

研究表明,机器学习系统在理论和实践中都容易受到对抗样本的影响。到目前为止,此类攻击主要针对视觉模型,利用人与机器感知之间的差距。尽管基于文本的模型也受到对抗性样本的攻击,但此类攻击难以保持语义和不可区分性。在本文中探索了一大类对抗样本,这些样本可用于在黑盒设置中攻击基于文本的模型,而无需对输入进行任何人类可感知的视觉修改。使用人眼无法察觉的特定于编码的扰动来操纵从神经机器翻译管道到网络搜索引擎的各种自然语言处理 (NLP) 系统的输出。通过一次难以察觉的编码注入——不可见字符(invisible character)、同形文字(homoglyph)、重新排序(reordering)或删除(deletion)——攻击者可以显着降低易受攻击模型的性能,通过三次注入后,大多数模型可以在功能上被破坏。除了 Facebook 和 IBM 发布的开源模型之外,本文攻击还针对当前部署的商业系统,包括 Microsoft 和 Google的系统。这一系列新颖的攻击对许多语言处理系统构成了重大威胁:攻击者可以有针对性地影响系统,而无需对底层模型进行任何假设。结论是,基于文本的 NLP 系统需要仔细的输入清理,就像传统应用程序一样,鉴于此类系统现在正在快速大规模部署,因此需要架构师和操作者的关注。
0x01 Introduction
x 和 х 在你看来是一样的吗?人类可能看它们相同,但大多数自然语言处理系统不同。字符串“123”中有多少个字符?如果你猜100,你是对的。第一个示例包含拉丁字符 x 和西里尔字符 h,它们通常以相同的方式呈现。第二个示例在可见字符之后包含 97 个零宽不连字(zero-width non-joiners)。
研究表明,机器学习系统在理论上和实践中都容易受到对抗样本的影响。此类攻击最初针对图像分类中使用的视觉模型,但最近对自然语言处理和其他应用程序产生了兴趣。本文对基于文本的模型提出了一大类强大的对抗样本攻击。这些攻击使用不可见字符、控制字符和同形文字(共享相似字形的不同字符编码)应用输入扰动。这些扰动对于基于文本系统的人类用户来说是察觉不到的,但是用于编码它们的字节可以极大地改变输出。
处理用户提供的文本的机器学习模型,例如神经机器翻译系统,特别容易受到这种攻击,例如市场领先的服务 Google Translate 。在撰写本文时,在英语到俄语模型中输入字符串“paypal”正确输出“PayPal”,但将输入中的拉丁字符 a 替换为西里尔字母 а 会错误地输出“папа”(英语中的“father”) . 模型管道对其字典外的字符不可知,并用 <unk> 标记替换它们;然而,调用它们的软件可能会将未知词从输入传播到输出。虽然这可能有助于对文本的一般理解,但它扩展了一个攻击面。
过去会使用简单的文本编码攻击来通过垃圾邮件过滤器获取邮件。比如2018年的SpamAssassin项目就曾有过关于如何处理零宽度字符的简单讨论,在一些sextortion骗局中已经发现了这个问题。从机器翻译到版权执法再到仇恨言论过滤,NLP 系统在大范围应用中的快速部署,创造了大量高价值目标。

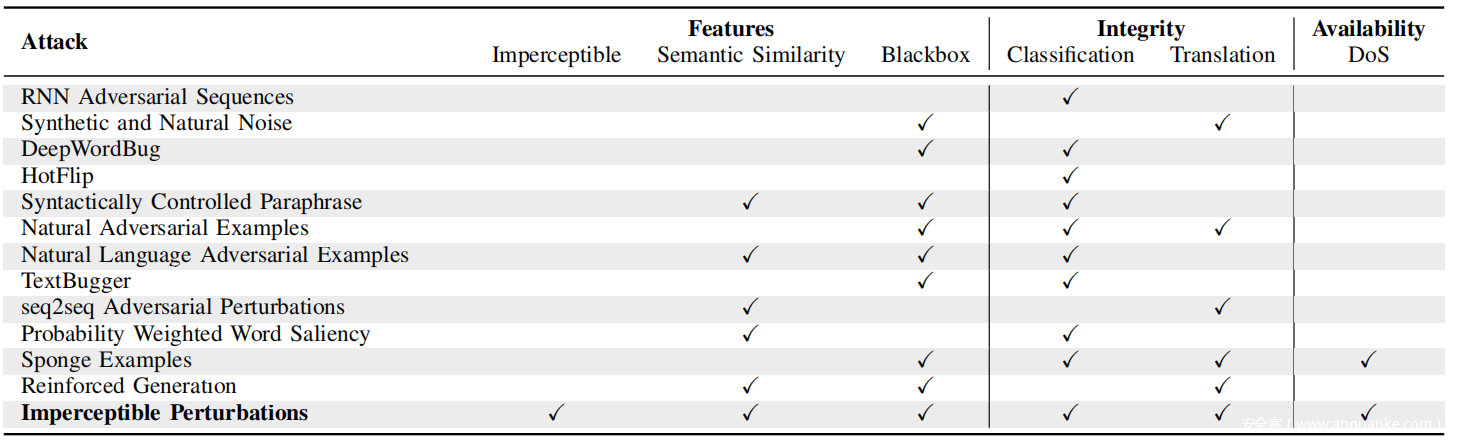
这项工作的主要贡献是探索和开发一类基于编码的难以察觉的攻击,并研究它们对现在大规模部署的 NLP 系统的影响。实验表明,此类系统的许多开发人员都忽视了风险;鉴于对利用未净化输入的多种系统进行攻击的悠久历史,这令人惊讶。在上表中提供了一组跨各种 NLP 任务的不可察觉攻击的示例。 正如稍后将描述的,这些攻击采用不可见字符、同形文字、重新排序和删除的形式,通过遗传算法注入,该算法最大化定义的损失函数每个 NLP 任务。
本文研究结果提出了一个攻击向量,在设计任何系统处理自然语言时必须考虑该向量,无论是直接从 API 还是通过文档解析,都可以使用现代编码摄取基于文本的输入。然后探索了一系列防御措施,可以针对这组强大的攻击提供一些保护,例如在标记化之前丢弃某些字符、限制字内字符集混合以及利用渲染和 OCR 进行预处理。但是,防御并非完全简单,因为应用程序要求和资源限制可能会阻止在某些情况下使用特定防御。
0x02 Motivation
研究人员已经尝试对 NLP 模型进行对抗攻击。然而,到目前为止,此类攻击对人工检查是显而易见的,并且可以相对容易地识别出来。如果攻击者插入单个字符的拼写错误,它们会显得格格不入,而释义通常会改变文本的含义,足以引起注意。在本文中讨论的攻击是针对现代 NLP 模型的第一类攻击,这些攻击是不可察觉的并且不会扭曲语义。
攻击在实践中会造成重大伤害。假设 Alice 破解了 Bob 的 Office365 帐户并更改了他的发票模板,使其仍然显示为“Pay account no. 123“,但在不知不觉中受到干扰,因此谷歌翻译会将其呈现为不同的帐号。然后 Bob 将这些带有陷阱的发票发送给他的客户,当 Carlos 用西班牙语读到一张发票时,他将钱转给 Alice。
通过使人类易于阅读但机器难以处理来隐藏文本的能力,可以被许多不良行为者用来逃避平台内容过滤机制,甚至阻碍执法和情报机构。同样的扰动甚至会阻止正确的搜索引擎索引,使恶意内容首先难以定位。发现生产搜索引擎不会解析不可见字符,并且可以通过精心设计的查询恶意定位。在最初撰写本文时,谷歌搜索“The meaning of life”返回了大约 9.9 亿条结果。在披露该问题之前,搜索包含 250 个不可见的“零宽不连字”的视觉上相同的字符串时,完全没有返回。
0x03 Related Work
A. 对抗样本
机器学习技术容易受到许多大类别的攻击,其中一个主要类别是对抗性样本。这些是模型的输入,在推理过程中这些输入会导致模型输出不正确的结果。在白盒环境中——攻击者知道模型——可以使用许多基于梯度的方法找到这样的样本,这些方法通常旨在在一系列约束下最大化损失函数。在模型未知的黑盒设置中,攻击者可以从另一个模型传输对抗样本,或者通过观察输出标签和在某些设置中的置信度来近似梯度。
训练数据也可能被毒化以操纵特定输入的模型准确性。在推理过程中可以引入位错误以降低模型的性能。还可以选择输入来最大化模型在推理过程中花费的时间或能量,或者通过推理技术公开机密的训练数据。换句话说,对抗性算法会影响机器学习系统的完整性、可用性和机密性。
B. NLP模型
自然语言处理 (NLP) 系统旨在处理人类语言。机器翻译早在 1949 年就被提出,并已成为 NLP 的一个关键子领域。机器翻译的早期方法往往是基于规则的,使用人类语言学家的专业知识,但随着该领域的成熟,统计方法变得更加突出,最终使用了神经网络,然后是循环神经网络 (RNN),因为拥有参考过去上下文的能力。当前最先进的技术是 Transformer 模型,它通过使用注意力机制在传统网络中提供了 RNN 和 CNN 的好处。
Transformer 是编码器-解码器模型的一种形式,将序列映射到序列。每种源语言都有一个编码器,可将输入转换为学习的跨语言,一种中间表示,然后使用与该语言关联的模型将其解码为目标语言。
无论用于翻译的模型的细节如何,自然语言都必须以可用作其输入的方式进行编码。最简单的编码是将单词映射到数字表示的字典,但这无法对以前看不见的单词进行编码,因此词汇量有限。 N-gram 编码可以提高性能,但会以指数方式增加字典大小,同时无法解决看不见的词问题。一种常见的策略是在编码之前将单词分解为子词段,因为这可以在许多情况下对以前看不见的单词进行编码和翻译。
C. 对抗性NLP
早期的对抗性机器学习研究侧重于图像分类,后来开始在 NLP 系统中搜索对抗性样本,目标是序列模型。由于自然语言的离散性,对抗样本本质上更难制作。与可以以近乎连续且几乎察觉不到的方式调整像素值以最大化损失函数的图像不同,对自然语言的扰动更加明显,并且涉及对更多离散标记的操纵。
更一般地,将提供针对人类用户的有效对抗样本的源语言扰动需要考虑语义相似性。研究人员提出使用基于单词的输入交换与同义词或基于字符的交换与语义约束。这些方法旨在将扰动限制为一组人类不太可能注意到的转换。神经机器翻译和文本分类模型通常在拼写错误等嘈杂输入上表现不佳,但这种扰动会产生清晰的视觉伪影(visual artifact),更容易被人类注意到。
使用具有相同含义的不同释义,而不是一对一的同义词,可能会提供更多的回旋余地。释义集可以通过比较大型文本语料库的机器反向翻译来生成,并用于系统地生成机器翻译系统的对抗性样本。还可以在嵌入空间中搜索输入句子的邻居;这些例子通常会导致低性能的翻译,使它们成为对抗样本的候选者。尽管释义确实有助于保留语义,但人们经常注意到结果看起来很奇怪。另一方面,本文攻击不会引入任何可见的扰动,使用更少的替换并完美地保留语义。
遗传算法已被用于发现对抗情绪分析系统输入的对抗性扰动,在黑盒设置中提出了一种可行的攻击,而无需访问梯度。强化学习可用于有效地为翻译模型生成对抗性样本。与本文中描述的技术不同,所有现有的 NLP 对抗性样本技术都会在输入中产生人类可感知的视觉伪影。
虽然 BLEU 通常用于评估自然语言设置中的各种准确度指标,但不太常见的相似度指标(例如 chrF)可能会为对抗样本提供更强的结果。未知标记 <unk>用于编码 NLP 设置中自然语言编码器无法识别的文本序列,由于编码为 <unk > 的字符的灵活性,可以利用它们来制作引人注目的源语言扰动。然而,迄今为止提出的用于生成 <unk> 的所有方法都使用可见字符。在下表中展示了对抗性 NLP 攻击的分类。
D. Unicode
Unicode 是一个字符集,旨在标准化文本的电子表示。在撰写本文时,它可以代表 143,859 个跨多种不同语言和符号组的字符。拉丁字母、繁体汉字、数学符号和表情符号等各种字符都可以用 Unicode 表示。它将每个字符映射到一个代码点或数字表示。
这些数字代码点通常用前缀 U+ 表示,可以用多种方式编码,尽管 UTF-8 是最常见的。这是一种将代码点表示为 1-4 个字节的可变长度编码方案。字体是描述应如何呈现代码点的字形集合。大多数计算机支持许多不同的字体。不需要字体的每个代码点都有一个字形,没有相应字形的代码点通常呈现为“未知”占位符字符。
E. Unicode安全
由于它必须支持全球广泛的语言集,Unicode 规范非常复杂。这种复杂性会导致安全问题,正如 Unicode 联盟关于 Unicode 安全考虑的技术报告中所详述的那样。
Unicode 规范中的一个主要安全考虑因素是多种编码同形文字的方法,同形文字是共享相同或几乎相同字形的独特字符。这个问题不是 Unicode 独有的;例如,在 ASCII 范围内,小写拉丁语“l”的呈现通常与大写拉丁语“I”几乎相同。在某些字体中,字符序列可以充当伪同形文字,例如大多数无衬线字体中的序列“rn”和“m”。
这种视觉技巧为网络诈骗者提供了一种工具。发现的最早的例子是 paypal.com(注意最后一个域名字符是大写的“I”),它在 2000 年 7 月被用来诱骗用户泄露 paypal.com 的密码。实际上,此后对 URL 中的同形文字给予了极大的关注。一些浏览器试图通过在导航时以小写形式呈现所有 URL 字符来纠正这种歧义,并且 IETF 设置了一个标准来解决非 ASCII 字符与 ASCII 字符同形异义词之间的歧义。该标准称为 Punycode,将非 ASCII URL 解析为仅限于 ASCII 范围的编码。
例如,大多数浏览器会自动将 URL paypаl.com(使用西里尔文 а)重新呈现为其 Punycode 等效项 xn–pypl-53dc.com,以突出显示潜在危险的歧义。但是,Punycode 可以引入新的欺骗机会。例如,URL xn–google.com 解码为四个语义上没有意义的繁体中文字符。此外,Punycode 无法解决 URL 之外的跨脚本同形文字编码漏洞。例如,单字形过去曾在各种非 URL 区域(例如证书通用名称)中造成安全漏洞。
Unicode 攻击也可以利用字符排序。某些字符集(例如希伯来语和阿拉伯语)自然地按从右到左的顺序显示。混合从左到右和从右到左文本的可能性,就像在阿拉伯报纸中引用英语短语一样,需要一个系统来管理混合字符集的字符顺序。对于 Unicode,这是双向 (Bidi) 算法。 Unicode 指定了多种控制字符,允许文档创建者微调字符顺序,包括允许完全控制显示顺序的两个双向覆盖字符。最终效果是,攻击者可以强制字符以不同于编码顺序的顺序呈现,从而允许由各种不同的编码序列表示相同的视觉呈现。
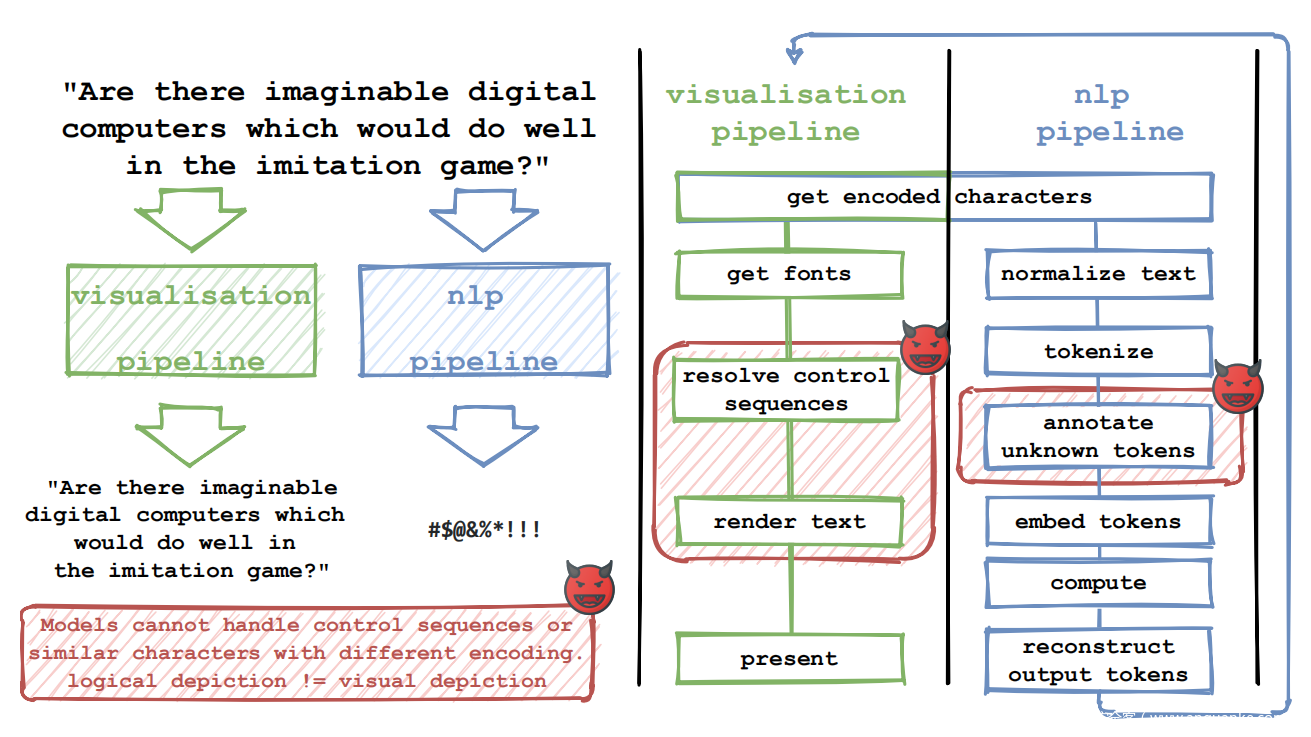
最后,一整类漏洞源于 Unicode 实现中的错误。这些历史上一直被用来产生一系列有趣的漏洞利用,很难概括。虽然 Unicode Consortium 确实发布了一组支持 Unicode 的软件组件,但许多操作系统、平台和其他软件生态系统都有不同的实现。例如,GNOME 生成 Pango,Apple 生成 Core Text,而 Microsoft 生成 Windows 的 Unicode 实现。在接下来的内容中,将主要忽略错误并专注于利用 Unicode 标准的正确实现的攻击。相反,利用了可视化和 NLP 管道之间的差距,如下图所示。
0x04 Background
A. 攻击分类
在本文中,探讨了基于 Unicode 和其他通常适用于基于文本的 NLP 模型的编码约定的不可察觉攻击类别。将每次攻击视为一种对抗样本,其中将难以察觉的扰动应用于现有基于文本的 NLP 模型的固定输入。将这些难以察觉的扰动定义为对文本字符串编码的修改,导致:
• 与未受干扰的输入相比,符合标准的渲染引擎不会对字符串的渲染进行视觉修改,
• 视觉上的修改足够微妙,以至于使用普通字体的普通人类读者不会注意到。
对于后一种情况,也可以通过两个字符串的渲染图像之间的计算机视觉模型或这种渲染之间的最大像素差异来代替人类的不可感知性作为不可区分性。考虑了对 NLP 模型的四种不同类别的不可察觉的攻击:
1) 不可见字符:按设计不呈现为可见字形的有效字符用于扰乱模型的输入。
2) 同形文字:呈现为相同或视觉上相似的字形的独特字符用于扰乱模型的输入。
3) 重新排序:方向性控制字符用于覆盖字形的默认渲染顺序,允许对用作模型输入的编码字节进行重新排序。
4) 删除:删除控制字符,例如退格符,被注入到一个字符串中,以从其视觉渲染中删除注入的字符,以扰乱模型的输入。
这些对 NLP 模型的基于文本的难以察觉的攻击代表了一种抽象的攻击类别,独立于不同的文本编码标准和实现。出于具体样本和实验结果的目的,将假设几乎无处不在的 Unicode 编码标准,相信本文结果可推广到任何具有足够大字符和控制序列集的编码标准。
存在更多基于文本的攻击类别,但所有其他攻击类别都会产生视觉假象。本文中描述的基于文本的难以察觉的攻击可用于广泛的 NLP 模型。正如稍后解释的那样,不可察觉的扰动可以操纵机器翻译,破坏投毒内容分类器,降低搜索引擎查询和索引,并为DoS攻击生成sponge样本,以及其他可能性。
B. NLP管道
现代 NLP 管道经过数十年的研究发展,包括大量性能优化。在模型推断之前,基于文本的输入经历了许多预处理步骤。通常,分词器首先以对任务有意义的方式应用于分离单词和标点符号,例如本文稍后评估的 Fairseq 模型中使用的 Moses 分词器。然后对标记化的词进行编码。早期的模型使用字典将标记映射到编码的嵌入,在训练期间看不到的标记被替换为一个特殊的<unk>嵌入。许多现代模型现在在字典查找之前应用字节对编码 (BPE) 或 WordPiece 算法。 BPE(一种常见的数据压缩技术)和 WordPiece 都可以识别标记中的常见子词。这通常会提高性能,因为它允许模型从语素中获取有关语言语义的额外知识。这两种预处理方法通常用于部署的 NLP 模型,包括本文评估的 Facebook 和 IBM 发布的所有三个开源模型。
如前图所示,现代 NLP 管道以与文本渲染系统非常不同的方式处理文本,即使处理相同的输入也是如此。 NLP 系统处理人类语言的语义,而渲染引擎处理大量不同的控制字符。模型所见与人类所见之间的这种结构差异是在攻击中所利用的。
C. 攻击方法
将对抗样本的生成视为一个优化问题。 假设 NLP 函数 f(x) = y : X → Y 将文本输入 x 映射到 y。 根据任务,Y 是字符、单词或热编码类别的序列。 例如,WMT 等翻译任务假定 Y 是字符序列,而 MNLI 等分类任务假定 Y 是三个类别之一。 此外假设一个强大的黑盒威胁模型,其中攻击者可以访问模型输出但无法观察内部结构。 这使攻击变得现实:稍后证明它可以安装在现有的商业 ML 服务上。 在这个威胁模型中,攻击者的目标是使用扰动函数 p 在不知不觉中操纵 f。 这些操作分为两类:
• 完整性攻击:攻击者的目标是找到满足 f(p(x)) = f(x) 的 p。对于有针对性的攻击,攻击者进一步约束 p,使得扰动输出与固定目标 t 匹配:f(p(x)) = t。
• 可用性攻击:攻击者的目标是找到 p 使得 time(f(p(x))) > time(f(x)),其中 time 度量 f 的推理运行时间。
定义对扰动函数 p 的约束:
• Budget:budget b 使得 dist(x, p(x)) ≤ b。函数 dist 可以指任何距离度量。
将攻击定义为优化对输入文本的一组操作,其中每个操作对应于注入一个短的 Unicode 字符序列,以对所选类执行单个不可察觉的扰动。注入序列的长度取决于选择的类和攻击实现;在评估中,使用一个字符注入用于不可见字符和同形字,两个字符用于删除,十个字符用于重新排序。选择了一种无梯度优化方法 – 差分进化- 使这种攻击能够在黑盒设置中工作,而无需恢复近似梯度。这种方法随机初始化一组候选者,并在多次迭代中对它们进行进化,最终选择表现最佳的特征。攻击算法如算法 1 所示。它以参数函数 A 为参数,在给定输入字符串和扰动编码的情况下,返回一个扰动字符串,允许该算法用于所有四类不可察觉的扰动。

D. 不可见字符
不可见字符是经过编码的字符,可以在没有字形的情况下进行渲染,并且在生成的渲染中不占用空间。不可见字符通常不是特定于字体的,而是遵循编码格式的规范。 Unicode 中的一个示例是零宽度空格字符 12 (ZWSP)。下图显示了使用隐形字符进行攻击的示例。

需要注意的是,在特定字体中缺少字形定义的字符通常不会被视为不可见字符。由于 Unicode 和其他大型规范中的字符数,字体通常会省略稀有字符的字形定义。例如,Unicode 支持来自古代迈锡尼文字 Linear B 的字符,但这些字形定义不太可能出现在以现代语言(如英语)为目标的字体中。然而,大多数文本渲染系统保留一个特殊字符,通常为□或? , 用于没有相应字形的有效 Unicode 编码。因此,这些字符在呈现的文本中可见。
但实际上,不可见字符是特定于字体的。即使某些字符被设计为具有非字形渲染,细节仍由字体设计者决定。例如,它们可能通过将相应的 Unicode 代码点打印为基数为 10 的数字来呈现所有传统上不可见的字符。然而,少数字体主宰了现代计算世界,常用字体尊重 Unicode 规范。出于本文的目的,将使用 GNU 的 Unifont13 字形来确定字符可见性。 Unifont 之所以被选中,是因为它对当前 Unicode 标准的覆盖范围相对较广,它与常见操作系统的分布以及它与其他常见字体的视觉相似性。
尽管不可见字符不会产生渲染字形,但它们仍然代表有效的编码字符。基于文本的 NLP 模型将编码字节作为输入进行操作,因此这些字符将被基于文本的模型“看到”,即使它们没有被呈现为人类用户可感知的任何东西。发现这些字节改变了模型输出。当任意注入模型的输入时,它们通常会降低准确性和运行时间方面的性能。当以有针对性的方式注入时,它们可用于以所需的方式修改输出,并且可以在许多 NLP 任务中连贯地改变输出的含义。
E. 同形文字
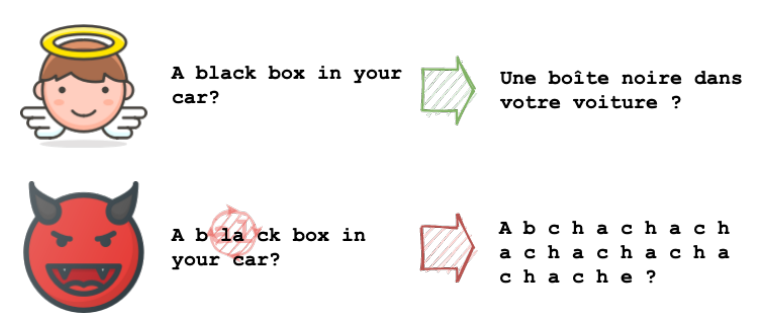
同形文字是呈现为相同字形或视觉上相似字形的字符。当在不同的语言系列中使用同一书面脚本的部分时,通常会发生这种情况。例如,考虑英语中使用的拉丁字母“A”。西里尔字母中使用了非常相似的字符“А”。在 Unicode 规范中,这些是不同的字符,尽管它们通常呈现为同形文字。

上图显示了使用同形文字进行攻击的示例。与不可见字符一样,同形文字是特定于字体的。即使底层语言系统以相同的方式表示两个字符,字体也不需要尊重这一点。也就是说,在日常计算中使用的最常见字体中有众所周知的同形文字。
Unicode Consortium 与 Unicode Security Mechanisms 技术报告 一起发布了两个支持文档,以引起对类似渲染字符的关注。第一个文档定义了一个字符映射,这些字符在 Unicode 规范中是同形的,因此应该映射到字体实现中的相同字形。第二个文档定义了一组可能在视觉上混淆的字符,即使它们不是用完全相同的字形呈现的。
对于本文中的实验,使用 Unicode 技术报告来定义同形字符映射。还注意到,可以使用无监督聚类算法针对表示渲染字形的向量来识别同形文字,特别是对于特定的不太常见的字体。为了说明这一点,使用 VGG16卷积神经网络 将 Unifont 字体中的所有字形转换为矢量化嵌入并执行各种聚类操作。下图将 Unicode 技术报告提供的映射可视化为降维字符簇图。发现经过良好调整的无监督聚类算法的结果产生了类似的结果,但为了重现性,选择使用本文中的官方 Unicode 映射。

F. 重新排序
Unicode 规范支持从左到右和从右到左方向读取的语言中的字符。当这些脚本混合在一起时,管理起来就变得很重要了。 Unicode 规范定义了双向 (Bidi) 算法以支持混合脚本文档的标准渲染行为。但是,该规范还允许使用不可见的方向覆盖控制字符覆盖 Bidi 算法,这允许对固定编码顺序进行近乎任意的渲染。
上图显示了使用重新排序的攻击示例。在对抗性设置中,Bidi 覆盖字符允许修改字符的编码顺序而不影响字符渲染,从而使它们成为一种难以察觉的扰动形式。
与不可见字符和同形文字攻击不同,重新排序攻击的类别与字体无关,并且仅依赖于 Unicode Bidi 算法的实现。 Bidi 算法实现有时在处理特定覆盖序列的方式上有所不同,这意味着某些攻击在实践中可能是特定于平台或应用程序的,但大多数成熟的 Unicode 渲染系统的行为相似。算法 2 定义了一种算法,用于使用嵌套的 Bidi 覆盖字符为长度为 n 的字符串生成 2^(n-1)个唯一的重新排序。在撰写本文时,它已经过测试,可以与 Chromium 中的 Unicode 实现相适应。

当使用通过轻微重新排序(例如标准数字)保留语义有效性的数据时,重新排序攻击特别阴险。例如,考虑字符串“Please send money to account 1234.”。通过一次重新排序,这可以呈现为“Please send money to account 2134.”。 在NLP模型推断中丢弃孤立的重新排序控制字符是很常见的,因为它们通常作为通用的<unk>标记嵌入。因此,在向用户可视化之前通过 NLP 管道(例如机器翻译)的银行指令可能会导致恶意结果。
G. 删除
Unicode 中的少量控制字符可能会导致相邻文本被删除。最简单的例子是退格 (BS) 和删除 (DEL) 字符。还有回车 (CR),它会导致文本呈现算法返回到行首并覆盖其内容。例如,表示“Hello CRGoodbye World”的编码文本将呈现为“Goodbye World”。

上图显示了使用删除攻击的示例。删除攻击与字体无关,因为 Unicode 不允许对从 ASCII 继承的基本控制字符(包括 BS、DEL 和 CR)进行字形规范。一般来说,删除攻击也与平台无关,因为 Unicode 删除实现没有显着差异。然而,这些攻击在实践中可能更难利用,因为大多数系统不会将删除的文本复制到剪贴板。因此,使用删除扰动的攻击通常需要攻击者将编码的 Unicode 字节直接提交到模型中,而不是依赖受害者的复制+粘贴功能。
0x05 NLP攻击
A. 完整性攻击
无论 NLP 模型中使用了何种分词器或字典,系统都不太可能在没有特定防御的情况下优雅地处理难以察觉的扰动。针对 NLP 模型的完整性攻击利用这一事实,以有针对性或无针对性的方式降低模型性能。
尽管对这种扰动的响应在不同的模型之间有所不同,但最有可能的管道是,所有不熟悉的字符都嵌入了一个表示所有未知标记的特殊向量<unk>。该<unk>向量虽然是一种特殊情况,但通常在嵌入变换后由模型处理,与任何其他字符没有区别。对输入嵌入变换的具体影响取决于所使用的扰动类别:
•不可见字符(单词之间):不可见字符被转换为适当嵌入相邻单词之间的<unk>嵌入。
•不可见字符(字内):除了转换为<unk>嵌入之外,不可见字符可能导致包含该字符的字作为多个较短的字嵌入,从而干扰标准处理。
•同形文字:如果模型词典中存在包含同形文字的标记,则包含同形文字的单词将嵌入由此类数据创建的较不常见且可能性能较低的向量。如果同形符未知,则标记将作为<unk>嵌入。
•重新排序:除了Bidi覆盖字符(每个字符都被视为不可见字符)外,输入模型的其他字符将按照基本编码顺序而不是呈现顺序。
•删除:除了删除控制字符(每个字符都被视为不可见字符)外,编码到输入中的已删除字符仍由模型有效处理。
对嵌入式输入的每一次修改都会降低模型的性能。原因是特定于模型的,但对于基于注意的模型,希望<unk>标记上下文中的标记会得到不同的处理。
B. 可用性攻击
机器学习系统可能会受到异常缓慢的工作负载的攻击。产生这种计算的输入称为海绵样本(Sponge Examples)。最初使用遗传算法生成给定恒定大小的海绵样本,可以显著降低翻译速度,但通过算法创建的海绵样本最终在语义上毫无意义。事实上,这些例子往往最终使用汉字作为模型的输入,而这些模型假设输入为其他语言。
在本文中展示了海绵样本可以有针对性地构造,包括固定的和增加的输入大小。例如,对于固定大小的海绵,攻击者可以将单个字符替换为外观相同但处理时间较长的字符。如果可以容忍输入大小的增加,攻击者还可以注入不可见字符,迫使模型花费额外的时间来处理其输入序列中的这些额外步骤。
如果输入的视觉外观没有引起用户的怀疑,则可以更隐蔽地进行此类攻击。如果大规模并行启动,托管NLP模型的可用性可能会降低,这表明分布式拒绝服务攻击可能在文本处理服务上可行。
0x06 Evaluation
A. 实验设置
针对三个 NLP 任务:机器翻译、投毒内容检测和文本蕴涵分类,评估了每一类不可感知扰动攻击的性能——不可见字符、同形文字、重新排序和删除。根据谷歌、Facebook、微软和 IBM 发布的三个开源模型和三个闭源商业模型的集合来执行这些评估。重复每个实验,扰动值从 0 到 5 不等。
所有实验都是在黑盒环境中进行的,其中允许无限制的模型评估,但不允许访问评估模型的权重或状态。这代表了最强大的威胁模型之一,几乎在所有环境中都可能对其进行攻击,包括针对商业机器学习即服务 (MLaaS) 产品。检查的每个模型都容易受到难以察觉的扰动攻击。这些攻击的适用性在理论上应该推广到任何没有适当防御的基于文本的 NLP 模型。
对所有三个 NLP 任务执行非针对性攻击,对于文本蕴涵分类,还使用输出概率访问和仅输出标签设置执行有针对性的攻击。还对翻译任务执行海绵样本攻击。实验是在一组机器上进行的,每个机器都配备了 Tesla P100 GPU 和运行 Ubuntu 的 Intel Xeon Silver 4110 CPU。
对于每一类扰动,按照算法 1 定义了一个目标函数,该函数旨在最大化评估模型的扰动和未扰动输入的输出之间的距离,或者在有针对性的攻击的情况下,寻求最大化这些的分类概率选定的目标。在这些目标函数中使用了 Levenshtein 距离,但实际上可以选择任何度量。然后进行了差分进化,发现优化很快收敛,因此在遗传算法中使用了 32 的种群大小,最多 10 次迭代。进一步增加这些参数可能会让攻击者找到更有效的扰动;即实验结果获得了一个下限。
对于这些实验中使用的目标函数,从包括 ZWSP、ZWNJ 和 ZWJ17 的集合中选择不可见字符;根据相关的 Unicode 技术报告 18 选择了同形文字集;重新排序是从使用算法 2 定义的集合中选择的,删除是从所有非控制 ASCII 字符后跟一个 BKSP19 字符的集合中选择的。将扰动budget的单位值定义为一个注入的不可见字符、一个同形字符替换、一个根据重新排序算法的 Swap 序列或一个 ASCII-退格删除对。
发布了一个用 Python 编写的命令行工具来进行这些实验以及这些实验产生的整个对抗样本集(github.com/nickboucher/imperceptible )。 还发布了一个在线工具(imperceptible.ml),用于验证文本是否可能包含不可察觉的扰动和生成随机不可察觉的扰动。在以下部分中,将详细描述每个实验。
B. 机器翻译:完整性
对于机器翻译任务,使用了在 Facebook 发布的 WMT14 数据上预训练的英法转换器模型,作为 Fairseq 的一部分,Facebook AI Research 的开源 ML 工具包用于序列建模。利用相应的 WMT14 测试集数据为每个对抗样本提供参考翻译。

对于完整性攻击集,为 500 个句子制作了对抗样本,并针对 0 到 5 的扰动budget重复对抗生成。每个样本平均需要 432 秒来生成。对于生成的对抗样本,将生成的翻译的 BLEU 分数与上图中的参考翻译进行比较。还在下图中提供了这些值之间的 Levenshtein 距离,该距离随着距离最大的重新排序近似线性增加。
C. 机器翻译:可用性
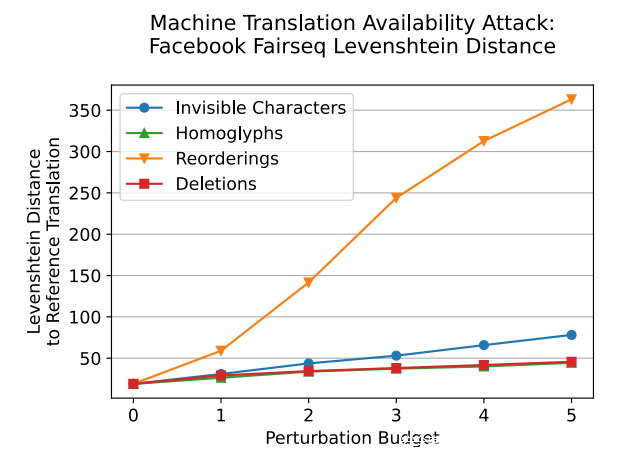
除了对机器翻译模型完整性进行攻击之外,还探索了是否可以发起可用性攻击。这些攻击采用海绵样本的形式,这些样本是为了最大化推理运行时间而精心制作的对抗样本。使用与完整性实验相同的配置,为 500 个句子制作对抗样本,扰动budget为 0 到 5。每个样本平均需要 420 秒来生成。
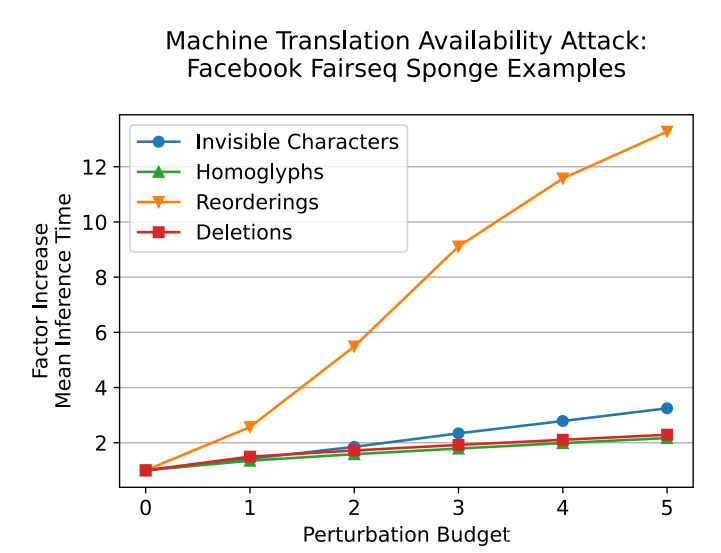
上图显示了针对 Fairseq 英法模型的海绵样本结果,该图表明重新排序攻击在某些方面是最有效的。尽管减速不如 通过将中文字符放入俄语文本所实现的那么显着,但攻击在语义上是有意义的,并且不会被人眼察觉。
D. 机器翻译:MLaaS
除了对 Fairseq 开源翻译模型的完整性攻击之外,还对两个流行的机器学习即服务 (MLaaS) 产品进行了一系列案例研究:Google Translate 和 Microsoft Azure ML。这些实验证明了这些攻击在现实世界中的适用性。在此设置中,翻译推理涉及基于 Web 的 API 调用,而不是调用本地函数。

由于这些服务的成本,针对从 0 到 5 的 20 个budget句子的完整性制作了对抗样本,并将最大进化迭代值降低为 3。针对 Google Translate 和 Microsoft Azure ML 的测试的 BLEU 结果如下图。相应的 Levenshtein 结果如上图。
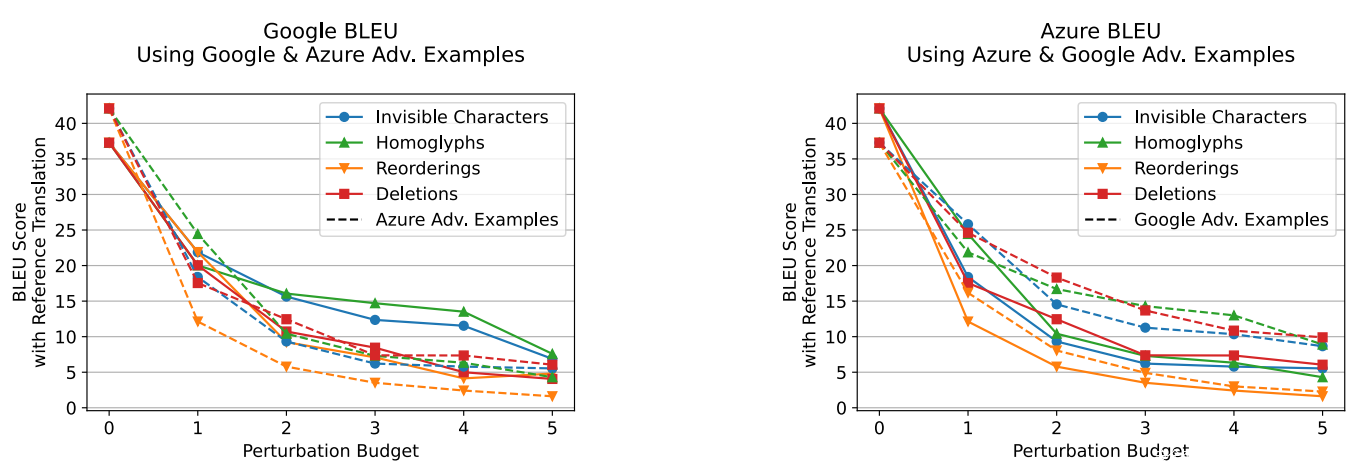
有趣的是,针对每个平台生成的对抗样本似乎对另一个平台有效。上图中将每个服务的对抗样本的 BLEU 分数绘制为虚线。这些结果表明,可以在模型之间转移难以察觉的对抗样本。
E. 投毒内容检测
在这项任务中,试图击败投毒内容检测器。对于实验,使用 IBM 发布的开源投毒内容分类器模型。在这种情况下,攻击者可以访问模型发出的分类概率。
对于这组实验,为 Wikipedia Detox 数据集中标记为投毒的 250 个句子制作了对抗样本,扰动budget从 0 到 5。每个样本平均需要 18 秒来生成。
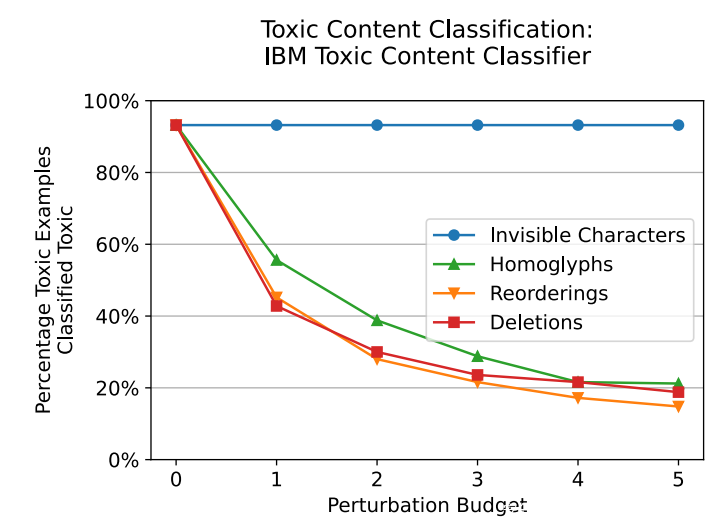
IBM 投毒内容分类扰动结果如上图所示。同形文字、重新排序和删除有效地将模型性能降低了 75%,但有趣的是,不可见字符对模型性能没有影响。这可能是因为训练数据中存在不可见字符并进行了相应学习,或者更有可能的是,该模型使用了忽略不可见字符的标记器。
F. 投毒内容检测:MLaaS
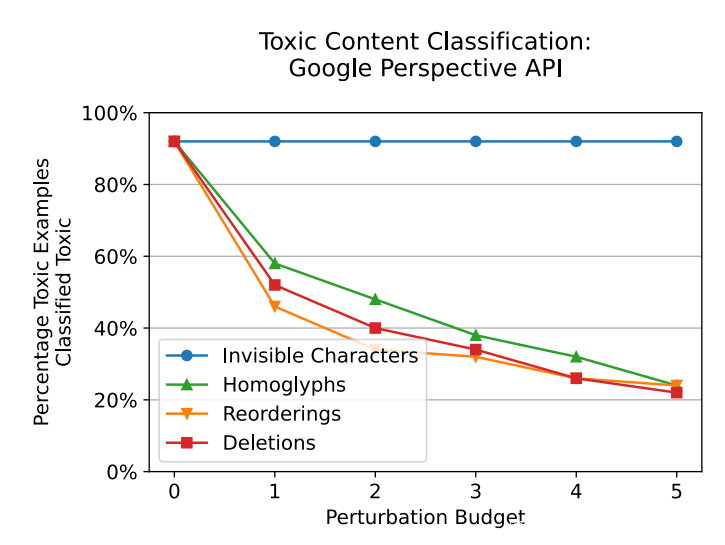
针对 Google 的 Perspective API重复了投毒内容实验,该 API 在现实世界中大规模部署用于投毒内容检测。使用了与 IBM 投毒内容分类实验相同的实验设置,只为 50 个句子生成了对抗样本。结果见下图。
G. 文本蕴涵:无针对性
识别文本蕴涵是一项文本序列分类任务,需要将一对句子之间的关系标记为蕴涵、矛盾或中性。对于文本蕴涵分类任务,使用在 MNLI 语料库上微调的预训练 RoBERTa 模型进行了实验。该模型由 Facebook 作为 Fairseq的一部分发布。
对于这些文本包含完整性攻击,为 500 个句子制作了对抗样本,并为 0 到 5 的扰动budget重复生成对抗样本。本实验中使用的句子取自 MNLI 测试集。生成每个样本平均需要 51 秒。该实验的结果如下图所示。 即使budget为 1,性能也会显着下降。
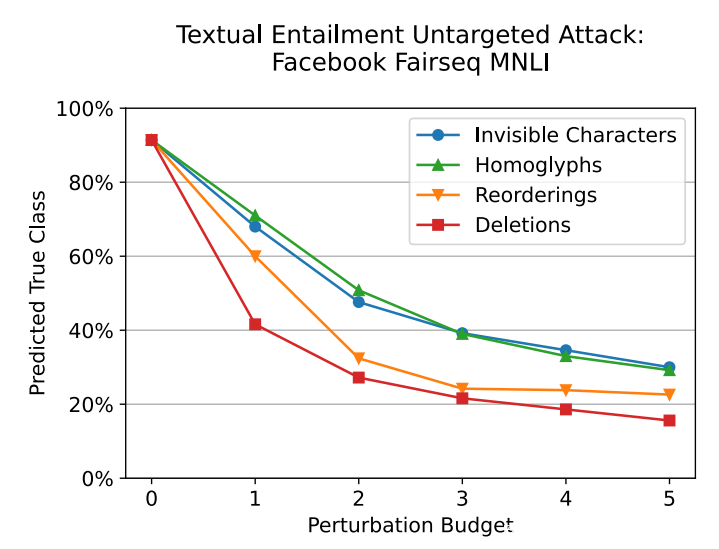
H. 文本蕴涵:有针对性
在针对性攻击的完整性实验中重复了一组文本蕴含分类。对于每个句子,尝试针对三个可能的输出类别中的每一个制作一个对抗样本。自然地,这些类之一是正确的未扰动类,因此预计budget = 0 结果的成功率约为 33%。由于每个句子的对抗样本数量增加,为 100 个句子制作了对抗样本,并针对 0 到 5 的扰动budget重复生成对抗样本。结果如下图所示。

在第一组有针对性的文本蕴涵实验中,允许攻击者访问分类模型输出的完整 logits 集。换句话说,差分进化算法可以访问分配给每个可能输出类别的概率值。第二次重复了目标文本蕴涵实验,其中攻击者只能访问选定的输出标签,而没有概率值。这些结果在上图中绘制为虚线。仅标签攻击似乎只有轻微的劣势,甚至随着扰动budget的增加,这种劣势也会减弱。
0x07 Discussion
A. 攻击潜力
来自操纵Unicode编码的难以察觉的扰动为基于文本的 NLP 模型提供了广泛而强大的攻击类别。它们使攻击者能够:
• 改变机器翻译系统的输出;
• 避开投毒内容检测;
• 无形中毒化NLP 训练集;
• 对索引系统隐藏文档;
• 降低搜索质量;
• 对 NLP 系统进行拒绝服务攻击。
这些扰动使用有效但不寻常的编码来欺骗采用常见编码形式的 NLP 系统。当从系统安全的角度查看基于文本的自然语言处理系统时,由此产生的漏洞就很明显了。从事过 Web 应用程序的每个人都知道不要将不受约束的用户输入作为 SQL 查询的输入,甚至不要将其输入到有限长度的缓冲区中。随着 NLP 系统在广泛的应用程序中迅速获得认可,他们的开发人员将不得不吸取操作系统开发人员从莫里斯蠕虫中学到的教训,以及网络开发人员在互联网热潮中吸取的教训。
也许难以察觉的扰动攻击最令人不安的方面是它们的广泛适用性:测试的所有基于文本的 NLP 系统都容易受到影响。对抗性含义可能因一个应用程序而异,从一个模型到另一个模型,但所有基于文本的模型都基于编码文本,除非编码受到适当约束,否则所有文本都受对抗性编码的影响。
B.搜索引擎攻击
编码字节与其视觉呈现之间的差异会影响搜索和索引系统。搜索引擎攻击分为两类:搜索攻击和索引攻击。
攻击来自受干扰的搜索查询的搜索结果。大多数系统通过比较已编码的搜索查询和有索引的资源集来进行搜索。在对搜索的攻击中,攻击者的目标是降低结果的质量或数量。扰动的查询会干扰比较。
对索引的攻击使用扰动来隐藏搜索引擎的信息。即使被扰动的文档可能会被搜索引擎的爬虫抓取,用于索引它的术语也会受到扰动的影响,使得它不太可能从对未受扰动的术语的搜索中出现。因此,可以“在视线范围内”从搜索引擎中隐藏文档。例如,一家不诚实的公司可能会在其财务文件中掩盖负面信息,以便股票分析师使用的专业搜索引擎无法找到它。
C. 防御
在这里提出各种防御不可察觉的扰动攻击的方法。这些防御措施不会解决 NLP 中出现的所有与编码相关的问题;编码问题和一般输入噪声(例如拼写错误)之间存在一条模糊的界线,这是一个开放性问题。然而,防御可以显着减少当前 NLP 系统暴露于非标准编码的攻击面。
鉴于此攻击的概念来源源于逻辑和视觉文本编码表示的差异,一个解决方案是呈现所有输入,使用光学字符识别 (OCR) 对其进行解释,并将输出输入到原始文本模型中。这种通用防御会导致对附加模型进行推理的计算和能源成本,这可能不适合某些应用程序。
1) 不可见字符防御:一般来说,可见字符不影响文本的语义,但与格式问题有关。对于许多基于文本的 NLP 应用程序,在推理之前从输入字符串中删除一组标准的不可见字符将阻止不可见字符攻击。
如果应用程序要求不允许它丢弃这些字符,则必须以某种方式处理它们。如果在推理过程中某些不可见字符不能被忽略有语言上的原因,那么标记器必须将它们包含在源语言词典中,从而产生一个非<unk>的嵌入向量。

2) 同形文字防御:同形文字集通常源于Unicode 包含许多字母表的事实,其中一些字母表具有相似的字符。虽然多语言使用者经常会在同一个句子中混合来自不同语言的单词和短语,但在同一个单词中使用来自不同语言的字符是非常罕见的。也就是说,词间语族混合是常见的,但词内混合的情况要少得多。例如,见上表。方便的是,Unicode 规范将代码点划分为不同的命名块,例如“基本拉丁语”。在设计时,模型设计者可以将块分组到语言族中。但是当你发现一个输入词包含来自多个语系的字符时,你会怎么做?如果你丢弃它,它本身就会创建一个攻击向量。在许多应用中,稳健的行动方案可能是停止并发出警报。如果应用程序不允许这样做,另一种方法是为每个单词仅保留来自单个语族的字符,将所有词内混合字符映射到主要语族中的同形文字。
3) 重排序防御:对于一些具有图形用户界面的基于文本的 NLP 模型,可以通过在输入显示给活动用户时剥离所有 Bidi 覆盖字符来防止重排序攻击。但这不适用于缺少可视化用户界面的界面,或者将英语等从左到右的语言与希伯来语等从右到左的语言混合在一起的界面。在此类应用程序中,如果在输入中检测到 Bidi 覆盖字符,则可能需要在模型的输出中返回警告。
4)删除防御:怀疑删除字符是模型的有效输入的用例可能并不多。如果用户通过普通的图形表单字段输入文本,则在将键入的文本传递给模型之前,文本渲染引擎将处理删除字符。
但是,如果攻击者能够直接将编码文本注入模型,则必须对删除攻击给予一定的关注。 一种可能的防御是对模型输入进行预处理,以便在模型处理输入之前对删除字符进行操作。 或者,当检测到删除字符时,模型可能会抛出错误。
0x08 Conclusion
基于文本的 NLP 模型容易受到一大类难以察觉的扰动的影响,这些扰动可以改变模型输出并增加推理运行时间,而无需修改输入的视觉外观。这些攻击利用语言编码功能,例如不可见字符和同形文字。尽管过去偶尔会在垃圾邮件和网络钓鱼诈骗中看到它们,但现在大规模部署的许多 NLP 系统的设计者似乎完全忽略了它们。
本文已经对针对 NLP 系统的文本编码漏洞进行了系统的探索。对这些攻击进行了分类,并详细探讨了它们如何被用来误导和毒化机器翻译、投毒内容检测和文本蕴涵分类系统。事实上,它们可以用于处理自然语言的任何基于文本的 ML 模型。此外,它们可用于降低搜索引擎结果的质量并隐藏索引和过滤算法中的数据。
本文针对此类攻击提出了多种防御措施,并建议所有构建和部署基于文本的 NLP 系统的公司都实施此类防御措施,如果他们希望他们的应用程序对恶意行为者具有鲁棒性。







发表评论
您还未登录,请先登录。
登录