

作者:at0de@星盟
介绍
Seccomp(全称:secure computing mode)在2.6.12版本(2005年3月8日)中引入linux内核,将进程可用的系统调用限制为四种:read,write,_exit,sigreturn。最初的这种模式是白名单方式,在这种安全模式下,除了已打开的文件描述符和允许的四种系统调用,如果尝试其他系统调用,内核就会使用SIGKILL或SIGSYS终止该进程。Seccomp来源于Cpushare项目,Cpushare提出了一种出租空闲linux系统空闲CPU算力的想法,为了确保主机系统安全出租,引入seccomp补丁,但是由于限制太过于严格,当时被人们难以接受。
2005年的Cpushare项目原文及评论:https://lwn.net/Articles/120647/
实例
我们可以写一个实例验证一下:
ps:如果没有头文件可以直接用apt安装
sudo apt install libseccomp-dev libseccomp2 seccomp
代码如下:
#include <stdio.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
int main() {
//prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT);
char *buf = "hello world!n";
write(0,buf,0xc);
printf("%s",buf);
}
未使用seccomp:hello world!hello world!
使用seccomp:hello world!Killed
初代的seccomp就是这样暴力,禁用白名单之外的所有函数!
Seccomp-BPF
介绍
尽管seccomp保证了主机的安全,但由于限制太强实际作用并不大。在实际应用中需要更加精细的限制,为了解决此问题,引入了Seccomp – Berkley Packet Filter(Seccomp-BPF)。Seccomp-BPF是Seccomp和BPF规则的结合,它允许用户使用可配置的策略过滤系统调用,该策略使用Berkeley Packet Filter规则实现,它可以对任意系统调用及其参数(仅常数,无指针取消引用)进行过滤。Seccomp-BPF在3.5版(2012年7月21日)的Linux内核中(用于x86 / x86_64系统)和Linux内核3.10版(2013年6月30日)被引入Linux内核。
Seccomp我们已经知道了,那么BPF规则是什么?
最初构想提出于1992年,其目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在那个位置利用一个校验器进行检查 —— 以避免内核崩溃或者安全问题 —— 并附着到一个套接字上。其简化的语言以及存在于内核中的即时编译器(JIT),使 BPF 成为一个性能卓越的工具。
两者是如何结合的?
seccomp在过滤系统调用(调用号和参数)的时候,借助了BPF定义的过滤规则,以及处于内核的用BPF language写的mini-program。此外,BPF使得seccomp的用户无法遭受系统调用插入框架中常见的检查时间-使用时间(TOCTOU)攻击。BPF程序不能取消引用指针,这将所有过滤器限制为直接评估系统调用参数。
Seccomp-BPF在原来的基础上增加了过滤规则,大致流程如下:
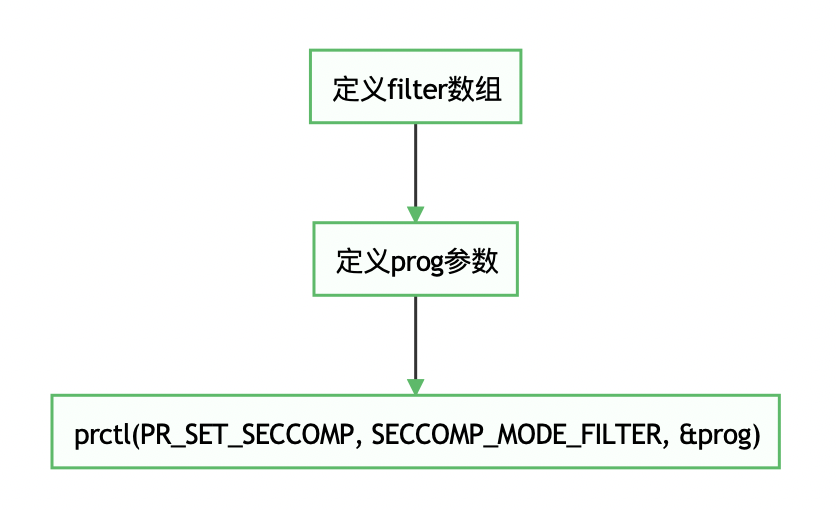
现在我们逐步分析代码。
step 1:定义过滤规则
先看看禁用execve函数的规则:
struct sock_filter filter[] = {
BPF_STMT(BPF_LD+BPF_W+BPF_ABS,4), //前面两步用于检查arch
BPF_JUMP(BPF_JMP+BPF_JEQ,0xc000003e,0,2),
BPF_STMT(BPF_LD+BPF_W+BPF_ABS,0), //将帧的偏移0处,取4个字节数据,也就是系统调用号的值载入累加器
BPF_JUMP(BPF_JMP+BPF_JEQ,59,0,1), //当A == 59时,顺序执行下一条规则,否则跳过下一条规则,这里的59就是x64的execve系统调用
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_KILL), //返回KILL
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_ALLOW), //返回ALLOW
};
我从filter.h中找到了结构体和宏指令,BPF的过滤规则就是由两个指令宏组成的指令序列完成的,这个序列是一个结构体数组。
/*
* Try and keep these values and structures similar to BSD, especially
* the BPF code definitions which need to match so you can share filters
*/
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */
unsigned short len; /* Number of filter blocks */
struct sock_filter __user *filter;
};
/* ret - BPF_K and BPF_X also apply */
#define BPF_RVAL(code) ((code) & 0x18)
#define BPF_A 0x10
/* misc */
#define BPF_MISCOP(code) ((code) & 0xf8)
#define BPF_TAX 0x00
#define BPF_TXA 0x80
/*
* Macros for filter block array initializers.
*/
#ifndef BPF_STMT
#define BPF_STMT(code, k) { (unsigned short)(code), 0, 0, k }
#endif
#ifndef BPF_JUMP
#define BPF_JUMP(code, k, jt, jf) { (unsigned short)(code), jt, jf, k }
#endif
在bpf_common.h中有BPF_STMT和BPF_JUMP这两个操作指令参数的介绍,中文注释来自看雪论坛okchenshuo师傅
#define BPF_CLASS(code) ((code) & 0x07) //首先指定操作的类别
#define BPF_LD 0x00 //将操作数装入A或者X
#define BPF_LDX 0x01
#define BPF_ST 0x02 //拷贝A或X的值到内存
#define BPF_STX 0x03
#define BPF_ALU 0x04 //用X或常数作为操作数在累加器上执行算数或逻辑运算
#define BPF_JMP 0x05 //跳转指令
#define BPF_RET 0x06 //终止过滤器并表明报文的哪一部分保留下来,如果返回0,报文全部被丢弃
#define BPF_MISC 0x07
/* ld/ldx fields */
#define BPF_SIZE(code) ((code) & 0x18) //在ld时指定操作数的大小
#define BPF_W 0x00 //双字
#define BPF_H 0x08 //单字
#define BPF_B 0x10 //单字节
#define BPF_MODE(code) ((code) & 0xe0) //操作数类型
#define BPF_IMM 0x00
#define BPF_ABS 0x20 //绝对偏移
#define BPF_IND 0x40 //相对偏移
#define BPF_MEM 0x60
#define BPF_LEN 0x80
#define BPF_MSH 0xa0
/* alu/jmp fields */
#define BPF_OP(code) ((code) & 0xf0) //当操作码类型为ALU时,指定具体运算符
#define BPF_ADD 0x00 //到底执行什么操作可以看filter.h里面的定义
#define BPF_SUB 0x10
#define BPF_MUL 0x20
#define BPF_DIV 0x30
#define BPF_OR 0x40
#define BPF_AND 0x50
#define BPF_LSH 0x60
#define BPF_RSH 0x70
#define BPF_NEG 0x80
#define BPF_MOD 0x90
#define BPF_XOR 0xa0
#define BPF_JA 0x00 //当操作码类型是JMP时指定跳转类型
#define BPF_JEQ 0x10
#define BPF_JGT 0x20
#define BPF_JGE 0x30
#define BPF_JSET 0x40
#define BPF_SRC(code) ((code) & 0x08)
#define BPF_K 0x00 //常数
#define BPF_X 0x08
有师傅写了函数库seccomp-bpf.h,用来快速添加规则
#define VALIDATE_ARCHITECTURE
BPF_STMT(BPF_LD+BPF_W+BPF_ABS, arch_nr),
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, ARCH_NR, 1, 0),
BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_KILL)
#define EXAMINE_SYSCALL
BPF_STMT(BPF_LD+BPF_W+BPF_ABS, syscall_nr)
#define ALLOW_SYSCALL(name)
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, __NR_##name, 0, 1),
BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_ALLOW)
#define KILL_PROCESS
BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_KILL)
我们只需要按照结构体去创建规则就可以使用它,可以有多条过滤规则,seccomp会从第0条开始逐条执行,直到遇到BPF_RET返回,决定是否允许该操作以及做某些修改。
step 2:定义prog参数
prog结构体过滤规则个数与规则数组起始位置。
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter)/sizeof(filter[0])), /* Number of filter blocks */
.filter = filter, /* Pointer to array of BPF instructions */
};
step 3:使用prctl函数
prctl(PR_SET_NO_NEW_PRIVS,1,0,0,0);
prctl(PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&prog);
prctl函数原型如下:
int prctl(int option, unsigned long arg2, unsigned long arg3,unsigned long arg4, unsigned long arg5);
我们这里用到了两种
prctl(PR_SET_NO_NEW_PRIVS,1,0,0,0);
为了保证安全性,需要将PR_SET_NO_NEW_PRIVSW位设置位1。这个操作能保证seccomp对所有用户都能起作用,并且会使子进程即execve后的进程依然受控,意思就是即使执行execve这个系统调用替换了整个binary权限不会变化,而且正如其名它设置以后就不能再改了,即使可以调用ptctl也不能再把它禁用掉。
prctl(PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&prog);
PR_SET_SECCOMP指明我们正在为进程设置seccomp;
SECCOMP_MODE_FILTER将seccomp的过滤规则指向&prog;
&prog就是我们定义的过滤规则
实例
代码:
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <time.h>
#include <string.h>
#include <stdlib.h>
#include <malloc.h>
#include <sys/prctl.h>
#include <seccomp.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
int main() {
struct sock_filter filter[] = {
BPF_STMT(BPF_LD+BPF_W+BPF_ABS,4),
BPF_JUMP(BPF_JMP+BPF_JEQ,0xc000003e,0,2),
BPF_STMT(BPF_LD+BPF_W+BPF_ABS,0),
BPF_JUMP(BPF_JMP+BPF_JEQ,59,0,1),
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_KILL),
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter)/sizeof(filter[0])),
.filter = filter,
};
prctl(PR_SET_NO_NEW_PRIVS,1,0,0,0);
prctl(PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&prog);
printf("start!n");
system("id");
return 0;
}
添加多条规则建议使用seccomp-bpf.h库,简单方便
例如
#define _GNU_SOURCE 1
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <time.h>
#include <string.h>
#include <stdlib.h>
#include <malloc.h>
#include <sys/prctl.h>
#include <seccomp.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include "seccomp-bpf.h"
static int install_syscall_filter(void)
{
struct sock_filter filter[] = {
/* Validate architecture. */
VALIDATE_ARCHITECTURE,
/* Grab the system call number. */
EXAMINE_SYSCALL,
/* List allowed syscalls. */
ALLOW_SYSCALL(rt_sigreturn),
#ifdef __NR_sigreturn
ALLOW_SYSCALL(sigreturn),
#endif
ALLOW_SYSCALL(exit_group),
ALLOW_SYSCALL(exit),
ALLOW_SYSCALL(read),
ALLOW_SYSCALL(write),
KILL_PROCESS,
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter)/sizeof(filter[0])),
.filter = filter,
};
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(NO_NEW_PRIVS)");
goto failed;
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(SECCOMP)");
goto failed;
}
return 0;
failed:
if (errno == EINVAL)
fprintf(stderr, "SECCOMP_FILTER is not available. :(n");
return 1;
}
int main()
{
if (install_syscall_filter())
return 1;
return 0;
}
seccomp库函数
seccomp库可以提供一些函数实现prctl类似的效果,库中封装了一些函数,可以不用了解BPF规则而实现过滤。
需要安装一些库文件
sudo apt install libseccomp-dev libseccomp2 seccomp
实例
#include <unistd.h>
#include <seccomp.h>
#include <linux/seccomp.h>
int main(void){
scmp_filter_ctx ctx;
ctx = seccomp_init(SCMP_ACT_ALLOW);
seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 0);
seccomp_load(ctx);
char * str = "/bin/sh";
write(1,"hello worldn",12);
syscall(59,str,NULL,NULL);//execve
return 0;
}
scmp_filter_ctx是过滤器的结构体
seccomp_init对结构体进行初始化,若参数为SCMP_ACT_ALLOW,则过滤为黑名单模式;若为SCMP_ACT_KILL,则为白名单模式,即没有匹配到规则的系统调用都会杀死进程,默认不允许所有的syscall。
seccomp_rule_add用来添加一条规则,arg_cnt为0,表示我们直接限制execve,不管参数是什么,如果arg_cnt不为0,那arg_cnt表示后面限制的参数的个数,也就是只有调用execve,且参数满足要求时,才会拦截
seccomp_load是应用过滤器,如果不调用seccomp_load则上面所有的过滤都不会生效
注意:编译的时候要在最后面加 -lseccomp
seccomp-tools
项目地址:https://github.com/david942j/seccomp-tools
可以用来查看过滤规则
$ seccomp-tools dump ./a.out
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x05 0xc000003e if (A != ARCH_X86_64) goto 0007
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005
0004: 0x15 0x00 0x02 0xffffffff if (A != 0xffffffff) goto 0007
0005: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0007
0006: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0007: 0x06 0x00 0x00 0x00000000 return KILL
还有其他几个功能,可以自己探索
seccomp在ctf中的应用
seccomp在ctf中大多用于禁用execve函数,解决办法就是构造shellcode,用open->read->write的方式读flag
做题这部分网上的例题和参考资料很多,我就不说了
我讲一下如何出seccomp类型的题:
1.栈类型的题使用ptrcl或seccomp库都行;
2.堆类型需要用ptrcl函数,因为seccomp库会留下堆的使用痕迹,如下图所示;

我查看seccomp.c的源码,发现了内核空间使用的kmalloc、kfree等函数
3.出堆题时将seccomp库的规则放到最后
[GKCTF2020]Domo 这道题的师傅是这样做的,但是会出现非预期解
总结
seccomp的pwn题近两年算是一个热点,搞懂这种机制运行原理很重要,希望能对大家有帮助。
参考资料
https://www.kernel.org/doc/Documentation/prctl/seccomp_filter.txt
https://www.kernel.org/doc/html/v4.16/userspace-api/seccomp_filter.html
https://ajxchapman.github.io/linux/2016/08/31/seccomp-and-seccomp-bpf.html
https://zhougy0717.github.io/2019/11/30/seccomp%E4%BB%8B%E7%BB%8D/
https://blog.betamao.me/2019/01/23/Linux%E6%B2%99%E7%AE%B1%E4%B9%8Bseccomp/#seccomp







发表评论
您还未登录,请先登录。
登录