

前言
堆利用这块内容相对独立但是类型较多,希望本系列文章能够让读者掌握堆利用的一些通用方法,建立堆利用的基本知识体系。
堆是一块需要动态管理的内存,glibc是实现堆管理的库,为了效率更高的管理堆,引入了很多机制,这就给利用堆破坏漏洞实现代码执行提供了很多攻击面。
但是,相比于栈破坏的利用,堆本身就很复杂,需要理解堆的一些关键部分的工作原理,才能更好的写出利用代码,因此我们这篇文章先学习了解下堆的基本概念和关键实现原理。
关于libc的版本
malloc和calloc相关的代码都在libc中,但是不同libc版本,malloc的差异性可能会很大,导致需要利用不同的利用方式来针对同一种类型的漏洞。因此,在利用之前一定要搞清楚libc的版本,是uclibc还是glibc,以及具体的子版本号。
Malloc Chunk
首先我们要学习一下Chunk的基本概念
当我们在调用malloc的时候,就会返回一个指针指向一个chunk
我们的测试代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void main(void)
{
char *ptr;
ptr = malloc(0x10);
strcpy(ptr, "panda");
}
我们可以看到在panda的前面是有一块描述区的,这一块也是chunk的一部分,我们可以把它叫做metadata部分,他主要是由一块标识前一个chunk大小的和一个表示当前chunk大小的部分组成。在64位中,一个标识的长度是8个字节,在32位中则是4个字节。
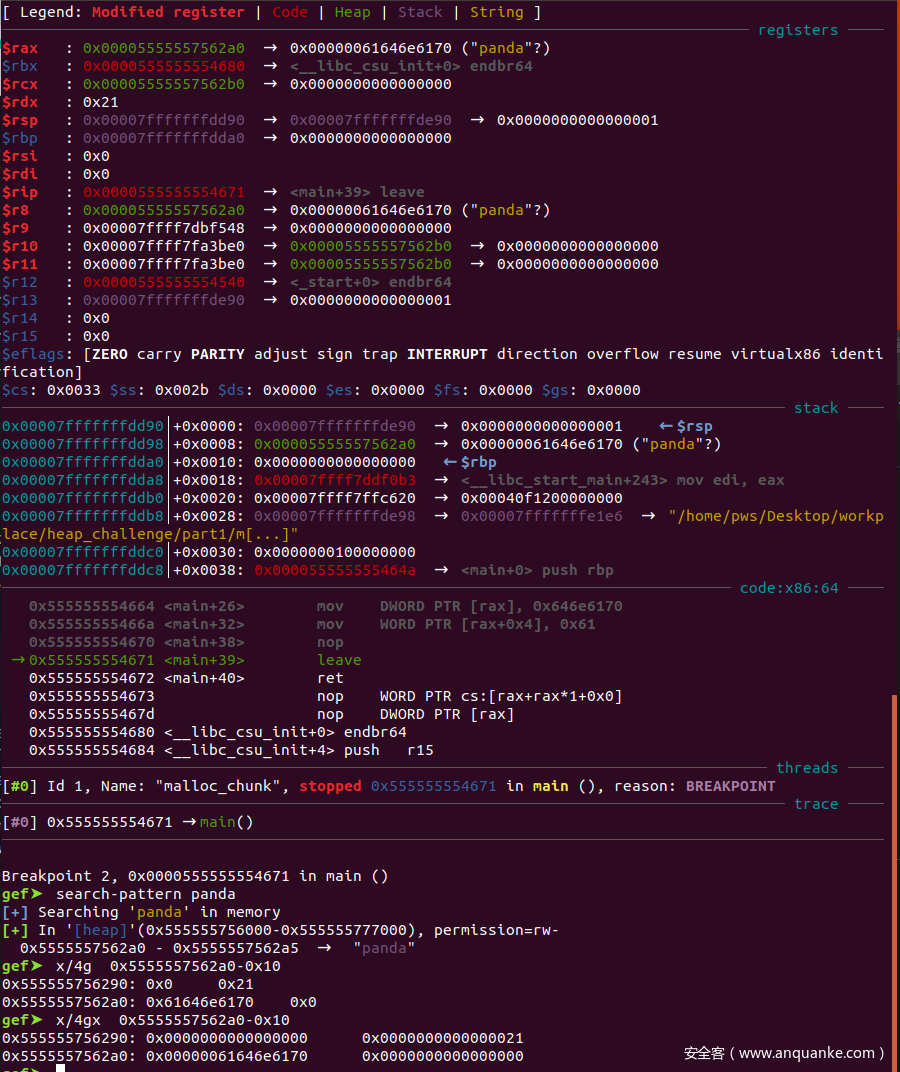
0x0: 0x00 - Previous Chunk Size
0x8: 0x21 - Chunk Size
0x10: "pada" - Content of chunk
我们可能会发现,在本例中标识前一个块的大小的是0x0,这是什么意思,这个主要是根据chunk size这个字段的标识0x21,说明前面一个紧邻的chunk是被使用了,因此previouschunksize这个字段实际上是上一个chunk的数据区部分。换句话说,根据chunk size字段的最后一位的不同,chunk的结构的意义是不一样的,但是大小是不变的。
Chunk size字段的最后一位是标志着前面一块是否在使用的,1代表着在使用,0代表着没有使用
对于被释放的Chunk,他还有两个字段是用来指向在bin链表中相邻的chunk的,注意bin链表中相邻与实际上的相邻chunk是不一样的。有的bin链表是双向链表,需要使用fd和bk两个字段,有的链表是单向链表,只需要使用fd字段,bk无意义。
Bins
heap中有各种各样的Bin数据结构,当一个chunk被释放了,会被bin数据结构记录,一般是一个链表。根据被释放的chunk的大小,将他们放到不同的bin中,主要有下面几种bin
- Fast bin:
- Unsorted bin
- Small bin
- Large bin
这个数据结构可以加快下一次分配chunk的时候更加迅速,直接在这些bin中先寻找合适的chunk
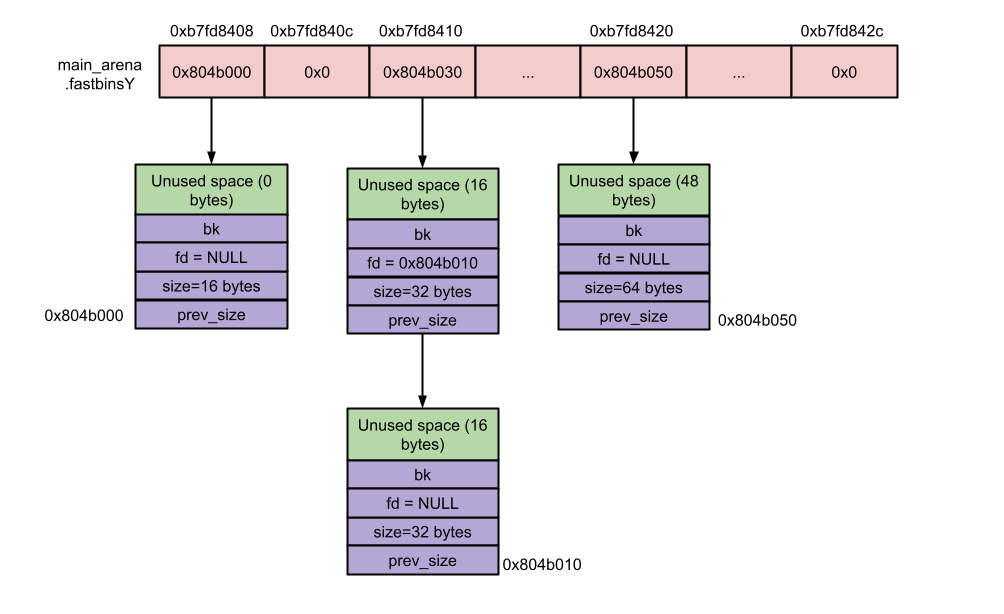
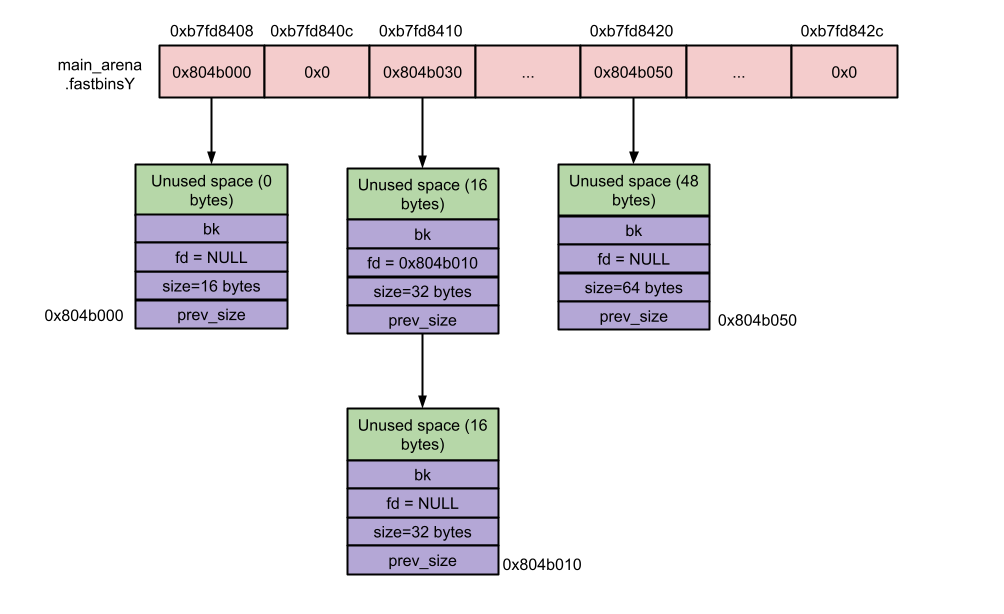
Fast bin
在x64中,Fastbin chunk的大小是从0x20,到0x80。Fastbin共有7个链表组成,每个链表上维护的chunk的大小都是相同的,通过GEF的 heap bins fast可以方便的查看各个fast bin链表上的情况
────────────────────── Fastbins for arena 0x7ffff7dd1b20 ──────────────────────
Fastbins[idx=0, size=0x10] ← Chunk(addr=0x602010, size=0x20, flags=PREV_INUSE) ← Chunk(addr=0x602030, size=0x20, flags=PREV_INUSE)
Fastbins[idx=1, size=0x20] ← Chunk(addr=0x602050, size=0x30, flags=PREV_INUSE)
Fastbins[idx=2, size=0x30] ← Chunk(addr=0x602080, size=0x40, flags=PREV_INUSE)
Fastbins[idx=3, size=0x40] ← Chunk(addr=0x6020c0, size=0x50, flags=PREV_INUSE)
Fastbins[idx=4, size=0x50] ← Chunk(addr=0x602110, size=0x60, flags=PREV_INUSE)
Fastbins[idx=5, size=0x60] ← Chunk(addr=0x602170, size=0x70, flags=PREV_INUSE)
Fastbins[idx=6, size=0x70] ← Chunk(addr=0x6021e0, size=0x80, flags=PREV_INUSE)
注意要分清楚Fast chunk和fast bin是不同的概念,fast chunk的意思是放在fast bin链表上的chunk。fastbin本身实际上是一个数组,数组的每个元素是一个fast bin链表指针,fast bin链表指针指向heap中的chunk的地址,而chunk中有fd指针,又指向了下一个free chunk,因此这样就形成了一个单向链表。当插入chunk的时候是从头部开始插入的,就是先入后出的。
tcache
这个数据结构是在2.26版本中新引入的,每一个线程都会有一个tcache,目的是不需要再多线程中操作heap的时候给bin加锁,这样就可以更加的迅速。tcache是在分配chunk的时候的第一优先考虑的分配来源,甚至比fast bin还要优先。
tcache的数据结构与Fast bin类似,都是一个单向链表,都是先入后出的。相关的数据结构源码
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
struct tcache_perthread_struct *key;
} tcache_entry;
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
static __thread bool tcache_shutting_down = false;
static __thread tcache_perthread_struct *tcache = NULL;
static __thread tcache_perthread_struct *tcache这个是个全局变量,直接指向了这个tcache数据结构,应该是每个线程都会维护以这个这个全局变量。 tcache_perthread_struct中包含了一个tcache_entry数组,元素有64个,代表着64个链表,也就是说以供会有64个单向链表组成一个tcache,每个链表上也是与fast bin一样都是记录的相同大小的某个size的chunk。但是与fastbin不一样的是,单向链表的长度是有限制的,不能超过7,当超过7个的时候就会往对应的bin上进行分流,同样可以通过GEF的heap bins tcache去查看。64个链表维护的chunk大小范围为0x20-0x410,间隔是0x10.
Unsorted, Large 和 Small bins
Unosrted, Large 和 Small bins联系的比较紧密,他们都是在一个数组中的,而fastbin 和tcache都是有自己单独的数组的。
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
bins这个数组中的第0个元素空置,第一个元素就是指向unsorted bin list的指针,紧接着的62个元素都是指向samll bin 链表的指针,后面63个指向的是Large bin链表的指针。
如下图所示的结构图
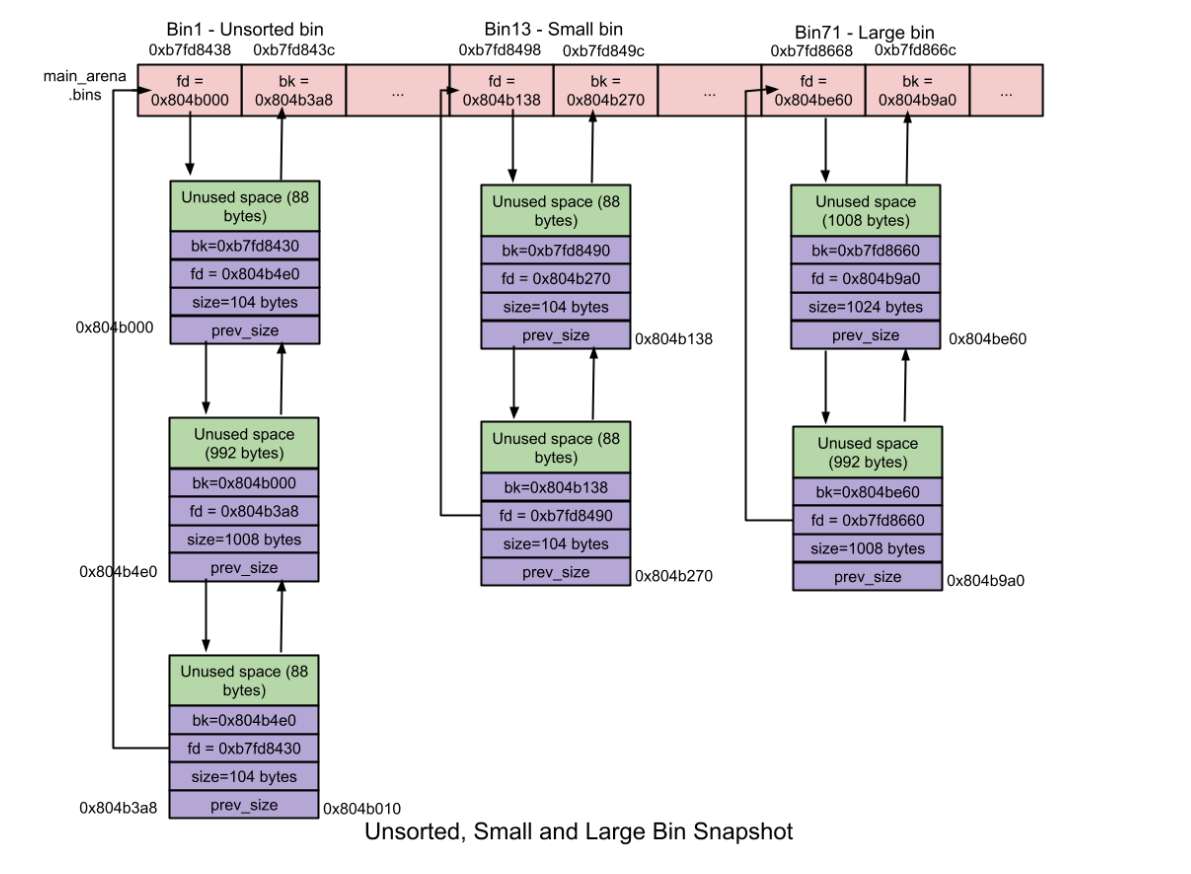
Unsorted bin链表,这个主要是用来存放刚被释放的chunk,被free释放掉的chunk并不会直接回到对应的fast bin或者small bin large bin中,而是先回到unsorted bin,以供后面malloc的时候更加快速的使用。
- 这是一个双向链表,与fast bin链表不同是它多了一个bk指针
- 这个链表上的大小并不是固定的,任何大小的chunk都可以到这个链表上来
- 当出现malloc_consolidate,就是一次对heap的整理,就会把unsorted bin重新放到各自对应chunk size的链表上
Small bin的每个链表存放的元素的大小的都是相同的,对于大小不大于0x400(64bit)的chunk会被放置在这个链表上
Large Bin使用来存放超过0x400大小的chunk的,但是这些链表上的chunk的大小并不一定是相同的,而是有一个范围的,比如对于0x400到0x420(仅举例)的chunk都放在第一个large bin的链表上。
Top chunk
是在当前在用的堆区的最顶部,它不是属于任何一个bin,是一个之前调用mmap或者sbrk从内核中分配的内存还剩下未用的区域。如果用户请求的size在所有的bin和tcache中都没有满足,就会从top chunk开始分配,剩下的未用的chunk则是新的top chunk。
如果当前用户请求的size连top chunk都满足不了,则会继续调用系统调用mmap或者sbrk扩展堆区,就是扩展top chunk。然后再把chunk返回给用户。
top chunk是所有分配的源头,第一个malloc肯定是从top chunk中分配的,因为此时所有的bin和tcache都是空的
各种bin和chunk在内存中的示意图
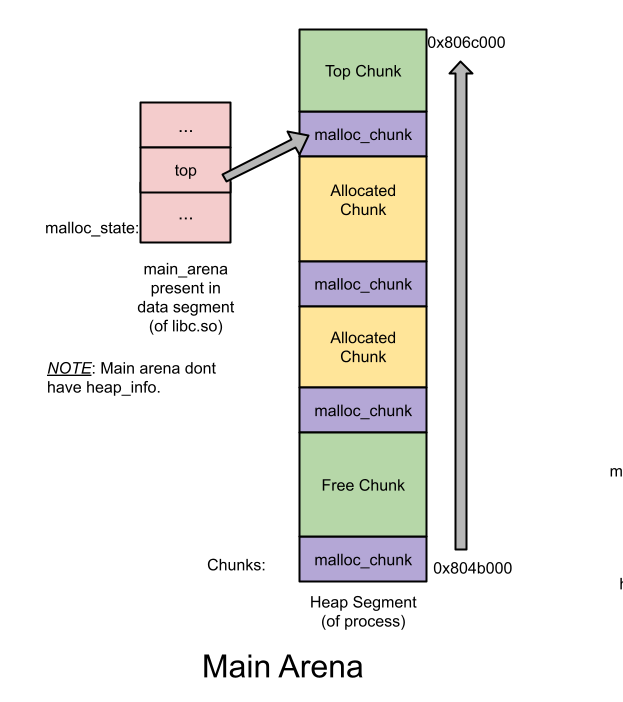
malloc_chunk就是chunk header,是一个chunk的开头,无论malloced或者空闲的都有这个header.
Main Arena
Main Arena实际上就是一个对heap的抽象的数据结构,它包含了对各种bin的定义,tcache的定义,top chunk的定义,都是在这个数据结构中的,它在初始化的时候是作为一个全局变量保留在全局区域的。
当我们在GEF中调用heap相关的各种命令实际上都是通过对这个变量的读取来解析的。
gef➤ heap bins
[+] No Tcache in this version of libc
────────────────────── Fastbins for arena 0x7ffff7dd1b20 ──────────────────────
Fastbins[idx=0, size=0x10] ← Chunk(addr=0x602010, size=0x20, flags=PREV_INUSE)
Fastbins[idx=1, size=0x20] 0x00
Fastbins[idx=2, size=0x30] 0x00
Fastbins[idx=3, size=0x40] 0x00
Fastbins[idx=4, size=0x50] 0x00
Fastbins[idx=5, size=0x60] 0x00
Fastbins[idx=6, size=0x70] 0x00
───────────────────── Unsorted Bin for arena 'main_arena' ─────────────────────
[+] Found 0 chunks in unsorted bin.
────────────────────── Small Bins for arena 'main_arena' ──────────────────────
[+] Found 0 chunks in 0 small non-empty bins.
────────────────────── Large Bins for arena 'main_arena' ──────────────────────
[+] Found 0 chunks in 0 large non-empty bins.
gef➤ x/20g 0x7ffff7dd1b20
0x7ffff7dd1b20 <main_arena>: 0x0 0x602000
0x7ffff7dd1b30 <main_arena+16>: 0x0 0x0
0x7ffff7dd1b40 <main_arena+32>: 0x0 0x0
0x7ffff7dd1b50 <main_arena+48>: 0x0 0x0
0x7ffff7dd1b60 <main_arena+64>: 0x0 0x0
0x7ffff7dd1b70 <main_arena+80>: 0x0 0x602120
0x7ffff7dd1b80 <main_arena+96>: 0x0 0x7ffff7dd1b78
0x7ffff7dd1b90 <main_arena+112>: 0x7ffff7dd1b78 0x7ffff7dd1b88
0x7ffff7dd1ba0 <main_arena+128>: 0x7ffff7dd1b88 0x7ffff7dd1b98
0x7ffff7dd1bb0 <main_arena+144>: 0x7ffff7dd1b98 0x7ffff7dd1ba8
Consolidation
由于多次的释放和malloc会不可避免的出现很多小的chunk,这就有可能有两个连续的chunk虽然都是空闲的,但是由于是两个独立的chunk,在malloc使用的时候并不能将他们作为一个chunk返回,因此就会降低内存的使用效率,为了减少碎片,就需要在合适的时候将这些相邻的空闲块给合并成一个大的chunk。
合并的函数就是malloc_consolidate, 调用它的时候就会对空闲块进行合并,那么这个函数的调用条件有什么呢:
malloc large bin的时候,当需要很大的chunk的时候,就会调用这个函数先进行一次合并,看看会不会多出来一些可以用的chunk。
当top chunk中的空间不够用的时候
free函数之后,会对chunk进行前后合并,如果这个合并后的chunk size大于FASTBIN_CONSOLIDATION_THRESHOLD,也会调用一次
与堆利用相关的
我们前面先简单介绍了一下与堆相关的一些基本概念,虽然没有覆盖完全,但是与堆利用相关的已经基本列出,更加详细的认知需要在漏洞利用的过程中再去学习。
下面列出对漏洞利用的知识体系的基本框架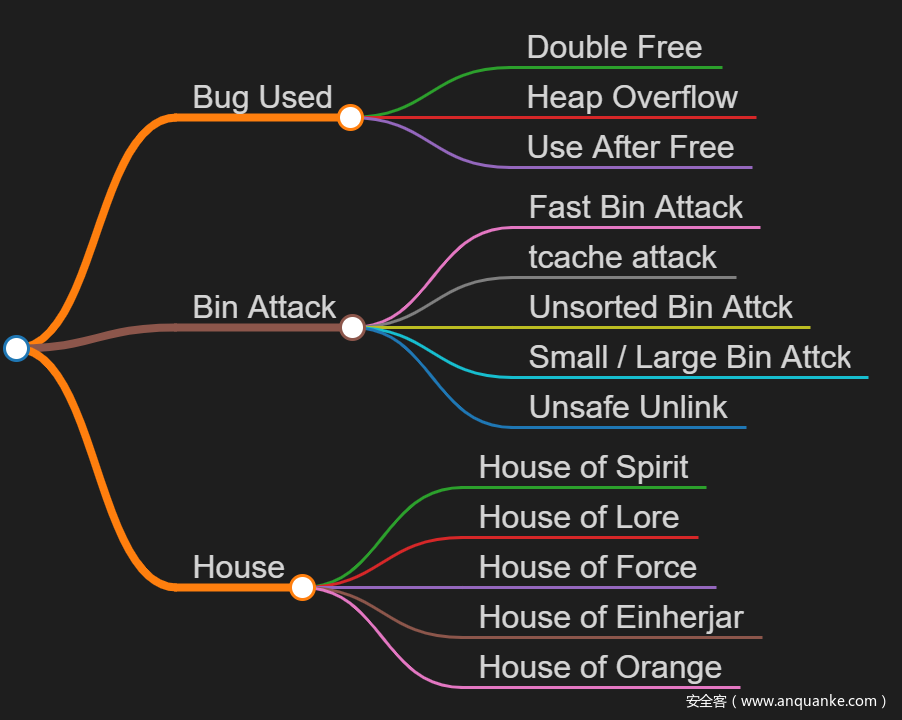
我们要想进行堆利用,就需要首先发现一个与堆相关的漏洞,UAF,堆溢出,double free这些,然后我们通过这个漏洞去修改一些chunk,这些chunk肯定是属于某个bin 链表或者tcache中,然后我们再借用house的各种方法去实现更复杂的利用方法。虽然还有很多方法没有列出,但是我们可以先掌握这些最基本的,这也是我在这个系列文章中要覆盖到的一些方法。
参考
1.https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/comment-page-1/
2.https://guyinatuxedo.github.io/25-heap/index.html?search=







发表评论
您还未登录,请先登录。
登录