

尽管它们的 DRAM 内目标行刷新 (TRR,Target Row Refresh) 缓解,一些最新的 DDR4 模块仍然容易受到多行 Rowhammer 位翻转的影响。 虽然这些位翻转可以从本机代码中利用,但在浏览器中从 JavaScript 触发它们面临三个重大挑战。鉴于 JavaScript 中缺少缓存刷新指令,现有的基于驱逐(eviction-based)的 Rowhammer 攻击对于较旧的单行(single-sided)或双行(double-sided)变体来说已经很慢,因此并不总是有效。 使用多行Rowhammer,发起有效攻击更具挑战性,因为它需要从 CPU 缓存中驱逐许多不同的攻击者地址,最有效的多行(n-side)需要大量物理连续的内存区域,这在 JavaScript 中是不可用的。
本文克服了这些挑战,构建了SMASH(Synchronized MAny-Sided Hammering),这是一种在现代 DDR4 系统上从 JavaScript 成功触发 Rowhammer 位翻转的技术。 为了发起有效的攻击,SMASH 利用缓存替换策略的高级知识为基于驱逐的多行Rowhammer 生成最佳访问模式。 为了取消对大型物理连续内存区域的要求,SMASH 将n行 Rowhammer 分解为多个双行对,使用切片着色来识别它们。 最后,为了绕过 DRAM TRR 缓解措施,SMASH 仔细安排缓存命中和未命中,以成功触发同步的多行 Rowhammer 位翻转。 本研究展示了具有端到端 JavaScript 漏洞的 SMASH,该漏洞平均可以在 15 分钟内完全破坏 Firefox 浏览器。
0x01 Introduction
在本文中展示了在现实假设下,确实可以直接从 JavaScript 绕过 TRR,从而允许攻击者利用浏览器中重新出现的 Rowhammer 漏洞。此外,分析揭示了实际规避 TRR 的新要求。例如,TRRespass所示快速连续激活多行可能并不总是足以产生位翻转。 DRAM 访问的调度也起着重要作用。
目标行刷新:2014 年 Rowhammer 漏洞的发现 导致了一种全新的攻击类别,这些攻击都利用了该漏洞:跨越安全边界的位翻转。特别是研究人员已经证明了对浏览器、虚拟机、服务器和移动系统的实际攻击,这些攻击从本机代码、JavaScript 甚至网络发起 。除了这些内存损坏攻击之外,Rowhammer 还可以作为泄漏信息的侧信道。
为应对锤击,制造商使用 in-DRAM TRR 增强了 DDR4 芯片,这是一种 Rowhammer “修复”,可监控 DRAM 访问以减轻类似 Rowhammer 的活动。 TRR 由两部分组成:sampler和inhibitor。sampler负责对内存请求进行采样,以在它们造成危害之前检测潜在的 Rowhammer 诱导序列。inhibitor试图通过主动刷新受害者行来避免攻击。不幸的是,最近TRRespass表明缓解是不够的,可以通过从双行移动到多行 Rowhammer 来绕过,即根据特定的 TRR 实现,不仅激活两行,而且最多激活 19 行。
问题的症结在于内存芯片的sampler。一个可靠的sampler会采集足够的样本来为inhibitor提供足够准确的信息,以便在 Rowhammer 攻击的情况下刷新所有必要的受害者行。不幸的是,常见的sampler实现监视有限数量的攻击者,并且总是在同一时间 ,隐含地依赖于内存请求将以不协调、混乱的方式到达的假设。然而,如果通过大的物理连续内存区域精确控制要锤击的行,并通过显式缓存刷新(使用 CLFLUSH 指令)积极锤击多行,多行 Rowhammer 可以压倒sampler并触发位翻转,即使在启用 TRR 的 DRAM。
从 JavaScript 绕过 TRR:虽然本机代码 Rowhammer 在现代 DDR4 系统上的复活确实很严重,尤其是在云和类似环境中,但它不会立即影响暴露于 JavaScript 攻击的 Web 用户。在没有 CLFLUSH 和对物理连续内存的控制的情况下,如果没有新的发现,就不可能通过缓存逐出以足够高的速度诱导位翻转同时绕过 DRAM TRR 来控制大量行.请注意,与双行 Rowhammer 相比,多行 Rowhammer 模式加剧了这些挑战,因为它们需要更多的物理连续内存和更多的驱逐。
0x02 Threat Model
假设攻击者控制了受害者访问的恶意网站(或良性网站上的恶意广告)。 攻击者不依赖任何软件漏洞,而仅利用 JavaScript 沙箱内触发的 Rowhammer 位翻转来控制受害者的浏览器。 假设受害者的系统部署了针对 Rowhammer 和侧信道攻击的所有最先进的缓解措施,即现代 DRAM 内 Rowhammer 缓解措施和针对微架构攻击的浏览器缓解措施,包括low-resolution、jittery timers 和针对推测执行攻击的缓解措施。SMASH 依赖透明大页内存(THP,transparent huge page) 来制定其访问模式。 有关Linux 发行版上默认 THP 设置的概述,见下表。

0x03 Rowhammering DDR4 in the Browser
从 JavaScript 内部执行 Rowhammer 攻击从来都不是一件小事。 攻击者需要找到一种方法来从缓存中刷新攻击者,而不依赖于缓存刷新指令。 JavaScript 中缺乏内存寻址信息使此类攻击进一步复杂化。 DRAM 内 TRR 缓解的竞争对手只会加剧此类挑战。 由于缓解,普通的双行 Rowhammer 将不再足够。 要攻击启用 TRR 的 DDR4,攻击者需要多方面的访问模式。
挑战1:要构建多行访问模式,攻击者需要大量的物理内存,这在JavaScript中很难获得。
多行模式由许多相邻的行组成。由于DRAM行地址是由高物理地址位决定的,收集相邻行需要相对大量的物理内存。如后所示,SMASH 通过应用有关多行 Rowhammer 的新见解来应对这一挑战,这允许它收集所需的攻击者或地址,而无需大量连续的物理内存块。
攻击者面临的下一个障碍是:如何确保每个内存访问都进入 DRAM(而不是其中一个缓存)?攻击者可以尝试采用已知的解决方案,例如 Rowhammer.js提出的技术。这些方法使用驱逐集来创建 CLFLUSH 自由访问模式。
挑战2:攻击者需要找到一种策略,生成能够有效地执行多行漫游器的模式,而不会引入太多额外的缓存命中。
如下所示,SMASH 通过设计最佳访问模式来解决这一挑战,以确保所有缓存未命中都落在攻击者行上并有助于锤击。
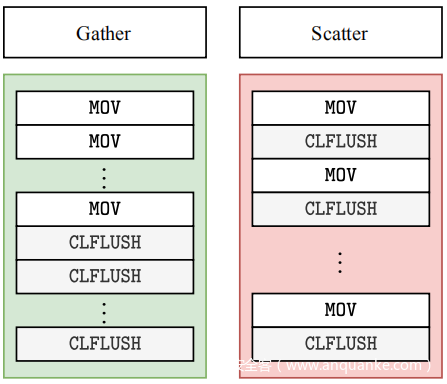
所做的下一个重要观察是关于缓存命中和缓存未命中的顺序。普遍的看法是,只要在给定的时间内向内存发送了足够多的请求,就有可能触发 Rowhammer 位翻转。上图中总结的另一个实验表明,这不适用于具有 in-DRAM TRR 的 DDR4 设备。在一种情况下,为 18行模式批量发送 18 个内存请求,然后是从缓存中刷新攻击者的 CLFLUSH 指令。确认此模式会触发位翻转,但是如果将 CLFLUSH 指令与对攻击者行的内存请求交错,尽管在给定时间段内发送了相同数量的请求,也无法再触发位翻转。正如稍后展示的,这是由于 TRR 缓解的特性。
挑战3:攻击者必须仔细安排缓存命中顺序,才能成功绕过DRAMTRR缓解。
如下所示,SMASH 通过将 DRAM 访问与 TRR 缓解同步来解决这一挑战。
0x04 Minimal Rowhammer Pattern
TRRespass 需要比现代操作系统提供的更大的连续内存分配,以控制每个攻击者的位置。这是物理内存和 DRAM 地址之间映射的结果——以及操作系统向用户空间应用程序提供物理内存范围的方式(参见下图)。例如,为了构建一个 19 行的模式,TRRespass 发现该模式对本文的一个测试有效,攻击者需要 2^(17+log2^37) = 4.63MB 的连续物理因为 DRAM 行地址从高阶物理地址位 17 开始,总共需要 2 · 19-1 = 37 行,包括受害者行,以形成 19行模式。从 JavaScript 沙箱的受限环境中获取此类分配并非易事。

JavaScript 中的连续内存:为了从 JavaScript 中获得对 DRAM 行地址的控制,先前的工作依赖于两种技术来获得连续分配:(i) 2 MB 透明大页 (THP) 或 (ii) massaging buddy allocator以获得高阶分配(最大 4 MB)。这两种技术都不允许获得执行 19行Rowhammer 所需的 4.63 MB 连续物理内存。
放宽限制:在最初的一项实验中,试图了解在尝试绕过 DRAM TRR 时行位置的影响。从辅助双行模式开(即由任意行“护送”的双行对)。本研究实现了它的概括:N-辅助双行。即,单个双行对伴随着 N 个虚拟行的模式。这意味着 19行模式变为双行模式,N = 19-2 = 17 个傀儡。在特定的 DIMM 上,这些傀儡的位置很重要,在测实验中,没有观察到同一组内任意位置傀儡行的翻转次数有任何明显差异。这意味着攻击者只需要形成一个双行对和 N 个虚拟行映射到同一个存储体——将展示一个更容易满足的要求。
最小可行分配:DRAM 行地址由应用于物理地址的线性函数的结果决定。这些函数只是将高位物理地址位映射到行地址(见上图)。由于 N 辅助双行的发现,现在只需要控制三个相邻的 DRAM 行:两个侵略者行和中间的受害者行。换句话说,只需要控制 DRAM 行地址的两个 LSB。
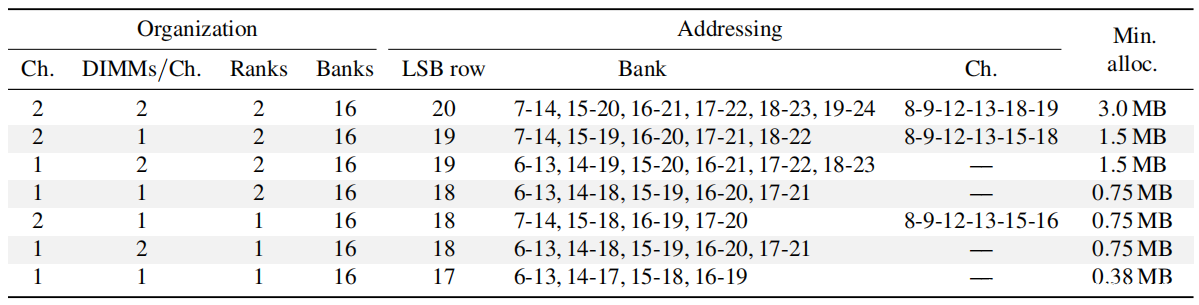
为了找出需要多少连续物理内存(或这两个 LSB 在物理地址中的位置),对大多数现代英特尔 CPU 的 DRAM 寻址函数进行了逆向工程。 它们可以在上表中找到。
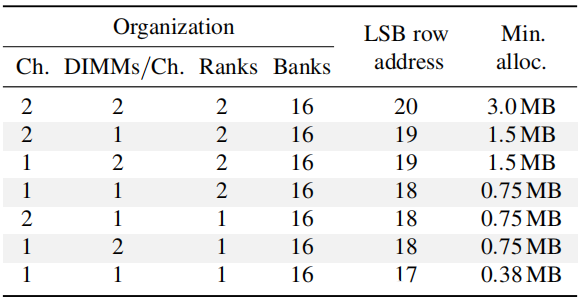
鉴于这些特定函数,上表显示了控制一对双行需要多少连续物理内存。如前所述,大页面提供了 2 MB 的连续物理内存,通过massaging伙伴系统内存分配器,可以获得 4 MB。因此得出结论,在大多数情况下,大页面就足够了。它们仅适用于大型配置,例如使用两个以上 DRAM 通道的系统。
0x05 Self-Evicting Rowhammer
Rowhammer 的有效性在很大程度上取决于攻击者激活率的最优性(即,固定时间间隔内的激活次数)。正如前文中所解释的,先前工作中描述的基于驱逐的 Rowhammer 技术虽然在 DDR3 系统上有效,但不会产生足够的内存访问来触发 DDR4 系统上的位翻转需要 Rowhammer 模式。这需要更新的驱逐策略来最大化锤击吞吐量。
例如一种基于驱逐的 Rowhammer 的方法通过利用 LLC的类似 LRU 的替换策略,为每个攻击者引入了一个缓存未命中。在双行 Rowhammer 的情况下,这转化为对 DRAM 的两次额外访问。然而,每个额外的攻击者都会引入另一个额外的访问,因此该方法不能扩展到多方面的模式。
前文中解释了虚拟行(即用于分散 TRR 缓解的行)的位置无关紧要。在本节中,将展示也可以通过使用虚拟行进行逐出来消除所有额外的 DRAM 访问。
A.选择双行对
本文的自驱逐 Rowhammer 模式的目标是使用傀儡绕过 in-DRAM TRR sampler,同时驱逐缓存。为了便于讨论,首先定义将在本文其余部分使用的术语。
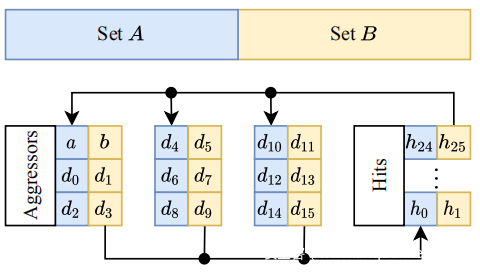
术语:如前所述,双行对是映射到同一银行中第三行(即受害者)周围的两行(即攻击者)的一对地址。让 (a,b) 表示具有虚拟地址 a 和 b 的双行对。如果虚拟地址 d 与 a 位于同一组中,则虚拟地址 d 是 (a,b) 的虚拟地址,因此也与 b 位于同一组中,并且不等于任何一个。建立这些定义后,按访问顺序排列的 N 辅助双行模式如下所示:

其中 di 表示 (a,b) 的第 (i + 1) 个傀儡。在 dN-1 之后,再次访问 a。将使用术语 aggressor 来指代 a、b 或一个虚拟地址。此外,使用 A 和 B 分别指代 a 和 b 的缓存集。
现在能够更准确地说明本研究意图,使用虚拟对象 di 来从 CPU 缓存中逐出 a 和 b。为此,将它们分成大小相等的两组,如下所示:d2k虚拟映射到 A,d2k+1 虚拟映射到 B,k 是从 0 到 N/2 的整数。基本上是在创建一个类似zebra的模式,其中每个其他地址都映射到同一组。
构建驱逐集:为了实现自我驱逐的目标,需要确保虚拟地址不仅与 (a,b) 位于同一存储体,而且还与 a 或 b 一致,即它们映射到相同的缓存集。不幸的是,能够分配 2 MB 连续物理内存的攻击者无法控制用于索引 CPU 缓存切片的高阶物理地址位(即位 20 以上的位)。在页面着色算法的帮助下解决了这个问题,该算法允许发现看似无法访问的高阶切片位。
大页面着色:考虑一个攻击者可以使用一组 2 MB 大页面。然后,大页面的颜色由仅应用于大页面偏移量上方的切片位的切片散列函数的结果给出。由于攻击者已经控制了页面偏移内的切片位,使用已知的页面颜色,攻击者可以完全控制切片索引。
为了揭示大页面的颜色,攻击者利用基于缓存驱逐的侧信道。举例来说,假设 LLC 的结合性是 W = 1。有两个大页面 P 和 Q,想知道它们的颜色是相同还是不同。为了找出答案,选择一个任意的页面偏移 f 并创建两个地址 p 和 q,每个页面一个,但都在页面偏移 f 处,以确保它们在页面内的设置索引和切片位相等。然后访问 p,然后是 q,再次是 p。如果对 p 的第二次访问导致(慢速)缓存未命中,则高位切片位的散列或 P 和 Q 的等效页面颜色相等,否则它们不同。
首先选择双行对(a,b)。为了找到一个,攻击者在已知的彩色大页面之一中选择任意偏移量。然后,为了找到 b,将 a 的行地址加二(或减二)。还更改了 b 中的一些附加位,以确保添加后 a 和 b 仍映射到同一组。 接下来选择虚拟地址在与 (a,b) 相同的页面偏移量处,但来自相同颜色的不同大页面。在相同颜色的页面上使用相同的偏移量,确保与 a 映射到 A 的偏移量相同的傀儡,以及 b 偏移量处的傀儡映射到 B。此外,傀儡将自动位于同一位置与 (a,b) 相同的存储体。
B.处理更换策略
现在有了双行对 (a,b) 和傀儡。原则上,假设傀儡映射到 A 或 B,N 辅助双行模式是自驱逐的。然而在实践中,如果虚拟对象不都适合它们的缓存集,它们只会相互驱逐或驱逐双行对。特别是,长度 L = N +2 的 N 辅助双行模式仅在 L/2 > W 时才会自驱逐,其中 W 是 LLC 的关联性。这将严重限制 SMASH 只能使用非常多的 N。
命中:必须引入另一种地址,将其称为命中(如缓存命中)。命中是永远不应该离开 LLC 的地址,并且像傀儡一样,它们要么映射到 A 要么映射到 B。也就是说,h2k 与 a 和 d2k 是一致的,而 h2k+1 与 b 和 d2k+1 一致对于某些整数k。命中用于有效地将 LLC 的感知关联性降低到 W’ < W。例如,使用命中,即使 LLC 的关联性更大,辅助双行模式(每组有四个攻击者)也可以自驱逐比四个,实际情况就是这样。对于命中,这种 6 辅助双行模式可能如下所示:
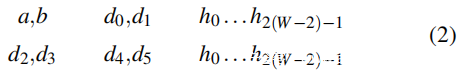
每行正好包含填满 A 和 B 的 2W 次访问。每行上的前四次访问进入 DRAM,并逐出另一行上的前四次。例如,在等式 2 中,d2 驱逐 A 中的 a,d3 驱逐 B 中的 b,d4 再次驱逐 A 中的 d0,等等。下图显示了另一个示例,W’ = 3 的 16 辅助双行模式。
随着命中的引入,还引入了一个新参数,即在模式中引入了多少。至少需要确保模式不适合 A 和 B(否则将不会有驱逐),因此必须至少将 W-L/2 添加到长度为 L 的模式中。 其次,它不会使引入超过 2(W-1) 的意义,因为 A 和 B 中没有空间留给攻击者。第三,请注意,如果 W’ 不划分 L/2(它在等式 2 中进行,其中 W’ = 2 和 L/2 = 4),访问顺序变得有点复杂,例如如果 W’ = 3 得到:
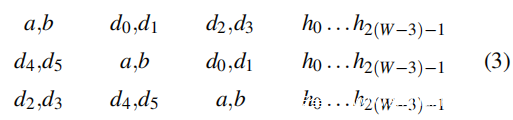
处理 QLRU:到目前为止,已经隐含地假设了一个类似 LRU 的替换策略。现在演示如何放宽这一假设以创建使用 Quad-age LRU (QLRU) 自我驱逐的模式,这是现代英特尔 CPU 的 LLC 使用的实际替换策略。下图显示了自驱逐下缓存集 A 的演变,说明了降低关联性 W’ = 1 下的 QLRU 行为3,这意味着在每个集访问一个攻击者后,立即转向命中。将从 1 开始,在 5 结束,6 表示下一轮的开始。
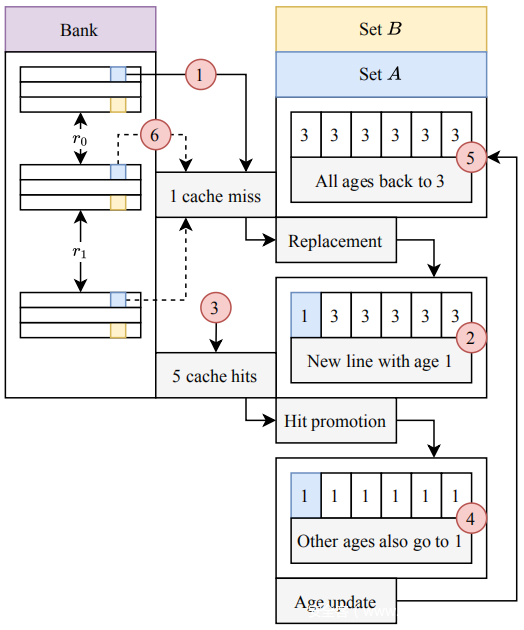
首先1访问 a,它被带入集合 A 并替换最旧和最左边的缓存行。 2 由于此时所有行的时间都为 3(可能是最旧),因此 a 会在最左边的位置结束。因为 a 是新的,所以它的时间变成1。 3继续造成五个缓存命中,访问当前在缓存中但时间为 3 的每个其他缓存行。 4 访问它们会使他们的时间回到原来的水平。 5 最后,因为现在所有时间都是一,所以替换策略说他们都应该变成三个,这是通过时间更新来完成的。 6 现在回到开头,a 位于 LRU 位置,准备在攻击者访问到 A 的第一个虚拟映射即 d0 时被驱逐。
C.双指针雕镂
最后为了使模式更快,使用双指针雕镂(Pointer chase)来执行访问,而不是更常见的单指针雕镂。 在单个(寄存器)指针雕镂中,攻击者指向的内存位置提供下一个攻击者的地址(或者有时是命中,就像例子中一样)。 然而,这种方法并没有最大限度地提高内存吞吐量,因为每第二次内存访问都需要等到第一次访问完成,从而降低了内存控制器级别的并行度。
为此没有使用一个寄存器,而是使用了两个。 自然地将模式分成两半,每一半中的地址映射到 A 或 B。然后将两半链接到相互关联的两个单指针雕镂中。 结果是这样的
每条指令从内存加载,而不是存储。 实验表明与使用单指针追逐相比,双指针追逐提高了 80% 的内存吞吐量。
0x06 Synchronized Rowhammer
本节中介绍的自驱逐模式不能直接触发位翻转,即使双行对包含已知易受攻击的行也不能。这意味着单靠多行 Rowhammer 并不总是足以绕过 TRR。为了对此进行研究,必须了解可以触发位翻转中基于“收集”CLFLUSH 的模式(即基准模式)与不能触发位翻转的自驱逐模式之间的区别。
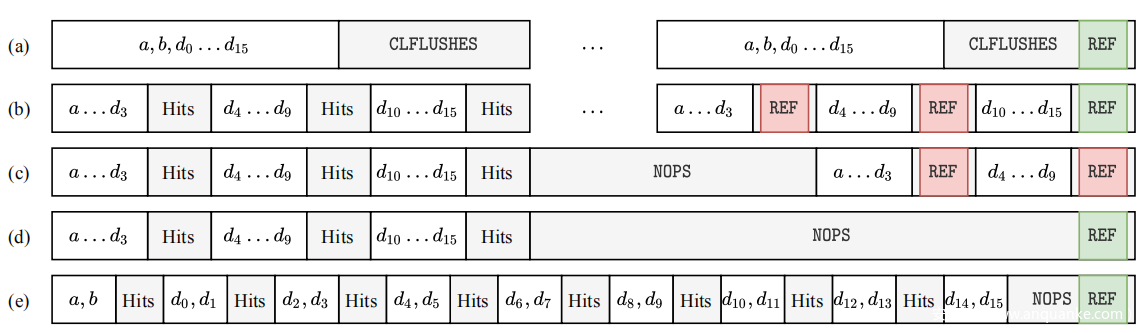
在本节中,将阐明攻击者如何以 S0 为案例研究来制作 Rowhammer 诱导的同步自驱逐模式。一种系统配置通常容易受到多种多行模式的影响。这一事实简化了最终实现,因为攻击者可以选择具有最佳攻击者行数的模式,以改进驱逐过程。因此,选择使用 18 行(或者更确切地说,16 行辅助双行) 。如上图-a 所示,基准模式遍历攻击者,连续发出内存请求,然后使用 x86 64 CLFLUSH 指令刷新这些地址。测试机配备了 Intel i7-7700K CPU,具有 16 路组关联 LLC(即 W = 16)。选择设置约化关联性 W’ = 3。作为示例,自驱逐模式如下所示(双行对、八对傀儡和 26 次命中,见上图-b):
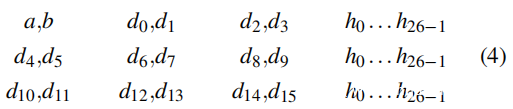
鉴于此模式比基准模式快约 30%,令人惊讶的是它不会产生位翻转。因此尝试减慢此模式以使其以与基准模式相同的速度执行。
A.硬同步自驱逐
为了研究这种现象,通过在 (a,b) 前面添加额外的 NOP 来减缓模式。这样,激活间隔增加。结果如下图所示:
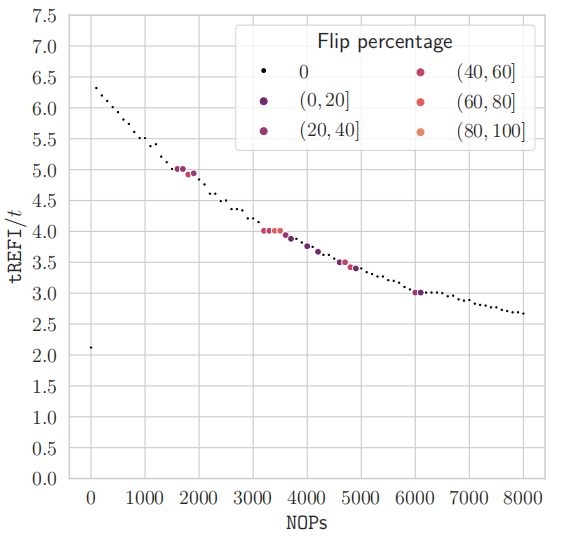
1.首先,能够将内存请求与发送到 DRAM 的刷新命令同步。确切地说,当 t(即迭代公式 4 的模式一次的时间)或 2t 除以 tREFI 时,尽管 NOP 数量增加,但两种模式都停止减速并且曲线变平。
2.其次,如果模式太快,即tREFI/t > 5,则不会触发位翻转。
in-DRAM TRR对每个刷新命令起作用,并且sampler的每个刷新间隔可以采样多个攻击者。在所有实验中,只在与第一个 nnS 攻击者相邻的受害者行中发现位翻转,其中 n 始终是攻击者的总数,S 是sampler的可疑容量,就其跟踪的攻击者数量而言。只是通过减少攻击者的数量来学习 S,直到不再能够重现特定的位翻转。
存储器控制器需要平均每 tREFI = 7.8 µs 调度一次刷新命令。现代内存控制器试图通过在没有 DRAM 活动时机会性地发送刷新命令来提高性能。为了成功触发 Rowhammer 位翻转,模式需要重复数万次,在此期间内存控制器必须发出许多刷新命令。当没有 NOP 时,内存控制器将尝试在具有许多缓存命中的区域之一期间安排刷新命令。这意味着,当刷新命令到达缓存命中的三个不同区域时,TRR 机制将能够成功地采样和刷新公式 4 模式中的 18 个攻击者行中的每一个。
当在模式前面插入 NOP 时,可能会发生三种不同的情况,如前图所示。 在第一个场景中,在 NOP 数量较少的情况下,内存控制器可能仍会选择发送在具有缓存命中的区域中刷新命令,导致没有位翻转。在第二种情况下,每个模式前面的大量翻转会使模式太慢而无法触发位翻转。在第三种情况下,使用正确数量的 NOP,模式与内存控制器打算发送刷新命令的时间同步。这导致第一个攻击者 (a,b) 逃脱 TRR 机制以成功锤击内存并触发位翻转。
虽然在自驱逐模式的开头添加 NOP 的策略在触发位翻转方面是有效的,但它需要攻击者非常精确地与刷新命令同步,并找出成功攻击的正确 NOP 数量。虽然这是一个合理的策略,正如将在评估中展示的那样,但在 JavaScript 中与刷新间隔精确同步并不总是微不足道的。相反,将描述另一种创建模式的策略,该模式仅与内存控制器的刷新命令进行软同步,并取消找到有效锤击的确切 NOP 数量的要求。
B.软同步自驱逐
为了确保内存控制器不会在不需要的时刻进行刷新,必须确保具有缓存命中的区域足够小。为此,稍微修改了自驱逐访问模式,以在缓存未命中之间更均匀地分配缓存命中,从而创建以下自驱逐模式:
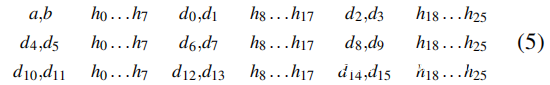
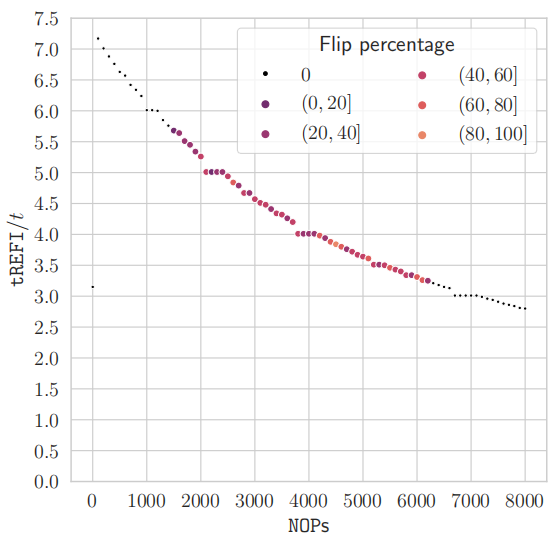
上图显示了在前面使用可变数量的 NOP 执行此模式的结果。鉴于少量缓存命中并没有为内存控制器提供足够大的窗口来调度刷新,它会机会性地使用单个可用的 NOP 间隙来代替调度刷新命令。因此,公式 5 的模式可以更柔和地与刷新命令同步,而无需精确数量的 NOP。这使得从 JavaScript 搜索位翻转更加方便,如下一节所示。
调整缓存切片:在这些实验中发现访问不同切片可能需要可变的时间。这使得生成同步模式变得更加困难,其中地址映射到的两个集合 A 和 B 驻留在不同的切片中。因此,通过调整每个地址的列位,确保 A 和 B 映射到同一个切片。
0x07 Evaluation
上一节表明,可以成功生成自驱逐锤击模式,这些模式能够使用软同步技术和重新操作来绕过 TRR 机制。还展示了正确选择攻击者地址的能力取决于虚拟到 DRAM 寻址功能以及如何选择映射到给定缓存集和切片的地址。
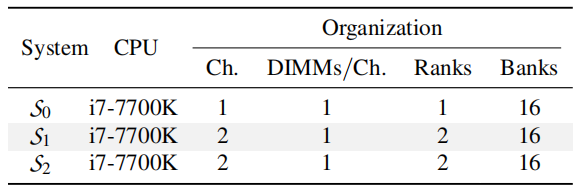
在本节中,评估攻击者可以成功创建有效的自驱逐模式的约束条件。本文评估了在来自两个主要内存供应商的具有不同内存配置和内存模块的三种设置上构建自驱逐模式的可行性(见上表)。所有系统均采用采用 Kaby Lake 微架构的 Intel Core i7-7700K CPU。由于 Skylake、Kaby Lake、Coffee Lake (R) 微架构都对给定的内存配置使用相同的 DRAM 寻址函数,正如前文中发现的那样,关注在不同内存配置上构建自驱逐同步模式的可行性在 CPU 的微体系结构方面不乏通用性。
A.自驱逐模式的实用性
是否可以仅从大页面中提取自驱逐模式,取决于内存控制器采用的 DRAM 寻址功能。在较小程度上,它还取决于用于切片寻址的复杂寻址方案,自 Sandy Bridge 以来,这种方案没有改变,除了从 Skylake 开始,切片的数量等于超线程的数量而不是内核的数量。

使用基于软件的 DRAMA 方法对几种内存配置的物理到 DRAM 寻址功能进行了逆向工程。上表显示了为获得 (a,b) 形式的双行对而需要更改的位。假设启用了 THP,在七种可能配置中的六种中,可以成功地在大页面内找到双行对。在其余情况下,行位在大页边界之后开始,因此找不到与 a 相隔两行的 b。
B.产生位翻转
首先使用开源 TRRespass为的三个测试中的每一个找到最有效的多行访问模式。然后,根据前文中描述的策略使每个模式自驱逐和同步。下表总结了所得模式的一些不同属性(例如,降低的关联性 W’)。
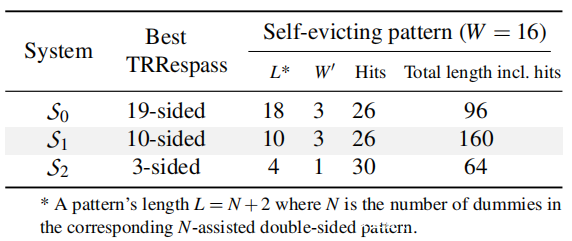
下表显示所有三种自驱逐模式都能够使用原生 C 实现触发位翻转。同时,观察到不同系统所需的 NOP 数量存在明显差异。特别是,与系统 S0 相比,系统 S1 和 S2 上的“有效 NOP 范围”更窄。怀疑这是因为 S1 和 S2 构建的自驱逐模式的相对缓慢(与刷新模式相比)造成的。如上表所示,与 S0 相比,S1 和 S2 的 TRRespass 模式更小(即所需的傀儡更少),这意味着命中的引入将对 (a,b) 的激活之间的时间产生更大的相对影响。因此,使用太多 NOP 会使这些模式太慢而无法触发位翻转。

在 JavaScript 中的实现能够触发系统 S0 和 S1 上的位翻转。观察到与 S0 相比,S1 上位翻转的发生频率较低。尽管使用原生实现也观察到了这一点,但与 S0 相比,系统 S1 和 S2 的更严格的同步要求(即更小的 NOP 范围)会夸大差异是合理的。由于 NOP 在 JavaScript 中不可用,实现使用 XOR 代替。这两条指令都很便宜,但 JavaScript 中的 XOR 循环有更多的开销,因此引入了更粗粒度的延迟。这使得瞄准系统 S1 和 S2 的最佳位置变得更加困难。
C.JavaScript 实现基准
现在评估运行在最新版本的 Mozilla 的 JavaScript 运行时 SpiderMonkey 上的 JavaScript 实现的性能。特别地,考虑了程序的初始化阶段(例如检测页面颜色所花费的时间)和锤击阶段。
初始化:攻击者首先运行切分着色算法,以揭示支持其 ArrayBuffer 的 500 个大页面的页面颜色。接下来,攻击者使用大页面的子集(其大小取决于模式的长度)来组装第一个自驱逐模式。最后,攻击者需要注意同步,并通过改变模式前面的 XOR 数量来做到这一点。
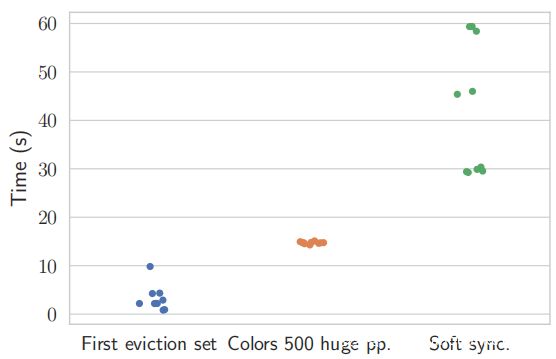
上图报告了在每个步骤上花费的时间:“第一个驱逐集”和“上色 500 大页”。一起报告切片着色算法找到五个相同颜色的大页面并随后使用它们分别显示其他 500 个页面的颜色所需的时间。最后,“软同步”。报告为软同步寻找正确数量的 XOR 所花费的时间。每次测量都重复了 10 次。平均而言,攻击者需要一分钟才能完成初始化。请注意,软同步步骤花费的时间最长。在实现中,使用放大的时间测量来估计模式在将其用于锤击之前适合 7.8 µs 的刷新间隔 tREFI 的次数。如果模式适合四次,那么它是一个很好的锤击候选者。
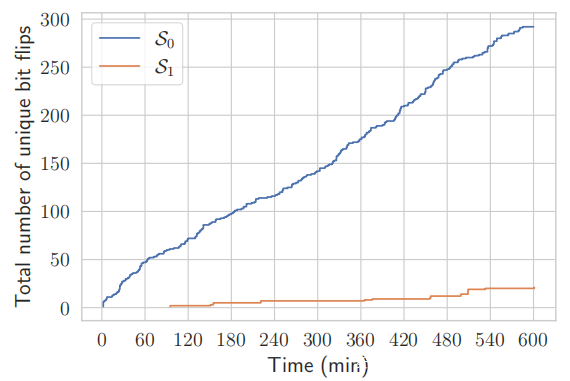
锤击时间:初始化完成后,攻击者开始寻找可利用的位翻转。为了锤击不同的行,攻击者只需更改用于模式组装的大页面子集。上图显示了在 S0 和 S1 上的单个 10 小时实验期间随时间推移的唯一位翻转的累积数量。
D.讨论
要成功执行 SMASH,攻击者需要了解受害者的内存配置。特别是,如果不知道 DRAM 寻址功能和至少一种绕过 TRR 的 n 行模式,就不可能构建自驱逐模式。虽然指纹可以检测特定系统,但攻击者也可以尝试不同的配置,直到成功。
0x08 Mitigations
在硬件中缓解 Rowhammer:Rowhammer 是 DRAM 硬件中的一个漏洞,期望它应该在硬件中修复是明智的。不幸的是,更新和更有效的缓解措施需要很多年才能到达终端用户。此外,鉴于未来的 DRAM 设备将采用更小的晶体管,是否有可能为此类设备构建有效的缓解措施还有待观察。尽管如此,未来 DRAM 设备的安全性可以从三个方向提高:首先,硬件制造商可以以更高的成本构建更精确的sampler,无论是在 DRAM 设备内部还是在内存控制器上。其次,可以部署比现有解决方案更积极的纠错,以降低触发位翻转的概率。第三,根据访问模式和给定 DRAM 设备的脆弱性,可以限制潜在激活的数量。所有三个方向都伴随着性能或存储开销,更不用说额外的功耗了。
在软件中缓解 Rowhammer:在硬件缓解措施可用的情况下,已经有许多建议可以在软件中缓解 Rowhammer。它们的安全性、兼容性或性能总是存在问题。 CATT建议使用保护页来保护内核内存免受用户内存的攻击。不幸的是,内核内存可能会通过页面缓存等常见机制直接暴露给用户内存,从而使系统暴露在外。 ALIS和GuardION试图保护系统的其余部分免受可能被攻击的内存区域,但这些解决方案需要对每个软件进行更改,而且不能保护系统的其余部分免受攻击。 ZebRAM尝试使用奇数行和偶数行将 VM 的内存划分为安全和不安全区域。虚拟机可以直接访问安全区,而不安全区则用作受 ECC 保护的交换缓存。 ZebRAM 的设计虽然可以抵御已知攻击,但在处理内存密集型工作负载时具有非平凡的性能开销。
减轻 SMASH:现在讨论更实用的缓解措施,这些缓解措施在不解决底层Rowhammer漏洞的情况下让攻击者更难通过SMASH来利用浏览器。当前版本的 SMASH 依靠 THP 来构建高效的自驱逐模式。禁用 THP,同时引入一些性能开销,将停止 SMASH 的当前实例。此外,漏洞利用特别依赖于浏览器中的破坏指针来破坏 ASLR 并转向伪造对象。保护软件或硬件中指针的完整性(例如,使用 PAC)将阻止当前的 SMASH 漏洞利用。
0x09 Conclusion
本研究展示了互联网用户仍然受到现代 DDR4 设备中 Rowhammer 漏洞的影响。 这些设备需要多行 Rowhammer 模式来绕过它们的 TRR 缓解。 在不访问缓存刷新指令和连续物理内存的情况下,在 JavaScript 中高效执行此类模式特别具有挑战性。 发现了 TRR 缓解的一个新属性,结合精心选择的锤击地址,可以在浏览器中创建高效的多行Rowhammer 模式。 然而,在 JavaScript 中触发位翻转需要更进一步,并根据 CPU 内存控制器发出的刷新命令仔细安排缓存访问。 端到端漏洞利用称为 SMASH,可以在平均 15 分钟内启用所有缓解措施来完全破坏 Firefox 浏览器。 最后讨论了减轻 Rowhammer 攻击的未来方向,特别是 SMASH。







发表评论
您还未登录,请先登录。
登录