

本文对kernel双机调试环境搭建、基础LKM编写、内核Hook系统调用、内核模块在不同机器上的加载进行了简单的介绍。
0x00 前言
先介绍一下背景吧,目前IOT设备发展可谓如火如荼,在研究的时候作为一个懒狗,总想能够找到一些比较通用的办法,root shell已经不足以满足我了,于是就把罪恶的手伸向了内核,想要在内核里做一个Hook,但是在实际查看环境的时候才发现,很多IOT设备在出厂的时候,把 build 目录都给删了,能获取到的信息只有通过 uname -sr 查看到的版本号,因为对内核没有什么基础,最开始上手的时候极其困难,踩了许多坑,特此总结一下,同时也希望能给后入坑的师傅们做个参考。因为想尽量的细致的把这个流程写出来,很多东西可能比较啰嗦,见谅见谅。
0x01 双机调试环境搭建
如果从方便的角度来讲的话,qemu+gdb无疑是比较简便的调试方式,但是在自己之前接触的过程中发现qemu调试相对于双机调试来说还是存在其局限性的,因此个人还是建议要对内核进行调试的话还是使用双机调试的方式会比较舒服。其实如果编写的内核模块比较简单的话,通过 `dmesg` 的方式就已经可以提供很大的帮助了。
调试环境基于 Vmware + Centos 7 进行搭建
0x1 编译内核
~~搭建环境选择的kernel为 ~~`~~3.10.0~~`~~ ,这里建议的是kernel版本与系统发行时使用的kernel版本尽量接近,以免出现一些奇奇怪怪的问题。~~
这里建议选择下载rpm.src包后解包进行安装,本以为不会在这块踩坑了,无奈还是踩了个大坑,从官方源下载的kernel源码编译安装后无法正常进入系统,一直会有一个小光标在那闪来闪去闪来闪去。。目前走通的步骤如下:
- 下载源码包
wget http://vault.centos.org/7.4.1708/updates/Source/SPackages/kernel-3.10.0-693.21.1.el7.src.rpm - 安装源码包
rpm -ivh kernel-3.10.0-693.21.1.el7.src.rpm - 解压内核源码
cd /root/rpmbuild/SOURCES/ tar -xvf linux-3.10.0-693.21.1.el7.tar.xz cd linux-3.10.0-693.21.1.el7 - 编译内核
在这里可能会遇到些依赖库的问题,可能需要自行安装一下,我这里碰到的是 ncurses-devel
make menuconfig
为方便后续的调试,需要勾掉下面这个选项,在开启该选项的情况下,会将内核一些区域设置为只读,导致kgdb设置的断点失效。
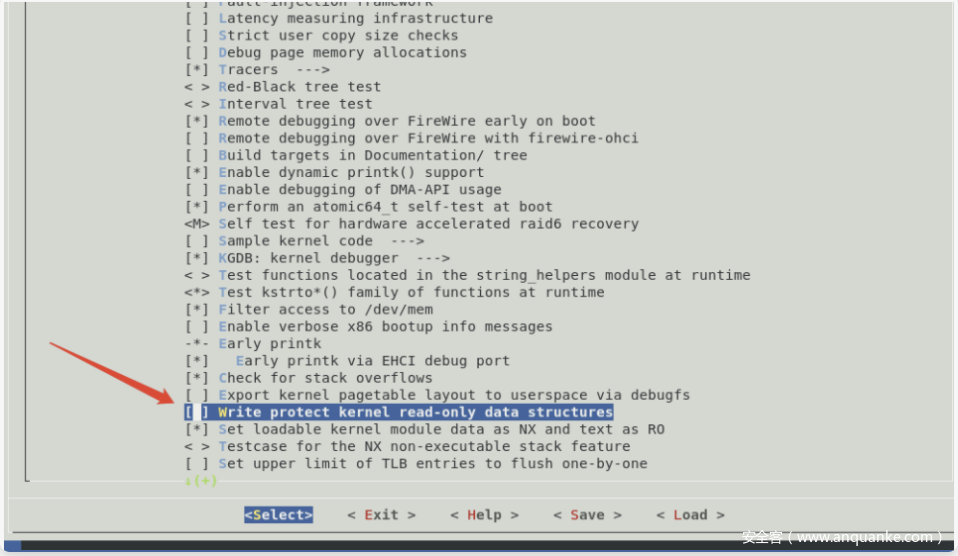
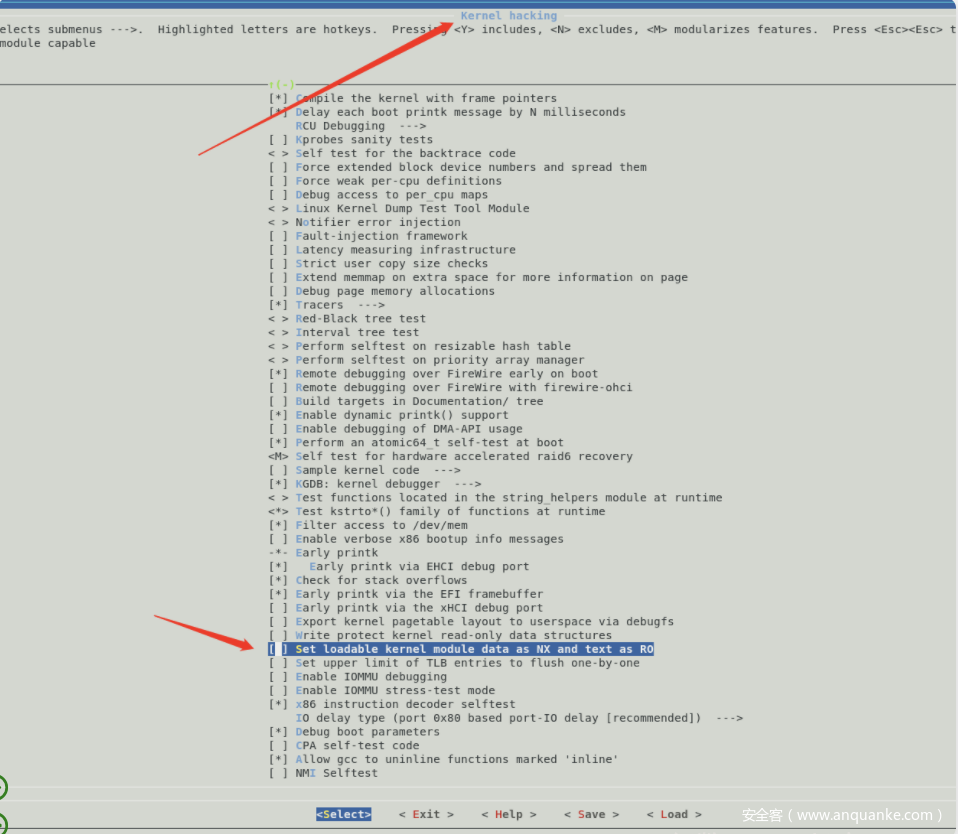
编译安装
make -j $(nproc)
make modules_install
make install
编译完成以后就可以把当前虚拟机克隆作为调试机了。
0x2 配置调试选项
- 生成initrd文件
mkinitrd initrd.img-xxx xxx // xxx 为版本号 - 拷贝文件
cp -r linux-xxx /usr/src/ cd /usr/src/linux-xxx cp arch/x86_64/boot/bzImage /boot/vmlinuz-xxx-kgdb cp System.map /boot/System.map-xxx-kgdb cp initrd.img /boot/initrd.img-xxx-kgdb - 配置grub
使得默认内核启动的时候使用串口并等待gdb连接。
vim /etc/default/grub
新增一行 GRUB_CMDLINE_LINUX_DEFAULT="quiet splash text kgdbwait kgdboc=ttyS0,115200"
grub2-mkconfig -o /boot/grub2/grub.cfg
- 添加串口
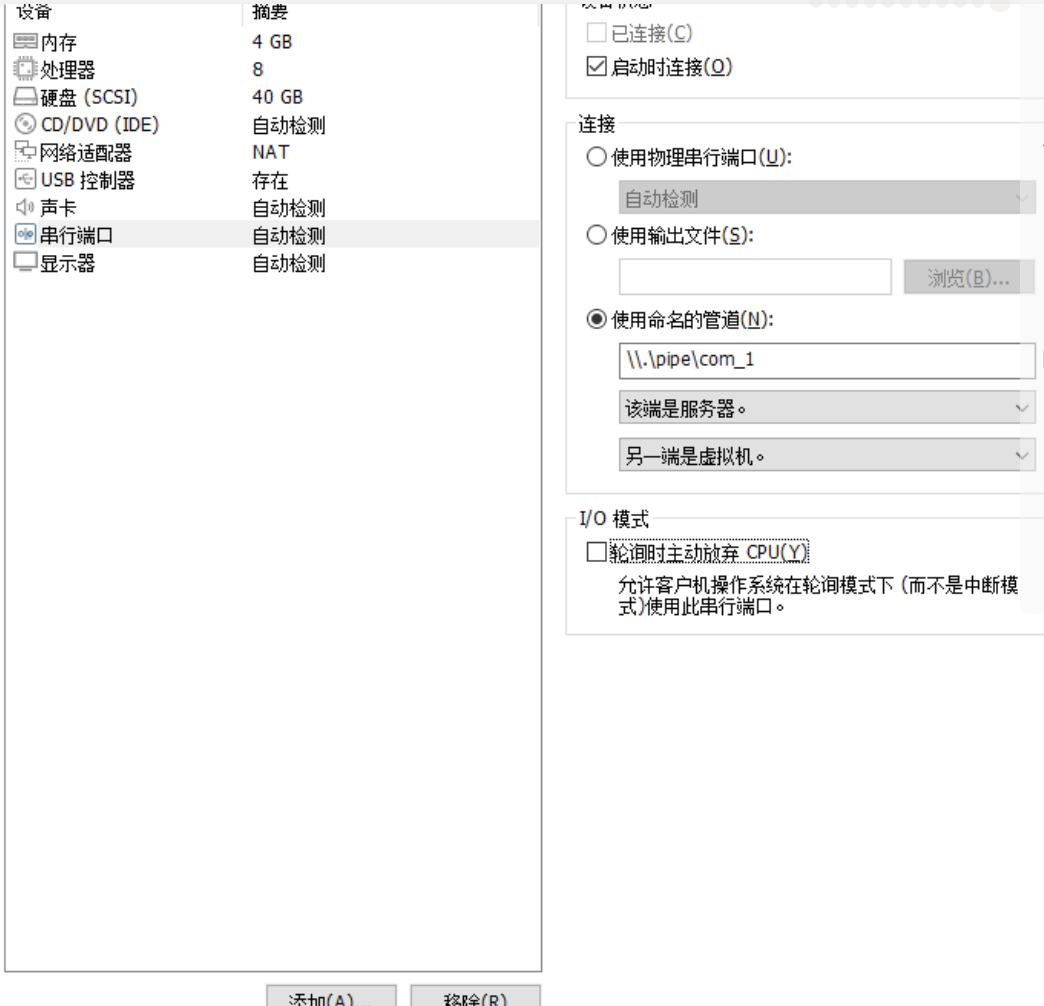
- 配置grub
vim /etc/default/grub GRUB_CMDLINE_LINUX 中增加 "kgdboc=ttyS0,115200" grub2-mkconfig -o /boot/grub2/grub.cfg
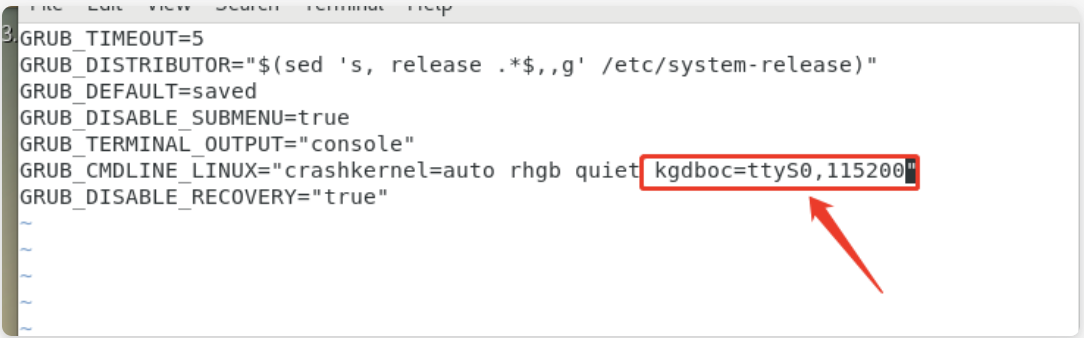
- 添加串口
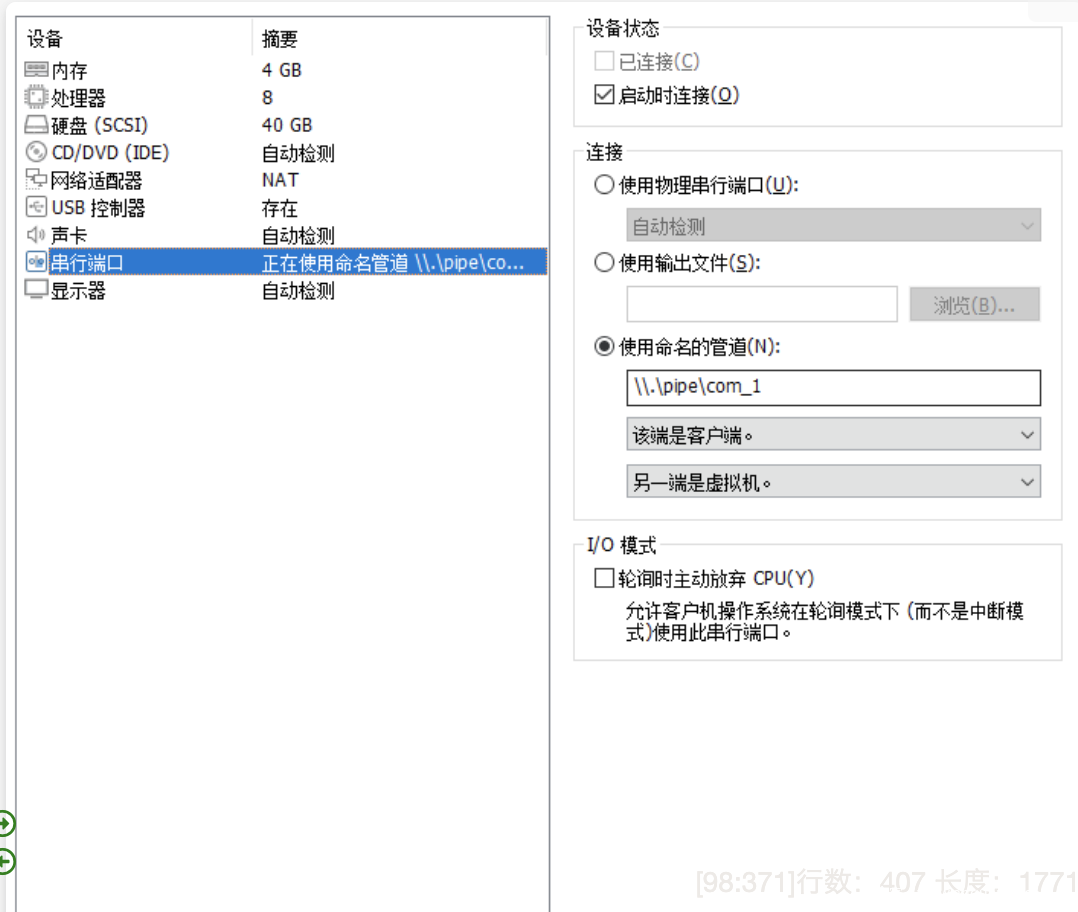
0x3 开始调试
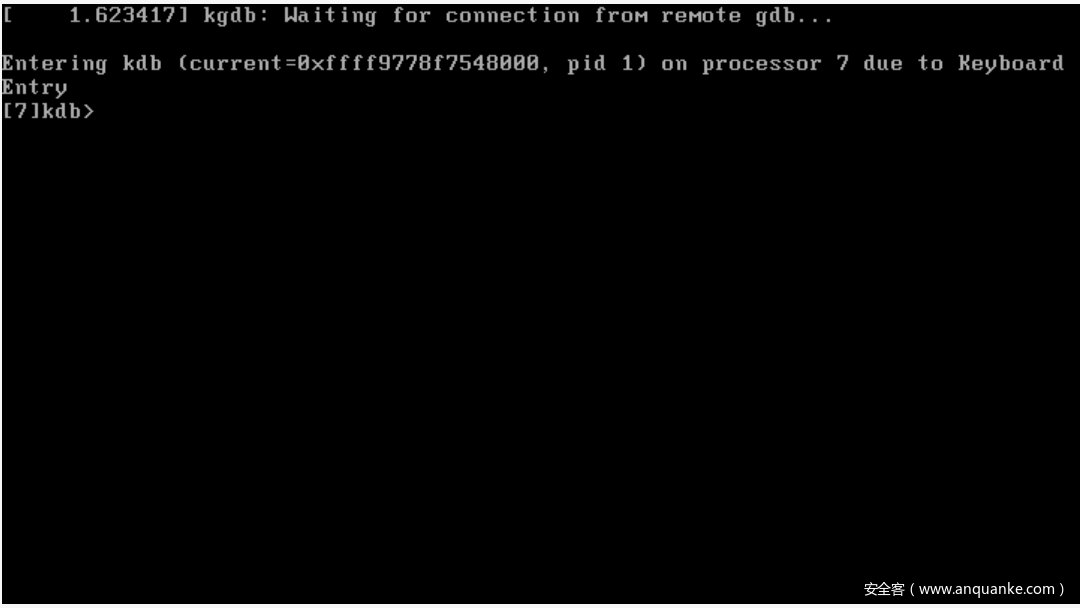
当Server端开机后选择新编译的内核后进入如下图的状态后,说明目前内核处于挂起状态,在等待kgdb连接。
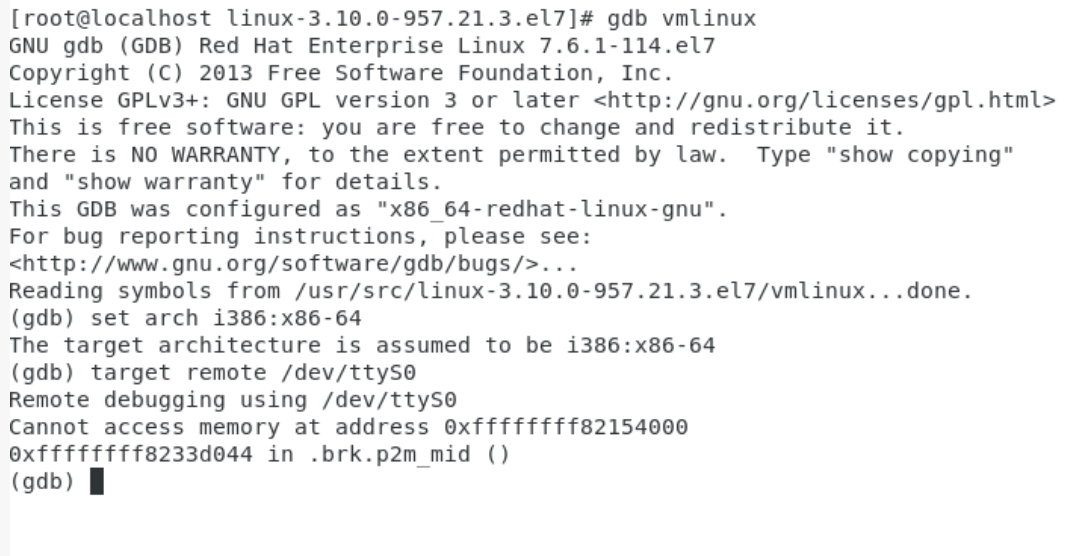
此时通过client端的gdb进行连接后即可调试内核了
我在这次编码过程中用到的调试手段还是主要以 dmesg 查看报错为主的,因此内核双机调试这块暂时就写到这里了,后续有机会的话会尝试一下 vscode+kgdb 的调试方式,毕竟源码调试内核才是王道。
0x02 内核 Hook 简介
从分类上来讲,Linux Kernel Hook其实是属于Linux RootKit的一种,通过编写LKM(Loadable Kernel Modules 可加载内核模块)来扩展Linux内核的功能,LKM相对于直接在内核中添加代码而言,具有可插拔,无需重新编译内核的特点,因此LKM原本的是被大量应用与设备驱动程序的编写中的,同时也因为上述的优点,以及内核高权限的诱惑,LKM也常常被应用于Linux rootkit中。
在介绍如何Hook之前,首先需要学习一下kernel里系统调用的实现,内核里实现了各种各样的功能,最终通过系统调用的方式向用户层提供其接口。
以execve为例:
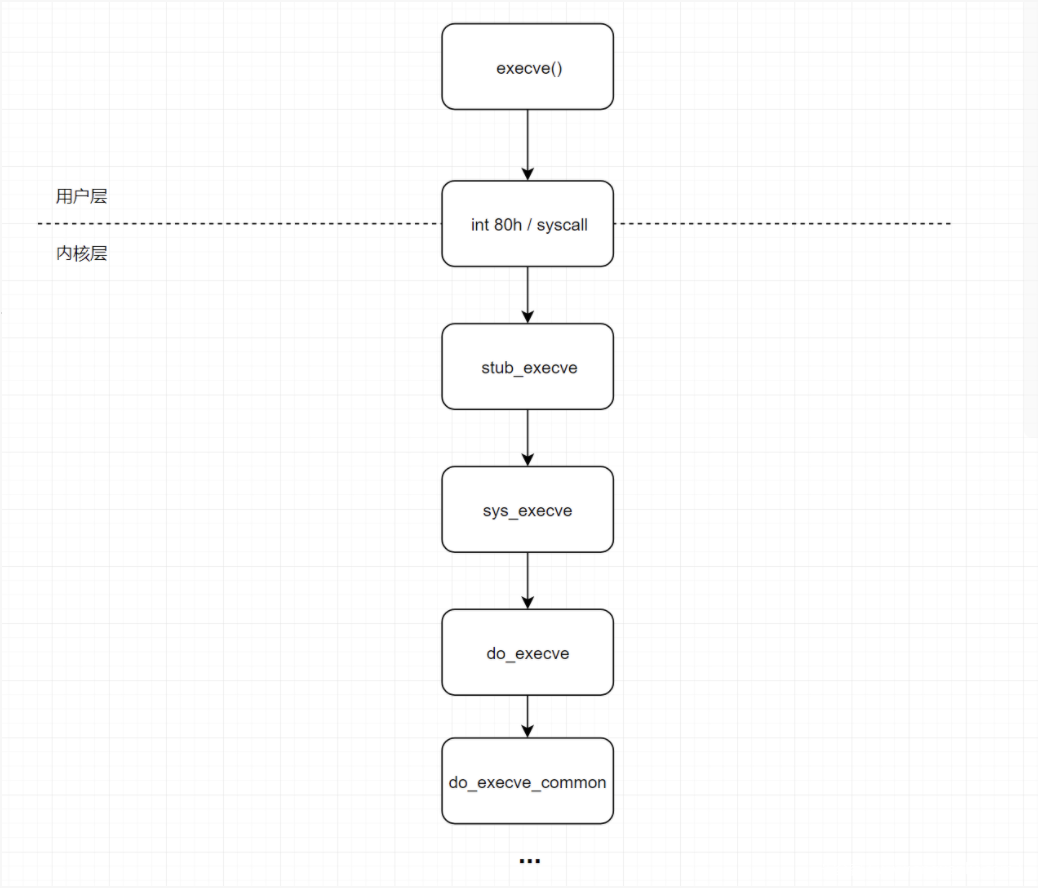
- 用户态转入内核态
用户态程序调用execve后,首先引发系统中断,根据EAX的功能号__NR_execve在系统调用表(sys_call_table)中查询到对应系统调用的入口地址。
...
#define __NR_link 9
#define __NR_unlink 10
#define __NR_execve 11
#define __NR_chdir 12
#define __NR_time 13
#define __NR_mknod 14
#define __NR_chmod 15
...
- 获取系统调用地址
在查询到的系统调用入口这里不同内核版本的结果是不太一样的,对于Linux kernel <= 2.6 的内核,在 sys_call_table 中查出来的地址就是 sys_execve 函数的地址。 Linux kernel > 2.6 也就是本次使用的 Linux 3.x 系列的内核中,sys_execve 外层套了一个壳: stub_execve,由这个系统调用中转后再调用 sys_execve,这个方式在 Linux kernel 4.x 的版本中貌似又被去除了,因此对于 Linux kernel 3.x 的 Hook就要采用不同的方式进行 Hook。
ENTRY(stub_execve)
CFI_STARTPROC
addq $8, %rsp
PARTIAL_FRAME 0
SAVE_REST
FIXUP_TOP_OF_STACK %r11
call sys_execve
movq %rax,RAX(%rsp)
RESTORE_REST
jmp int_ret_from_sys_call
CFI_ENDPROC
END(stub_execve)
ENTRY(stub_x32_execve)
CFI_STARTPROC
addq $8, %rsp
PARTIAL_FRAME 0
SAVE_REST
FIXUP_TOP_OF_STACK %r11
call compat_sys_execve
RESTORE_TOP_OF_STACK %r11
movq %rax,RAX(%rsp)
RESTORE_REST
jmp int_ret_from_sys_call
CFI_ENDPROC
END(stub_x32_execve)
- sys_execve
通过sys_call_table获取到的sys_execve最终是通过do_execve来完成其功能,在sys_execve这一层面主要做了要执行文件的文件信息校验,确认要执行的文件无误后传入do_execve中。
45 * sys_execve() executes a new program.
46 */
47 asmlinkage long sys_execve(const char __user *filenamei,
48 const char __user *const __user *argv,
49 const char __user *const __user *envp,
50 struct pt_regs *regs)
51 {
52 long error;
53 struct filename *filename;
54
55 filename = getname(filenamei);
56 error = PTR_ERR(filename);
57 if (IS_ERR(filename))
58 goto out;
59 error = do_execve(filename->name, argv, envp, regs);
60 putname(filename);
61 out:
62 return error;
63 }
在do_execve后还有do_execve_common,实际的执行逻辑其实都在do_execve_common中实现,但这些并不是这篇文章的重点,有兴趣的话可以自行去查看一下相关的代码。
通过上述对系统调用流程的简介可以发现,从用户层到内核层的最关键的一个位置就在于sys_call_table中的内容,如果我们修改了sys_call_table中调用号对应的地址为我们所插入的LKM中函数的地址的话,就可以完成对特定系统调用的Hook了。
对于 Linux Kernel <= 2.6 以及 Linux Kernel 4.x 的 Hook 来说,通过修改sys_call_table中 NR_execve 对应的地址为自实现execve函数的地址即可。
对于 Linux Kernel 3.x 的 Hook 来说,就不能简单的替换 NR_execve 来实现了,在 stub_execve 的实现中对rsp进行了平衡后才调用的 sys_execve, 根据这个逻辑就产生了两种 Hook 的方式:
- 替换 stub_execve 后自行实现栈平衡
通过 inlline hook 的方式对内存进行patch,修改 call sys_execve 调用的地址为我们自己实现的 execve 函数的地址
我是使用第二种方式进行的 Hook,相对于第一种方法来说具有一定的暴力性,需要对内核的代码段进行修改。
内核系统调用Hook的代码需要通过内核模块的方式加载进入内核中,首先需要对内核模块有一个简单的了解。下面是一个 LKM 的 hello world
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
MODULE_LICENSE(“GPL”);
MODULE_AUTHOR(“user”);
MODULE_DESCRIPTION(“A simple example Linux module.”);
MODULE_VERSION(“0.1”);
static int __init hello_init(void) {
printk(KERN_INFO “Hello, World!\n”);
return 0;
}
static void __exit hello_exit(void) {
printk(KERN_INFO “Goodbye, World!\n”);
}
module_init(hello_init);
module_exit(hello_exit);
在编写内核模块前必须导入的三个头文件 linux/init.h , linux/module.h, linux/kernel.h,其次是模块的加载,LKM中没有main函数,对应的是module_init和module_exit,module_init在LKM被加载进入内核后调用,module_exit在LKM被卸载时调用。
编写完 LKM 后需要写一个简单的 Makefile
obj-m += hello_world.o # obj-m 表示将 hello_world.o 编译为模块, obj-y 表示将 hello_world.o 编译入内核中(更详细的内核Makefile命令的解释可以参考官方文档)
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
make 后就可以看到一个 hello_world.ko 的文件
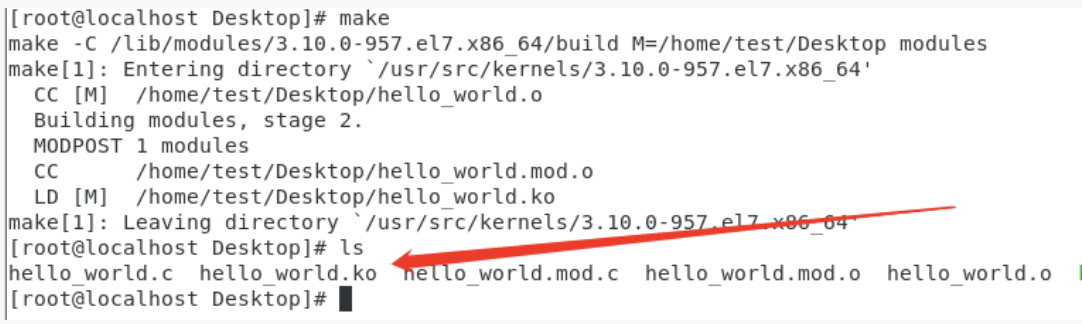
此时,通过 insmod 指令即可将 hello_world.ko 模块加载进入内核中,通过dmesg命令就可以看到hello world了。
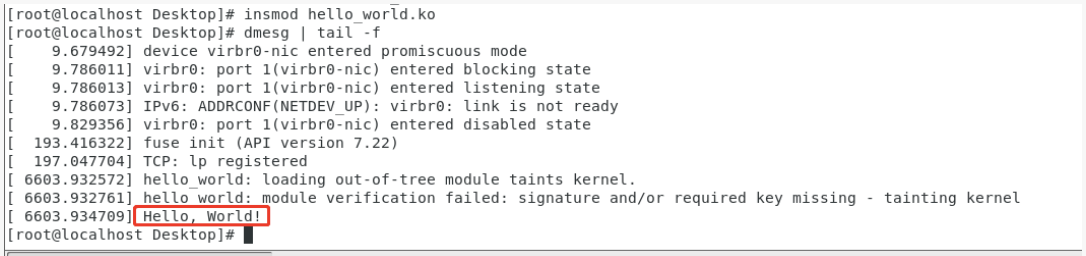
卸载 LKM 的命令为 rmmod, 需要注意的是,如果在编写代码过程中没有写 module_exit 的话,LKM是不能通过 rmmod 卸载掉的!
0x03 Hook execve
首先实现一个自己的sys_execve函数,这里需要注意的是,在实现自己的内核函数的时候,一定要严格按照原函数的定义来定义自己的函数,否则在调用的时候有一定的几率会 crash

asmlinkage long my_hook_execve(const char __user *filename, const char __user * const __user *argv,
const char __user *const __user *envp)
{
char user_filename[500] = {0};
get_user_cmdline(argv, user_filename, 500);
return orig_execve_func(filename, argv, envp);
}
代码逻辑比较简单,打印当前执行指令的参数后就直接调用了原本的 sys_execve 函数,这里如果之前没有对内核编码有基础了解的话,容易踩的一个坑就是内核代码是不能直接访问用户空间数据的,需要通过指定的接口来从用户空间拷贝数据到内核中。
bool get_user_cmdline(const char __user *const __user *argv, char* cmdline, int cmd_len)
{
if(unlikely(argv==NULL||cmdline==NULL||cmd_len<=0))
return false;
memset(cmdline, 0, cmd_len);
int i=0, offset=0;
if(argv != NULL){
for(;i<0x7fffffff;){
const char __user *p;
int ret = get_user(p, argv+i);
if(ret || !p || IS_ERR(p)){
break;
}
char tmp[256]={0};
ret = copy_from_user(tmp,p,256);
if(ret<256){
int tmp_len = strlen(tmp);
if(offset+1+tmp_len > cmd_len){
printk("[err] %s. too much args",__FUNCTION__);
break;
}
strncpy(cmdline+offset, tmp, tmp_len);
offset += tmp_len;
cmdline[offset]=' ';
offset++;
}
else{
printk("[err] %s. copy_from_user failed. ret:%d.\n",__FUNCTION__, ret);
}
++i;
}
}
if(cmdline[offset-1]==' ')
cmdline[offset-1]=0;
printk("[cmdline]:%s, offset:%d\n", cmdline, offset);
return true;
}
通过 copy_from_user、strncpy_from_user、copy_to_user、get_user、put_user 可完成用户空间数据与内核的交互。
//__copy_from_user — Copy a block of data from user space, with less checking.
unsigned long __copy_from_user (void * to,const void __user * from,unsigned long n);
//strncpy_from_user -- Copy a NUL terminated string from userspace.
long strncpy_from_user (char * dst, const char __user * src, long count);
//copy_to_user -- Copy a block of data into user space.
unsigned long copy_to_user (void __user * to, const void * from, unsigned long n);
//get_user -- Get a simple variable from user space.
get_user (x, ptr);
//put_user -- Write a simple value into user space.
put_user (x, ptr);
获取sys_call_table前首先要根据内核对应结构信息,在代码中增加相关的定义
typedef asmlinkage long (*sys_call_ptr_t)(const struct pt_regs *);
static sys_call_ptr_t *sys_call_table;
typedef asmlinkage long (*execve_t)(const char __user *filename, const char __user * const __user *argv,
const char __user *const __user *envp, struct pt_regs *);
execve_t orig_execve_func = NULL;
execve_t stub_execve_func = NULL;
sys_call_table = (sys_call_ptr_t *)kallsyms_lookup_name("sys_call_table"); //获取 sys_call_table 地址
stub_execve_func = (execve_t)sys_call_table[__NR_execve]; // 获取stub_execve地址
orig_execve_func = kallsyms_lookup_name("sys_execve"); // 获取原始sys_execve地址
因为需要对内核的代码段打patch,首先需要内核对代码段的保护(CR0),patch完毕后再开启。
write_cr0(read_cr0() & (~0x10000));
replace_kernel_func(stub_execve_func, orig_execve_func, (unsigned long)my_hook_execve);
write_cr0(read_cr0() | 0x10000);
patch函数源码如下:
static int replace_kernel_func(unsigned long handler,
unsigned long orig_func, unsigned long my_func)
{
unsigned char *tmp_addr = (unsigned char*)handler; // stub_execve 函数的地址
int i = 0;
do{
/* in x86_64 the call instruction opcode is 0x8e,
* occupy 1+4 bytes(E8+offset) totally
*/
if(*tmp_addr == 0xe8){ // 从头开始找 call 指令
int* offset = (int*)(tmp_addr+1);
if(((unsigned long)tmp_addr + 5 + *offset) == orig_func){ // 找到 call 指令后判断是否 call 的地址是 sys_execve
printk("call:0x%08x, offset:%08x, old_func:%08x.\n",
(unsigned int)tmp_addr, *offset, orig_func);
/* replace with my_func relative addr(offset) */
*offset=my_func-(unsigned long)tmp_addr-5; // 如果是,则替换该地址为我们自实现的地址
printk("call:0x%08x, offset:%08x, new_func:%08x.\n",
(unsigned int)tmp_addr, *offset, my_func);
return 1;
}
}
tmp_addr++;
}while(i++ < 128);
return 0;
}
在完成hook后不要忘记将call sys_execve恢复到原来的状态,否则在 LKM 卸载后,call sys_execve 仍然会跳转到原本是自实现execve函数的地址上去导致crash。
static int __exit test_exit(void)
{
write_cr0(read_cr0() & (~0x10000));
replace_kernel_func(stub_execve_func, (unsigned long)my_hook_execve, orig_execve_func);
write_cr0(read_cr0() | 0x10000);
return 0;
}
最终实现的效果如下:
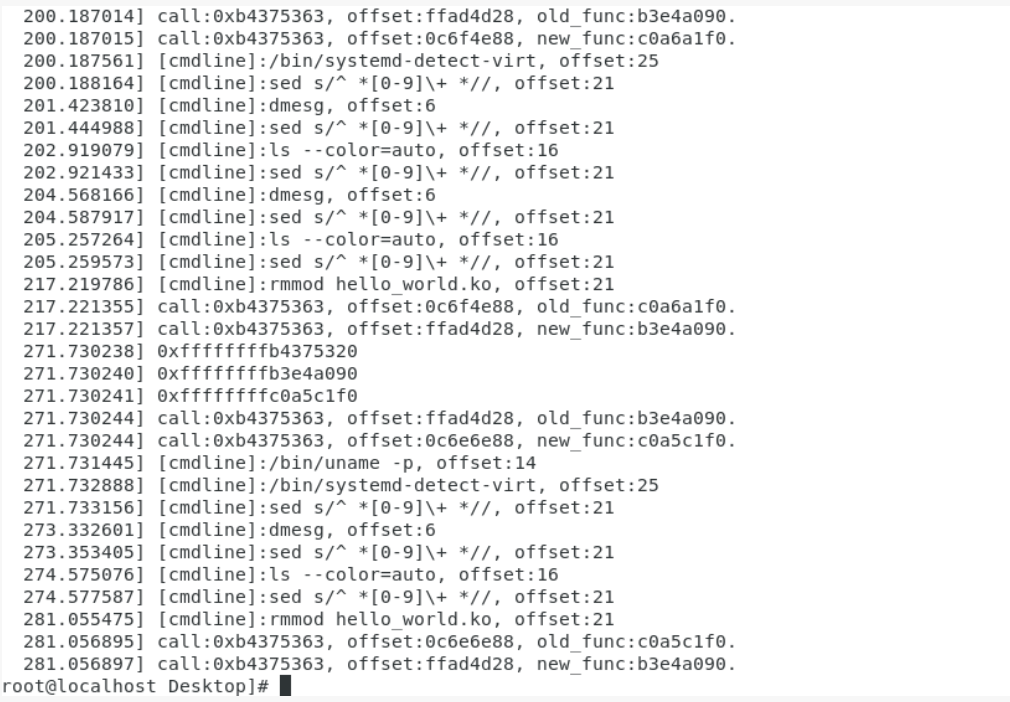
此时,我们就已经成功的在Centos上把模块跑起来了~
0x04 内核模块迁移
当我拿着连小版本号都匹配上的实验环境中编译的内核模块放到IOT设备上执行了 `insmod` 后,系统无情的给报了一个错误:
[Thu May 13 xx:xx:xx 2021] hello_world: disagrees about version of symbol module_layout
google 查询了一圈之后,得到的回答基本都是需要LKM与kernel版本完全匹配,否则kernel会拒绝LKM的加载,难道就已经没有办法了吗?不甘心的我打开了IDA,偶然间看到了 `__version` 区段
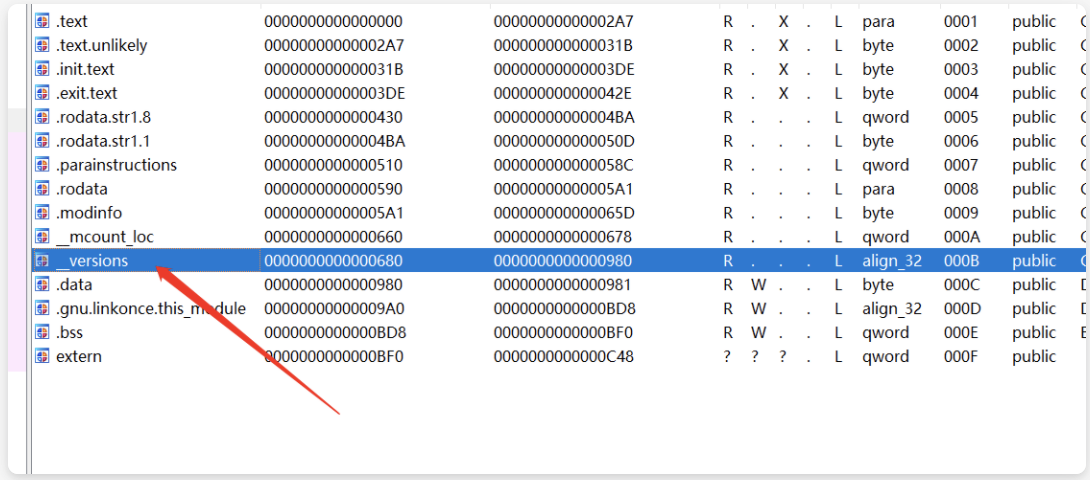
然后在 Hex 窗口看到了这样的一串hex

想必很多大师傅已经懂了我要干什么了,我从目标上扒了一个ko文件下来,找到了module_layout 的四字节签名后直接在 IDA 中把我的ko文件中module_layout 的签名patch成和目标上一样的。

把该patch的地方都patch完了以后直接 insmod ,本以为能够加载起来,系统又把我策马奔腾的心给拦下来了,这次提示的错误是找不到 __x86_indirect_thunk_rax 这个符号,这可如何是好??
kernel: helloworld: Unknown symbol __x86_indirect_thunk_rax (err 0)
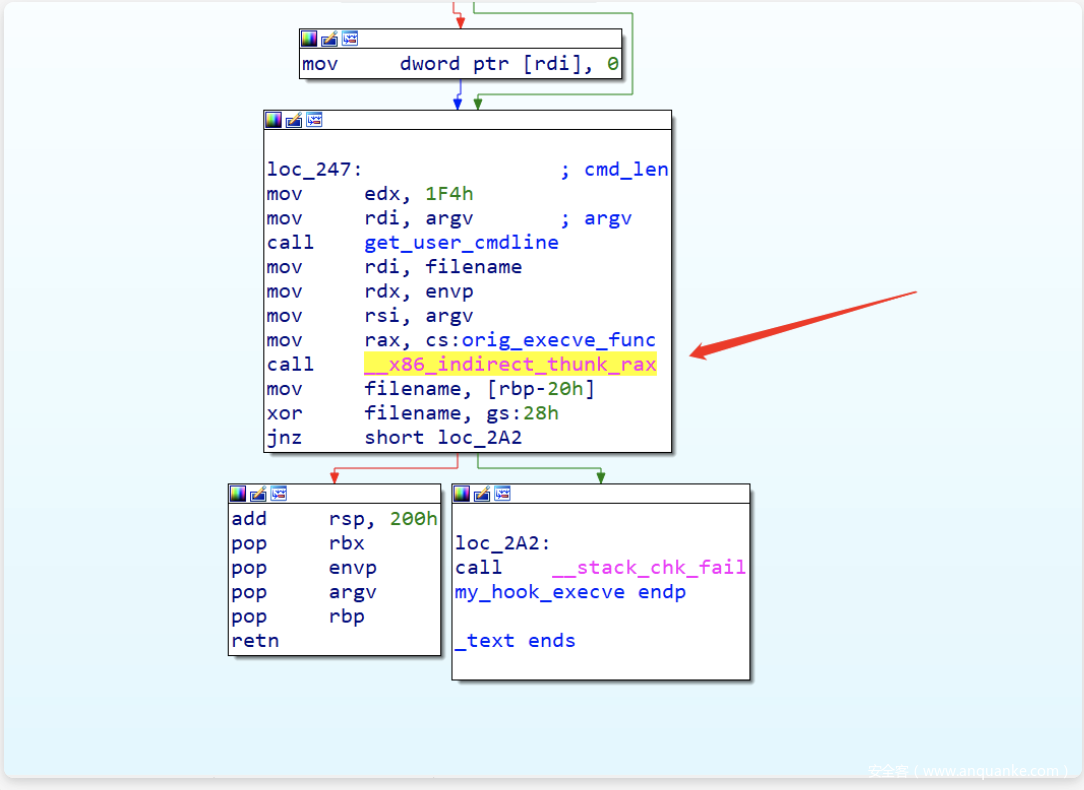
代码逻辑里最终调用原本的sys_execve函数是通过一个动态调用实现的,编译完成后就变成了__x86_indirect_thunk_rax 这个符号,总不能把这玩意删了吧?
不死心的我在目标上查询了一下,确实是没有这个符号。。

此时的我一度陷入僵局,就差最后一步就能将模块成功加载了,通过对这个函数的搜索后,果然是找到些端倪,在搜索过程中,`__x86_indirect_thunk_rax` 与 `retpoline` 的关联相当的密切,经过一番学习后才知道,**retpoline是Google开发的针对Spectre变种2漏洞缓解利用技术。**换句话说就是IOT设备在发布的时候,还没有爆出Intel幽灵漏洞,但是在我编译内核模块的实验环境中,系统已经打过这个补丁了,导致我使用的内核模块中导入了新的内核符号,从而造成在IOT设备上加载的时候无法找到该符号的问题。
那么解决办法也很简单了,在搭建实验环境的时候去除上述的补丁即可~
最终也是成功的在IOT设备上成功的把模块加载起来了在整个编码过程中踩了许多坑,同时非常感谢在这次学习中为我提供无私帮助的大师傅们。
参考链接
https://mp.weixin.qq.com/s/SDeSOCb-C4YEeIKAGfA8WQ
https://qkxu.github.io/2019/05/29/CentOS-7-%E4%B8%8A%E7%BC%96%E8%AF%91%E5%AE%89%E8%A3%85Linux%E5%86%85%E6%A0%B8.html
https://www.cnblogs.com/cobcmw/p/11387801.html
https://www.kernel.org/doc/Documentation/kbuild/makefiles.txt
https://elixir.bootlin.com/linux/v3.10/source/fs/exec.c#L1583
https://cloud.tencent.com/developer/article/1087370







发表评论
您还未登录,请先登录。
登录