
mruby 简介
mruby是一个Ruby语言的轻量级实现,mruby工作方式类似CPython,它可以将Ruby源码编译为字节码,再在虚拟机中解释运行。
第一次碰到mruby字节码是在DEFCON 2021 Finals,其中的barb-metal题目是mruby字节码运行的模拟IoT固件。没想到在几个月后的第五空间线上赛又碰到了mruby逆向,于是总结了一下mruby字节码的特性。
mrb字节码格式
mruby实现的是基于寄存器的虚拟机,所有的opcode可以从opcode.h查看,mruby字节码对寄存器按照函数参数、局部变量、临时寄存器的顺序进行分配。将mruby源码clone到本地并编译,在bin目录下的mirb程序是一个交互式mruby解释器,运行时加上-v参数,可以将解释器生成的字节码打印出来,方便理解。
mruby 2.1.0 (2019-11-19)
> def f(a,b)
* c=a+b
* d=a-b
* return c*d
* end
...
irep 0x55c104345310 nregs=4 nlocals=2 pools=0 syms=1 reps=1 iseq=14
local variable names:
R1:_
file: (mirb)
13 000 OP_TCLASS R2
13 002 OP_METHOD R3 I(0:0x55c104346290)
13 005 OP_DEF R2 :f
13 008 OP_LOADSYM R2 :f
13 011 OP_RETURN R2
13 013 OP_STOP
irep 0x55c104346290 nregs=9 nlocals=6 pools=0 syms=0 reps=0 iseq=36
local variable names:
R1:a
R2:b
R3:&
R4:c
R5:d
file: (mirb)
13 000 OP_ENTER 2:0:0:0:0:0:0
14 004 OP_MOVE R6 R1 ; R1:a
14 007 OP_MOVE R7 R2 ; R2:b
14 010 OP_ADD R6
14 012 OP_MOVE R4 R6 ; R4:c
15 015 OP_MOVE R6 R1 ; R1:a
15 018 OP_MOVE R7 R2 ; R2:b
15 021 OP_SUB R6
15 023 OP_MOVE R5 R6 ; R5:d
16 026 OP_MOVE R6 R4 ; R4:c
16 029 OP_MOVE R7 R5 ; R5:d
16 032 OP_MUL R6
16 034 OP_RETURN R6
首先从下面部分的字节码可以看出,mruby函数用到的寄存器已经分配给了特定的变量使用,R1-R2用于参数a和b,R4-R5用于局部变量c和d,R6-R7为临时寄存器。
对于有多个操作数的指令,mruby总会先将操作数存入连续的寄存器里,然后将第一个寄存器编码到字节码内,例如上图中的032 OP_MUL R6,实际上OP_MUL接受两个寄存器,R6和R7,并且总是将相乘的结果存入R6中。再例如上方的f函数声明部分:002 OP_METHOD R3 I(0:0x55c104346290)将f函数的指针放入R3,后面的005 OP_DEF R2 :f是把R(2+1),即R3中的函数指针声明为R2中的名字,即:f。了解到这一特性之后就可以对mruby字节码进行初步的逆向了。
示例:DEFCON 2021 barb-metal
这道题目是DEFCON 29决赛中的一道攻防题目,可以参考archive.ooo上的存档。题目用mrubyc(mruby解释器的另一种实现)跑了一个模拟IoT设备,该IoT设备有Alarm,Thermostat,Speaker等几个组件,每个组件可以接受不同的命令,例如Thermostat组件存储了一些温度数据,可以用THERM read day friday/THERM set night monday 90之类的指令读写数据。
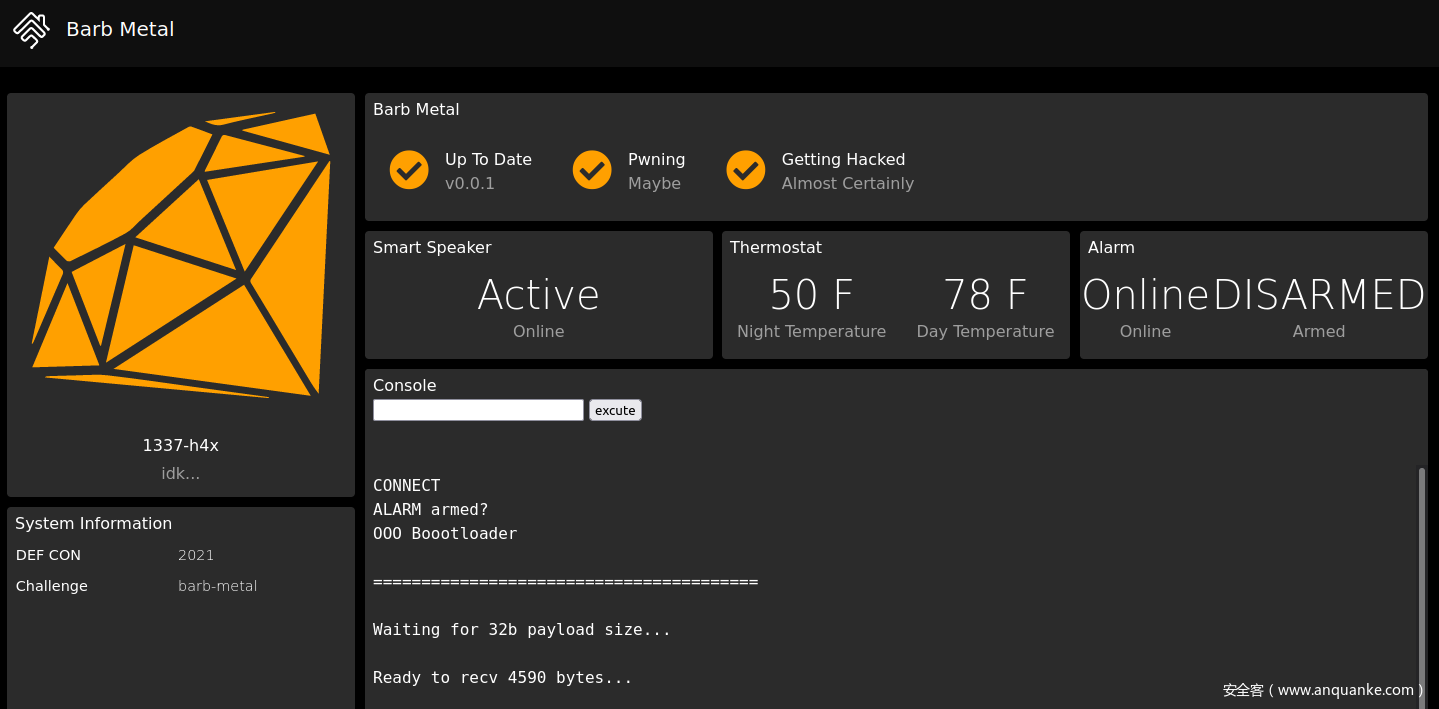
对题目的service程序进行逆向分析,可以发现Alarm,Thermostat,Speaker这些组件的逻辑均是用C实现,并注册为Ruby对象的成员函数。

题目的payload.bin是mruby字节码,除去前260字节的签名后,开头的magic bytes是RITE0006,找到对应的mruby版本是v2.1.0,编译后用mruby -v -b payload.bin运行,dump出字节码。
下面是set_therm函数片段,用来处理THERM set指令:
267 OP_MOVE R7 R5 ; R5:date
270 OP_GETIV R8 @dayofweek
273 OP_SEND R8 :size 0
277 OP_GT R7
# 此处R7是输入的date,R8是dayofweek数组长度,用来检查输入的星期是否溢出
# OP_GT R7隐含了比较的对象R8
279 OP_JMPNOT R7 306
# 若R7<R8,跳转到306,即通过验证,未通过则向下走返回
283 OP_LOADSELF R7
285 OP_STRING R8 L(5) ; "INVALID date "
288 OP_MOVE R9 R5 ; R5:date
291 OP_STRCAT R8
293 OP_STRING R9 L(3) ; ""
296 OP_STRCAT R8
298 OP_SEND R7 :putsDBG 1
302 OP_LOADNIL R7
304 OP_RETURN R7
# 输出字符串,提示越界
# OP_SEND R7 :putsDBG 1隐含一个参数R8
306 OP_GETIV R7 @therm
309 OP_MOVE R8 R4 ; R4:time
312 OP_MOVE R9 R5 ; R5:date
315 OP_MOVE R10 R6 ; R6:temp
318 OP_SEND R7 :write 3
322 OP_RETURN R6 ; R6:temp
# 验证通过,调用设备函数
# OP_SEND R7 :write 3中函数指针为R7,隐含3个参数R8-R10
在mruby字节码中,OP_GETIV R7 @therm即获得Thermostat组件的对象,放入R7寄存器,OP_SEND R7 :write 3意为用R7后面的3个寄存器,即R8-R10中的值作为参数,调用R7对象的write函数,此处的write函数是C注册的Thermostat组件的写入功能(sub_112CBF)。
这道题目的意思就是通过发送指令,由mruby程序对输入的参数进行校验,再传给C函数完成相应操作。题目只允许对mruby字节码进行patch,修补参数校验中的漏洞。
经过逆向分析可以发现THERM set指令的第一个参数可以是day/night,也可以直接输入0/1,第二个参数星期也可以直接输入数字0-6,而上面的函数片段显示mruby只检查了data\<dayofweek.size,即输入的星期要小于7,没有检查下界,利用THERM set 0 -addr value可以实现越界写。
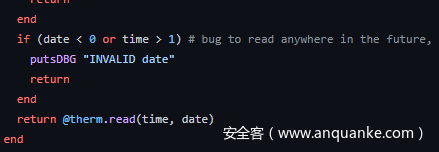
同样在THERM get对应的get_therm函数中:
238 OP_MOVE R6 R5 ; R5:date
241 OP_LOADI_0 R7
243 OP_LT R6
245 OP_JMPIF R6 256
# 判断date是否小于0,若小于0检查失败
249 OP_MOVE R6 R4 ; R4:time
252 OP_LOADI_1 R7
254 OP_GT R6
256 OP_JMPNOT R6 273
# 判断time是否大于1,若大于1检查失败
260 OP_LOADSELF R6
262 OP_STRING R7 L(4) ; "INVALID date"
265 OP_SEND R6 :putsDBG 1
269 OP_LOADNIL R6
271 OP_RETURN R6
273 OP_GETIV R6 @therm
276 OP_MOVE R7 R4 ; R4:time
279 OP_MOVE R8 R5 ; R5:date
282 OP_SEND R6 :read 2
286 OP_RETURN R6
对date参数的校验只有下界没有上界,可以造成越界读,赛后参考源码可以发现这里是出题人故意埋的漏洞。
Alarm和Speaker组件中也有越界读写的漏洞,由于这道题mruby仅用来校验参数,后面的攻击就回到了普通的堆利用上,对这题的逆向分析就到此为止。
实战:第五空间线上赛 babyruby
再次碰到mruby还是比较意外的,由于有了DEFCON的经验,这次的babyruby做的比较顺利,侥幸拿了全场唯一解。
题目给的字节码开头是RITE0200,对应mruby v3.0.0,编译运行并dump字节码,程序的main函数位于底部,开头先检查flag{xxxx}格式,括号内的x共32字节。
再翻一翻上面的字节码,发现其中有不少有趣的函数:
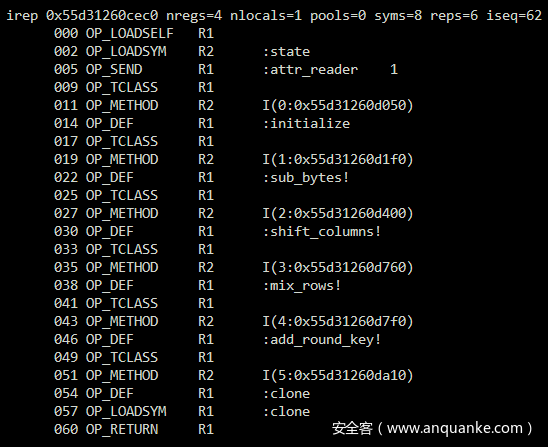
显然后四样操作是AES的组成部分,于是猜测题目是AES加密,开始寻找加密后的密文,以及加密用的密钥。密文比较部分就位于整个程序的末尾:
1796 OP_MOVE R10 R14 ; R10:wanted
1799 OP_JMP 2065
# 这里是一个for循环开始的部分,首先跳转到循环变量i的检查
1802 OP_GETCONST R14 :Cipher
1805 OP_SEND R14 :new 0
1809 OP_MOVE R11 R14 ; R11:cipher
1812 OP_MOVE R14 R3 ; R3:content
1815 OP_MOVE R15 R4 ; R4:i
1818 OP_SEND R14 :[] 1
# R14=content[i]
1822 OP_MOVE R15 R3 ; R3:content
1825 OP_MOVE R16 R4 ; R4:i
1828 OP_ADDI R16 16
1831 OP_SEND R15 :[] 1
1835 OP_ADD R14 R15
...
2011 OP_MOVE R12 R14 ; R12:cc
# R14+=content[i+16],下面省略了一些取content数组元素的操作,
# 最终的结果是用content[i,i+8,i+16,i+24]四字节组成一个14字节的字符串放在cc里
2014 OP_MOVE R14 R11 ; R11:cipher
2017 OP_MOVE R15 R12 ; R12:cc
2020 OP_STRING R16 L(2) ; c*
2023 OP_SEND R15 :unpack 1
2027 OP_SEND R14 :hash 1
2031 OP_MOVE R13 R14 ; R13:output
# output=cipher.hash(cc.unpack("c*"))
# 将cc字符串unpack为bytes,再把bytes传给cipher的hash函数
2034 OP_MOVE R15 R10 ; R10:wanted
2037 OP_MOVE R16 R4 ; R4:i
2040 OP_SEND R15 :[] 1
# wanted=R4[i],R4即比较对象,下文有解释
2044 OP_SEND R14 :!= 1
2048 OP_JMPNOT R14 2056
2052 OP_LOADF R14
2054 OP_RETURN_BLK R14
# if(output!=wanted){return false;}
2056 OP_MOVE R14 R4 ; R4:i
2059 OP_ADDI R14 1
2062 OP_MOVE R4 R14 ; R4:i
# i = i+1
2065 OP_MOVE R14 R4 ; R4:i
2068 OP_MOVE R15 R3 ; R3:content
2071 OP_SEND R15 :length 0
2075 OP_LOADI_4 R16
2077 OP_DIV R15 R16
2079 OP_LT R14 R15
2081 OP_JMPIF R14 1802
# if(i < content.length/8) goto 1802;
# 循环变量i从0到content.length/8,每轮循环处理4字节
2085 OP_LOADT R14
2087 OP_RETURN R14
# return true,flag正确
题目将输入的32字节分为8组,每组4个字节先扩展到14字节,再经cipher.hash函数处理后与R4数组的值进行比较,R4是一个8×64的二维数组,静态编码在mruby字节码中,可以直接提取。
cipher.hash函数是一个14字节到64字节的映射,起初我认为是AES加密,但AES128的特征是前9轮是完整的四样操作,最后一轮是没有MixColumns的三样操作,我在程序中找不到仅有SubBytes,ShiftRows和AddRoundKey的尾轮操作,没法证明AES的猜想。从cipher.hash函数的名字,以及输出长度64字节,还有代码中的一些padding操作,可以推断这是Whirlpool)散列函数(Whirlpool是一种利用了AES的四种操作构造出的散列函数,其内部状态是8×8的置换排列网络。据我所知使用了AES的组件的算法有Whirlpool、ARIA、SM4、Rijndael-192和Rijndael-256,这几种算法都可以使用Intel AESNI进行加速,十分神奇)。
由于每轮输入仅4字节,可以直接对R4数组中散列的结果进行爆破,找出输入:
#include <openssl/whrlpool.h>
#include <stdio.h>
#include <string.h>
const unsigned char h1[] = {
16, 87, 130, 164, 79, 211, 145, 230, 203, 8, 8, 147, 105, 87, 47,
... // 从字节码中提取出R4数组
};
int main() {
int a, b, c, d;
int i;
char flag[32];
char buf[14];
memset(flag, 0xff, 32);
unsigned char md[64];
for (i = 0; i < 8; i++) {
printf("%d\n", i);
for (a = 0; a < 80; a++) {
for (b = 0; b < 80; b++) {
for (c = 0; c < 80; c++) {
for (d = 0; d < 80; d++) {
buf[0] = a;
buf[1] = c;
buf[2] = c;
buf[3] = b;
buf[4] = d;
buf[5] = c;
buf[6] = a;
buf[7] = c;
buf[8] = a;
buf[9] = c;
buf[10] = b;
buf[11] = c;
buf[12] = d;
buf[13] = c;
WHIRLPOOL(buf, 14, md);
if (memcmp(md, h1 + 64 * i, 64) == 0) {
printf("%d good\n", i);
flag[i] = a;
flag[i + 8] = b;
flag[i + 16] = c;
flag[i + 24] = d;
goto done;
}
}
}
}
}
done:
printf("%d done\n", i);
}
for (i = 0; i < 32; i++) {
printf("0x%02x,", flag[i]);
}
return 0;
}
//[0x16, 0x27, 0x00, 0x35, 0x32, 0x16, 0x18, 0x15, 0x22, 0x21, 0x03, 0x1a, 0x1e, 0x1d, 0x3b, 0x1a,
// 0x2d, 0x38, 0x0e, 0x03, 0x28, 0x08, 0x28, 0x0e, 0x2e, 0x31, 0x39, 0x3e, 0x04, 0x1d, 0x15, 0x23]
然而这还不是这道题目的全部,爆破结果只是输入cipher.hash的数组,在这之前该程序还对输入有一些处理:
081 OP_MOVE R15 R3 ; R3:content
084 OP_SEND R15 :length 0
088 OP_SUBI R15 1
091 OP_RANGE_INC R14
# R14=content[0:length-1],OP_RANGE_INC用R15创建range
093 OP_BLOCK R15 I(0:0x55d31260ff20)
096 OP_SENDB R14 :each 0
# OP_BLOCK加载了一个lambda函数到R15中
# 将这个lambda函数应用到R14的每个元素上,类似python的map函数
100 OP_LOADI_1 R6 ; R6:step
102 OP_LOADI_0 R4 ; R4:i
104 OP_LOADI_0 R7 ; R7:lst
# setp=1, i=0, lst=0,初始化一个复杂的循环
106 OP_MOVE R14 R4 ; R4:i
109 OP_MOVE R15 R6 ; R6:step
112 OP_ADD R14 R15
114 OP_MOVE R4 R14 ; R4:i
117 OP_JMP 214
# i+=step,循环开始
120 OP_MOVE R14 R3 ; R3:content
123 OP_MOVE R15 R7 ; R7:lst
126 OP_SEND R14 :[] 1
130 OP_SEND R14 :ord 0
134 OP_MOVE R8 R14 ; R8:c
# c=ord(content[lst])
137 OP_MOVE R14 R7 ; R7:lst
140 OP_ADDI R14 1
143 OP_MOVE R15 R4 ; R4:i
146 OP_SUBI R15 1
149 OP_RANGE_INC R14
151 OP_BLOCK R15 I(1:0x55d31260fff0)
154 OP_SENDB R14 :each 0
# 对[lst-1:i+1]范围内的每个元素应用R15的lambda表达式
158 OP_MOVE R14 R8 ; R8:c
161 OP_MOVE R15 R7 ; R7:lst
164 OP_ADDI R15 1
167 OP_SEND R14 :^ 1
171 OP_SEND R14 :chr 0
# R14=chr(c^lst)
175 OP_MOVE R15 R3 ; R3:content
178 OP_MOVE R16 R7 ; R7:lst
181 OP_MOVE R17 R14
184 OP_SEND R15 :[]= 2
188 OP_MOVE R14 R4 ; R4:i
191 OP_MOVE R7 R14 ; R7:lst
194 OP_MOVE R14 R6 ; R6:step
197 OP_ADDI R14 1
200 OP_MOVE R6 R14 ; R6:step
203 OP_MOVE R14 R4 ; R4:i
206 OP_MOVE R15 R6 ; R6:step
209 OP_ADD R14 R15
211 OP_MOVE R4 R14 ; R4:i
# lst=i, step=step+1, i=i+step
214 OP_MOVE R14 R4 ; R4:i
217 OP_MOVE R15 R3 ; R3:content
220 OP_SEND R15 :length 0
224 OP_LT R14 R15
226 OP_JMPIF R14 120
# if(i<content.length) goto 120; 否则循环结束
content是输入的32字节,循环过程中有一个lambda表达式较为复杂,通过静态分析很难找出其中的操作,于是我采用了动态调试的方法猜出其中的处理逻辑。
mruby动态调试
上面的循环中有一个特别的opcode:149 OP_RANGE_INC R14,它为我们提供了一个完美的断点位置,我们只需要找出mruby虚拟机中对OP_RANGE_INC的处理,断在这里,再查看此时R3中的内容,就能看出输入的32字节经过了什么样的变换。解释器主函数位于src/vm.c:
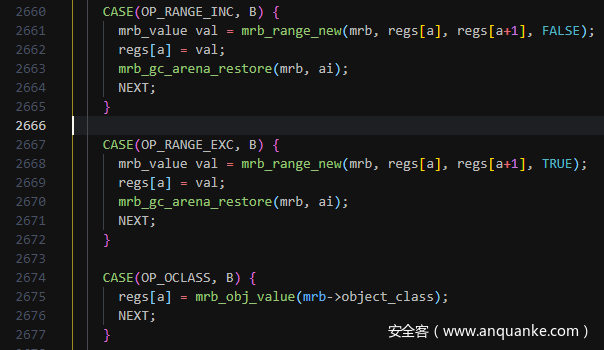
首先准备调试环境:mruby的变量采用了类似Chromium V8的指针压缩机制,参见mruby文档中的MRB_WORD_BOXING,这一特性使得gdb查看mruby变量变得十分困难,好在编译时可以选择关掉该特性:
export CFLAGS='-DMRB_NO_BOXING=1 -O0 -g' && make -j4
编译出带调试信息的mruby解释器,gdb断点设在vm.c:2661,随便输入一个测试flag,比如flag{whosyourdaddyISEEDEADPEOPLE10086},这里故意避免输入连续的01234或者abcd,为了方便猜测后面的处理究竟是异或还是加减乘除四则运算。
过掉第一个断点,第二次断下时位于091 OP_RANGE_INC R14,查看一下mrb->c->ci->stack[3],即R3的内容:
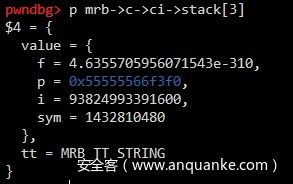
R3类型是MRB_TT_STRING,这个string就是content变量,即我们输入的32字节。再把value的p成员转换成RString,继续深入查看:
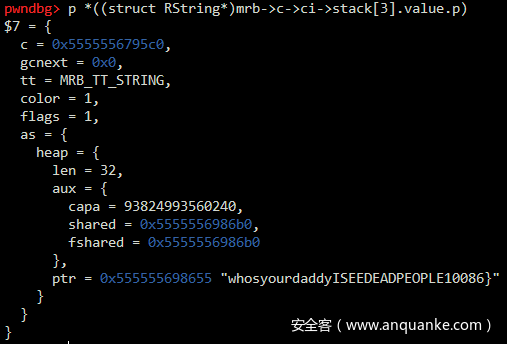
看到了我们的输入存放的位置,此时继续执行,进入循环,每次循环将该位置的内存dump下来:
pwndbg> x/32xb ((struct RString*)mrb->c->ci->stack[3].value.p)->as.heap.ptr
0x555555698655: 0x77 0x68 0x6f 0x73 0x79 0x6f 0x75 0x72
0x55555569865d: 0x64 0x61 0x64 0x64 0x79 0x49 0x53 0x45
0x555555698665: 0x45 0x44 0x45 0x41 0x44 0x50 0x45 0x4f
0x55555569866d: 0x50 0x4c 0x45 0x31 0x30 0x30 0x38 0x36
# 将字母数字从ASCII转为对应的index
0x555555698700: 0x3a 0x2b 0x32 0x36 0x3c 0x32 0x38 0x35
0x555555698708: 0x27 0x24 0x27 0x27 0x3c 0x12 0x1c 0x0e
0x555555698710: 0x0e 0x0d 0x0e 0x0a 0x0d 0x19 0x0e 0x18
0x555555698718: 0x19 0x15 0x0e 0x01 0x00 0x00 0x08 0x06
# content[0] ^= 1
0x555555698700: 0x3b 0x2b 0x32 0x36 0x3c 0x32 0x38 0x35
0x555555698708: 0x27 0x24 0x27 0x27 0x3c 0x12 0x1c 0x0e
0x555555698710: 0x0e 0x0d 0x0e 0x0a 0x0d 0x19 0x0e 0x18
0x555555698718: 0x19 0x15 0x0e 0x01 0x00 0x00 0x08 0x06
# content[1] ^= 2
# content[2] ^= 2^content[1]
0x555555698700: 0x3b 0x29 0x1b 0x36 0x3c 0x32 0x38 0x35
0x555555698708: 0x27 0x24 0x27 0x27 0x3c 0x12 0x1c 0x0e
0x555555698710: 0x0e 0x0d 0x0e 0x0a 0x0d 0x19 0x0e 0x18
0x555555698718: 0x19 0x15 0x0e 0x01 0x00 0x00 0x08 0x06
# content[3] ^= 4
# content[4] ^= 4^content[3]
# content[5] ^= 5^content[4]
0x555555698700: 0x3b 0x29 0x1b 0x32 0x0e 0x01 0x38 0x35
0x555555698708: 0x27 0x24 0x27 0x27 0x3c 0x12 0x1c 0x0e
0x555555698710: 0x0e 0x0d 0x0e 0x0a 0x0d 0x19 0x0e 0x18
0x555555698718: 0x19 0x15 0x0e 0x01 0x00 0x00 0x08 0x06
# content[6] ^= 7
# content[7] ^= 7^content[6]
# content[8] ^= 8^content[6]
# content[9] ^= 9^content[6]
0x555555698700: 0x3b 0x29 0x1b 0x32 0x0e 0x01 0x3f 0x0a
0x555555698708: 0x17 0x15 0x27 0x27 0x3c 0x12 0x1c 0x0e
0x555555698710: 0x0e 0x0d 0x0e 0x0a 0x0d 0x19 0x0e 0x18
0x555555698718: 0x19 0x15 0x0e 0x01 0x00 0x00 0x08 0x06
逻辑虽然难以描述,但是规律还是一目了然,在加上之前逆出的mruby字节码逻辑,还是很容易猜出公式。该循环是一个异或的过程,每次处理1,2,3,4个字节,直到超出数组长度。
写出python还原输入:
a = [0x16, 0x27, 0x00, 0x35, 0x32, 0x16, 0x18, 0x15, 0x22, 0x21, 0x03, 0x1a, 0x1e, 0x1d, 0x3b, 0x1a,
0x2d, 0x38, 0x0e, 0x03, 0x28, 0x08, 0x28, 0x0e, 0x2e, 0x31, 0x39, 0x3e, 0x04, 0x1d, 0x15, 0x23 ]
s = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
v = 1
t = 1
l = 0
p = 0
while True:
a[p] ^= v
for i in range(l):
a[p+1+i] ^= (v+i)
a[p+1+i] ^= a[p]
v += t
t += 1
p += 1 + l
l += 1
if l > 6:
break
print('flag{{{}}}'.format(''.join(map(lambda x: s[x], a))))
flag: flag{Nbdn7YVDrt8PQOzAtZMQsUW7eszx4TLZ}
总结
Ruby作为一种灵活的脚本语言,经常在CTF比赛中出现,Ruby的一种实现————mruby解释器是基于寄存器的虚拟机,可以将Ruby代码编译为mruby字节码。mruby的编译器实现得比较简单,没有复制消除等优化过程,生成的字节码可读性很高,稍微静下心来逆出程序的逻辑还是比较容易的。







发表评论
您还未登录,请先登录。
登录