

本文是《AI与安全》系列文章的第7篇。
如今,机器学习已演化为了一种服务模式,即机器学习即服务(Machine learning as a service)。互联网公司通过模型调用接口来满足用户对各类机器学习模型的使用需求,如Google的多种预测API、亚马逊机器学习(AmazonML)、MicrosoftAzure机器学习 (Azure ML)等。在这些平台上,使用者不清楚模型和训练算法的实现细节,仅能进行简单的模型选择工作,模型的结果也高度依赖于输入模型的数据质量和打标结果。机器学习服务提供商通过用户调用该API的费用来收费,因此对于用户而言,这些API接口都是黑盒。

MLaaS架构
针对这样的黑盒,攻击者有办法获取到模型的细节或是模型背后的数据吗?
答案是,有的,而且不止一种。
在本文中,我们就将介绍黑客破坏模型机密性的三种方法,分别是针对模型的模型萃取攻击(Model Extraction Attacks)和针对数据的成员推理攻击(Membership Inference Attacks)和模型逆向攻击(Model Inversion Attack)。

机器学习模型的机密性指:机器学习系统必须保证未授权用户无法接触到模型的相关信息,包括模型本身的信息(如模型参数、模型架构、训练方式等)和模型用到的训练数据。
1-模型萃取攻击
模型萃取攻击(Model Extraction Attacks),也称为模型提取攻击,是一种攻击者通过循环发送数据并查看对应的响应结果,来推测机器学习模型的参数或功能,从而复制出一个功能相似甚至完全相同的机器学习模型的攻击方法。
这种攻击方法由Tramèr等人在2016年提出,并发表于信息安全顶级会议Usenix上,并分别展示了针对函数映射类模型(LR、SVM、神经网络)、决策树模型和不输出置信度的模型的提取方式。
1.1 针对函数映射类模型
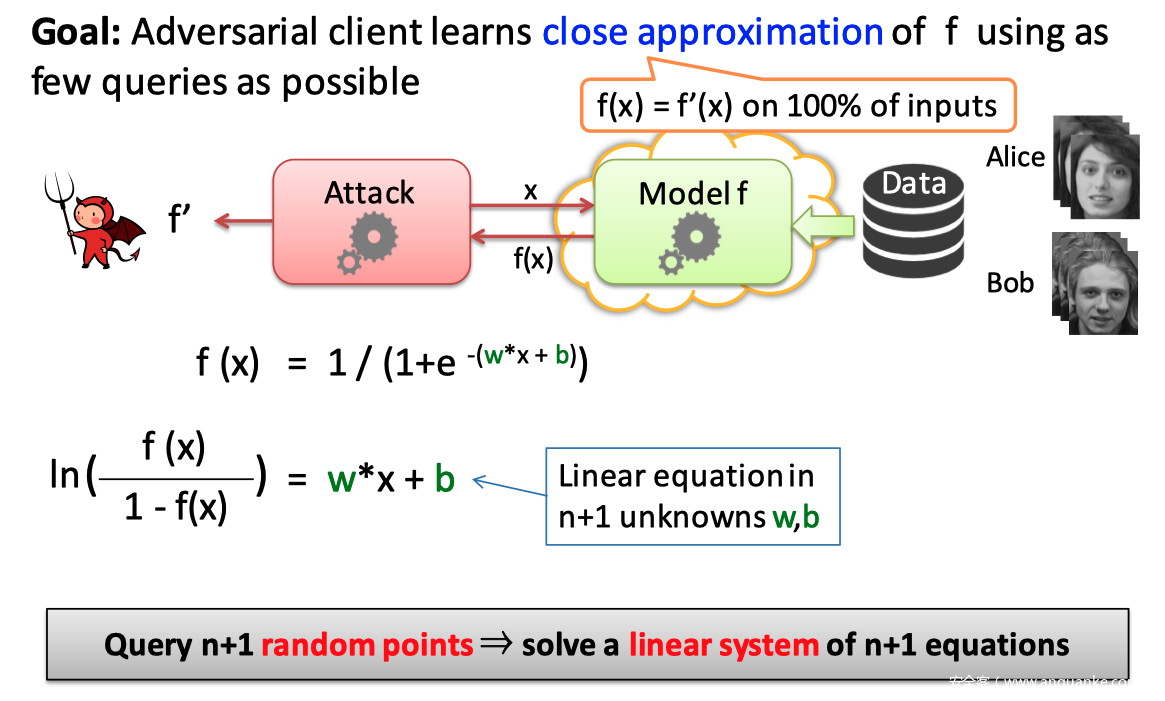
对于逻辑回归(LR)、支持向量机(SVM)、神经网络(NN)这类算法而言,我们可以将其模型看做是一个函数f(x),模型的输入是x,模型的输出结果是f(x),模型在训练过程中通过优化函数f(x)里的参数来达到分类的目的。因此,如若我们想要对这类模型进行萃取,只需求解f(x)里的参数值就可以了,实际上就是一个解方程的过程。
如对于下图中的逻辑回归模型:
$f(x) = frac{1}{1 + e^{-(w * x + b)}}$
函数的参数是 w 和 b,其中w是n维的权重向量,b 是偏置向量。我们对 sigmod 函数进行求反,得到一个线性函数 $w*x + b$,因为$w$ 是n维的权重向量,b是1维的偏置向量,因此总共有n+1个参数需要求解,也就是说,至少需要n+1个等式就可以借出这个方程,所以从理论上而言,我们只需要查询 n+1 次便可窃取到这个逻辑回归模型。
而对于多分类模型,只需要举一反三即可。
多分类模型要完成对 c(c>2)个类别进行分类,置信度则是输入在每个类别的概率分布,输出的置信度是 n 维向量。则其输出的置信度公式为
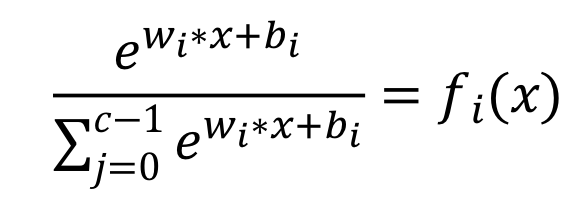
其未知参数有 c*(n+1)个(每个类别存在 n+1 个未知数),且为非线性函数。换而言之,我们通过多次访问构建的方程组是非线性方程组,且每个方程都是超越方程。针对这种情况,我们可以利用梯度下降方法来实现对方程的求解:构造一个损失函数为凸函数,转化为凸优化问题求解,其中全局最优解为模型的参数。

1.2 针对决策树
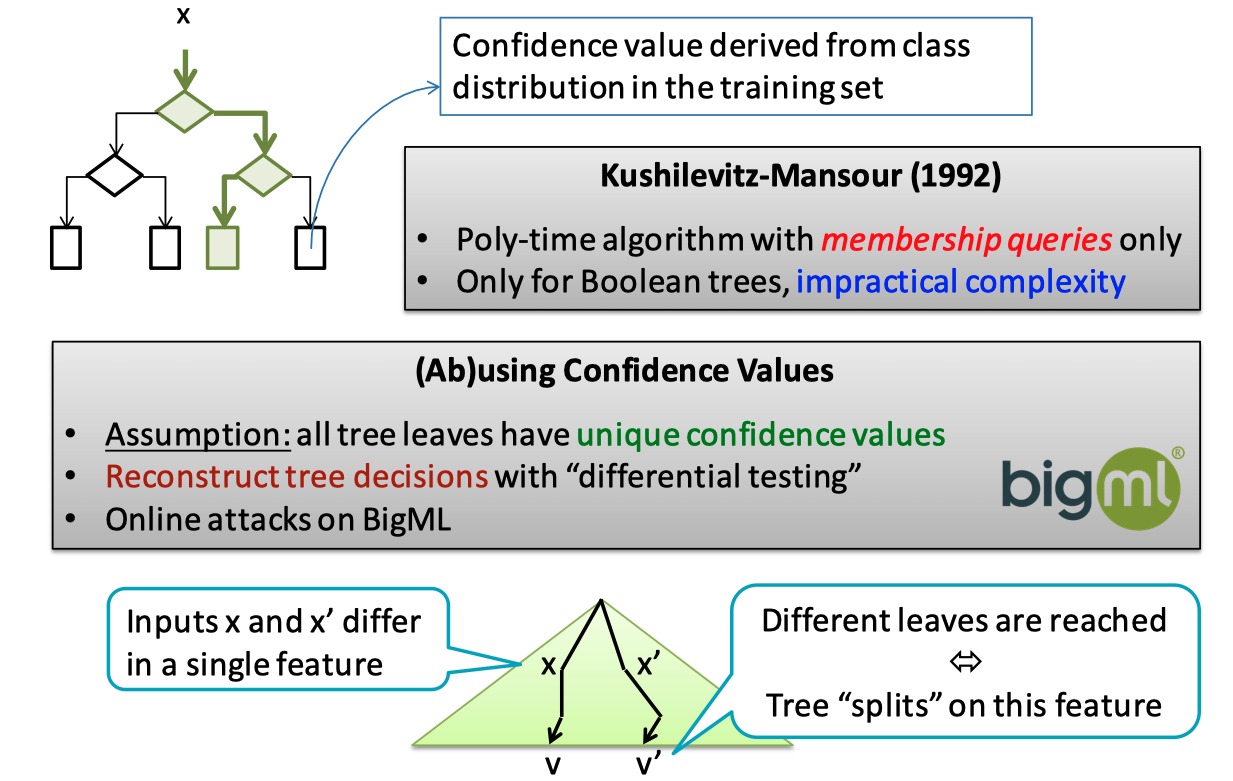
与回归模型相反,决策树不计算输入值属于某个分类的概率,而 是将输入分隔成多个离散区域,并给每个区域分配标签和置信度值。 决策树上每个叶子节点都有其对应的置信度值。假设每个叶子节点都有不同的置信度值,则可利用置信度作为决策树叶子节点的伪标识。同时,很多 MLaaS 提供商为 了提升 API 访问的可访问性,即使输入数据是部分特征依然可以得到输出结果。这就为针对决策树进行路径寻找攻击提供了必要条件。
简单来说,针对决策树模型的提取是自顶向下的,首先我们获取到决策树根节点的标识,之后依次设置不同的特征来到达不同的节点,递归搜索决策树的结构特征。
1.3 针对不输出置信度的模型
为了避免遭受到模型萃取攻击,部分云厂商不再提供机器学习预测结果的置信度,而只给出“是”或“否”的答案。但论文作者表示,这类模型仍然可能遭受到模型萃取攻击。
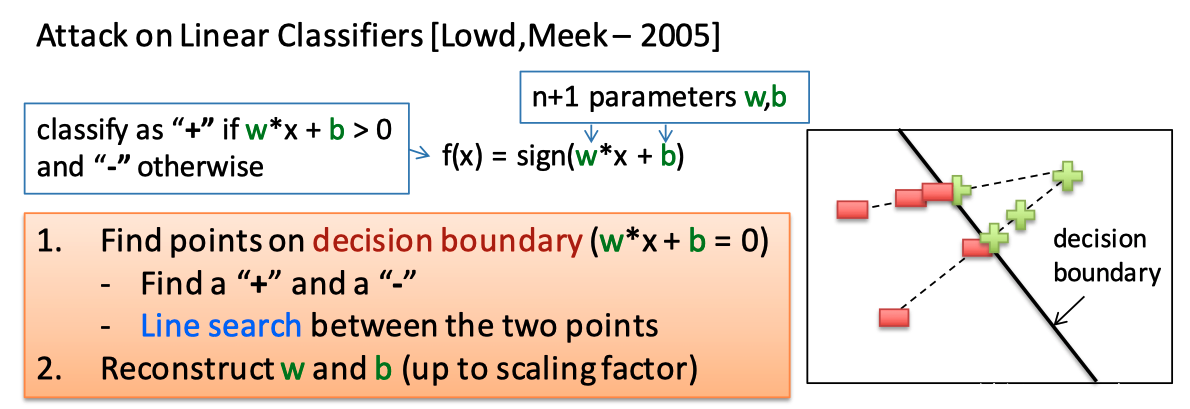
如上图所示,首先,攻击者随机生成样本并输入目标模型,得到预测结果。然后将这些数据作为训练集,在本地训练一个和目标模型同类的本地模型,将靠近本地模型分类边界的数据点抽取出来,再对目标模型进行访问,获得新的训练集,并继续更新本地模型,直到本地模型和目标模型的误差足够小。
这样,本地模型就高度相似于目标模型了。
1.4 模型水印
除了隐藏输出结果的置信度外,为了避免模型被盗用、保护知识产权,IBM的研究者提出了模型水印( watermarking)的概念。
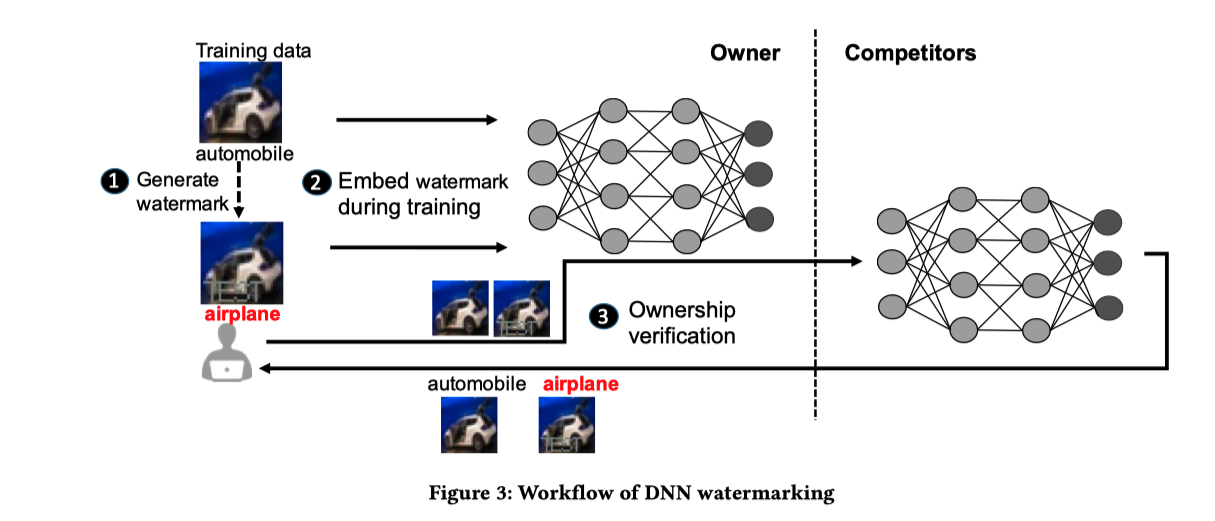
如上图所示——
- 首先算法人员基于训练集,生成一系列带有水印的数据集,如上图中的automobile和airplane, 其中airplane是嵌有水印的图片
- 然后将训练集和带有水印的数据一起输入到神经网络中
- 如果竞争者盗用了他们的模型,那么当输入带水印的图片时,对方的模型就会将其识别为airplane,而不是automobile,以此证明对方剽窃了自己的模型
研究人员开发了三种算法来生成三种类型的水印:
- 将“有意义的内容”与算法的原始训练数据一起嵌入模型
- 嵌入不相关的数据样本
- 嵌入噪声
2-成员推理攻击
成员推理攻击(Membership Inference Attacks)是指给定数据记录和模型的黑盒访问权限,判断该记录是否在模型的训练数据集中。
这个攻击的成立主要是基于这样一个观察结果:对于一个机器学习模型而言,其对训练集和非训练集的uncertainty 有明显差别,所以可以训练一个Attack model 来猜某样本是否存在于训练集中。
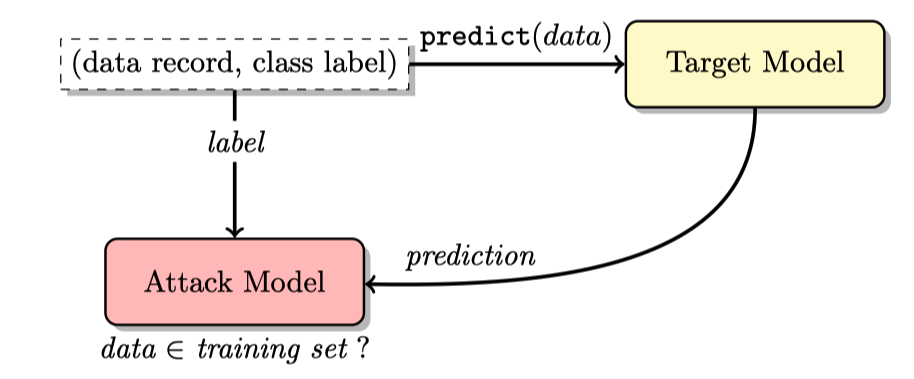
如对于上图所示,首先,攻击者将一个样本输入到目标模型中,并获得相应的预测结果,然后将样本的标签、目标模型的预测结果输入到Attack Model里,判断这个记录是否在目标模型的训练集中。
由于Attack Model需要训练集才能生成,因此作者进一步提出了影子模型(shadow model)这个概念。
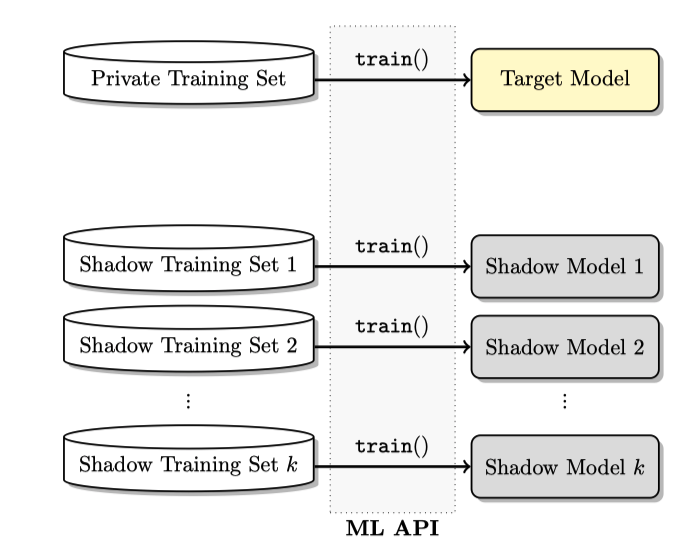
影子模型很好理解,生成方式和模型萃取攻击相似,即影子模型 T’ 与目标模型 T 的架构要一样,然后随机生成data x,把 x 输入 T 得到的label 预测结果p当作 y,再用这些(x, y) 去训练 T’。 因为两个模型的架构相同, T 与 T’ 预测的机率分布也是相似的,所以针对影子模型 T’ 的 attack model 也可以对目标模型 T 做成员推理攻击。
影子模型训练数据的生成方式:
- 基于模型的合成方式 Model-based synthesis:如果攻击者没有真正的训练数据,也没有关于其分布的任何统计,他可以利用目标模型本身为影子模型生成合成训练数据。直观来看,高置信度的目标模型分类的记录应当在统计上类似于目标的训练数据集,因此能用于训练影子模型。
- 基于统计的合成方式 Statistics-based synthesis :攻击者可能拥有目标模型的训练数据的一些统计信息。例如,攻击者可能事先知道不同特征的边缘分布。在实验中,可以通过独立地从每个特征的边缘分布中进行采样,来生成影子模型的训练集。
- 含噪音的真实数据 Noisy real data : 攻击者可以访问一些与目标模型的训练数据类似的数据,这些数据可以被视为“噪音”版本。
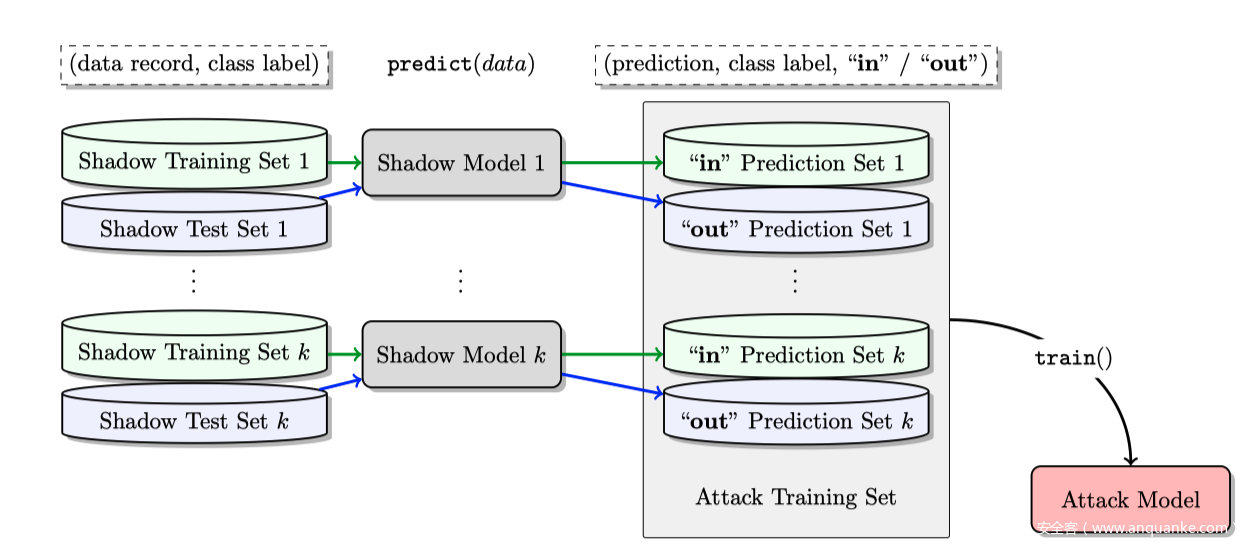
生成影子模型后,构造攻击模型的训练集(训练集的标签,和影子模型的输出结果),并对攻击模型进行训练就好了。
防御手段:
- 一些防止 overfitting 的方法可以用来防御成员推理攻击,如 droupout、regularization
- 对预测结果做一些后续处理也可以防御成员推理攻击,如取 top k classes、rounding、增加 entropy 等手法
3-模型逆向攻击
破坏模型机密性的第三种手段是模型逆向攻击(Model Inversion Attack)。这种攻击方法利用机器学习系统提供的一些API来获取模型的一些初步信息,并通过这些初步信息对模型进行逆向分析,获取模型内部的一些隐私数据。这种攻击和成员推理攻击的区别是,成员推理攻击是针对某一条单一的训练数据,而模型逆向攻击则是倾向于取得某个程度的统计信息。
例如,用模型和某位病患的人口属性,可以回推出该病患的遗传资料(即该模型的input); 用一个名字(模型的output)回推出这个人的脸部影像,如上图所示,图右是训练集中的原图,图左是从模型逆向中推出的这个人的长相,攻击者只有这个人的名字和人脸识别模型的API调用权限。

这种攻击是怎么进行的呢?我们用最简单的线性回归模型来举例。
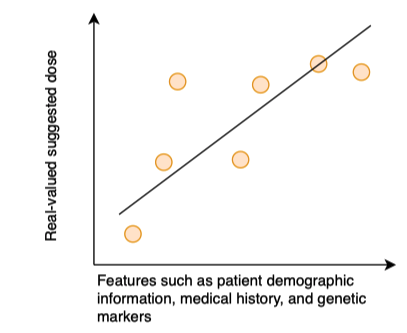
如上所示,假如我们有一个基于病人的人口统计信息、医疗记录和基因特征来预测病人应该服用多少剂量药物的线性回归模型。我们假定基因特征是敏感特征x1, 那么模型逆向攻击的目的就是通过构造大量的样本,来推断病人的基因特征x1的值是多少。
这里,模型的表达式为y = f(x_1,…,x_d)。首先,攻击者需要对病人的其他信息有一定了解,如人口统计信息和医疗记录,从而减少遍历次数,其次,攻击者需要知道x1的取值范围是多少。之后,只要通过不停构造测试数据,并将模型返回的结果和实际结果进行对比,就可以获得该患者的敏感特征x1了。
如果我们对数据源一无所知,只有一个标签,比如姓名,还可以发起攻击吗?
我们拿人脸识别系统来举例。
首先,因为我们对数据源一无所知,我们需要用随机生成的输入向量来冷启动攻击,然后通过在输入空间使用梯度下降来最大化模型在目标预测值上的置信度,当误差小于我们指定的阈值时,模型暂停,获得重构的人脸。
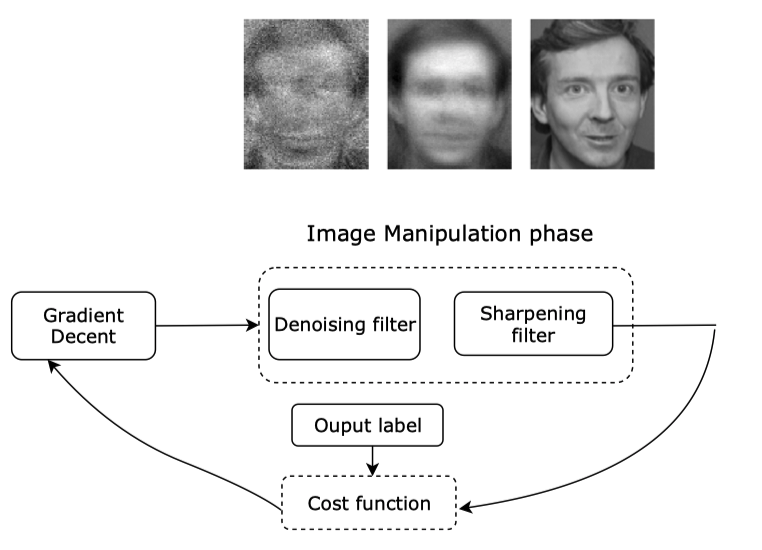
详细的过程比较复杂,感兴趣的同学可以自行参考这篇论文:
Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures[C]//Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 2015: 1322-1333.
references
[1] Chakraborty A, Alam M, Dey V, et al. Adversarial attacks and defences: A survey[J]. arXiv preprint arXiv:1810.00069, 2018.
[2] Zhang J, Gu Z, Jang J, et al. Protecting intellectual property of deep neural networks with watermarking[C]//Proceedings of the 2018 on Asia Conference on Computer and Communications Security. 2018: 159-172.
[3] Tramèr F, Zhang F, Juels A, et al. Stealing machine learning models via prediction apis[C]//25th {USENIX} Security Symposium ({USENIX} Security 16). 2016: 601-618.
[4] Shokri R, Stronati M, Song C, et al. Membership inference attacks against machine learning models[C]//2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017: 3-18.
[5] Fredrikson M, Lantz E, Jha S, et al. Privacy in Pharmacogenetics: An End-to-End Case Study of Personalized Warfarin Dosing[C]//USENIX Security Symposium. 2014: 17-32.
[6] Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures[C]//Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 2015: 1322-1333.







发表评论
您还未登录,请先登录。
登录