

前言
在现代多节点的机器学习系统,如分布式训练、协作学习等系统中,交换梯度进行训练是一种被广泛采用的方法。例如对于我们比较了解的联邦学习而言,杨强教授有一句经典的话“数据不动模型动”,意思是说数据留在参与方本地,本地的数据不会泄露给其他参与方,参与方与中心服务器之间通过交互梯度信息进行协作训练。这背后的假设是,共享梯度是没问题的,或者说,各个参与方之间交互梯度是不会泄露数据的。但是事实上并非如此,从共享梯度中获取私有数据是可行的,这就是本文的主题.
梯度泄露攻击
为了执行攻击,我们首先随机生成一对伪输入和标签,然后执行通常的前向和反向传播。在从伪数据推导出伪梯度后,不像典型训练中那样优化模型权重,而是优化伪输入和标签,以最小化伪梯度和真实梯度之间的距离,通过匹配梯度使虚拟数据接近原始的数据。当整个优化过程完成后,私有的数据(包括样本和标签)就会被恢复。
这种攻击的危害范围有多大呢?
我们知道分布式训练有两种,如下图所示,分别是中心式分布训练和去中心化分布式训练。
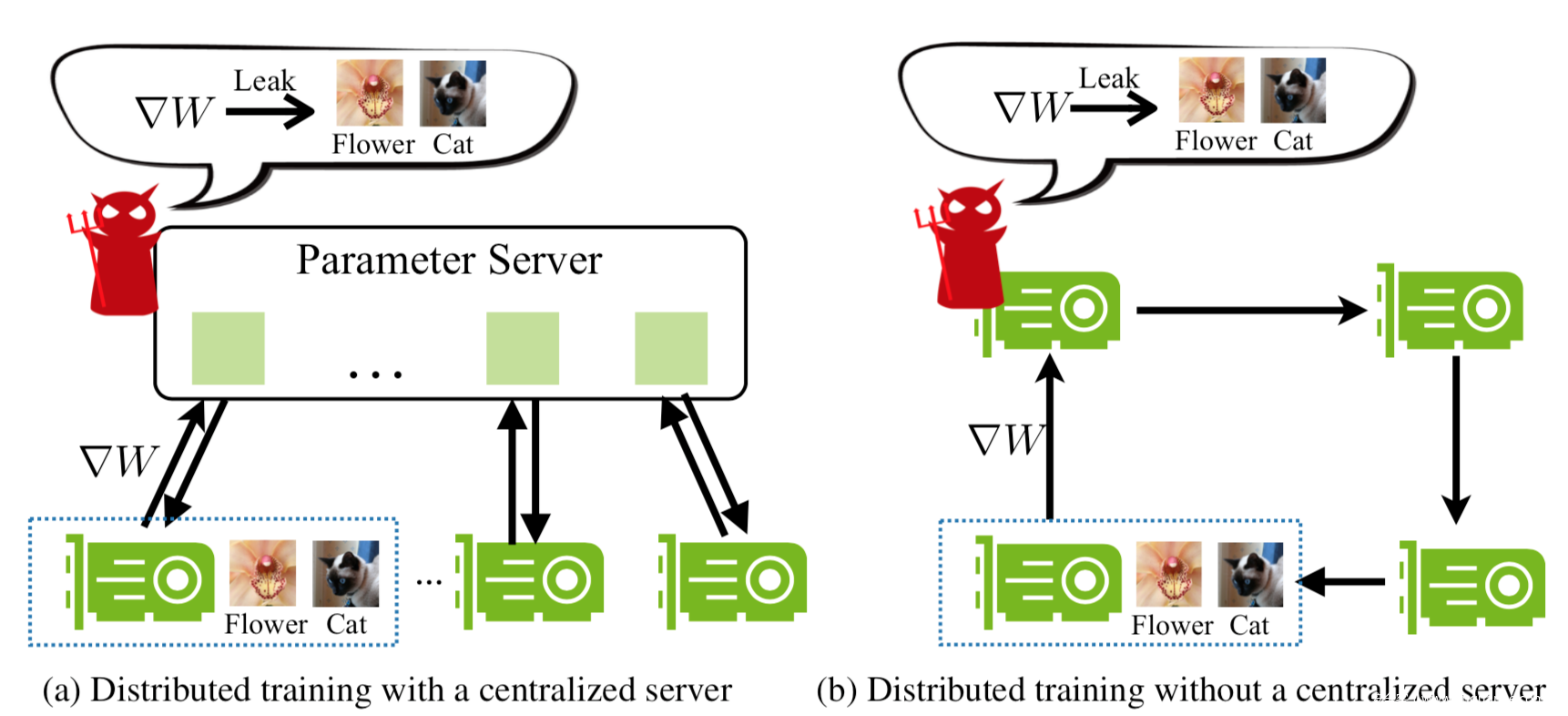
在两种方案中,每个节点首先进行计算,更新其本地权重,然后向其他节点发送梯度。对于中心式训练,梯度首先被聚合,然后返回到每个节点。对于去中心化分布式训练,梯度在相邻节点之间交换。使用本文提出的攻击方案,对于前者而言,参数服务器虽然不存储任何训练数据,但是就可以窃取所有参与方的本地训练数据,而对于后者而言,任何参与方都可以窃取与其交互梯度的参与方的训练数据,所以都是不安全的。
形式化
设在每一步t,每个节点i会从其本地数据集采样一个minibatch,来计算梯度,如下所示
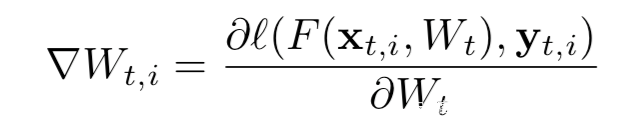
这些梯度会在N个服务器上被平均,然后用来更新权重:
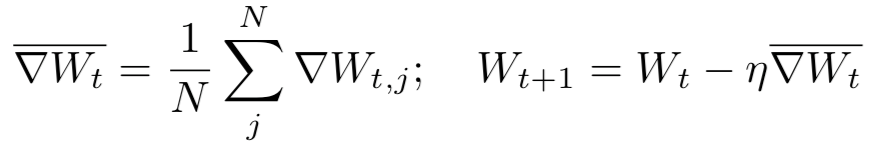
给定从其他参与方k获得的梯度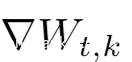
我们的目标是窃取参与方k的训练数据!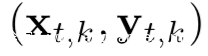
为了从梯度中恢复出数据,我们首先随机初始化一对伪输入x’和标签y‘。然后将其输入模型并获取伪梯度
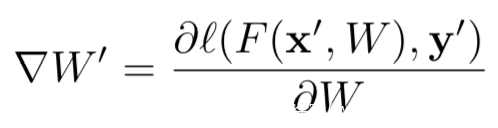
当我们在优化伪梯度让其接近原始梯度的过程中,伪数据也会逐渐接近原始的真实训练数据。
给定某一步的梯度,我们通过最小化如下目标来获得训练数据
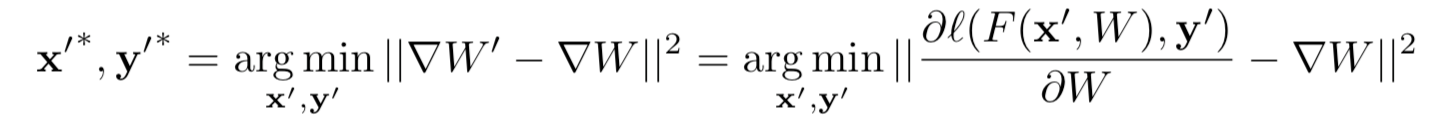
上式中的||∇w’-∇w||2是关于伪输入x’和y’可微的,所以可以用标准的基于梯度的方法进行优化。
整个形式化的攻击流程就是这么简单,我们可以来看看示意图
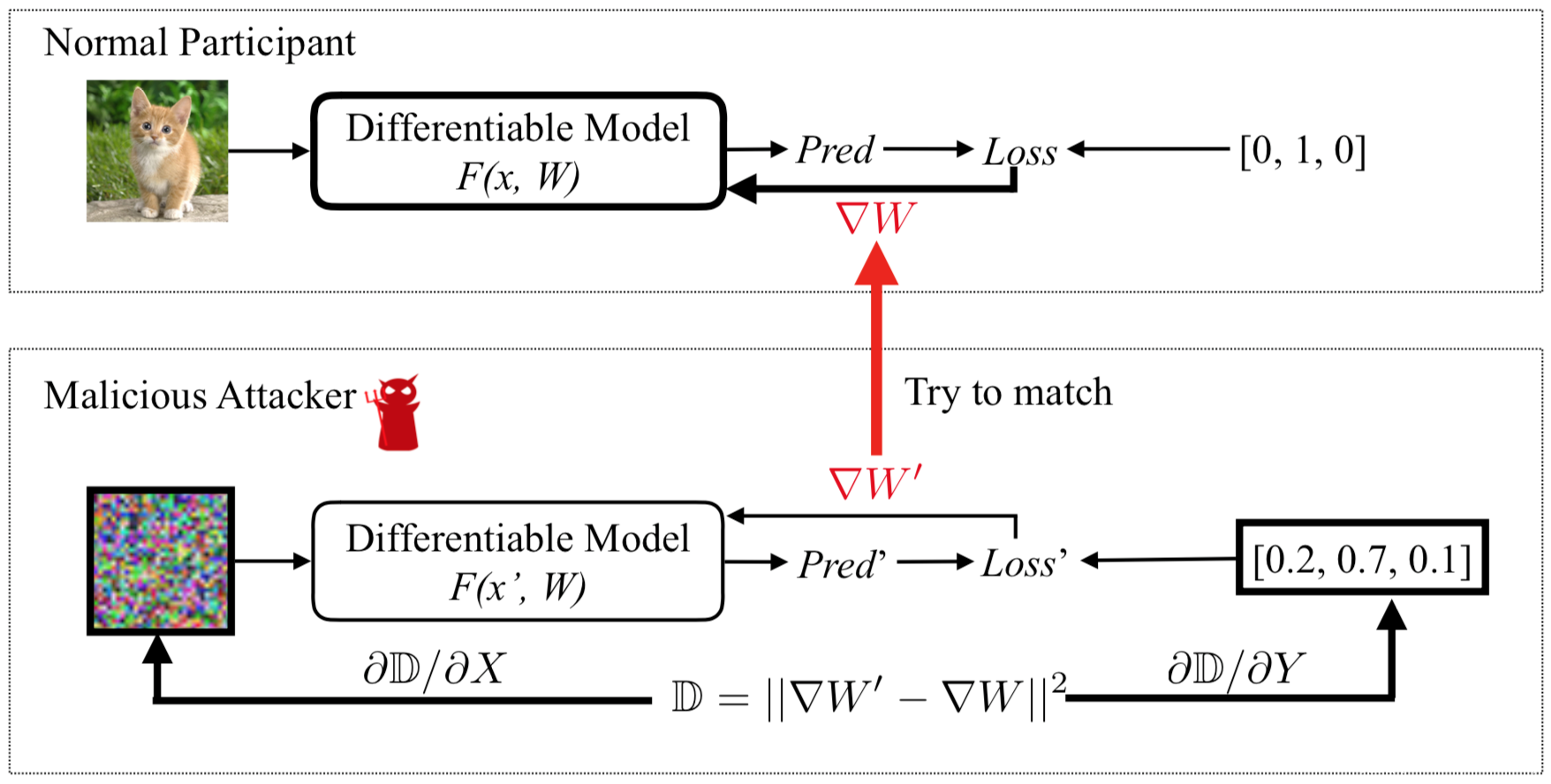
图中,需要更新的变量被粗体边框标记。正常参与方计算∇W,利用其私有训练数据更新参数,攻击者则更新其伪输入和标签,以最小化梯度距离。当优化完成时,攻击者可以从正常参与方那里窃取训练数据。
伪码表示如下

实验分析
下图是在MNIST、CIFAR-100、SVHN和LFW数据集上进行攻击的效果。从左到右,迭代次数增多,最后成功恢复了数据,图中倒数第二栏是之前的工作的攻击结果,只恢复了简单的图像和背景而已,最后一栏是原始数据。

关于梯度距离与恢复出的图像之间的关系可以看下图
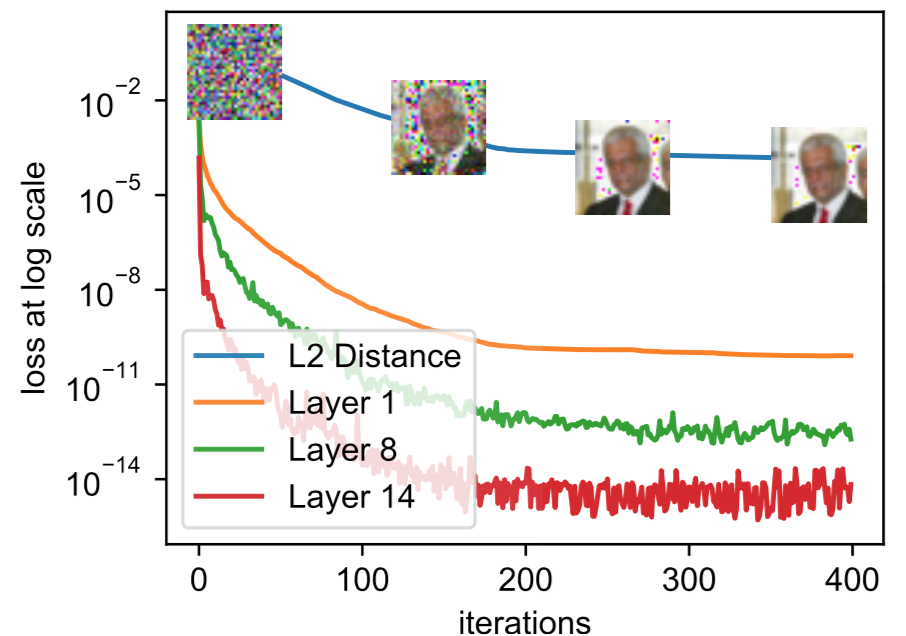
图中,layer -i表示第i层真实梯度与伪梯度之间的MSE。当梯度距离越小,恢复出的图像与原始图像之间的MSE也越小,恢复的效果也就越好。
实战
将标签转为独热标签

计算交叉熵

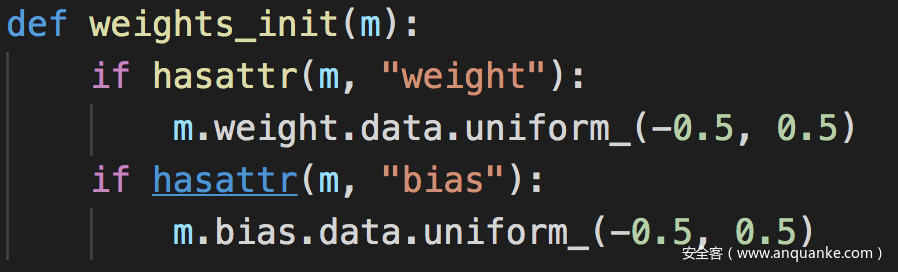
权重初始化
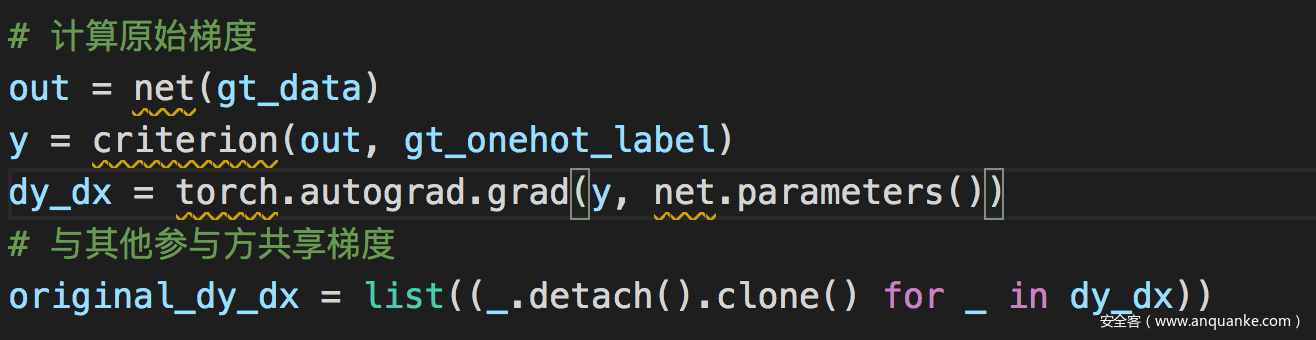
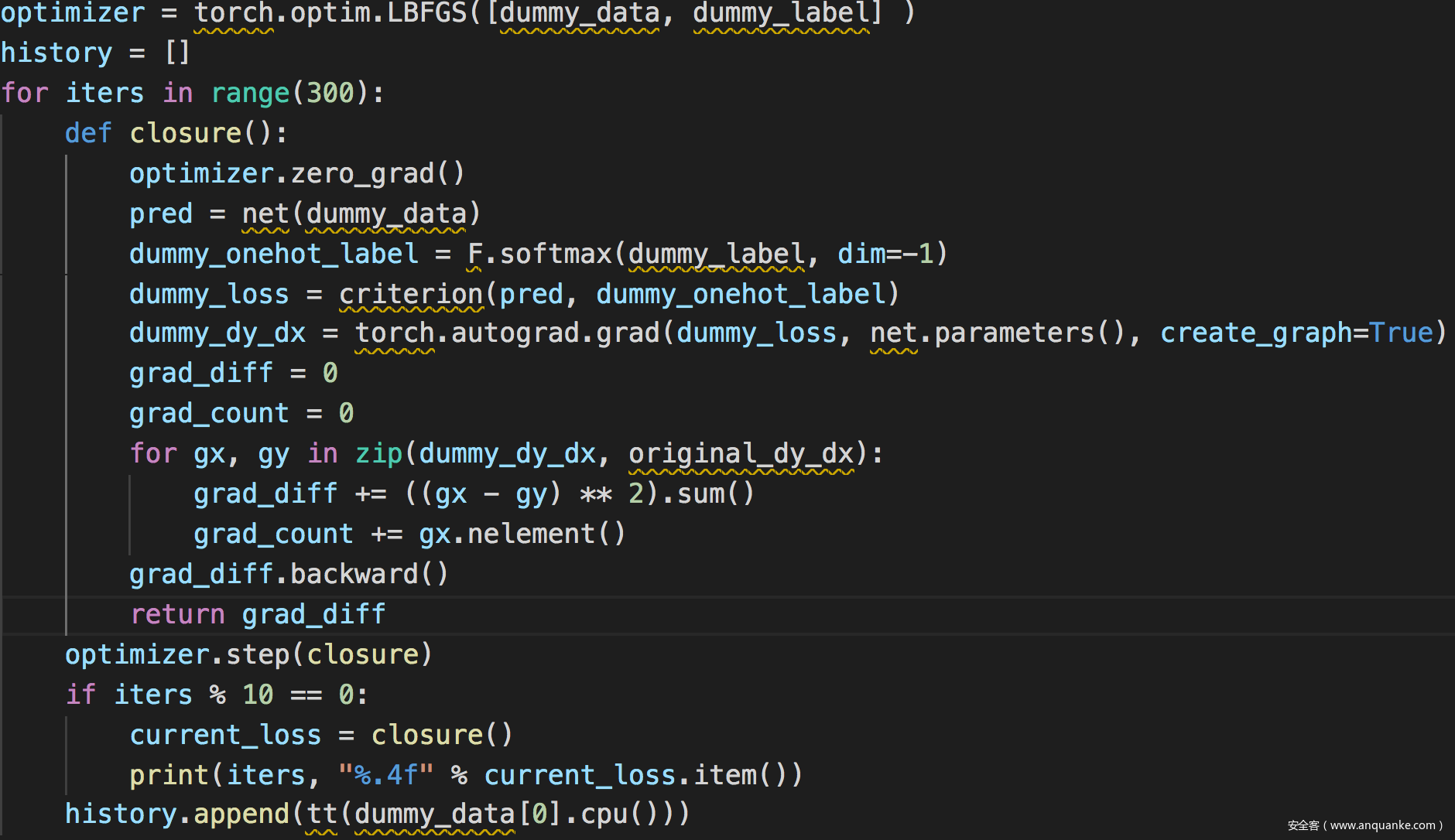
攻击
打印出原始数据真实标签以及原始图像

使用torch的randn生成随机数来初始化伪数据,并使用模型对伪数据的预测作为伪标签

然后进行训练
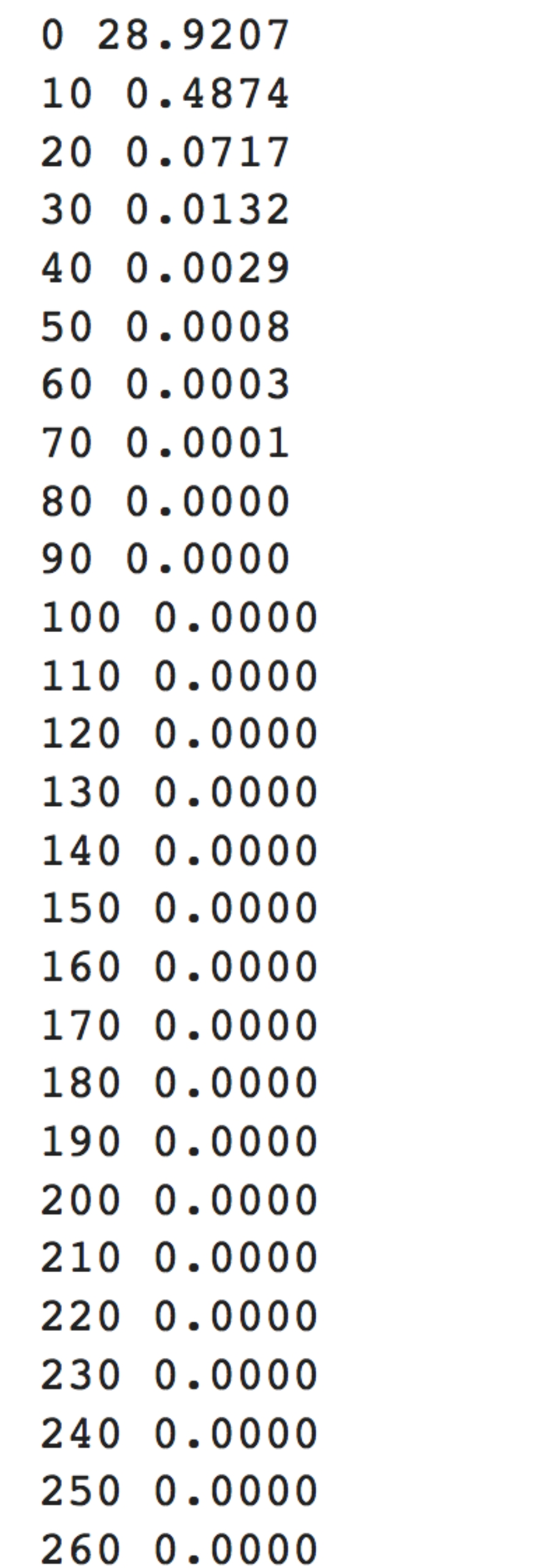
打印出每次迭代得到的数据

同样地,我们也可以使用小安的图像进行测试
原图

伪图像
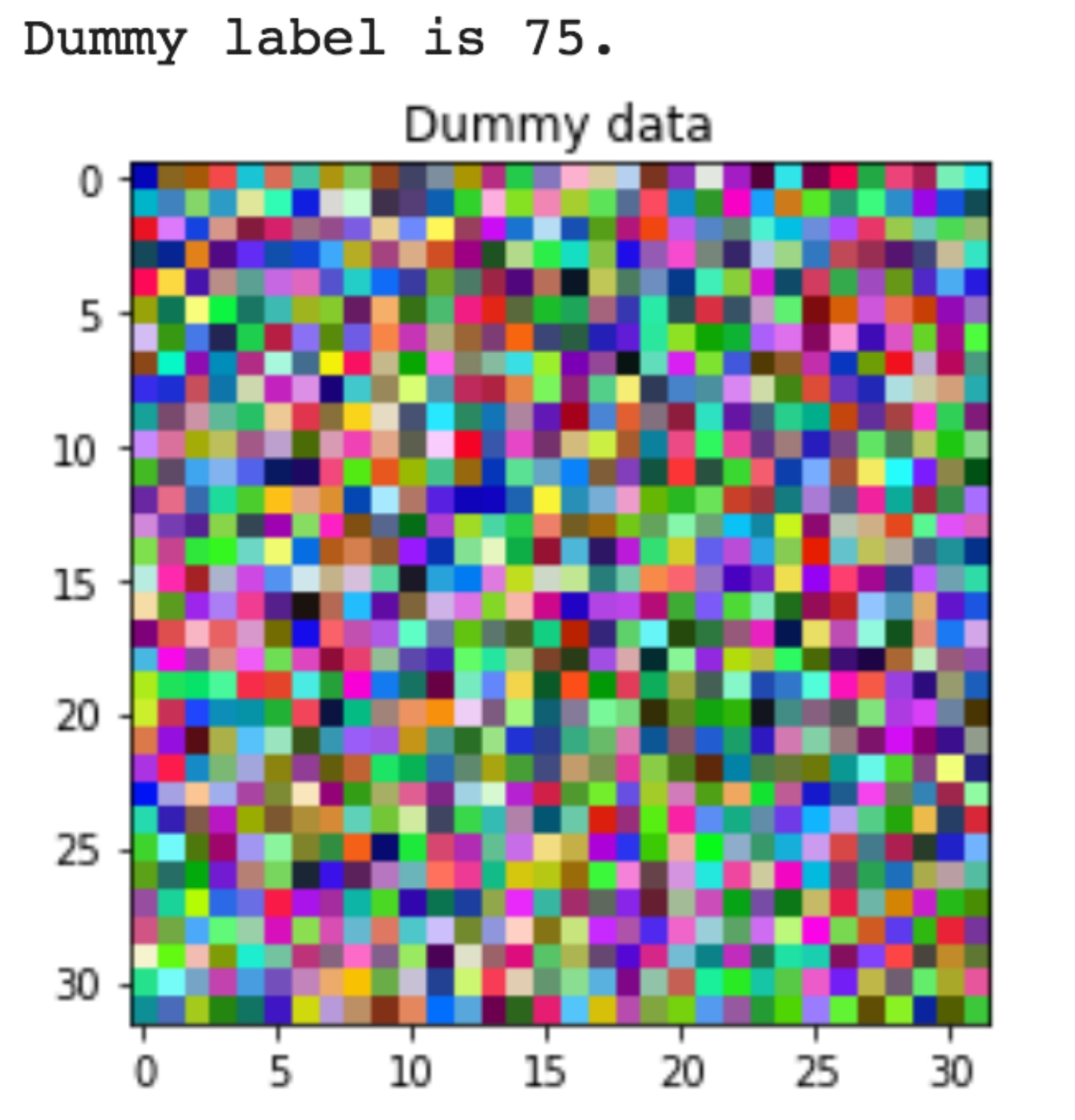
多次迭代中每次生成的图像及变换如下所示

改进攻击
上面的方案虽然确实有效,但是也存在一些问题,它不能可靠地提取到真实标签或生成良好质量的伪数据。本小节介绍一种有效的方法来从共享梯度中提取真实标签。该方案证明了关于正确标签激活的分类损失的梯度在(−1,0),而其他标签的梯度在(0,1),因此,正确标签和错误标签的梯度的符号是相反的。有了这个规则,我们可以根据共享的梯度识别真实标签。换句话说,真实标签肯定是通过共享交叉熵损失训练得到的神经网络的梯度而泄露的。这使我们能够始终提取真实标签和极大简化原攻击方案的目标,从而恢复出高质量的数据。
形式化
设神经网络是在独热编码的标签上使用交叉熵损失进行训练的,其被定义为:
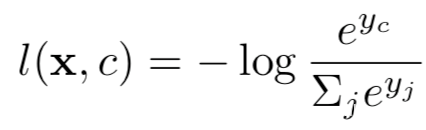
其中x为输入,c为真实标签,y=[y1,y2…]是输出,即logits,yi代表是预测为第i类的置信度。关于每个输出的损失的梯度为:
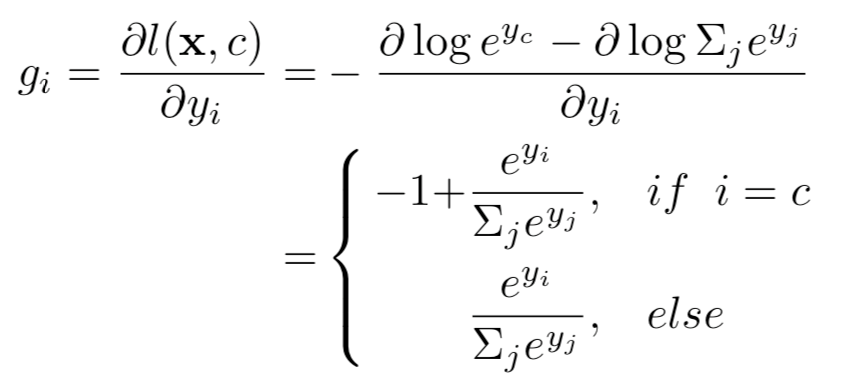
因为
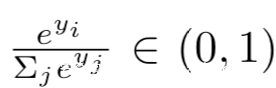
所以我们有
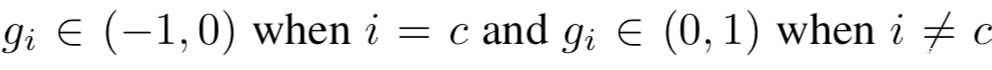
因此,如果输出的索引有负的梯度的话,我们就可以将其认作真实标签。然而,我们可能无法得到关于输出y的梯度,因为他们并不在对模型W的权限求导得到的共享梯度∇W中。不过连接到输出层中第i个logit的权重WLi的梯度向量∇WLi可以写作
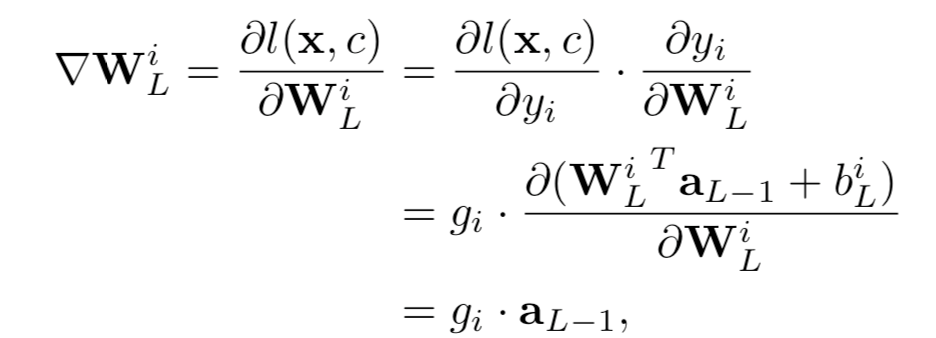
上式中,L指网络共有L层,y=aL是输出层的激活,biL是偏置参数
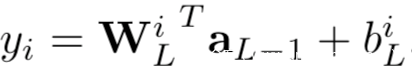
由于激活向量aL-1是与类索引i独立的,所以我们可以根据∇WLi的符号轻易地识别出真实标签。
因此,真实标签c给预测为:
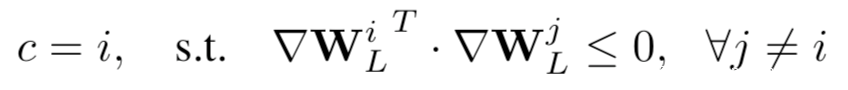
当使用非负激活函数如ReLU和Sigmoid时,∇WLi和gi的符号是相同的。因此我们可以简单地识别出对应的∇WLi为负的真实标签。通过该规则,很容易从共享梯度∇W中识别出私有训练数据x的真相标签c。
通过上述的推导,我们就得到最终的改进后的攻击方案:
首先是从共享梯度∇W中提取真实标签c ‘,然后随机初始化伪数据x ‘←N(0,1),之后基于伪数据和提取的标签(x ‘,c ‘)计算伪梯度∇W’
训练的目标是匹配伪梯度和共享梯度,即最小化
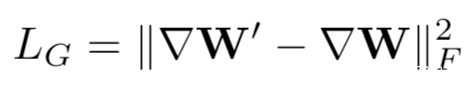
基于这个训练目标,我们可以通过梯度下降更新伪数据x’,即
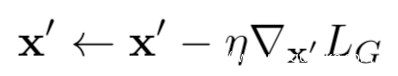
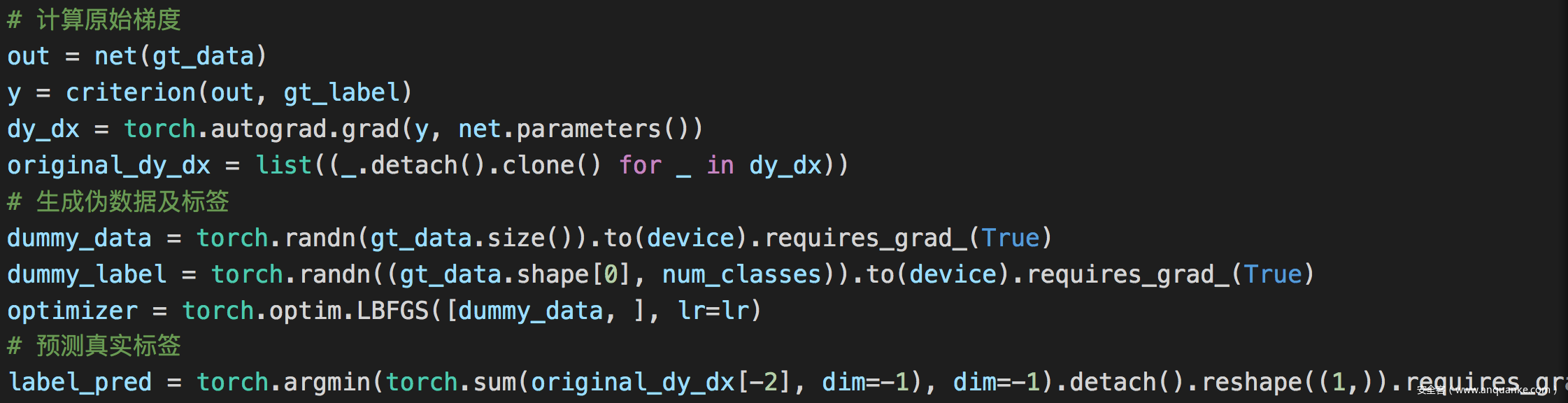
伪码表示如下

实战
计算梯度等
训练
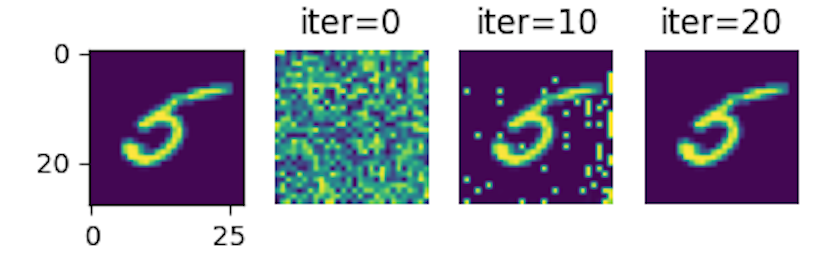
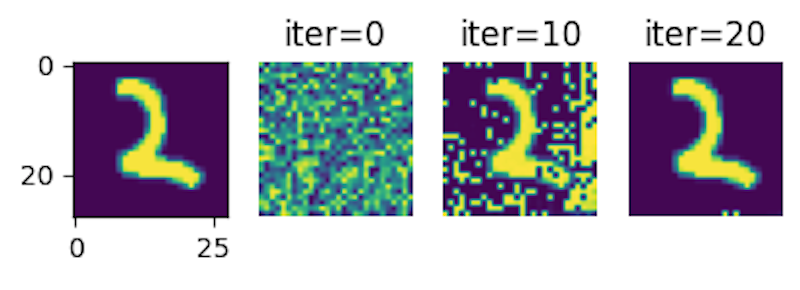
训练完毕后会得到恢复过程中保存的图像
可以看到,这些图像很容易就恢复了,经过几次迭代就可以
防御
梯度压缩
我们知道这种攻击的本质是利用了梯度,那么相关的防御措施自然也是针对梯度进行的。
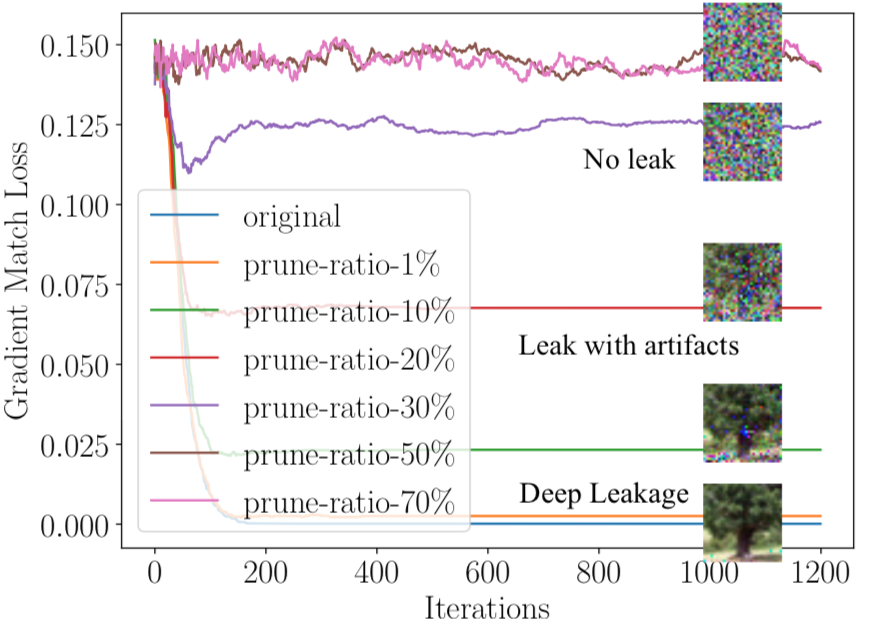
我们可以将小幅度的梯度修剪为零。当优化目标被修剪时,这种攻击方案更难匹配梯度。下图显示了不同程度的修剪如何防御泄漏。当修剪程度为1% ~ 10%时,对攻击几乎没有影响。当修剪程度增加到20%时,恢复图像上存在明显的伪像。当修剪程度比较大时,恢复的图像不再可识别了,看起来就是噪声,这说明梯度压缩可以成功防止泄漏。
添加噪声
作为防御,也可以在梯度被共享之前,加上噪声。我们使用高斯噪声和拉普拉斯噪声进行实验,其方差范围从10−1到10−4,实验结果如下
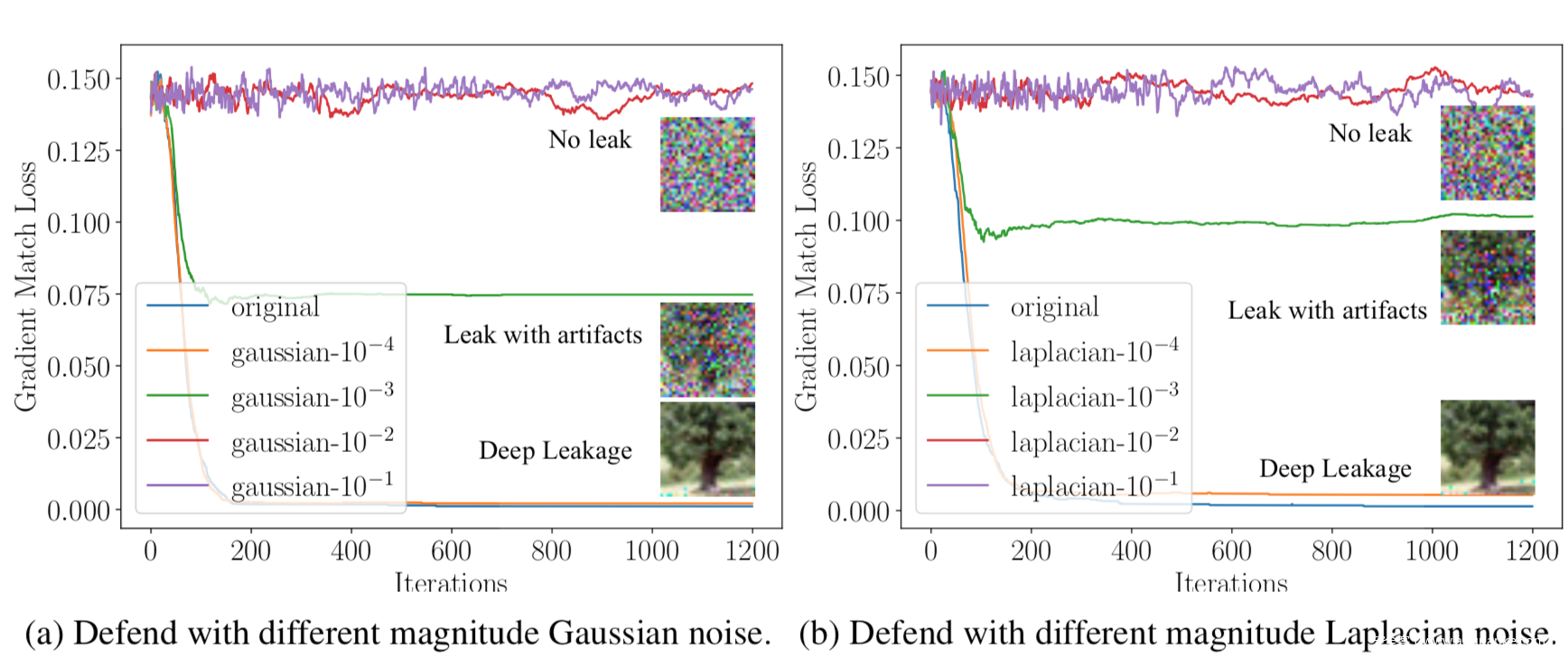
从图中可以看到,防御的效果主要取决于分布方差的大小,与噪声类型无关。当方差为10−4时,不能防止泄漏。对于方差为10−3的噪声,尽管存在伪影,仍然可以执行泄漏。只有当方差大于10−2,且噪声开始影响精度时,恢复出的图像基本不可识别了,方差大于10−2的噪声会导致恢复彻底失败。
参考
1.Laal M, Ghodsi S M. Benefits of collaborative learning[J]. Procedia-social and behavioral sciences, 2012, 31: 486-490.
2.Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19
3.Zhu L, Han S. Deep leakage from gradients[M]//Federated learning. Springer, Cham, 2020: 17-31.
4.Zhao B, Mopuri K R, Bilen H. idlg: Improved deep leakage from gradients[J]. arXiv preprint arXiv:2001.02610, 2020.







发表评论
您还未登录,请先登录。
登录