

近年来,笔者在国内外 CTF 竞赛中见到不少与 AI 相关的题目。有一些是需要选手自行实现一个 AI,来自动化某些操作;有些是给出了一个目标 AI 模型,要求选手进行破解。本文主要谈论后者——在 CTF 竞赛中,我们如何欺骗题目给出的 AI?
CTF 中的欺骗 AI 问题一般分成两类:基于神经网络的和基于统计模型的。如果题目要求选手欺骗神经网络,一般会给出白盒的模型(往往是图像分类任务);如果是要求选手欺骗统计学习模型,有些题目会给出白盒的模型参数,也有的提供训练数据集。
我们先从一道很简单的欺骗统计学习模型看起,来体验这类问题的主要求解过程。
欺骗 kNN:[西湖论剑2020] 指鹿为马
任务目标
有一个 AI 模型,要求选手上传一张图片,与 dear.png 的差异很小,但被 AI 判别为马。
import numpy as np
from PIL import Image
import math
import operator
import os
import time
import base64
import random
def load_horse():
data = []
p = Image.open('./horse.png').convert('L')
p = np.array(p).reshape(-1)
p = np.append(p,0)
data.append(p)
return np.array(data)
def load_deer():
data = []
p = Image.open('./deer.png').convert('L')
p = np.array(p).reshape(-1)
p = np.append(p,1)
data.append(p)
return np.array(data)
def load_test(pic):
data = []
p = Image.open(pic).convert('L')
p = np.array(p).reshape(-1)
p = np.append(p,1)
data.append(p)
return np.array(data)
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct / float(len(testSet))) * 100.0
def check(pic):
source_p = Image.open('deer.png')
try:
c_p = Image.open(pic)
except:
print("Please upload right picture.")
exit()
diff_pixel = 0
a, b = source_p.size
if c_p.size[0] != a and c_p.size[1] != b:
print("Please upload right picture size("+str(a)+','+str(b)+')')
exit()
for y in range(b):
for x in range(a):
diff_pixel += abs(source_p.getpixel((x, y)) - c_p.getpixel((x, y)))
return diff_pixel
def main():
while 1:
print('-' * 134)
print(''' ____ __ _ _ _ _ _ _ _
| __ \ / _| | | | | | | | | | | | | | |
| |__) |___| |_ ___ _ __ | |_ ___ | |_| |__ ___ __| | ___ ___ _ __ __ _ ___ | |_| |__ ___ | |__ ___ _ __ ___ ___
| _ // _ \ _/ _ \ '__| | __/ _ \ | __| '_ \ / _ \ / _` |/ _ \/ _ \ '__| / _` / __| | __| '_ \ / _ \ | '_ \ / _ \| '__/ __|/ _ \\
| | \ \ __/ || __/ | | || (_) | | |_| | | | __/ | (_| | __/ __/ | | (_| \__ \ | |_| | | | __/ | | | | (_) | | \__ \ __/
|_| \_\___|_| \___|_| \__\___/ \__|_| |_|\___| \__,_|\___|\___|_| \__,_|___/ \__|_| |_|\___| |_| |_|\___/|_| |___/\___|
''')
print('-'*134)
print('\t1.show source code')
print('\t2.give me the source pictures')
print('\t3.upload picture')
print('\t4.exit')
choose = input('>')
if choose == '1':
w = open('run.py','r')
print(w.read())
continue
elif choose == '2':
print('this is horse`s picture:')
h = base64.b64encode(open('horse.png','rb').read())
print(h.decode())
print('-'*134)
print('this is deer`s picture:')
d = base64.b64encode(open('deer.png', 'rb').read())
print(d.decode())
continue
elif choose == '4':
break
elif choose == '3':
print('Please input your deer picture`s base64(Preferably in png format)')
pic = input('>')
try:
pic = base64.b64decode(pic)
except:
exit()
if b"<?php" in pic or b'eval' in pic:
print("Hacker!!This is not WEB,It`s Just a misc!!!")
exit()
salt = str(random.getrandbits(15))
pic_name = 'tmp_'+salt+'.png'
tmp_pic = open(pic_name,'wb')
tmp_pic.write(pic)
tmp_pic.close()
if check(pic_name)>=100000:
print('Don`t give me the horse source picture!!!')
os.remove(pic_name)
break
ma = load_horse()
lu = load_deer()
k = 1
trainingSet = np.append(ma, lu).reshape(2, 5185)
testSet = load_test(pic_name)
neighbors = getNeighbors(trainingSet, testSet[0], k)
result = getResponse(neighbors)
if repr(result) == '0':
os.system('clear')
print('Yes,I want this horse like deer,here is your flag encoded by base64')
flag = base64.b64encode(open('flag','rb').read())
print(flag.decode())
os.remove(pic_name)
break
else:
print('I want horse but not deer!!!')
os.remove(pic_name)
break
else:
print('wrong choose!!!')
break
exit()
if __name__=='__main__':
main()
我们详细看一遍代码,发现这个 AI 模型是 k-邻近(k-Nearest Neighbor, KNN),而且还是个 k=1 的情形,且训练集中,鹿和马各只有一张图片。题目将选手的图片读进去,做的事情如下:
- 检查选手上传的图片与
deer的像素差是否小于 100000。如果超过限制,则报告错误。 - 求选手图片与
deer和horse的欧几里得距离。离谁更近,就判定为哪个分类。 - 如果选手图片被判定为马,则选手获胜。
deer 和 horse 都是灰度图,如下:
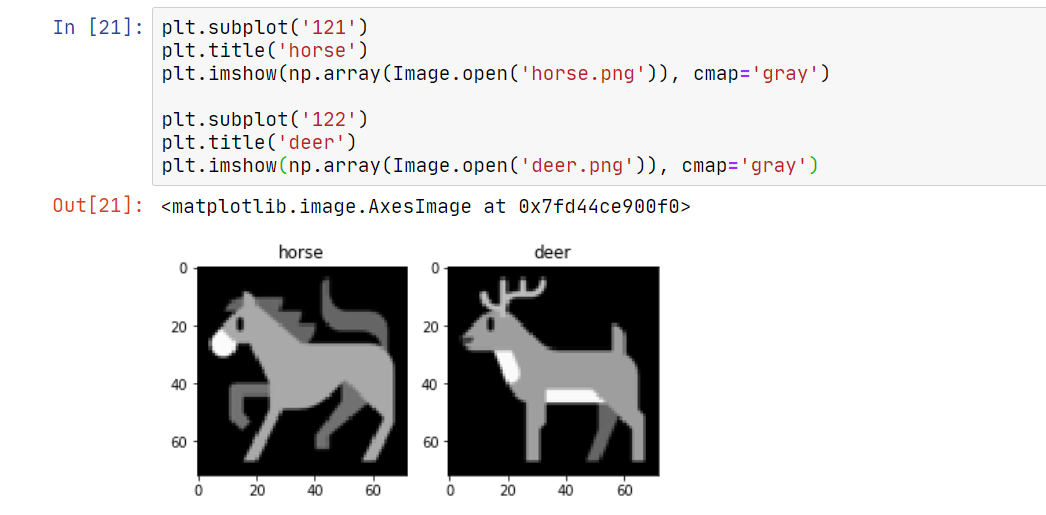
笔者建议在做机器学习类 CTF 题的时候,采用 jupyter notebook 或者 jupyter lab,并用好 matplotlib 来可视化当前的结果。这会大大提升工作效率。
我们现在的目标就是在 deer 的基础上进行小幅度修改,使得它与 horse 之间的的欧氏距离小于其与 deer 的。
尝试:随机噪声
为了构造出合法的图片,我们需要回去看「修改幅度」的衡量方式。其代码如下:
for y in range(b):
for x in range(a):
diff_pixel += abs(source_p.getpixel((x, y)) - c_p.getpixel((x, y)))
return diff_pixel
它衡量的是图片 A 与 B 之间每个像素点的距离之和。换句话讲,这是曼哈顿距离。笔者遇到的大部分 CTF 欺骗 AI 题目,衡量修改幅度都是采用曼哈顿距离。
这张图片共有 5184 个像素点,也就是说,平均下来,每个像素点允许 19 的偏差。事实上,这是非常宽松的值,我们随便演示一个合法的修改:
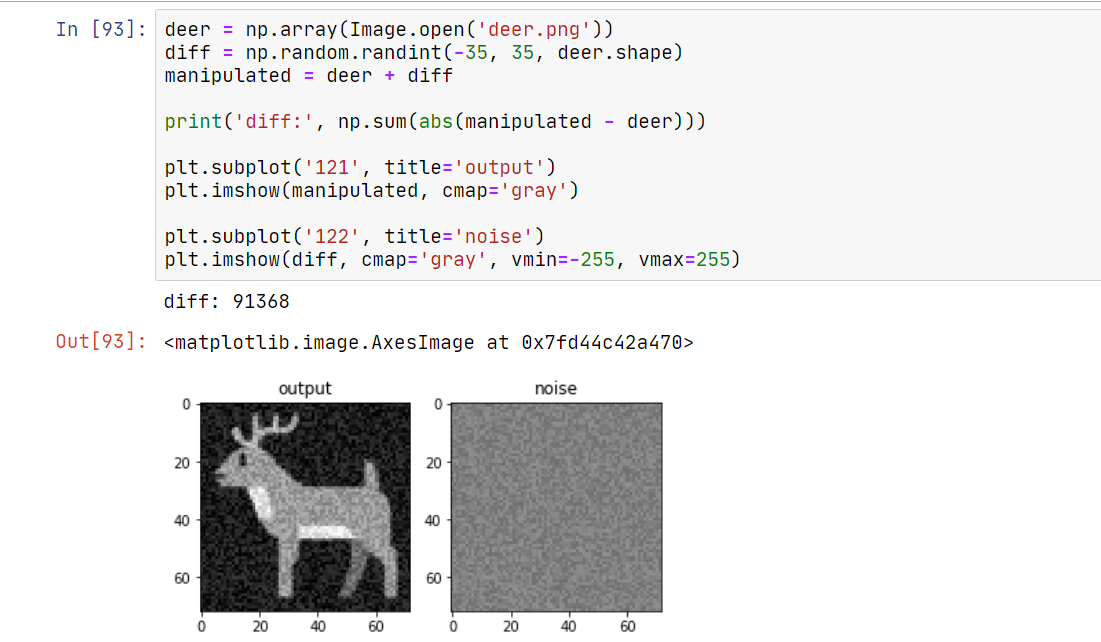
输出的图片就像老式电视一样。那么它能否骗过 AI 呢?

很遗憾,其与鹿之间的欧氏距离,小于其与马之间的欧氏距离。我们现在要开始反思一个问题:把 100000 个差异值随机平摊到每个像素上,是最好的解法吗?
解法:修改差异大的像素
在二维平面上考虑这个问题。假设我们想让一个点在欧氏距离的衡量下远离 (0, 0),但要保持曼哈顿距离不超过 2。如果选择 (1, 1),则欧氏距离为 sqrt(2);如果选择 (0,2),则欧氏距离可以达到 2,这是更优的选择。
那么,我们相应地猜测:对于本题,我们应该把一些像素点直接改到与 horse 的对应像素相等;其他的像素点可以放弃。而那些应当修改的点,是 deer 与 horse 像素差异最大的点。
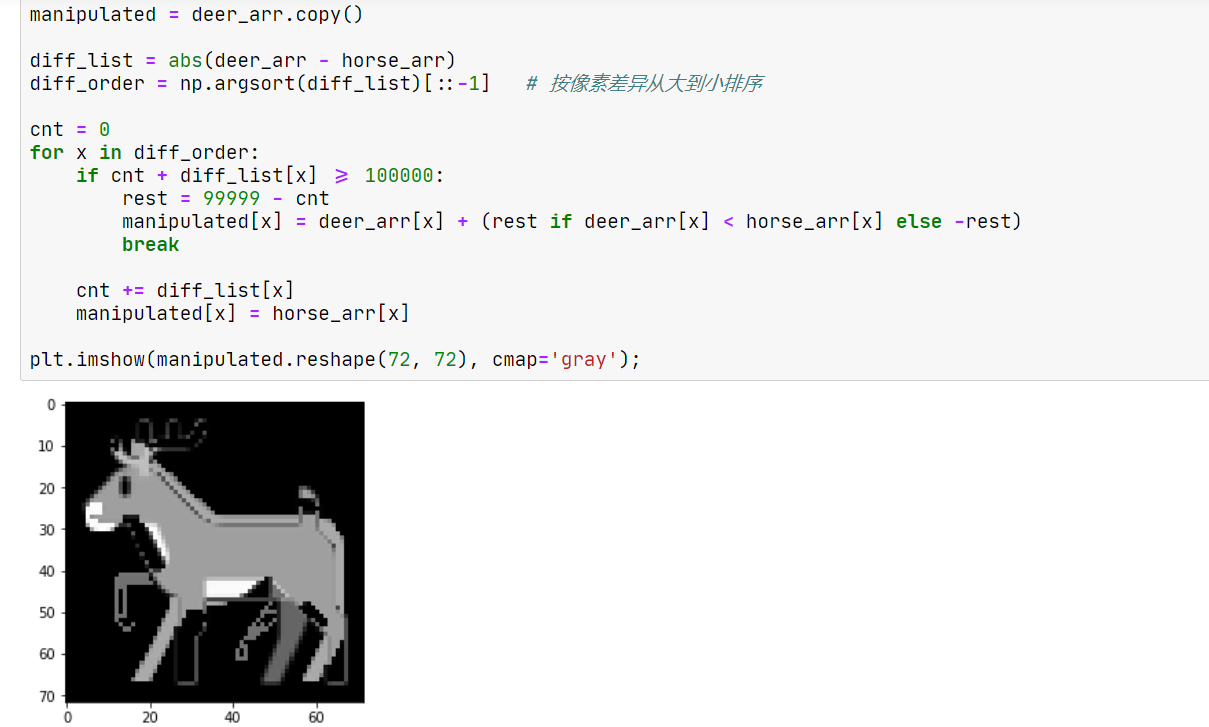
生成了一张很怪的图。来验证一下是否满足要求:
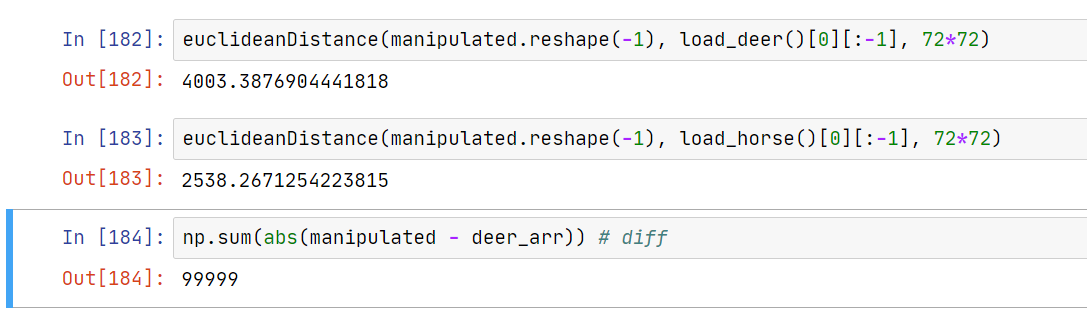
可见与鹿的距离是 4003,与马的距离是 2538,骗过了 AI。像素差异是 99999,我们成功完成了题目指定的目标。
数学上的证据
我们刚刚基于「差异越大的像素越应该修改」这个猜测,成功地解决了问题。这里给出为什么 it works 的证明。不爱看证明的读者可以跳过。


所以,我们从数学上证明了为什么「差异越大的像素点,越值得更改」。并且从数学推导中,我们还可以发现另一个结论:将像素点改成马的对应像素值,并非最优解。要改就改彻底:要么改成 0,要么改成 255。不过本题的像素差异限制 100000 是一个很松的界,所以我们之前不那么优秀的算法也可以成功。
总结
回顾我们的做题过程,我们从一个原图片 X 出发,施加一个很小的扰动向量,获得样本 Y,且 AI 对 Y 的表现与对 X 的表现非常不同。这样的样本被称为「对抗样本」,如何构造高质量的对抗样本、利用对抗样本来改进模型的鲁棒性,是机器学习研究中逐步受到重视的一个方向。
需要注意的是,攻击统计学习 AI 模型,往往需要进行一些数学推导。如果读者有兴趣,笔者推荐了解一下 kNN、kmeans、混合高斯模型等经典的统计学习方法。
欺骗白盒神经网络
概述
神经网络能解决大量传统模型难以解决的问题,近年经历了飞速发展。神经网络一般是由多层神经元构成的,每个神经元有自己的参数。下图是一个简单的神经网络模型(多层感知机):
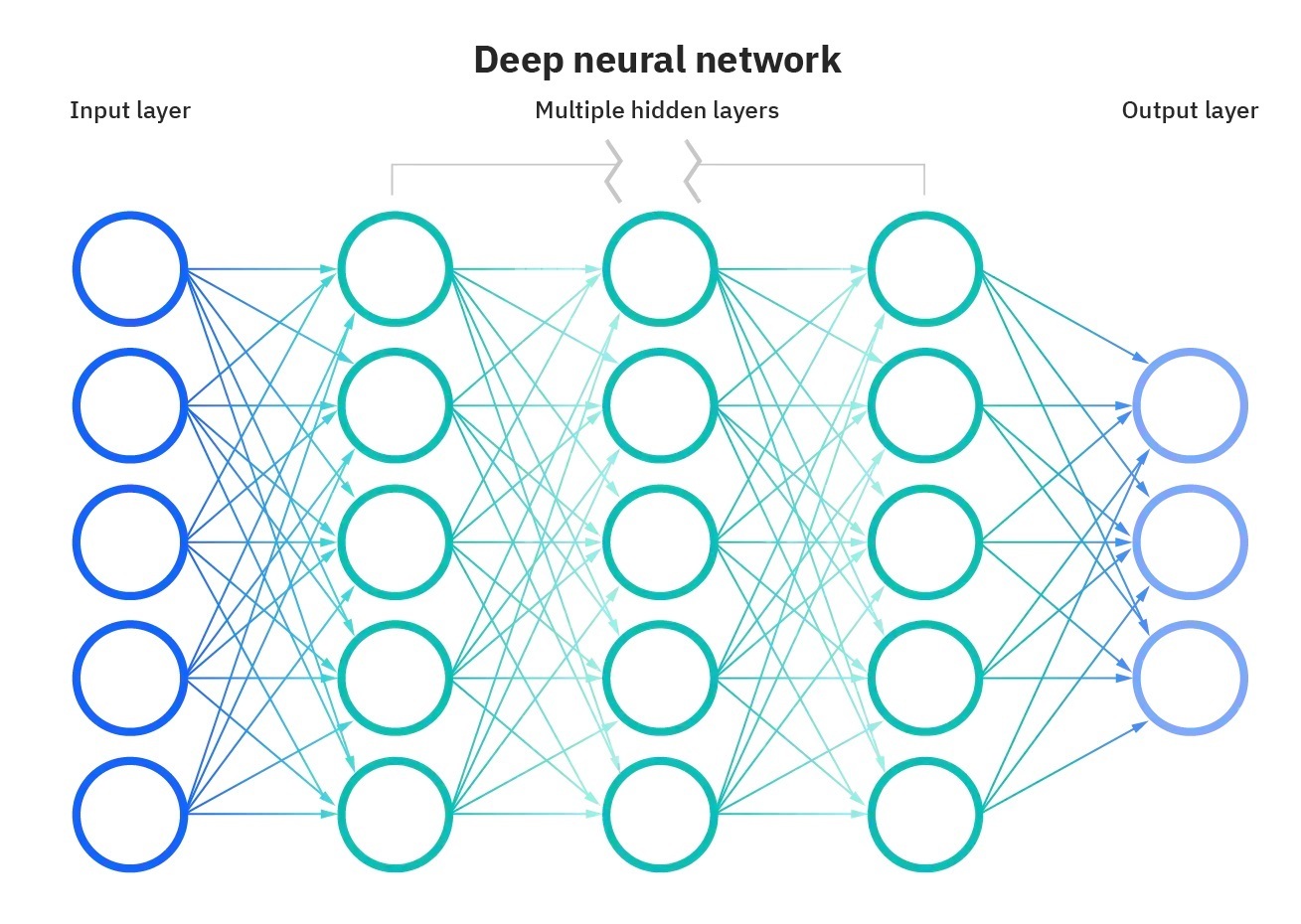
图源 IBM。本文假定读者已经对神经网络有一些了解;如果从零学起的话,笔者推荐看一看 3Blue1Brown 的机器学习教程、PyTorch 的官方教程。
以上图描述的神经网络为例。在图像分类任务中,图像的每个像素点被输入到第一层,然后传导到第二层、第三层……直到最后一层。最后一层的每个神经元代表一个分类,其输出是「图像是否属于本类」的打分。我们一般取打分最高的那一类,作为分类结果。
CTF 中的欺骗神经网络题一般如下:给定一个预训练好的分类模型(PyTorch 或者 TensorFlow),再给定一张原图。要求小幅度修改原图,使得神经网络将其误分类为另一个类别。
攻击手段
我们训练神经网络时,一般采用梯度下降的方法。每一轮迭代可以理解为下面的过程:首先输入 X,然后运行 net(X) 获取输出,根据网络输出与期望输出的不同,来反向传播,修改网络模型的参数。
那么,我们现在要攻击这个网络,可以采取什么办法呢?首先还是给网络提供原图 X,得到输出 net(X),接下来,我们根据「网络分类的结果」与「我们想要误导的结果」的差异计算 loss 值,进行反向传播。但是需要注意,我们不修改网络参数,而是将原图减去其梯度。这样迭代若干次,直到成功误导 AI 为止。
下面,我们以识别手写数字(MNIST数据集)的任务为例,从训练网络开始,演示一下攻击方法。
实践:训练神经网络
这里采用 PyTorch 来实现神经网络。首先是导入数据集:
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
trans_to_tensor = transforms.Compose([
transforms.ToTensor()
])
data_train = torchvision.datasets.MNIST(
'./data',
train=True,
transform=trans_to_tensor,
download=True)
data_test = torchvision.datasets.MNIST(
'./data',
train=False,
transform=trans_to_tensor,
download=True)
data_train, data_test
实现一个 DataLoader,作用是生成随机打乱的 mini batch 用于训练:
train_loader = torch.utils.data.DataLoader(
data_train,
batch_size=100,
shuffle=True)
来看一个 mini batch。

接下来定义网络。我们采用一个很原始的模型:将输入的 28*28 的灰度图展开为一维数组,然后经过 100 个神经元的全连接层,激活函数为 ReLu。接下来再通过 10 个神经元的全连接层,激活函数为 sigmoid,作为预测值输出。
class MyNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 100)
self.fc2 = nn.Linear(100, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
net = MyNet()
如果图像中的数字是 c,我们希望输出的 10 维向量中仅有第 c 位是 1,其余都是 0。所以我们采用交叉熵损失函数以及 Adam 优化器:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
接下来就是训练这个网络。
def fit(net, epoch=1):
net.train()
run_loss = 0
for num_epoch in range(epoch):
print(f'epoch {num_epoch}')
for i, data in enumerate(train_loader):
x, y = data[0], data[1]
outputs = net(x)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
run_loss += loss.item()
if i % 100 == 99:
print(f'[{i+1} / 600] loss={run_loss / 100}')
run_loss = 0
test(net)
def test(net):
net.eval()
test_loader = torch.utils.data.DataLoader(data_train, batch_size=10000, shuffle=False)
test_data = next(iter(test_loader))
with torch.no_grad():
x, y = test_data[0], test_data[1]
outputs = net(x)
pred = torch.max(outputs, 1)[1]
print(f'test acc: {sum(pred == y)} / {y.shape[0]}')
net.train()
来看 5 个 epoch 之后的结果:
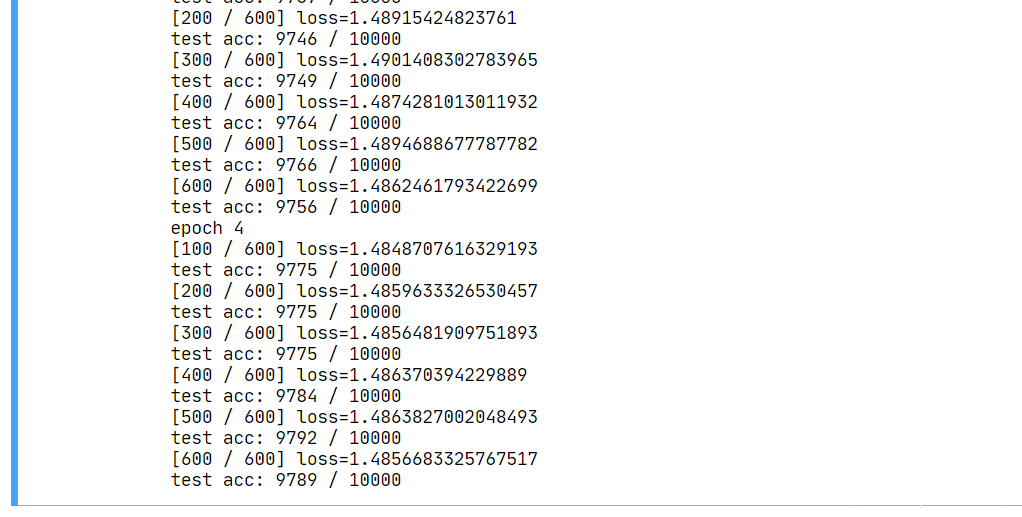
我们训练出了测试准确率 97.89% 的网络。接下来,我们开始针对网络进行攻击。
实践:欺骗白盒多层感知机
目前网络的所有参数我们都是知道的。在 CTF 中,一般会提供训练网络的代码,以及通过 torch.save() 导出的预训练模型,选手通过 model.load_state_dict() 即可导入模型参数。
我们随便选择一个数据,作为原图:

我们的模型以很强的信心,将其分类为 2。接下来,我们篡改原图,使得网络将其误分类为 3。过程如下:
- 将图片输入网络,得到网络输出。
- 将网络输出与期望输出求 loss 值(这里采用交叉熵)。
- 将图片像素减去自己的梯度 * alpha,不改变网络参数。
重复以上过程,直到误导成功为止。代码如下:
def play(epoch):
net.requires_grad_(False) # 冻结网络参数
img.requires_grad_(True) # 追踪输入数据的梯度
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数
for num_epoch in range(epoch):
output = net(img)
target = torch.tensor([3]) # 误导网络,使之分类为 3
loss = loss_fn(output, target)
loss.backward() # 计算梯度
img.data.sub_(img.grad * .05) # 梯度下降
img.grad.zero_()
if num_epoch % 10 == 9:
print(f'[{num_epoch + 1} / {epoch}] loss: {loss} pred: {torch.max(output, 1)[1].item()}')
if torch.max(output, 1)[1].item() == 3:
print(f'done in round {num_epoch + 1}')
return
img = origin.view(1, 28, 28)
play(100)
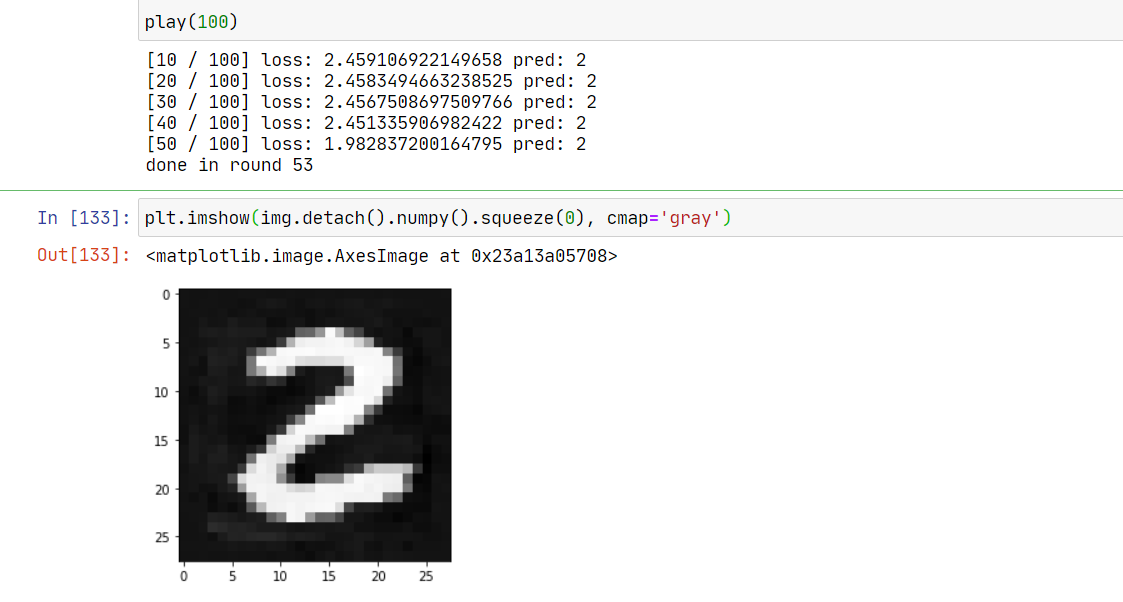
我们成功地构造出了一个对抗样本,我们人类看显然还是 2,但模型将其识别为 3。至此成功完成任务。对比图如下:
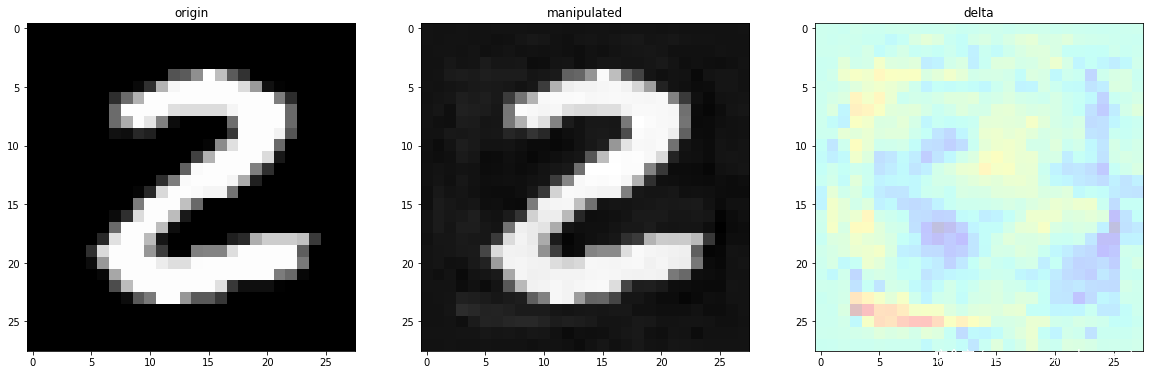
总结
很多 CTF 欺骗神经网络题目,都可以采用上面这一套代码。训练网络的代码选手不用自己写,只需要导入预训练好的模型即可。在迭代时,选手应该选取合适的学习率 alpha(笔者的代码中是 0.05)、添加一些特殊约束(例如对每个像素的修改距离不能超过特定值)。无论如何,欺骗白盒神经网络的主要思想,往往都是「固定网络参数、通过梯度下降修改原图」。
更进一步的讨论
我们已经一步步完成了对白盒神经网络的欺骗。但日常生活中,很少有神经网络会把自己的参数广而告之,这使得我们不能采用上面的套路去攻击。此外,我们上面生成的那张图片很不「自然」,有大量的背景噪声,而这是正常的数字图片中不会存在的。
关于这些问题,ICLR2018 的一篇论文 Generating natural adversarial examples 可以提供一些启发。该论文提出的方法不要求预先知道网络参数,甚至不要求知道网络模型。而且该方案能生成比较自然的对抗样本,如下所示:
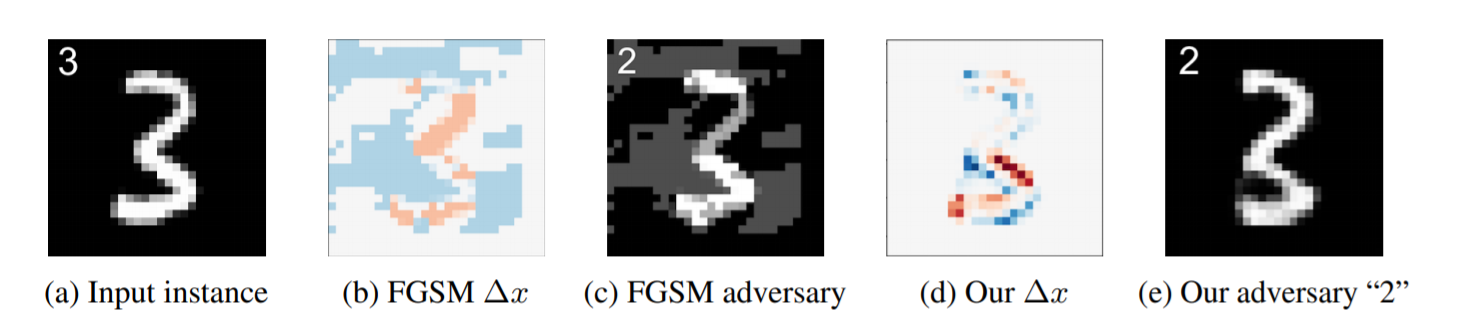
那么,他们是如何做到的呢?下面简要描述一下原理。首先,通过类似于 CycleGAN 的思路,训练一个从 latent space 到图片的生成器、一个从图片反推 z 的编码器。接下来,把原图编码成向量 z,并在 z 的附近随机选择很多的 z’,利用生成器从这些 z’ 生成图片,然后交给目标模型去判断。如果有图片成功误导了模型,则报告成功。
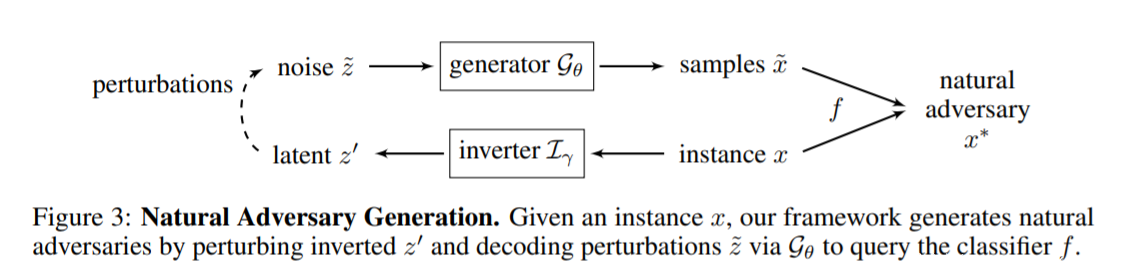
论文作者给出了该方法用于 CV 和 NLP 两个领域的成效,并成功地攻击了谷歌翻译。他们的代码开源在 Github 上。
这是一个适用范围比较广的方案,不过笔者认为可能不适合用于 CTF 出题。这是因为训练 GAN 是一件费时费力、且需要机器学习技巧的工作,已经超出了 CTF 一般的考察范畴;且由于出题人模型是黑盒的,可能训练模型技巧较好、使用的判别模型与出题人差异较大的选手反而难以成功。
总而言之,对抗样本是一条很有趣的研究方向。笔者今天介绍了 CTF 竞赛中欺骗 AI 的一般步骤,希望对 CTF 选手有所帮助。







发表评论
您还未登录,请先登录。
登录