

前言
对抗攻击从2013年被Szegedy等人提出之后,截止目前,已经被研究的很深入了,相关文章也呈爆炸增长
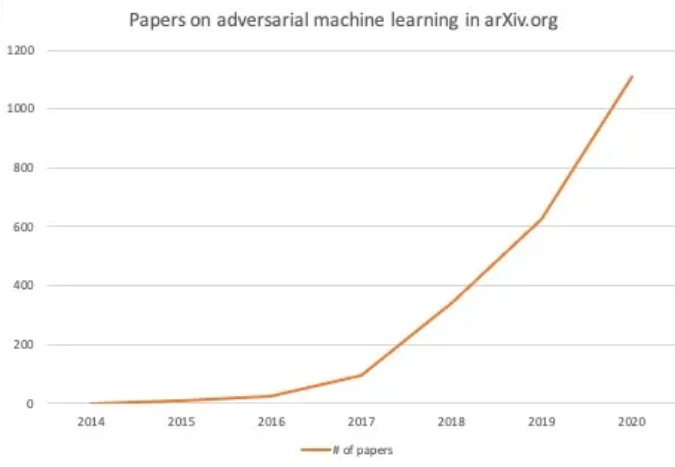
上图是发在arxiv上的有关对抗攻击的文章数量,该领域的火爆程度可见一斑。
现在如果这个时候要进入对抗攻击领域,可能需要往三条路去探索:1.寻找新的应用场景;2.设计的新的算法;3.研究如何规避已有防御方案。
为了方便第三条研究路线的探索,本文归纳分析已有防御方案特点。
对抗攻击
什么是对抗样本?
对抗样本(adversarial example)是指在原数据集中通过人工添加肉眼不可见或在经处理不影响整体的肉眼可见的细微扰动所形成的样本,这类样本会导致训练好的模型以高置信度给出与原样本不同的分类输出。
其中说的扰动(perturbation)是对抗样本生成的重要部分.一般来说,扰动需要有两个方面的要求:一是要保证其微小性,达到添加后肉眼不可见或者肉眼可见但不影响整体的效果;二是将其添加到原有图像的特定像素上之后,所产生的新图像具有迷惑原有分类深度模型的作用。
如果将对抗样本输入到深度学习模型里,可以引发模型的分类出现错误。现有的模型很容易受到对抗样本的攻击,它可以使模型产生误判,对抗攻击的流程中我们知道,会涉及输入样本以及模型两个关键组成部分。那么我们要进行防御的话也从这两个方向来做就可以了,对于样本的话,可以进行检测判断其是否为对抗样本,以及对其进行转换,消除对抗扰动特有的对抗扰动;而对于模型,则可以修改模型结构或者训练过程来增强模型的面对对抗攻击时的鲁棒性。我们接下来从模型和样本两方面来归纳分析代表性的防御方案。
防御
基于模型的防御
对抗训练是在训练集中加入对抗样本,以提升模型的鲁棒性。
对抗训练也可以分为两种,一般的对抗训练[1]所添加的对抗样本是通过攻击自身模型产生的,还有一种对抗训练方法[2]加入的对抗样本则是通过攻击其他模型产生的,通过增加对抗样本的多样性,提升了模型低于其他对抗攻击的鲁棒性。
具体而言,[1]从鲁棒优化的角度研究了神经网络的对抗鲁棒性,使用min-max公式将攻击与防御纳入一个共同的理论框架,这本质上是一个鞍点问题,而末尾呢可以通过对抗训练直接对其进行优化。问题如下
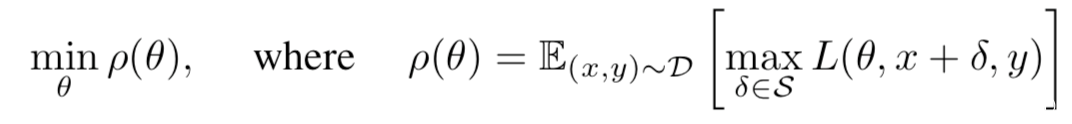
我们将p量化为网络的对抗损失。该问题的内部是最大化问题,外部是最小化问题的组合。内部的最大化问题的目标是找到给定数据点x的一个具有高损失的对抗样本,这正是对抗攻击的目标,而另一方面,外部最小化问题的目标是寻找模型参数,使得内部问题给出的对抗损失最小化,这正是模型的对抗鲁棒性的目标。这篇文章就是解决了这种鞍点问题在神经网络环境下的求解,从而实现对抗训练提升模型的对抗鲁棒性。其中一部分实验结果如下
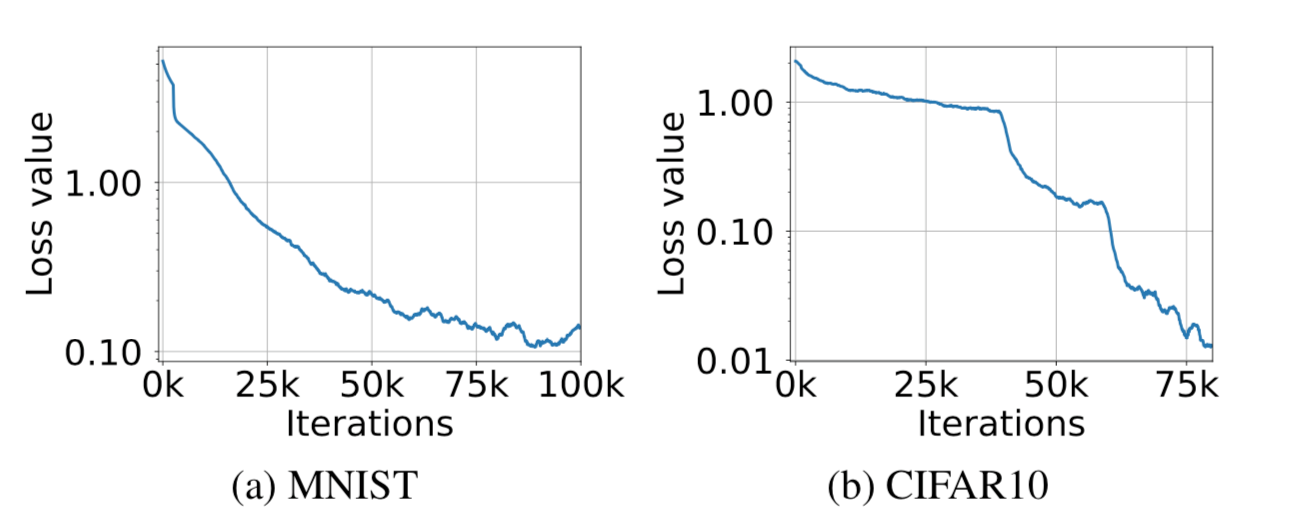
图中所示是对抗样本在训练期间的交叉熵损失,可以看到,在MNIST和CIFAR10上使用PGD攻击时对抗损失在持续下降,这意味着通过对抗训练,模型已经越来越鲁棒了。
[2]指出,由于对抗样本在模型之间可以迁移,在其他模型上生成的扰动是[1]所提公式中最大化问题的很好的近似,而其训练的模型不会影响这些对抗样本的强度,因为最小化训练损失的问题意味着增加了对来自其他模型的黑盒攻击的鲁棒性。部分实验结果如下
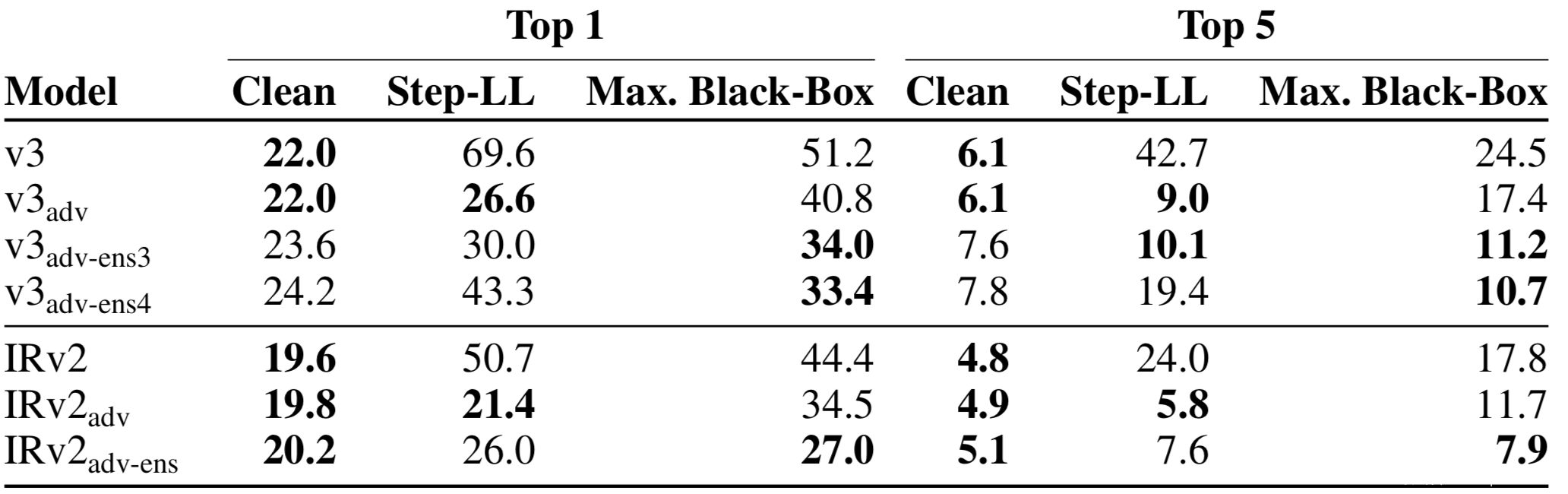
其中Step-LL是FGSM的一种变种,由其生成的对抗样本可以表示为
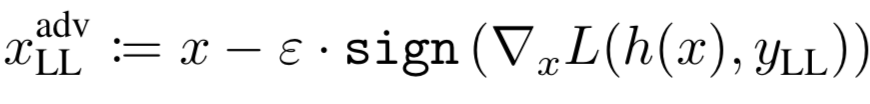
而Max.Black-Box是几种黑盒攻击(Step-LL,R+step-LL,FGSM,I-FGSM,PGD等)中具有最高错误率的数据。第一类中下标为adv-ens*的表示是通过集成对抗训练得到的模型,从表中数据可以看到,集成对抗训练得到的模型的错误率是最低的,说明其鲁棒性最佳。
[16]通过GAN,用两个网络交替训练,一个网络生成对抗样本,另一个网络尝试进行区分,通过相互博弈,他们构造的分类网络具有更高的鲁棒性,同时也可以检测对抗样本。GAN中的两个网络实际上是在通过值函数V(G,D)进行双方参与的min-max博弈:
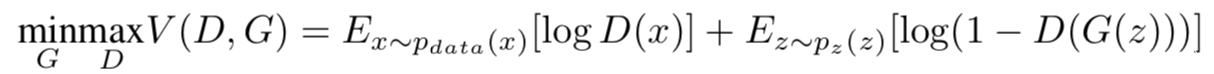
这种博弈会迫使两个模型都提高自己的能力,直到鉴别器无法区分生成的样本与原样本。[16]将该方案应用于提升模型的对抗鲁棒性,示意图如下
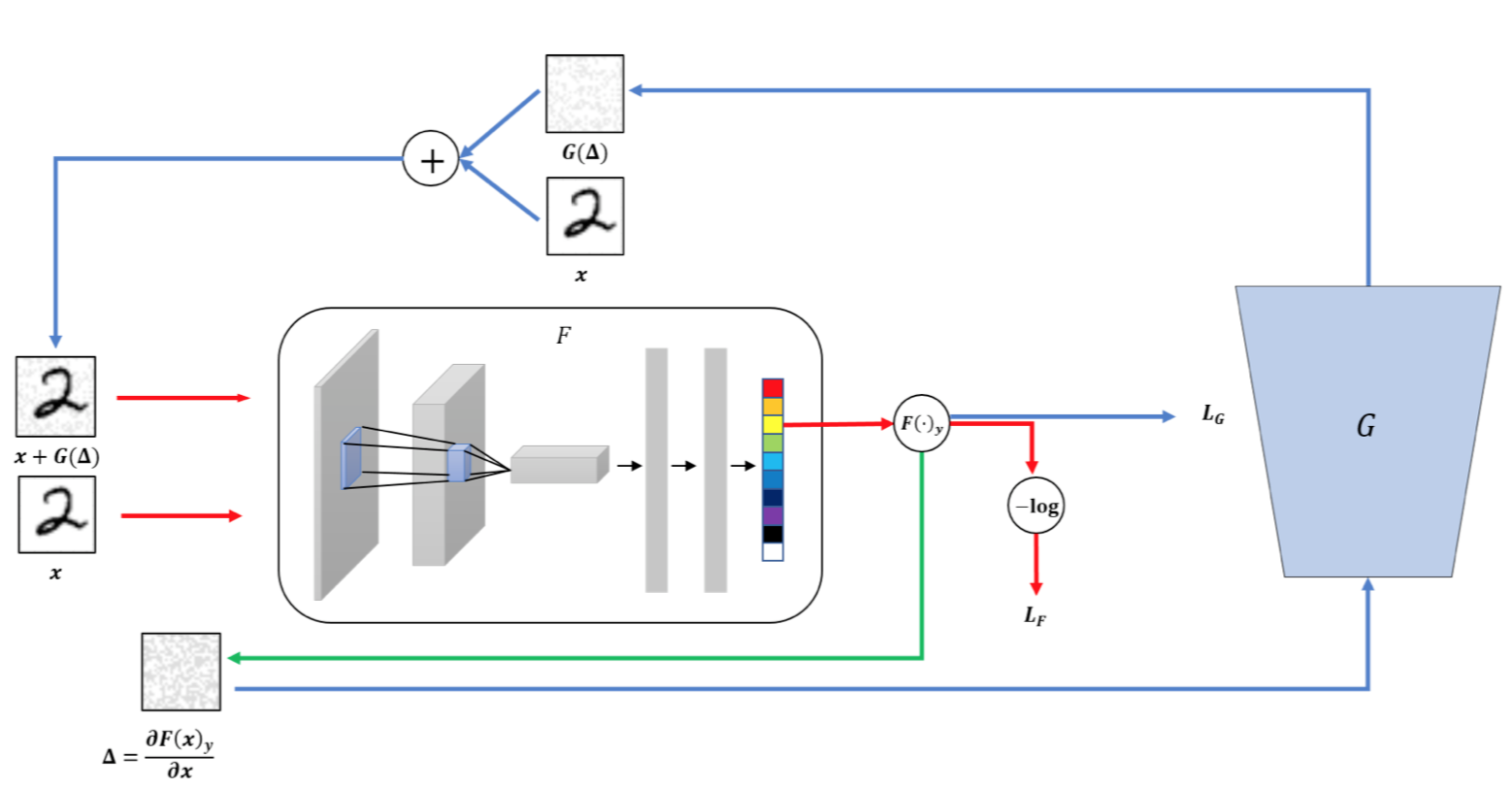
使用生成器G生成扰动,该扰动可以利用每个图像的梯度欺骗分类器网络,而在分类器网络F这边,训练其对G生成的对抗样本与原样本进行区分
生成器是其中的关键,其损失函数定义如下
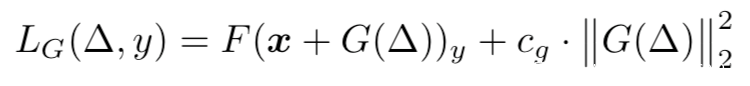
上式包括两个部分,一个是损失函数,这是用于寻找可以降低被F正确分类概率的扰动图像,另一个是代价函数,用于限制扰动功率,使其不要太大,而cg是用于调节两个函数之间比率的超参数。分类器F的损失函数基于对抗目标函数,表示如下
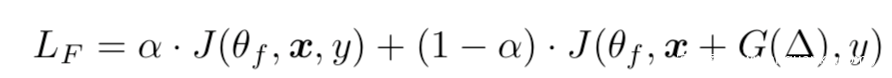
部分实验结果如下
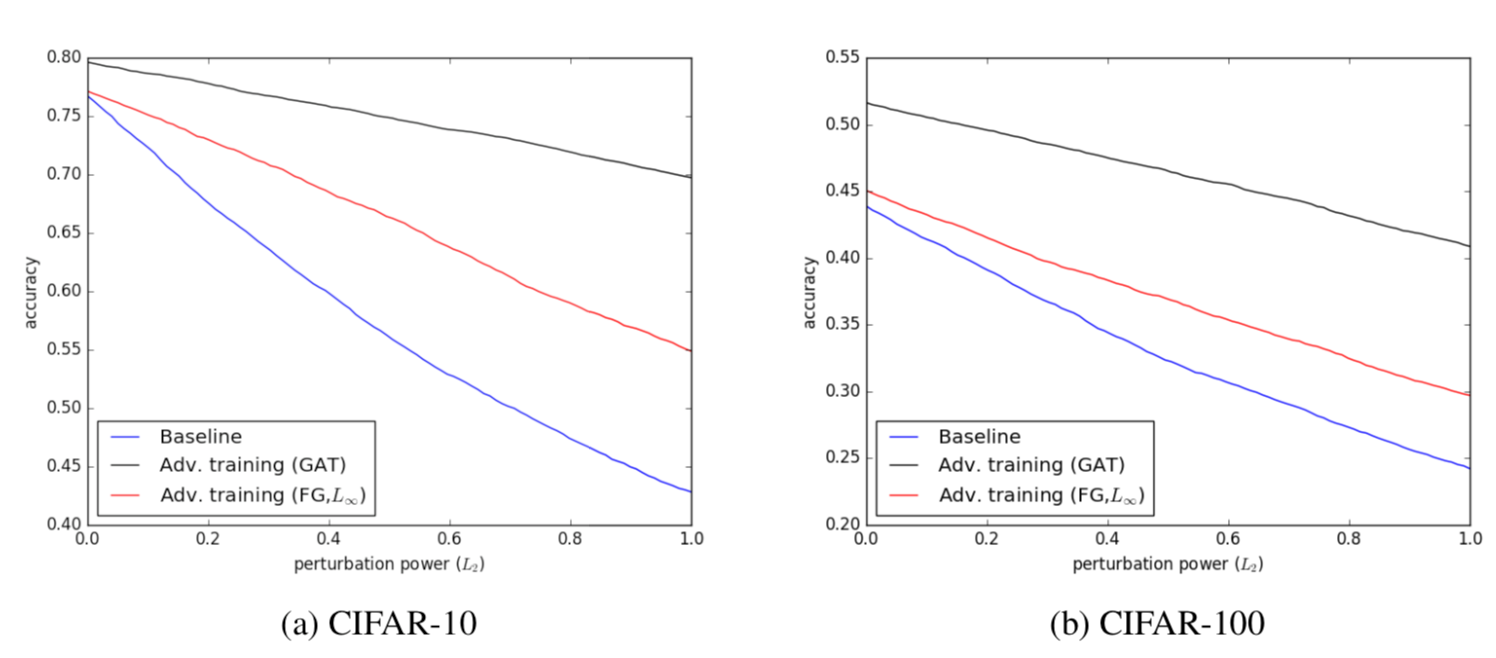
图中,a,b分别是在不同数据集上实验,黑线代表使用GAN训练得到的模型在面对对抗样本攻击时的准确率变化,红线是基础的对抗训练,蓝线是正常训练,从图中可以看到GAN训练得到的对抗鲁棒性高于基础的对抗训练,高于正常训练。
大多数攻击算是会使用模型的梯度信息来生成对抗样本(FGSM.BIM等),我们已经知道对于不可微分的模型(决策树、KNN,随机森林)基于梯度的攻击是无效的,因此可以通过隐藏模型的梯度信息实现防御。
[3]提出Deep Contractive network(DCN),通过在训练过程中引入contractive autoencoder(CAE)平滑惩罚项,使得模型的输出变化对输入敏感性降低,从而达到隐藏梯度信息的目的。理想情况下,DCN模型会惩罚下面的目标
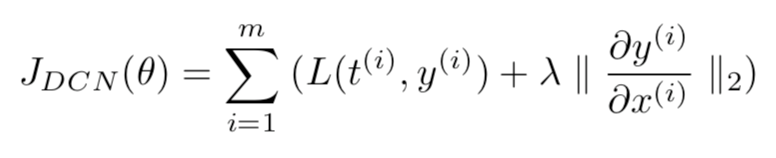
但是上式计算代表高昂,因为需要在反向传播的每一层上计算偏导数,因为可以将上式简化如下
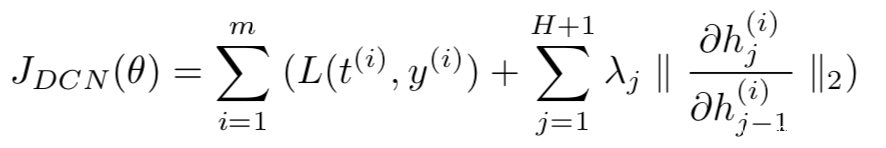
此时逐层压缩penalty使得计算偏导数的方法与CAE中的相同,并且很容易并入反向传播过程。
部分结果结果如下

从表中可以看到,DCN相比于原模型而言,要求对抗样本提升失真率才能发动攻击,说过DCN相比于一般模型具有更强的鲁棒性。
[4]提出了防御蒸馏,利用蒸馏方法,但是不改变模型的规模,只是为了让模型的输出更平滑,鲁棒性更高。该方案的示意图如下
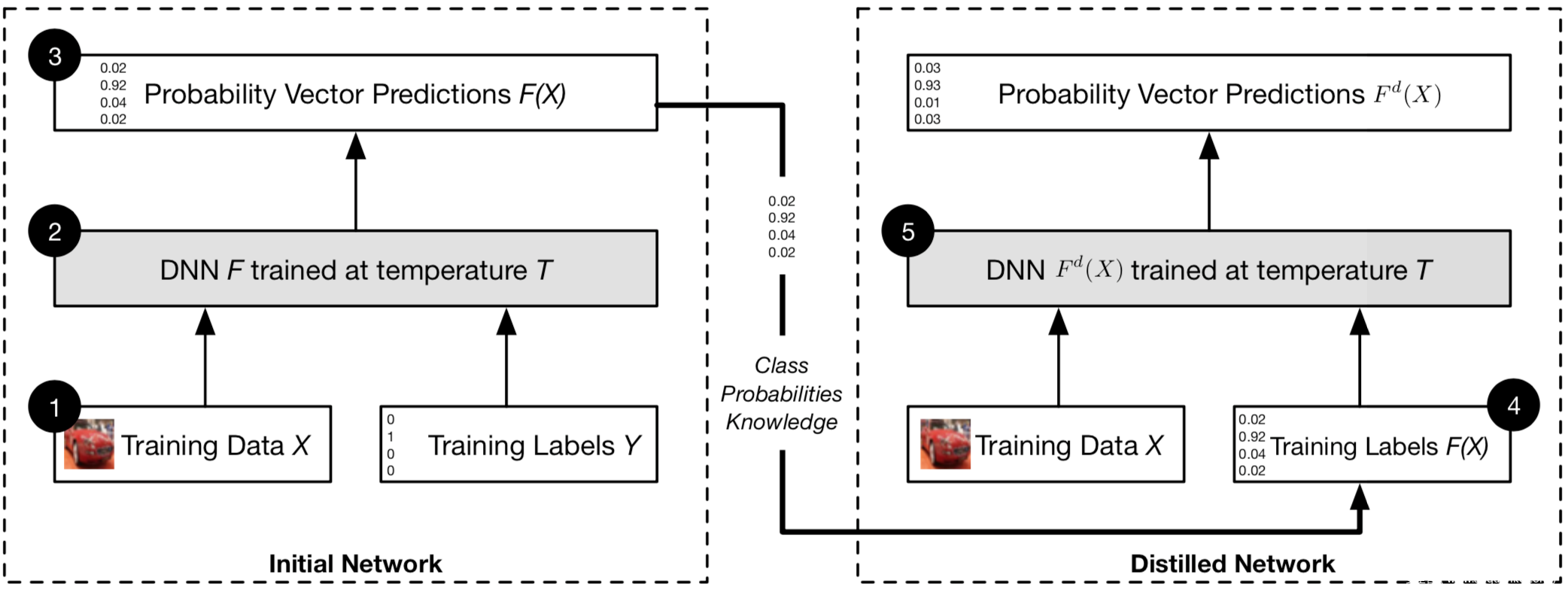
首先在soft温度条件下,在训练集X上训练一个初始网络F,然后得到其预测向量F(X),使用其中含有的类概率知识,在温度T下对同样的数据X训练蒸馏网络Fd
该方案背后的核心思想是,通过蒸馏提取的知识以概率向量的形式传给别的网络,可以维持与原网络相近的准确率,同时可以提升网络在训练集外的泛化能力,从而增强其对与扰动的抗干扰能力,即鲁棒性。部分实验结果如下
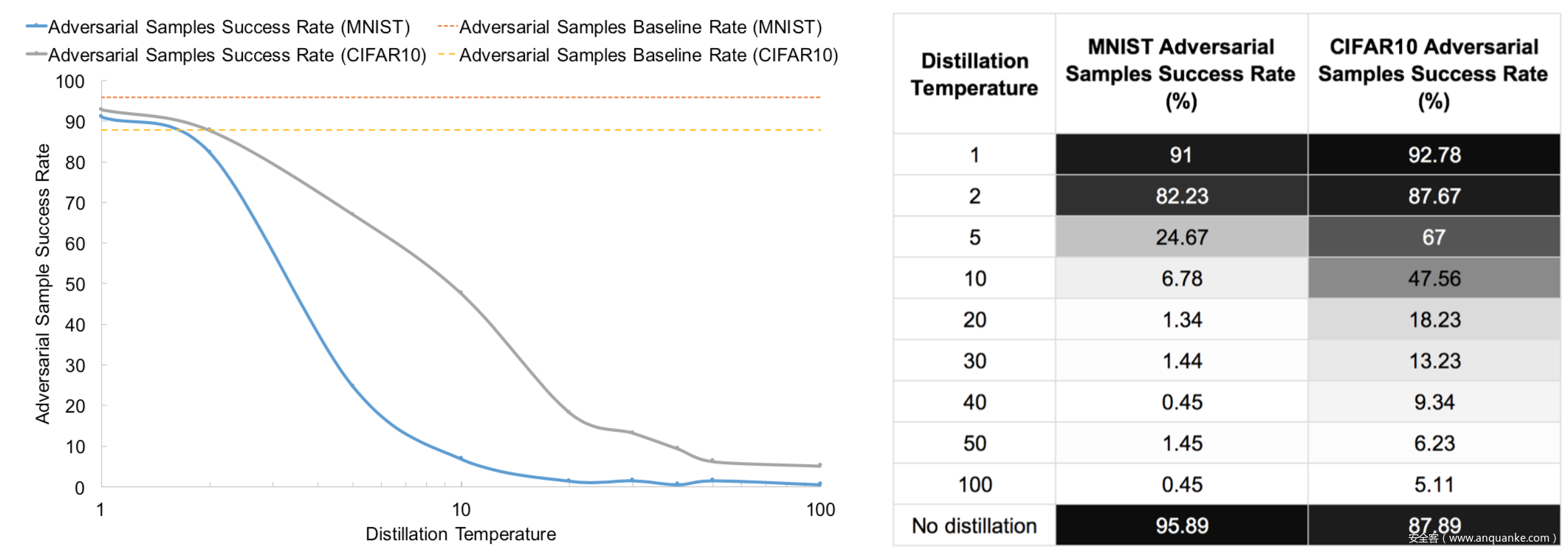
从图中可见,没有应用蒸馏时,对抗攻击的成功率在MNIST上为95.89%,在CIFAR10上为87.89%,而应用蒸馏后,在一定程度上温度越高,鲁棒性越强,从图中可以看到,对于MNIST数据集而言,当温度为40和100时鲁棒性最强,对于CIFAR10而言,温度达到100时其鲁棒性最强。
[5]使用输入梯度正则化进行训练,在目标函数上惩罚输出对于输入的变化程度,在一定程度上限制小的对抗扰动不会大幅改变最终模型的预测结果,提升了模型的鲁棒性。该方案是通过最小化网络的energy以及其相对于输入特征的变化率来进行训练,表示如下
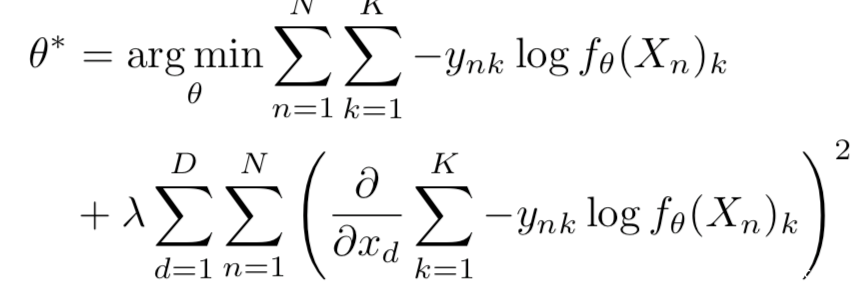
可以更精确的表示为
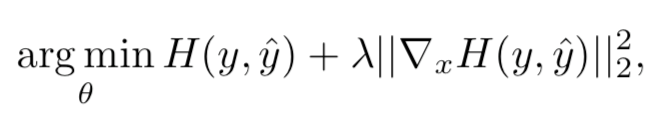
其中的lamda是指定惩罚力度的的超参数。
这种方案的目标是确保输入的任何微小变化,预测和标签之间的KL散度不会发生显著改变,将其应用于模型训练中可以提升模型鲁棒性。部分实验结果如下
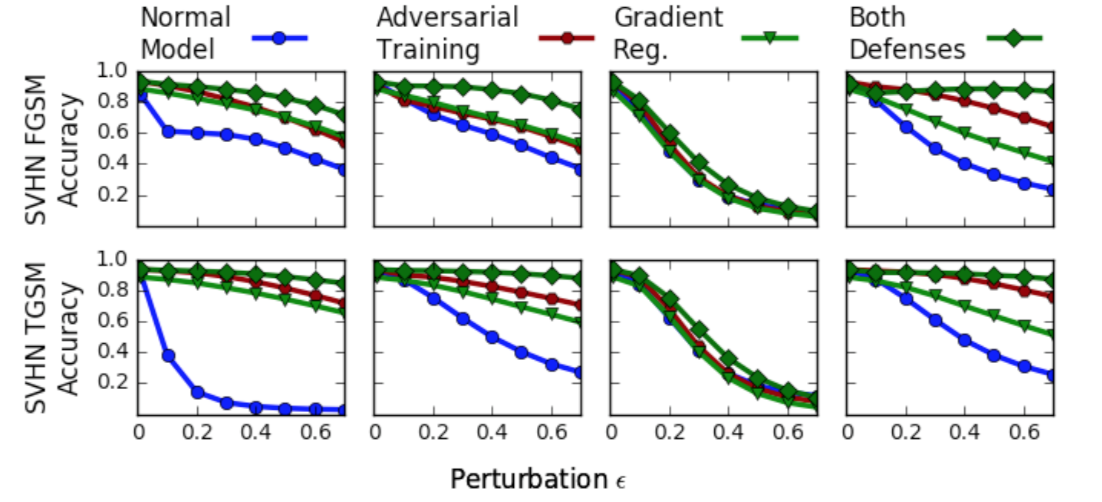
从上图可以看出,梯度正则化的方案确实极大提升了模型的鲁棒性,此外,如果可以同时结合梯度正则化与对抗训练,模型的鲁棒性会更高。
本质上基于梯度隐藏的方案还有[15]提出一种新的框架,该框架产生的梯度更新信息在统计上难以区分,因此通过梯度正则化,可以去除可能导致对抗样本的显著信息;此外,[11]使用高阶表征引导去噪器(HGD),训练一个基于神经网络的去噪器来消除对抗扰动也增强了模型的对抗鲁棒性。
基于样本的防御
[6]采用了最常用的5种图像预处理和转换方法,直接对输入的样本同时进行5种转换,提高模型预测对抗样本的准确度。
这5种方法可以进一步分三类,裁减-缩放(cropping-rescaling)、比特位缩减(bit-depth reduction)以及压缩(compression)是第一类。该类方案通过各种转换方法减少待预测样本中可能存在的扰动量,然后将转换后的样本输入模型进行预测。图像裁剪-缩放可以改变对抗扰动的空间位置,这对攻击的成功是非常重要的,研究人员在训练时间对图像进行裁剪和缩放,作为数据增强的一部分,而在测试时做输入样本做随机裁减,然后取预测的平均。位缩减则是一种 简单的量化操作,从图像中去除像素值的小扰动;压缩也是也类似的方法去除扰动。
第二类是总方差最小化(total variance minimization)。该方法随机选择一小组像素,并重建与所选像素一致的最简单的图像,重建后的图像不包含对抗扰动,因为这些扰动往往较小并且是局部的。首先通过对每个像素位置(i, j, k)采样一个伯努利随机变量X(i, j, k)来选择一个随机像素集;当X(i, j, k) = 1时,我们保持一个像素。接下来,我们使用总变差最小化来构造一个图像z,它类似于(扰动的)输入图像x,用于选定的像素集合,同时在总变差方面也是最简单的,通过求解下式即可
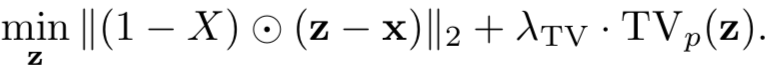
上式中的TVp代表总方差,通过下式计算
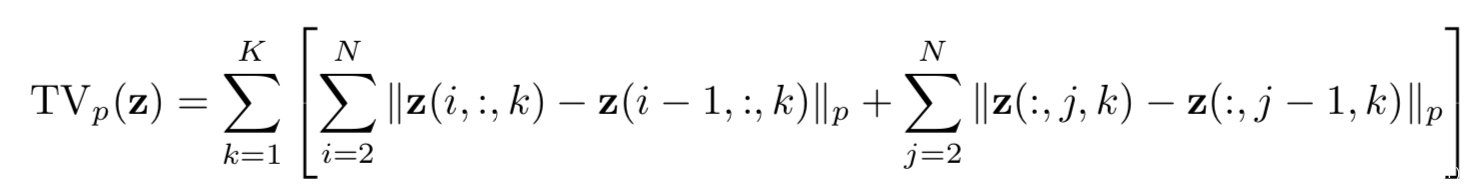
通过TV的最小化就可以去除小扰动。
第三类方法是图像缝合(image quilting).该方案通过构建一个只包含来自“干净”图像(没有对抗扰动)的补丁数据库来去除对抗性扰动;合成图像所用的补丁是通过从补丁数据库中的对抗图像中找到对应补丁的K个最近邻(像素空间),然后均匀随机地选取其中一个近邻来选择的。这种防御方案的背后的思想是,生成的图像只包含没有被攻击者修改过的像素,因为真实补丁的数据库不太可能包含出现在攻击者图像中的结构。部分实验结果如下
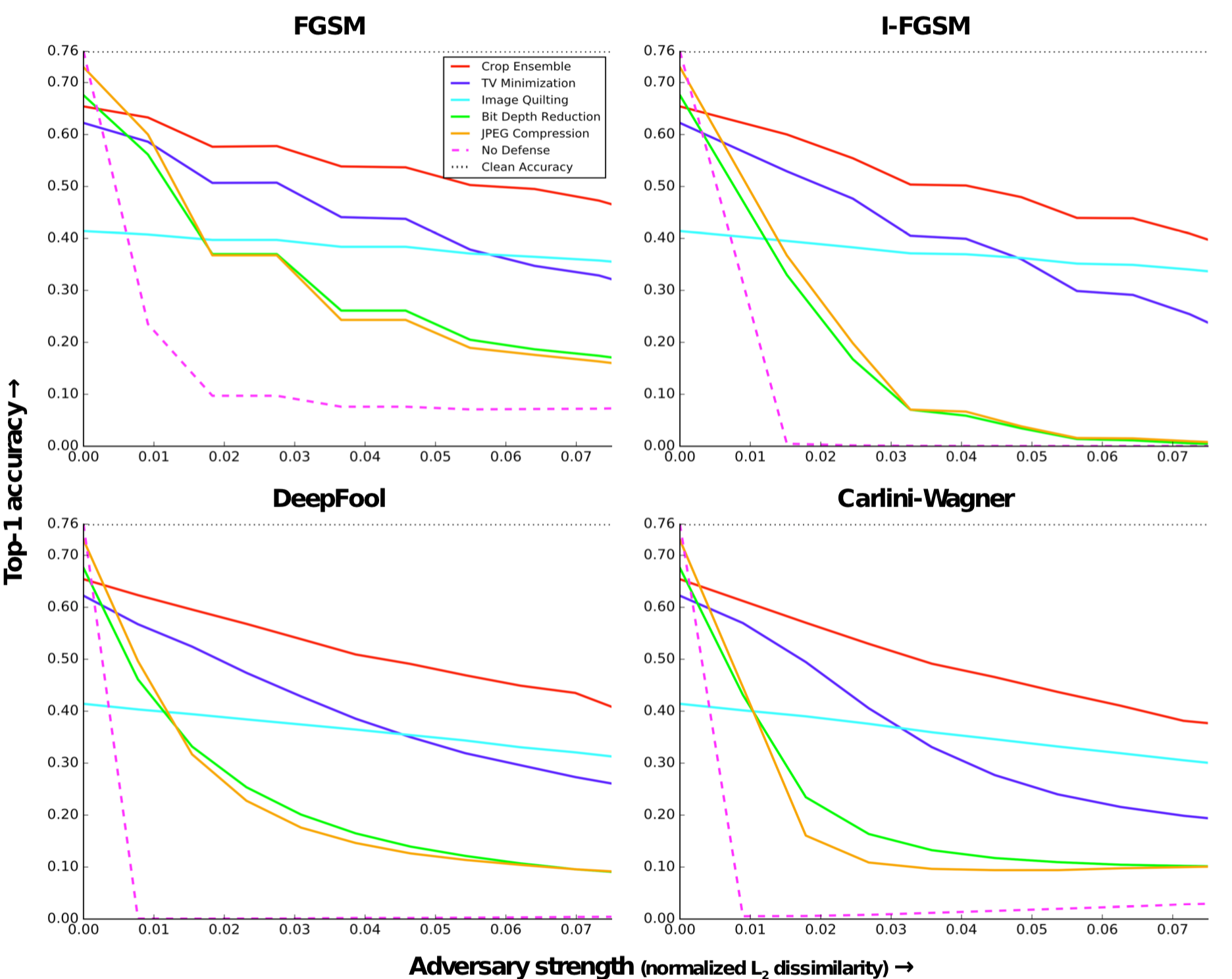
图中直观比较了5中处理方案与没有防御的情况的对比,可以看到,提出的5种防御方案的准确率都比没有防御时要高,此外,基于裁减-缩放的方案防御效果最好。
[7]在待预测样本输入到原模型之前增加额外随机化层(包括随机调整大小和随机填充(以随机方式在输入图像周围填充0)),再用原模型预测,处理流程如下所示
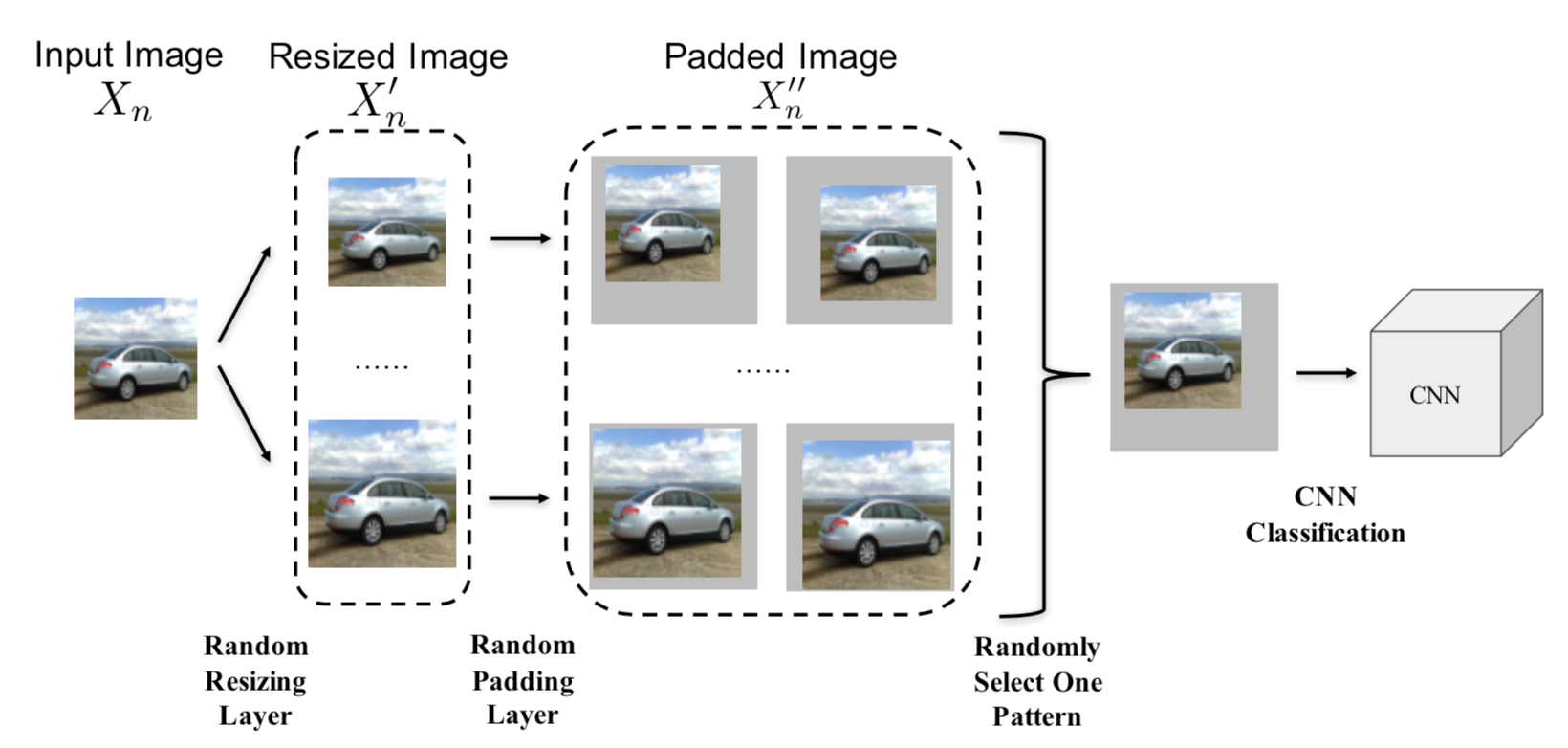
输入的图像首先经过随机调整大小,然后在随机调整大小基础上进行随机填充,让模型对填充后的样本进行预测。部分实验结果如下
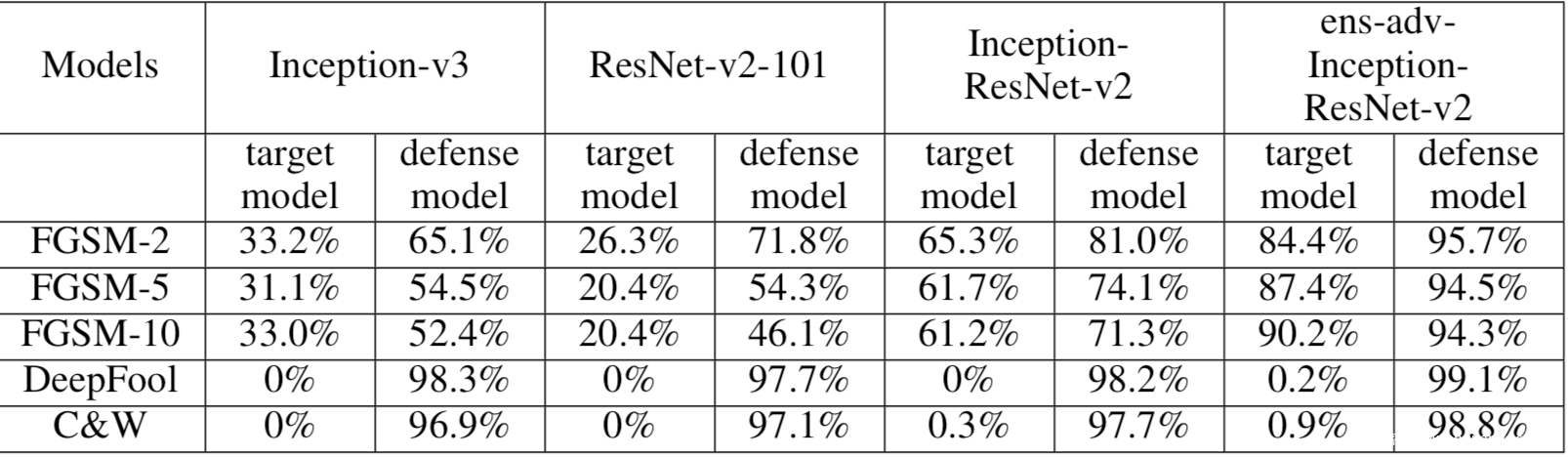
可以看到随机化层有效地减轻了所有对抗攻击,而且将其与对抗训练联合起来使用时,防御效果更好。
[8]设计了PixelDefend,通过将对抗样本向着训练集中呈现的分布移动,从而“净化”图像。
该方案背后的思想是对输入进行转换,通过对输入样本进行微小变换,可以将它们移回训练数据正常的分布,也就是将图像向高概率的区域移动。该过程可由下式表示
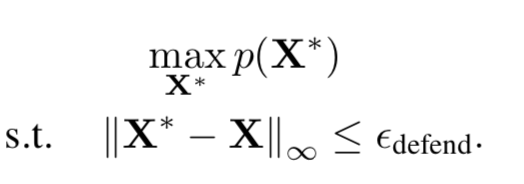
其中p是训练集IDE分布,输入样本为X,我们希望得到处理后的样本为X,这里的约束Edefend,是用于trade-off的,如果值过大,则X\可能与X的语义不同,而值较小,则可能不足以回到正常的分布。研究人员使用PixelCNN的分布pCNN(X)来近似p(X).部分实验结果如下
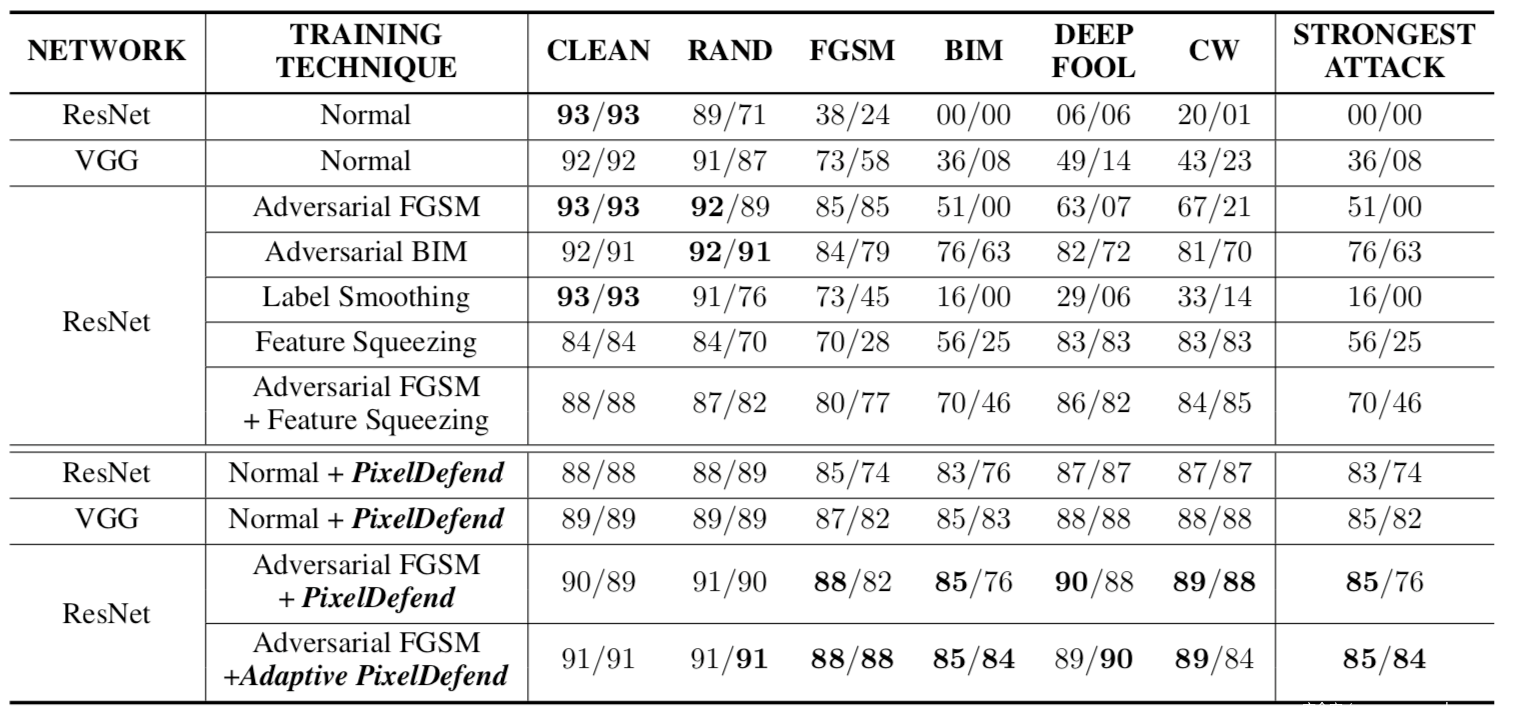
该表是在Fashion_MNIST数据集上实验时记录的。表中上半部分是基线防御方案的效果,下半不部分是本文的工作的效果,单元格中的格式x/y,其中x表示约束为8时,对图像进行攻击的准确率,y表示约束为5时的准确率。每一列中黑体标出的是最好的情况,从表中可以看出,该方案的效果在大多数情况下都是最优的。
同属于该类的方案还有:[17]在分类之前将位图输入图像转换为矢量图像空间并返回,以避免被对抗结构所欺骗;[9]将连续的输入样本使用温度计编码进行离散化,该方案在训练和预测阶段都使用温度计编码后的样本,限于篇幅不再展开。
[12]假设对抗样本不在非对抗数据流形中,在此情况下提出核密度法和贝叶斯不确定性估计2种对抗性检测方法。我们知道对抗样本可以让人类正确分类,但是模型却会误分类,我们可以从训练数据的流形的角度来理解这个现象。图像被认为位于低维流形上,有研究表明通过遍历数据流形,可以改变图像的真实类别。这背后的关键思想是,对抗扰动(对于输入没有有意义的改变)需要将样本从数据流形中推出去,对抗样本位于数据子流形边缘的类边界附近,基于这些研究,我们认为对抗样本不存在于数据流形上。假设原样本为x,其类别为cx,生成得到的对抗样本为x,x\不在流形中,其类别为cx*。
在二分类情况下,简化的示意图如下,图中对抗样本x*,被从“-”推出,黑色的虚线是决策边界,此时可能有三种情况:
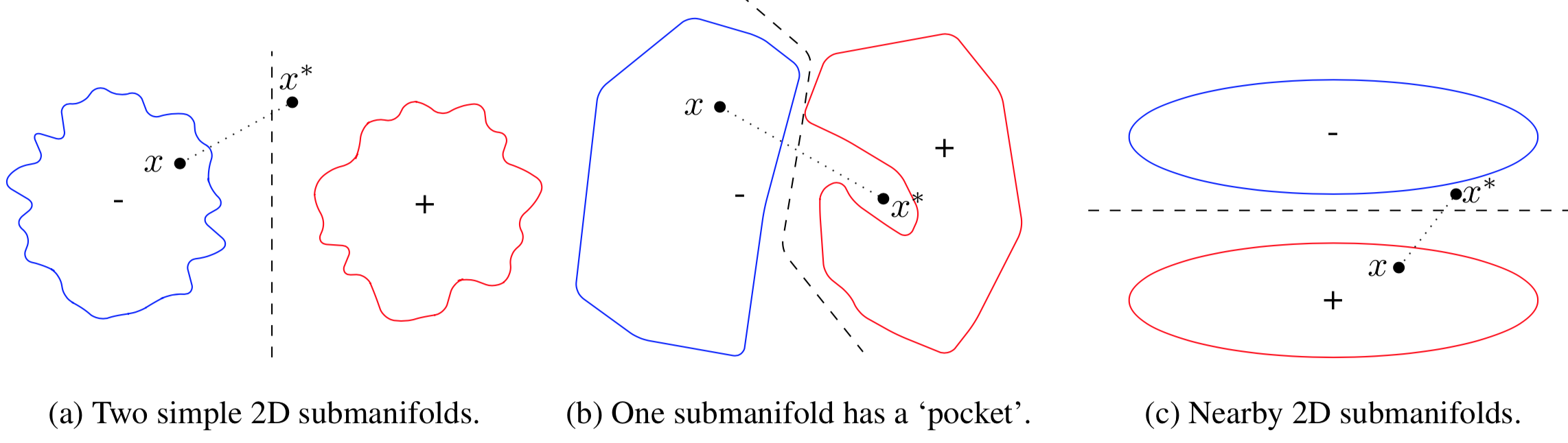
在a中,x离”+”子流形较远;在b中,“+”子流形有一个pocket,x\位于其中;在c中,x*离两个子流形的边界和决策边界都很近。
研究人员在最后一层隐层的特征空间中进行核密度估计,从而对每一类的子流形进行建模,密度估计的公式如下,其可以用于衡量x距离t子流形还有多远
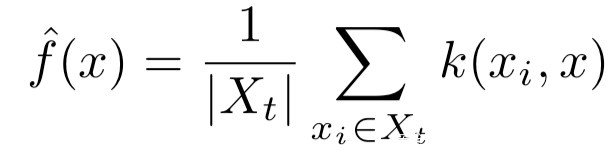
而对于预测类为t的点x,其密度估计定义为:
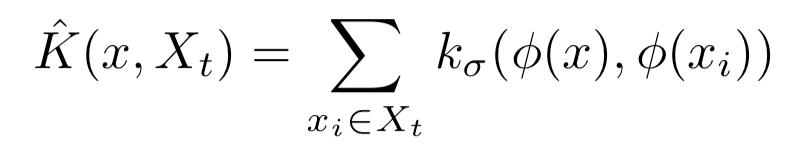
式中的φ是点x的最后一个隐层的激活向量,Xt是类t的训练集数据点的集合。
对于MNIST数据集,BIM对抗攻击而言,我们画出密度估计如下
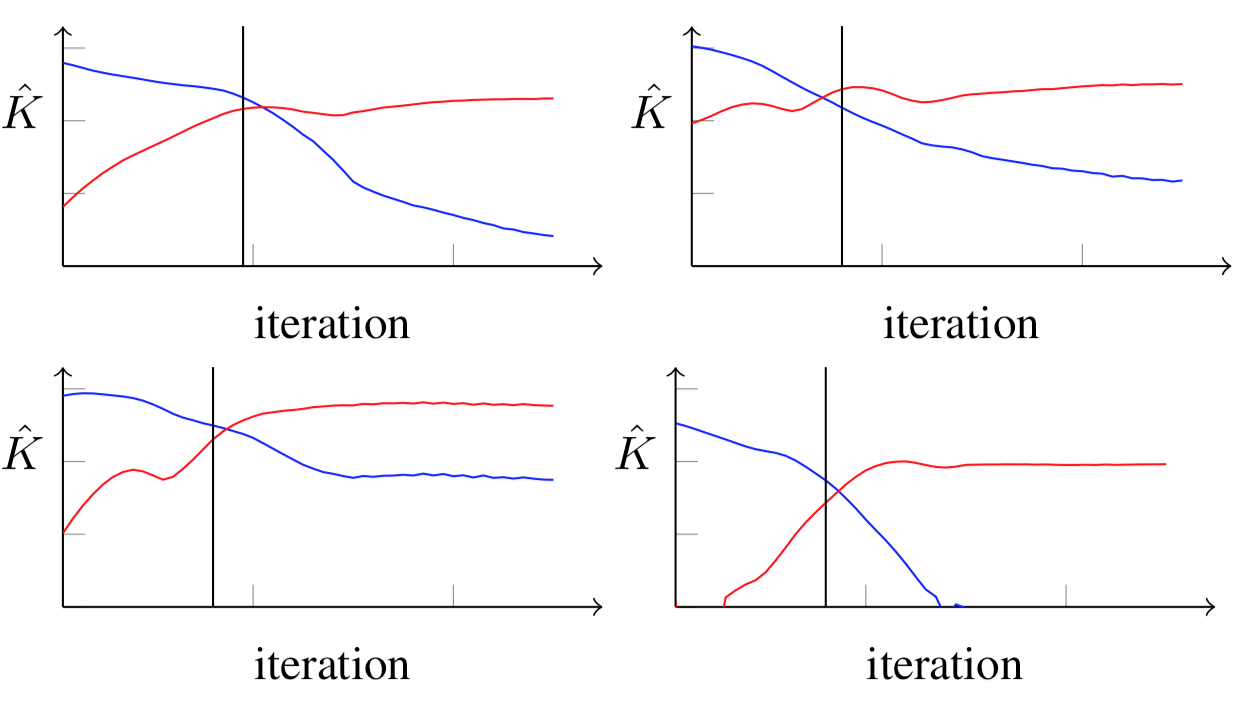
从图中可以看到,对原类的估计在下降(蓝色),对错误类的估计在上升(红色),而交叉点基本在预测类改变的附近(黑线)。所以该方法确实可以检测对抗样本,但是使用密度估计的方法可以仅可以轻易检测出原理cx*子流形的对抗样本,所以引出了第二种方法—贝叶斯不确定性估计,其可以通过下式进行计算
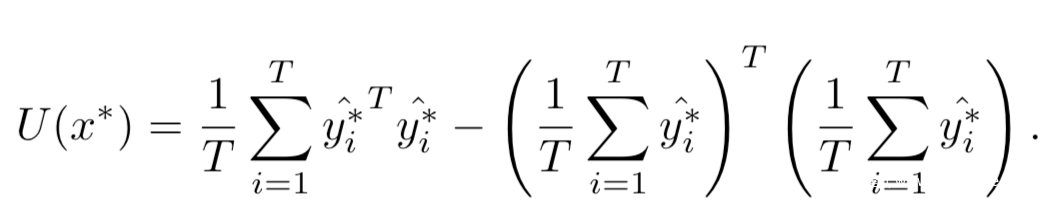
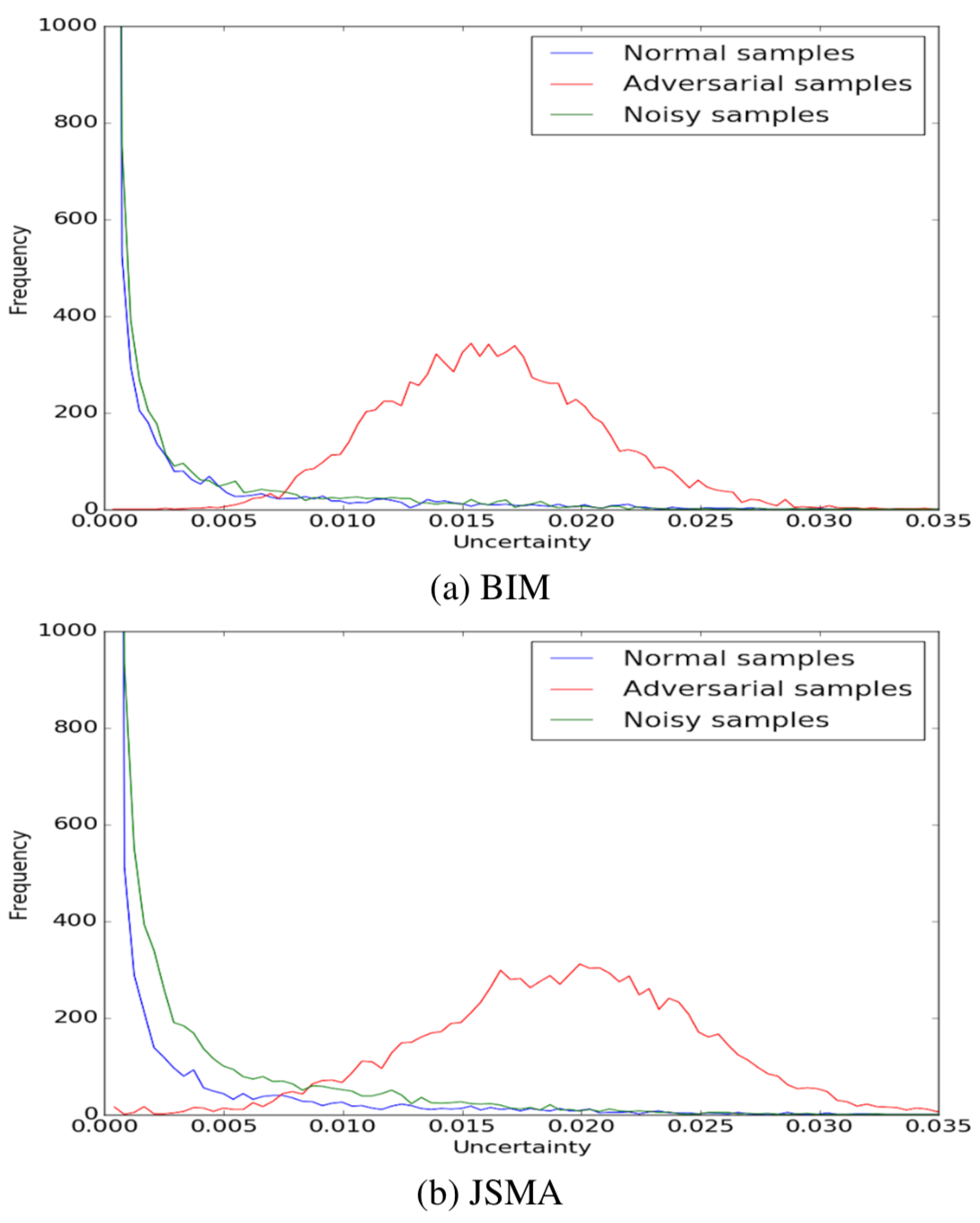
下图比较了对抗样本与正常样本以及噪声样本的贝叶斯不确定分布,对BIM和JSMA都做了实验,从下图的结果可以看到,对抗样本的不确定分布在统计上是不同于其他两类样本的,所以可以通过该方案进行检测。
该类型的其他方案还包括:[13]使用ADN作为二元检测器网络以区分正常样本和对抗样本,[10]利用对抗样本的LID(局部本征维数)远大于正常样本这一性质来区分对抗样本与正常样本.
总结
对抗防御的工作远不止本文介绍的这些,限于篇幅,本文仅介绍部分经典工作,不过本文基于防御方案的原理对已有的工作做了合理的划分,如果对某一子方向的感兴趣的话完全可以深入研究。
由本文归纳分析的方案,我们可以看到,基于对抗训练的防御不仅需要大量的正常样本,而且需要大量的对抗样本,极大增加了训练的时间和所需资源,所以该方案很难在实际大规模数据的场景下应用;此外,该方案只能加入由已知攻击技术产生的对抗样本,所以实际上只能在面对同类型攻击时防御才有效,对其他攻击产生的对抗样本不具有鲁棒性。而基于梯度隐藏的方案需要改变模型结构并重新训练分类器,复杂度高。与此同时该方案很容易被绕过,一个简单的方法就是训练一个与被防御的模型相似的替代模型,使用替代模型的梯度来构造对抗样本,从而绕过基于梯度的防御。基于输入转换的防御需要对输入样本进行转换,但是转换之前必须进行检测,对疑似对抗样本的输入样本采取转换措施,不过该方案的FP,TN都较大。基于检测的防御仅限于检测,检测之后如何处理没没有统一的较好的方法。
对抗样本的防御之路任重而道远。
参考
1.towards deep learning models resistant to adversarial attacks
2.Ensemble adversarial training:attack and defenses
3.towards deep neural network architectures robust to adversarial examples
4.distillation as a defense to adversarial perturbations against deep neural networks
5.Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients
6.Countering Adversarial Images using Input Transformations
7.Mitigating adversarial effects through randomization
8.PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples
9.Thermometer Encoding: One Hot Way To Resist Adversarial Examples
10.Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality
11.Defense against adversarial attacks using high-level representation guided denoise
12.Detecting adversarial samples from artifacts
13.On Detecting Adversarial Perturbations
14.Intriguing properties of neural networks
15.gradient adversarial training of neural networks
16.Generative adversarial trainer: defense to adversarial perturbations with GAN







发表评论
您还未登录,请先登录。
登录