

摘要
近年来,报告的漏洞已经显著增加,其中SQL注入(SQLi)是最突出的,特别是在Web应用程序。这些漏洞的增加可以解释为多个软件部件(如各种插件和模块)的集成,通常由不同的组织开发,从而组成了网络应用的变种。机器学习有可能成为寻找漏洞的重要盟友,通过减少搜索空间或甚至通过自己对程序进行分类来帮助专家。然而,以往的工作通常不考虑SQLi或利用难以扩展的技术。此外,对于PHP这种最流行的Web应用服务器端语言,利用机器学习进行漏洞检测存在明显的差距。本文提出了一个深度学习模型,能够将PHP切片分类为易受SQLi攻击(或不受攻击)。由于片子可以属于任何变体,我们建议使用一种中间语言来表示片子,并将其解释为文本,求助于研究透彻的自然语言处理(NLP)技术。使用该模型的初步结果表明,它可以发现SQLi,帮助程序员并排除最终将花费大量成本来修复的攻击。
第一节. 导言
网络应用已经成为每个人生活的中心。我们用它们来查看邮件、进行交易、进行社交等等。随着它们的作用越来越大,对黑客的吸引力也越来越大,漏洞数量也在逐年持续增长。近几年来,报告的漏洞明显增多[1],其中SQL注入(SQLi)是最突出的漏洞之一,尤其是在Web应用中,并出现在OWASP的Top10上[2]。此外,SQLi被认为是最具破坏性的Web漏洞之一,因为它们允许入侵者访问私人数据,成功的攻击会让公司花费大量的资金进行修复。另外,SQLi漏洞相对容易被利用,这使得它们对攻击者更有吸引力。例如,在所有网络攻击中,它们占了三分之二(65%)的网络攻击[3]。
SQLi 漏洞的增加也可以解释为多个软件部件(例如,各种插件和模块)的集成,通常由不同的组织开发,从而组成了网络应用的变种。例如,正如Nunes等人[4]和Medeiros等人[5]的作品所示,WordPress插件以其糟糕的安全形状而闻名。
一些工具采用了不同的技术来检测网络应用程序的漏洞,最流行的是那些依赖于静态分析[6][7][8]-[9]的技术,即通过分析应用程序的源代码来搜索漏洞,以及模糊[10][11][12]-[13]的技术,即通过注入恶意输入来执行对目标应用程序的攻击,并验证它们是否成功(即利用应用程序中存在的任何漏洞)。然而,这两种技术都存在局限性,分别导致产生假阳性(不存在的漏洞)和假阴性(未检测到的漏洞)。最近,机器学习(ML)作为一种发现漏洞的技术出现了。一些工具诉诸数据挖掘[14]、[15],从应用程序的源代码中提取可以与漏洞相关的特征,预测应用程序是否包含漏洞;另一些工具则采用自然语言处理(NLP)算法[16]和神经网络[17]、[18]来处理应用程序代码,并输出是否包含漏洞。虽然ML模型取得的进展已经在准确、精确地检测漏洞上迈出了第一步,但该领域仍有改进空间。
在本文中,我们提出了一种利用深度学习(DL)和NLP的新型方法,以将PHP切片分类为易受SQLi攻击(或非易受攻击)。尽管PHP是最流行的Web应用服务器端语言[19],但通过ML来检测PHP中的软件漏洞仍然是相对未被探索的。我们以其操作码格式处理PHP代码片,该格式类似于C/C++的汇编操作码,被认为是一种中间语言。这种方法可以让我们更近距离地观察语言的内部结构,这对我们旨在解决的分类任务有帮助。此外,由于切片可以属于任何网络应用变体,使用中间语言来表示它们可以促进变体之间的分析横向性。此外,这种中间语言还没有被用于解决我们的任务。
我们使用DL和NLP最先进的方法来提出一个模型来解决这个任务。我们首先使用DL模型,如长短期记忆(LSTM)层,考虑到每个操作码的上下文。这些通常被用于解决NLP任务,并且在一些作品中被用于检测其他编程语言的漏洞[20][17][21]。然而,据我们所知,它们从未被用来处理PHP代码或操作码。
在我们提出的模型中,漏洞检测过程开始于将每个PHP操作码表示为一个嵌入向量,该向量沿着其余的参数进行训练。接下来,该模型使用LSTM、Dropout和Dense层,输出片断对SQLi的漏洞概率。我们的方法使用了一个从软件保障参考数据库(SARD)1中检索的数据集,它提供了对SQLi易受攻击和不易受攻击的PHP测试用例。每个测试用例都是由一个代码片断组成,该片断开始于一个入口点(接收用户定义输入的指令,如$_GET),结束于一个敏感汇(一个函数,如mysqli_query,当用恶意输入执行时,可能会导致不受欢迎的行为,如向未经授权的人提供对私人数据的访问)。
我们评估了不同DL优化器的各种超参数配置下的模型,结果表明,该模型可以发现SQLi,帮助程序员,并排除最终会花费大量成本来修复的攻击。
该论文的贡献在于 1)对PHP中级opcode语言的PHP网络应用的分析,2)一个能准确地将PHP opcode片划分为SQLi易受攻击或非易受攻击的DL模型,3)一个PHP opcode片的数据集,4)每个PHP opcode的预训练嵌入向量,5)一个实验评估,提供不同超参数配置的不同评估。
本文的大纲如下。第二节介绍了NLP背景下漏洞和DL的一些背景信息。在第三节中,对之前的工作和我们的工作进行了比较。在第四节,介绍了我们使用的方法,我们组成的数据集,模型以及如何评估它。第五节介绍了已经研究的模型的实验结果,第六节是本文的结论。
第二节. 背景
A. 网络漏洞
漏洞是系统中存在的缺陷。当攻击者利用它们时,就会破坏一些安全策略,其影响会给组织带来巨大的损失。在过去的几年里,随着互联网的重要性不断提高,网络应用被广泛使用,漏洞的数量成倍增长[22]。根据2017年OWASP的TOP10[2],最受欢迎的Web漏洞类别是:
注入(Injection)。
破解认证
敏感数据暴露
XML外部实体(XXE)
破损的访问控制
安全配置错误
跨站脚本(XSS)
不安全的反序列化
使用存在已知漏洞的组件
记录和监测不足
排名第一的Web漏洞类叫做Injection。每当恶意数据被发送到网络应用程序,然后解释器将其作为命令或查询(如SQL查询)的一部分进行处理时,就会发生注入。这使得攻击者可以欺骗解释器执行非预期的命令或未经适当授权访问数据。例如,解释器可以被编程语言的一个函数(如PHP上的mysqli_query)访问,该函数接收被注入的代码作为参数包含在查询中。注入很容易被利用—攻击者只需要插入适当的字符串就可以利用目标解释器,通常是通过添加元字符—,而且对系统的影响很大,因此对攻击者特别有吸引力。所以,防止注入漏洞的最好方法是保证命令和查询不被恶意数据污染(破坏)。这种方法最好是利用安全的API,或者在不可能的情况下,对特殊字符进行转义[9]。
有几种类型的注入,如命令行、SQL、LDAP和XML。在这项工作中,我们将只研究SQL注入(SQLi)。
根据Clarke[23],SQLi是最具破坏性的漏洞类之一。任何时候,只要一个应用程序给攻击者提供了控制它传递给数据库的SQL查询的机会,这个软件就容易受到SQLi漏洞的攻击。这个问题并不局限于Web应用程序,也就是说,任何使用动态SQL语句与数据库进行通信的系统,比如一些服务器客户端系统,都可能容易出现这类漏洞。
在我们的工作中,我们选择检测PHP代码中的SQLi漏洞,因为PHP是服务器端的高级语言,大多数Web应用程序都是用它来编写的。根据W3Tech[19],79%的Web应用程序是用PHP编写的。

清单1:—易受SQLi攻击的PHP片断实例。
清单1中描述的PHP例子是对SARD漏洞样本的改编。在第1行,外部数据通过全局数组SESSION进入程序,并被存储在inted变量中,然后,$tainted的值通过过滤器表示其格式是否符合FILTER_VALIDATE_EMAIL(行)。接下来,$tainted值通过一个过滤器,表示其格式是否符合FILTER_VALIDATE_EMAIL(第3行)。然而,这个过滤器不会转义”‘“和””等字符。例如,攻击者可以给出一个格式为”‘<恶意查询> ‘@gmail.com “的字符串作为输入,其中<恶意查询>是任何遵循SQL语法的内容。在第8行,用给定的输入构建一个查询字符串。这样一来,攻击者可能会获得存储在$res(第11行)中的私有数据的访问权,$res存储了数据库中执行查询的结果。因此,该分片存在SQLi漏洞。这个漏洞除了验证电子邮件格式外,还可以通过转义特殊字符来修复。
B. 自然语言处理的深度学习
ML擅长处理人类可以直观解决但难以形式化的问题。例如,人类很容易区分狗和猫。尽管如此,要详尽地列出两种动物之间的所有差异是很难的。正因为如此,这些问题对于机器来说更难处理。在许多ML模型中,比如Logistic回归,数据表示对于模型性能来说是很主要的—必须收集和选择合适的特征,这些特征将用于表示每个数据实例。在前面的例子中,如果我们使用腿的数量作为特征,我们可能无法区分两个物种,但也许一个代表动物是否有尖耳朵的布尔特征会更有用。不过对于很多任务来说,很难决定使用哪种表示方法。
在DL模型中,不需要指定特征,而是可以和主任务一起学习它们。在我们的例子中,我们可以简单地使用狗和猫的图片像素,省去了很多思考哪种特征更能区分两种动物的精力。在这些情况下,DL模型是很好的替代品。DL模型是由多层构成的。每一层都接收上一层的输出作为输入,并对输入进行一些变换。通过拥有多层,模型可以基于更简单和更广泛的概念(来自前一层),学习更复杂和有用的概念[24]。
DL模型和任何ML模型一样,都有一个它们打算最小化的隐性成本函数,即它们是最小化任务,需要一个优化算法来完成。通常,神经网络优化器是基于随机梯度下降(SGD)的。常用的基于SGD的优化器有三种。1)ADADELTA[25],使用按维度计算的动态学习率(lr);2)RMSProp[26],使用重新缩放的梯度生成更新;3)ADAM[27],使用梯度的运行平均值生成更新。
NLP处理的是自然语言数据。由于数据的特点,即缺乏结构性、模糊性、差异性和稀疏性[28],往往很难找到适合所需任务的表示方法,因此DL方法在该领域非常流行[29],[30]。
在NLP的DL中,有两个广泛使用的组件:卷积神经网络(CNN)和循环神经网络(RNN)[28]。这些都不是独立的层,但作为特征提取器很重要。CNN是一种前馈网络,可以从数据中提取局部特征。RNN架构既考虑到了词的排序,也考虑到了一个序列中所有过去的词。它们对于序列数据非常出色,并在许多NLP领域取得了最先进的成果[31],[32]。
CNN和RNN层之前通常有一个嵌入层,它将离散的符号映射成连续的向量,解决了自然语言数据的稀疏性问题。另外,通常将这些组件的输出馈送到一个前馈组件,该组件可以学习执行所需的任务,比如分类[28]。
最近,一些新的方法取得了令人振奋的结果,如注意力和RNN或CNN的结合[33],[34]以及只用注意力,求助于变换器[35],[36]。
1)卷积神经网络。
CNN是一种前馈网络,由于其架构的原因,它很擅长在不同大小的长序列中寻找信息量大的局部模式。CNN层背后的主要思想是将一个非线性学习函数(过滤器)应用到一个大小为k的窗口上。 每一个时间步骤,窗口都会滑动,直到覆盖整个序列,并产生一个标量值,代表该时间窗口的标记[28]。我们可以对每个窗口应用n个滤波器,从而产生一个n维向量,表征该窗口。最后,将得到的向量通过池化操作组合成一个向量,代表整个序列。有几种池化操作,然而,最常见的是。
最大池化: 取每个特征的最大值。
平均池化:取每个特征的平均值。
K-max Pooling:对于每个特征,保留k个最高值,保留它们的顺序,并将得到的向量进行连接。
但是,CNN不能提取输入的全局顺序,只能表示局部顺序。因此,这种架构在解决计算机视觉任务时特别擅长,如图像分类和物体识别[37],[38]。
2)循环神经网络。
RNNs是通过内部状态空间维持短期记忆的网络。状态空间可以被看作是以前处理过的输入的痕迹,并且能够表示可能很近或相距较远的标记之间的依赖关系[39]。第一个深度学习语言模型使用了一种称为拍打延迟线(TDL)的前馈网络。这些网络接收位置t的t标记和之前的w个标记作为输入,其中w是预定的。Sejnowski等人[40]训练了一个TDL网络来发音书面英语单词。然而,这种方法有一个明显的缺点:如果w太小,模型可能会错过有趣的模式,如果太长,它的参数会过载,可能会过度拟合。此外,每个token将被独立处理多次,时间步长不同[39]。
RNNs以一种更有效的方式考虑到所有之前的输入,并且不需要麻烦地调整超参数w。 有几种递归单元。最简单的一种称为简单递归神经网络(SRNN)[41],它的内部状态有一个单一的递归层,接收前一个状态的输出并应用激活函数。Bengio等人[42]注意到,即使SRNNs可以学习短期依赖性,但长序列导致消失或爆炸的梯度,使模型难以学习。

图1: 一个LSTM的方案, 显示单位t -1,t和t+1.
LSTM单元[43]就是为了解决这个问题而开发的。LSTM模型可以通过引入两个门—输入门和遗忘门—来控制让多少信息进来[44],从而保持误差流恒定。输入门它控制输入xt,而遗忘门ft控制前一个单元的输出yt-1。这些门产生一个介于0和1之间的值(0表示它们不让任何东西通过,1表示所有东西都通过)。方程(1)显示了如何计算it和ft。在公式it和ft中,Ui,Wi和bi分别是输入门的权重矩阵和偏置,Uf,Wf和bf是忘记门的权重矩阵和偏置。
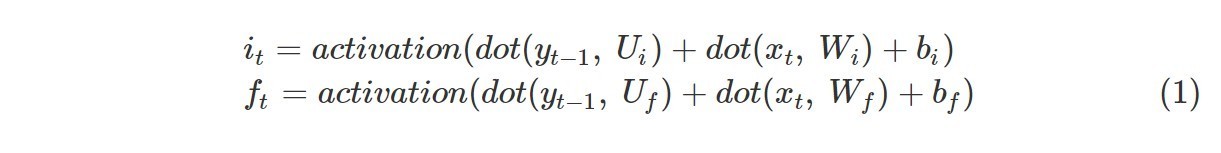
图1显示了LSTM单元(用灰色圆圈表示)的不同部分如何工作。每个单元都有一个数据流ct,跨时间步长传递信息。除了门,还有一个简单的隐藏层组件kt,其方程由式(2)给出,其中Uk,Wk和bk代表隐藏层的权重矩阵和偏置。
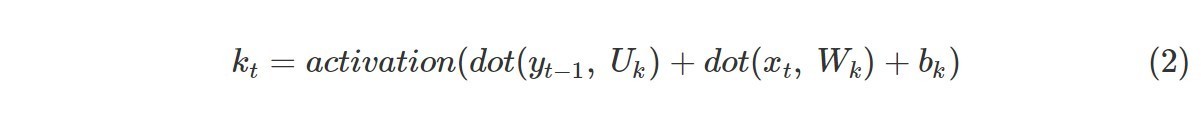
结合ct,it,ft和kt计算出下一个携带数据流ct+1,用式(3)表示。
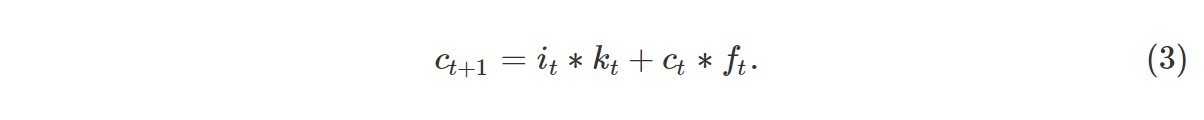
最后,由式(4)计算出该单元的输出,也就是下一个单元的状态,其中ct与输入的xt和状态yt-1相结合,通过密集变换。类似于式(1)和(2),这里我们还有权重矩阵Uy、Wy和Vy,以及偏置向量由。

在过去的几年里,出现了其他的循环单元。Gated Recurrent Unit(GRU)[45]是一个较新的RNN,与LSTM非常相似,但它的开发目的是为了更便宜地运行。然而,它可能没有LSTM层[44]那么大的表示能力。双向循环神经网络(BiRNN)[46]不仅可以基于过去的信息,还可以基于未来的信息进行学习,拓宽了考虑的背景。图2显示了BiRNN层内部的情况。BiRNN将输入向量送入一个RNN,反过来的输入向量送入另一个RNN。最后,输出是两个RNN的输出的组合。
3)输入表示。
在NLP中,为了便于操作,需要将文本数据表示为数字向量。首先要做的是决定表示的粒度:一个向量可以表示一个句子/序列,一个token(单词或其他字符序列用空格隔开),一个字符,其他字符之间。例如,假设它代表一个token。主要有两种表示方法:一热向量和嵌入向量。一热向量是二进制向量,其中只有一个条目的值为1。在一热表示法中,每个特征对应一个token,其值对应该token是否是该特征的token。这就形成了一个二进制稀疏向量,它的属性和词汇中的词一样多。已知这种表示形式会降低神经网络模型的性能[28]。另一方面,嵌入向量是低维空间中的连续表示。它们可以捕获标记之间的相似性,允许模型以类似的嵌入表示方式处理标记[28]。同时,利用嵌入向量,我们可以选择大小,并对其进行调整,以提高模型的性能。
这些表征的连接形成一个参数矩阵,它可以是。
预训练:有一些特定的嵌入训练模型(例如,Word2vec[47]和GloVe[48]),可以应用在更广泛的数据集上。例如,如果我们打算将英语新闻分为假的或不假的,我们可以使用来自多个领域的大量英语文档语料,以更好地把握每个单词的上下文,然后将预先训练好的嵌入用于我们的模型上。
固定或动态:当使用动态嵌入时,我们允许表征矩阵在训练过程中改变其值。对于没有经过预训练的嵌入,情况总是这样。然而,如果我们选择对表征进行预训练,我们可能希望它们适应我们的数据(并使用动态方法),或者干脆按原样使用它们(使用固定方法)。
图 3 显示了我们数据的 opcode 的编码的两张热图,左边是一热,右边是嵌入,每条水平 “线 “代表一个 opcode。从图中可以清楚地看到,一热表示需要一个较高维度的空间,因为它总是需要和唯一的tokens(词汇量)一样多的特征。此外,它是一种稀疏的表示方法—图像(a)显示了一个大的浅灰色区域,对应于值0,只有对角线有黑点,对应于值1。嵌入图像是密集的,需要的特征较少,因为每个特征的意义更大。这也意味着模型的参数会更少,这有助于防止过度拟合。

图3:-一热和嵌入编码的运算码的热图。

图4:-Word2vec模型两个变体的高层次视图。
Word2vec是一种用于训练单词嵌入的流行模型。Word2vec有两种方法,连续词袋模型(CBOW)和连续跳格模型。它们都是由一个投影层(一个简单的线性层)组成。然而,CBOW模型试图预测给定上下文的缺失词,而Skip-Gram试图预测给定词的上下文[49]。通常情况下,第二种模型取得了较好的效果,它是普遍使用的模型。在图4中,有两个模型的图。我们可以看到,CBOW模型接收单词xt的上下文xt-2,xt-1,xt+1,xt+2,窗口大小等于2,并尝试预测它。另一方面,Skip-Gram模型接收单词xt作为输入,并尝试预测其上下文。这些模型的主要优点是它们能够把握词的语义。例如,公式(5)显示了Word2vec在寻找句法和语义词关系方面的威力。
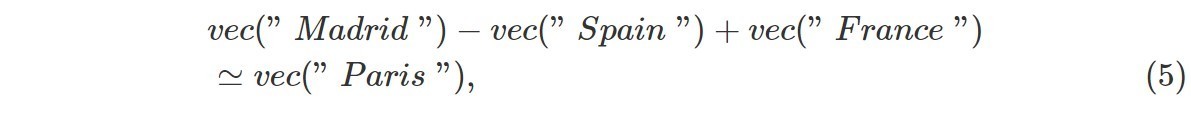
第三节. 相关工作
几年来,ML已被用作脆弱性检测模型的一个组成部分。它最初是作为一种支持机制,使发现漏洞任务的某些部分自动化。例如,Yamaguchi、Lindner和Rieck[50]使用主成分分析(PCA)来创建描述代码中API使用模式的向量表示。然后,专家分析师通过这些向量研究漏洞的存在,并对其进行分类。另一种方法将污点分析应用到PHP代码中,以提取可能的漏洞[14]。接下来,他们应用ML模型对其进行漏洞或不漏洞的分类。在这里,ML模型有助于减少假阳性,这是静态分析的一个著名问题。
最近,出现了一些依靠ML来完成分类任务的漏洞检测模型。Medeiros、Neves和Correia[51]从PHP程序中提取代码片,并将其翻译成作者开发的中间语言。最后,通过隐藏马尔科夫模型对这些翻译进行分类,以确定它们是否存在漏洞。这种方法的一个潜在的局限性是,所使用的中间语言可能会简化代码,并松散地了解其背后的计算。我们的 “类似汇编 “的中间语言可以将复杂的函数分解为更简单的函数,暴露出它们的执行方式以及它们在程序内部的相互联系。同时,它可以让我们处理一种更简单的语言,而没有高级程序语言的复杂语义。
一些作品使用了NLP技术,如Word2vec,来预训练嵌入向量[17],[52]。这样可以使输入向量中嵌入语义信息。预训练嵌入向量应该在一个大的数据集中进行,不一定是用于主任务的那个数据集。因为它不需要被标记,所以通常更容易构建。这种方法是相当相关的,特别是当可用的数据集很小的时候,就像我们的案例中发生的那样。
Russel等人[21]提出了一种有趣的方法,作者将情感分析与CNN结合起来表示数据,将功能级分类与RNN结合起来表示数据。最后,他们使用随机森林对整个程序进行分类。虽然这是一项有趣的工作,但他们使用的是C/C++程序的数据集,而C/C++程序并不像Web应用程序那样容易出现软件漏洞。
在恶意软件检测的相关领域,Guo等人[20]开发了一个黑盒混合模型来解释DL模型。虽然这不在我们的工作范围内,但它是未来研究的重要课题,因为可解释性在漏洞检测中是必不可少的,而DL是相当难以解释的。
据我们所知,我们解决这个任务的方式是新的,以前从未尝试过。以前的工作要么是在其他语言上,这些语言不存在相同类型的漏洞[17]、[21],使用的方法不考虑每个标记的顺序[52],要么没有使用易于扩展和灵活的中间语言[51]。
第四节.解决方案提案
我们的目的是通过用中间语言处理PHP片,将其分为SQLi易受攻击的和不受攻击的两种,中间语言由各自的操作码组成。为此,我们提出了一个由Embedding、LSTM和Dense层组成的DL模型,遵循第II-B节中介绍的指南。这是一种新颖的方法,在 PHP 漏洞检测中还没有使用过。
在本节中,我们将介绍所使用的方法。我们首先定义数据集和必要的预处理。接下来,我们介绍我们正在研究的网络,提供每一层的细节,以及用于评估模型的方法,包括我们考虑的指标。
A. PHP程序数据集
本节的目的是介绍我们如何建立我们的数据集,从一组 PHP 程序开始,并在它们的 opcodes 表征中进行转换,从而生成一个新的数据集,用于我们的 DL 模型。

图 5: 一个代码片断和它所经历的连续转换的例子。
表一 由 VLD Opcodes 组成的词汇。位置i,j的Op码的索引为i∗5+j+1。

1)原始数据集。
Stivalet和Fong[53]开发了一个PHP测试用例生成工具2来生成SARD测试用例。每个样本由一个标注注释部分和一个代码片组成。代码片从一个入口点开始,在一个敏感的汇流处结束。
从SARD中,我们使用1362个SQLi测试用例作为原始数据,即858个易受攻击的实例和504个非易受攻击的实例。非易受攻击的实例是指用户输入被正确消毒或验证的代码片。另一方面,易受攻击的片断没有正确地对输入进行消毒或验证。请注意:1)输入可能已经被消毒,但仍然会危害到应用程序;2)恶意输入可能会在整个分片中传播到其他变量的赋值中。这些显示了我们打算解决的任务的复杂性。
2)数据转换和处理。
传统上,PHP使用一个名为Zend 3的虚拟机引擎来编译和运行程序。Zend将PHP程序转化为操作码,然后执行。一个名为Vulcan Logic Dumper (VLD) 4的工具能够在操作码执行之前拦截它们的处理过程,让它们被保存到一个文件中。这样一来,我们就可以获得一个中间语言表示,在这个中间语言中,原来的函数已经被分割成更简单的函数,并且有一个更受限制的空间。用中间语言分析程序的另一个优点是,它可以用于比高级编程语言更多的程序,将模型适合于任何可能由这种中间语言表示的编程语言。
我们首先在VLD上执行所有的例子,为每个PHP分片获得一个PHP操作码分片。我们还定义了由VLD中使用的所有有效操作码组成的词汇,这将在训练模型时有用。表I列出了这个词汇表。除了PHP操作码,我们还添加了一个特殊的标记来指定可能出现的词汇外标记,即OOV标记。位置(i,j)( 行,列)的操作码的索引由表达式i∗5+j+1给出。
由于神经网络接收的是作为输入的数值数组,因此我们通过将操作码映射到词汇中对应的索引,为每个实例创建一个数值向量。图5显示了一个例子,说明如何从我们数据集的代码片(部分(a))中获得数值向量(部分(c)),并通过VLD工具(部分(b))在操作码片中进行转换。我们可以观察到,该分片的第一个运算码FETCH R的索引为82(应用表达式16×5+1+1=82,见表一),这是向量的第一个元素。
LSTM层不支持不同大小的输入。为此,在训练前,我们在所有较小的序列末尾垫上0,使所有序列的大小与训练集中最长的序列相同。如果在评估模型时出现较长的序列,那么我们就将其截断。
B. 模型
图6给出了我们提出的模型的高层视图。该模型由至少五个层组成,依次工作。它产生一个最终的输出,在0和1之间,表示样本易受攻击的概率。这样一来,输入向量依次经过Embedding、LSTM、Dropout和Dense层,遭受连续的变换,产生最终的输出。
LSTM+Dropout层可以叠加n次,以增加模型的学习能力。表二列出了各层的输入和输出大小,以及激活函数。第一个LSTM层接收一个矩阵(大小为MAX_LENGTH×HIDDEN_SIZE)作为输入,并输出一个向量(大小为HIDDEN_SIZE×1),但后续的LSTM层只是将向量转化为其他向量。MAX_LENGTH对应我们允许的最大序列大小,HIDDEN_SIZEi是一个预定义的值,需要和n一起调整,其中i∈{1,…,n}和n∈N。每个层的激活函数的选择遵循Keras文档[54]对LSTM层的建议,以及Goodfellow、Bengio和Courville[24]对密集层的建议。他们指出,在有两个类的分类问题中,ReLU是神经网络层的首选激活函数,Sigmoid是输出层的首选激活函数。接下来,我们将详细介绍各层的情况。
表二是各层输入、输出和激活函数的定义。

图6:-我们模型的高层次视图。

1)嵌入层。
嵌入层将代币映射到嵌入向量。我们将研究三种嵌入方法。
动态:矩阵从均匀分布初始化[54],其值根据反向传播算法和训练数据[44]进行更新。
预训练和固定:使用word2vec skip-gram模型对每个操作码的嵌入向量进行预训练。接下来,用这些向量来初始化权重矩阵。在训练过程中,这些值不会改变。
预训练和动态:它遵循与上一点相同的想法,但现在我们允许在训练过程中改变值,以适应我们任务的数据。
需要注意的是,对于预训练的方法,我们必须从PHP应用中建立一个语料库,作为Word2vec模型的训练数据。
2)LSTM层。
在学习了每个操作码的嵌入向量之后,我们要学习操作码片中存在的模式。在漏洞检测任务中,运算码在切片中的顺序是非常相关的。为此,我们选择了堆叠n个LSTM层,因为它们可以产生编码前一个操作码及其顺序信息的输出向量。我们从单层开始,然后按照Chollet关于如何在神经网络中平衡欠拟合和过拟合的建议[44],研究增加额外层的影响。
3)Dropout层。
在训练过程中,该层根据给定的概率(δ),将其输入的一些条目随机设置为零。这种方法的目标是在模型中引入噪声,以防止它记忆不相关的模式,这些模式是由LSTM层偶然学习的。在测试阶段,该层不对其输入应用任何变换[44]。虽然模型收敛需要更多的时间,但具有dropout层的神经网络模型可以进一步减少过度拟合,提高其性能[55]。我们决定在模型的每个LSTM层后增加一个Dropout层。
4)密集层。
最后两层是全连接的前馈神经网络层。第一层Dense Layer的作用是学习分片和对应标签(弱势或非弱势)之间的关系。它将输入转化为一个形状相同的向量,掌握这种关系。最后一层对片子进行分类。它遵循分类问题中常见的配置,比如我们正在解决的问题,通过Sigmoid激活函数[44]将输入转化为0和1之间的数值。在这种情况下,该值代表该代码片中存在SQLi漏洞的概率。
C. 评价
为了评估该模型,我们对数据集应用了70/30的随机分层训练-测试拆分法,保持了每个集合中脆弱/非脆弱样本的比例。因此,训练集由953个样本组成,测试集由409个样本组成,其中63%是脆弱的,其余是非脆弱的。此外,我们对训练集应用了分层的10倍交叉验证,对每个模型进行了三次。应用这种技术可以让我们1)在70%的数据上对每个模型进行30次训练和验证,2)在30%的从未见过的测试数据上测试最终模型。
在像我们旨在解决的分类任务中,通常会根据正确分类实例的比率(称为准确率)、真阳性率(或召回率)以及给定所有预测阳性的真阳性率(称为精度)来衡量模型的泛化程度。然后,我们的目标是更好地平衡这三个指标。由于我们对每个模型进行了 30 次训练和验证,因此每个指标将有 30 个值,使我们能够做出更明智的决策。通过每个指标有30个值,我们可以产生比单一值更稳健、更可信的统计数据,因为单一值很容易是偶然的,会导致我们得出错误的结论。这种技术在处理小数据集时更有意义,比如我们的数据集,其中的方差通常较高。
第五节 实验结果
在本节中,我们将深入研究针对1个LSTM层模型进行的实验。我们将首先给出实现的细节。接下来,我们描述了实验所采取的方法和决定,以及测试的各种配置,以便找到最适合我们任务的配置。最后,我们将介绍获得的结果。
A. 实施
我们研究了具有一个块的LSTM + Dropout层的模型。为此,我们使用著名的Python包Keras[54]来实现各种模型配置。Keras为开发神经网络提供了一个方便易用的接口。它可以作为开源Tensorflow包[56]的封装器,后者需要更多细节来配置模型。
B. 实验的配置
在整个实验过程中,我们固定了训练-测试分割的种子(在第四节-C中描述),这样所有的模型都用相同的数据进行训练和测试。除了帮助重现性之外,我们认为这使得配置之间的比较更加公平。
在我们的实验中,我们决定测试ADADELTA、RMSProp和ADAM优化器,以确定哪个是最适合我们的问题。神经网络有相当多的超参数。因此,为了简化第一次实验,并获得对问题的一些直觉,我们决定将优化器的超参数保留为默认值。表三列出了这些值。
关于其他超参数,我们选择调整LSTM层中的单元数δ和纪元数,在不同的配置中评估它们。接下来,我们详细介绍每个超参数。
表三 各优化器的默认超参数列表。

LSTM层中的单元数,对应HIDDEN_SIZE1。我们简单地用HIDDEN_SIZE来表示,因为只有一个层,只有一个HIDDEN_SIZEi需要调整。这个超参数与模型的学习能力密切相关:层的单位越多,它的学习能力越强。然而,权衡之下,它可能会开始有太多的参数来学习和过度拟合,失去泛化能力。
δ,代表掉线率,是一个与掉线层相关的0到1之间的值,对应于输入向量的每个条目变成0的概率。
epochs数,定义优化器更新参数的次数。一般来说,这个参数越高,模型的学习效果越好。但我们又需要平衡学习和泛化能力,不要让模型过度拟合。
我们对这三个参数进行了手动超参数调整,逐一测试,并按照它们在上面列表中出现的顺序进行。表四显示了每个超参数和优化器组合的测试配置。对于每个超参数,我们首先测试一个范围的稀疏值。接下来,我们对搜索进行微调,测试最佳结果周围的两个值(一个更小,一个更大),必要时重复该过程多次。每个配置都测试了10个纪元(当然,调整纪元数时除外)。
表四 对每个超参数测试的配置。

C. 结果
根据我们在上一节描述的评估方法,每个优化器的结果,用每个超参数找到的最佳值进行训练,如表五所示。我们可以观察到,最差的优化器是ADADELTA,因为它的性能是所有指标中最差的。此外,它是需要最长时间收敛的优化器—它需要160个纪元,而RMSProp需要70个纪元,ADAM需要35个纪元。ADAM和RMSProp在不同的指标上都有不错的结果。RMSProp的精度和召回率最好,ADAM的精度最好。需要注意的是,ADAM可以用一半的纪元(35对70)和更少的单位(70对80)达到几乎和RMSProp一样好的精度(0.9413对0.9535)。对于我们的工作来说,比起更少的计算成本,更重要的是指标的结果,所以我们认为RMSProp在这些假设下取得了最好的结果。
表五 分析的各种配置的准确率、精确度和召回率的结果。


图7.超参数的框图
使用RMSProp优化器对LSTM层的隐藏大小、丢弃率和外延次数(分别为第一、第二和第三行)。
图7显示了对RMSProp进行调整后的9个框图,这些框图被组织在一个3×3的矩阵中,其中每条线对应一个超参数,每列对应一个度量。正如我们所看到的,随着数值的增加,框图趋于改善,直到达到一个点,性能开始下降。在分析多个盒图和多个度量时,我们应该考虑一些方面。(1)我们总是希望平衡三个指标的性能,尽管准确性略微重要一些;(2)不仅要看每个图的中位数,而且要看方差,以箱体的高度为代表;(3)最后,在两个相似的箱体图之间,如果其中一个有较低的离群值,我们应该选择另一个。根据这些准则,我们选择了隐藏单元数的值为80,辍学率为0.15,纪元数为70。
第六节. 结论
本文旨在推进Web应用中漏洞检测的最先进水平,重点是SQLi漏洞。为此,我们提出了一个用于自然语言处理(NLP)的深度学习(DL)模型,该模型可以处理翻译成中间语言的PHP代码。该模型由不同的层构成,即Embedding、LSTM + Dropout和Dense层。同时,论文还介绍了对一个LSTM的模型的评估,其中有三个优化器(ADADELTA、RMSProp和ADAM)及其超参数的不同配置。RMSProp取得了最好的成绩。目前的实验已经验证了我们的方法,我们最好的模型在准确度、精度和召回率方面都达到了95%以上的结果。尽管如此,训练集和测试集是从同一个生成的数据集中检索出来的,这可能并不代表完全真实的PHP应用。在未来,这项工作应该用真实的PHP应用程序的数据集进行测试,以减少这个问题。尽管如此,初步结果使我们得出结论,所提出的DL模型可以发现SQLi漏洞,从而向基于机器学习的漏洞检测又迈进了一步。







发表评论
您还未登录,请先登录。
登录