

前言
在图像领域的对抗样本的例子大家已经很熟悉了,比如下图的例子,对熊猫进行对抗扰动,模型就会将其识别为长臂猿

但实际上对抗样本并不仅仅存在于图像领域,在其他系统中也面临对抗样本攻击的风险。本文就会介绍视频领域以及音频领域的对抗样本攻击,包括相应的saliency frame attack,PGD attack等技术,同时通过直接的视频压缩、音频压缩进行防御。
攻击视频动作识别(video action recognition )系统
我们使用UCF101数据集,UCF101是从YouTube收集的真实动作视频的动作识别数据集,有101个动作类别,共13320个视频,UCF101在动作方面有很大的多样性,并且在相机运动、物体外观和姿势、物体尺度、视点、杂乱背景、照明条件等方面存在较大变化,它是最迄今为止具有挑战性的数据集。101个动作类别的视频分为25组,每组可以包含4-7个动作视频。来自同一组的视频可能具有一些共同的特征,例如相似的背景、相似的视点等
我们针对其中篮球动作的一小段视频进行实验。视频如下

首先我们先准备好待会儿会用到的函数
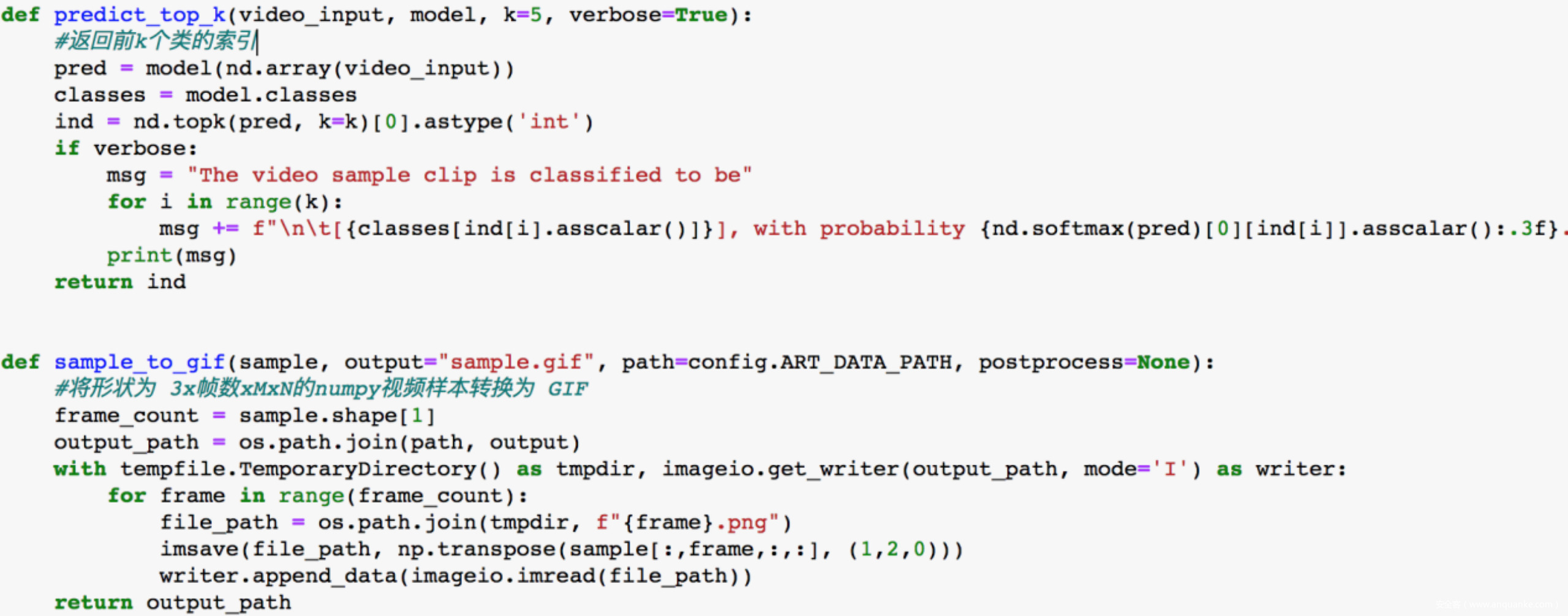
由于训练比较费时,而且不是本文的重点,所以我们直接加载其他人已经预训练好的模型

查看模型对篮球动作的预测结果

可以看到以0.725的置信度将该动作识别为篮球。
接着我们使用FGM进行攻击,攻击会破坏视频样本,使其被错误分类。
FGM全称是Fast Gradient Method,容易让我们想到FGSM(Fast Gradient Sign Method),其实FGM就是FGSM的变种,因为其攻击还扩展都了其他范数,所以称之为FGM,其代码实现如下
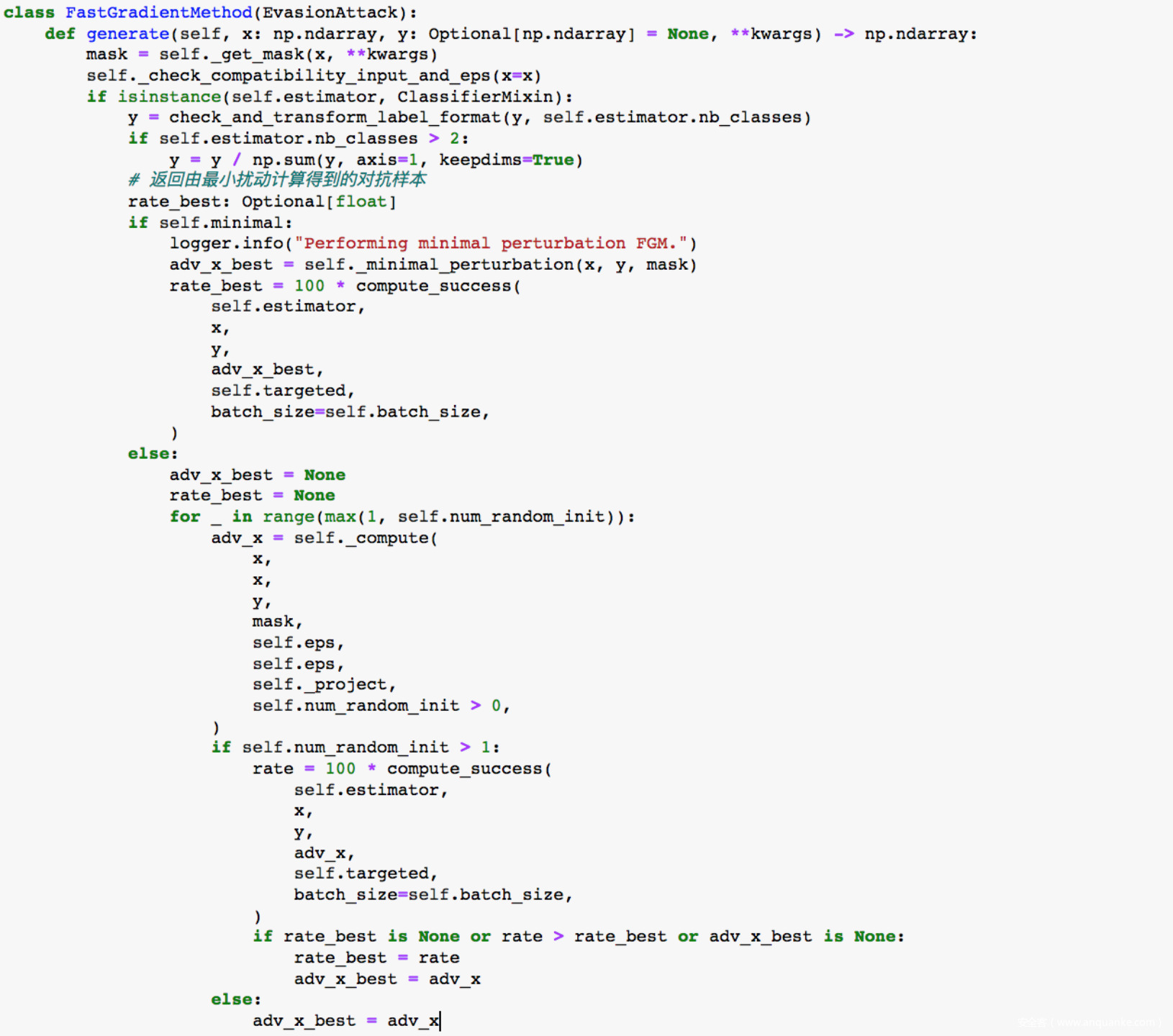

接着让模型预测对抗样本

可以看到,已经预测失败了,甚至top-5里面都没有篮球
这个方法我们在面对图像的对抗样本中也见过。接下来我们应用基于帧显著图(frame saliency)的方法来进行攻击,我们将帧按照显著性递减的顺序进行扰动
我们将帧的显著性定义为
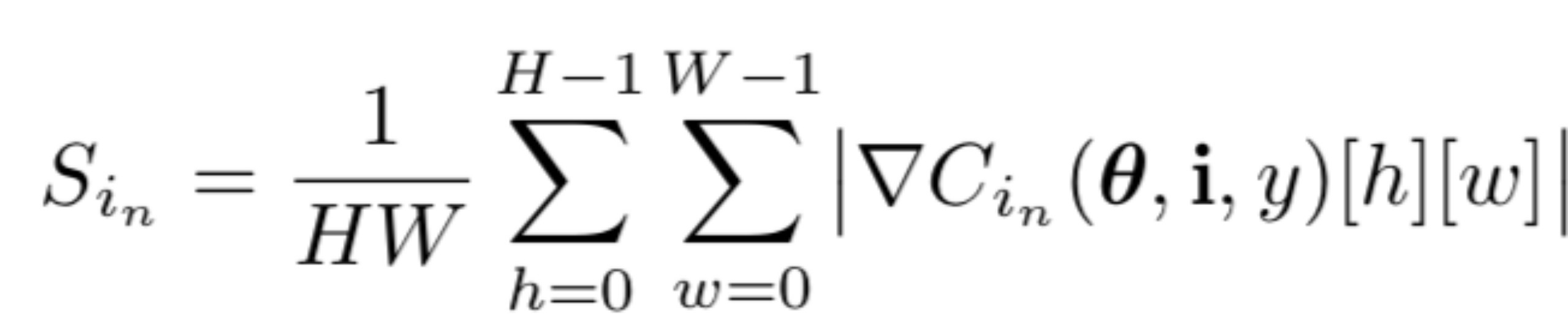
其中,H 和 W 分别表示视频帧的空间高度和宽度。 换句话说,这个显著标量是关于单个帧梯度的平均幅度。
这个概念其实是受到Simonyan等人的启发,他们指出“使用类分数导数的图像特定类显著性表明了对图像的哪些像素更改最少能对类分数影响最大”,这种攻击背后的直觉是,通过迭代扰动对预测结果最敏感的视频帧(即上面公式计算得到的有高平均显著性的帧),我们可以制作稀疏扰动的对抗样本。代码实现如下

我们可以直接指定对某一帧进行扰动,如下所示
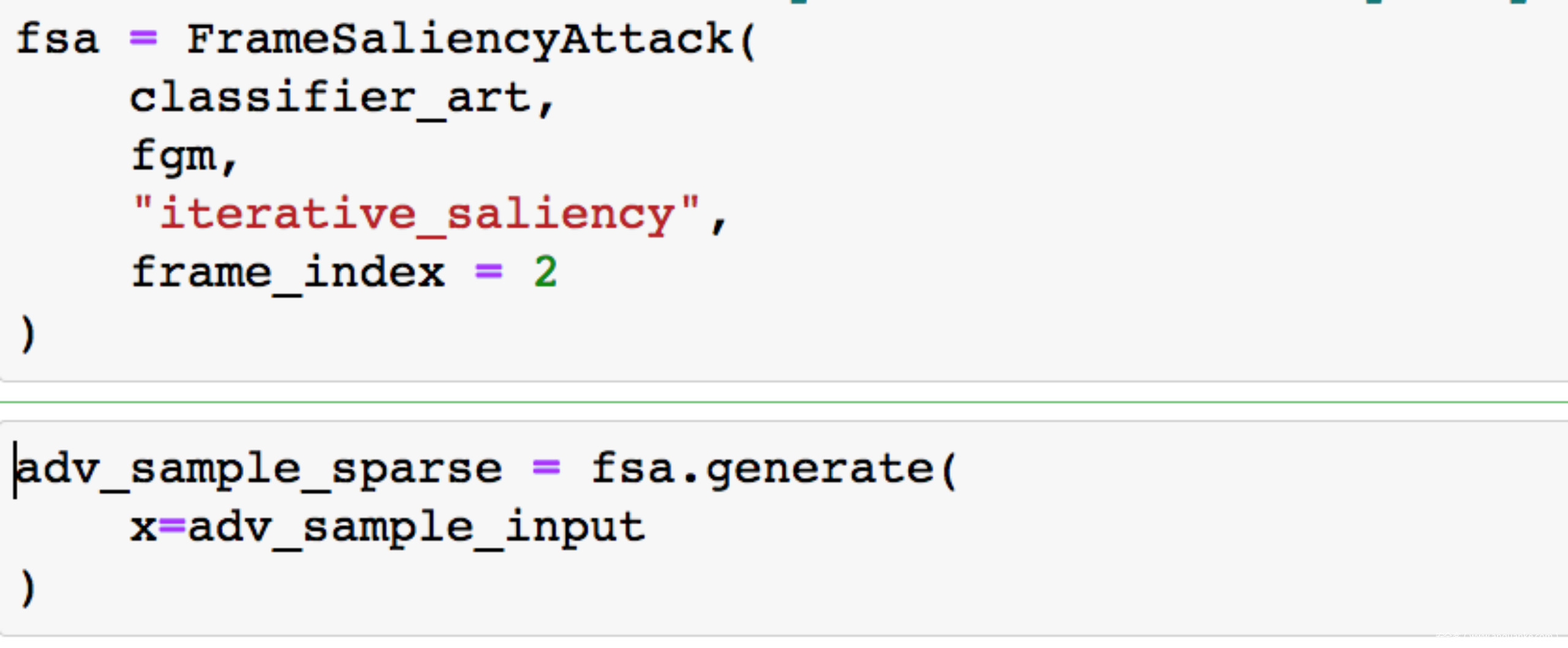

从预测结果可以看到,排在第一位的是打网球,不过打篮球排在第二位
由于对抗样本返回时是数组形式,我们可以将其保存成gif格式
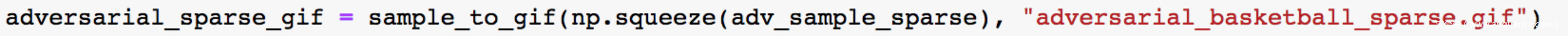
保存后的gif如下所示

这个对抗样本和原来的视频我们人眼当然是看不出区别的
那么应对这种防御,有没有什么防御技术呢?
最简单的办法就是在预处理层面做防御,直接对视频做压缩,基于 H.264/MPEG-4 AVC进行视频压缩防御。视频压缩的基本原理就是去除图像的冗余信息。同一张图像内会有很多冗余的区域,视频的图像序列之间也有很多冗余的区域,视频的帧率越大,冗余度会越大。当然,我们在这里进行压缩的目的是为了去除对抗样本中添加的额外扰动。
其实现代码如下

应用后的结果如下
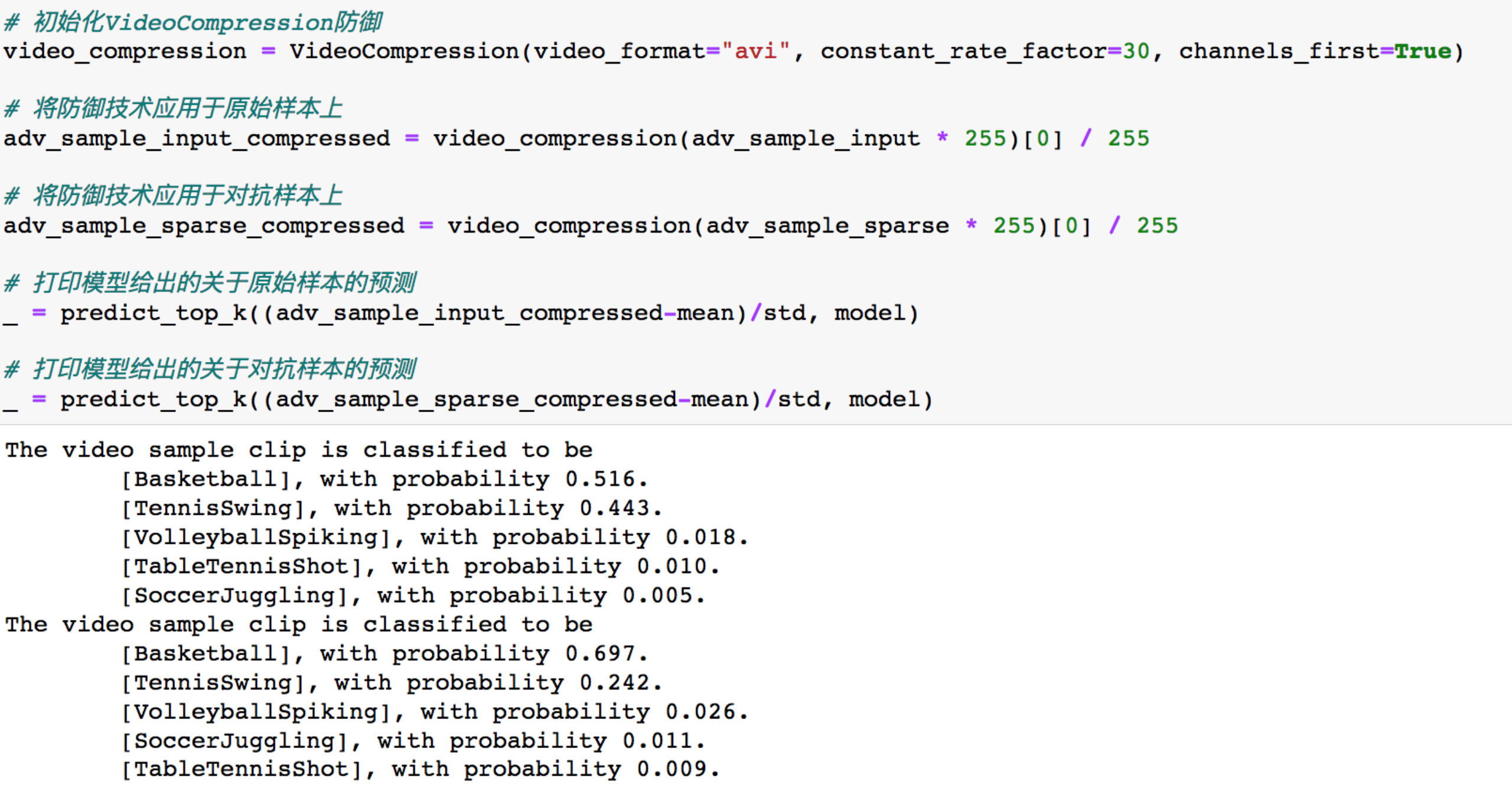
可以经过视频压缩,不论是原视频还是对抗样本都以最高的置信度被分类为了篮球,说明该防御技术是有效的。
攻击音频识别(speech recognition)系统
我们使用的数据集是AudioMNIST,该数据集由60个不同说话人的30000个语音数字(0-9)的音频样本组成。每个说话人都有一个保存自己录音的目录。
首先下载数据集及在其上预训练好的模型

由于涉及到音频,所以还需要准备好后面会用到的辅助函数

然后加载测试集以及模型

接下来该发动攻击了,但是怎么对音频信号发动攻击呢?
对抗样本的实质就是在特征空间添加扰动,那么对于音频信号,我们可以考虑在其频谱特征x上添加扰动,如下所示
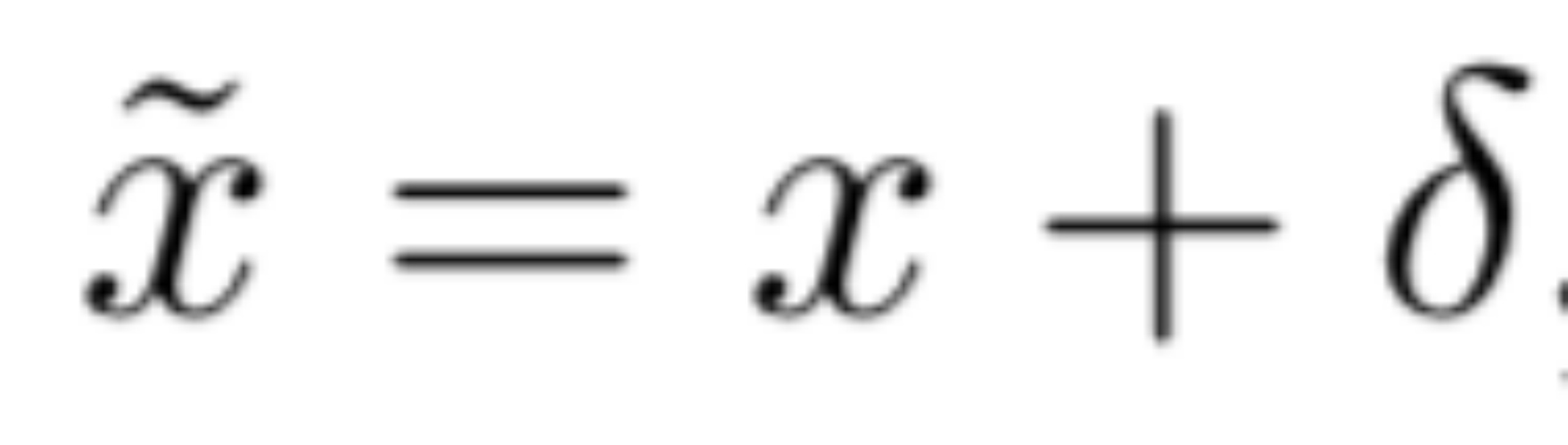
其中,足够小,以至于扰动版本的x~重建得到的音频信号对于人类而言与x是无法区分的,但是却可以欺骗模型做出误分类的结果。
如何找到一个合适的可以形式化为求解下面的优化问题
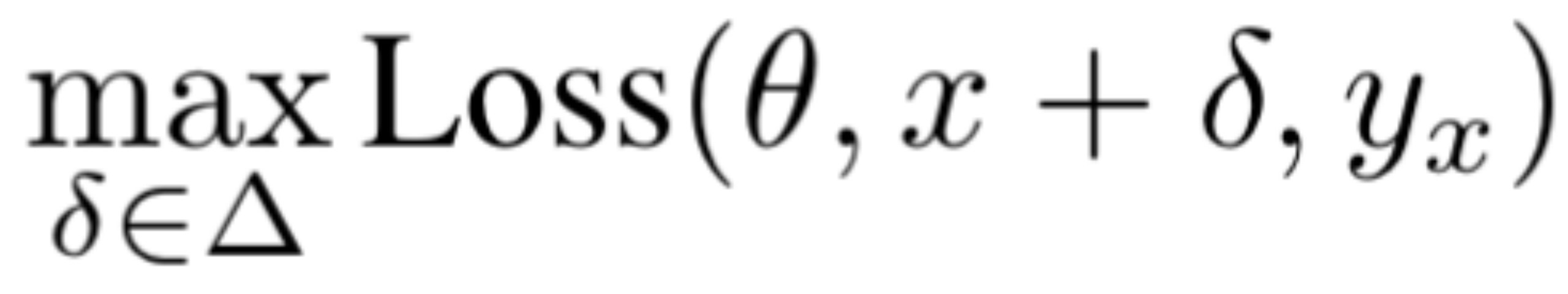
其中,loss是损失函数,是模型参数,是x的标签,是允许扰动的集合,表征着攻击者的能力。我们可以设为一个小的-ball,即
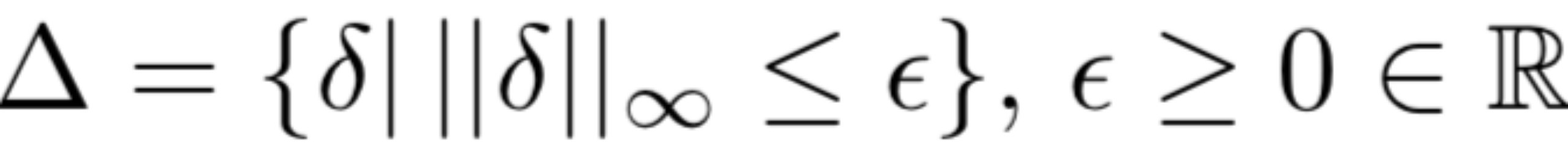
我们可以应用PGD解决此优化问题。
PGD是一种迭代的方法,从原始输入开始,输入根据下式进行迭代更新
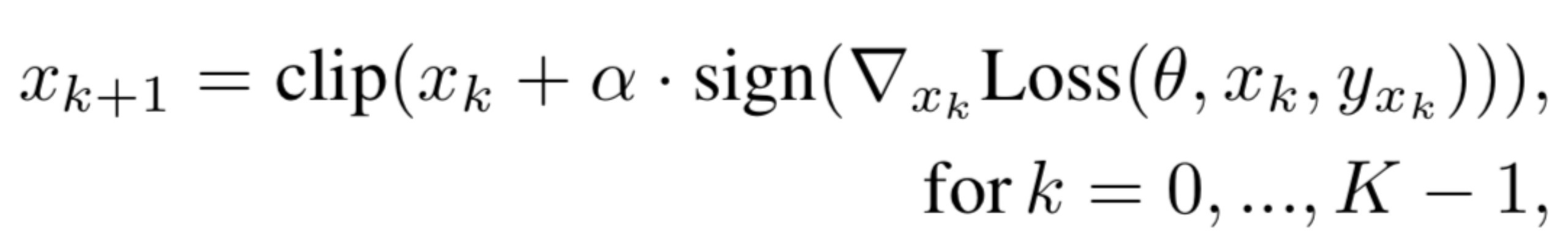
其中,是步长,K是迭代次数,clip()函数用于逐元素裁减以满足
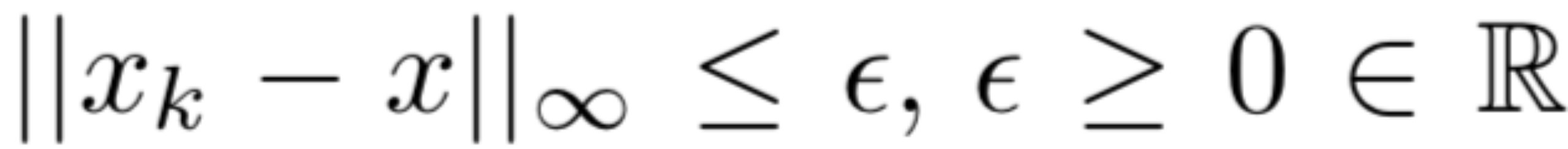
我们将作为最终得到的扰动的频谱特征。
PGD的代码实现如下
清楚攻击方案后,我们来进行实践。
加载一个测试样本,并应用PGD生成对抗样本,然后使用模型分别预测这两个样本查看其预测结果
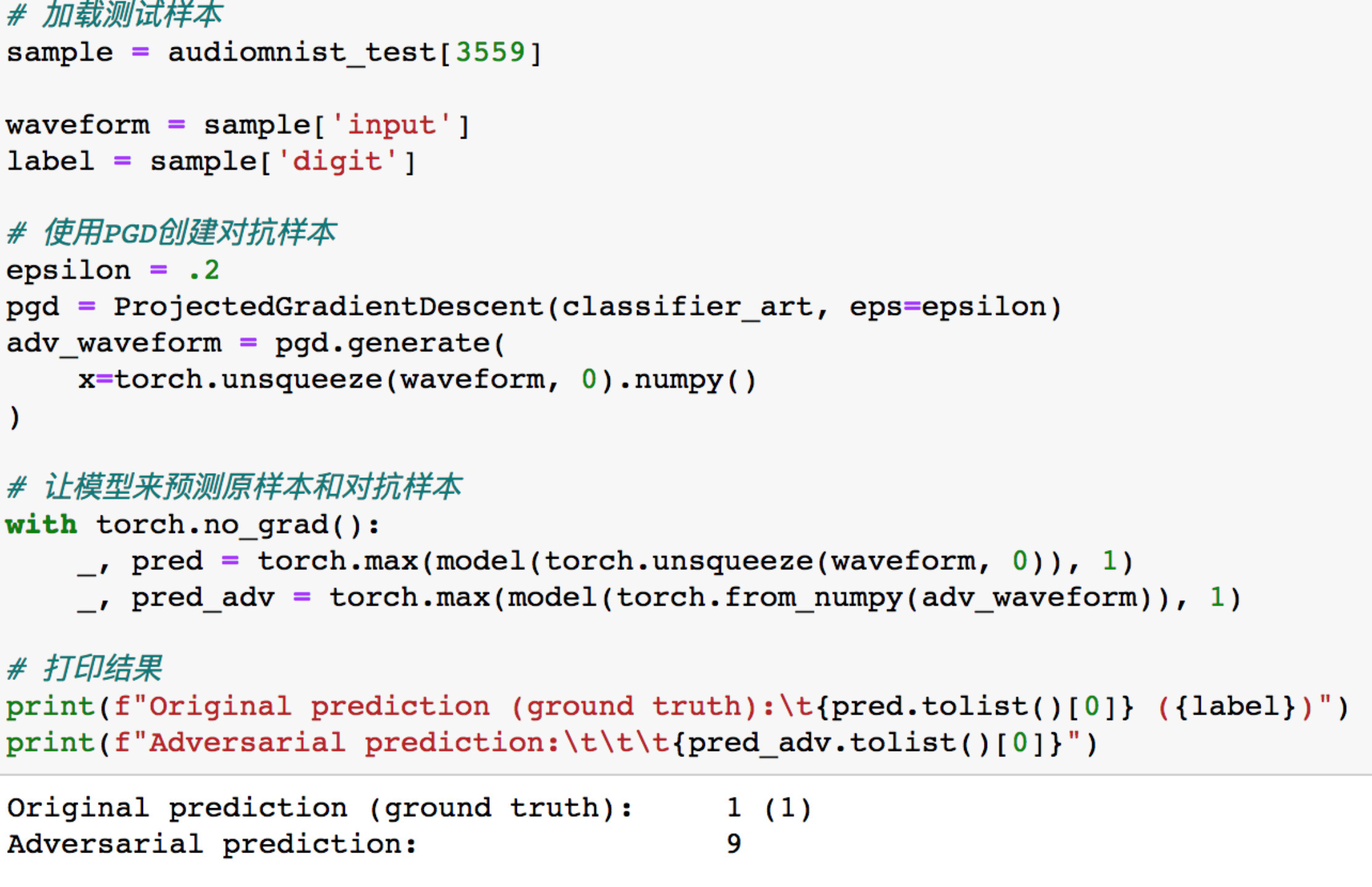
可以看到原样本被预测为了1,而对抗样本被预测为了9,说明对抗样本攻击成功了
打印出他们的波形看看
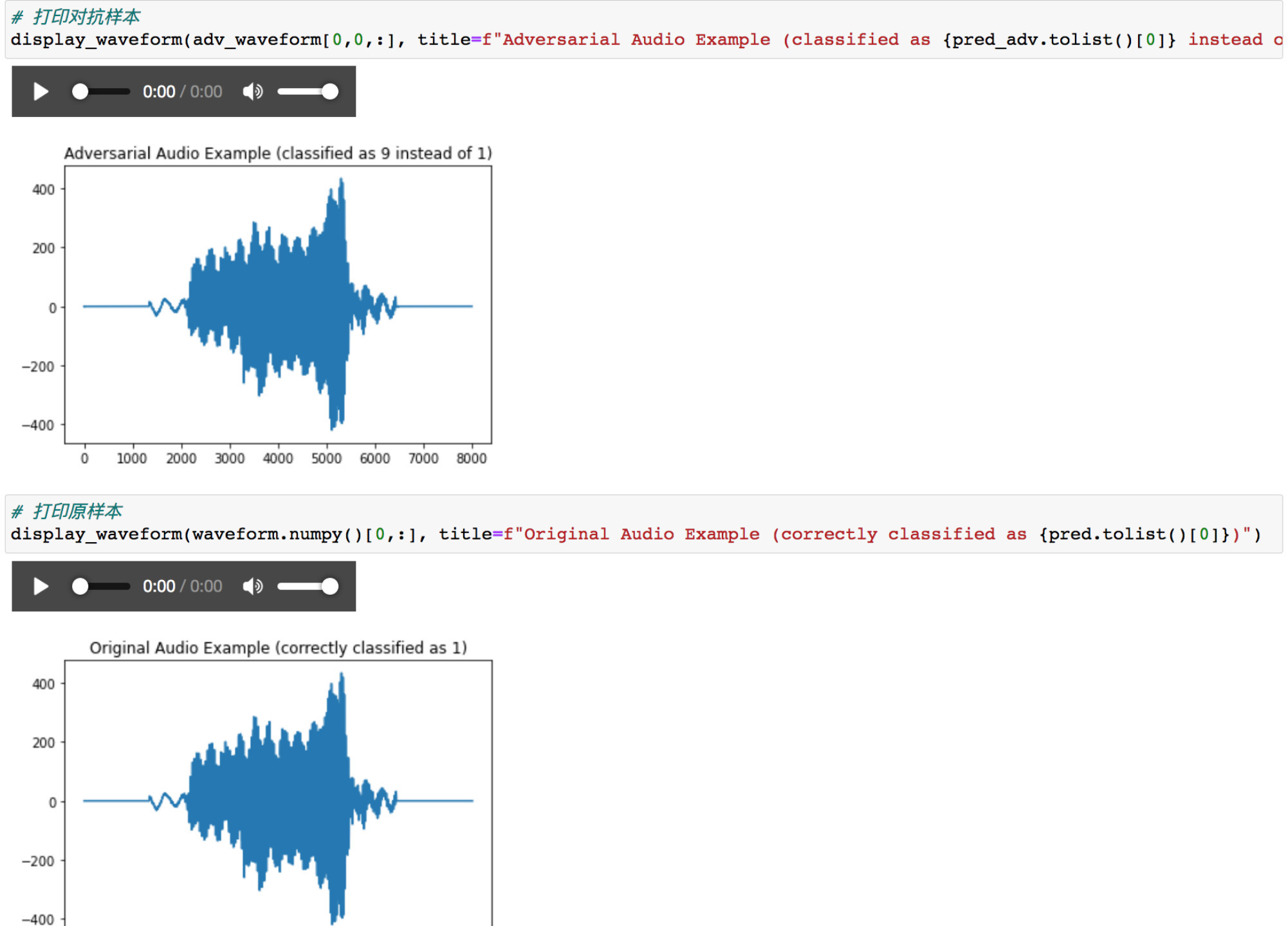
可以波形基本类似,同时听音频也听不出差别来。
可以换个测试样本看看

模型将原样本预测为8,将相应的对抗样本预测为3,说明对抗样本攻击成功了
打印其波形
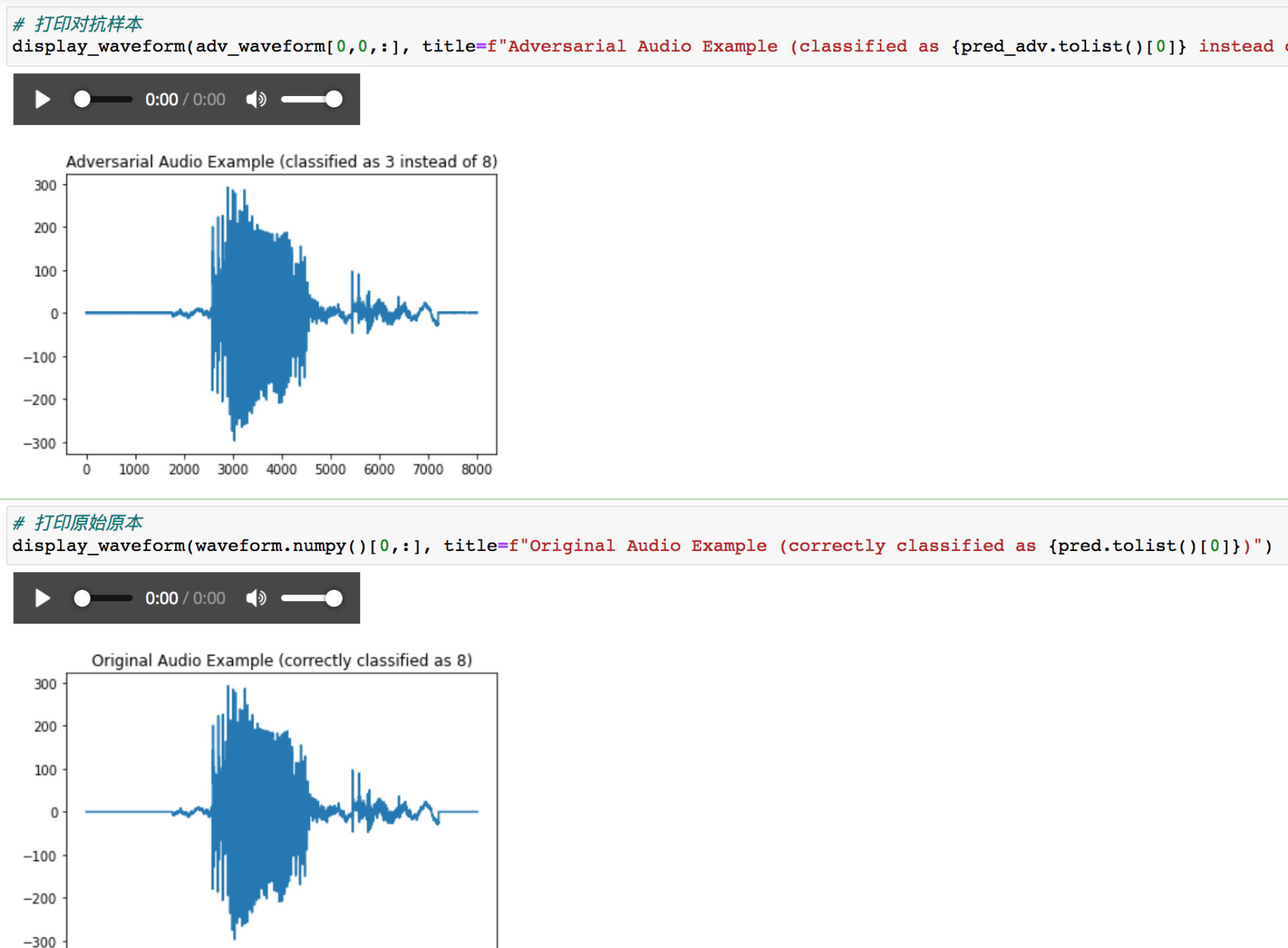
可以看到波形上区别不出来,听音频也无法区分
面对这种攻击怎么防御呢?
我们可以应用最直观的MP3压缩技术进行防御。MP3压缩的工作原理是降低(或接近)某些声音成分的准确度,这些声音成分(通过心理声学分析)被认为超出了大多数人的听力能力。这种方法通常被称为感知编码或心理声学建模,然后使用MDCT和FFT算法以节省空间的方式记录剩余的音频信息,本质上就是去除冗余。当然,我们应用mp3压缩的目的是为了在保持音频结果正确的同时去除对抗样本中添加的扰动。
其代码实现如下
将mp3防御应用于原样本和对抗样本
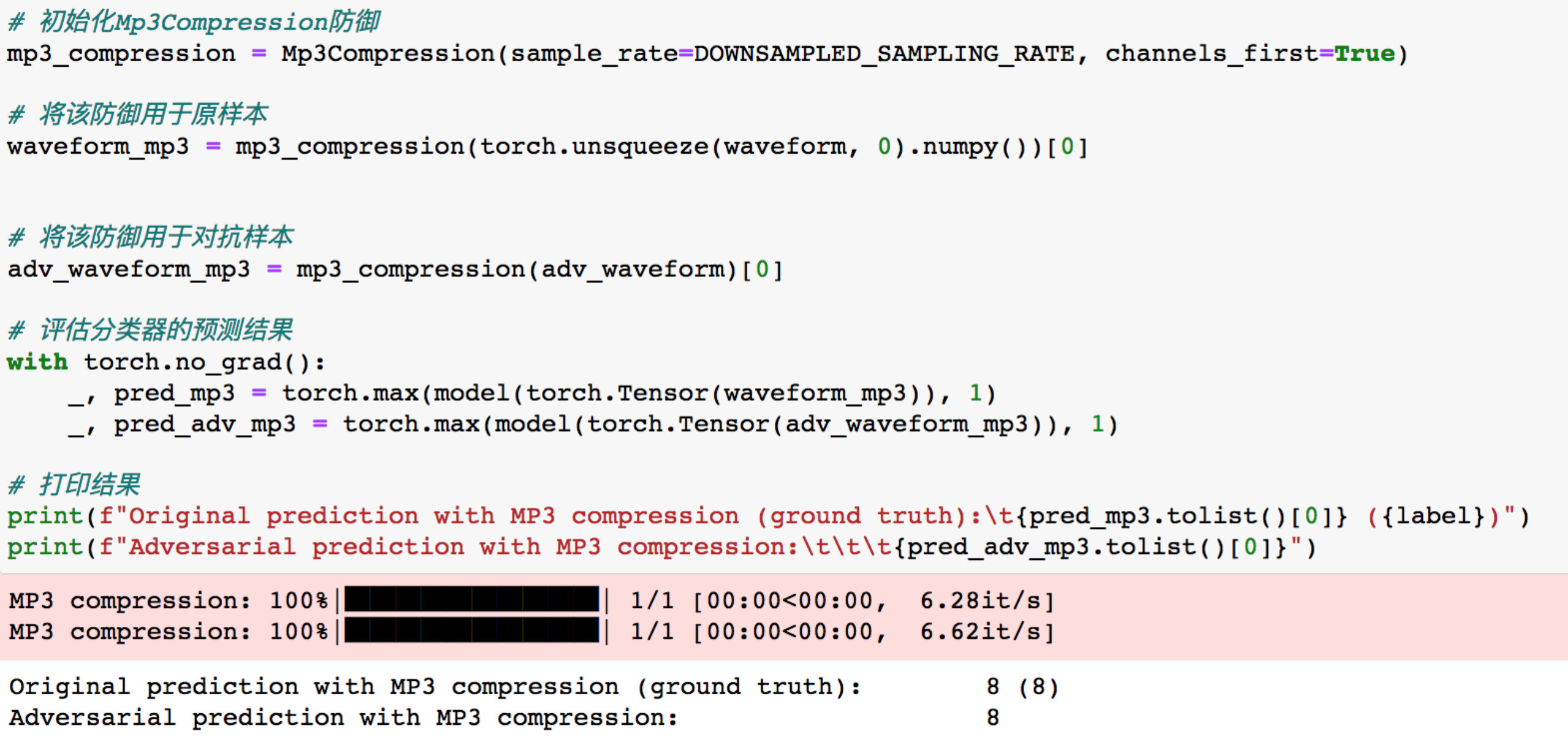
可以看到模型此时对两个样本的预测都是8,说明我们的防御措施生效了。
参考
1.https://www.crcv.ucf.edu/data/UCF101.php
2.https://github.com/soerenab/AudioMNIST
3.On Evaluating Adversarial Robustness
4.ADVERSARIAL ATTACKS FOR OPTICAL FLOW-BASED ACTION RECOGNITION CLASSIFIERS
5.ADVERSARIAL ATTACKS ON SPOOFING COUNTERMEASURES OF AUTOMATIC SPEAKER VERIFICATION
6.Audio Adversarial Examples: Targeted Attacks on Speech-to-Text
7.https://en.wikipedia.org/wiki/MP3
8.https://zh.wikipedia.org/zh/H.264/MPEG-4_AVC
9.https://github.com/carlini/audio_adversarial_examples
10.https://github.com/roiponytch/Flickering_Adversarial_Video







发表评论
您还未登录,请先登录。
登录