

前言
对抗样本大家都耳熟能详了,但是大家可能觉得离自己比较远,毕竟主要是学术界在做这方面的工作,可能还需要很多数学理论基础,所以没有尝试动手实践过。在本文中,不会提及高深的数学理论,唯一的公式也仅是用于形式化描述攻击方案,并不涉及任何数学概念,同时以代码为导向,将论文中提出的方案进行实践,成功实施对抗样本攻击,之后给出了典型的防御方案,即对抗训练,同样也是以实战为导向,证明防御方案的有效性。对抗样本领域的研究正热火朝天,本文提及的攻击和防御方案并不是最优的,希望感兴趣的师傅们看了本文后,能够不再对该领域抱有排斥心理,加入对抗样本的研究队伍中来,为AI安全贡献自己的力量。
模型搭建及评估
本次我们使用的数据集是Fashion MNIST。Fashion-MNIST是一个替代MNIST手写数字集的图像数据集。 它是由Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自10种类别的共7万个不同商品的正面图片。Fashion-MNIST的大小、格式和训练集/测试集划分与原始的MNIST完全一致。60000/10000的训练测试数据划分,28×28的灰度图片.
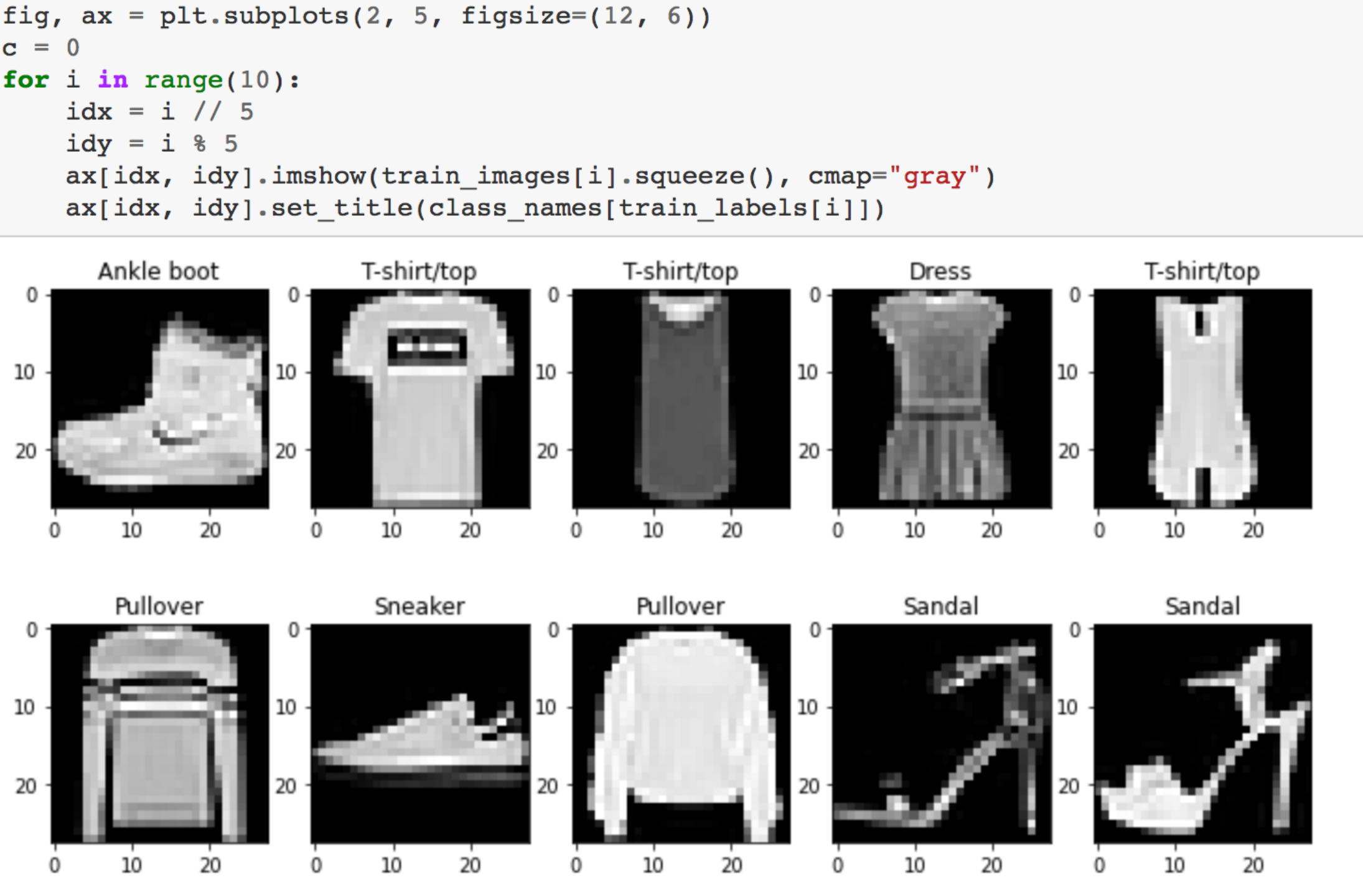
数据集大致如下所示

上图中每一类有3行,10个类别分别是T-shirt/top’, ‘Trouser’, ‘Pullover’, ‘Dress’, ‘Coat’,’Sandal’, ‘Shirt’, ‘Sneaker’, ‘Bag’, ‘Ankle boot’
首先加载数据集

我们需要简单的对数据集预处理,给其添加一个channel维度,否则卷积层不能正常工作,还需要将像素值缩放到[0,1]范围

接下来打印出实际加载的样本看看
因为图片是灰度图像,所以输入的shape定义如下

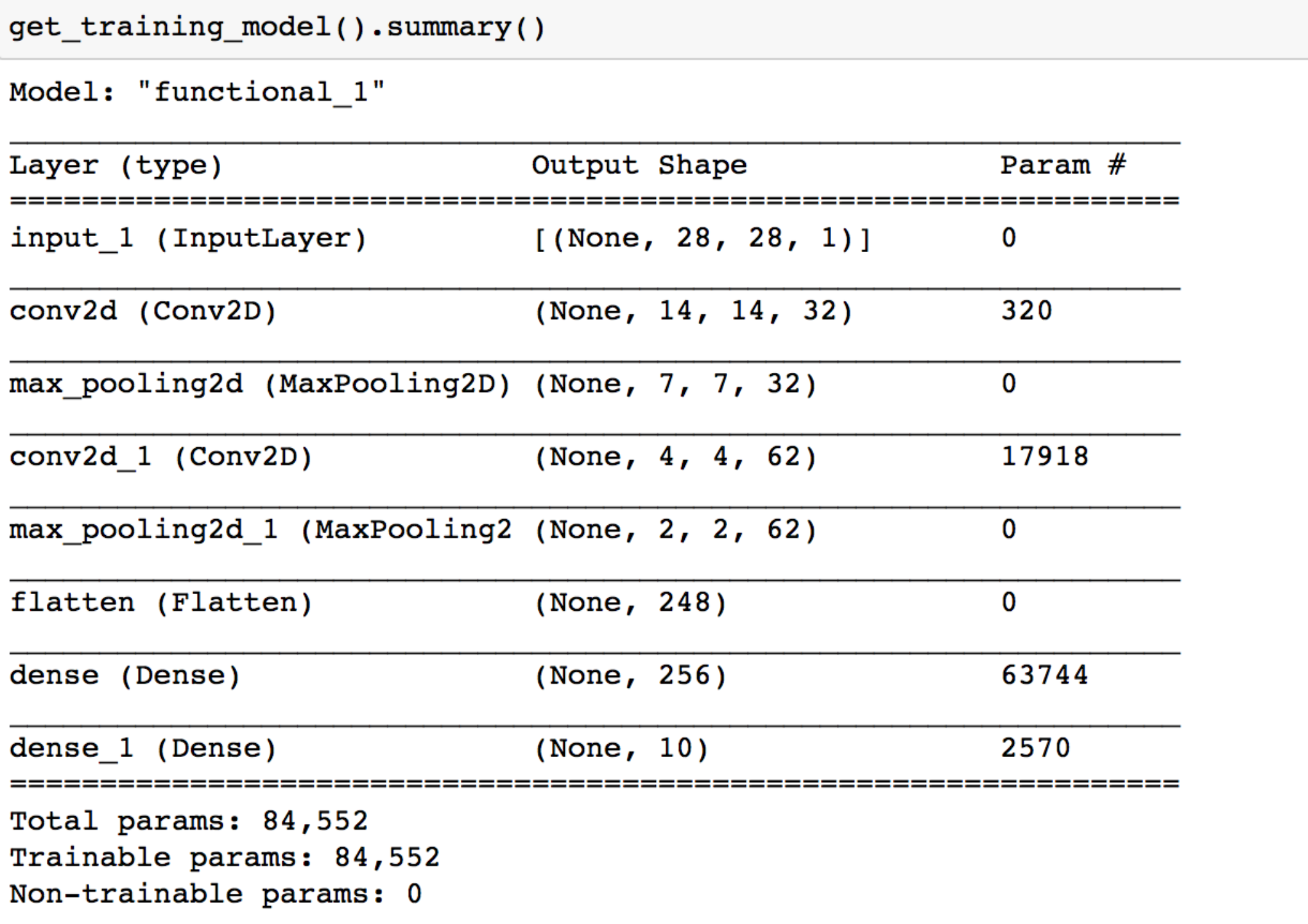
接下来搭建一个CNN模型,架构如下

使用summary方法输出各层的参数状况
设置优化器、损失函数、batch size等超参数

我们再定义一个辅助函数,用于绘出训练过程相关度量指标的变化

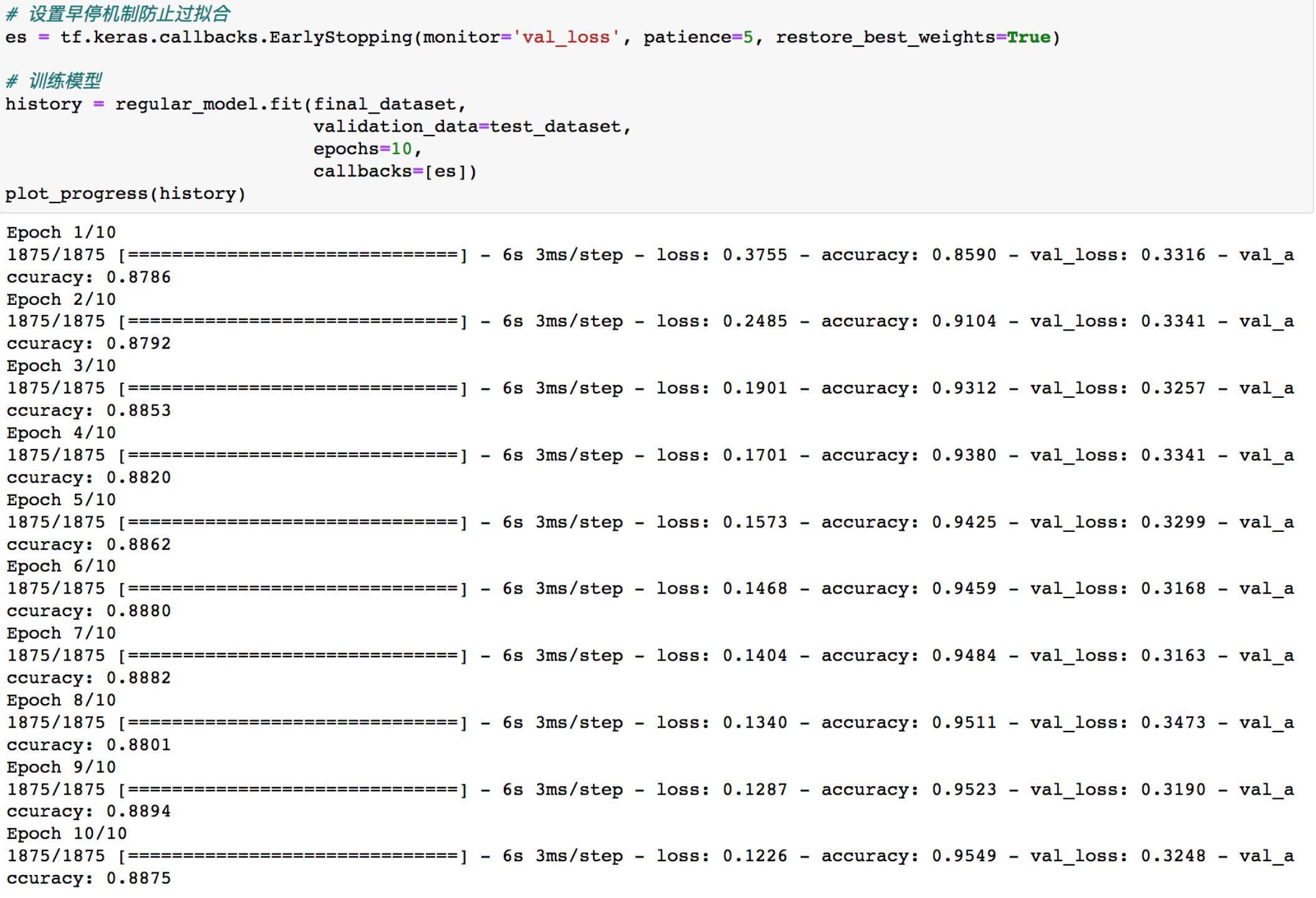
接下来开始训练模型

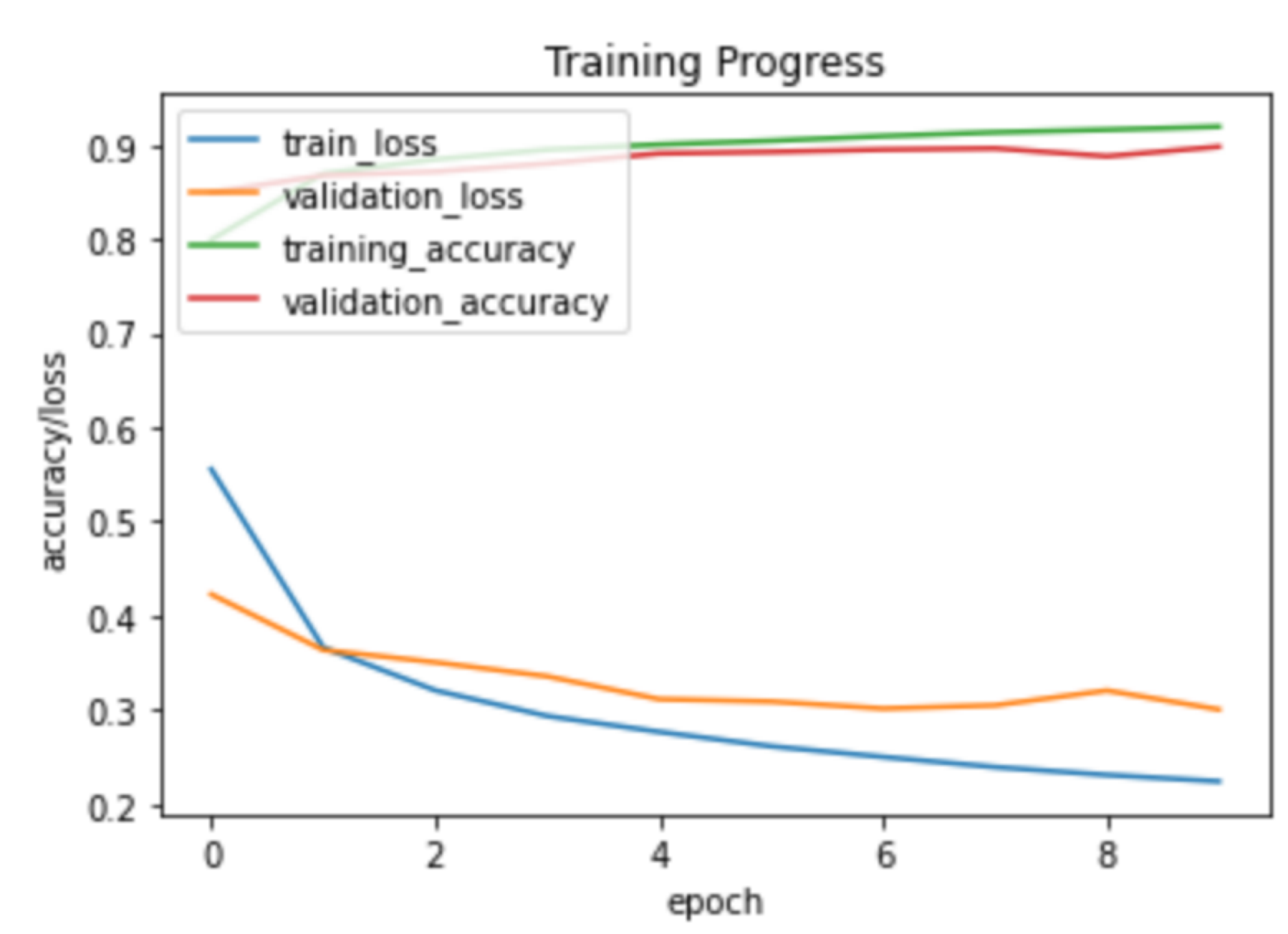
使用前面定义的绘图函数画出模型训练过程的指标的变化情况
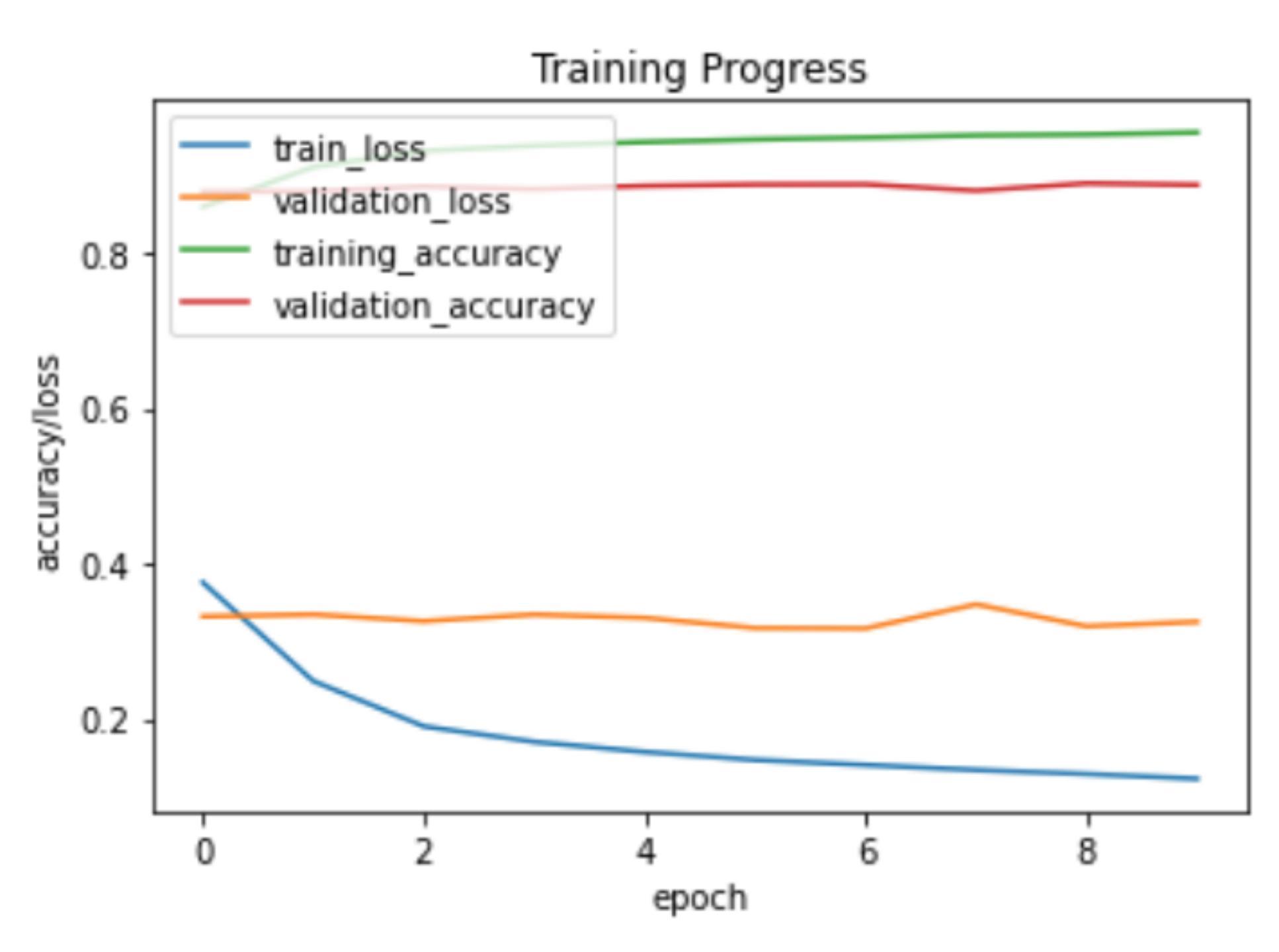
评估模型在测试集上的性能
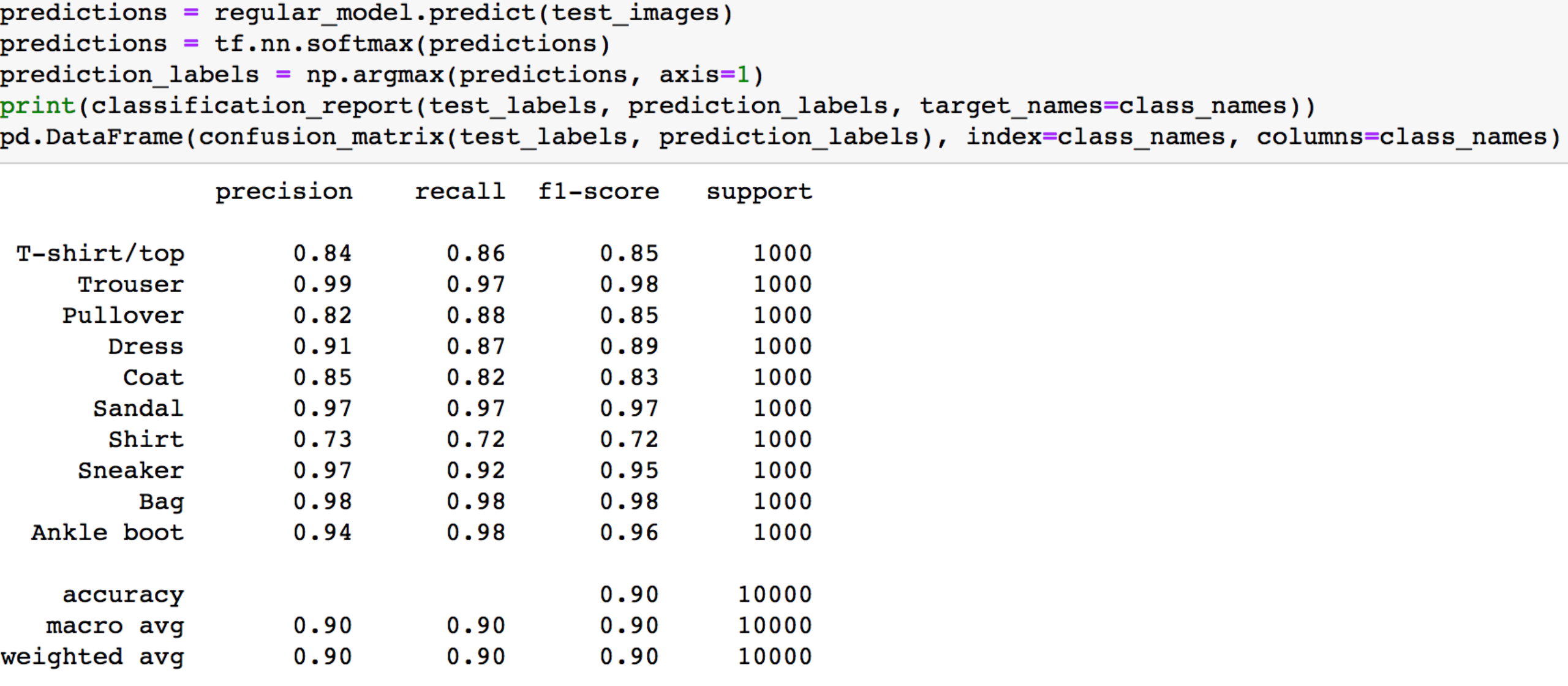
上图打印出的classification report,这个怎么看呢
列表左边的一列为分类的标签名
右边的第一行中,precision recall f1-score三列分别为各个类别的精确度、召回率及F1 值.support是某类别在测试数据中的样本个数;
accuracy表示准确率,也即正确预测样本量与总样本量的比值;macro avg表示宏平均,表示所有类别对应指标的平均值,而weighted avg带权重平均,表示类别样本占总样本的比重与对应指标的乘积的累加和。
从上面的classification report可以看到模型在测试集上的表现还是不错的
而打印出的混淆矩阵如下
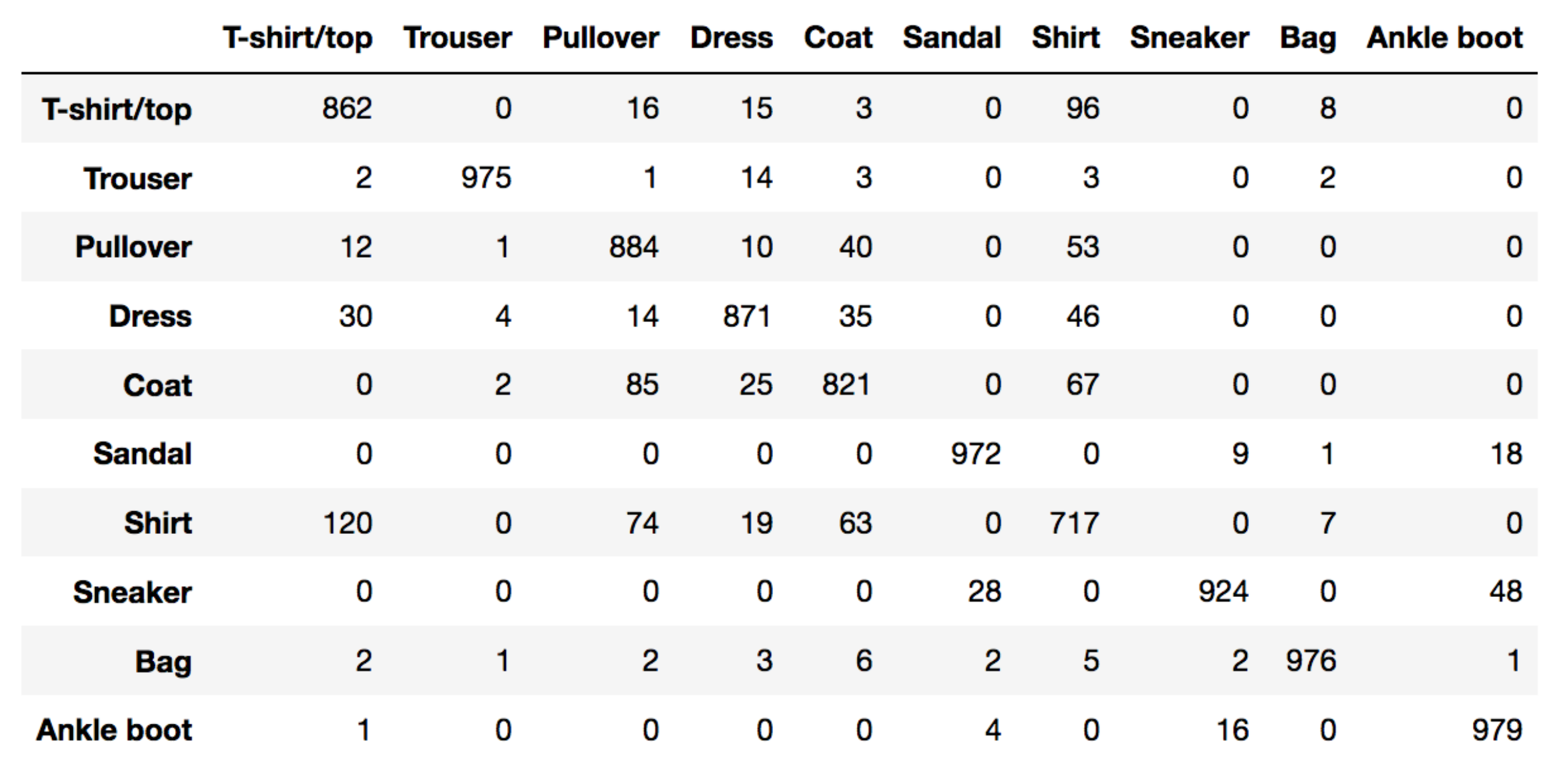
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
我们以第一行为例,样本的真实类别为t-shirt,在分类结果里,有862个样本被正确分类,有16个样本被错误分类到pullover,有15个样本被错误分类到dress,有3个样本被错误分类到coat,有96个样本被错误分类到shirt,有8个样本被错误分类到bag
如果只要看有每个类别分别由多少样本被正确分类,则只需要看对角线即可。每一类总共是1000个测试样本,而t-shirt有862个被正确分类,trouser有975个被正确分类,以此类推。从混淆矩阵可以更具体看出测试样本是被错误分到了哪一类。
对抗攻击
对抗样本可能或多或少都有听说过,它是通过对数据集中的样本应用较小但蓄意的会导致最坏情况的扰动而形成的输入,因此,被扰动的输入导致模型以高置信度输出错误的答案。
我们本次来实践最经典的对抗样本攻击方案—FGSM,下面这张图片大家应该都看过,它正是出自于提出FGSM的论文

从熊猫图像开始,攻击者在原始图像上添加小扰动,结果模型将此图像预测为长臂猿。
那么FGSM攻击是如何实现的呢?或者说攻击中添加的扰动是怎么来的呢?
我们知道训练分类模型时,网络基于输入图像学习特征,然后经过softmax层得到分类概率,接着损失函数基于分类概率和真实标签计算损失值,回传损失值并计算梯度(也就是梯度反向传播),最后网络参数基于计算得到的梯度进行更新,网络参数的更新目的是使损失值越来越小,这样模型分类正确的概率也就越来越高。
对抗样本攻击的目的是不修改分类网络的参数,而是通过修改输入图像的像素值使得修改后的图像能够扰乱分类网络的分类,那么根据前面提到的分类模型的训练过程,可以将损失值回传到输入图像并计算梯度,也就是下式
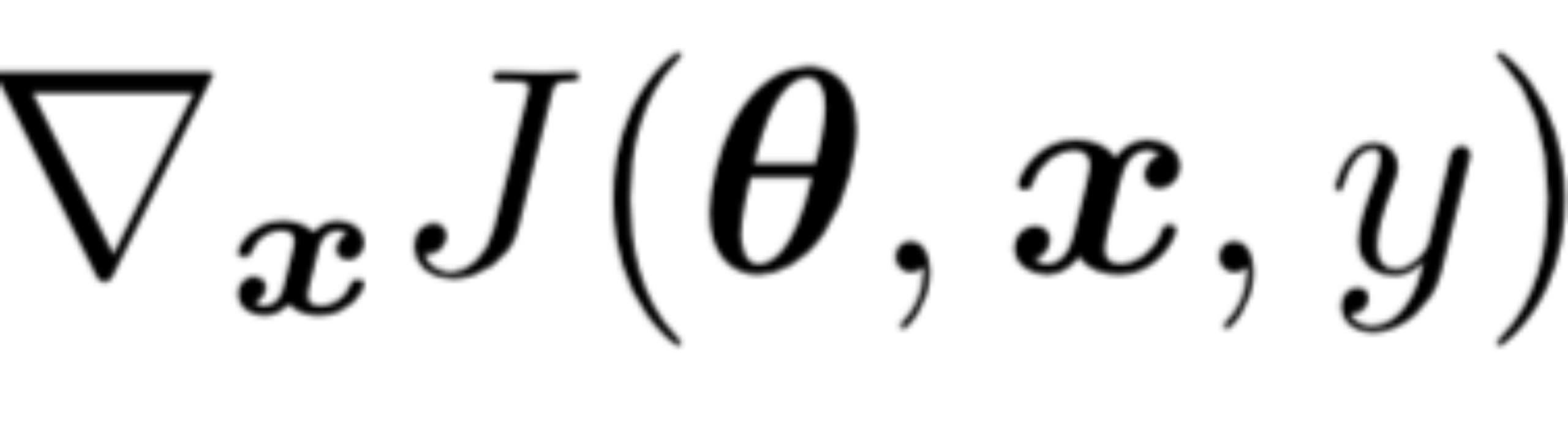
其中, θ 是模型的参数,x 是模型的输入,y 是与 x 关联的类别,J (θ, x, y) 是用于训练神经网络的损失函数。
接下来可以通过sign()函数计算梯度的方向,sign()函数是用来求数值符号的函数,比如对于大于0的输入,输出为1, 对于小于0的输入,输出为-1,对于等于0的输入,输出为0。之所以采用梯度方向而不是采用梯度值是为了控制扰动的距离.
常规的分类模型训练在更新参数时都是将参数减去计算得到的梯度,这样就能使得损失值越来越小,从而模型预测对的概率越来越大。既然对抗攻击是希望模型将输入图像错分类成错误类别,那么要求损失值越来越大,也就是模型预测的概率中对应于真实标签的概率越小越好,这和原来的参数更新目的正好相反。因此只需要在输入图像中加上计算得到的梯度方向,这样修改后的图像经过分类网络时的损失值就比修改前的图像经过分类网络时的损失值要大,换句话说,模型预测对的概率变小了。此外我们还需要用来控制扰动的程度,确保扰动足够小。所以,扰动的式子如下
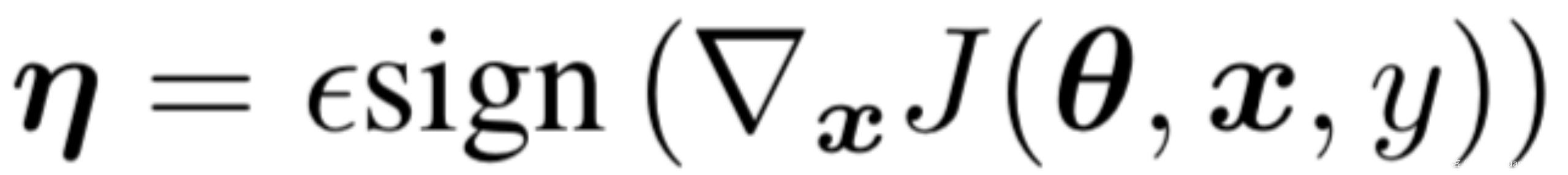
将扰动加到原样本上就得到了对抗样本,如下所示
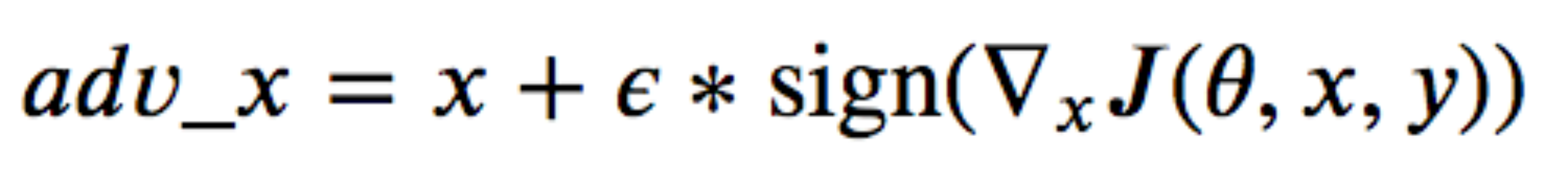
我们将这称为生成对抗样本的fast gradient sign method(快速梯度符号方法)。
对应的代码实现如下

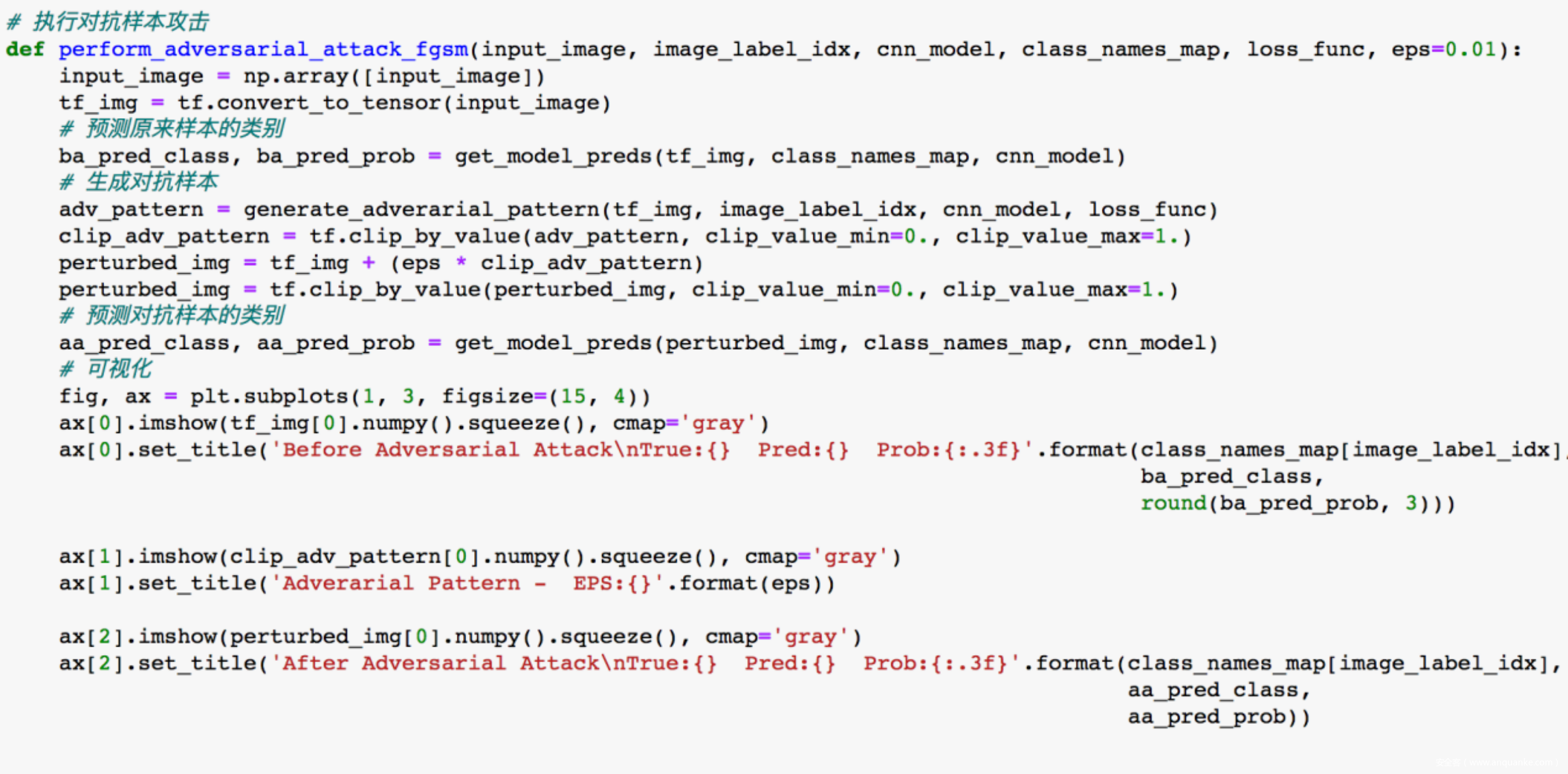
应用以上函数,我们来看看对coat样本的攻击前后的结果
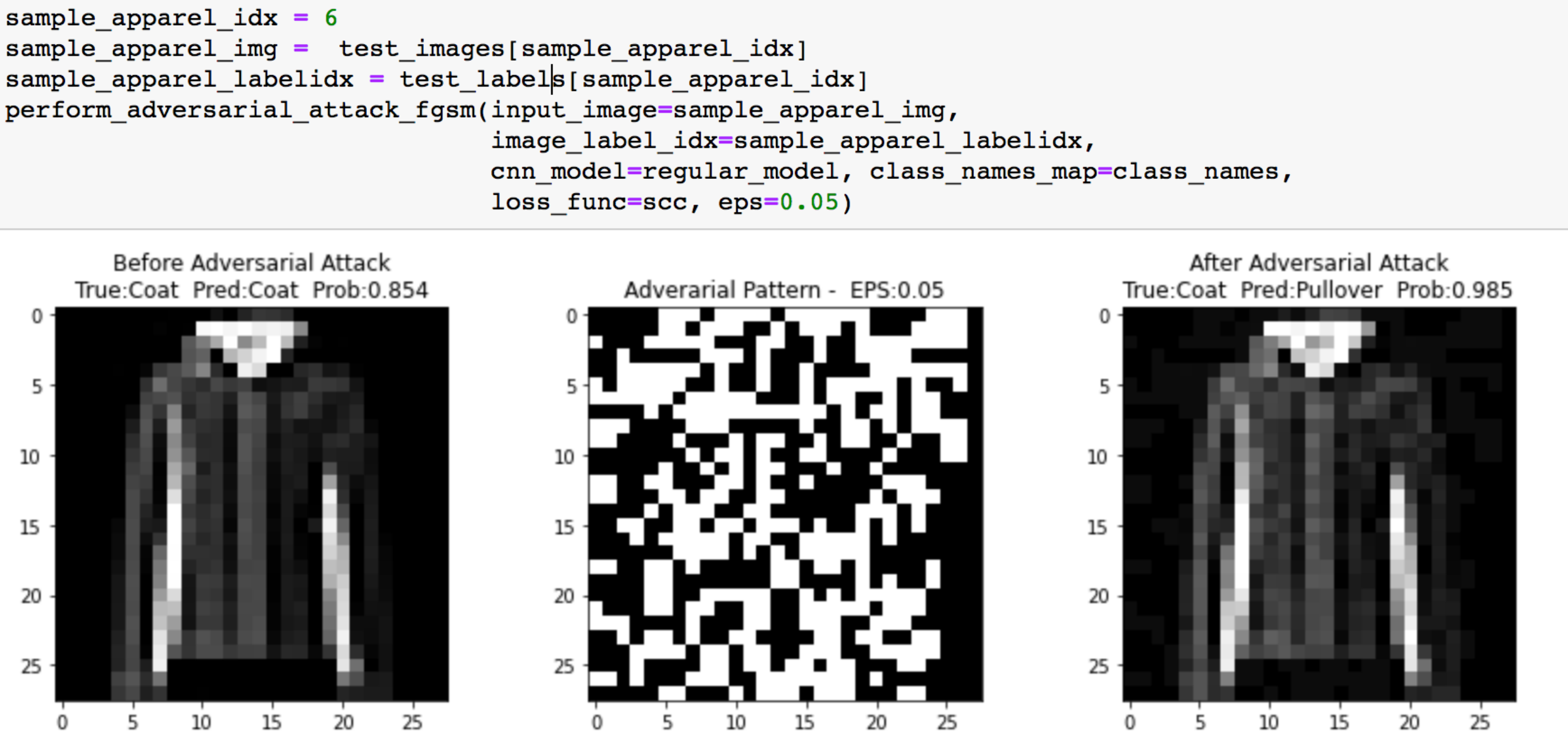
从可视化的结果可以看到,左边是原样本,以真实标签为coat,模型以较高的置信度将其预测为coat,中间是添加的对抗扰动,加上之后就得到了右边的对抗样本,其被模型错误预测为了pullover,说米我们攻击成功了。
查看对sneaker的攻击前后结果

同样攻击成功了,对于其他测试集样本生成的对抗样本同样可以攻击成功。
接下来我们来进行对抗训练,提升模型的鲁棒性
为了更全面的衡量模型在面对对抗样本攻击时有多么容易受到攻击,我们可以针对测试数据应用FGSM生成对应的对抗样本测试集
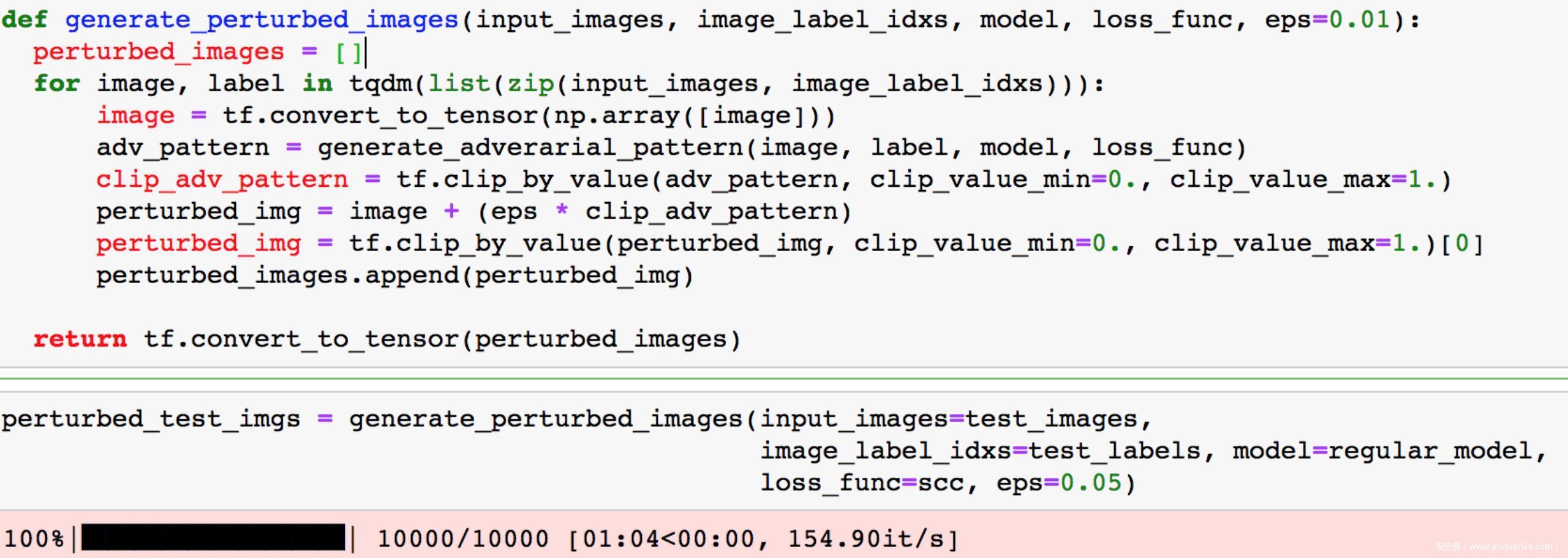
通过打印classification report和混淆矩阵来评估模型在面对对抗样本攻击时的鲁棒性

可以看到整体的指标都是较低的,说明模型面对对抗样本攻击的鲁棒性较弱
接下来我们通过对抗训练的方法增强模型的鲁棒性
对抗训练
在实践之前,先来介绍对抗训练的概念。
对抗训练(Adversarial Training)最初由 Ian Goodfellow 等人提出,作为一种防御对抗攻击的方法,其思路非常简单直接,将生成的对抗样本加入到训练集中去,做一个数据增强,让模型在训练的时候就先学习一遍对抗样本。
对抗训练实际上是一个min-max优化问题,寻找一个模型(以参数表示),使得其能够正确分类扰动在一定范围S内的对抗样本,即
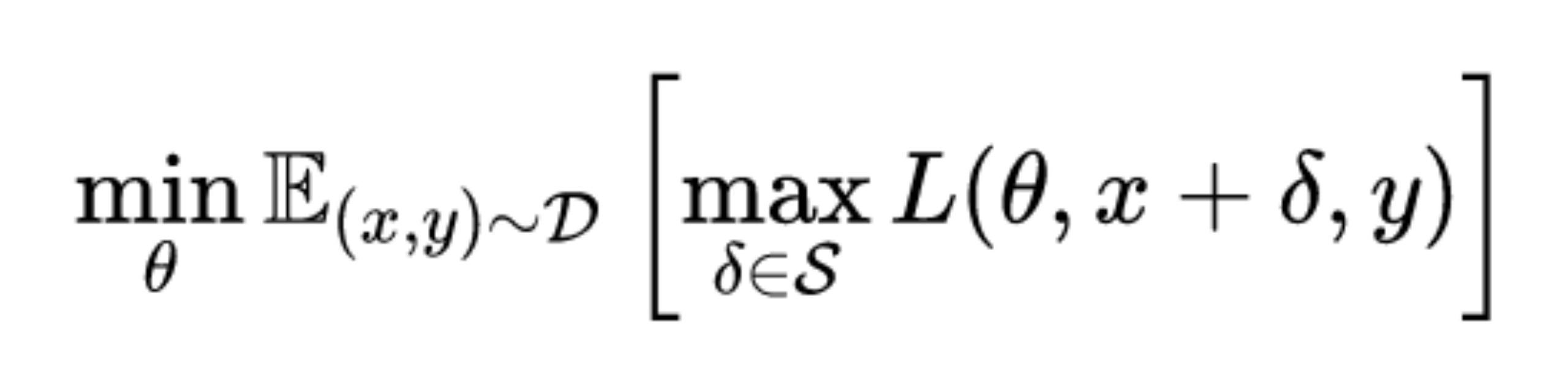
其中(x,y)表示原始数据和对应的标签,D表示数据的分布,L是损失函数
内层(中括号内)是一个最大化,L则表示在样本x上叠加一个扰动,再经过神经网络函数,与标签y比较得到的损失。 max L是优化目标,即寻找使损失函数最大的扰动,简单来讲就是添加的扰动要尽量让神经网络迷惑。外层就是对神经网络进行优化的最小化公式,即当扰动固定的情况下,我们训练神经网络模型使得在训练数据上的损失最小,也就是说,使模型具有一定的鲁棒性能够适应这种扰动。
接下来我们来看实际中对抗训练是怎么做到提升模型鲁棒性的
首先将同样的方法应用于训练集,生成原训练集的一批对抗样本,作为对抗样本训练集,并将对抗样本训练集和原来的训练集合在一起作为最终的训练集

开始在最终的训练集上训练模型
训练过程中的指标变化如下
如此,就完成了对抗训练
那么怎么对抗训练得到的模型的好坏呢?
首先要看该模型在正常的测试集上的性能,毕竟大多数测试样本都是正常的,这才是训练模型最主要的任务,即需要在正常的测试样本面前表现好
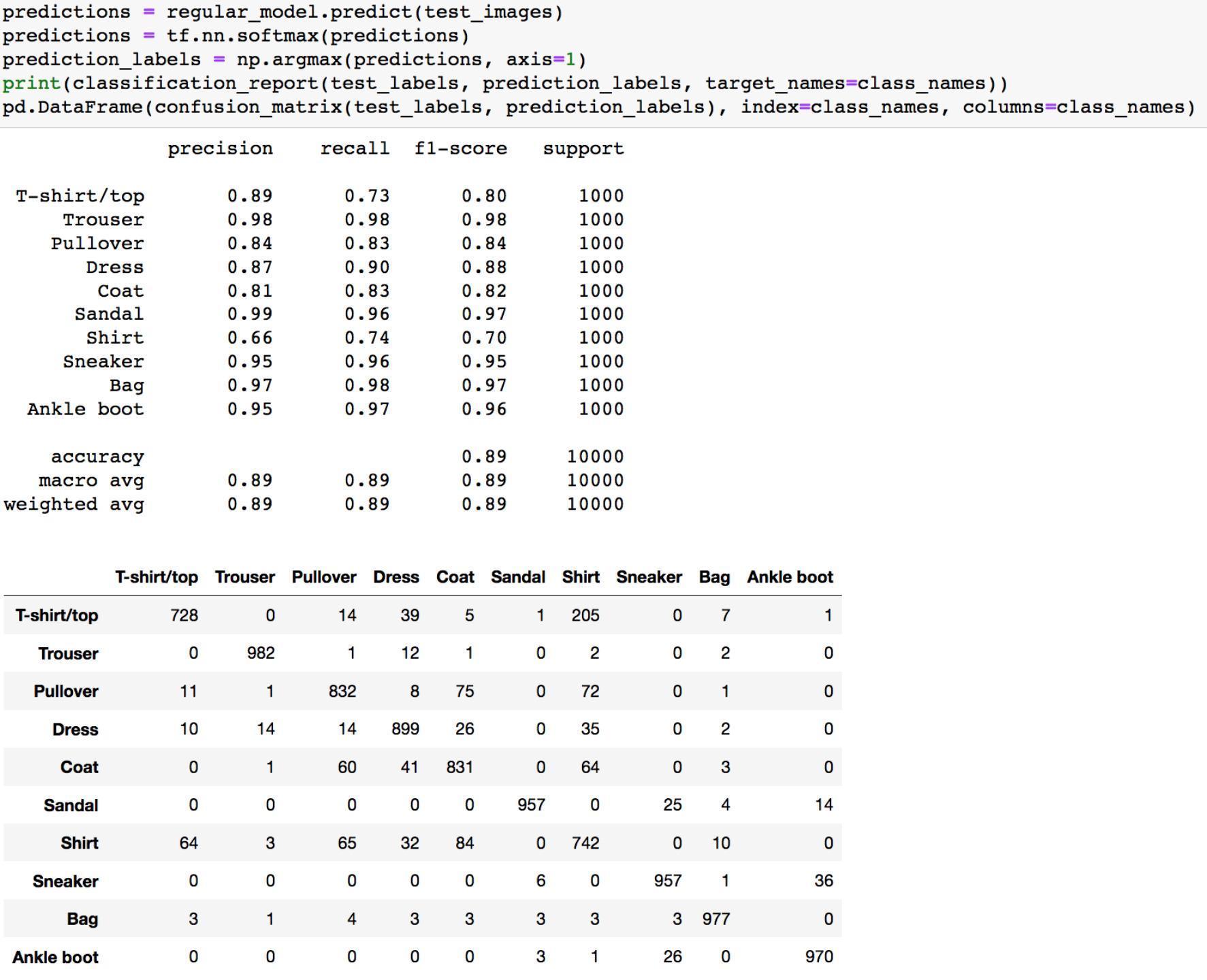
可以看到性能还是不错的
另外还要看模型在接收对抗样本时的性能,毕竟这是对抗训练相比一般训练最主要的目的所在,就是为了在面对对抗样本时,不会被其欺骗
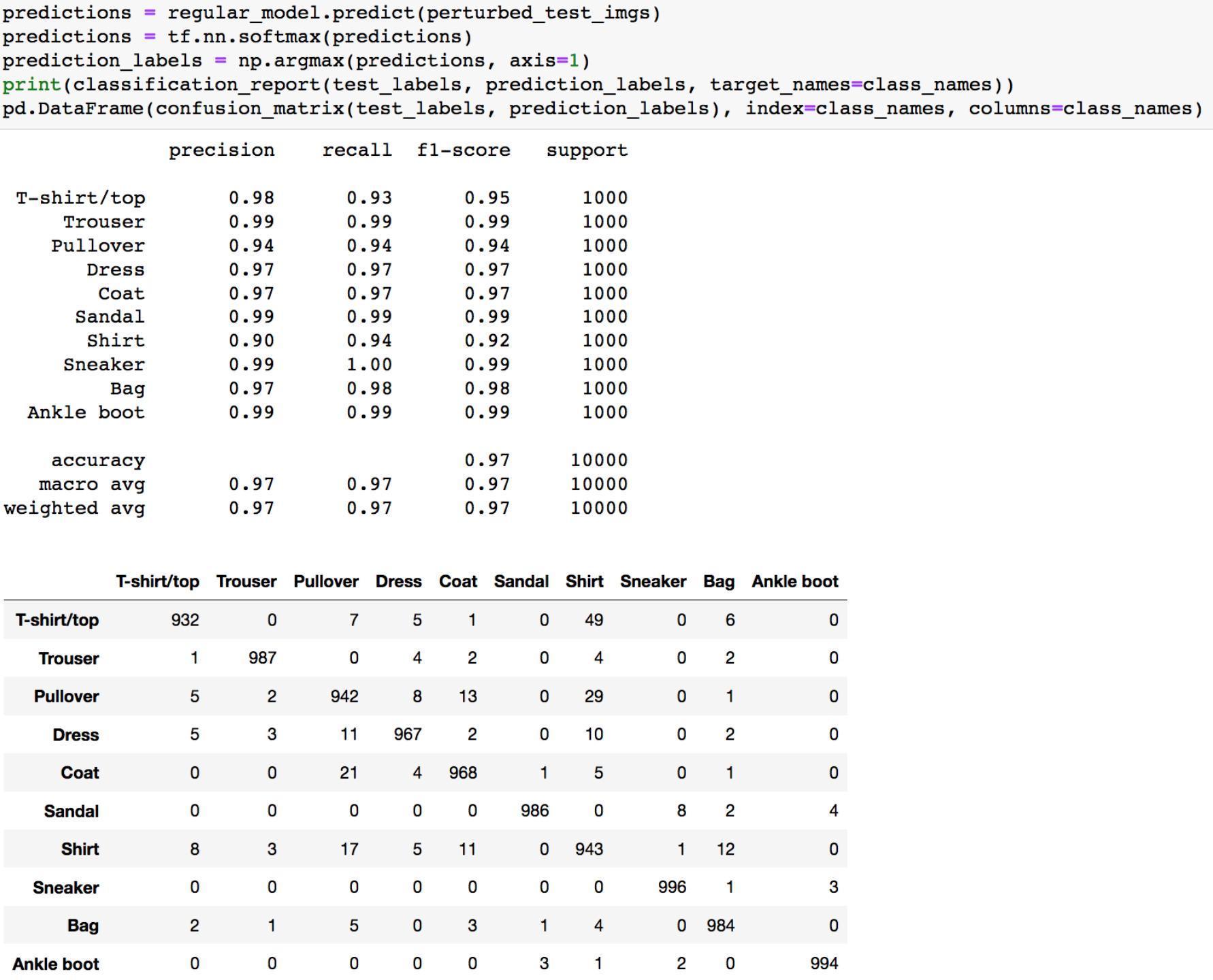
从结果可以看到,模型在面对对抗样本时表现非常好
直接看这些指标不具体的话,我们可以从10类样本中各打印一个样本的对抗样本,并查看模型对其分类结果
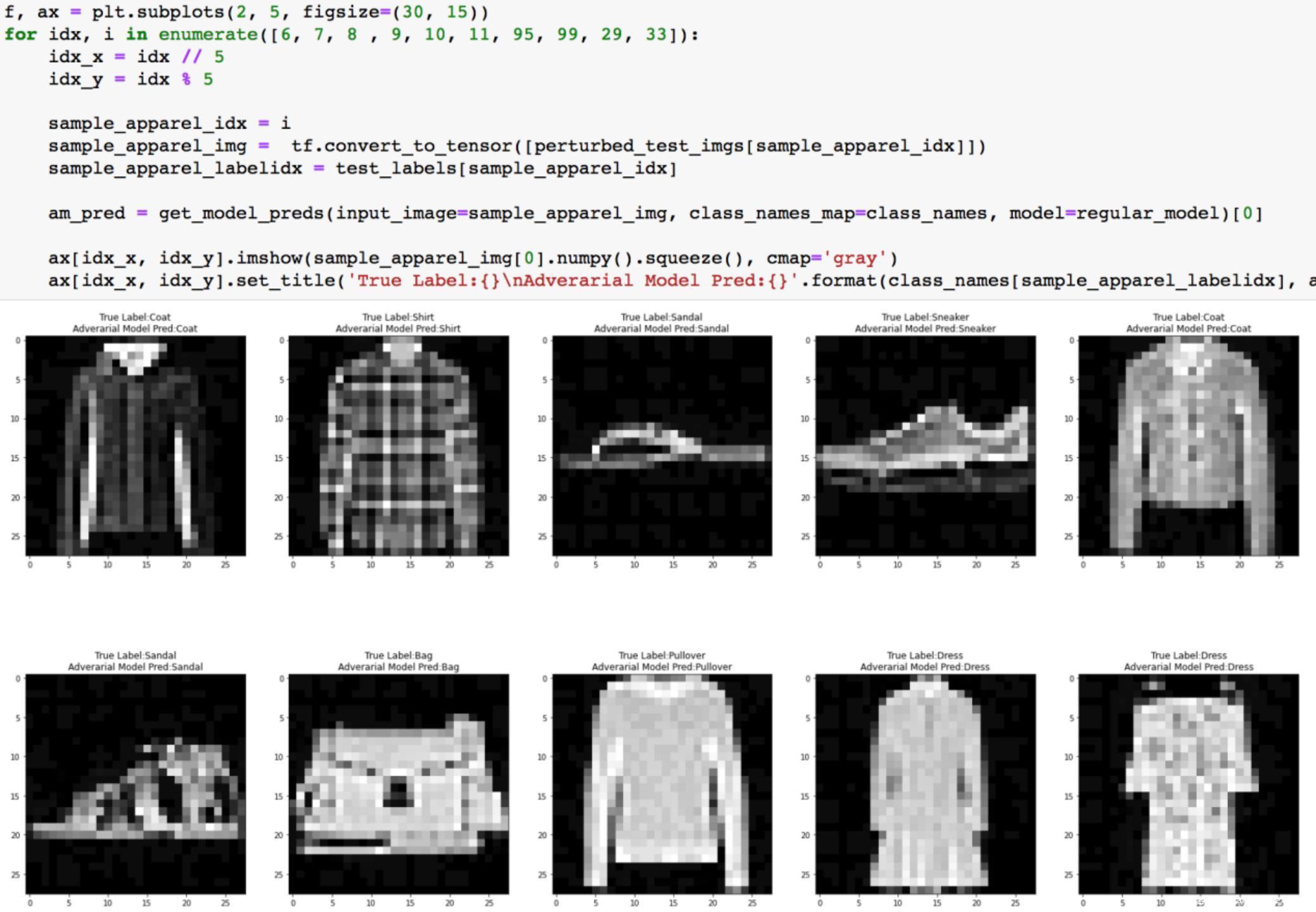
从结果可以看到,10个对抗样本都被模型正确分类了,说明模型的鲁棒性较好,表明了对抗训练的有效性。
参考
1.EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES
2.ADVERSARIAL TRAINING METHODS FOR SEMI-SUPERVISED TEXT CLASSIFICATION
3.Towards Deep Learning Models Resistant to Adversarial Attacks
4.https://zhuanlan.zhihu.com/p/104040055
5.https://zhuanlan.zhihu.com/p/166364358
6.https://github.com/1Konny/FGSM
7.https://github.com/ndb796/Pytorch-Adversarial-Training-CIFAR
8.https://github.com/zjfheart/Friendly-Adversarial-Training







发表评论
您还未登录,请先登录。
登录