

起因
近期在内网发现了有个应用之前的开放重定向漏洞的绕过,通过这个漏洞绕过,我又发现了 apache/dubbo 的一个有意思的问题以及 URL 相关的话题。
之前,给内网应用提交过一个开放重定向漏洞,后面又发现这个开放重定向漏洞存在一个绕过方法。假设一个恶意 URL 为 https://evailhost#@whitehost,那么这个恶意链接依然可以实现跳转。开发说他们已经做过了白名单限制,理论上应该不存在被绕过的可能了。那么我就去看了下代码,对于重定向地址进行验证的代码类似如下。
public static String checkUrlSafety(String url, List<String> domainWhitelistSuffix, String domainWhitelist) {
Url url2 = null;
try {
url2 = UrlUtils.parseURL(url, null);
} catch (Exception e) {
}
String host = url2.getHost();
if (verifyDomain(host, domainWhitelistSuffix, domainWhitelist)) {
return url;
} else {
...
}
}
private static boolean verifyDomain(String host, List<String> domainWhitelistSuffix, String domainWhitelist) {
return domainWhitelist.contains(host) || verifyDomainSuffix(host, domainWhitelistSuffix):
}
apache/dubbo 的问题
核心代码其实主要就是上面两个函数,主要是通过 verifyDomain 方法来进行白名单的过滤,那么问题就很有可能出现在这里。这里,值得注意的是,host 是通过 UrlUtils.parseURL 解析出来的 URL 获取的。这个方法是开源仓库 apache/dubbo 的,组件版本是 2.7.8,是最新的版本。可以简单的通过一个 demo 代码来验证一下问题所在。
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.utils.UrlUtils;
public class Main {
public static void main(String[] args) throws Exception {
String[] whiteHosts = new String[]{"whitehost"};
String evilUrl = "https://evilhost#@whitehost";
URL url = UrlUtils.parseURL(evilUrl, null);
System.out.println(url.getHost());
System.out.println(whitehostCheck(whiteHosts, url.getHost()));
java.net.URL url1 = new java.net.URL(evilUrl);
System.out.println(url1.getHost());
System.out.println(whitehostCheck(whiteHosts, url1.getHost()));
}
private static boolean whitehostCheck(String[] whiteHosts, String hostToCheck) {
for(String host: whiteHosts) {
if (host.equals(hostToCheck)) {
return true;
}
}
return false;
}
}
上面的执行结果是:
evilhost
false
whitehost
true
很明显,问题出现在 parseURL 这个方法上,它错误地解析了这个链接的 host,如果这个链接中包含 @ 符号(在实际利用场景中还需要配合 # 符号进行利用,这个在后文还会提到)。那么下面就看看这个 parseURL 方法,这个函数位于 org.dubbo.common.utils.UrlUtils.java 中。不如打个断点,进去看看。
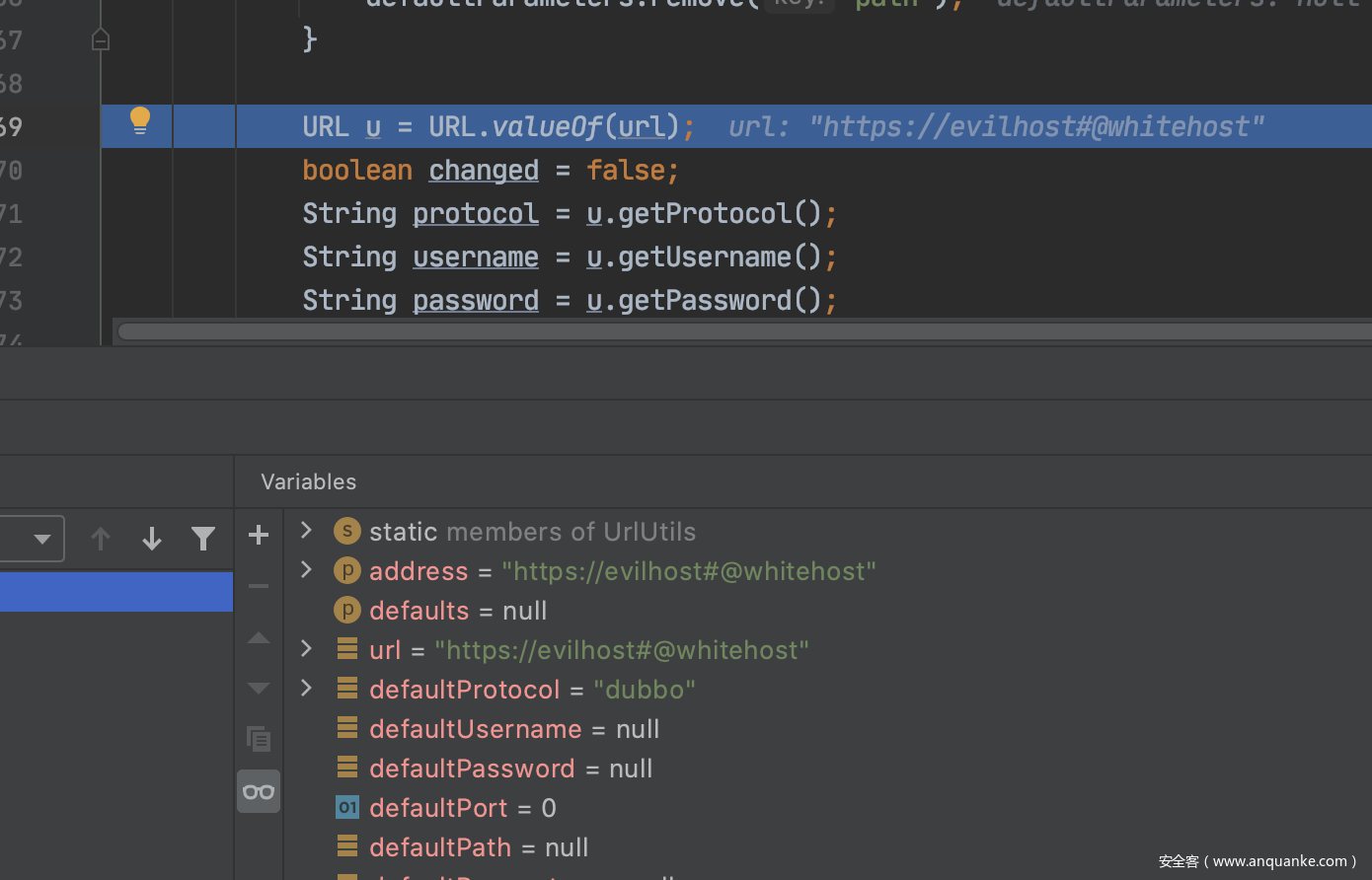
在 parseURL 方法中并没有特别之处,到这处 URL u = URL.valueOf(url);,进入到 valueOf 这个函数中。
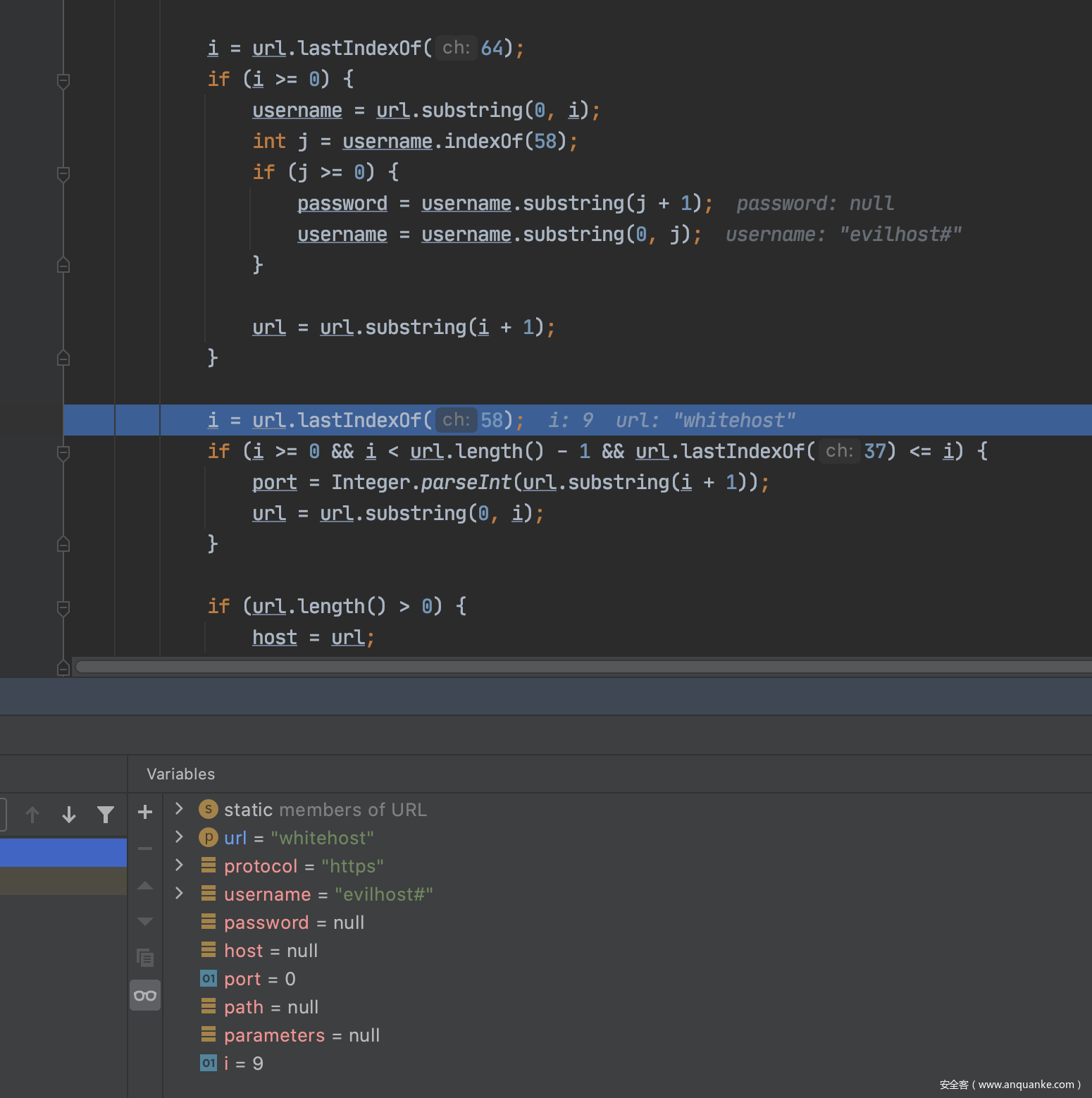
上面的逻辑就是如果 url 中包含 @ 符号的话,那么就先解析出 username 为 evailhost#,从而得出 host 为 whitehost。正是因为这一步解析导致解析出的 host 不正确。关于这个问题,我也一直很纠结这到底算不算一个安全漏洞。不过仔细想想,严格意义上这还不能算作一个安全漏洞,更应该算是一个 bug。我一开始有写一个报告提供给 dubbo 的官方安全邮箱,不过一直没有收到回复,后来还是给他们的仓库提了一个 issue。我的修复建议是 valueOf 里面的逻辑就不要自己去造轮子实现了,还不如使用 JDK 的方法去解析 URL。
URL 的其它门道
那么关于这个绕过是不是就到此结束了,并没有,通过这个问题我也发现了好几个有意思的点,下面我将一一分享。
@ 符号
首先,先谈谈 url 中的 @ 符号,在上文提到过,这个开放重定向的利用需要配合 # 符号。为什么呢?如果仅仅通过 @ 符号是可以通过白名单校验的。假如 url 为 http://evilhost@whitehost,那么解析出的 URL 的 host 为 whitehost,因此是可以通过白名单校验的。但是在重定向的时候,只会重定向到 whitehost 下,这样就达不到攻击的目的了。我有创建一个 spring-demo 项目来验证。
@GetMapping(value = "/redirect")
public RedirectView redirect(@RequestParam String service) {
System.out.println(service);
RedirectView view = new RedirectView();
view.setUrl(service);
return view;
}
对于 redirect 接口,请求 http://localhost:8080/redirect?service=https://baidu.com@github.com,它会重定向到 github.com 而不是 baidu.com。原因在于 @ 符号前面的内容会被认为是账号部分。
# 符号
聊完 @ 符号,还要说说 # 符号。假设下面两个链接:
%23 是 # 符号 url 编码的结果,那么这两个链接的结果会是一样的吗?答案是否定的,因为对于浏览器来说,或者说 url 的标准规范来说,# 和 %23 有着截然不同的含义。

在 url 中,# 部分的内容被称为 fragment,一般是用于定位页面的内容,像一般页面中的一级标题二级标题,经常是通过这个来进行定位的。这个符号在目前前端框架中的单页面应用也有着广泛的使用。所以,如果传入的参数是 http://evilhost#@whitehost,那么实际传入的仅仅只是 http://evilhost。
大部分语言或者 web 服务已经实现了对 url 中 url 编码的内容自动进行 url 解码。尝试过 spring boot 以及 golang 之后,发现这二者创建的服务都支持 url 解码。
@GetMapping(value = "/cas")
public String test(@RequestParam String service) {
System.out.println(service);
return "";
}
如果请求 http://localhost:8080/cas?service=http://evilhost%23@whitehost,那么后台实际接收到的参数将是 http://evilhost#@whitehost。另外尝试了 golang 搭建的 web 服务,其结果是一致的。
package main
import (
"io"
"log"
"net/http"
"fmt"
)
func main() {
helloHandler := func(w http.ResponseWriter, req *http.Request) {
host, _ := req.URL.Query()["host"]
fmt.Println(host)
io.WriteString(w, "Hello, world!\n")
}
http.HandleFunc("/hello", helloHandler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
总结
通过这次的开放重定向的绕过,发现了很多很有意思的问题。即使可能看起来微不足道的问题,可能也会暗含玄机。由于开发使用了 dubbo 中的 parseURL 方法去解析 url,从而导致白名单的校验被绕过,这可能是开发也没有预料到的。对于某些方法,如果研究的比较深入,的确是会有一些未预料到的影响。







发表评论
您还未登录,请先登录。
登录