

概述
笔者在去年夏天学习和分析CobaltStrike时编写了一篇yara入门的文章,算是填坑,在此文中记录下一些常见的编写思路。
PDB路径
PDB文件是在程序编译时产生的,它记录了程序的符号表,通过PDB,我们可以很方便对目标程序进行调试。
#程序编译时分为Private Build和Public Build。
#private build 表示开发人员在自己的电脑上进行coding和build,此时编译后的程序和pdb在相同的路径下。
#Public build 表示开发人员在公用的电脑上进行build,在这种情况下,还需一个symbol server以存储所有程序的pdb,当用户程序报错,debugger才能根据symbol server自动找到报错程序所对应的pdb,加载符号以方便程序员进行调试
pdb信息一定是和生成的程序同名的,若生成的程序名为: normal.exe 那么对应的pdb一定为: normal.pdb。
当调试器加载目标进程的pdb时,调试器首先会尝试查找与程序同名的pdb文件,若成功找到目标pdb,调试器则会检查嵌入到PDB和目标进程中的GUID是否匹配,匹配则成功加载,不匹配则加载失败。由于GUID计算时会使用时间因子,所以pdb和程序总是一一对应的。

还是以上面的简单代码为例,在加载pdb之后,可以最大程度的还原符号表,提升分析效率
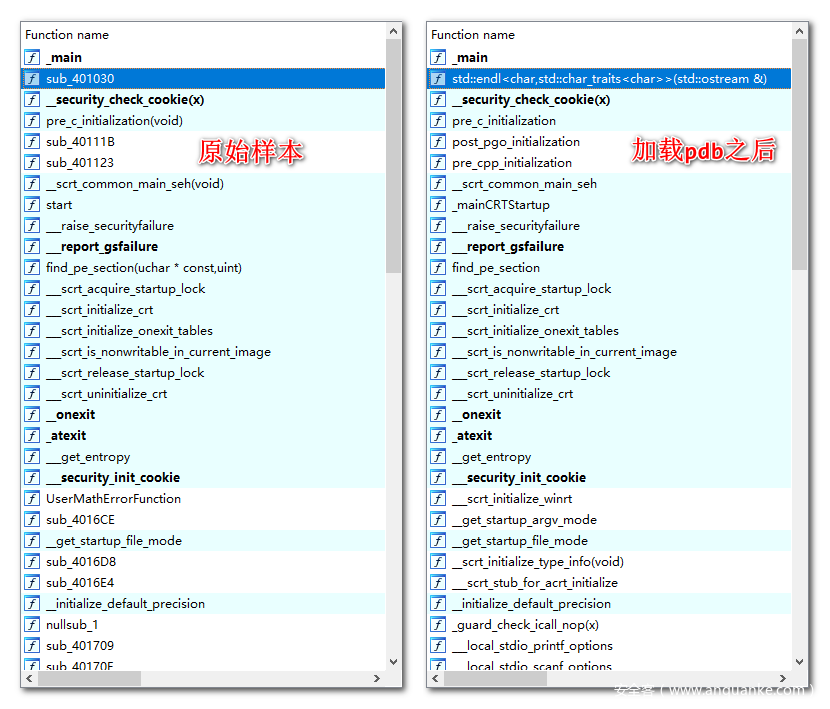
了解了pdb的作用和基本原理之后,下面来看看在样本查杀和hunting中pdb发挥的作用。
#需要稍微区分下hunting和查杀的区别
#通常在样本hunting时可以将特征写的宽泛一些,因为hunting的目的是尽可能的根据当前的信息去寻找更多的样本,在这种情况下,是允许误报并且可以由特征编写人员去人工判定误报的。
#而查杀,也就是恶意代码查杀方向,对特征的要求会比较高,通常不能接受误报,特征编写人员需要把握好查杀率和误报率之间的平衡。
一般来说,在分析中遇到的pdb信息有如下几类
1、普通pdb名,可完全匹配pdb,以pdb信息作为查杀条件。
2、以pdb路径中的部分信息作为过滤条件,快速过滤掉不相干样本。
3、无字面意义pdb,如文件名称为随机字符串,此类pdb最好不好选做特征,否则将会变成单杀特征。
4、带人名/盘符/路径/日期/等信息的有价值pdb,此类pdb有可能是攻击者不小心留下来的,价值较高。
5、误导性pdb,有的pdb信息不仅无用,还会误导分析人员。
普通pdb
以最近又异常活跃的Dridex为例,笔者在分析其中一个样本时发现样本中保留的pdb信息如下:

这里只是一个孤零零的pdb名称,并无路径信息,且此pdb名称并无实际意义,在vt上对此信息进行检索,能查到大批相关样本(从文件大小可以看出这些样本其实是相同的,可能只修改了极少的字节所以有了不同的md5,这里只是用它们举一个简单的例子)

关于Dridex相关的样本,MalawareBazaar上面倒是又不少,这里刚好可以借助其进行练习。笔者之前根据bazaar提供的API接口写了个简单的脚本用于批量查询样本并获取基本信息,效果如下

免费注册bazaar之后将会得到一个APIkey,将自己的APIkey填充到下面的脚本中即可,调用方式为:
python3 get_bazaar_samples_info.py <samples_tag> <limit>
比如要得到上面csv中的内容,输入
python3 get_bazaar_samples_info.py Dridex 10
import sys
import requests
import os
import json
import csv
import datetime
def getbaseinfo(tag,limit):
getdate = datetime.datetime.now().strftime('%Y-%m-%d')
csvFileName = getdate + "_" + tag + '.csv'
f = open(csvFileName,'w',newline='',encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['sha256_hash','md5_hash','first_seen','file_name','file_size','file_type','signature','tags','clamav'])
headers = {'API-KEY':'your API key'}
data = {
'query':'get_taginfo',
'tag':''+tag+'',
'limit':''+limit+''
}
response = requests.post('https://mb-api.abuse.ch/api/v1/', data=data,headers=headers)
json_response = json.loads(response.content)
samples_info = json_response['data']
for sample in samples_info:
hash256 = sample['sha256_hash']
md5 = sample['md5_hash']
first_seen = sample['first_seen']
file_name = sample['file_name']
file_size = sample['file_size']
file_type = sample['file_type']
signature = sample['signature']
tags = sample['tags']
intelligence = sample['intelligence']
if 'clamav' in intelligence.keys():
clamav = intelligence['clamav']
else:
clamav = ""
csv_writer.writerow([hash256,md5,first_seen,file_name,file_size,file_type,signature,tags,clamav])
f.close()
# print(json_response['data'][0]['md5_hash'])
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Usage: python3 get_bazaar_samples_info.py <samples_tag> <limit>")
quit()
tag = sys.argv[1]
limit = sys.argv[2]
getbaseinfo(tag,limit)
同样的,也可以根据bazaar提供的API接口完善脚本,实现查询之后自动从bazaar上下载样本并解压到本地。
样本下载回来之后,按照大小排序,可以看到一共有三类样本,分别是162kb大小、160kb大小和159kb大小。三类样本对应的pdb信息分别是 Gsp.pdb、fffp4.pdb、Gsp.pdb
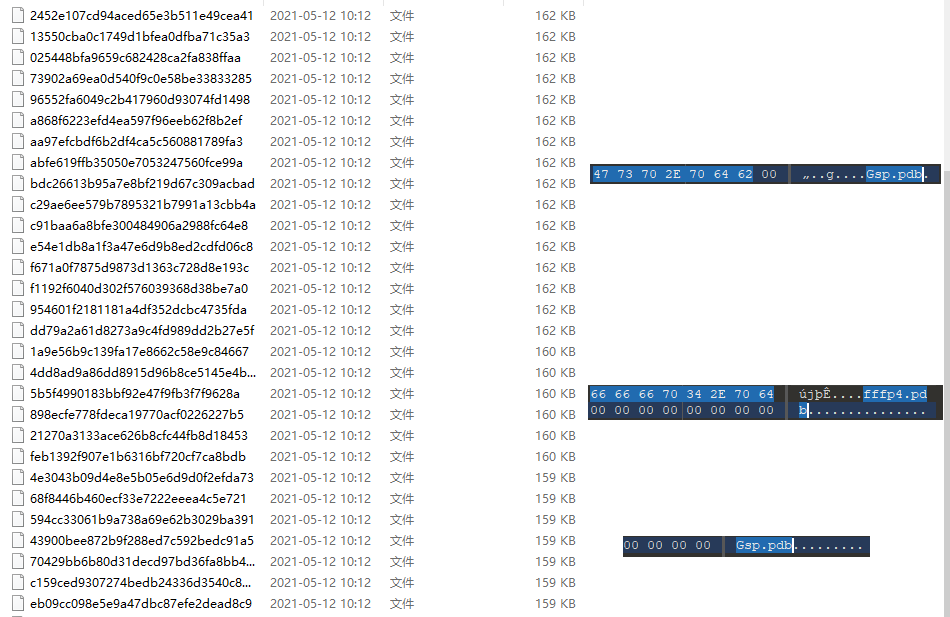
此时,光通过fffp4.pdb这个信息已经不足以匹配完我们视野范围内的Dridex样本了,这也是光以pdb信息作为特征点的一个局限性:通用性较差,很有可能查不了代码没怎么改变的变种样本。
通过pdb过滤
上面样本遇到的fffp4.pdb,通过google引擎检索之后只有6条相关结果,且出来的结果都是沙箱相关的检测报告,点进去发现对应的样本的确是属于Dridex的恶意样本,因此可以考虑以fffp4.pdb作为一条特征。

但是更多的时候,我们可能在样本中会遇到名字普普通通的pdb名称,此时再用pdb作为特征就明显不合适。以ebb83160e97ea11f46057a92f16e37ec样本为例,该样本所包含的pdb名称为debug.pdb

debug.pdb这个名字较为常见,此时若是以该名字作为特征明显不合适,但是这里可以注意到,一般情况下,正常程序的pdb信息是完整路径,而不是像这个样本中孤零零的一个文件名。所以正常程序的debug.pdb前面应该是路径中的斜杠而不是00,因此可以加上00在vt上进行connect搜索:

搜索结果返回回来全是恶意程序,但这并不意味着可以直接以这段hex作为特征,我们将搜索结果限制在报毒数小于10可以看到就出现了一些白样本

因此,此类pdb可以作为一个筛选过滤条件。
再来看看另一批样本,原始样本中的pdb信息如下

在只有一个样本或是一批相同样本的情况下比较难利用此pdb信息做文章,笔者在分析和关联之后,定位到了同源,但是拥有不同pdb的样本,信息如下
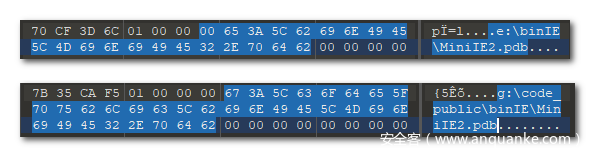
经过简单的关联分析之后,很快可以得到结论,该家族的样本binIE\MiniIE2.pdb 的信息不会变,前面的盘符和code_路径有可能改变,但若只匹配binIE\MiniIE2.pdb 还是有一定几率的误报,所以可以以该段hex数据作为过滤条件,加上部分的实际代码抑制误报。
无意义pdb
严格意义上来讲,上面提到的fffp4.pdb也算是无意义pdb,因为将该pdb信息写成yara特征,扫描回来的样本必然是大同小异的,或者说代码段几乎完全相同,在这种情况下,看似是pdb信息起了作用,实际上随便取一段代码的opcode做特征效果也一样。
还有一种笔者认为的无意义pdb是随机字符串pdb,如下所示:

此类pdb没有路径等信息,基本上只会出现一次,就算通过该信息关联到了样本,情况和上面的fffp4.pdb也大致相同。
高价值pdb
“高价值”pdb信息通常出现在高级威胁追踪与分析中。
以BITTER为例,部分样本残留了pdb信息:
C:\Users\ARAGON\Documents\Visual Studio 2008\Projects\DownWin32\Release\DownWin32.pdb
C:\Users\UserA\Documents\Visual Studio 2008\Projects\Artra\Release\Artra.pdb

虽然此类样本pdb信息不相同,代码也相差甚远,但是pdb的命名风格却较为相似。
C:\Users{UserName}\Documents\Visual Studio 2008\Projects{demoName}\Release{DemoName}.pdb
从上面两个样本来看,可变部分是上面橙色标记的几个值,但是这里不妨猜测,Visual Studio的版本后面也会变,所以可以编写一条正则特征,用于检测包含了下面这种模式pdb的样本
C:\Users{UserName}\Documents\Visual Studio {2008}\Projects{demoName}\Release{DemoName}.pdb
后面的样本也能佐证这条特征的合理性:

继续分析,还能看到有的样本中加入了时间因子,这里的28Nov应该是表示11月28,我们可以对比分析作者信息不相同的样本,慢慢找到BITTER中不同人员的分工,以及他们的共用代码。

错误pdb
一个典型的错误pdb是msf框架所生成的meterpreter的payload。
#常见的msf马有两种
#一类是patch入口点,创建线程执行shell code之后跳转到原始的入口点继续执行。
#一类是将入口点完全替换为msf的shellcode,此类样本会直接通过多个跳转动态解密执行。
msf默认生成的meterpreter样本尾部有一个pdb路径叫做:C:\local0\asf\release\build-2.2.14\support\Release\ab.pdb
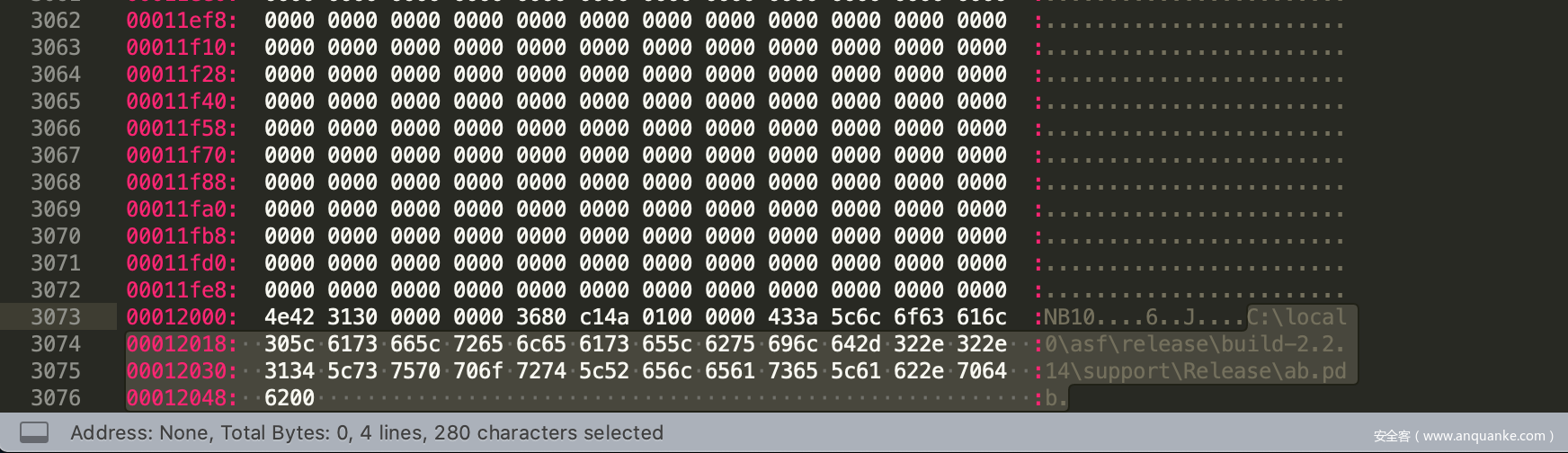
这里的pdb其实不是msf自身的pdb,而是Apache提供的性能检测工具ab.exe的pdb信息。
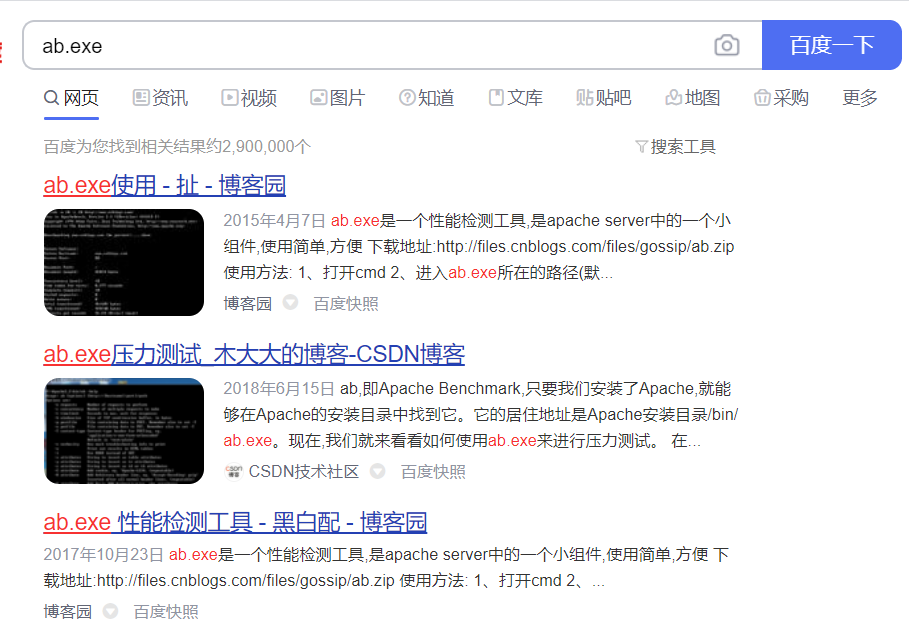
patch ab.exe是msf的常见手法,通常来说,msf生成的meterpreter还会保留ab.exe的版本信息,笔者暂未阅读过msf的源码,所以猜测起初可能是为了增加样本的免杀性,但是目前在免杀方面已经没什么效果,可能可以迷惑一下初级的样本分析人员
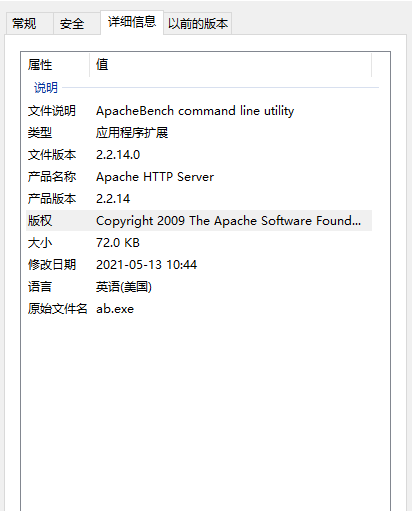
虽然这里的pdb路径不在正常的位置的,IDA载入文件时也不会提醒加载pdb,但是yara作为全文扫的引擎,不能指定pdb出现的位置,为了避免误报,所以不能取这样的pdb作为特征。
关于PDB,暂时说这么多,总的来说,样本中残留的pdb信息有时可以比较好的帮助我们完成溯源、关联等工作。但是不适合作为特征,可以在yara中作为一个可选条件。
互斥体
和pdb一样,互斥体大多数时候并不能直接作为查杀特征甚至是hunting特征,只是在深入分析某个组织,构建TTPS时可以起到一定的作用。
大多数恶意软件感染计算机之后会通过计划任务、开机启动注册表、启动项等方式实现本地持久化,但是像计划任务启动这种方式有可能会倒是程序多开,过多的进程名可能会引起用户或运维人员的注意,为了避免此类情况,攻击者有时候会创建互斥体以保证样本在主机上只有一个实例运行。
恶意软件常见的互斥体有以下几类
1、获取当前的计算机基本信息计算出一个ID,以该ID作为互斥体名
2、硬编码在代码中的互斥体名,如程序名、C2地址、地名、小说人物名、随机乱码名
3、仿冒正常程序的互斥体名。
互斥体取名相对来说比较”困难”,为了避免不同版本的恶意软件感染同一个主机并在主机上同时运行,攻击者通常需要选用多个版本同时适用的互斥体名。
比较直接的做法是获取用户主机的计算机名、用户名等信息通过固定的算法生成一个ID用于标识受害者主机,这个ID可以作为互斥体名,同时也可以作为请求头中的id,发送上线标识包。
还有一个简单的做法是以请求域名作为互斥体名称,这样可以保证,与同一个C2通信的样本不会重复运行。
不过大部分的恶意软件开发者会选择实用随机字符串作为互斥体名,这可能是他们没有考虑版本更新方面的问题,也有可能是有意为之。
随机字符串
以Clop勒索软件为例(7edc821c3b46e85f262a96182ed2de86),样本运行后会在线程中创建名为
FSKJHFOJKW#^^^66^6
的互斥体,经过搜索引擎和VT可得知该互斥体名为随机生成,并无实际意义,所以不能作为样本特征。
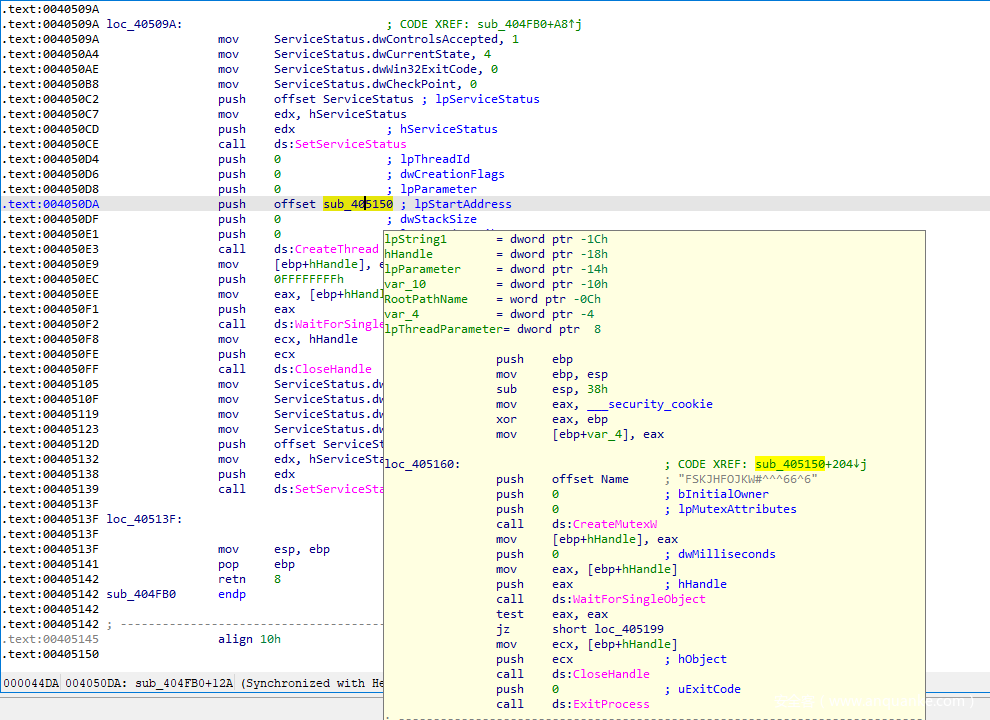
以Clipper家族的样本为例,同一批样本,代码结构很相似,但是创建的互斥体名也是不同的,这里的互斥体名也是通过随机字符生成,不能作为特征点或是关联分析的关键点。

请求域名
以05690a450fea902744c9f7560a999267样本为例,样本运行后,会创建名为
qq2009.3322.org
的互斥体名

通过VT也可以看到,的确有很多样本请求了该域名

因此,类似于这种以域名作为互斥体名的样本,是可以考虑直接以互斥体名(域名)作为特征的,但是这个特征说是查互斥体名,其实也是查域名,通用性相对来说也较差。
伪装
在上面讲pdb的时候讲到了有的恶意软件会伪装正常软件的pdb信息以迷惑用户,互斥体也不例外。
以e6fcdc19924db03a6c2c026c7992344b样本为例,样本运行后会创建名为chromiumUndate的互斥体名。
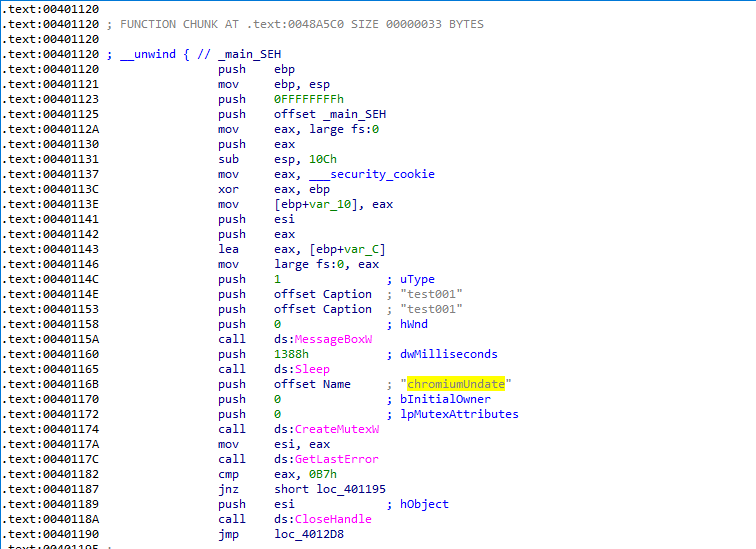
这里的互斥体名很明显是仿冒了Chromium更新程序名,此外,攻击者还仿冒了Chromium的版本信息

并且特意保留了仿冒Chromium的pdb信息,希望通过这三层信息迷惑用户或是迷惑初级分析人员

此类样本的特征是相对危险的,在提取时需要格外注意。
计算生成
通过收集本地主机信息计算ID作为互斥体名的一般是高级威胁所涉及的样本。
这里又会分为两类
1、 直接在样本中获取指定信息,计算,然后生成互斥体名。
2、 上一阶段的样本获取信息并计算ID传入到C2,C2根据此ID生成对应的样本。
通过这种方式,较难根据互斥体名进行溯源或是主动关联其他样本,但是我们可以收集和记录,在遇到该家族其他样本时进行被动关联。
关于此类互斥体名,已经脱离了静态特征的范畴,在此节中不进行深入讨论







发表评论
您还未登录,请先登录。
登录