

前言
之前写过一个arl运行流程图,结果思维导图画出来了,可是还是有一些地方搞不懂怎么运行的,这就很纳闷了!今天看了一下Celery的文档,稍微对这个应用有了一些概念。然后趁热又去看了一下arl的源码,尝试再次梳理运行流程,上次的疑惑终于解开了。
资产收集
纵观灯塔,每个功能模块都是建立在Task基础上的,这次单单聊聊资产收集模块。
灯塔的资产收集大致可以分为两块:基于IP的收集,对应文件app\tasks\ip.py;基于域名的收集,对应文件app\tasks\domain.py。
灯塔的资产收集模块,不单单是收集资产,它是吧基于这个IP的所有功能都加进去了,类似一个链条一次性完成。具体包括那些,下边详细梳理。
这种设计,优缺点都比较明显。优点:省事,开局只需要输入一个IP或者域名,设置好需要做的操作,就不用管了;缺点:单个任务等待周期过长。中间无法进行操作,某个环节出现不可控错误时,导致整个任务失效,损失相对较大。
资产收集task视角运行流程图:

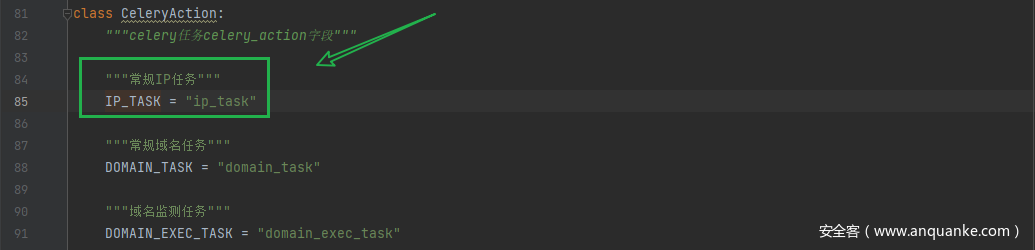
基于IP的资产收集
【参照上图流程】
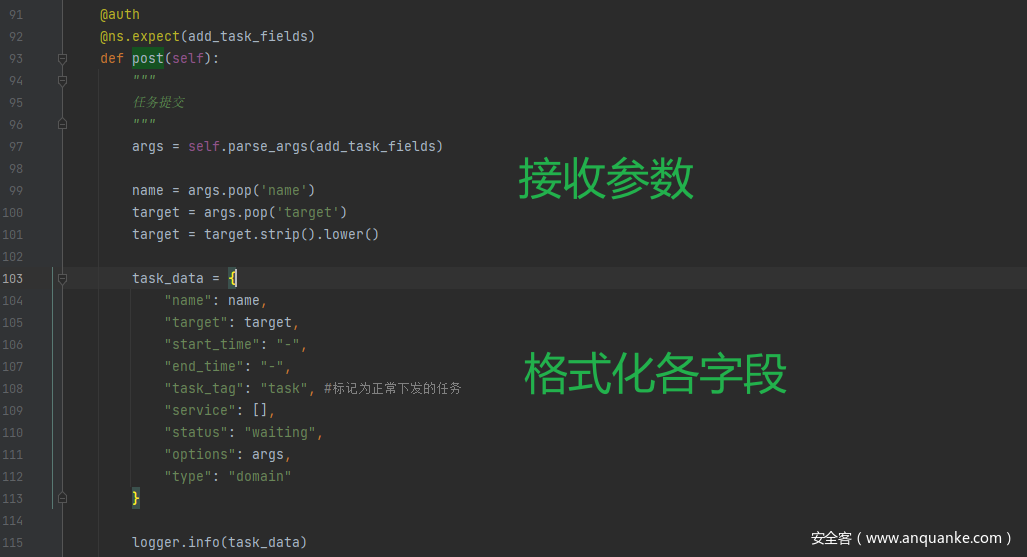
app.routes.task.ARLTask.post 任务提交
判断任务类型
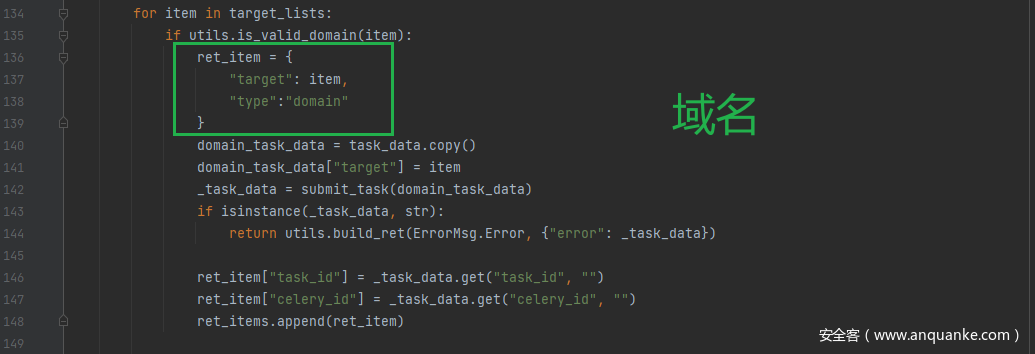
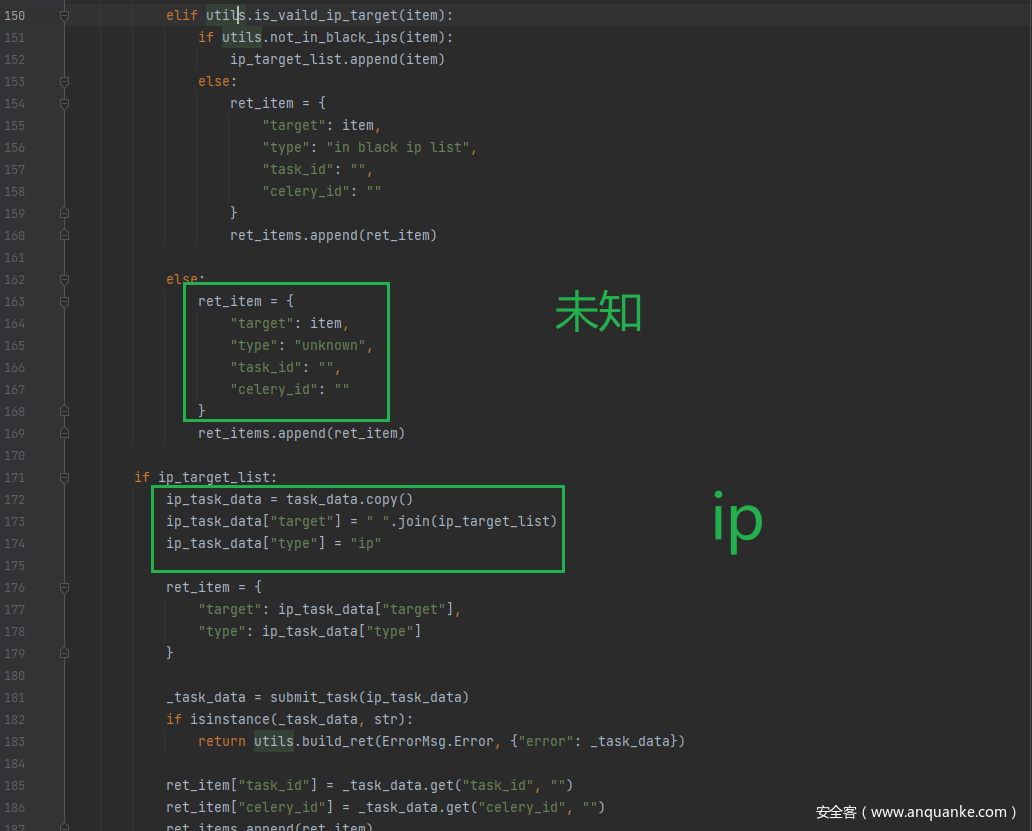
app.routes.task.submit_task
传入task_data参数,
判断type类型,选择对应方法
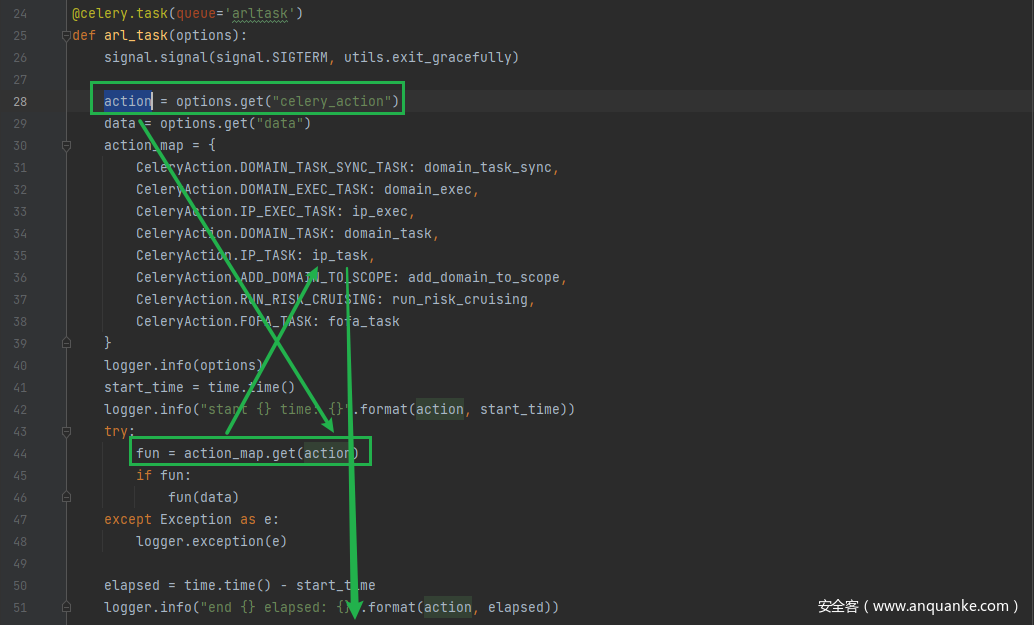
celerytask.arl_task.delay(options)
celer队列下发任务,返回celery_id,写入数据库
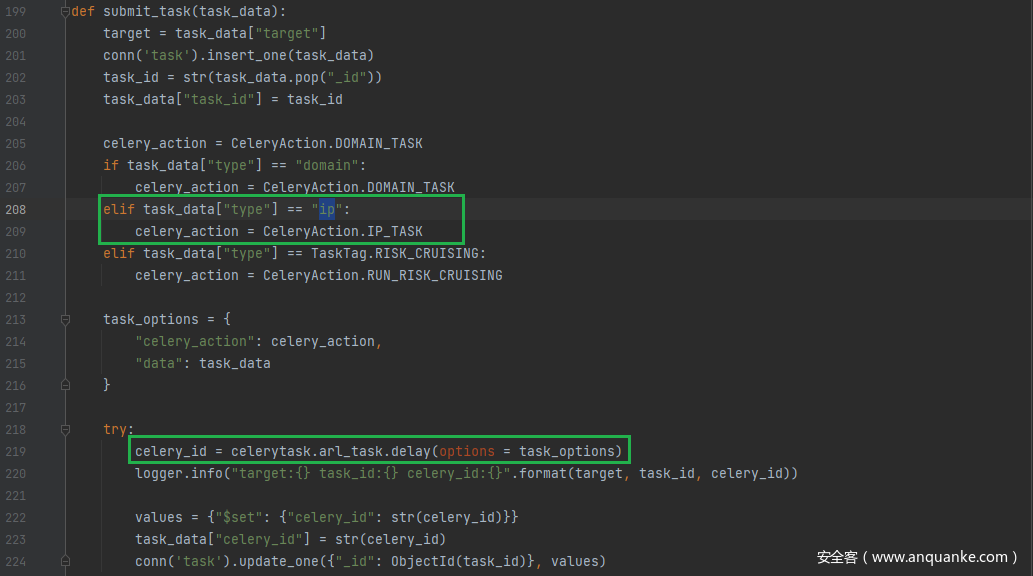
通过app.celerytask.ip_task调用app.tasks.ip.ip_task
灯塔很多地方,总是绕来绕去,简洁一点不好么?
把任务数据发送给app/tasks/ip.py文件处理

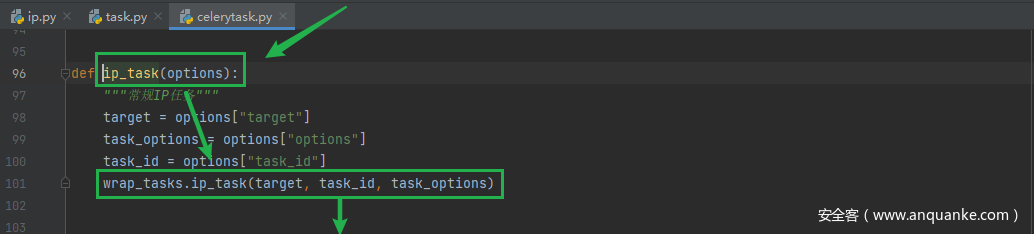

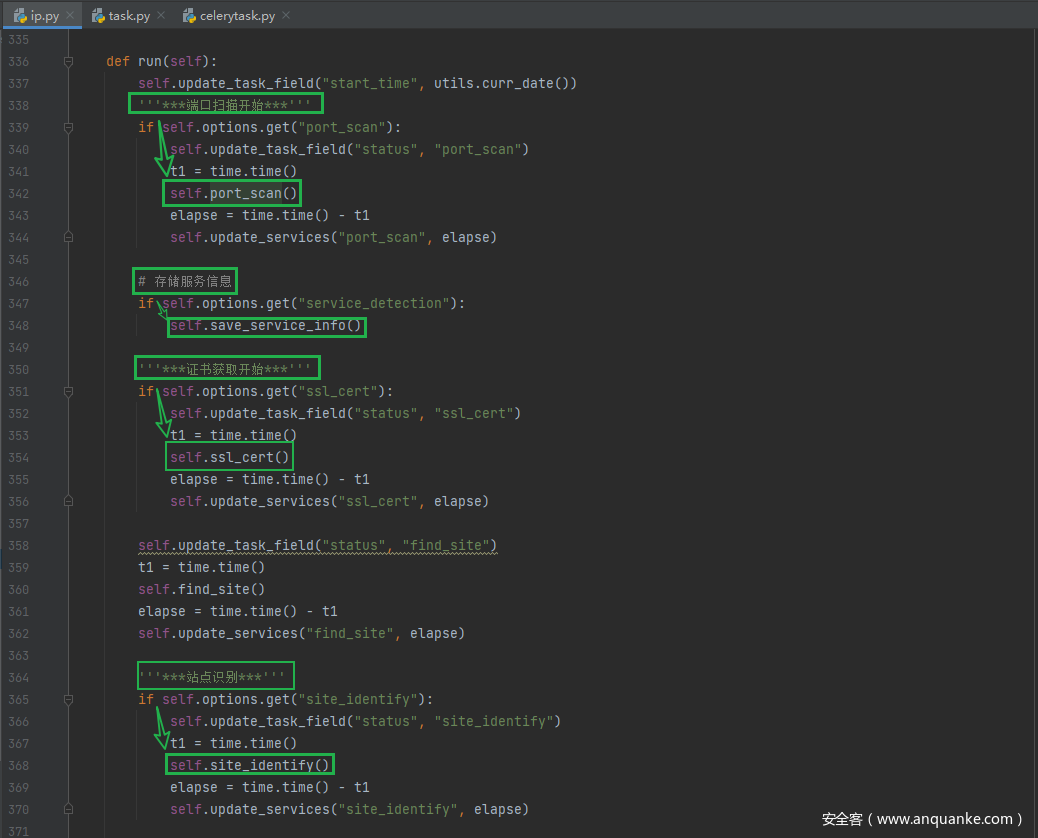
app.tasks.ip.IPTask.run()运行ip任务的全部方法
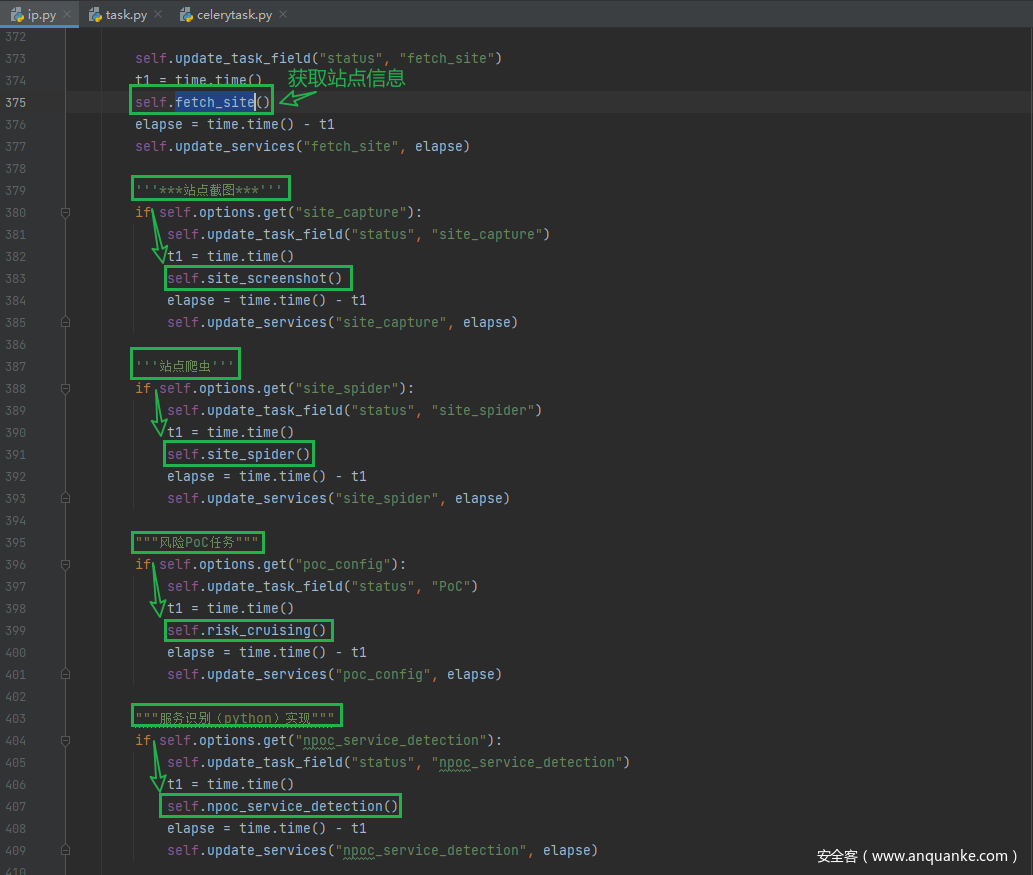
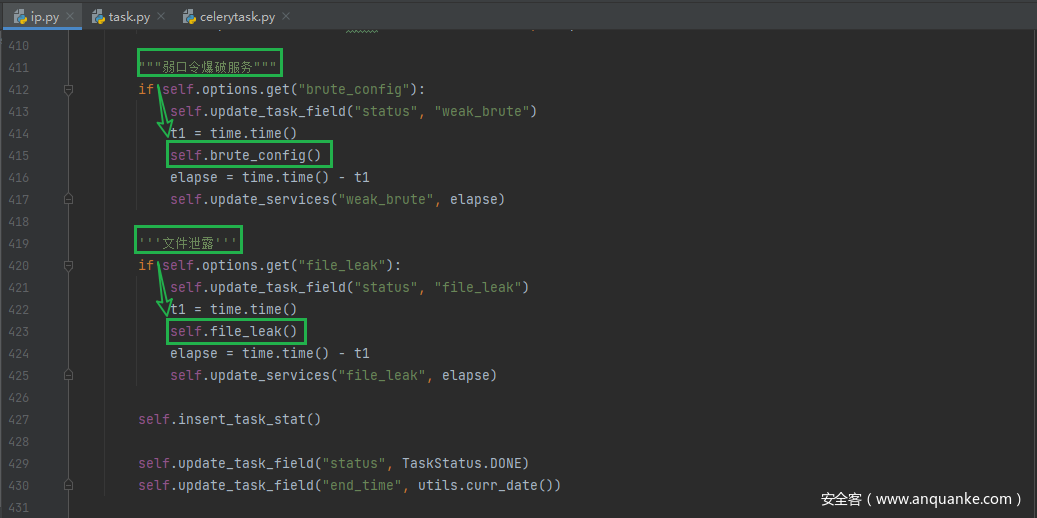
基于domain的资产收集
基于domain的流程跟ip流程类似,只不过一些方法不一样。后面会对这块进行二开,到时候会详细分析,这里就不过多介绍了。
后记
基于domain的资产收集,主要集中在子域名获取上面。这里主要通过爆破、证书查询、dns查询、搜索引擎搜索等方法收集子域名。
当然,域名收集这块,还有很大的改进空间,比如OneForAll就是一个很优秀的子域名收集工具,可以移植进来。当然,还有一些地方可以细化,比如有用到fofa收集域名,程序中只利用了证书语法搜索资产。
后续有空,再接着写。把资产收集这块二开一下。







发表评论
您还未登录,请先登录。
登录