

书接前文,本文主要介绍 Go 二进制文件中 Meta Information 的解析,与函数符号和源码文件路径列表的提取。最后详细介绍一下 Moduledata 这个结构。
5. Meta information
5.1 Go Build ID
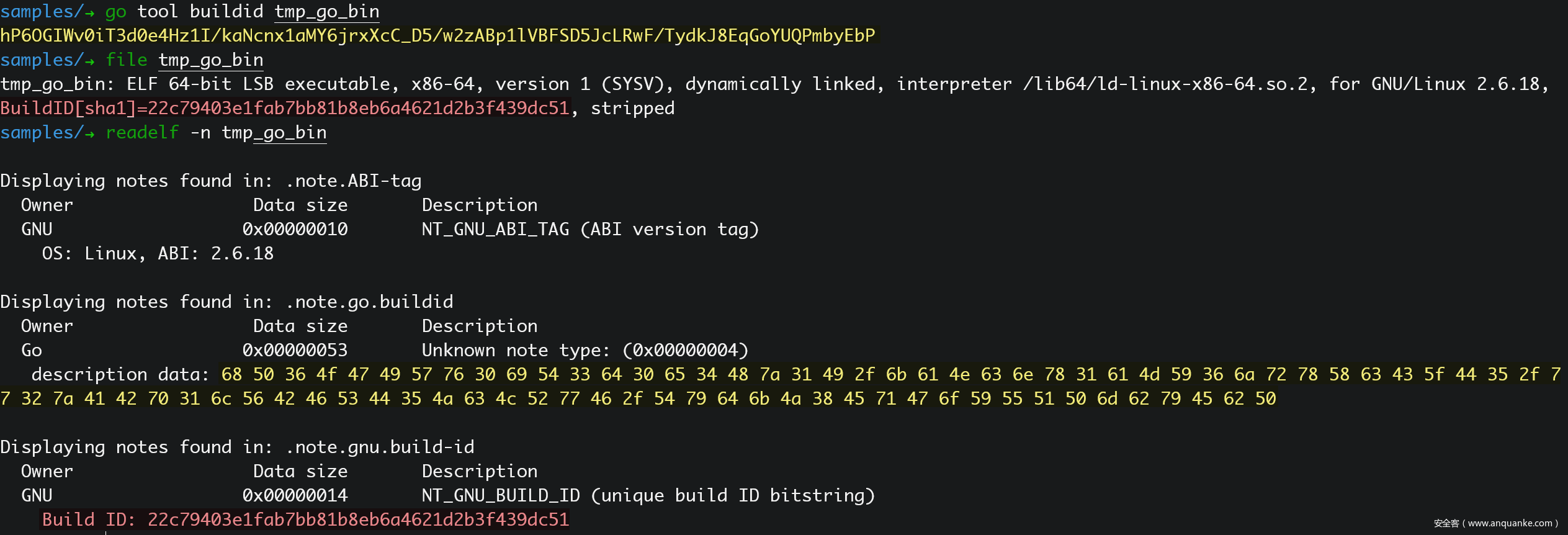
每一个 Go 二进制文件内,都有一个独一无二的 Build ID,详情参考 src/cmd/go/internal/work/buildid.go 。Go Build ID 可以用以下命令来查看:
$ go tool buildid <GoBinaryFilePath>
对于 ELF 文件,也可以用 readelf 命令查看,不过看到的只是 Hex String:

转换一下上图的 Hex String,就是 $ go buildid tracker_nonstrip 的显示结果了:
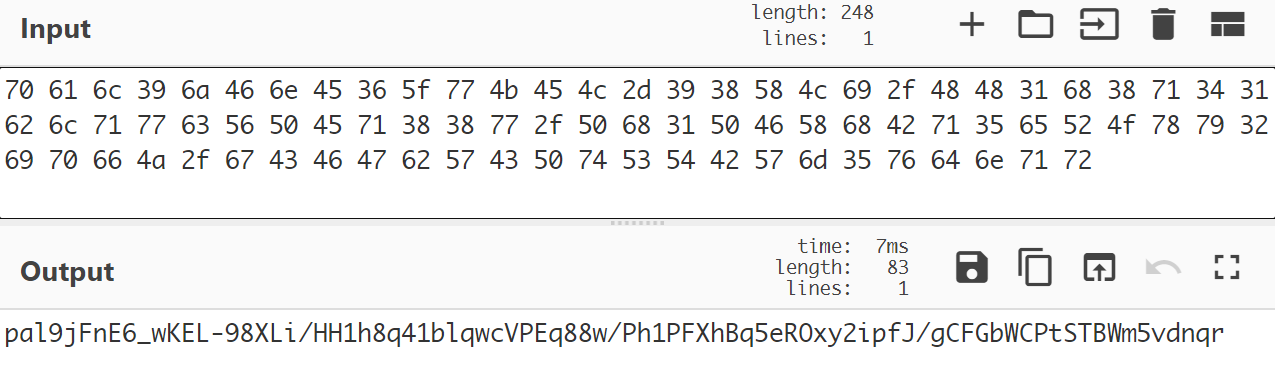
另外,如果是用 gccgo 编译的 ELF 文件,用 file 命令 或者 readelf 命令还能看到 GNU Build ID ,注意区分一下:
Build ID 是 Go 二进制文件中的元信息之一,但是对逆向分析二进制文件并没有什么实际帮助,本文只做简单介绍。
5.2 Go Version
Go 二进制文件中,还会把构建本文件的 Go 语言版本号打包进去。查看方式有以下 2 种:
- 通过 IDAPro 中的 strings 检索:
![]()
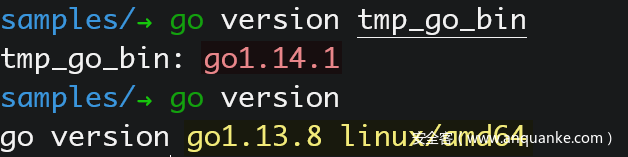
- 通过 Go 语言官方命令
$ go version [FILE],该命令不指定文件则打印本地安装的 Go 语言版本,指定文件则打印目标文件对应的 Go 语言版本:![]()

5.3 GOROOT
GOROOT 是 Go 语言的安装路径,里面有 Go 的标准库和自带的命令行工具。一般来说,Go 的二进制文件中都会把 GOROOT 打包进去,并在 runtime.GOROOT() 函数中会用到这个值。比如某 Go 样本中打包的 runtime.GOROOT() 函数,可以看到构建该样本所在主机的 GOROOT 路径是 /usr/lib/go :
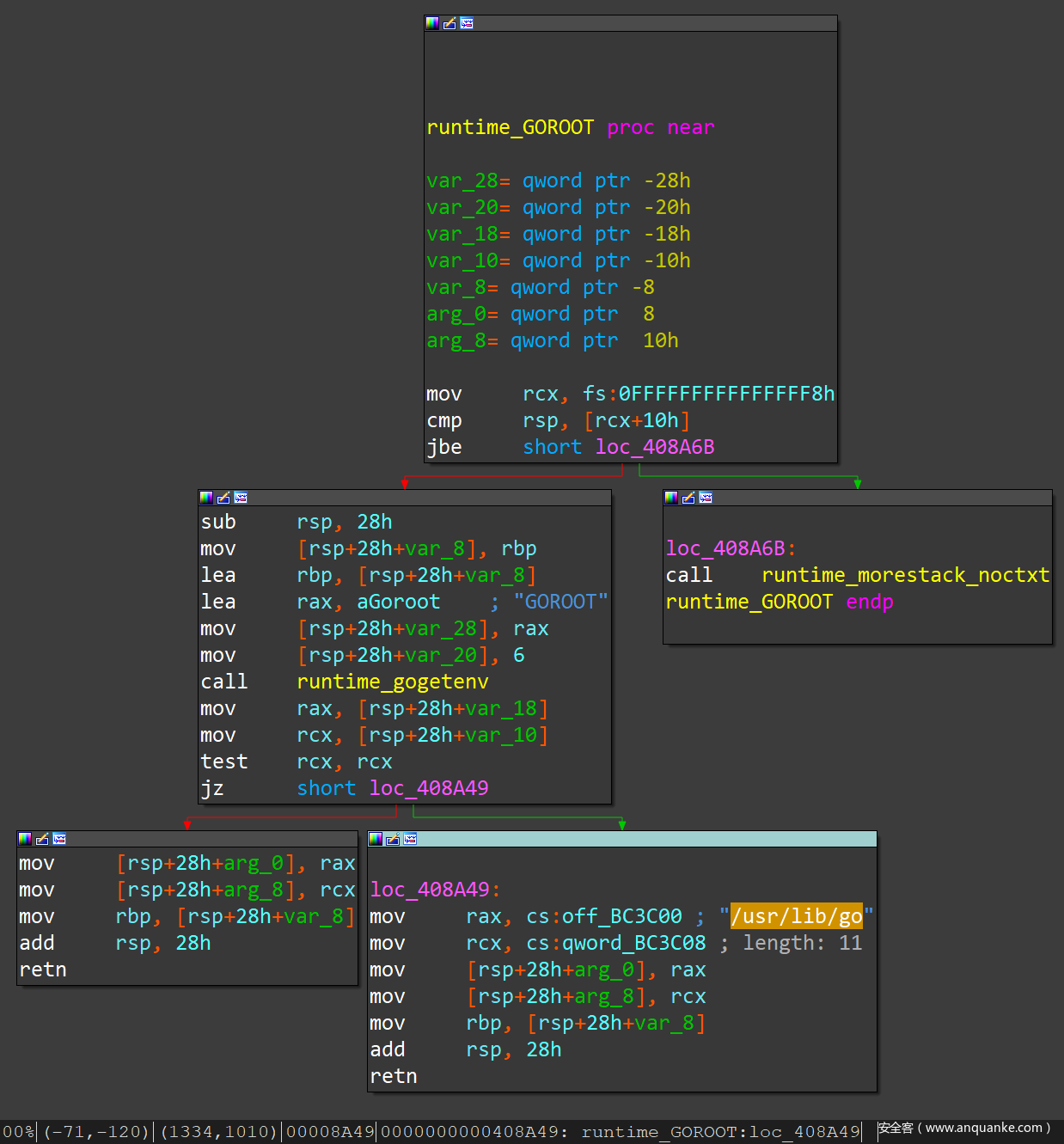
看 Go 标准库中 runtime.GOROOT() 函数的源码 ,会发现这个路径其实叫 sys.DefaultGoroot :

至于如何提取这个字符串,就需要在 IDAPro 中先把函数名符号恢复出来,然后根据函数名找到 runtime.GOROOT() 这个函数,最后在这个函数中提取出 sys.DefaultGoroot 的值。提取方法可能有多种,go_parser for IDAPro 中的方法 是先解析该函数的 FlowChart ,找到最后带 return 的 FlowChart,然后再找出该值的地址。
那么知道了这个信息,对逆向分析有什么用处?后文描述如何提取、过滤 Go 二进制文件中的源码路径列表时会用到。
6. pclntab
6.1 pclntab 介绍
pclntab 全名是 Program Counter Line Table,可直译为 程序计数器行数映射表, 在 Go 中也叫 Runtime Symbol Table, 所以我把它里面包含的信息叫做 RTSI(Runtime Symbol Information)。2013 年由 Russ Cox (Go 语言创始团队成员,核心开发者)从 Plan9 移植到 Go 1.2 上,至今没有太大变化。至于 PC(Program Counter),是给 Go 语言的 runtime 来操作的,可以粗浅理解为 runtime 当前执行的程序代码(或指令)。
按 Russ Cox 在《Go 1.2 Runtime Symbol Information》中的说法,引入 pcnlntab 这个结构的最初动机,是为 Stack Trace 服务的。参考前文《Go二进制文件逆向分析从基础到进阶——综述》中 redress 工具的报错信息,当程序运行出错要 panic 的时候,runtime 需要知道当前的位置,层级关系如 pkg->src file->function or method->line number,每一层的信息 runtime 都要知道。Go 就把这些信息结构化地打包到了编译出的二进制文件中。除此之外,pcnlntab 中还包含了栈的动态管理用到的栈帧信息、垃圾回收用到的栈变量的生命周期信息以及二进制文件涉及的所有源码文件路径信息。
pclntab 的概要结构如下(其中的 strings 指的是 Function name string、Source File Path string,并不是整个程序中用到的所有 strings):
pclntab:
- func table
- _func structs
- pcsp
- psfile
- pcline
- pcdata
- strings
- file table
而我们最关心的信息,其实主要是 2 个:函数表(func table) 和 源码文件路径列表(file table)。针对性的 pclntab 结构如下:

简单解释一下:
- pclntab 开头 4-Bytes 是从 Go1.2 至今不变的 Magic Number: 0xFFFFFFFB ;
- 第 5、6个字节为 0x00,暂无实际用途;
- 第 7 个字节代表 instruction size quantum, 1 为 x86, 4 为 ARM;
- 第 8 个字节为地址的大小,32bit 的为 4,64 bit 的为 8,至此的前 8 个字节可以看作是 pclntab 的 Header;
- 第 9 个字节开始是 function table 的起始位置,第一个 uintptr 元素为函数(pc, Program Counter) 的个数;
- 第 2 个 uintptr 元素为第 1 个函数(pc0) 的地址,第 3 个 uintptr 元素为第 1 个函数结构定义相对于 pclntab 的偏移,后面的函数信息就以此类推;
- 直到 function table 结束,下面就是 Source file table。Source file table 以 4 字节(int32)为单位,前 4 个字节代表 Source File 的数量,后面每一个 int32 都代表一个 Source File Path String 相对于 pclntab 的偏移;
- uintptr 代表一个指针类型,在 32bit 二进制文件中,等价于 uint32,在 64bit 二进制文件中,等价于 uint64 。
pclntab 在源码中是如此定义的,构建二进制文件时,RTSI 也是在二进制文件中按上面顺序排列的。所以,在 IDAPro 中解析 pclntab,就按照如上说明来解析即可。go_parser 在 IDAPro 中解析好的 pclntab 开头部分如下:

关于如何查找、定位到 pclntab,下文详述。
6.2 函数表
函数表(func table)的起始地址,为 (pclntab_addr + 8),第一个元素( uintptr N) 代表函数的个数,如上图中的 0x1C3A。
解析来就是每两个 uintptr 元素为一组,即 (func_addr, func_struct_offset),每组第一个元素为函数的地址,第二个元素为函数结构体定义相对于 pclntab 起始地址的偏移。即:
func_struct_addr = pclntab_addr + func_struct_offset
# 以上图第一个函数 internal_cpu_Initialize() 为例,pclntab 的地址为 0x8FBFA0,它的 func_struct_offset 为 0x1C3C0
# 那么它的 func struct address 为:
0x8FBFA0 + 0x1C3C0 = 0x918360
地址 0x918360 处的 Function Struct 是什么模样?下图为 go_parser 在 IDAPro 中解析好的结果:

Function Struct 在 Russ Cox 的《Go 1.2 Runtime Symbol Information》有介绍:
struct Func
{
uintptr entry; // start pc
int32 name; // name (offset to C string)
int32 args; // size of arguments passed to function
int32 frame; // size of function frame, including saved caller PC
int32 pcsp; // pcsp table (offset to pcvalue table)
int32 pcfile; // pcfile table (offset to pcvalue table)
int32 pcln; // pcln table (offset to pcvalue table)
int32 nfuncdata; // number of entries in funcdata list
int32 npcdata; // number of entries in pcdata list
};
对于逆向分析来说,这里最有用的信息,就是函数名了。如上图所示,函数名是一个以 0x00 结尾的 C-String。在 Function Struct 中,第二个元素只是 int32 类型的偏移值,而函数名字符串的地址,则用以下方式计算得出:
func_name_addr = pclntab_addr + Dword(func_stuct_addr + sizeof(uintptr))
# 比如上面函数 internal_cpu_Initialize() 的 func_struct_addr 为 0x918360,
# 它的 Func Name String Offset 为 0x1C408,那么它的 Func Name String Address 就是
0x8FBFA0(pclntab_addr) + 0x1C408 = 0x9183A8
如此一来,就从 Go 二进制文件中恢复出了一个函数的名字。用这种方式遍历 Function Table,便可以恢复所有函数名。
有的师傅可能还会问,Function Struct 中第 3 个元素 args ,有没有对逆向分析有用的信息?如果知道函数的参数、返回值信息,岂不更爽。这个……曾经有,现在,真没有了。在 Go 标准库源码 src/debug/gosym/symtab.go 中解析这个 Function Struct 的一个类型定义中,有两条注释,说 Go 1.3 之后就没这种信息了:

另外,还有一些函数用上面的方式无法解析,是编译器做循环展开时自动生成的匿名函数,也叫 Duff’s Device),函数体型如下图:
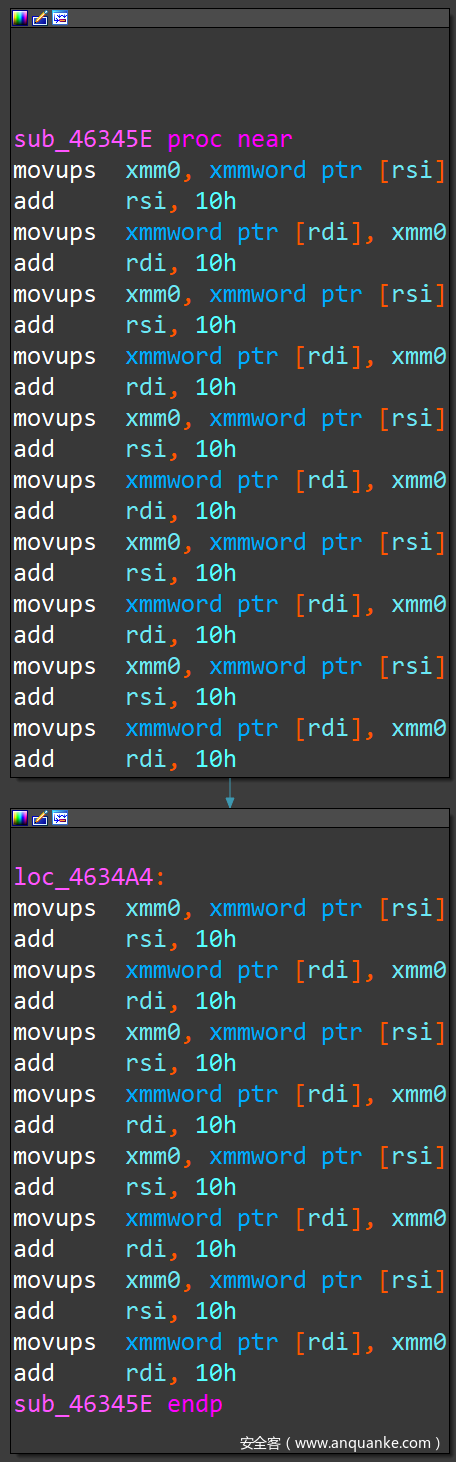
这样的函数知道它是用来连续操作内存(拷贝、清零等等)的就可以。
6.3 源码文件路径
在 pclntab 中,函数表下面隔一个 uintptr 的位置,就是源码文件表(Srouce File Table) 的 偏移,长度为 4-Bytes:
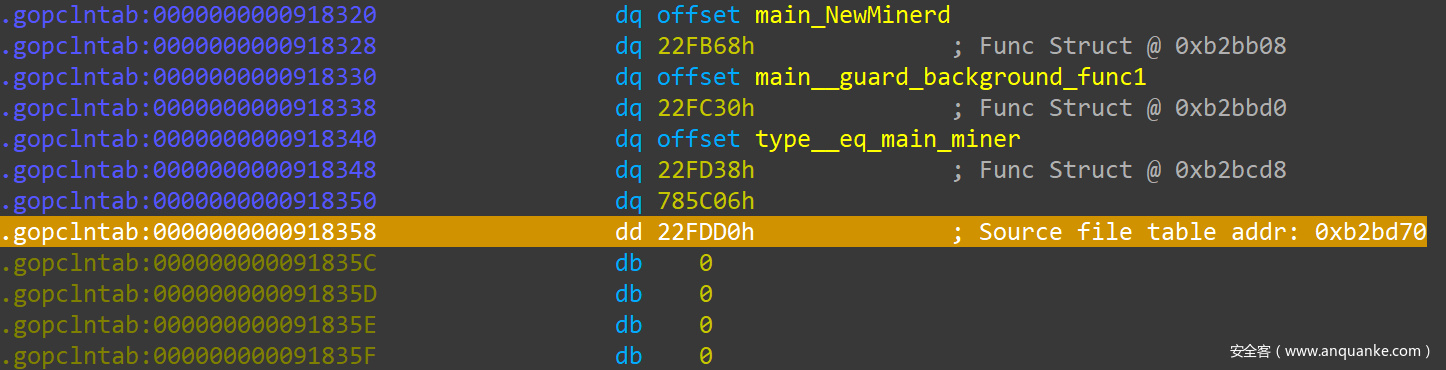
这个偏移,是相对 pclntab 的起始地址来说的。接着上面的例子,pclntab 的地址为 0x8FBFA0,此处偏移量为 0x22FDD0 ,那么源码文件路径列表的地址就是:
srcfiletab_addr = pclntab_addr + srcfiletab_offset
0x8FBFA0 + 0x22FDD0 = 0xB2BD70
在 IDAPro 中,0xB2BD70 处 go_parser 解析好的效果如下:
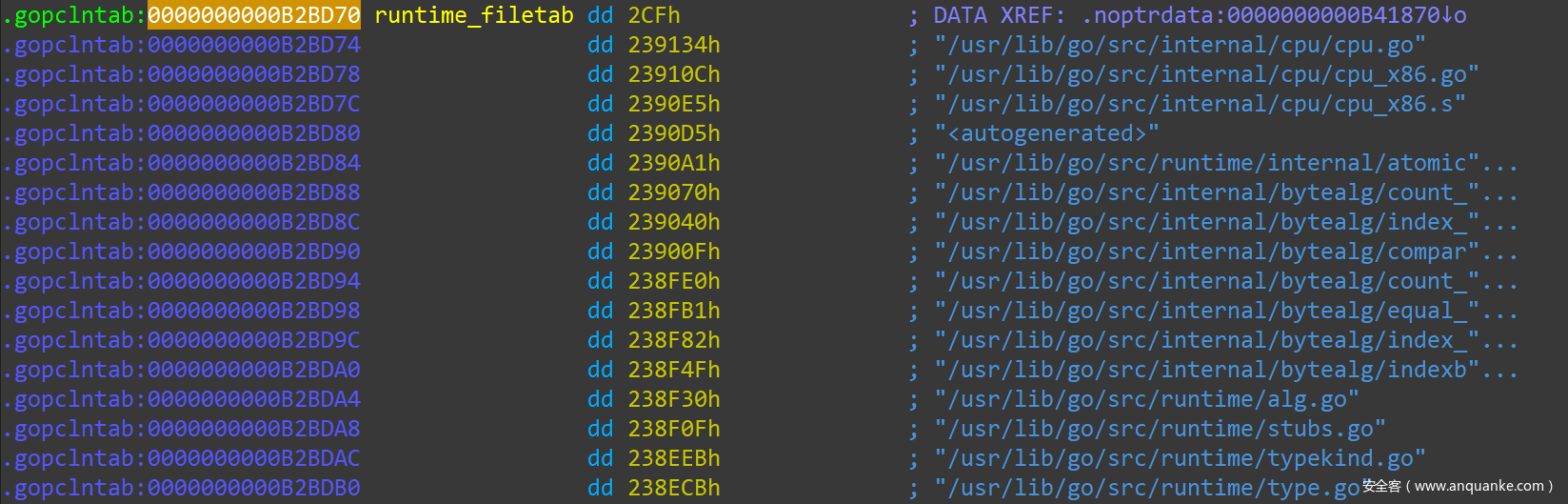
Source File Table 中的元素全都以 4-Bytes(uint32) 为单位,第一个元素(0x2CF)是本二进制文件涉及的所有源码文件的个数,包括标准库的源码文件、第三方 Pacakge 的源码文件以及当前项目的源码文件。后续每个 uint32 元素代表一个相对于 pclntab 的偏移量,该偏移量加上 pclntab 的起始地址,即为相应源码文件路径字符串的起始地址。每个源码文件路径名都是以 0x00 结尾的 C-String。
go_parser 对此的处理,是计算出每个偏移量对应的地址,然后创建字符串,并为当前偏移所在的地址创建 data reference,在 IDAPro 中双击 data reference 即可跳转到相应的字符串地址。比如,第一个源码文件的偏移量为 0x239134,那么它对应的实际地址为:
0x8FBFA0(pclntab_addr) + 0x239134 = 0xB350D4
查看地址 0xB350D4 处的字符串即可印证:

另外, go_parser 如果成功定位到 runtime.GOROOT() 函数,并解析出 sys.DefaultGoroot 的值,还会根据这个值过滤掉所有标准库源码文件路径和第三方 Package 源码文件路径,在 IDAPro 的 Console 中只打印本项目相关的所有源码文件路径;如果没能提取出 sys.DefaultGoroot ,则会打印所有源码文件路径。DDG 样本中的源码文件路径列表如下所示(IDAPro Console):

7. moduledata
7.1 moduledata 介绍
在 Go 语言的体系中,Module 是比 Package 更高层次的概念,具体表现在一个 Module 中可以包含多个不同的 Package,而每个 Package 中可以包含多个目录和很多的源码文件。
“A module is a collection of related Go packages that are versioned together as a single unit.”*
— Go Module Docs
详情参考:《Go Modules in Real Life》
相应地,Moduledata 在 Go 二进制文件中也是一个更高层次的数据结构,它包含很多其他结构的索引信息,可以看作是 Go 二进制文件中 RTSI(Runtime Symbol Information) 和 RTTI(Runtime Type Information) 的 地图。Moduledata 源码定义如下(关键字段看注释):
type moduledata struct {
pclntable []byte // pclntab address
ftab []functab // function table address
filetab []uint32 // source file table address
findfunctab uintptr
minpc, maxpc uintptr // minpc: first pc(function) address
text, etext uintptr // [.text] section start/end address
noptrdata, enoptrdata uintptr
data, edata uintptr // [.data] section start/end address
bss, ebss uintptr // [.bss] section start/end address
noptrbss, enoptrbss uintptr // [.noptrbss] section start/end address
end, gcdata, gcbss uintptr
types, etypes uintptr // types data start/end address
textsectmap []textsect
typelinks []int32 // offset table for types
itablinks []*itab // interface table
ptab []ptabEntry
pluginpath string
pkghashes []modulehash
modulename string
modulehashes []modulehash
hasmain uint8 // 1 if module contains the main function, 0 otherwise
gcdatamask, gcbssmask bitvector
typemap map[typeOff]*_type // offset to *_rtype in previous module
bad bool // module failed to load and should be ignored
next *moduledata
}
根据 Moduledata 的定义,Moduledata 是可以串成链表的形式的,而一个完整的可执行 Go 二进制文件中,只有一个 firstmoduledata 包含如上完整的字段。简单介绍一下关键字段:
- 第 1 个字段 pclntable,即为 pclntab 的地址;
- 第 2 个字段 ftab,为 pclntab 中 Function Table 的地址(=pclntab_addr + 8);
- 第 3 个字段 filetab,为 pclntab 中 Source File Table 的地址;
- 第 5 个字段 minpc,为 pclntab 中第一个函数的起始地址;
- 第 7 个字段 text,在普通二进制文件中,对应于 [.text] section 的起始地址;在 PIE 二进制文件中则没有这个要求;
- 字段 types,为存放程序中所有数据类型定义信息数据的起始地址,一般对应于 [.rodata] section 的地址;
- 字段 typelinks,为每个数据类型相对于 types 地址的偏移表,该字段与 types 字段在后文解析 RTTI 时要用到;
- 字段 itablinks,则是 Interface Table 的起始地址,该字段解析 Interface Table 时要用到。
go_parser 在 IDAPro 中对 firstmoduledata 的解析结果示例如下:
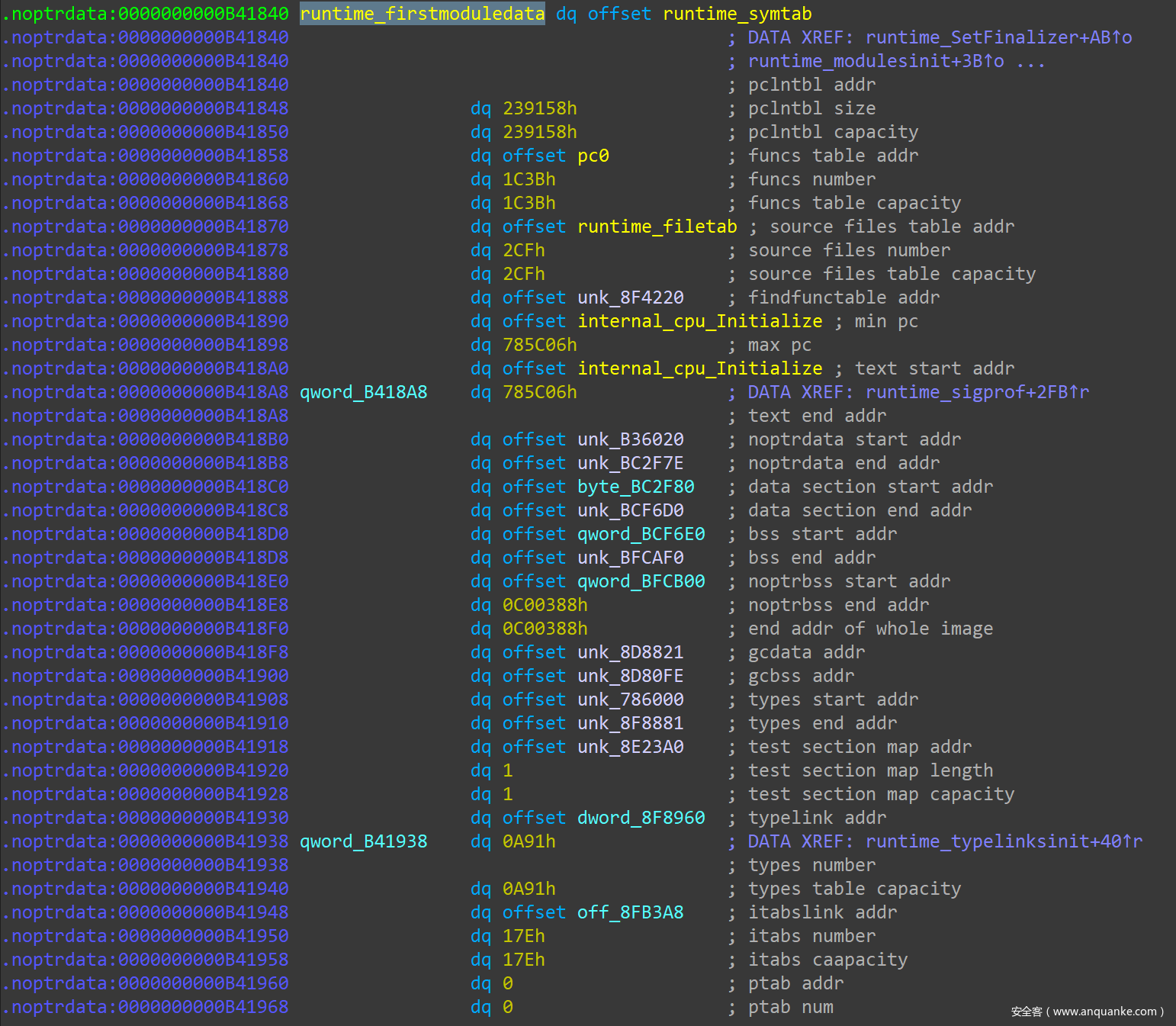
需要注意的是,Go 语言中,一个 Slice 类型数据的底层定义要用到 3 个元素:(Data Address, Length, Capacity)。所以在 IDAPro 中看某个 Slice 类型的字段,要一次看 3 个 uintptr 元素。
7.2 firstmoduledata 定位
通过上面的介绍可以知道,如果在 Go 二进制文件中事先找到 firstmoduledata 这个结构,然后在这个结构中就可以按图索骥找到其他我们感兴趣的信息。那么如何在一个 Go 二进制文件中精准定位到 firstmoduledata 呢?
很直观就想到 pclntab,原因有两点:一是它对应于 firstmoduledata 结构的第一个字段;最主要的是 pclntab 包含的信息丰富,起始位置还有独特的 4-Bytes 的 Magic Number。一旦找到了 pclntab ,就可以定位到 firstmoduledata。
7.2.1 定位 pclntab
定位 pclntab 的方法,公开的相关工具里用的最多的,是根据二进制文件中的 Section Name 来定位。因为平常见到的 Go 二进制文件,PE 文件和 ELF 文件中 .gopclntab Section 就对应于 pclntab 结构,MachO 文件中 __gopclntab Section 对应于 pclntab 结构。
然而这种方法并不靠谱。
最主要的原因,是 PIE 二进制文件。PIE 全称为 Position Independent Executable,意思是地址无关的可执行文件,这个类型的二进制文件结合 ASLR 技术可以加强 Go 二进制文件自身安全性。这对 Go 自身的内存安全机制来说,是个锦上添花的特性。Go 的 build/install 命令在构建二进制文件时,有几个 buildmode 选项:
➜ go help buildmode
The 'go build' and 'go install' commands take a -buildmode argument which
indicates which kind of object file is to be built. Currently supported values
are:
-buildmode=archive
Build the listed non-main packages into .a files. Packages named
main are ignored.
-buildmode=c-archive
Build the listed main package, plus all packages it imports,
into a C archive file. The only callable symbols will be those
functions exported using a cgo //export comment. Requires
exactly one main package to be listed.
-buildmode=c-shared
Build the listed main package, plus all packages it imports,
into a C shared library. The only callable symbols will
be those functions exported using a cgo //export comment.
Requires exactly one main package to be listed.
-buildmode=default
Listed main packages are built into executables and listed
non-main packages are built into .a files (the default
behavior).
-buildmode=shared
Combine all the listed non-main packages into a single shared
library that will be used when building with the -linkshared
option. Packages named main are ignored.
-buildmode=exe
Build the listed main packages and everything they import into
executables. Packages not named main are ignored.
-buildmode=pie
Build the listed main packages and everything they import into
position independent executables (PIE). Packages not named
main are ignored.
-buildmode=plugin
Build the listed main packages, plus all packages that they
import, into a Go plugin. Packages not named main are ignored.
Go 在构建可执行 ELF 文件时,目前还是默认使用 -buildmode=exe,而从 2019 年 4 月底 Go 语言官方 Change Log 203606 开始,在 Windows 上构建可执行 PE 文件时,则会默认使用 -buildmode=pie:

下图是同一个项目,用 3 种不同的编译方式生成的可执行 ELF 文件 Section Headers 对比,从左至右编译方式依次为:
- go build
- go build -ldflags “-s -w”
- go build -buildmode=pie -ldflags “-s -w”
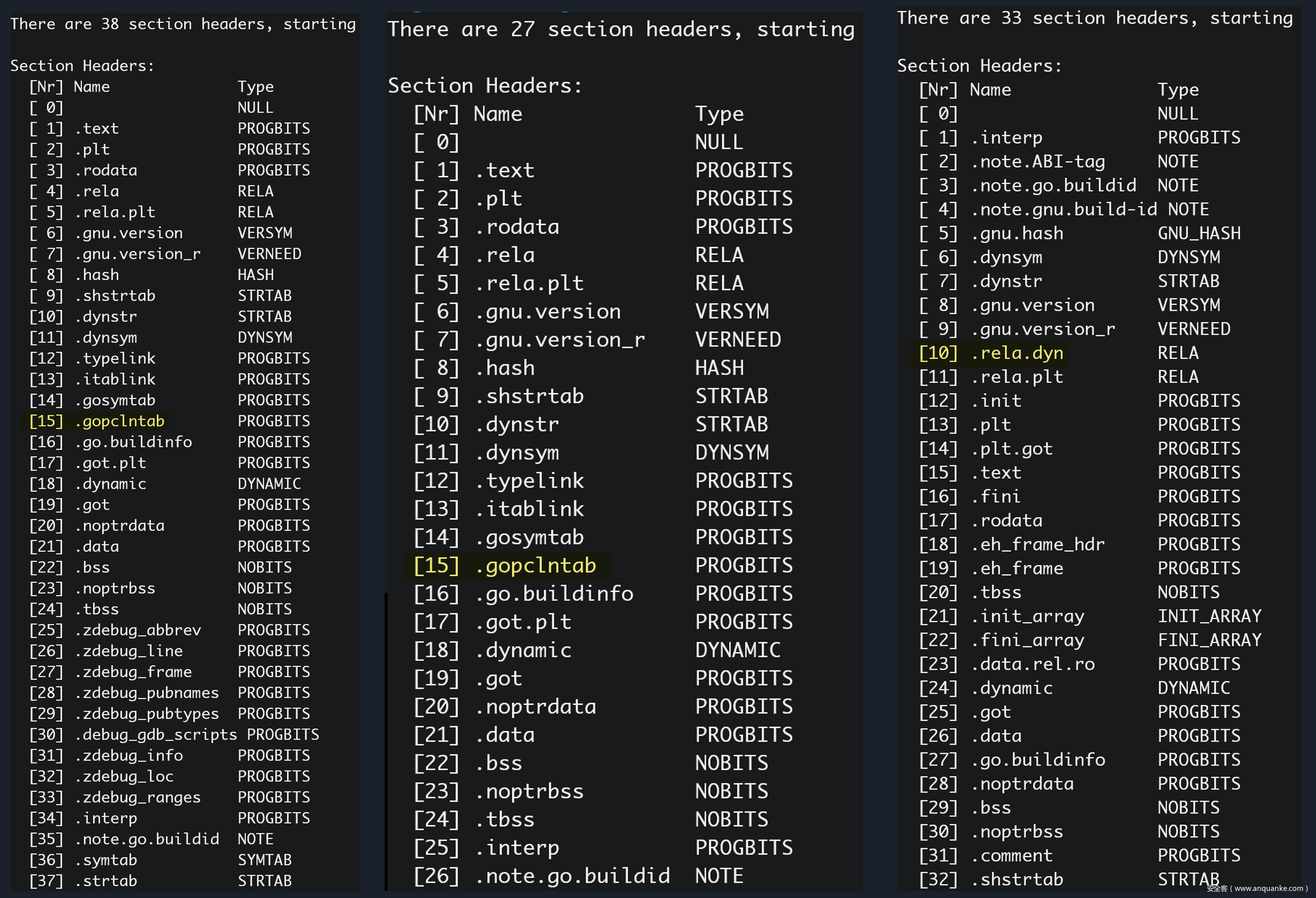
可以看到,第三种编译方式生成的 PIE 文件,是没有 .gopclntab 这个 Section 的,而是多了一些重定向相关的 Section。这也是前文《Go二进制文件逆向分析从基础到进阶——综述》中 redress 工具报错的原因:它根据 Section Name 查找 pclntabl 的思路,对 PIE 文件无效。
既然靠 Section Name 来定位 pclntab 的方式不靠谱,其他能用的方式就只剩暴力搜索 pclntab 的 Magic Number 了。通过研究发现,无论是否 PIE ,ELF 文件中的firstmoduledata 总是在 .noptrdata 这个 Section 里,PE 文件中可能会在 .data 或 .noptrdata Section,而 MachO 文件中的 firstmoduledata 会在 __noptrdata Section 中。如此一来,就可以按 uintptr 为单元遍历目标 Section,检查每个 uintptr 指向的地址前 4 字节是否为 pclntab 的 Magic Number 0xFFFFFFFB,找到这个位置,就差不多了。伪码可表示为:
Dword(uintptr(possible_firstmoduledata_addr)) & 0xFFFFFFFF == MagicNumber
之所以说 差不多,是因为二进制文件中可能还有别的值为 0xFFFFFFFB,并不是所有这个值的位置都是 pclntab。找到这个值,还要精准验证它是不是 pclntab,以及上级数据结构是不是 firstmoduledata 。
7.2.2 验证 firstmoduledata
按照上述思路,找到一个可能的 firstmoduledata 起始地址,其第一个 uintptr 元素指向的位置,前 4 字节为 pclntab 的 Magic Number。如果是真实的 firstmoduledata,它内部是有几个字段可以跟 pclntab 中的数据进行交叉验证的,比如:
- firstmoduledata.ftab == pclntab_addr + 8
- firstmoduledata.filetab == firstmoduledata.ftab + pclntab.functab_size + sizeof(uintptr)
- firstmoduledata.minpc == firstmoduledata.text_addr == uintptr(pclntbl_addr + 8 + ADDR_SZ) == first function of pclntab.functab
当然,不一定要验证上面所有条件,验证其中一部分甚至一个关键条件,就可以确认当前地址是否为真正的 firstmoduledata。
另外,随着 Go 的持续迭代, pclntab 和 moduledata 的结构定义也会发生变化。《Reconstructing Program Semantics from Go Binaries》 中对比过几个版本的 moduledata 之间的区别:
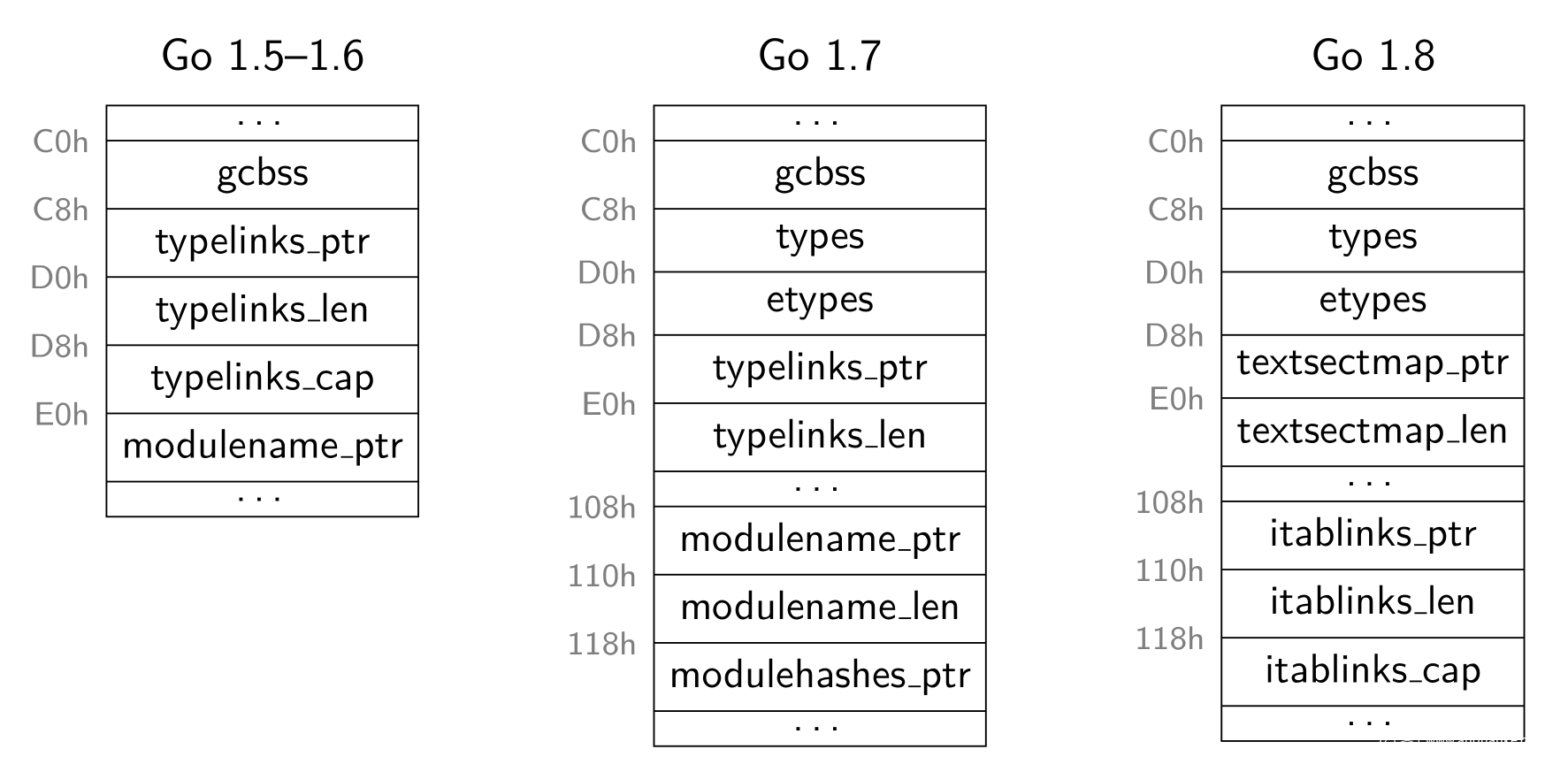
我们对此结构的解析,也要随着 Go 语言的迭代而进行相应调整,否则可能 Go 语言发了一个新版,里面改动了关键数据结构,我们按照旧的结构去解析,就会出错。







发表评论
您还未登录,请先登录。
登录