

大家好,我是第一次在安全客这个平台发文章,这次发这篇文章主要是想给大家介绍下一款基于FastAPI实现的Frida-RPC工具-Arida(Github地址),我是这个工具的独立开发者,想跟大家介绍下这款工具的开发构想以及它的使用方式。
1 开发设想
工具往往来源于日常工作,当工作中出现了“重复、重复、又重复”的环节时,一款能够节约时间、提高工作效率的工具便顺应诞生了。我的日常工作会涉及逆向分析APP协议,目前使用的工具一般都是Frida,有时候为了验证分析结果,都会采用Hook的方式调用方法并通过自带RPC的方法暴露出接口来,因为日常分析的APP数量比较多,所以碰到了一系列的问题促使我想给自己开发一套工具提升工作效率。
1.1 工作中遇到的问题
刚刚开始在工作中频繁使用Frida工具的同学一定会发现每次逆向分析APP的时候都需要写不同的JavaScript文件,时间一长,如何维护这么多文件?如何针对不同的APP启动对应的JavaScript文件?每个文件的重复代码如何抽取出来? 这些都是关于Frida-Js文件管理的问题。
这个问题怎么理解呢?大家知道Frida JavaScript Function的暴露方法是这样的
rpc.exports = {
decryptData: decrypt_data,
generateUrl: generate_url,
encryptData: encrypt_data
}
使用rpc.exports对应的Map来指定暴露方法和对应的函数,但是这样的话也只是利用了JavaScript的exports关键字使方法暴露出来使其他脚本能够调用。那怎么能够做成Http接口呢?可以直接利用NodeJs的Http框架,例如Express,不过我们使用最多的一般都是Python,例如Flask、Django这样的框架,用过框架的人都知道我们需要针对每个API写对一个的方法,例如这样
@app.route("/test")
def test():
return "hello"
结合这种方式,我们调用Frida-RPC的方式就是这样
@app.route('/sign')
def sign_test():
sign = request.args['sign']
res = script.exports.sign(sign)
return res
我们需要针对每个JavaScript方法写对应的Python方法并且要直接调用的参数,这导致的问题就是累积的方法越多,我们的整体项目就越庞大,但是其中很多部分的代码都是重复的简单的调用代码。
同样是个很麻烦的问题,当你很费劲的完成以上的所有操作并且部署好服务之后,其他人要使用你的这些API,你是否能提供一个完整的API文档?难道还是需要一个个接口去写相应的文档?
1.2 工具需要解决哪些痛点
针对以上的这些问题,我们需要一款高效率的工具能够帮助我们屏蔽这些工作中的细节问题,让我们能够更专注于去逆向分析APP中的调用流程。所以,我们需要一款工具能够完成以下这些功能:
- 管理
JavaScript文件,具备APP-文件的映射关系 - 自动针对现有的
JavaScript方法生成相应的API方法 - 自动生成
Open API文档
1.3 Arida工具
当“想开发一个工具”的想法产生的时候,就风风火火的搞起来了,大概花了两个小时的时间,完成了一个简单的工具,也就是这次提到的Arida这个工具,名称来源于Frida和API这两个词,简单拼接成的,具备的功能也是如上文提到的一样。
工作流程如下:
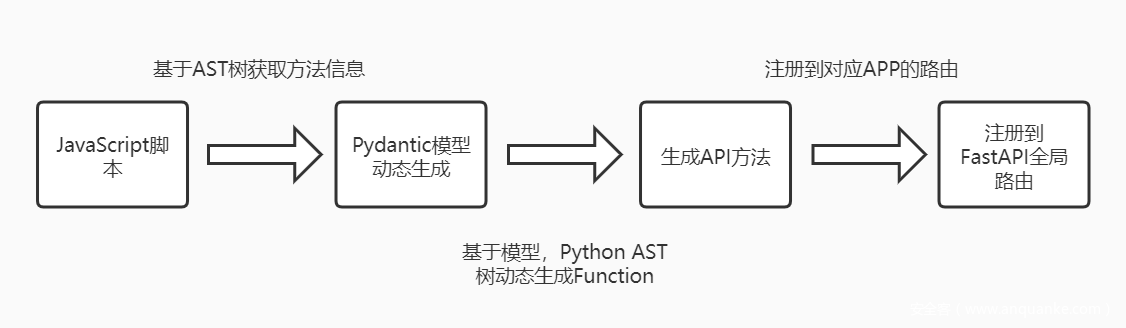
主要分为四步:
- 第一步:利用
JavaScript AST树获取到exports的Map中的函数名称以及对应的函数的参数个数,以便于后续的构造Pydantic的Model。 - 第二步:生成
Pydantic动态模型便于FastAPI的API Doc的生成。 - 第三步:结合
模型以及获取到的JavaScript的方法名和参数个数产生新的Python方法。 - 第四步:注册各个APP相对应的路由,最后注册到全局路由中。
2 源码解读
之前大致讲了Arida的整个工作流程,下面主要讲解下各个部分的实现。
2.1 Frida JavaScript脚本函数信息导出
一般的Frida-Js脚本的是这样的
var result = null;
function get_sign(body) {
Java.perform(function () {
try {
var ksecurity = Java.use('com.drcuiyutao.lib.api.APIUtils');
result = ksecurity.updateBodyString(body)
console.log("myfunc result: " + result);
} catch (e) {
console.log(e)
}
});
return result;
}
rpc.exports = {
getSign: get_sign,
}
我们需要获得的信息是导出函数名以及导出函数对应的内部函数的参数个数,考虑过使用正则来做,不过正则方法显得笨重,所以从JavaScript AST树入手,能够更好的解析到我们需要的信息。
解析的脚本如下:
const babel = require('@babel/core')
var exports = new Map();
var functions = new Map();
var result = new Map();
function parse(code) {
let visitor = {
// 处理exports节点,获取导出函数对应表
ExpressionStatement(path) {
let params = path.node.expression.right;
try {
params = params.properties
for (let i = 0; i < params.length; i++) {
exports.set(params[i].value.name, params[i].key.name)
}
} catch {
}
},
// 处理function,获取函数名以及对应参数
FunctionDeclaration(path) {
let params = path.node;
var lst = new Array();
for (let i = 0; i < params.params.length; i++) {
lst.push(params.params[i].name)
}
functions.set(params.id.name, lst)
}
}
babel.transform(code, {
plugins: [
{
visitor
}
]
})
exports.forEach(function (value, key, map) {
result.set(value, functions.get(key))
})
return Object.fromEntries(result);
}
主要解析了function和exports两个节点,最终返回Map
2.2 FastAPI API接口模型动态生成
上一步得到了JavaScript的Map数据,大概是这样
{
"getSign":3
}
接下来,需要利用这个信息来动态生成接口模型,之所以要生成接口模型,是因为在FastAPI这个框架当中,Post接口使用的是Pydantic的BaseModel,使用BaseModel的原因也是因为一方面要生成对外的接口文档,另一方面要对参数做类型校验,动态生成的代码如下:
from pydantic import create_model
params_dict = {"a":""}
Model = create_model(model_name, **params_dict)
引入Pydantic的create_model,参数是各个方法参数的类型,例如是String类型就直接是"",是int类型就直接是0。
2.3 基于Python AST动态生成Python方法
到了最后一步,有了模型以及JavaScript的Map数据我们就可以动态生成Python方法了,由于一般的API方法都是一样的,如下:
def sign_test():
sign = request.args['sign']
res = script.exports.sign(sign)
return res
我们这需要动态生成以上这种格式就好了,可以采取两种方案
- 第一种:闭包的方法-函数返回函数,比如
def outer(): def inner(): return "hello" return inner - 第二种:使用
Python AST树生成Python字节码,利用types.FunctionDef来生成,代码如下:function_ast = FunctionDef( lineno=2, col_offset=0, name=func_name, args=arguments( args=[ arg( lineno=2, col_offset=17, arg='item', annotation=Name(lineno=2, col_offset=23, id=model_name, ctx=Load()), ), ], vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[], posonlyargs=[] ), body=[ # Expr( # lineno=3, # col_offset=4, # value=Call( # lineno=3, # col_offset=4, # func=Name(lineno=3, col_offset=4, # id='print', ctx=Load()), # args=[ # Call( # lineno=3, # col_offset=10, # func=Name(lineno=3, col_offset=10, # id='dict', ctx=Load()), # args=[Name(lineno=3, col_offset=15, # id='item', ctx=Load())], # keywords=[], # ), # ], # keywords=[], # ), # ), Assign( lineno=3, col_offset=4, targets=[Name(lineno=3, col_offset=4, id='res', ctx=Store())], value=Call( lineno=3, col_offset=10, func=Attribute( lineno=3, col_offset=10, value=Attribute( lineno=3, col_offset=10, value=Name(lineno=3, col_offset=10, id='script', ctx=Load()), attr='exports', ctx=Load(), ), attr=func_name, ctx=Load(), ), args=[ Starred( lineno=4, col_offset=38, value=Call( lineno=4, col_offset=39, func=Attribute( lineno=4, col_offset=39, value=Call( lineno=4, col_offset=39, func=Name( lineno=4, col_offset=39, id='dict', ctx=Load()), args=[ Name(lineno=4, col_offset=44, id='item', ctx=Load())], keywords=[], ), attr='values', ctx=Load(), ), args=[], keywords=[], ), ctx=Load(), ), ], keywords=[], ), ), Return( lineno=4, col_offset=4, value=Name(lineno=4, col_offset=11, id='res', ctx=Load()), ), ], decorator_list=[], returns=None, )先动态生成对应方法的
Python AST树module_ast = Module(body=[function_ast], type_ignores=[]) module_code = compile(module_ast, "<>", "exec") function_code = [ c for c in module_code.co_consts if isinstance(c, types.CodeType)][0]生成对应
Python AST树的字节码function = types.FunctionType( function_code, { "script": script, model_name: model, "print": print, "dict": dict } ) function.__annotations__ = {"item": model}利用
字节码生成新的方法,由于在生成新方法的时候会丢失原字节码的注解,也就是__annotations__这个属性,因此需要在生成新方法之后手动补充。
3 使用方式
下面讲下Arida具体的使用方式,项目中已经包含了两个简单的例子,在Apps目录下面,配置信息在config.py文件中。
3.1 两步构建新项目
如何构建新项目呢?只需要两步就可以了,按照如下所示的步骤:
- 第一步:添加配置信息,文件地址是
config.py
INJECTION_APPS = [
{
"name": "我的测试1",
"path": "yuxueyuan",
"package_name": "com.drcuiyutao.babyhealth"
},
{
"name": "我的测试2",
"path": "kuaiduizuoye",
"package_name": "com.kuaiduizuoye.scan"
}
]
如代码中所示,需要在INJECTION_APPS列表中添加具体APP的信息,主要是三个字段:
-
name:影响的是FastAPI Doc中的分组名称,没有具体的实际意义,可以理解成对看接口文档的人的体验度的提升。 -
path:根据这个字段的值在Apps文件夹中匹配到对应的JavaScript文件。 -
package_name:需要注入的包名
添加好之后就完成了第一步。
- 第二步:开发对应APP的
Frida-Js脚本
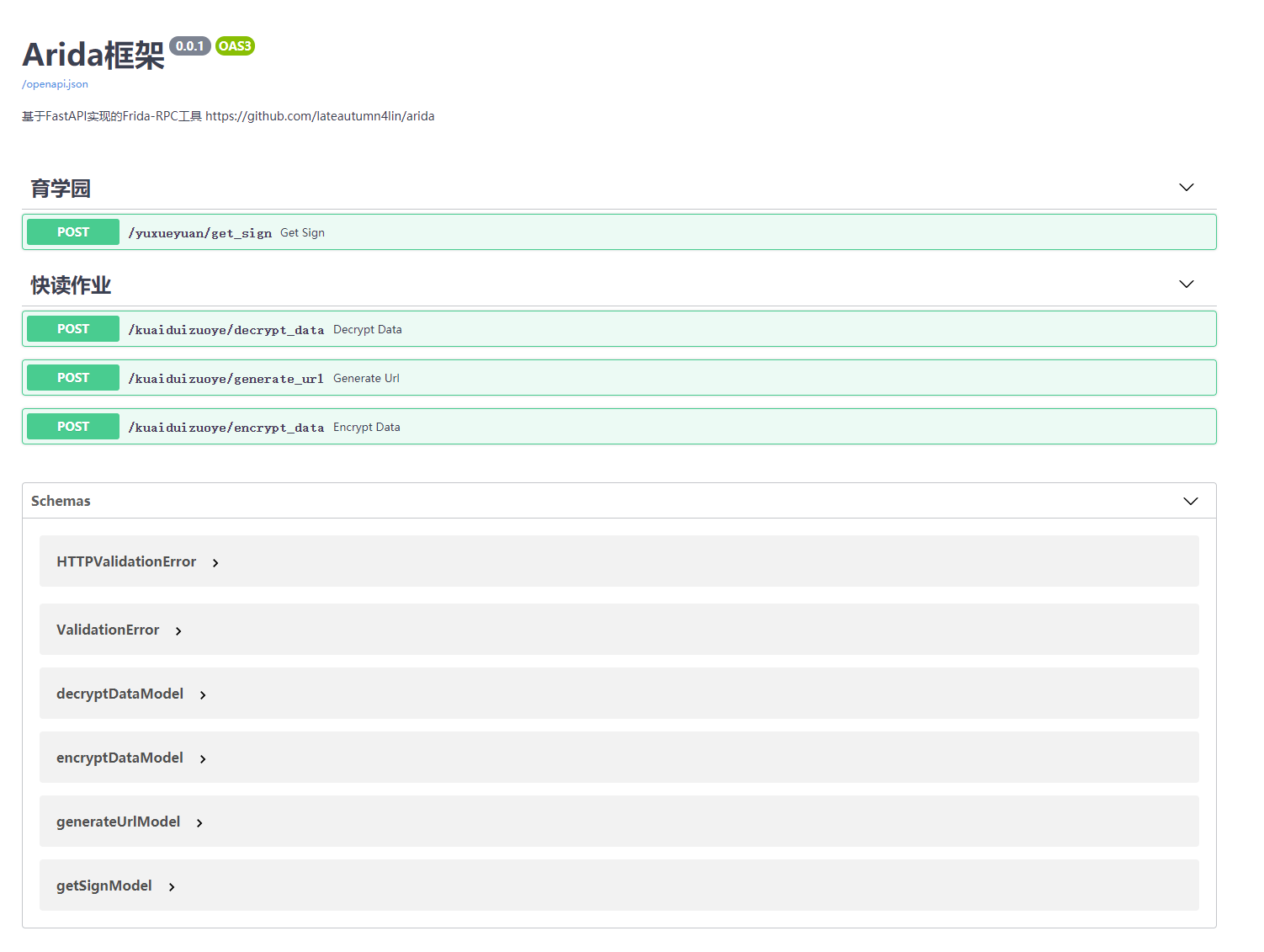
3.2 企业级多APP签名API暴露
因为在日常工作中,我们往往会同时去逆向分析多个APP,所以同时暴露多个APP的API接口测试也是必不可少的,Arida支持同时启动多个APP并注入相应的JavaScript脚本,只需按上面的步骤完成每个APP项目的开发,启动的时候会自动注入相应的APP,同时,在查看文档的时候也会如图所示:
4 注意点
4.1 参数类型标记
由于JavaScript不能指定方法的参数的类型,导致读取到的JavaScript的方法只能是参数个数,不能获取参数的类型,因此生成的Pydantic模型的时候只能统一类型为字符类型,如果想要自定义参数的类型,可以在main.py文件中的function_params_hints来进行配置:
function_params_hints = {
"encryptData": [0, 0, 0, 0, "", 0, 0, 0, 0, 0, 0]
}
通过这样来生成合适的参数模型,这样在使用者使用接口的时候由参数模型根据模型中的参数对应的类型来进行类型转化。







发表评论
您还未登录,请先登录。
登录