

参考链接
https://www.pediy.com/kssd/pediy12/142371.html
https://www.bilibili.com/video/BV1tJ411M7kd
微软文档 查询 https://docs.microsoft.com/en-us/cpp/build/exception-handling-x64?view=msvc-160
感谢周壑老师和boxcounter。
环境
VS2019
idapro7.5
正文
在PE+的结构中,异常处理的信息存储在ExceptionDirectory中,且每个字段都是3*4=12字节。
typedef struct _RUNTIME_FUNCTION {
ULONG BeginAddress;
ULONG EndAddress;
ULONG UnwindData;
} RUNTIME_FUNCTION, *PRUNTIME_FUNCTION;

了解SEH的习惯,x64 SEH 不基于栈,不发生异常和通常执行没有区别(效率高),每个非叶函数至少对应一个 RUNTIME FUCNTION结构体叶函数如果使用了SEH, 也会对应 RUNTIME FUCNTION结构体。
既不调用函数、又没有修改栈指针,也没有使用 SEH 的函数就叫做“叶函数”。
代码演示
使用代码
#include<stdio.h>
#include<stdlib.h>
#include<Windows.h>
int filter() {
printf("filter\n");
return 1;
}
void exc() {
int x = 0;
int y = x / x;
}
int main() {
__try {
__try {
exc();
}
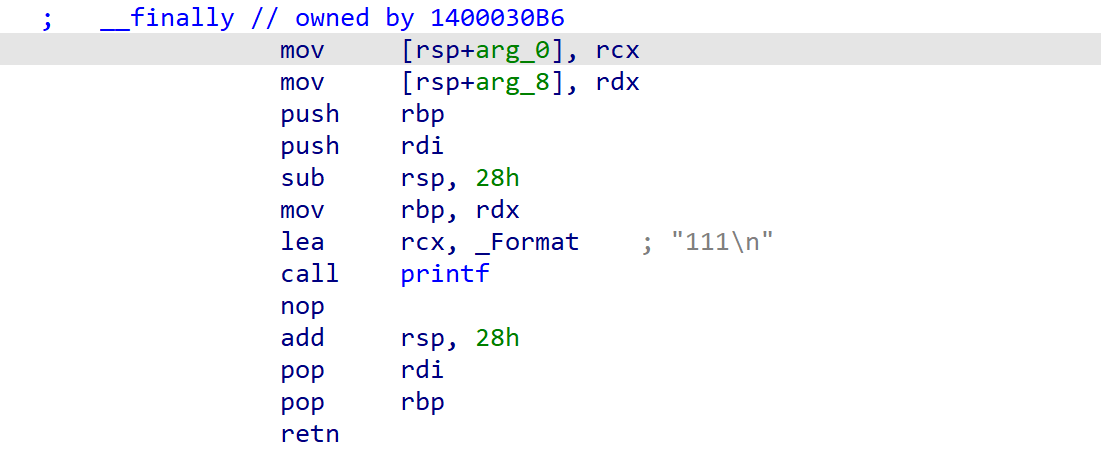
__finally {
printf("111\n");
}
}
__except (filter()) {
printf("222\n");
}
system("pause");
return 0;
}
通过除零异常,进行异常处理流程的学习。根据执行结果可看到,在exc()异常(EXCEPT_POINT )后,首先执行filter函数(EXCEPT_FILTER ),然后执行finally函数(FINALLY_HANDLER ),再执行except中的异常处理函数(EXCEPT_HANDLER )。 这是基础的执行流程。

然后在IDA中进行分析,找到main函数的引用,指向pdata段的一个RUNTIME_FUNCTION结构体,RUNTIME_FUNCTION里面存储的地址都是基于BaseAddress的32位RVA。依次是BeginAddress 就是函数开始地址,EndAddress也就是结束的地址,UnwindData是指向_UNWIND_INFO的地址。这个结构体表明了该异常处理的范围和异常处理回滚(unwind)所需要的信息。

_UNWIND_INFO是用来记录一个函数上堆栈指针的操作,以及非易失性寄存器保存在堆栈上的位置。(除了rcx,rdx,r8,r9,r10,r11为易失寄存器,其他都是非易失寄存器,使用前push进行保存,使用后pop进行恢复)。
typedef enum _UNWIND_OP_CODES {
UWOP_PUSH_NONVOL = 0, /* info == register number */
UWOP_ALLOC_LARGE, /* no info, alloc size in next 2 slots */
UWOP_ALLOC_SMALL, /* info == size of allocation / 8 - 1 */
UWOP_SET_FPREG, /* no info, FP = RSP + UNWIND_INFO.FPRegOffset*16 */
UWOP_SAVE_NONVOL, /* info == register number, offset in next slot */
UWOP_SAVE_NONVOL_FAR, /* info == register number, offset in next 2 slots */
UWOP_SAVE_XMM128 = 8, /* info == XMM reg number, offset in next slot */
UWOP_SAVE_XMM128_FAR, /* info == XMM reg number, offset in next 2 slots */
UWOP_PUSH_MACHFRAME /* info == 0: no error-code, 1: error-code */
} UNWIND_CODE_OPS;
typedef union _UNWIND_CODE {
struct {
UBYTE CodeOffset;
UBYTE UnwindOp : 4;
UBYTE OpInfo : 4;
};
USHORT FrameOffset;
} UNWIND_CODE, *PUNWIND_CODE;
#define UNW_FLAG_NHANDLER 0x0
#define UNW_FLAG_EHANDLER 0x01
#define UNW_FLAG_UHANDLER 0x02
#define UNW_FLAG_CHAININFO 0x04
typedef struct _UNWIND_INFO {
UBYTE Version : 3;
UBYTE Flags : 5;
UBYTE SizeOfProlog;
UBYTE CountOfCodes;
UBYTE FrameRegister : 4;
UBYTE FrameOffset : 4;
UNWIND_CODE UnwindCode[1];
/* UNWIND_CODE MoreUnwindCode[((CountOfCodes + 1) & ~1) - 1];
* union {
* OPTIONAL ULONG ExceptionHandler;
* OPTIONAL ULONG FunctionEntry;
* };
* OPTIONAL ULONG ExceptionData[]; */
} UNWIND_INFO, *PUNWIND_INFO;
typedef struct _SCOPE_TABLE {
ULONG Count;
struct
{
ULONG BeginAddress;
ULONG EndAddress;
ULONG HandlerAddress;
ULONG JumpTarget;
} ScopeRecord[1];
} SCOPE_TABLE, *PSCOPE_TABLE;
手把手解析_UNWIND_INFO结构体

结构体后面的冒号表示使用多少位,例如 Version+Flags一共使用8位,也就是1字节。
第0行
代表着结构数据有Version + Flags,SizeOfProlog,CountOfCodes,FrameRegister+FrameOffset。
0x19h = 0y00010011
Version= 0y011 = 3
Flags = 0y00010 = 2
根据数值找到对应的flag。
UNW_FLAG_NHANDLER 0x0 不对异常进行处理
UNW_FLAG_EHANDLER 0x01 使用Except函数进行处理。
UNW_FLAG_UHANDLER 0x02 使用finally函数处理。
UNW_FLAG_CHAININFO 0x04 使用调用链。
SizeOfProlog
函数头的大小。比较产生异常的相对函数头的大小与该值,判断回滚操作。函数头大小为6字节。
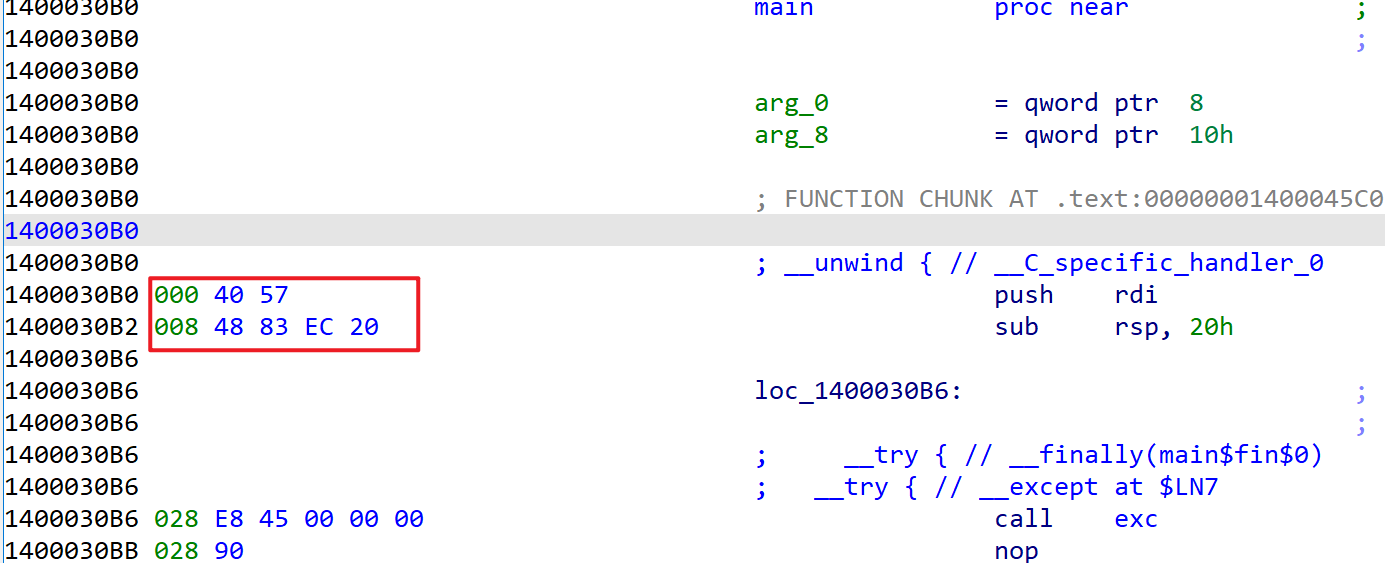
如果大于该值,则两个UNWIND_CODE都执行。如果小于该值,则通过UNWIND_CODE的CodeOffset进一步判断。CodeOffset小于相对数值则会进行该UNWIND_CODE的回滚。
下面UWIND_CODE的数量。2个。
根据FP进行相关操作。
第一行
UWIND_CODE用于记录函数头中有关非易失性寄存器和RSP的操作。

解析第一个,<6,32h>.
在距离便宜头部6字节及以内的地方异常,都会执行该操作。
32h = 0y00100011
UnwindOp = 2 //UWOP_ALLOC_SMALL

OpInfo = 3
所以创建了3*8+8 = 0n32= 0x24 所以记录了创建栈空间0x24字节,回滚时则需要释放32字节空间。
然而IDA已经标注了OPCODE,所以能很方便的进行判断。
第二个则是记录了压入 RDI。
0x70 = 0y01110000
UnwindOp = 0y0000 = 0n0
OpInfo = 0y0111 = 0n7
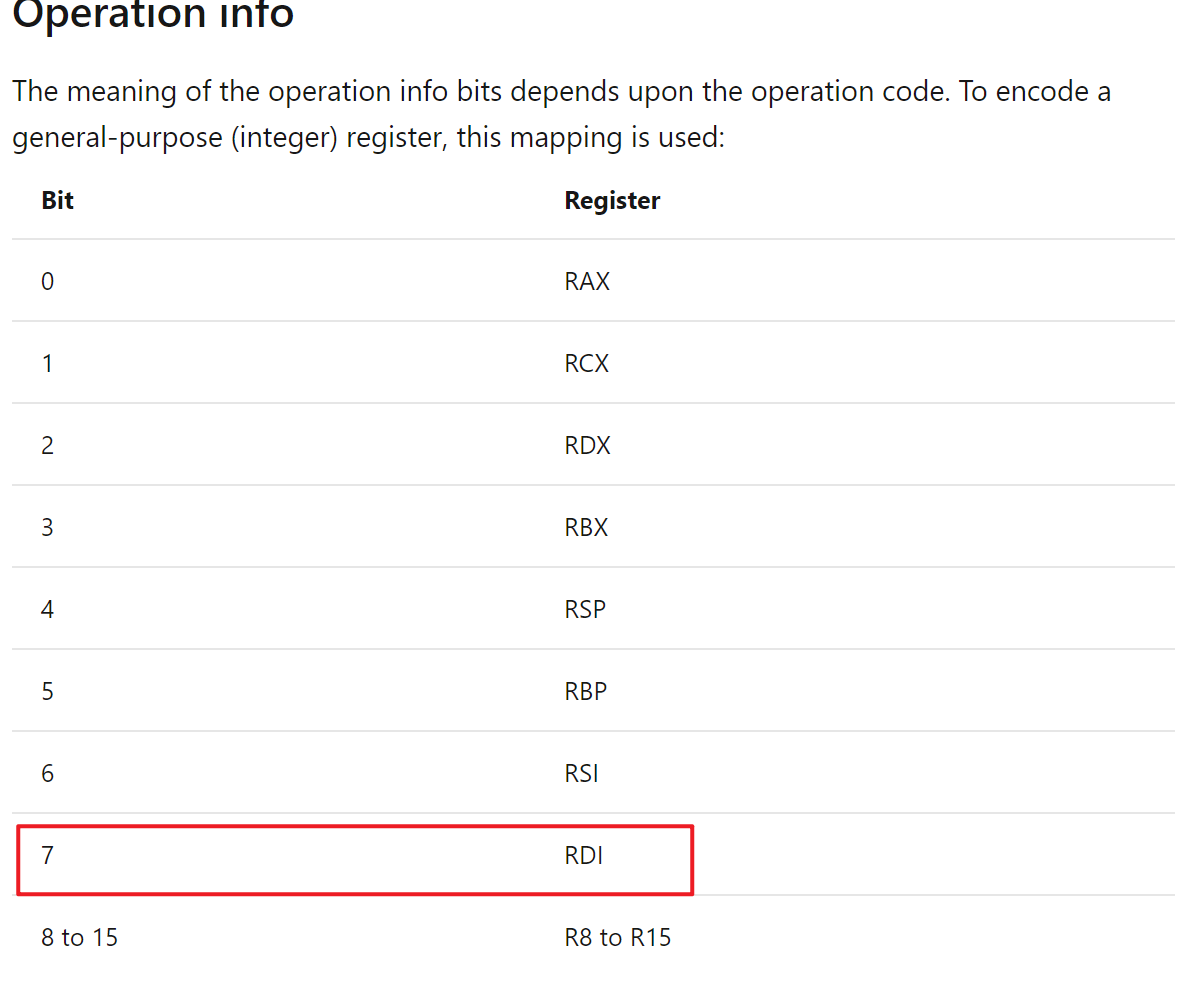
第三行
_C_specific_handler_0 是一个导入函数,是进行异常处理分发的,可以不用分析。
第四行
第四行解析_SCOPE_TABLE结构体。

有2组ScopeRecord。
引用boxcounter:
- Count 表示 ScopeRecord 数组的大小。
- ScopeRecord 等同于 x86 中的 scopetable_entry 成员。其中,
- BeginAddress 和 EndAddress 表示某个 __try 保护域的范围。
- HandlerAddress 和 JumpTarget 表示 EXCEPTION_FILTER、EXCEPT_HANDLER 和 FINALLY_HANDLER。具体对应情况为:
- 对于 try/except 组合,HandlerAddress 代表 EXCEPT_FILTER,JumpTarget 代表 EXCEPT_HANDLER。
- 对于 try/finally 组合,HandlerAddress 代表 FINALLY_HANDLER,JumpTarget 等于 0。
这四个域通常都是 RVA,但当 EXCEPT_FILTER 简单地返回或等于 EXCEPTION_EXECUTE_HANDLER 时,HandlerAddress 可能直接等于 EXCEPTION_EXECUTE_HANDLER,而不再是一个 RVA。
所以第一排指向Finally函数。
第二排指向filter和Except函数。
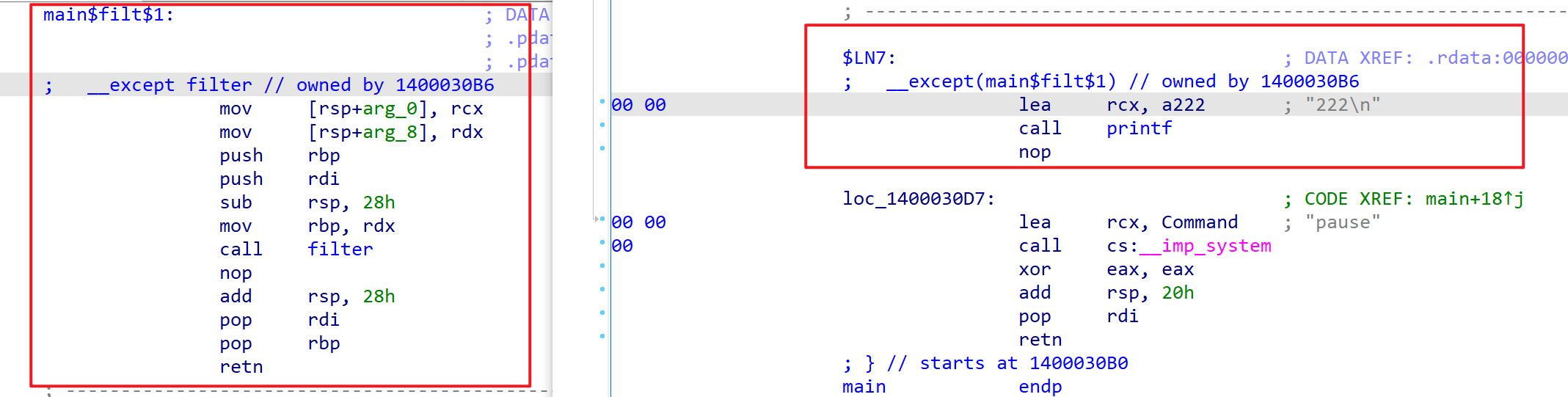
这时候看注释就明白很多。
当Flags为UNW_FLAG_CHAININFO

0x21 = 0y00100001
Flags = 0y00100=4,会看到末尾指向了一个_RUNTIME_FUNCTION,形成了链式结构,继续进行回滚判断。类似子函数对引用母函数的回滚。
进行异常回滚模拟
如果是在exc()函数中异常,首先查看自身函数的 RUNTIME_FUNCTION,找到UNWIND_INFO,进行回滚判断并操作。

1. 恢复栈空间0x10字节 add rsp,0x10h
2. pop rdi
然后根据栈查看调用者,再查看RUNTIME_FUNCTION找到UNWIND_INFO。这里也就是main的UNWIND_INFO。判断FLAGS为,00010为2,UNW_FLAG_UHANDLER 。

由于调用exc()函数实在六字节外,所以进行回滚。
3. add rsp,0x20h
4. pop rdi
然后交给_C_specific_handler_0,
判断异常相对于_SCOPE_TABLE字段的位置,都在内部。则两个都要执行。
由于第一个是JmpTarget是0,所以是finally,在此处进行记录。直到找到filter接管后,再执行。
然后第二个SCOPE_TABLE:
5. 执行EXCEPT_FILTER
6. FINALLY_HANDLER
7. EXCEPT_HANDLER
8. 顺序执行到system("pause")

总结
分析好后,就能更好地去理解IDA的注释了,读懂注释了。
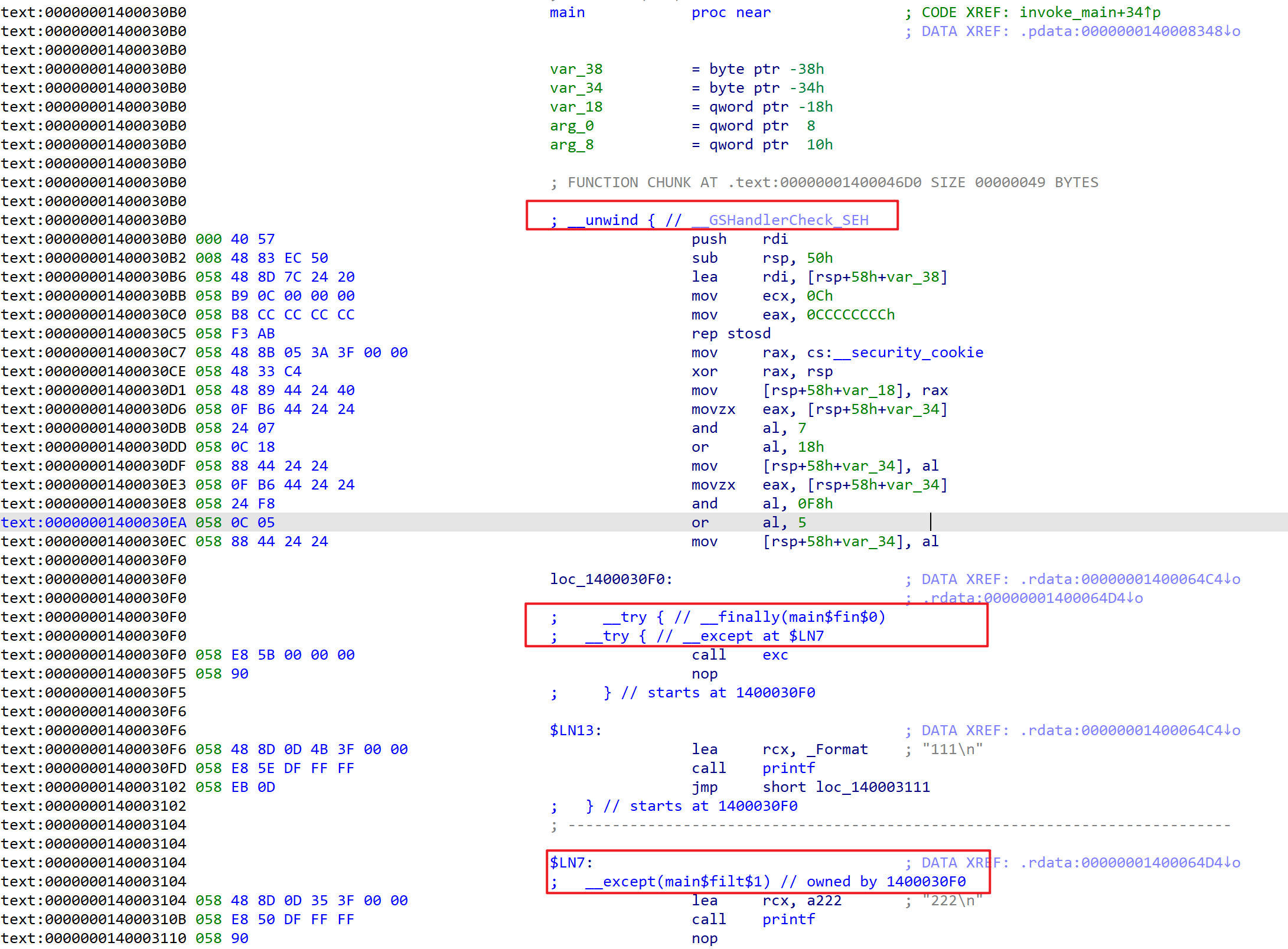
异常处理函数反向查找引用函数
通过最后的引用的RVA,进行搜索,最终定位到C_SCOPE_TABLE,找到UWIND_INFO结构体,然后找到其引用RUNTIME_FUNCTION,定位到调用者函数。
以filter为例,定位到调用者,假设看不到其引用。我们进行搜索。

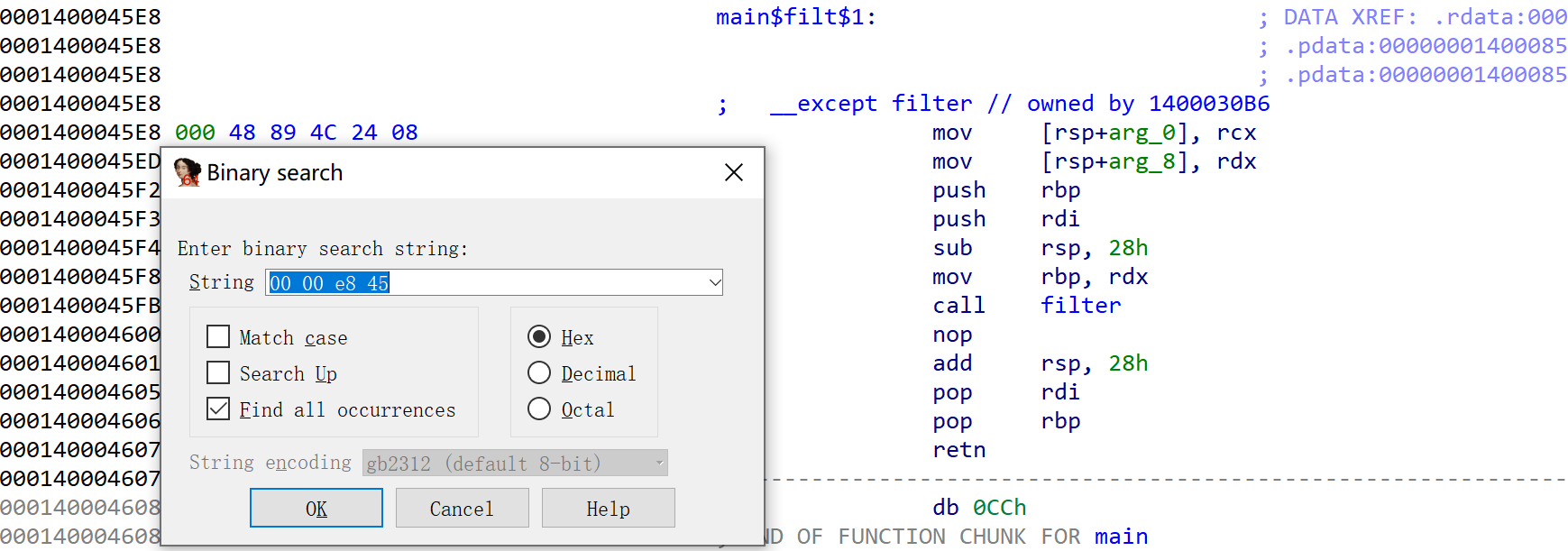
定位到疑似结构体。

然后就能找到引用该异常处理的函数部分。

万一有用?
文档中获取特定信息的宏。
#define GetUnwindCodeEntry(info, index) \
((info)->UnwindCode[index])
#define GetLanguageSpecificDataPtr(info) \
((PVOID)&GetUnwindCodeEntry((info),((info)->CountOfCodes + 1) & ~1))
#define GetExceptionHandler(base, info) \
((PEXCEPTION_HANDLER)((base) + *(PULONG)GetLanguageSpecificDataPtr(info)))
#define GetChainedFunctionEntry(base, info) \
((PRUNTIME_FUNCTION)((base) + *(PULONG)GetLanguageSpecificDataPtr(info)))
#define GetExceptionDataPtr(info) \
((PVOID)((PULONG)GetLanguageSpecificData(info) + 1)







发表评论
您还未登录,请先登录。
登录