

摘要
有针对性的网络钓鱼邮件正在增加,并每年从机构中窃取数十亿美元。虽然通过传统的恶意软件签名或机器学习技术可以检测到来自电子邮件中附件文件或恶意URL的恶意信号,但要识别不包含任何恶意代码、不与已知攻击共享单词选择的手工社交工程电子邮件是一项挑战。为了解决这个问题,我们通过用简单的适配器替代一半的Transformer块来对预训练的BERT模型进行了微调,从而有效地学习自然语言的语法和语义的复杂表示。我们的上下文感知(Context-Aware)网络还能从邮件标题中学习邮件内容和上下文特征之间的上下文表示形式。我们的CatBERT(Context-Aware Tiny Bert)实现了87%的检测率,相比之下,Distil BERT、LSTM和逻辑回归基线在假阳性率为1%的情况下,分别实现了83%、79%和54%的检测率。我们的模型也比与之竞争的Transformer方法更快,并且对故意用错别字或同义词替换关键词的对抗性攻击具有弹性。
1.简介
利用手工电子邮件进行社交工程攻击是网络犯罪的一个主要类别。因为这些电子邮件往往是手写的,有个别针对性的,并且经常结合目标对象的背景调查[17],它们对传统的检测系统构成了巨大的挑战,因为传统的检测系统依赖以前看到的垃圾邮件和新的恶意邮件之间的重复来识别这些邮件。事实上,有针对性的网络钓鱼邮件可能与之前看到的攻击没有任何没有任何相同的单词序列或单词选择,而且可能与良性邮件只有细微的差别。图1列出了两封有针对性的钓鱼邮件,以说明手工的钓鱼邮件的外观和感觉。虽然这些样本不包含任何恶意附件或钓鱼网址,但它们迫使受害者遵守要求的行为,已成为攻击剧本的一部分。

为了检测有针对性的钓鱼邮件,我们对一个定制的基于BERT的模型进行了微调,该模型已经对数十亿字的良性文本进行了预训练,以学习自然语言的语法和语义的复杂表示[1]。这使得网络能够拾取电子邮件主题、语气和风格的微妙之处。我们的微调方法则大大降低了网络的复杂性,并优化了网络以检测钓鱼攻击。BERT是一种基于Transformer的自然语言处理(NLP)模型,它在包括情感分类、机器阅读理解和自然语言推理等NLP任务中取得了巨大的成功。然而,在实时安全应用中部署具有高达3.4亿个参数的全规模BERT模型仍然具有挑战性。我们的微调方法获得了一个更小更快的模型,且性能得到了实质性的提升。除了电子邮件中的文本数据外,标题字段还提供了有关发件人和收件人之间关系的附加上下文信息。我们的网络架构将电子邮件的内容数据与这些附加的上下文结合起来,并提高了分类性能,超越了vanilla BERT。
我们的工作贡献如下:
- 我们提出了一个基于BERT的钓鱼邮件检测模型,该模型从邮件正文中的内容数据和邮件标题中的上下文数据中学习复杂的表示形式。所提出的模型在相同的训练数据上的表现优于vanilla BERT模型。
- 全尺寸的BERT模型对于实时安全应用来说是相当沉重的。我们的微调方法通过用简单的适配器替换两个Transformer块中的一个,大幅降低了模型的复杂性,从而得到了一个更小更快的模型。
- 我们的模型对故意用错别字或同义词替换单词的对抗性攻击具有很强的鲁棒性。
本文其余部分安排如:第2章介绍了相关工作。第3章阐述了我们所提出的方法,然后在第4章讨论该实验。在第5章对我们的工作做总结。
2.相关工作
我们的工作涉及到文本分类的机器学习模型和BERT模型的模型压缩方法的研究。
2.1机器学习方法
攻击者一直在使用各种技术来逃避现有的检测方法,这使得基于签名的方法在检测不断进化的攻击时效果不佳。研究人员提出了各种机器学习模型来解决这个问题。传统的NLP方法,在实践中仍然被广泛使用,提取TF-IDF(Term Frequency – Inverse Document Frequency)的特征,并训练逻辑回归(logistic regression)、基于树型结构和支持向量机(SVM)模型[10,16,18]。最近的工作在顺序语言数据上的应用[6,9]采用了RNN(Recurrent Neural Network)或CNN(Convolutional Neural Network)模型。
作者[10]利用 “phishy “关键词和URL信誉信息的特征,训练了一个随机森林分类器。信息,并从一个大规模的数据集中发现了不可见的钓鱼攻击。虽然他们的方法依赖大数据集的历史统计来收集URL的信誉分数,并计算收件人的相似度分数,但历史通信数据并不总是有效的。[6]的工作提出了一种基于LSTM(Long Short Tern Memory)的模型,利用4995个单词词汇,利用单词序列检测钓鱼攻击。我们的实验模型还包括一个基于LSTM的模型,其中包含了来自多语言BERT记号赋予器(tokenizer)的约12万个token,该模型的性能优于非基于序列的逻辑回归基线模型。然而,我们的实验表明,LSTM模型的表现被基于Transformer的模型所超越。在[9]中,引入了一个基于CNN的模型,仅从邮件标题中提取特征来检测潜在的垃圾邮件。我们的实验表明,结合来自邮件标题和正文的特征,可以提高对各种钓鱼攻击的检测性能。
2.2 Transformer模型
我们在这里提出的模型是基于一种比较新的神经网络构造,叫做transformer块。transformer块是为每个词输出依赖于该词上下文的上下文向量的注意力机制,是BERT[1]和GPT[12]等自注意(self-attention)语言模型中的核心组件,当2018年研究人员使用BERT在11个NLP任务中展示了最先进的结果时,该模型就被人们所熟知。
我们的模型来源于BERT,其训练过程包括两个阶段。在第一个预训练阶段,训练一个(全尺寸)BERT模型,以大规模数据集预测句子中的屏蔽词。该模型还学习正确预测下一个句子的预测。在第二个阶段,针对特定的分类任务,用标签目标数据集对预训练的模型进行微调。在微调步骤中,添加分类数据头,并通过训练标签对整个网络进行联合优化。由于模型的参数是在第一阶段用大规模数据进行预训练的,所以微调只需要用一个小的标签数据集进行两到三个迭代次数的训练,就可以得到最先进的性能。
OpenAI的GPT是一种基于差异化transformer块的方法,在2018年的众多NLP任务中也取得了最先进的成果。该模型使用一个标准的语言建模目标来最大化给定句子的下一个token的可能性。该模型由多个Transformer块组成,这些Transformer块对输入文本应用多头自注意操作。在通过预测句子中的下一个工作来训练模型后,通过优化监督目标和语言建模目标来进一步训练模型。虽然GPT可以对分类任务进行微调,但自回归语言模型的最佳应用是文本生成。在我们的初步实验中,当GPT和BERT模型包含相同数量的Transformer块时,它们都获得了相当的性能。
2.3 模型压缩
虽然复杂的BERT模型获得了令人印象深刻的结果,但全尺寸的模型计算成本高,内存密集。为了解决大型模型存在的问题,人们引入了模型压缩方法,在不显著降低模型性能的前提下减少模型的参数。参数修剪[14]和知识提炼[13]是模型压缩的有效方法。
修剪方法通过测量神经元的重要性来去除不太重要的神经元或集合。虽然这些方法会带来更小的稀疏网络,但由于许多深度学习框架并不完全支持稀疏操作,因此并不能保证推理时间的加速。
知识提炼法将深层网络压缩成浅层网络,其中压缩模型即学生网络模仿复杂模型即教师网络学习的功能。知识提炼的优势之一是,任何学生架构都可以用复杂的教师网络进行训练。该方法用一个标准的分类损失和一个额外的提炼损失来训练一个学生模型。提炼损失表示两个模型之间的输出差异,并允许学生(网络)从大型教师(网络)那里学习丰富的表征。
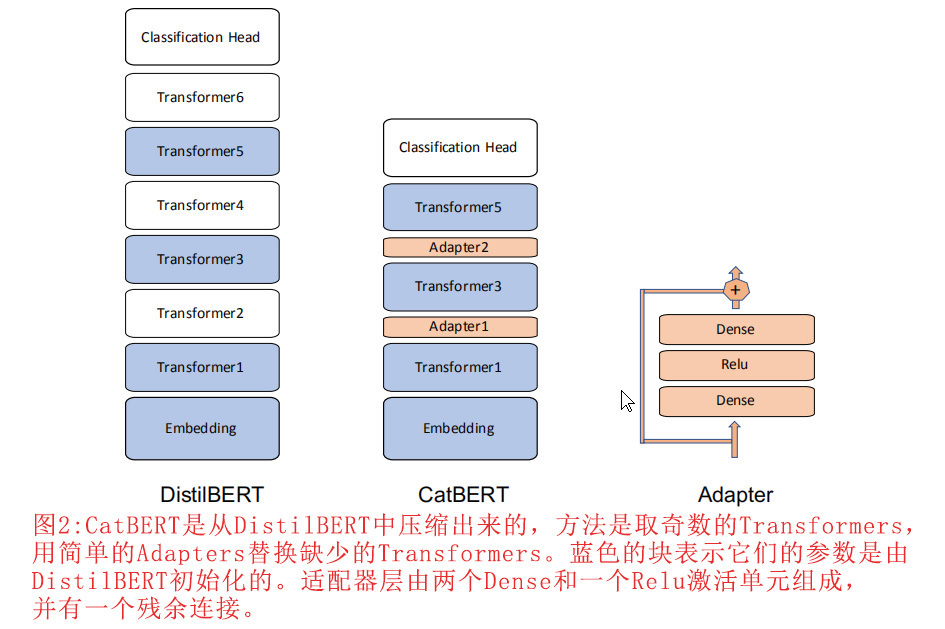
已经提出了几种压缩的BERT模型,如DistilBERT[2]和ALBERT[4]。DistilBERT减少了Transformer块的数量,而ALBERT通过在跨层中共享一个Transformer块来减小模型的大小。我们的方法是减少Transformer块的数量,用简单的适配器代替缺失的Transformer块,从而使结果更加稳定和改进。
3.提议的方法
BERT和GPT等最先进的NLP模型在包括情感分类、机器阅读理解和自然语言推理等自然语言处理(NLP)任务中取得了巨大的成功。它们的成功源于半监督学习,它同时利用了无监督和监督的方法和高效的自注意架构。目前的NLP模型具有由Transformer块组成的自注意层,它们的性能优于现有的模型,包括多层感知器(MLP)和递归神经网络(RNN)模型。半监督学习是一个两阶段的过程,包括用一个大的非标记数据集进行预训练和用一个小的标记数据集进行微调。该学习过程允许我们微调一个预先训练好的BERT模型来解决我们的电子邮件分类问题。在本节中,我们将介绍我们的网络架构和微调方法,以提高运行时间和分类的性能。
3.1 网络架构
我们对一个由标准的BERT模型压缩而成的预训练好的DistilBERT模型进行微调。学生网络(DistilBERT)在预训练中使用大型教师网络(BERT)进行了训练,较薄的学生模型获得了与其教师网络相当的性能[2]。由于DistilBERT中的Transformer块是用大数据集预先训练的,所以我们的方法是通过减少Transformer层的数量来进一步压缩DistilBERT。我们用简单的适配器来替换被移除的Transformer块。适配器块的灵感来自于参数高效迁移学习[19]的想法,它在每个Transformer的内部增加了微小的适配器。他们插入适配器的主要动机是为了降低许多下游任务的微调成本。他们的微调方法允许下游模型通过微调过的特定任务的适配器重用一个大而固定的Transformer参数。然而,他们的方法增加了下游模型的推理成本,因为适配器增加了生产系统预测的额外计算成本。我们的方法用简单的适配器替换了部分Transformer块,提高了推理速度。我们还修正了下部的两个Transformer块,但微调了剩余的上部Transformer块。在我们的部分微调实验中,我们冻结了两个下层Transformer块,并与下游任务联合微调了所有适配器和一个上层Transformer块。
虽然DistilBERT重用了BERT中使用的核心网络架构,但通过从两层中抽取一层,Transformer层数从12层减少到6层。我们的邮件模型CatBERT进一步将DistilBERT压缩了2倍。由于DistilBERT是使用大规模数据集的大型教师进行预训练的,我们通过从DistilBERT中初始化我们的微小BERT模型来重用优化后的参数,然后去除一半的Transformer块。我们的微调方法在没有教师模型的情况下直接优化了生成网络的参数,因为我们的初步实验表明,CatBERT上的知识提炼并没有提高检测性能,但却大大增加了训练成本。图2描述了我们如何减少Transformer块的数量。简单地去掉每一个偶数或奇数的Transformer,我们就可以将基于Transformer的模型的大小和复杂度降低2倍。第一、第三、第五个Transformers和底部嵌入层是由DistilBERT的参数初始化的。然而,顶部分类器头是随机初始化的。缺少的Transformer块被简单的随机初始化、可训练的Adapter块所取代。适配器块由一个完全连接的密集单元、一个Relu激活和具有残余连接的第二密集单元组成,密集单元与Transformer具有相同的维度。令人惊讶的是,尽管在原来的DistilBERT模型中,假定连续的块之间存在相互依赖性,但只要去掉一半的变压器块,用可训练的Adapter块代替它们,就足以超越完整模型的高性能。我们没有进一步探讨这个问题,但指出这是未来研究的一个领域。
我们使用二元交叉熵损失函数来拟合网络。给定我们的模型f(x;θ)对输入x和标签y∈0,1以及模型参数θ的输出,就可以定义损失L。
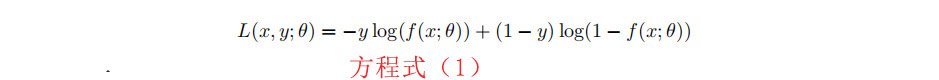
我们求解θˆ的最佳参数集,使数据集上的损失降到最小。
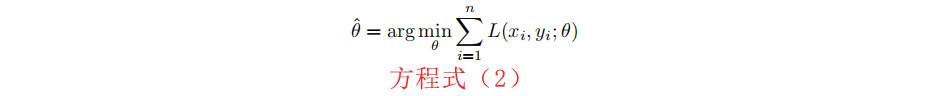
其中N是我们数据集中的样本数,xi和yi分别是ith训练样本和标签的特征向量。
3.2内容特点
最先进的NLP模型对原始文本进行预处理,并将文本转换为单词标记序列。传统的NLP模型使用预定义的词汇进行标记化,但最新的模型如BERT和GPT采用了子字标记化器。我们使用的是BERT tokenizer,它可以将一个复杂的词划分为简单的子词,并为英语模型维护了30 522个tokens,为多语言模型维护了119 547个tokens[1]。子词标记器可以解决词汇外的问题,因为未知词被标记为子词。token输入用token嵌入来表示,tokens的位置信息用位置嵌入来表示。有两个特殊的tokens,CLS是第一个令牌,SEP是每个文本输入的最后一个令牌。基于BERT的模型可以处理的最大序列长度为512。
当tokens的长度大于限制时,我们从tokens的开头截断文本。最后一个Transformer块中CLS token的隐藏状态被输入到最后的分类层。例如,当给出主题和主体文本时,提供并列的BERT tokens作为token嵌入块的输入,另外将token的位置信息输入位置嵌入块。在训练过程中联合学习两个嵌入,并将求和向量反馈给下一个Transformer层。当电子邮件中包含一个没有纯文本正文的HTML正文时,我们使用HTML解析器和一个简单的正则表达式来提取纯文本。HTML解析还可以防止HTML混淆攻击的风险,即在单词之间插入随机的HTML标签。
3.3 上下文特征
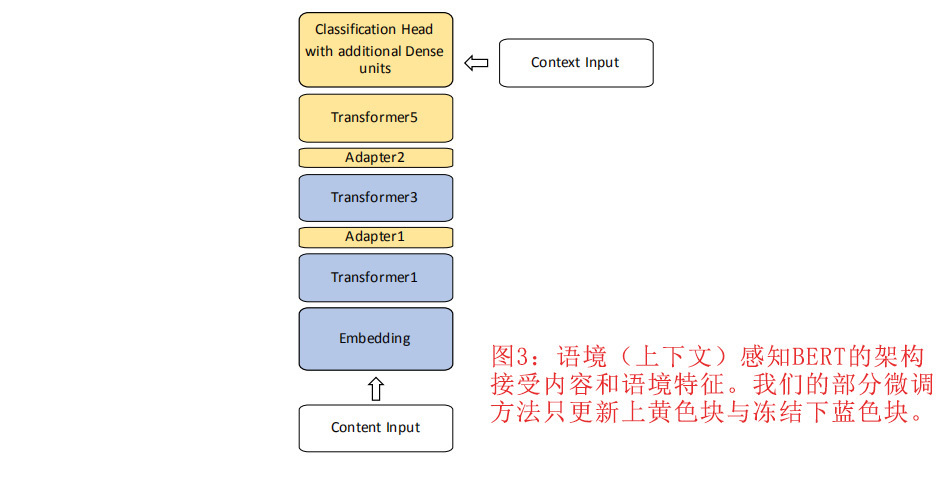
标准的BERT模型只接受文本作为输入。然而,一封邮件由文本内容和标题字段组成,它们提供了有价值的上下文信息。我们的上下文感知方法结合了来自文本的内容和来自标题字段的上下文作为输入数据。文本数据是由邮件的主题和正文中的一句话连缀而成。我们从标题字段中提取以下四个上下文特征。虽然上下文特性非常简单和通用,但它们捕获关于发件人和收件人之间通信的基本上下文信息。
- 内部通信:如果通信的发送者和接收者属于同一域名,则为内部通信。
- 外部通信:如果发送方和接收方的域名不同,则为外部通信。
- 收件人数量:表示收件人的大小。
- CC(Carbon Copy)数量:表示抄送的大小。
为了适应上下文和内容特征,我们的模型接收两个输入。如图3所示,内容特征被输入到嵌入层,上下文特征被输入到分类层。在最后一个Transformer层之后还有额外的密集单元,在密集层中结合了Transformer的富文本表达的上下文特征,从而使性能得到显著提升。CatBERT的分类头返回sigmoid输出,表示输入邮件的恶意程度。
参考文献:
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In arXiv preprint arXiv:1810.04805, 2018.
【下略】







发表评论
您还未登录,请先登录。
登录