

obfu
主逻辑分析
首先根据字符串锁定主函数。
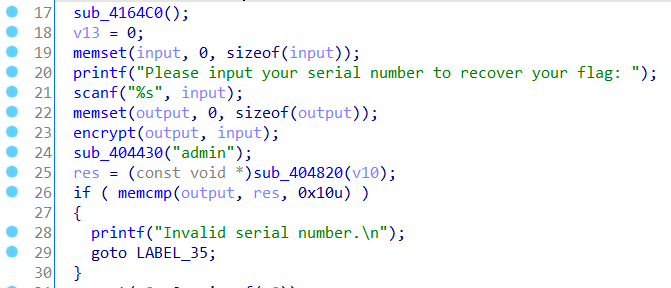
猜测程序先将输入input通过encrypt函数加密,结果存储到output中,在后面通过memcmp函数进行check,而比较的另一项res可能与输入无关,是一个定值。
根据提示字符串Please input your serial number to recover your flag:,结合后面代码打开加密文本flag.enc并写入数据到flag.txt中,则check成功后,程序就会根据我们的input对flag.enc数据解密,输出flag。而解密函数sub_407B90根据findcrypt插件能发现使用了AES加密的S盒,应该是进行AES加解密。结果在flag.enc中,但密钥,即输入是未知的。那么主要任务就是找到正确的input。
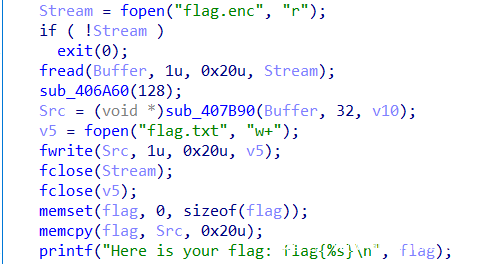
混淆部分
往后看,有一堆疑似用来混淆的while、if语句。其他函数中也有大量的类似混淆,符合题目名obfu。
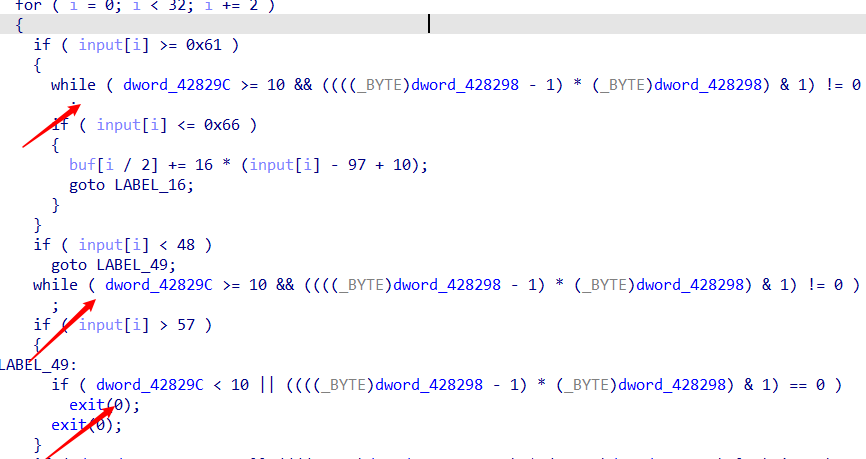
查看这些dword数据,可以发现都是bss段的数据,即存放程序中未初始化的全局变量和静态变量的一块内存区域,在程序执行之前会自动清0。查看交叉引用可以发现并没有再进行赋值,则这些数据全为0。
诸如这样的混淆别处也有,看着不爽可以选择进行patch。
首先想到一种方法。直接查看对应代码汇编指令,根据逻辑用脚本对一整块进行patch。但这样很慢而且容易出错,而且再次反编译结果有可能逻辑出现问题。
因此再考虑到这些混淆代码都是while或if类型语句,汇编指令应该也类似,可以根据混淆代码的汇编指令特征写脚本进行patch。这种方法也不是很好,反编译结果虽然一致但有些指令的具体实现不一样,速度虽然会快一点,但逻辑还是可能出错。
之后尝试将bss段的这些dword全部change byte为0,想让ida自动重新反编译,但似乎因为ida不能判断出这些数据是否后面被改变,所以这种方法行不通。
则最后考虑直接将所有使用这些dword的mov指令,直接patch为mov exx, 0。这样逻辑不会出错,也可以用脚本快速进行patch。
如对main函数中的while混淆,可以看出将前面dword_42829c改为0逻辑即可判断正确。

则查看汇编。

可以手动ctrl+alt+k用keypatch进行patch,其他地方类似。再反编译即可。
不过由于一个函数里大片连续地址中用的dword数据是一致的,我们可以考虑用脚本进行patch。
如这里我们复制机器码中的9c 82 42 00,alt+b进行搜索。
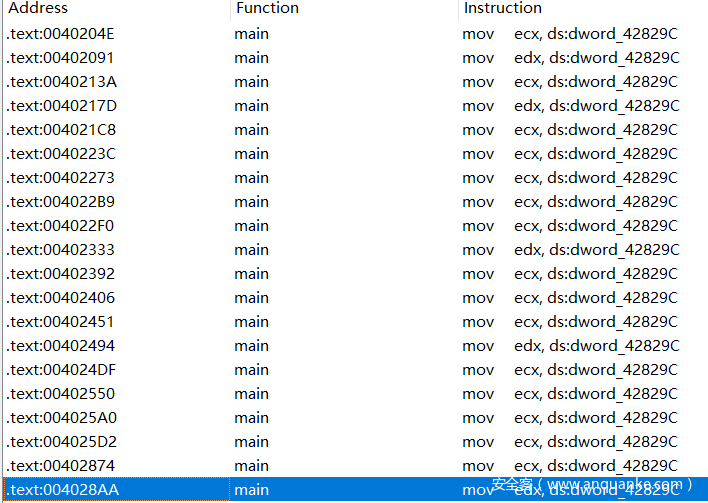
可以看出只有ecx和edx两种格式。对于我们应该进行patch(替换)的数据(机器码),可以先用keypatch将其改为目标汇编指令mov exx,0,从而得到对应的替换机器码。
写脚本搜索原汇编指令机器码并进行替换即可。
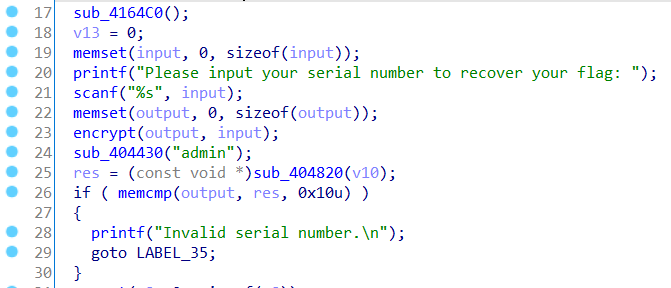
from idaapi import *
import re
start = ask_addr(0x0, "start address to set nop:")
print("start address:%08x"%(start))
end = ask_addr(0x0, "end address to set nop:")
print("end address:%08x"%(end))
origin_pattern = [b'\x8b\x15\x9c\x82B\x00',b'\x8b\r\x9c\x82B\x00',b'\x8b\x15\xa0\x82\x42\x00',b'\x8B\r\xa0\x82\x42\x00',b'\x8b\x15\xbc\x82\x42\x00',b'\x8b\r\xbc\x82\x42\x00']
patch_pattern = [b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90',b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90',b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90']
length = end-start+1
buf = get_bytes(start, length)
for i in range(len(origin_pattern)):
buf = re.sub(origin_pattern[i],patch_pattern[i],buf)
patch_bytes(start,buf)
加密过程分析
之后分析input处理过程。跟进encrypt函数。

首先,根据循环条件猜测input长度应该就是32(少了直接在循环中退出,多了也用不上),限定了输入只能为十六进制的16个字符,并每两个字符为一组转换为数据。
类似
string = '12345678'
d = bytes.fromhex(string)
之后对得到的16个数据再进行处理。
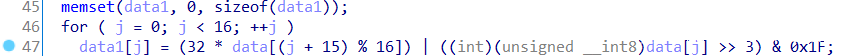
即所有数据二进制串循环右移3位。
之后分配四组内存空间,调用sub_41DAA0函数。跟进去。

可以看出调用malloc函数后应该就退出了。实质就是个malloc函数。
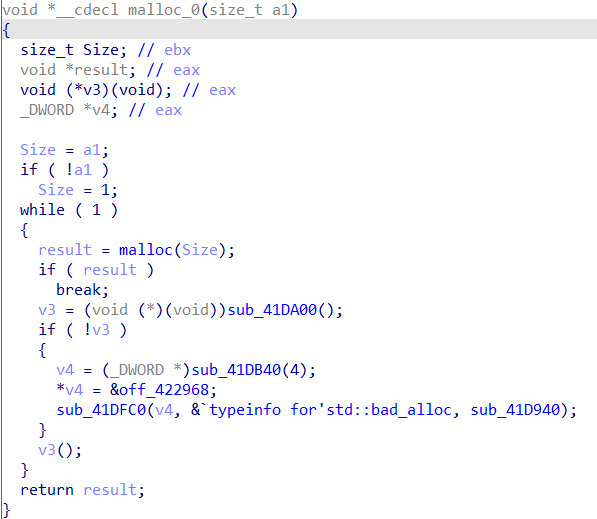
继续分析,可以看出调用的三个函数sub_402EB0、sub_403000和sub_403620都对处理过的data1数据无关,则猜测产生的buf_dword_8数据应该是固定的。在进行异或处理后对两个buf_dword_4数据进行赋值。
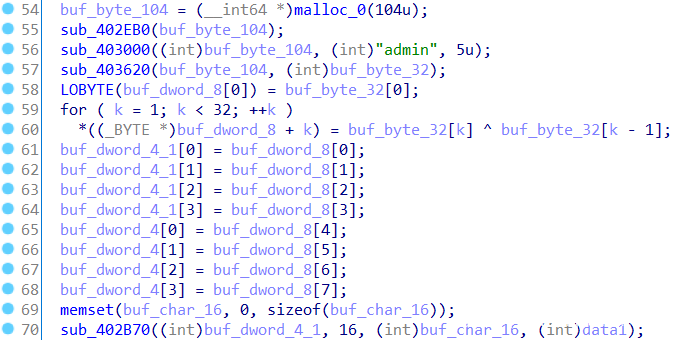
通过findcrypt插件我们可以知道sub_402EB0函数中是赋值了sha256加密算中的8个初始哈希值。则可猜测这三个函数是对字符串admin进行了sha256加密。
下断点查看数据。
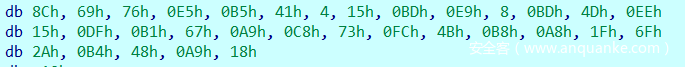
与我们用脚本写的sha256加密字符串admin的结果是一致的。
import hashlib
s = 'admin'
print(hashlib.sha256(s.encode()).hexdigest())
# 8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
则这里就是将字符串adminsha256加密后进行异或处理,得到一组固定数据。分为两组,每十六个字节分别转储。
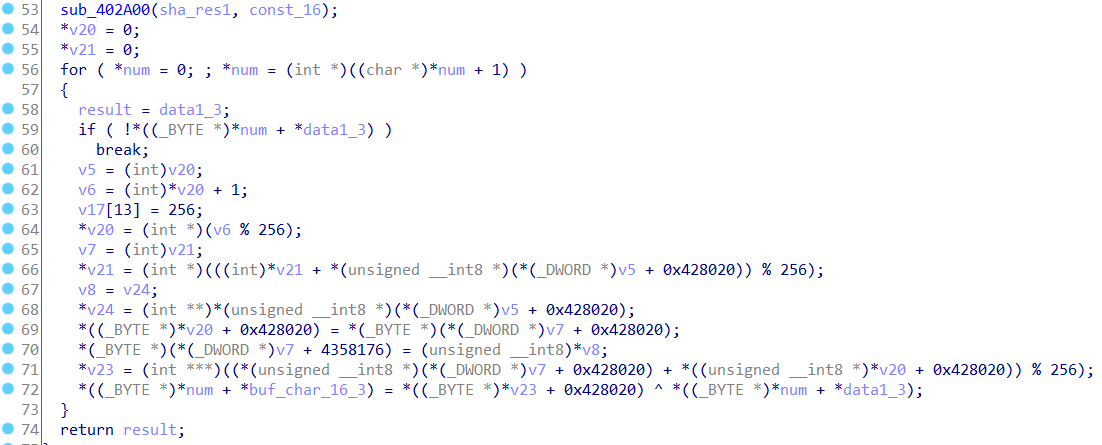
继续分析。这里分配16个字节空间,之后调用函数sub_402B70,根据参数,猜测这里是依据我们的输入生成的data1数据,以及前面sha256加密异或处理后的前16个字节,生成16个字节数据。
![]()
跟进分析。可以发现for循环次数就是data1的长度16,且有%256操作,可以看出应该是对data1进行rc4加密处理。则前面的sub_402A00函数应该就是生成密钥流,且储存在地址0x428020。
直接在异或处下断点,动调得到密钥流。
rc4_flow = [236, 251, 65, 89, 249, 231, 139, 18, 27, 63, 80, 130, 240, 163, 68, 43]
之后继续分析前面的encrypt函数。
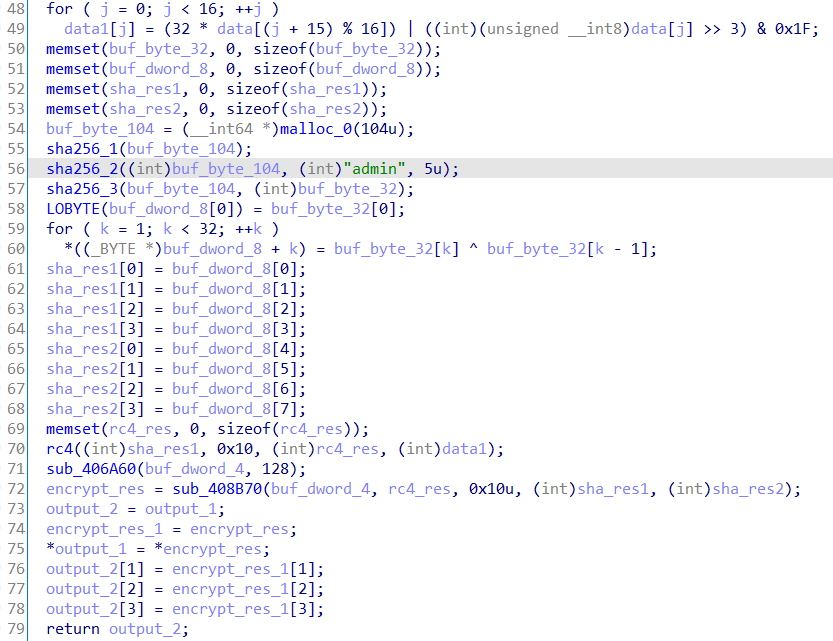
sub_406A60函数对buf_dword_4进行初始化赋值为4、4、10和16。
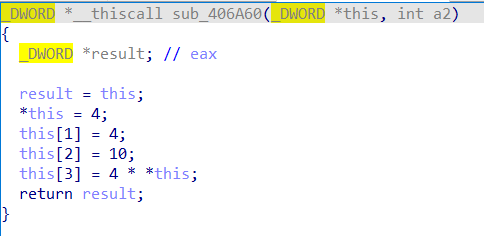
而后的sub_408B70函数参数涉及到了之前数据rc4加密后的结果,以及前面经过sha256加密异或得到的固定数据。返回值就是我们这整个encrypt函数的加密结果。应该是对rc4加密结果又做了处理。通过findcrypt插件我们已经可以发现这个函数中引用了AES的S盒,猜测是将rc4加密结果(16字节)作为明文,sha_res1(16字节)和sha_res2(16字节)分别作为密钥和初始化向量,进行AES相关操作。
跟进具体分析。

key_expansion函数的参数是sha_res1和176个字节的空间,函数中循环根据是否为4的倍数进行不同操作,且用到了AES的S盒,则这个函数就是进行密钥扩展。可知参数sha_res1即为密钥。

密钥扩展后的循环只进行一次,毕竟明文就只有16字节。
而后调用两个函数,跟进sub_407D70,我们可以发现具体使用的是AES加密的逆S盒(inverse S-box),且之后的函数sub_4089A0进行异或操作,通过逆S盒以及最后先处理再异或的顺序,可以判断出这里进行的是AES的CBC模式解密,key就是sha_res1,iv就是异或函数的参数sha_res2。
至此encrypt函数分析完毕,加密过程大致如下。
input = bytes.fromhex(input)
ror(input,3)
rc4_encrypt(input)
aes_decrypt(input,key=sha_xor_res1,iv=sha_xor_res2)
回到主函数。找check数据。
在函数sub_404430中发现了md5加密算法的4个链接变量的数据初始化,则推测这里是对字符串admin进行了md5加密,
动调发现结果一致,确实是这样。
![]()
import hashlib
s = 'admin'
print(hashlib.md5(s.encode()).hexdigest())
# 21232f297a57a5a743894a0e4a801fc3
exp
至此分析完毕,逆向该加密处理过程即可得到正确输入。
import hashlib
from Crypto.Cipher import AES
rc4_flow = [236, 251, 65, 89, 249, 231, 139, 18, 27, 63, 80, 130, 240, 163, 68, 43]
s = 'admin'
sha_res = bytes.fromhex(hashlib.sha256(s.encode()).hexdigest())
res = bytes.fromhex(hashlib.md5(s.encode()).hexdigest())
sha_res = list(sha_res)
sha_xor_res = [sha_res[0]]
for i in range(1,len(sha_res)):
sha_xor_res.append(sha_res[i] ^ sha_res[i-1])
key = bytes(sha_xor_res[:16])
iv = bytes(sha_xor_res[16:])
aes = AES.new(key,mode=AES.MODE_CBC,iv=iv)
aes_encrypt_res = aes.encrypt(res)
rc4_decrypt_res = []
for i in range(len(aes_encrypt_res)):
rc4_decrypt_res.append(aes_encrypt_res[i]^rc4_flow[i])
serial_number = [0]*32
for i in range(len(rc4_decrypt_res)):
serial_number[i] = (((rc4_decrypt_res[i]<<3)&0xff)|(rc4_decrypt_res[(i+1)%len(rc4_decrypt_res)]>>5))
print(hex(serial_number[i])[2:].rjust(2,'0'),end='')
# 653b987431e5a2fc7c3d748fba0088690x8e
输入正确序列后即可输出flag。
![]()
babyre
主逻辑分析
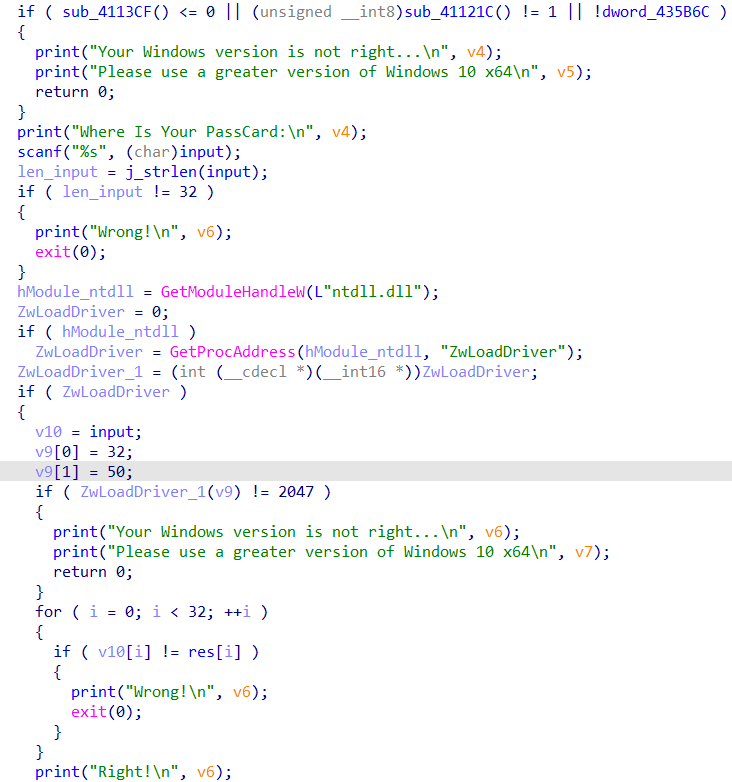
分析main函数,程序首先判断输入长度为32位,之后调用GetModuleHandleW函数获取ntdll动态链接库模块的句柄。然后调用GetProcAddress函数获取ntdll动态链接库中的导出函数ZwLoadDriver的地址。
之后将input转储到v10,并对v9进行赋值,查看变量声明处可以知道v9、v10是连续的空间,相当于在input前加添加了两个16比特的值。并将其作为参数,调用ZwLoadDriver函数,并对返回值检测。最后将v10与已知数据进行check,一致即可。
![]()
而整个过程中对input进行操作的地方只有ZwLoadDriver函数,但这个函数用于加载驱动,显然不是一个加密函数,但查看最后check时res的数组,可以发现有很多不可打印字符,肯定还是对输入进行加密了,那么猜测系统调用ZwLoadDriver函数应该被hook了,实际运行时执行的是别的加密函数。
hook分析
正常来讲,动调到执行ZwLoadDriver函数时单步跟进,应该就能找到真正的加密函数,或者根据字符串列表、函数列表等的耐心查看引用,也可以找到真正的加密函数。很多师傅也是这样做的。
但我单步跟踪后并没有跟进加密函数,根据提示字符串应该是系统版本跟出题人不完全一致导致的问题。
这里研究一下hook的流程。从start开始,可以看到有个crt的main函数。
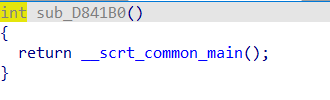
根据这篇C语言中的main函数为什么被称作程序入口,可以知道函数__scrt_common_main是用来进行基本的运行时环境初始化,而后继续跟进,这个__scrt_common_main_seh函数中继续做初始化工作。
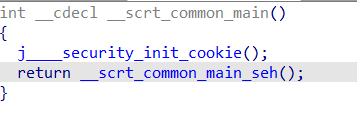
继续跟进。首先注意到下面的invoke_main函数,这个函数就是初始化完毕后要执行的主逻辑,也就是前面我们分析的main函数。

而上面的initterm_e函数,查阅文档_initterm, _initterm_e可知,该函数遍历函数指针表并对其进行初始化, 第一个指针是表格中的开始位置,第二个指针是结束位置。换句话说就是依次执行从开始指针到结束指针之间的函数(如果存在)。要在main函数前搞事情,一般就是在这里了。
(根据这篇C++ main函数运行分析,在VS里进行复现,可以发现这些运行时环境初始化的代码与ida中反编译出来的代码一致,根据这篇C/C++启动函数,可以知道这是运行c程序所必须要做的启动函数。)
分别在两个开始位置,设置dword类型的数组,来看到底调用了哪些函数。

第一处看起来就是正常的初始化。

第二处我们可以看出调用了一个可疑的sub_D817F0函数,跟进去最终能找可疑函数sub_D83600。

写代码解一下字符串加密。
d = [0xB4,0x8C,0x94,0xD5,0xD7,0xB7,0x91,0x82,0x8D,0x90,0x8A,0x97,0x8A,0x8C,0x8D]
s = 'siyqq3yqq'
for i in range(len(d)):
print(chr(d[i]^0xe3),end='')
print('')
for i in range(len(s)):
print(chr(ord(s[i])^0x1D),end='')
# Wow64Transition
# ntdll.dll
可以分析出这里的逻辑,首先获取ntdll动态链接库的句柄,然后获取其导出函数Wow64Transition的地址。查阅文档VirtualProtect function可知,后面的VirtualProtect函数将Wow64Transition函数的前4个字节空间的权限改为允许任意操作,之后将其原先的前4字节数据保存,再更改其前4字节为函数sub_6A1109的地址(即changed_wow64)。
那hookWow64Transition函数有什么用呢,先看看sub_6A1109函数的逻辑。

首先将eax的值保存,之后调用sub_9C1181函数,然后调用buf_func函数。
跟进sub_9C1181函数。
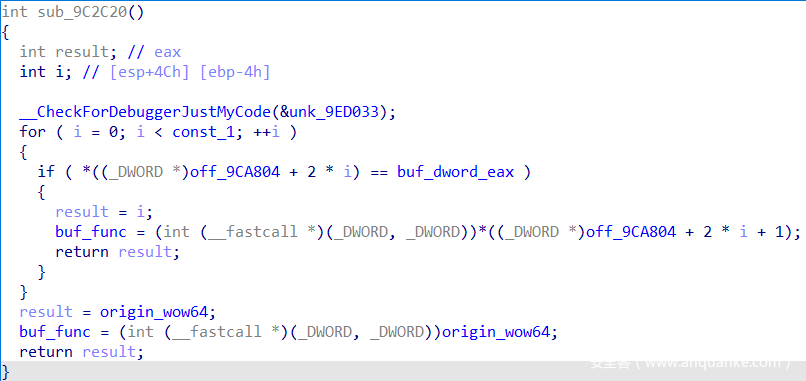
查看off_9CA804指针所指数据。

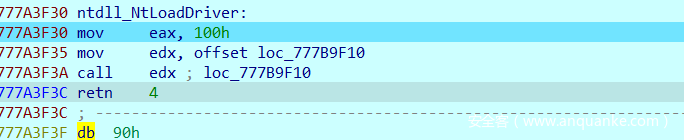
分析可知,该函数就是将eax的值与0x100进行对比,如果相同,那么后面就将调用sub_9C1028函数,否则就调用原本应该调用的wow64函数。查看sub_9C1028函数可以发现返回值是2047,也就是前面主函数进行check的值,即这里就是真正的加密函数。
那么我自己动调没有被hook成功,就肯定是因为这里赋值给eax的值并不是0x100,下面动调跟一下。

这里断点后继续单步。

可以看出就是NtLoadDriver函数,这里将eax赋值为0x105,也就说是函数NtLoadDriver的系统调用号是0x105。继续跟进。

之后跳转到Wow64Transition函数,而根据前面的分析,这时Wow64Transition函数前4字节已经被修改为自己的函数地址,从而进行hook,而检测值就是前面赋值给eax的0x105。而没有被成功hook的原因应该就是这里,在我的系统中NtLoadDriver的系统调用号为0x105,而出题人师傅应该是0x100。又去问了动调没问题的Bxb0师傅,师傅经过动调发现他这里赋值给eax就是0x100。所以就是系统不一致的问题。
这里进行相关资料查阅,WOW64 (Windows-on-Windows 64-bit)是一个Windows操作系统的子系统,它为现有的 32 位应用程序提供了32位的模拟,可以使大多数32位应用程序在无需修改的情况下运行在Windows 64位版本上。它在系统层提供了中间层,将win32的系统调用转换成x64进行调用,并且将x64返回的结果转换成win32形式返回给win32程序。技术上说, WOW64是由三个DLL实现的:Wow64.dll 是Windows NT kernel的核心接口,在32位和64位调用之间进行转换,包括指针和调用栈的操控。Wow64win.dll为32位应用程序提供合适的入口指针。Wow64cpu.dll负责将处理器在32位和64位的模式之间转换。
也就是说,在64位windows上,32位程序进行系统调用,最终都会根据wow64子系统来进行转换,出题人据此,将32位程序系统调用转换所必须经历的Wow64Transition函数进行hook,并在自己的函数中check是否为ZwLoadDriver函数,若不是则正常进行转换,继续系统调用,若是的话,就转而执行加密函数。所以前面该程序多处调该IsWow64Process函数来检测是否运行在64位系统上。不然不可能经历这个过程。
(企图单步调试观察这个转换过程但失败了,原因是32位调试器不能调试切换到64位模式的程序,用windgb好像可以解决这个问题,这里不再深究)
加密过程分析
之后分析前面找到的加密函数。

ZwSetInformationThread反调试
写代码解一下字符串加密。这里注意一下ProcName和v6空间也是连着的。
s1 = 'siyqq3yqq'
s2 = [118,91,127]+list(map(ord,'IXeBJC^AMXECBxD^IMH'))
for i in range(len(s1)):
print(chr(ord(s1[i])^0x1D),end='')
print('')
for i in range(len(s2)):
print(chr(s2[i]^0x2C),end='')
# ntdll.dll
# ZwSetInformationThread
则这里首先调用GetModuleHandleA函数获取ntdll动态链接库模块的句柄,然后调用GetProcAddress函数获取ntdll动态链接库中的导出函数ZwSetInformationThread的地址。后面再调用该函数。
而根据这篇详解反调试技术,函数ZwSetInformationThread拥有两个参数,第一个参数用来接收当前线程的句柄,第二个参数表示线程信息类型,若其值设置为ThreadHideFromDebugger(0x11),使用语句ZwSetInformationThread(GetCurrentThread(), ThreadHideFromDebugger, NULL, 0);调用该函数后,调试进程就会被分离出来。该函数不会对正常运行的程序产生任何影响,但若运行的是调试器程序,因为该函数隐藏了当前线程,调试器无法再收到该线程的调试事件,最终停止调试。
也就是说个函数的调用是用于反调试的,若要调试直接patch即可。
之后调用函数sub_E213ED,返回值看起来应该是个函数地址,用于后面对输入进行加密。
再之后的一个check其实毫无用处,因为之前main函数在我们input前加了两个word类型的数据,第一个就是32。
最后调用那个通过函数sub_E213ED获得的加密函数,对我们的输入每16个字节一组进行加密。
接下来就要找出具体的加密函数究竟是什么。跟进sub_E213ED进行分析。
cipher.dll装载
这里依次调用了三个函数,逐个分析。
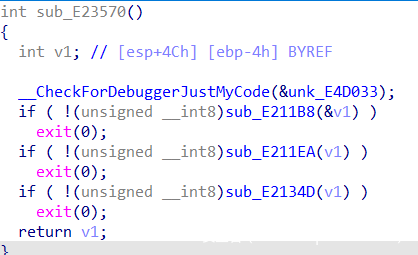
首先分析sub_E211B8函数,该函数首先调用了sub_E21226函数,再跟进。

函数sub_E21226首先调用GetModuleHandleW函数,参数为0代表获取当前进程模块的句柄。之后调用FindResourceW函数,确定具有指定类型和名称的资源在指定模块中的位置,即在当前程序中寻找资源,根据 PE文件解析-资源(Resource),PE文件中的资源是按照 资源类型 -> 资源ID -> 资源代码页 的3层树型目录结构来组织资源的,该函数第二个参数为资源ID/资源名lpName,ID是资源的整数标识符,第三个参数为资源类型lpType。根据字符串可以看出这里的资源应该就是一个用来加密的dll。返回值是指定资源的信息块的句柄,之后将此句柄传递给LoadResource函数,来获取资源的句柄。之后根据资源句柄,调用LockResource函数,来检索指向内存中该资源的指针,从而获取资源地址。
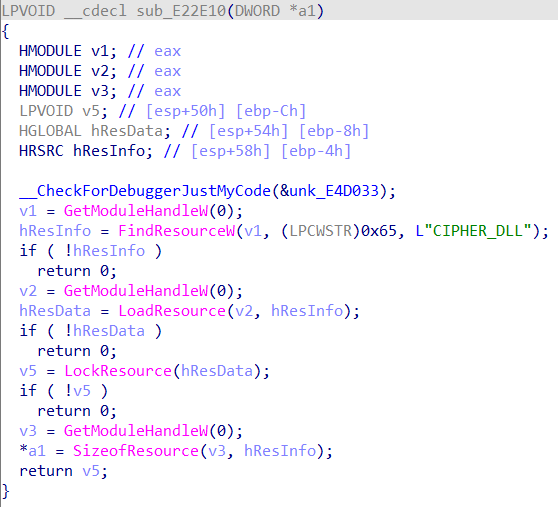
继续分析sub_E211B8函数,在调用sub_E21226函数后又调用了sub_E21258函数,第一个参数就是加载的dll资源的地址,第二个参数是资源的大小,跟进分析。可以看出首先将资源空间权限改为允许任意操作,之后对资源循环异或解密。(动调可以发现这里解密后就是一个dll文件)

回到sub_E211B8函数,之后将该cipher.dll的前64字节转储,也就是该pe文件的dos头,最后一个数据为e_lfanew,即相对于文件首的偏移量,用于找到NT头。
之后将该cipher.dll的NT头开始的248字节转储,也就是文件整个NT头。32位pe文件NT头大小就是0xF8(248),可选头大小一般为0xE0,而64位NT头中的可选头大小一般为0xF0。
再将NT头开始的第21个dword数据保存,这个数据就是NT头中的SizeOfImage。即该dll加载到内存中所需的虚拟内存大小。
再将NT头开始的第2个dword数据的高16位保存,这个数据就是NT头中的NumberOfSections。即该dll中的节区数量。
之后根据节区数量依次将节区头转储,32位pe文件节区大小就是40字节。
然后调用VirtualAlloc函数,在此babyre程序进程的地址空间中根据SizeOfImage分配内存。
之后将NT头开始的第22个dword数据保存,这个数据就是NT头中的SizeOfHeader,指明整个pe头的大小。从而根据SizeOfHeader将整个PE头加载到刚刚分配的内存空间中。
最后将每个节区,根据内存中节区的起始地址VirtualAddress,硬盘文件中节区的起始位置PointerToRawData,硬盘文件中节区所占大小SizeOfRawData,加载到分配的内存空间中。(这里注意那几个dword数据前面的地址就是节区头地址,则根据节区头位置以及pe文件格式即可判断出这些数据的含义)
再分析sub_E211EA函数。还是结合pe结构分析,实现了PE装载器将导入函数输入至IAT的过程,不再详细说明。(这里注意循环每次加5,类型是dowrd,可以看汇编)

最后分析sub_E2134D函数,可以发现是进行重定位,因为文件被加载的地址不是ImageBase定义的地址,涉及直接寻址的指令都需要重定位,重定位后的地址=需要重定位的地址-默认加载基址+当前加载基址。

综上,这三个函数其实就是实现了一个简单的pe装载器,将储存在资源中的cipher.dll解密后加载入内存。最终返回内存中该dll的首地址。
用Resource Hacker打开该程序,可以看到资源类型CIPHER_DLL且资源ID为0x65的资源。
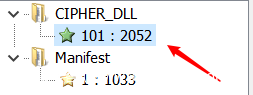
将资源保存后,解密可得到这个dll。
path = 'your_path/cipher.dll'
xor_data = list(map(ord,'wow!'))
buf = b''
with open(path, 'rb+') as fp:
buf = fp.read()
buf = list(buf)
for i in range(len(buf)):
buf[i] ^= xor_data[i%len(xor_data)]
with open(path, 'wb+') as fp:
buf = bytes(buf)
fp.write(buf)
查看导出窗口可以发现Cipher函数。
也可以直接动调,系统调用号的问题手动改为0x100,过反调试后,F8到加密的地方步入,也可以进入到cipher.dll。(函数sub_E213ED返回值为dll首地址,加的值0x4F6DE,查看dll后发现就是AddressOfEntryPoint的值,即程序最先执行的代码地址)
加密算法分析
用ida查看我们提取并解密的cipher.dll。
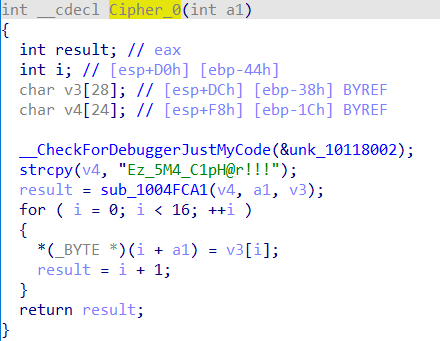
根据带有提示性质的密钥,知道这是sm4加密。没看出来也不要紧,跟进加密函数,能够发现sm4加密的s盒、系统参数fk和固定参数ck。由于传入参数只有我们的输入,因此加密就只是将我们的输入进行sm4的ecb加密,最后进行check。
exp
至此分析完毕,根据最后check的加密结果,以及密钥Ez_5M4_C1pH@r!!!,写脚本得到flag。
import pysm4
import binascii
key = b'Ez_5M4_C1pH@r!!!'
key = int(binascii.b2a_hex(key).decode(),16)
res = [0xEA, 0x63, 0x58, 0xB7, 0x8C, 0xE2, 0xA1, 0xE9, 0xC5, 0x29,
0x8F, 0x53, 0xE8, 0x08, 0x32, 0x59, 0xAF, 0x1B, 0x67, 0xAE,
0xD9, 0xDA, 0xCF, 0xC4, 0x72, 0xFF, 0xB1, 0xEC, 0x76, 0x73,
0xF3, 0x06]
flag = b''
for i in range(0,len(res),16):
tmp = int(binascii.b2a_hex(bytes(res[i:i+16])).decode(),16)
m = pysm4.decrypt(tmp,key)
s = binascii.unhexlify(hex(m)[2:])
flag += s
print(flag.decode())
Enigma
主逻辑分析
直接看主函数。
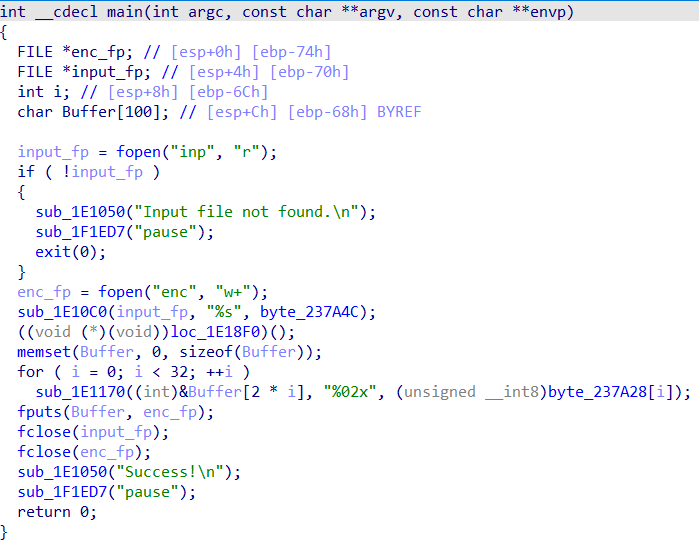
根据各函数的参数初步确定函数功能。
sub_1E1050->printfsub_1F1ED7->systemsub_1E10C0->fscanfsub_1E1170->sprintf
可以分析出程序的大致逻辑。即先打开一个inp文件,相当于我们的输入。读入input数据到byte_237A4C。之后调用loc_1E18F0函数,这里ida未能正确识别为函数,应该是进行了某种特殊处理,之后就将byte_237A28中的数据以十六进制格式依次转储到Buffer、enc文件中。
则调用的loc_1E18F0函数应该就是关键的加密代码,byte_237A28就是加密结果,现在enc文件数据已知,分析出loc_1E18F0所进行的加密过程即可得到flag。
异常反调试与虚拟机
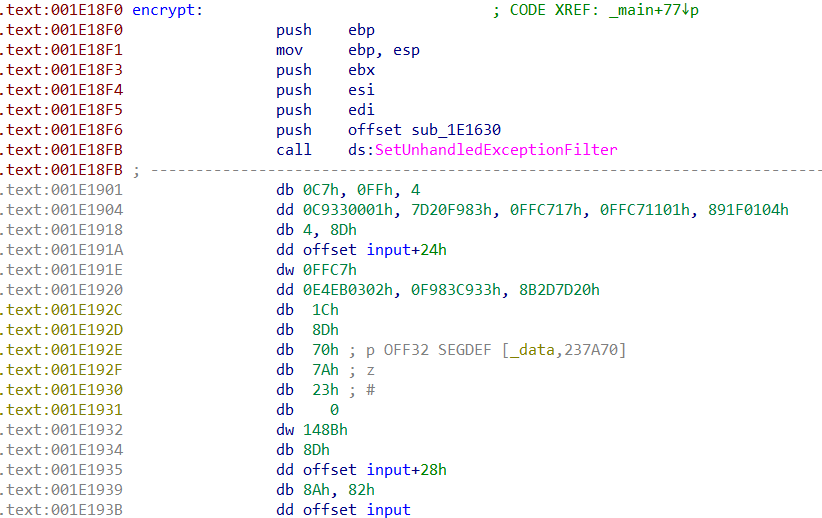
跟进encrypt函数可以发现指令难以识别,而且调用了SetUnhandledExceptionFilter函数。
查阅文档SetUnhandledExceptionFilter。我们可以知道,这个函数使应用程序能够取代进程的每个线程的顶级异常处理程序。 调用此函数后,如果在未调试的进程中发生异常,并且异常进入未处理的异常筛选器,则该筛选器将调用由lpTopLevelExceptionFilter参数指定的异常筛选器函数。
我们在ida中F9尝试运行,发现会报错。
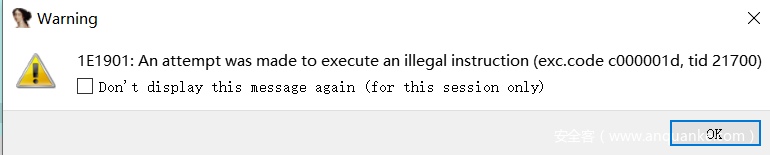
之后程序断在地址0x1E1901,即call SetUnhandledExceptionFilter后。
因此我们可以知道,这里的反调试手段是通过故意设置无法识别的指令来触发异常,使得程序走向由SetUnhandledExceptionFilter函数参数设置的异常筛选器函数,从而继续执行。
接下来分析参数设置的异常筛选器函数sub_1E1630。
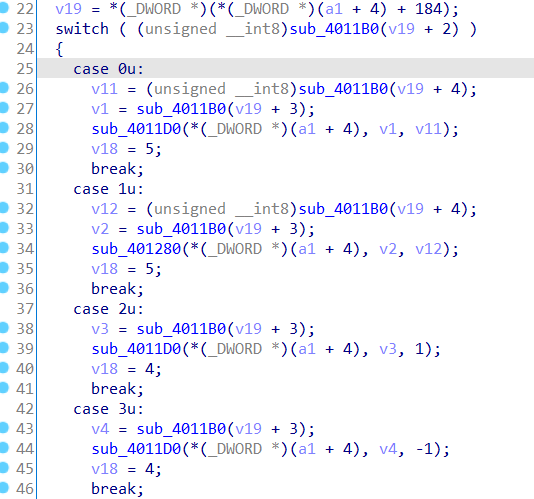
函数整体看起来十分混乱,这时因为ida并没有正确识别函数的参数。根据文档我们可以知道该异常筛选器函数语法类似UnhandledExceptionFilter函数,只有一个类型为LPEXCEPTION_POINTERS的参数。则我们选择该函数y进行set type,并n进行重命名。之后可以得到意义明确的伪代码。
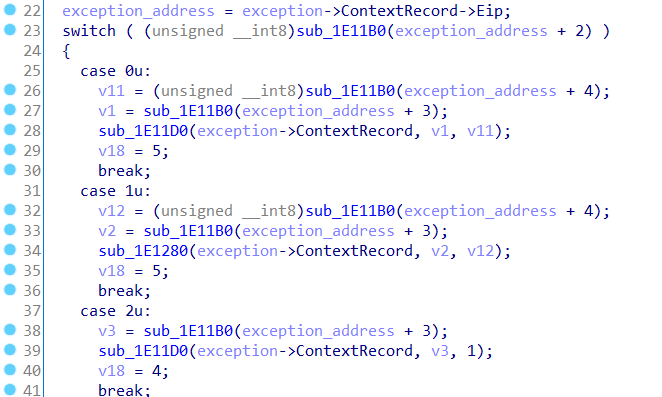
可以看出exception->ContextRecord->Eip就是我们触发异常的地址。跟进sub_1E11B0函数,可以发现就是简单的取异常地址之后的值。跟进有具有参数excption->ContextRecord的各个函数,根据文档GetExceptionInformation macro和EXCEPTION_POINTERS structure我们可以知道该参数的类型为PCONTEXT ,再次y进行设置。可以得到意义明确的伪代码。

可以发现不同函数就是对寄存器进行不同的操作。寄存器号由byte(eip+3)决定,操作值为byte(eip+4)或1、-1(case2和case3)。
可以看出这其实就是一个简单的虚拟机。异常筛选器函数sub_1E1630就是dispatcher,每次触发异常时eip+2即为opcode。每一个case对应一个handle。不同handle进行不同的处理。
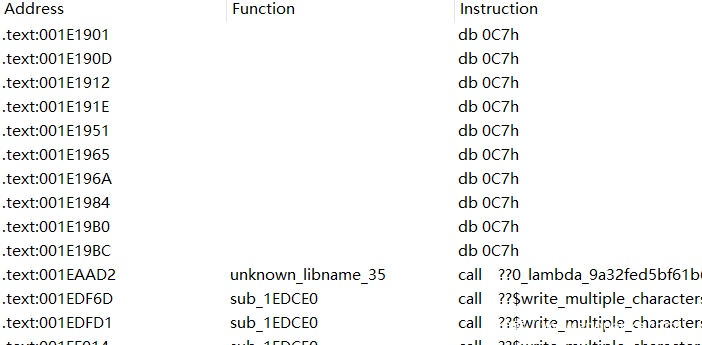
之后我们回到之前的encrypt函数,选取后c为代码,发现时不时就有一个0xC7,结合虚拟机逻辑查看汇编分析可知0xC7FF就是用来专门触发异常处理的。
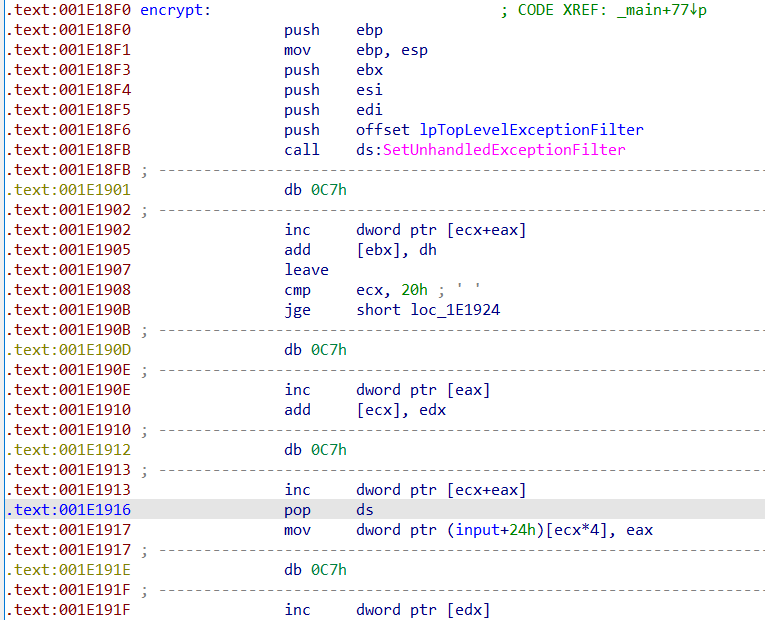
可以选择一个个进行分析后patch。
也可以根据异常和虚拟机的逻辑,写脚本依次得到触发每个异常时执行的指令。(根据alt+b搜索异常特征C7 FF得到地址范围)
from idaapi import *
start_addr = 0x1E1900
end_addr = 0x1E1A00
reg_dic = {1:'eax',2:'ebx',3:'ecx',4:'edx',5:'esi'}
op = {0:'add',1:'add',2:'add',3:'add',4:'and',5:'or',6:'xor',7:'shl',8:'shr'}
num = 0
for addr in range(start_addr,end_addr,1):
data = get_byte(addr)
if data == 0xC7:
data = get_byte(addr+1)
if data == 0xFF:
# 触发异常
num += 1
print('instruction '+str(num) + ':',end='')
opcode = get_byte(addr+2)
reg = get_byte(addr+3)
if opcode == 2:
value = 1
elif opcode == 3:
value = -1
else:
value = get_byte(addr+4)
print('{0} {1},{2}'.format(op[opcode],reg_dic[reg],value))
之后依次找到0xC7处进行patch,多余字节patch为nop,p为函数后F5得到伪代码。就可以清晰完整的看出加密的过程。
加密过程分析
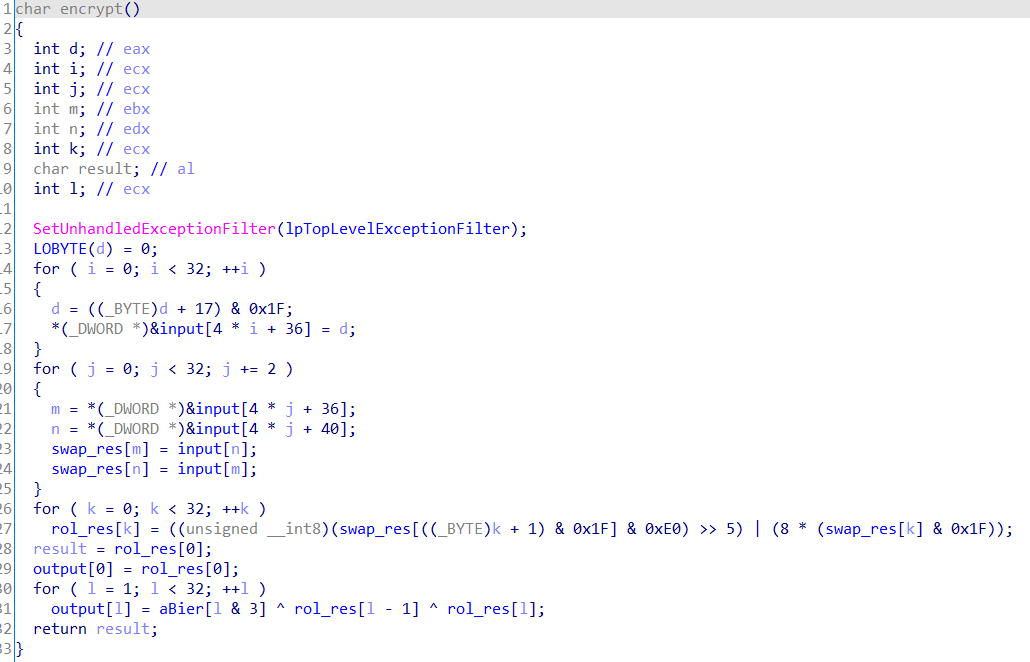
可以看出,先循环生成一组32个数据,之后根据生成数据对input进行交换,之后循环左移3位,再与固定数据进行循环异或,就得到了最终的输出。(不要忘了enc中是数据的十六进制形式)
exp
据此写逆向脚本即可得到flag。
output = '938b8f431268f7907a4b6e421301b42120738d68cb19fcf8b26bc4abc89b8d22'
output = bytes.fromhex(output) # 16进制格式文本还原为数据
xor_data = list(map(ord,'Bier'))
# 还原异或操作
rol_res = []
rol_res.append(output[0])
for i in range(1,32,1):
rol_res.append(xor_data[i%len(xor_data)]^output[i]^rol_res[i-1])
# 还原移位操作
swap_res = []
for i in range(32):
swap_res.append((rol_res[i]>>3)|((rol_res[(i+31)%32]<<5)&0xff))
# 还原交换操作
d = 0
num = []
for i in range(32):
d = (d+17)&0x1f
num.append(d)
inp = [0]*32
for i in range(0,32,2):
inp[num[i]] = swap_res[num[i+1]]
inp[num[i+1]] = swap_res[num[i]]
print(''.join(map(chr,inp)))
# B0mb3_L0nd0n_m0rg3n_um_v13r_Uhr.
child_protect
Debug Blocker
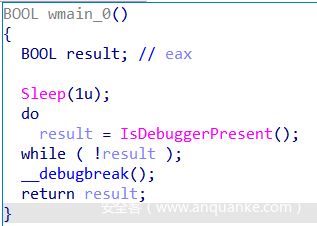
进入main函数,太短了估计是没有反汇编成功,__debugbreak()说明出现int 3指令,接下来查看汇编。
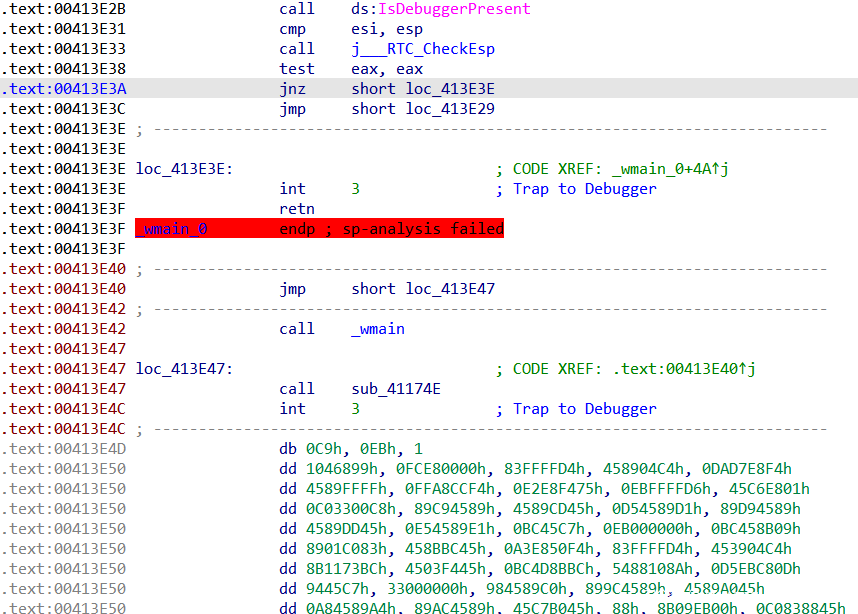
可以看到int 3指令后直接retn,这使得我们不能正确反编译main函数。后面还有大量数据没识别为代码。将其转换为代码。
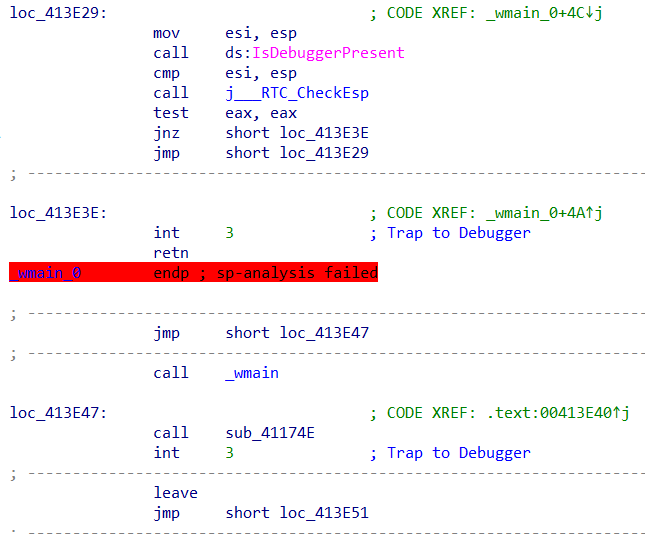
无法反编译,则不能很快确定程序的主要逻辑,多处出现int 3指令,显然不能直接patch掉那么简单,应该有相应的异常处理。那么接下来就要确定程序是如何处理的这个int 3异常,从而将main函数反编译,得到程序主逻辑。
既然不在main函数里,那应该就在main之前的运行时环境初始化部分。从start开始跟进_tmainCRTStartup()函数。
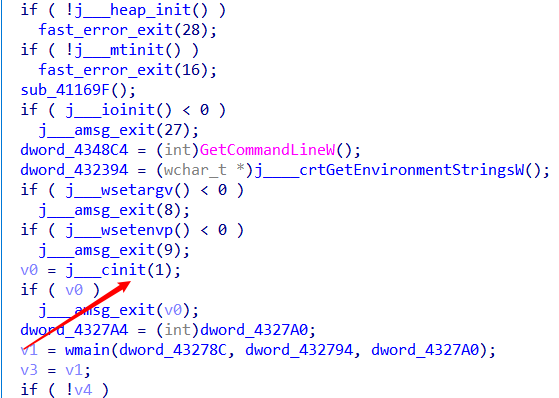
注意到这个cinit()函数,应该就是c运行时环境的初始化。

跟进可以发现initterm_e函数,查看依次执行的函数。

依次跟进可疑函数。首先查看sub_411785函数。

调用了一个IsProcessorFeaturePresent(0xA)函数,并将返回值保存。查看交叉引用,这个返回值似乎没什么用。
再查看sub_4118D9函数。
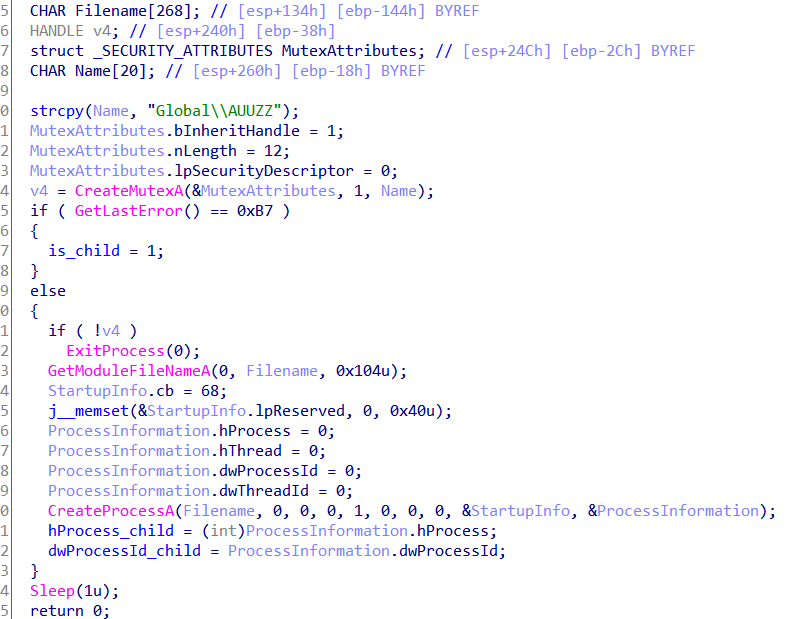
首先调用CreateMutexA函数创建一个名为Global\AUUZZ的互斥体对象。之后调用GetLastError函数,由于此时未发生错误,返回值为0,进入else语句,创建了一个子进程并保存子进程的句柄和id。则当子进程再次创建互斥体变量时,由于父进程已经创建并存在同名互斥体对象,所以LastError值为B7(ERROR_ALREADY_EXISTS),从而将设置变量为1标志这时运行的是子进程。
则这个函数之后存在两个进程。之后分析sub_4110E6函数。
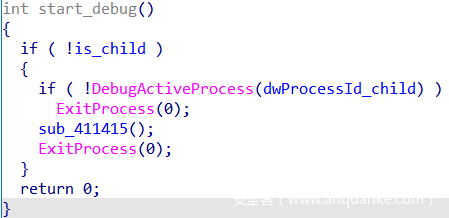
如果是子进程,则什么都不执行。最终去执行main函数。
若是父进程,则调用DebugActiveProcess函数使父进程作为调试器附加到子进程并调试它。
之后调用sub_411415函数。
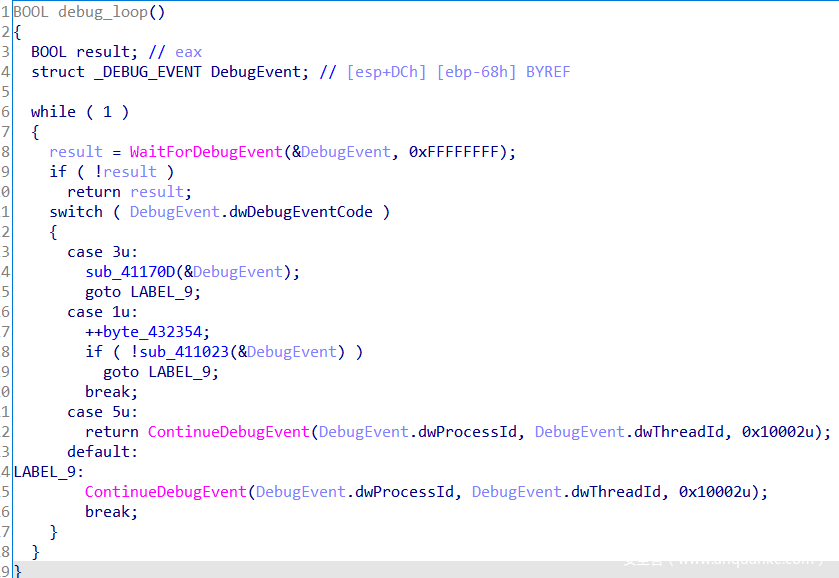
其实就是调试循环,父进程调试器通过WaitForDebugEvent函数获取调试事件,通过ContinueDebugEvent继续被调试进程的执行。
dwDebugEventCode描述了调试事件的类型,共有9类调试事件:
| value | meaning |
|---|---|
| CREATE_PROCESS_DEBUG_EVENT | 创建进程之后发送此类调试事件,这是调试器收到的第一个调试事件。 |
| CREATE_THREAD_DEBUG_EVENT | 创建一个线程之后发送此类调试事件。 |
| EXCEPTION_DEBUG_EVENT | 发生异常时发送此类调试事件。 |
| EXIT_PROCESS_DEBUG_EVENT | 进程结束后发送此类调试事件。 |
| EXIT_THREAD_DEBUG_EVENT | 一个线程结束后发送此类调试事件。 |
| LOAD_DLL_DEBUG_EVENT | 装载一个DLL模块之后发送此类调试事件。 |
| OUTPUT_DEBUG_STRING_EVENT | 被调试进程调用OutputDebugString之类的函数时发送此类调试事件。 |
| RIP_EVENT | 发生系统调试错误时发送此类调试事件。 |
| UNLOAD_DLL_DEBUG_EVENT | 卸载一个DLL模块之后发送此类调试事件。 |
其中值为3的是CREATE_PROCESS_DEBUG_EVENT,即调试器收到的第一个调试事件。值为5的是EXIT_PROCESS_DEBUG_EVENT,代表子进程结束,则父进程return后调用ExitProcess函数结束本进程。值为1的是EXCEPTION_DEBUG_EVENT,即发生异常时的调试事件,也就是之前main函数中遇到的int 3中断会触发的事件,这就是我们的目标。
其中一个变量byte_432354用于计数,但不是很清楚具体的作用。还是看关键函数sub_413950。将参数类型改为struct _DEBUG_EVENT *后进行分析。

根据文章中断点异常 STATUS_BREAKPOINT(0x80000003)可知,值0x80000003代表STATUS_BREAKPOINT,中断指令异常,表示在系统未附加内核调试器时遇到断点或断言。
通常中断指令异常可以在以下条件下触发:
- 硬代码中断请求,如:asm int 3
- System.Diagnostics.Debugger.Break
- DebugBreak()(WinAPI)
- 操作系统启用内存运行时检查,就像应用程序验证程序在堆损坏、内存溢出后会触发一样。
- 编译器可以有一些配置来启用未初始化的内存块和函数结束时应填充的内容(在重新运行..后的空白区域)。例如,如果启用/GZ,Microsoft VC编译器可以填充0xCC。0xCC实际上是asm int 3的操作码。所以如果某个错误导致应用程序运行到这样的块中,就会触发一个断点。
因此猜测可能在main函数中设置的int 3触发之前,还会由其他原因触发该调试事件两次,因此使用变量byte_432354来加以控制。
这里要注意,当int 3触发异常后,context中的eip已经指向了一下条指令,也就是addr(int 3) + 1。
因此这里处理的逻辑大致如下。
eip = addr(insn(int 3))+1
value = byte(eip)
if value == 0xA8:
eip += 9
elif value == 0xB2:
esp = 0x73FF8CA6
eip += 1
else:
eip += 1
了解处理逻辑后,回到main函数进行patch。
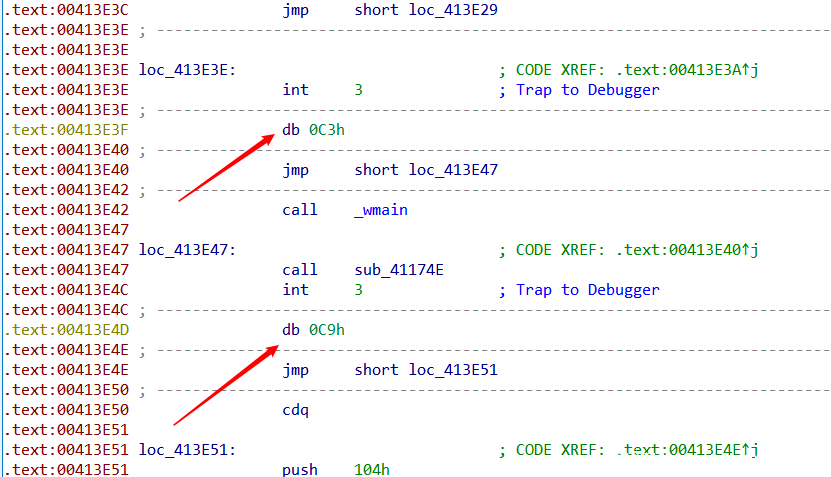
例如这里int 3后一字节既不是0xA8也不是0xB2,则直接这一字节patch(int 3也一块patch)。
patch后,再去除简单的花指令,可以反编译可得到伪代码。
事实上,这里使用的是Debug Blocker反调试技术。该技术有如下优点:
- 防止代码调试。因子进程运行实际的源代码且已经处于调试之中,原则上就无法再使用其他调试器进行附加操作了。如该程序如果在main函数中直接下断点,会发现根本断不下来。因为这时子进程执行的代码,而父进程执行的调试循环则可以断下来。
- 能够控制子进程。调试器-被调试器者关系中,调试器具有很大权限,可以处理被调试进程的异常、控制代码执行流程。使得代码调试变得十分艰难。这也是这个程序所用到的,子进程使用
int 3产生异常让父进程处理,从而破坏代码逻辑,且难以调试。
具体可见《逆向工程核心原理》第53章第7节以及第57章。
加密过程分析

首先调用sub_41174E函数,数组解密后输出Please input the flag:\n,之后调用sub_41193D函数读取输入,并检查长度为32。之后将输入进行转储。

之后一个循环进行数据类型转换,将输入的数据类型由char变为int。之后调用函数sub_41144C,跟进。
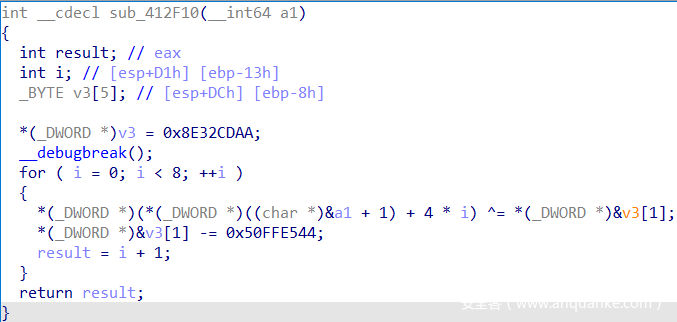
可以发现__debugbreak(),说明这里也有int 3指令。查看汇编。
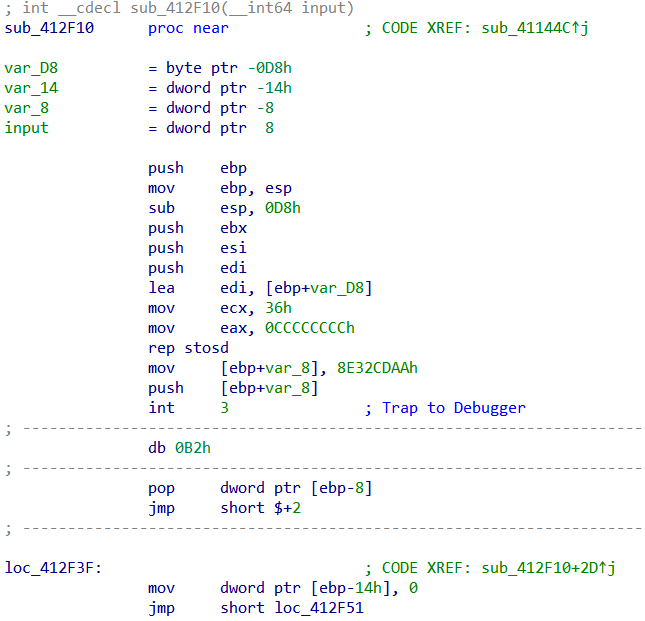
int 3指令后为0xB2,则要改变esp,即栈顶的值。栈顶的值就是最后int 3指令前最后push进栈的[ebp+var_8],而该值又由mov指令赋值,则实质上就是将这个mov指令赋值的0x8E32CDAA改为0x73FF8CA6,进行patch。

就是将输入数据按int类型进行了简单的异或操作。

之后一个循环,又将异或结果的数据类型由int转换为char。
之后调用sub_4110B9函数。

该函数根据常数计算得到一个长度为8的int型数组。
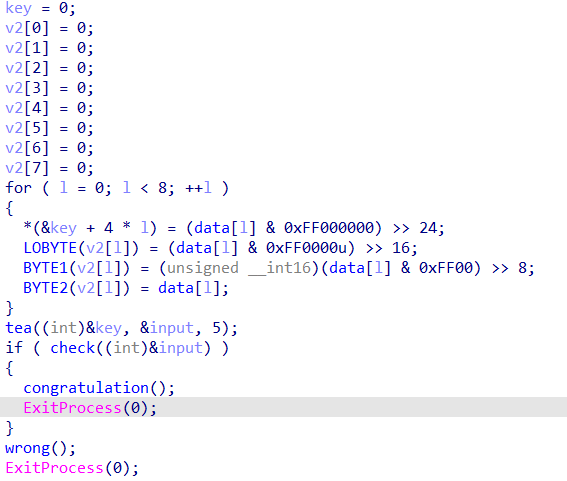
回到main函数,之后又一个循环将生成的数组由int类型转换为char。
之后调用sub_4115A0函数,参数为输入的异或结果和生成的data数组,显然是再次进行了加密。
最后对加密结果进行逐字节比较。
查看加密函数。

可以看到tea加密常数,观察可以发现是xtea加密。密钥就是前面生成的data数组的前四个数据,_byteswap_ulong就是将数据又由char类型又转换为int类型。
每轮加密结束后,又对字节序做了交换,实质又是将加密结果由int类型转换为char类型。
综上,加密过程很简单,就是先进行异或,再xtea加密,中间伴随很多次数据类型转换。
而xtea的密钥数据,可以动调直接修改eip跳转到生成数据的sub_4110B9函数,运行查看内存得到。
exp
逆向写脚本得到flag。
def tea_decipher(value, key):
v0, v1 = value[0], value[1]
k0, k1, k2, k3 = key[0], key[1], key[2], key[3]
delta = 0x9e3779b9
su = 0xc6ef3720
for i in range(32):
v1 -= ((v0<<4) + k2) ^ ((v0>>5) + k3) ^ (v0 + su)
v1 &= 0xffff_ffff
v0 -= ((v1<<4) + k0) ^ ((v1>>5) + k1) ^ (v1 + su)
v0 &= 0xffff_ffff
su = su - delta
value[0] = v0
value[1] = v1
def char2int(s):
data = []
for i in range(len(s)//4):
data.append((s[i*4]<<24)|(s[i*4+1]<<16)|(s[i*4+2]<<8)|(s[i*4+3]))
return data
def int2char(data):
s = []
for i in range(len(data)):
s.append((data[i]&0xff000000)>>24)
s.append((data[i] & 0xff0000)>>16)
s.append((data[i] & 0xff00)>>8)
s.append((data[i] & 0xff))
return s
def xor(data):
d = 0x73FF8CA6
for i in range(8):
data[i] ^= d
d -= 0x50FFE544
d &= 0xffff_ffff
if __name__ == '__main__':
res = [0xED, 0xE9, 0x8B, 0x3B, 0xD2, 0x85, 0xE7, 0xEB,
0x51, 0x16, 0x50, 0x7A, 0xB1, 0xDC, 0x5D, 0x09,
0x45, 0xAE, 0xB9, 0x15, 0x4D, 0x8D, 0xFF, 0x50,
0xDE, 0xE0, 0xBC, 0x8B, 0x9B, 0xBC, 0xFE, 0xE1]
key = [0x82ABA3FE, 0x0AC1DDCA8, 0x87EC6B60, 0x0A2394568]
dword_res = char2int(res)
for i in range(0, len(dword_res), 2):
tmp = [dword_res[i], dword_res[i+1]]
tea_decipher(tmp, key)
dword_res[i], dword_res[i+1] = tmp[0], tmp[1]
xor(dword_res)
flag = int2char(dword_res)
print(''.join(map(chr,flag)))
# Mesmerizing_And_Desirable_As_wjq
部分参考资料
WOW64!Hooks:深入考察WOW64子系统运行机制及其Hooking技术(上)
Win64 驱动内核编程-9.系统调用、WOW64与兼容模式







发表评论
您还未登录,请先登录。
登录