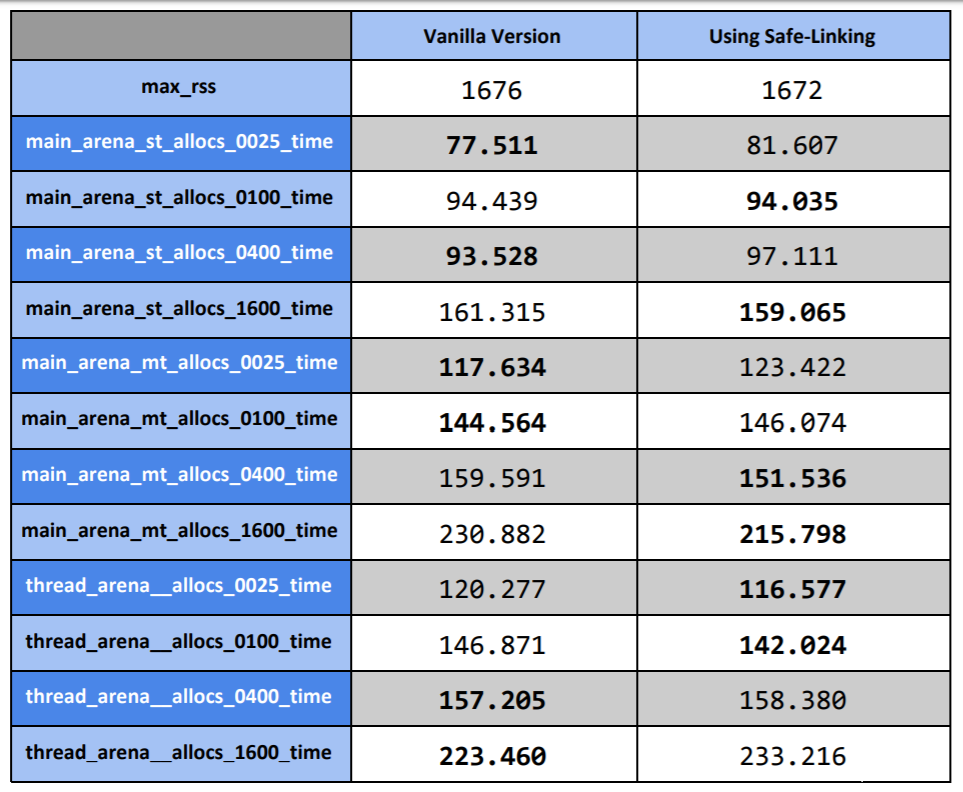
图8:glibc malloc-simple测试结果
每次测试的更快结果用粗体标记。正如我们所看到的,结果几乎是一样的,而且在一半的测试中,修补版本的速度更快,这实际上没有任何意义。这通常意味着服务器上的噪音级别远高于所添加功能对整体结果的实际影响。简而言之,这意味着我们新功能所增加的开销可以忽略不计,这是个好消息。
再举一个例子,对tcmalloc(gperftools)测试的最坏影响是1.5%的开销,而平均值仅为0.02%。
这些测试结果归因于所建议机制的精简设计:
- 1.该保护没有内存开销。
- 2.保护不需要初始化。
- 3.不需要特殊的随机性来源。
- 4.保护只使用L和P,它们都在指针需要被protect()或reveal()时出现。
需要特别注意的是,FastBin和TCache都使用单链表来保存数据,这一点在glibc的文档中有详细说明。它们只支持put/get API,没有通用的功能遍历整个列表并保持完整。虽然这种功能确实存在,但它只用于收集malloc统计信息(mallinfo),因此访问单链接指针的额外开销可以忽略不计。
回顾我们的线程模型
对齐检查减少了攻击面,并要求Fastbin或TCache的chunk指向一个对齐的内存地址。这直接阻止了已知的利。
就像Safe-Unlinking一样,我们的保护依赖于这样一个事实:攻击者不知道合法的堆指针是什么样子的。在双链表方案中,能够伪造内存结构并知道有效堆指针的结构的攻击者可以成功伪造有效的FD/BK对指针,该指针不会触发任意写原语,但是允许在攻击者控制的地址上创建一个chunk。
在单链表场景中,没有指针泄漏的攻击者将无法完全控制重写的指针,这是因为保护层依赖于从部署的ASLR继承的随机性。建议PAGE_SHIFT将随机位放在存储的指针的第一个位上。与对齐检查一起,这在阻止了攻击者更改保存的单链指针的最低位/字节(小端)。
Chromium’s MaskPtr()
我们的目的是将Safe-Unlinking合并到主要的开放源代码中,这些源代码实现了包含单链表的各种堆。其中一个这样的实现是由Google开发的tcmalloc,它当时只是作为gperftools存储库的一部分开放源码的。在将我们的补丁提交给gperftools之前,我们决定先看看Chromium的Git存储库,以防它们可能使用不同版本的tcmalloc。事实证明,他们做到了。
我们直接查看结果:
- 1.gperftools自2007年以来已经发布了公开版,最新版本是2.7.90。
- 2.Chromium的tcmalloc看起来好像是基于gperftool的2.0版本。
- 3.2020年2月,在我们已经向所有开源提交了补丁程序之后,Google发布了一个官方的TCMalloc GitHub存储库,该存储库与之前的两种实现都不相同。
在检查Chromium的版本时,我们发现他们的TCache现在不仅基于双向链表(现在称为FL,for Free List),而不是基于单链表(最初称为SLL),还添加了一个特别的函数MaskPtr()。仔细查看他们2012年发布的问题,可以看到以下代码片段:
inline void* MaskPtr(void* p) {
// Maximize ASLR entropy and guarantee the result is an invalid address.
const uintptr_t mask =
~(reinterpret_cast<uintptr_t>(TCMalloc_SystemAlloc) >> 13);
return reinterpret_cast<void*>(reinterpret_cast<uintptr_t>(p) ^ mask);
}
代码与我们的PROTECT-PTR实现非常相似。此外,这个补丁的作者特别提到“这里的目标是防止使用freelist攻击”
看起来Chromium的安全团队引入了他们自己的Safe-Linking到Chromium的tcmalloc的版本,他们在8年前就这么做了,这让人佩服。
通过检查他们的代码,我们可以看到他们的掩码是基于代码部分(TCMalloc_SystemAlloc)中的一个指针(随机值),而不是实现中使用的堆位置。另外,它们将地址移位硬编码值13,并且还反转其掩码的位。由于找不到他们设计的文档,我们可以从代码中读取位反转用于确保结果是无效地址。
通过阅读他们的日志,我们还了解到他们估计这个特性的性能开销小于2%。
与我们的设计相比,Chromium的实现包含了一个额外的内存引用和一个额外的asm指令,用于位反转。不仅如此,它们的指针掩码无需额外的对齐检查即可使用,因此代码无法在不导致进程崩溃的情况下提前捕获指针修改。
总结
我们测试了补丁程序,以将建议的缓解措施成功集成到最新版本的glibc(ptmalloc),uClibc-NG(dlmalloc),gperftools(tcmalloc)和更高版本的Google全新TCMalloc。此外,我们还指出了Chromium的开发团队使用我们提交给gperftools的版本的“Safe-Linking”,希望我们针对gperftools的性能提升能够在Chromium版本中发挥作用。
当我们开始研究Safe-Linking时,我们相信将Safe-Linking集成到这3个(现在为4个)主流库中,将会导致其他库在开源社区和行业内的封闭软件中得到更广泛的采用。自2012年以来,基础版本的Safe-Linking已嵌入Chromium中,这一事实证明了该解决方案的成熟性。
以下是整合的结果,与撰写此博客文章时的结果相同。
glibc(ptmalloc)
状态:集成。将于2020 年8月以2.32版发布。
激活:默认情况下打开。
GNU的glibc项目的维护者非常积极响应合作。主要的障碍是签署法律文件,这将使我们作为公司的员工可以向GNU的存储库捐赠GPL许可的源代码。一旦解决了这个问题,过程就非常顺利了,我们的补丁的已提交到最新版本库中,可以在即将发布的版本中使用。
我们要感谢glibc的维护者在整个过程中给予的合作。他们愿意将一个“默认打开”的安全特性集成到他们的项目中,这令人振奋,尤其是与我们最初的期望相比,以及与我们从其他存储库收到的响应相比。
uClibc-NG(dlmalloc)
状态:已在v1.0.33版本中发布。
激活:默认情况下打开。
向uClibc-NG提交我们的功能非常容易,并且已将其立即集成到此commit中。我们可以自豪地说,安全链接已作为uClibc-NG版本v1.0.33的一部分发布。如果我们回到对智能灯泡的研究,此功能将阻止我们的利用,并迫使我们在产品中发现其他漏洞。
我们再次感谢uClibc-NG的维护者在此过程中的合作。
gperftools(tcmalloc)
现状:正在进行整合。
激活:默认为关闭。
尽管我们之前提到了Chromium的MaskPtr()功能(自2012年起可用),但该功能并未在tcmalloc的两个公开版本中找到它。因此,我们很幸运能向gperftools的tcmalloc实现提交Safe-Linking。
由于gperftools存储库的复杂状态,现在谷歌的官方TCMalloc存储库是公开的,这个过程正在取得进展,但是比较缓慢。在2020年1月开始的pull请求中,您可以看到我们将该特性集成到存储库中的努力。最初的反应是我们担心的:我们的“破坏性能”功能。提醒一下,在使用存储库的标准测试套件时,最坏的情况是产生1.5%的开销,而平均只有0.02%。
最后,我们勉强决定将这个功能添加为“默认关闭”,希望有一天会有人自己激活这个功能。这个特性还没有被合并,但是我们希望它在不久的将来会被合并。
我们仍然要感谢这个项目的唯一维护者,他提供了所有必要的准备工作,以便允许用户使用配置选项来启用Safe-Linking。
TCMalloc(tcmalloc)
状态:已拒绝。
激活: N / A。
我们在此pull请求中将补丁提交给了TCMalloc ,但不幸的是,该请求被立即拒绝了。我们再一次听到“此功能的性能成本太高而无法合并”,并且即使作为“默认关闭”可配置功能,他们也不会将其集成:虽然macro-protected,它增加了另一个配置,需要构建并定期测试,以确保一切都保持工作。我们在谷歌中找不到任何能够帮助我们解决与存储库维护者之间的冲突的代表,所以我们让它保持原样。
不幸的是,谷歌最常见的malloc()的实现,在大多数C/C++项目中使用(如TCMOLLC文档中提到的),并没有集成一个安全特性,这使得在他们的项目中利用漏洞变得更加困难。
最后说明
Safe-Linking并不是阻止所有针对现代堆实现的攻击尝试的灵丹妙药。然而,这是朝着正确方向迈出的又一步。通过迫使攻击者在开始基于堆的攻击之前就存在指针泄漏漏洞,我们逐渐提高了标准。
从我们过去的经验来看,这种特定的缓解会阻止我们多年来利用的几个主要漏洞,从而将“破坏”的软件产品转变为“无法利用”(至少在我们各自研究项目时存在漏洞)。
还需要注意的是,我们的解决方案不仅限于堆实现。它还可以通过位于用户缓冲区附近的单链表指针来使危险的数据结构获得完整性保护,而不会增加任何内存开销,并且对运行时的影响可以忽略不计。这个解决方案可以很容易地扩展到ASLR系统中的每个单链表。
从我们在2019年底首次解决此问题开始,到设计安全缓解措施,最后将其集成为安全功能,这是一段艰难的旅程,默认情况下,该功能可在世界上两个最著名的libc实现中使用:glibc和uClibc-NG。最后,我们在集成此功能方面取得了比最初预期更好的结果,因此,我们再次感谢所有帮助实现此想法的维护者和研究人员。我们逐渐提高了漏洞利用水平,并帮助保护全世界的用户。







发表评论
您还未登录,请先登录。
登录